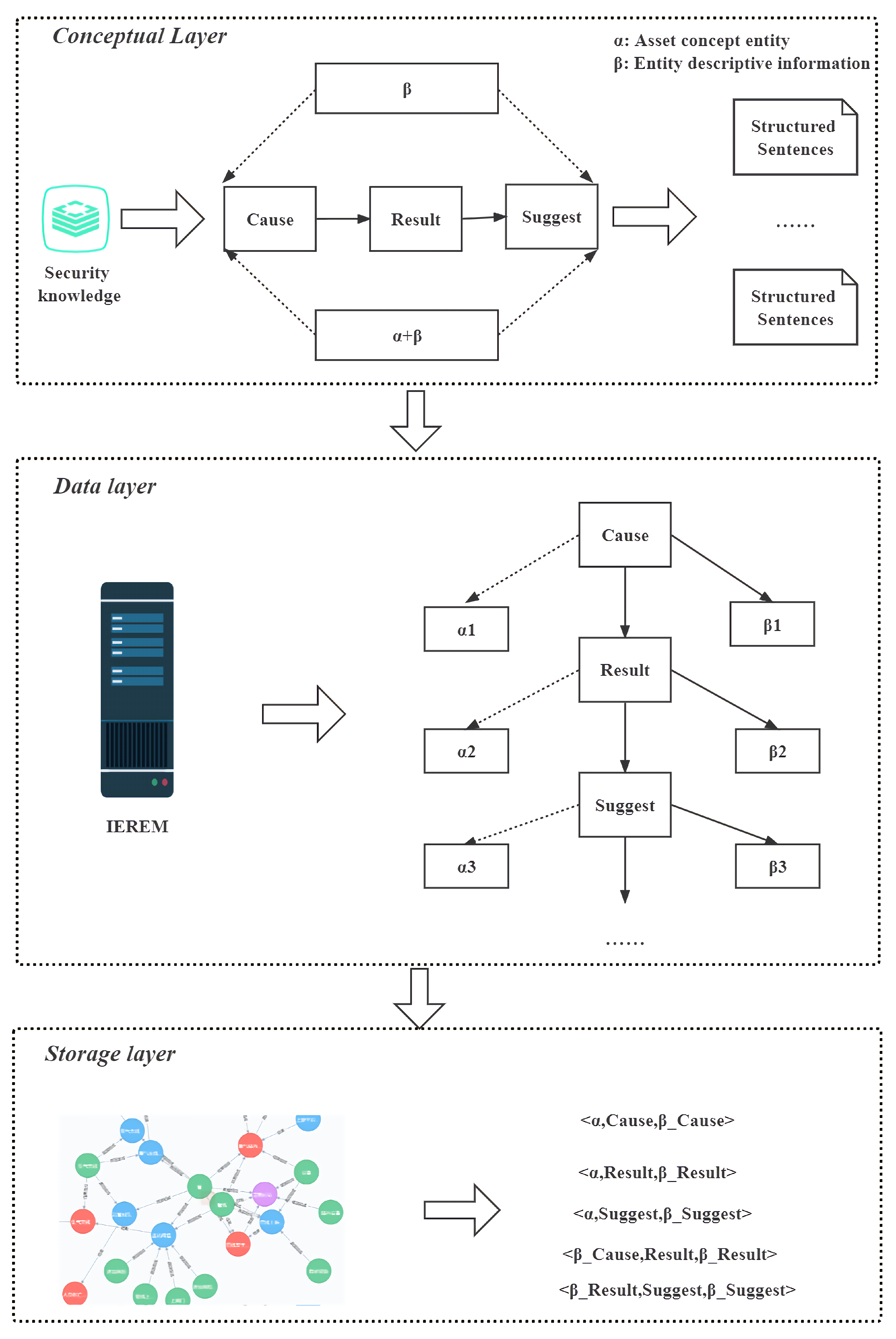
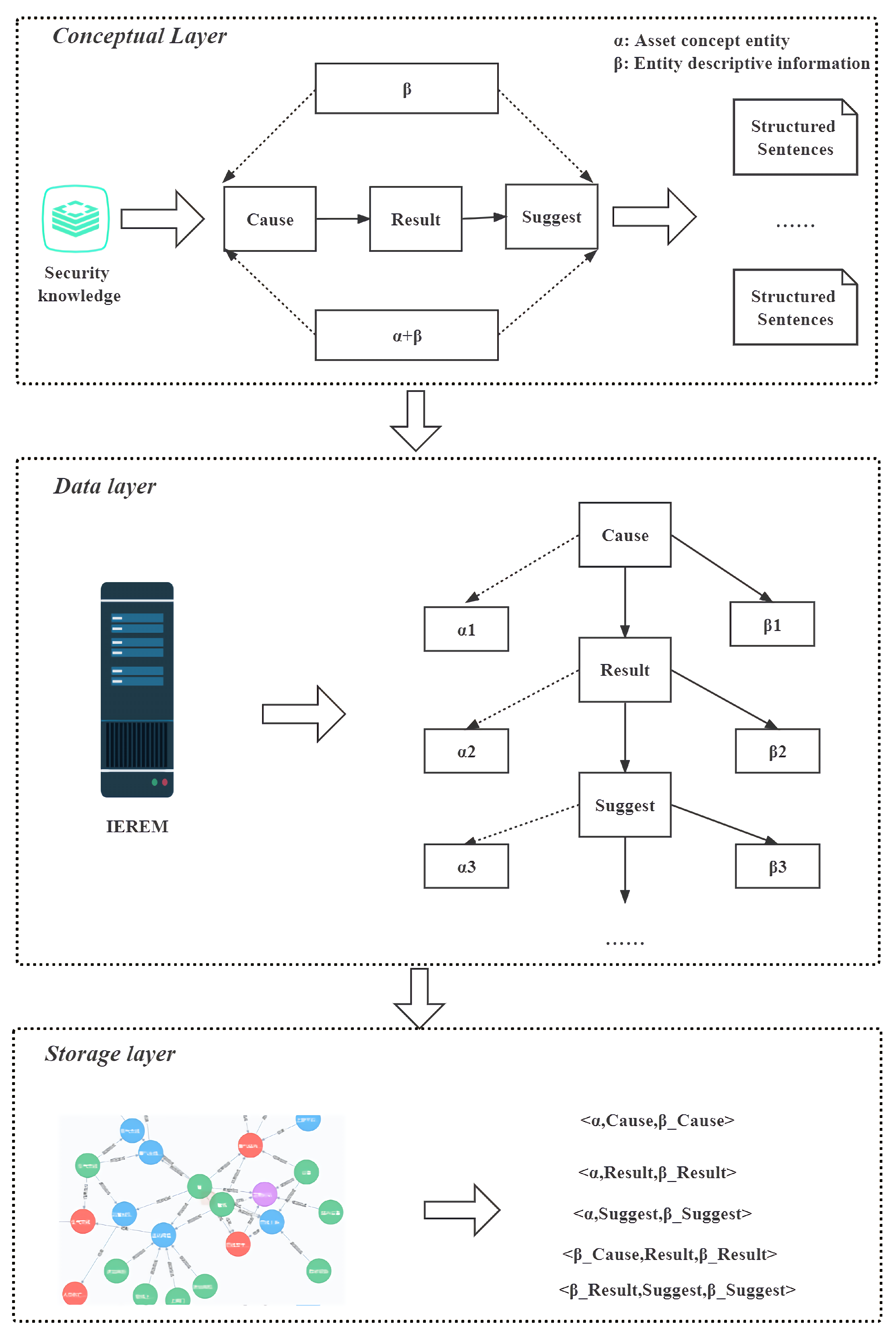
3.1. Conceptual Layer
Safety reports contain different knowledge for different processes in the process industry, such as fans and compressors in the fluid transport industry, and even within the same process, as safety experts have different focuses [
40]. Therefore, the design of industrial safety knowledge entities and their relationships faces a great challenge. To address this difficulty, we propose a process industry safety knowledge standardization framework to standardize the safety knowledge information of different processes and to represent the industrial safety knowledge of different processes uniformly. In addition, we design a generic process industrial safety knowledge expression relationship.
Due to the existence of a large number of obscure and difficult professional terms in the safety report, it is impossible to adopt methods such as clustering and merging to describe the industrial safety knowledge ontology. Therefore, we try to use the main structure of the safety report as a breakthrough. Inspired by the international standard IEC 61882 [
41], we use a top-down approach to systematically parse safety reports. First, we decompose safety reports into various hazard event processes, then decompose them into generic structures, and finally obtain an industrial safety knowledge ontology.
