1. Introduction
The petrochemical industry is the embodiment of comprehensive national strength and plays an important role in social development. The process of crude distillation is the link with the highest energy consumption in chemical plants and is the core and leading unit of the oil refining industry. This process is the first stage of crude oil processing to provide raw materials for the subsequent secondary processing. At present, the crude oil distillation process is more efficient and productive but still has the problem of high energy consumption. Based on the proposed national energy-saving policy and the economic costs associated with high energy consumption, the question of how to reduce energy consumption while maintaining production has become a top priority for factories. However, energy consumption cannot be predicted and analyzed over real time, resulting in operators being unable to monitor the change trend in energy efficiency timely.
The energy consumption of crude distillation is affected by numerous factors, such as the nature of crude oil, plant load, equipment operation, and production cycle. The reduction of energy consumption can improve the economic benefit of enterprises and make rational use of petroleum resources. Common energy saving and consumption reduction are carried out on the basis of existing equipment conditions. By changing some control parameters, such as feed temperature, feed flow rate, tower bottom temperature, and reflux ratio, the process operation conditions can be optimized to reduce energy consumption. Optimizing the energy integration of the crude distillation system and heat exchanger system can reduce energy consumption [
1], the optimization of operating conditions can improve economic benefits [
2], and a genetic algorithm is used to improve the production to achieve the balance between profit and energy consumption by multi-objective optimization problems [
3]. Yang et al. [
4] proposed an optimal operation strategy to improve the energy efficiency of a crude oil distillation unit without any structural transformation. The detailed process operation was expressed as a complex nonlinear programming model and then solved with the double-loop algorithm. It can help engineers easily adjust the key parameters of the process. Yao et al. [
5] optimized the operational variables of the simulated atmospheric distillation column by designing experimental techniques and support vector regression models. Li et al. [
6] introduced a knowledge-based operational optimization strategy to mitigate uncertainties in the properties of the materials. It combines neural network and fuzzy logic technology to provide instructions to adapt to different material properties. Ochoa Estopier et al. [
7] proposed a framework for thermally integrated crude oil distillation systems and developed an artificial neural network model and a heat exchanger network modification model. The above methods cannot achieve the prediction of energy efficiency and need to establish a complex mechanism model. Deep learning is a novel prediction method that can accurately predict energy efficiency.
With the advent of the era of big data, deep learning and artificial neural networks have been increasingly used in the chemical industry with their self-learning, self-adaptive, and self-organizing characteristics. It has improved the identification and diagnosis ability of abnormal energy consumption of chemical enterprises with a new solution for the energy saving of chemical companies [
8]. Accurate prediction of energy consumption of crude distillation is the basis of energy management and control and can be used by managers to optimize decisions [
9,
10]. Energy-efficiency prediction models can promote the efficient use of energy and low consumption of raw materials. Convolutional neural networks (CNNs) are the most effective deep learning networks for modeling complex processes. Qi et al. [
11] proposed a multi-operation mode-adaptive time-window convolutional neural network (MOM-ATWCNN) for energy consumption prediction, which shows its superiority in various performance indicators. The improvement of the algorithm is beneficial to reducing energy consumption and achieving economic goals. Navid Fekri et al. [
12] proposed an online adaptive recurrent neural networks (RNNs) model for power load prediction. By emphasizing newly arrived data and adaptive load changes, the prediction accuracy is improved and superior to several other models. Zhang et al. [
13] proved the effectiveness of CNNs in the power generation prediction. Although the key features are affected by multiple factors, the method can express these features more accurately and completely.
The data of the crude distillation process are characterized by multi-dimension and uncertainty. Energy consumption prediction for crude distillation is helpful in solving the problem of energy consumption target setting and scheduling optimization. The predicted results and optimized values are of great significance for reducing energy consumption, guiding crude oil production, and improving energy efficiency [
14]. RNNs have problems such as gradient disappearance or gradient explosion and can only learn short-term influence relationships. The long short-term memory network (LSTM), as a variant of the cyclic neural network, can effectively solve the above problems. In addition, much time-domain correlation data exist in the field of the chemical industry, so LSTM has great advantages for prediction. Han et al. [
15] proposed a fault diagnosis method for chemical processes based on optimized LSTM to determine the optimal number of hidden layer nodes under different fault conditions and improve the accuracy of fault diagnosis. Xu et al. [
16] proposed a prediction method for pipeline leakage of heat exchangers based on generative adversarial networks (GANs) and LSTM. The data enhancement method of GAN is used to solve the problem of data imbalance, a classifier based on LSTM is used to solve the problem of time dependence of process data, and the pipeline state is classified to predict leakage. Han et al. [
17] proposed an attentional mechanism-based production capacity analysis and energy-saving model of LSTM, established a production prediction model with LSTM, and applied the model to predict the production capacity, providing theoretical guidance for improving production capacity. Zhu et al. [
18] used LSTM to predict the operating profit of the natural gas–liquid recovery device so as to optimize the operating conditions of the process and improve the profit rate of the device.