We decompose the safety report into a set of entities . The is briefly described as follows:
(1) C: Cause entity, which is derived from the abnormal causes in HAZOP and the formation causes in PHA, such as “transport system failure” and “flow control valve FVC closed”, “coil blockage”.
(2) R: Resulting entity, derived from consequences in HAZOP, consequences in JHA, event description in LOPA, consequences in PHA, e.g., “liquid crude oil without vaporization flows into the transport system”, “crude oil in the vaporizer will boil”.
(3) S: Recommended entities, derived from the recommended measures in HAZOP, recommendations in LOPA, control measures in JHA, and preventive measures in PHA, e.g., “Clean the coils” and “Shut down the FCV linkage”.
The diagram category
is appropriately divided into string
and inverse tree
, positive tree
, and tie tree
according to the differences between entities in
, as shown in Equation (
1).
Among them,
is the simplest
, which contains only a single causal chain of relations. For
, different causes produce the same result, and it is a very tricky problem to analyze
by exhausting all the causes. In the
structure, each result generates multiple suggestions, which creates more obstacles for subsequent work.
is the most complex, integrating
,
, and
. In general, industrial processes are closely connected, and if one process fails, it will affect the others. Therefore,
has also gained the attention of industry professionals as a key structure in the field of process industry safety. Equations (
2)–(
5) are their definitions.
Furthermore, we denote each entity in each EL in the form of “
”, where
denotes the asset concept entity corresponding to the asset in the asset management shell (an asset is an “object of value to an organization”), and
denotes the descriptive information of the concept entity, e.g., the “failure” of the “supply system failure”. “failure” is the descriptive information about the “failure” of the concept entity “feed system”.
and
, as a general framework of basic knowledge, can be used to represent safety reports and form industrial safety knowledge ontologies (
) from them. We transition the possible pitfalls of such a corpus by treating assets as possible components of entities, as shown in Equation (
6).
The general framework of industrial safety knowledge constructed in this paper differs from the general knowledge graph in that there is no general sense of the relationship between industrial safety knowledge in safety reports. For example, “the main character of the movie Drunken Fist is Jackie Chan”, “Drunken Fist”, and “Jackie Chan” have the relationship of “main character”, but in the industrial field, “Drunken Fist” and “Jackie Chan” have the relationship of “main character”. However, in the industrial field, the “carburetor overload”, there is no relationship. Therefore, to overcome this obstacle, it is necessary to step out of the traditional shackles. The nature of safety reporting leads us to the following discussions:
(1) Industrial safety knowledge relationships aim to connect industrial safety knowledge into an organic whole. Safety reports usually have potential categories, such as PHA with multiple categories consisting of risk factors, consequences, formation causes, and preventive measures. Safety report as the carrier of the relationship can be equated to the key elements in the industrial safety report template collection V: cause, result, and recommendation;
(2) Safety reports take time toward the implementation of safety measures for prevention, and their own characteristics of the order of execution in terms of the causes and consequences of events make the execution more logical.
Therefore, we follow the execution logic of safety reports in a novel way by using industrial safety knowledge attributes as relations
of ISK, with the relation links shown in Equations (
9) and (
10).
In summary, we have completed the construction of the conceptual layer of the industrial safety knowledge ontology in this section; studied how the knowledge categories, including those specific to industrial safety reports, are transformed into relationships; and proposed a novel unified structure of industrial safety knowledge that enables the reuse and structured representation of industrial safety reports for different processes. The unified structure of industrial safety knowledge is an industrial safety engineering design practice, which expands the perspective of industrial safety engineering design and provides ideas for academic researchers. We also believe that it can help realize the intelligent and automated expression of knowledge in the field of industrial safety.
3.2. Extraction Layer
The general structure of the knowledge graph is a triadic structure of entities through relationships to another entity. The extraction layer should address both entity extraction and relationship extraction. Because the industrial safety knowledge relationships are already identified in the conceptual layer, this section focuses on how to perform the extraction of entities. The current security report text mainly has the following characteristics:
(1) A wide variety of long entities. For example, “safety switch installation set machinery”, “compressed gas regulation system”, “gas mains and gas cabinet water of gas cabinet”;
(2) Diversified entity nesting. For example, “gas main pipe of gas cabinet and gas cabinet water”, “overflow pipe of gas washing tower”, “water jacket or steam ladle constitutes a closed system”;
(3) Plenty of technical terms, such as “valve diversion" and “opening degree”;
(4) Even in the same process industry scenario, different experts usually have different semantic expressions for the same incident. For example, statements are inverted (“low flow initiates FAL”), and subjects are omitted (“no crude oil inflow”), so the text is more diverse.
It is worth noting that in the unified structure of industrial safety knowledge (ISKG), safety reports such as ISKG(, ) (ISKG with and content) or ISKG() (ISKG with content), and are intertwined, e.g., “The Roots blower pumped negative pressure, allowing air to enter the system and mix with semi-water gas”. How to extract entities from security reports with such characteristics is a problem worth considering. Therefore, inspired by the new knowledge graph connecting data science and engineering design, we design an advanced industrial safety information extraction model, INERM, which is a named entity information extraction model with a mixture of multilayer neural network and machine learning. We will describe the extraction layer from three aspects: security report dataset, INERM, and experiment.
3.2.1. Safety Report Dataset
First, we extract unstructured data from professional websites, such as China Industrial Safety Network, China ChemNet, Oil and Gas Storage and Transportation Network, and Aerospace Cloud Network, and search websites, such as Baidu Encyclopedia, Wikipedia, and Baidu Library. We preprocess them to obtain the original text of safety reports and collect 12,948 safety reports from the original text by data cleaning and segmentation operations and rule-based methods.
BIO is a classical and common annotation method in the field of named entities: B means the word is at the beginning of an entity (Begin), I means inside (Inside), and O means outside (Outside). A group of BI can form an entity (Single), another expansion B_x expresses the beginning of entity category x, I_x expresses the end of entity category X, O indicates that it does not belong to any type. We adopted the BIO annotation method to label 8000 security descriptive sentences with different relationships. Our definition of entity categories is shown in
Table 1. Finally, we split the security description corpus sentences into 80% training sets, 10% verification sets, and 10% test sets.
3.2.2. INERM
Bidirectional encoder representations for transformers (BERT) is a transformer’s bidirectional encoder designed to pre-train deep bidirectional representations from an unlabeled text by conditional computation common in left and right contexts. For a more accurate logical structure of R() in security reports, NEST sentence prediction (NSP) can predict better. However, the coexistence of multiple entities in safety report information often leads to the problem of correct linkage of entities. For example, “equipment and piping are not observed in manufacturing, inspection, and maintenance, and are inherently defective”, where there are multiple causal entities and only one factor, “defective”, leading to undesirable consequences, while “Inspection and maintenance are not observed” will not lead to adverse consequences. To solve, we provide a more natural way of thinking: calculate the entity weight of each entity based on the entity contribution weight model of BERT-biLSTM-CRF, then improve the Term Frequency-Inverse Document Frequency (TFIDF) algorithm by combining the entity weight of each candidate key entity, and finally retrieve and extract the key entity.
In conclusion, INERM is mainly composed of BERT, bidirectional long short-term memory (BiLSTM), conditional random field (CRF), and TFIDF. BERT extends and enriches semantic features. BiLSTM is used to obtain context information and information from the long-distance-dependent encoder. CRF can calibrate the order and relationship between labels to obtain the global optimal prediction sequence. TFIDF extracts key entities through statistical features.
Figure 2 shows the overall framework, where the input to INERM is the security report description and the output is the corresponding entity. First, token embedding (sentence embedding and position embedding) generated by the security report description is trantokensmitted to BERT, Then, BERT converts the joint embedding into semantic vectors containing semantic features and passes them to BiLSTM. Next, the BiLSTM uses a pair of bidirectional LSTM to encode the semantic vector to obtain a context vector with context characteristics. Finally, CRF calibrates the order and relationship between tags, the entity link rules constrain the output of entities, and TFIDF decodes the context vector to output the entity sequence with the maximum probability. A detailed description of each module follows.
BERT
Language model pre-training can effectively improve many natural language processing tasks [
42], where the BERT pre-training model is based on a bidirectional multilayer transformer model, and the transformer model is based on encoder–decoder and attention mechanisms [
43]. The BERT model removes the limitation of self-attentiveness of the unilateral context (above or below) through the bidirectional self-attentiveness mechanism [
44]. Applying the BERT pre-training model achieved better results in several natural language processing tasks.