In this paper, an energy-efficiency prediction method that combines mechanistic modeling and artificial intelligence is proposed. There is a close relationship between the energy efficiency of the crude distillation and the process parameters, and the real-time changes in parameters affect the energy-efficiency level of the product. By adding disturbance, the data of four typical operating conditions of the crude distillation units are simulated, and the distance-coded heat map is introduced to realize the visualization of the differences in operating conditions. The Savitzky–Golay filter is used to smooth the data and establish the sample set. The trained LSTM model is used to predict the energy efficiency of atmospheric two-line products and vacuum two-line products. The predicted energy-efficiency value can serve as a guide in the production process. Based on the input operating parameters, the LSTM model outputs predicted energy-efficiency values that can guide operators in making decisions to optimize operating parameters, energy-efficiency diagnostics, and applying optimal production strategies to improve energy-efficiency.
The rest of this paper is organized as follows. The second section introduces the proposed method and its theoretical basis. The third section introduces the process simulation of crude distillation. The fourth part predicts and analyzes the energy efficiency of the crude distillation. The last part summarizes the work of this paper.
2. Methodology and Theoretical Basis
2.1. Proposed Method
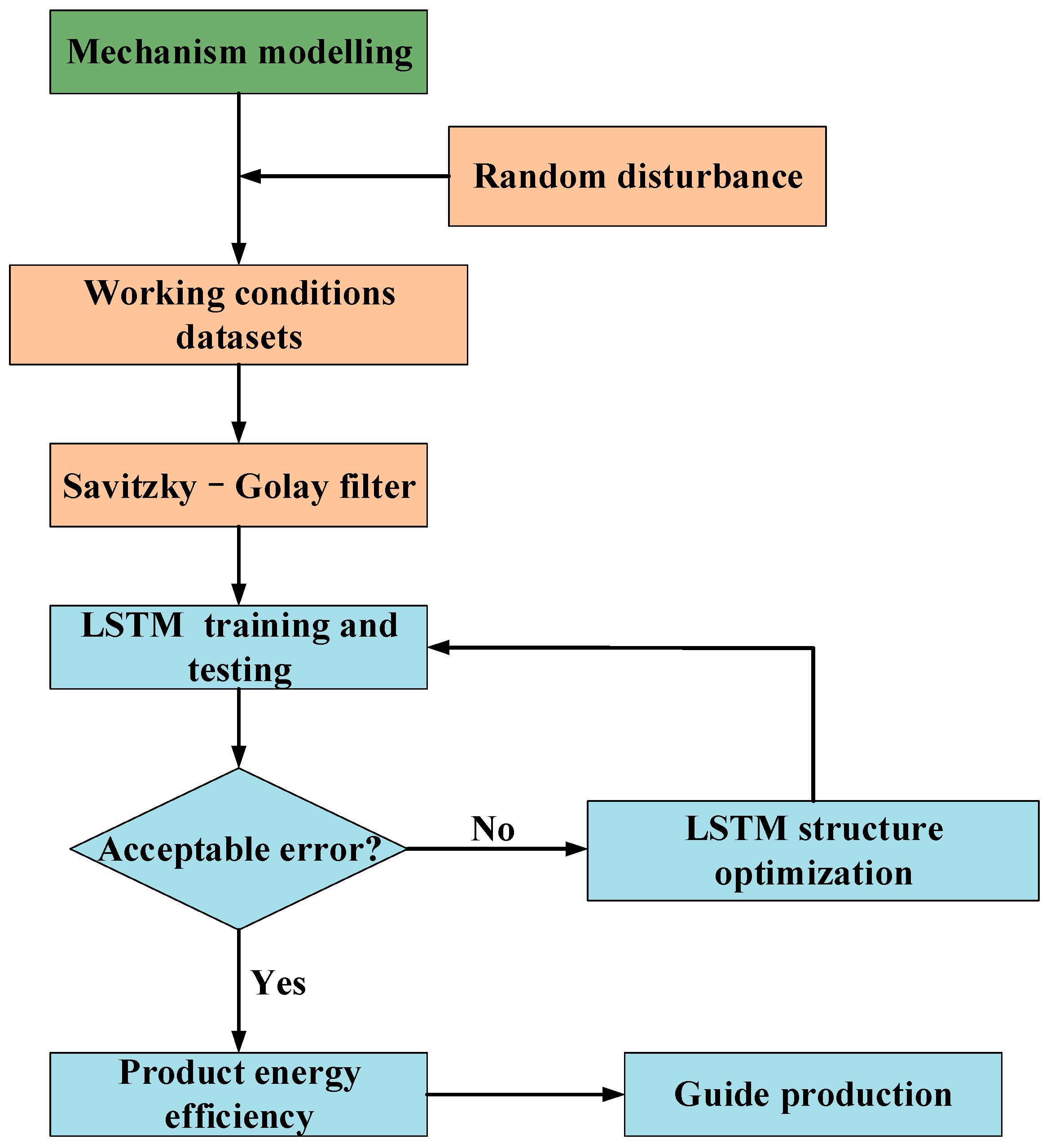
As shown in
Figure 1, the method consists of three parts: (1) construction of mechanism model of crude distillation process; (2) process data processing; and (3) energy-efficiency prediction based on LSTM.