In this paper, we use the model BERT, which is constructed as follows. First, the joint embedding
of word embedding and location embedding is passed to the multi-headed attention layer. The attention distribution
is obtained by the formulae of the multi-headed self-attentive layers q, k, v. Then, the vector e and the vector a are normalized to obtain
, and
is transferred to the feedforward neural network (FFN) to obtain a deeper representation of the vector
. Finally, the vector
f and the vector
are layer normalized once more to obtain the output vector
. The multi-headed sub-attention layer is the core of BERT, which solves the problem of long-range dependence on RNNs. The self-attention of BERT is shown in Equation (
11).
where
is the query vector,
is the key vector,
is the value vector.
Q,
K, and
V are obtained by linear mapping of the different weights W of the vector
E, which have the same dimension. It is worth noting that where
is the dimensionality of
K. In addition, we apply the Chinese BERT pre-training model released by Google on GitHub, which is trained using the Chinese Wikipedia corpus. The specific parameters of the model are introduced as shown in
Table 2.
In this paper, we extract the output of the last 4 layers of the pre-trained BERT model to calculate the sentence vector. Assuming that
is the output of the penultimate
i layer of the pre-trained model with time step j (0 < i < 5, 0 < j < 41), the sentence vector is computed as follows. First, calculate the average
of the output of each layer:
The entity vector
B is the merge of the mean of the four layers.
That is, if the input text is a sequence of text tweens containing more than 3 entities, the final output B is a two-dimensional matrix, , where l is the text length and H is the BERT model output vector dimension 768.
BiLSTM
BiLSTM is a special recurrent neural network that has been used as a tool for processing long time-series data and consists of the following three main parts. The first part is the information transfer part, where the input value
is a coefficient of
in the interval [0, 1], which is a mapping of the sigmoid function of
based on the output value
. If
is 1, the whole
will be retained. If
is 0, the whole
will be discarded as shown in Equation (
14). Then comes the information addition part. First, the hyperbolic tangent (tanh) generalization is performed on
and
simultaneously to generate the candidate vector
; then, the sigmoid functionalization is performed on
and
simultaneously to generate the weights W to regulate the update of
; finally, the superimposed state vectors
and
to update
, as shown in Equation (
15). The third part simultaneously sigmoid functionalizes
and
to generate weights
,
interacting with the functionalized
to obtain
, as shown in Equation (
16). These operations give the LSTM the ability to memorize and retain only important features, which can alleviate the problems of poor long-term dependence, gradient disappearance, and gradient explosion [
13].
The entity weight recognition model proposed in this paper is namely a sequence-labeling model for textual entity sequences.
Among them, LSTM solves the problem that the standard RNN model disappears when the time lag between the relative input event and the target signal is greater than 5–10 discrete time steps [
44] and has a wide range of applications in sequence-labeling-related tasks. The entity contribution recognition in this paper is a sequence-labeling task, and its processing of the current time-step semantic data requires both previous and subsequent semantic information, compared to standard RNN, LSTM cells add input gates, output gates, forgetting gates, a single LSTM cell as shown in
Figure 3.
Assuming that the input sequence is
, which
is the sequence of text vectors containing entities obtained by the BERT pre-training model, the LSTM cells are represented as follows:
where
is the input gate,
is the forgetting gate,
is the cell state,
is the output gate,
is the hidden layer,
is the activation function,
W is the weight parameter,
b is the bias parameter, and
W as well as
b are the parameters to be trained in the model. The network structure is shown in
Figure 4.
The BiLSTM is a superposition of a forward LSTM and a backward LSTM, and the output equation of a single-layer BiLSTM is as follows:
is the output of the hidden layer with forward LSTM time step t in BiLSTM, and
is the output of the hidden layer with backward LSTM time step t.
CRF
BiLSTM treats each label as an independent existence and focuses more on the maximum probability of the labels without considering the dependency relationship between labels, which leads to confusing prediction information. INERM introduces CRF as a decoder to solve the above problem. CRF can calibrate the order and relationship between labels to obtain the globally optimal prediction sequence. The maximum likelihood estimation loss function of CRF is shown in Equation (
19). It should be noted that after obtaining the entity label, the entity link rule constraint is performed, and the specific constraint is seen in the storage layer (
Section 3.3).
where
is the input sequence,
is the sequence of predicted entities,
is the actual entity sequence, and
is the sum of the firing and transition fractions.
BERT-BiLSTM-CRF-Based Entity Weight Calculation Model
The structure of the BERT-BiLSTM-CRF-based entity vector weight calculation model, i.e., the entity identification model. The entity vector weight calculation model based on BERT-BiLSTM-CRF is the entity identification model. The sentence vector sequence preprocessed by BERT is input to the BiLSTM model, and the output is the hidden vector
H. The output of the hidden layer of the BiLSTM model enters the CRF to correct the entity labels at each time step, and then the classification is performed by the classifier to complete the entity identification. The selected classifier is a softmax classifier with the following equation:
where
W hidden layer output,
H classifier parameters. Suppose the final trained BiLSTM model is a function g, the BERT Chinese model is a function f, and the input text sequence is
, then the probabilities of entity categories
(key entities (category 0), minor entities (category 1), and common entities (category 2)) in the model text sequence are calculated by sentence vectors as follows:
where arguments of the maxima (argmax) is the function to determine the position of the maximum value.
TFIDF
TFIDF is a common method to extract keywords by statistical features. Among them are TF Term Frequency, which is used to quantify the ability of a word to summarize the subject content of a text, and IDF, which refers to Inverse Document Frequency, which is used to quantify the ability of a word to distinguish different categories of texts. In this paper, we add sentence weights and external corpus to improve the TFIDF algorithm.
TF Calculation
The traditional TF calculation only takes the number of occurrences of a candidate word in a sentence as the ability of the word to summarize the text topic content, ignoring the semantic and contextual information, and thus cannot correctly represent the ability of the word to summarize the text topic content. In this paper, we propose the TF value algorithm for adding sentence weights, and the TF value for the
entity in the jth sentence is calculated as follows:
where
is the number of occurrences of
entity in the
jth sentence,
to balance the effect of sentence length; entity
in the lth occurrence of the jth sentence.
The sentence contribution weight that
is introduced as follows. Firstly, the probability that an entity in a sentence belongs to each type is calculated by the entity contribution weight calculation model, then the entity type is the class with the highest probability. Because different entity types correspond to different entity contribution weights, we use the parameter
to control the effect of type on the sentence contribution weight.
Calculation of IDF values by applying external corpus
The traditional IDF value is calculated as the log value of the ratio of the number of texts with candidate words to the total number of texts, which ignores the distribution of candidate words among different topics, e.g., the word “accident” occurs in almost all of the safety report corpus. In this paper, we apply the external corpus value algorithm, i.e., in the process of IDF value calculation, the external general corpus is added to the safety report sentence corpus, and the corpus for calculating IDF value is the set of external general corpus and safety report corpus, and the formula for calculating IDF value of
words in the jth sentence is as follows:
where D denotes the set of security report sentences and d denotes the set of external corpus sentences, where
shows the total number of sentences in the original corpus and the external corpus merged set,
the number of sentences with
words occurring in the corpus and the external corpus set.
TFIDF value calculation
The TFIDF value is the product of the TF value and the IDF value, and the TFIDF value for the
entity in the jth sentence is calculated as follows:
Experimental results
The metrics precision (P), recall (R), and F1-score (F1) are used to evaluate the extraction performance of INERM. P: P in this paper refers to how many of the keywords extracted by the algorithm are correct and are calculated. The expression is as follows:
R: R in this paper refers to how many correct keywords are extracted by the algorithm in a sentence and are calculated. The expression is as follows:
m is the number of correct key entities extracted,
is the number of key entities extracted, and
is the number of keywords in the text itself. F: The F-value is the weighted summed average of the precision rate P and the recall rate R, calculated as follows:
In this paper, we determine the sentence contribution weight parameter
experimentally, compare the model results of choosing different
on the training set, and select the best
value. Considering that most of the key entities of each sentence in the product development knowledge corpus are 2–4, the algorithm selects the first 4 as the key entities for each sentence. The performance of the algorithm corresponding to different
values on the training set is shown in
Table 3. When the
value in the table is 0.6, the accuracy of the model on the test set and the verification set is on average 8 percentage points higher than other values. Therefore, the
value selected is 0.6.
The keyword extraction algorithm proposed is used to verify the algorithm. Considering that there are different kinds of key entities in each sentence of the industrial safety report corpus, the total number of key entities is 1–4. For each sentence algorithm, 1–4 different types of key entities can be extracted. It should be noted that the common hyperparameters for all neural networks are the same in both evaluation and comparison experiments. For example, we use the Adam optimizer with a learning rate of
, the ReLU activation function, and train 30 epochs on the validation set and the test set for all models. In order to confirm the extraction effect of INERM, this paper conducts a comparative experiment on different algorithms to predict all entities on the test set. The comparison results are shown in
Table 4. The results show that INERM has a strong extraction performance. The results show that INERM is feasible in the task of industrial safety knowledge extraction.
In the table, the F score of the INERM predicted entity in the test set is 67.5%. From the overall comparison experiment results, the accuracy of the existing models on the test set is far less than 67.5%. In addition, the overall performance of all models in P, R, and F scores is far less than that of the INERM model. In the comparison of the F value, INERM is 19 percentage points higher than BERT, 21.4 percentage points higher than BiLSTM, and 15 percentage points higher than the most classic combination model BERT-BiLSTM-CRF. The results show that INERM has a strong entity extraction performance and also prove the feasibility of INERM in the field of industrial safety. We believe that it can make an important contribution to the task of industrial safety knowledge extraction.
3.3. Storage Layer
We show the industrial safety knowledge graph triad constructed by the relationship between industrial entities and settings in the form of Equation (
29). Where the set
of the industrial safety knowledge-mapping triad consists of node head
and node tail
, which are both industrial safety entities, and two nodes are connected with an edge e, which denotes the relationship located between the two entities. Specifically, each industrial safety report node description is taken as input. By extracting the entities (
and
) in the input, element relationships are embedded between
and
in turn. Considering the possibility of multiple C and S, the triples about R are first constructed from both ends of the input, and then the triples about C and S are constructed.
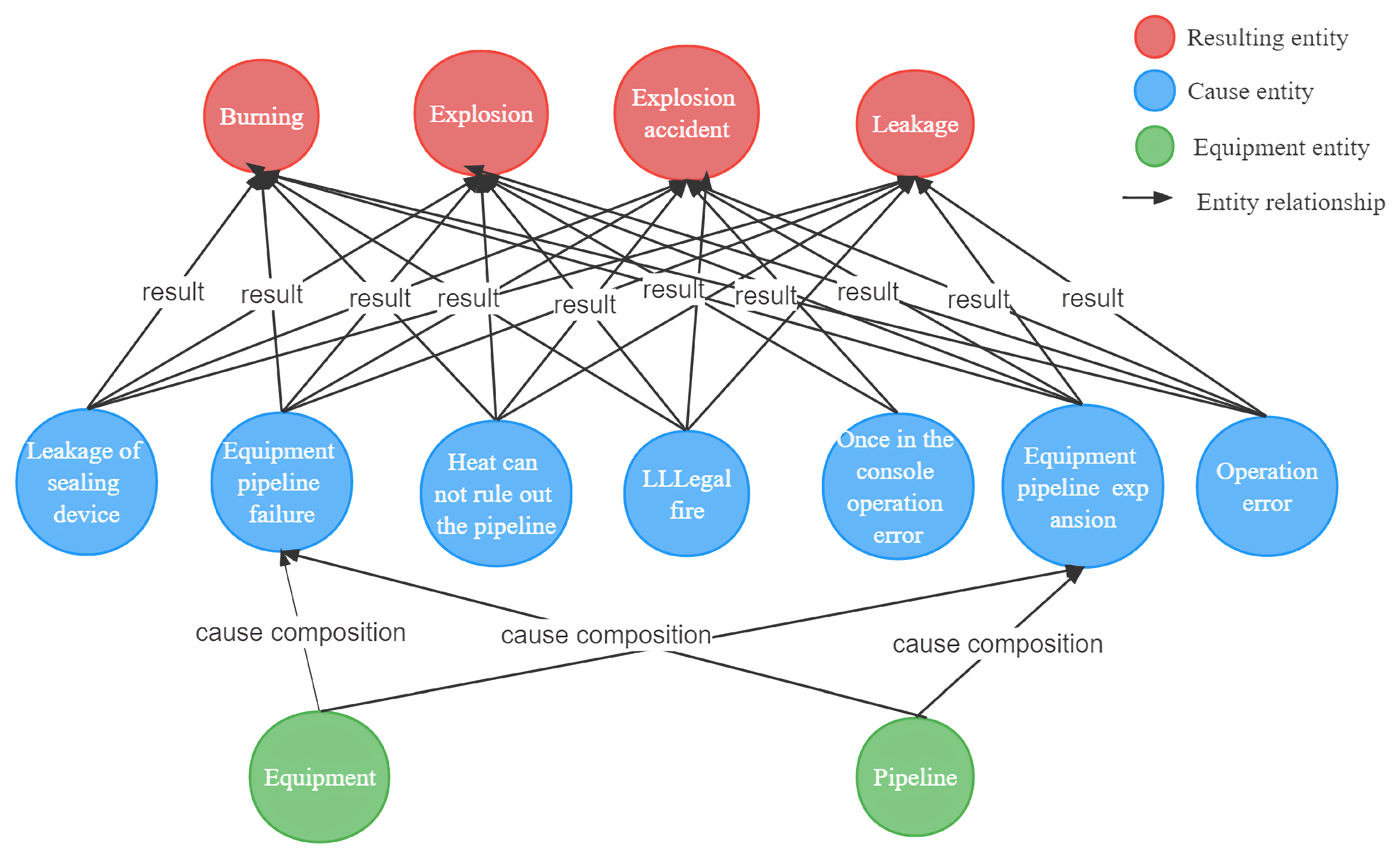
We import the industrial safety knowledge-mapping triad into the Neo4j graph database (Miller, 2013; Zhe Huang et al., 2020; W. Huang et al., 2020; Kim et al., 2021) to complete the non-normative industrial safety knowledge mapping. It is worth noting that the results recorded in the industrial safety reports are standardized and accurate with multiple analyses by expert groups, and even though the words are very close to each other literally, each word still has a unique meaning, such as “process pipeline” and “pipeline”. In addition, due to the complexity of the process, some entities and relationships are redundant. Therefore, to address the above issues, we adopt a set of regular entity linking rules as follows:
(1) Multiple logical words of the same kind of entities are linked as one entity, and each iteration is merged into the entity library. For example, if “gas main pipe of the gas cabinet”, “gas cabinet”, and “gas main pipe” are all asset entities, at this time, due to the logical word “of”, you can consider “gas master of the gas cabinet” as the same asset entity. Similar logical words are “on, attributed to, attached to, attributed to, in… on, contains… in”;
(2) The larger the length of the entity, the higher the priority of the association. The larger the length of an entity that has been linked to the entity library, the clearer the meaning of the entity and the more representative of a key entity, such as “ammonia production key equipment nitrogen and hydrogen compressor”, which is more representative of “ammonia production key equipment” than “ammonia production key equipment”. For example, “ammonia production critical equipment nitrogen and hydrogen compressor” is a class of entities compared to “ammonia production critical equipment”. Therefore, when linking entities, it is preferred to associate entities with greater length to the entity library;
(3) If there is only one key entity in a sentence, the key entity is linked to the entity library first;
(4) When there are multiple concurrent entities in a sentence, the entities should be split and linked to the corresponding entities. For example, “Carbon is a kind of flammable material, which is prone to spontaneous combustion under the conditions of high temperature and superheat accidental mechanical impact, airflow impact, electrical short circuit, external fire and static spark”, where “airflow impact”, “high temperature and superheat”, “accidental mechanical impact”, and other causes may lead to the result of “carbon spontaneous combustion”, so it should be split into multiple cause entities, respectively associated to the “carbon spontaneous combustion". Therefore, it should be split into multiple cause entities and linked to the resulting entity of “carbon self-ignition”;
(5) For an entity extracted from INERM, if its degree of repetition with the entity in the entity library is greater than , it is considered to belong to the corresponding entity in the entity library. In this paper, all kinds of industrial safety entities are composed of asset entities and descriptive language. If the asset entities are the same and the repetition of descriptive language is 80%, they are considered to be the same entity.
It should be noted that this entity linking rule is also used in the extraction layer (CRF).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}