In the part of mechanism modeling, based on the software characteristics of Aspen HysysV10, the steady-state model is first established to obtain the dynamic model. The ideal value obtained by steady-state simulation is used as a reference to evaluate the dynamic fluctuation degree of parameters.
In the data processing part, real-time changes in parameters affect the energy efficiency of the product. By adding random disturbance to the operating parameters, the data sets under four operating conditions are obtained, and the differences between operating conditions are demonstrated by using distance-coded heat maps. Savitzky–Golay filtering (SG) is used to reduce the noise of data and improve the prediction effect while preserving the original characteristics of data.
In the part of energy-efficiency prediction, the data after noise reduction are divided into a train set and a test set in a ratio of 8:2. The training set is used to train the model, and the test set is used to predict the energy efficiency. Under different working conditions, the LSTM model can predict accurately.
2.2. Process Simulation
Aspen Hysys has comprehensive thermodynamic data libraries for energy optimization and cost estimation. Compared with Aspen Plus and Aspen Dynamics, it allows for the conversion between steady-state and dynamic simulations in the program instead of switching between different programs [
19,
20]. By using Aspen Hysys to build the mechanism model, accurate simulation results can be obtained, and engineering efficiency can be improved [
21]. Therefore, the mechanism model used in this study is obtained through Aspen Hysys, and simulation results are then obtained to analyze and improve energy efficiency.
The steady-state model is built by using the loading data of the chemical process. The simulation results of the steady-state simulation are consistent with the actual production state. However, the actual chemical process is in an unstable state, and the problems in the process can not be solved by the steady-state simulation method. After building a reasonable steady-state model, dynamic import is carried out. The real operating state of the device is simulated, and the real-time data of the operating parameters are collected.
2.3. LSTM Model
Energy-efficiency prediction and analysis work is based on in-depth analysis of historical data, which are collected and analyzed. Artificial intelligence algorithm is used to learn the rules and internal information of the data. Compared with traditional data processing algorithm methods, the LSTM model has a better prediction effect on the time-series data. As a result, the prediction results with high accuracy will help people to make efficient decisions in time.
Recurrent neural networks (RNNs) are self-connected neural networks in the field of deep learning. Using neurons with self-feedback functions, it can process time sequence data of any length. RNNs with multiple hidden layers are composed of an input unit, output unit, and hidden unit, as shown in
Figure 2. x
t is the input at time t, and the input set is marked as {x
0,x
1,…,x
t,x
t+1,…}; o
t is the output at time t, and the output set is labeled {y
0,y
1,…,y
t,y
t+1,…}; S
t is the hidden state at time t, and the hidden unit is marked as {S
0,S
1,…,S
t,S
t+1,…}. The above can be expressed as:
where f is a nonlinear activation function, such as tanh, sigmoid, and ReLU.
RNNs can achieve short-term memory of time-series data. When the output information is close to node information, the model can make suitable use of historical information. However, it is difficult for the RNN model to make full use of the effective information for the long-time node case. In addition, RNNs have problems such as gradient vanishing or gradient explosion, which makes it impossible to learn the long-term influence relationship [
22]. LSTM, as one of the most successful variants of recurrent neural networks, can effectively solve the problem of continuous data input without preservation [
17]. The cell structure is shown in
Figure 3.
Compared to RNNs, LSTM has a forgetting gate, input gate, and output gate. The input gate controls the amount of information flowing into the storage unit; the forgetting gate controls the proportion of information accumulated in the unit from the previous moment to the current moment; and the output gate controls the proportion of hidden state information [
23]. LSTM has the advantage of adding a forgetting mechanism as follows. When there are new input samples, the model will judge which historical information needs to be deleted. When the model inputs new samples, it will automatically determine whether to use and save the features and control the transfer state by the gating mechanism to maintain a certain gradient, then show suitable performance. The calculation formulas are as follows.
where i
f(t)(vτ) is the input gate of the LSTM unit, g
f(t)(vτ) is the forgetting gate of the LSTM unit, o
f(t)(vτ) is the output gate of the LSTM unit, and σ is the activation function.
2.4. Savitzky–Golay Filter
Savitzky and Golay proposed the Savitzky–Golay filter in 1964, which is a filter method that can be fitted in the time domain based on the local polynomial least square method [
24]. This method can remove noise while keeping the width and shape of the signal unchanged. When the SG filter reduces noise at a point, it needs to fit and calculate the surrounding points so there are not enough data points when processing the first and last data. In order to overcome the phenomenon of suppressing high frequency and artifacts, we remove the front-end and back-end data points and keep the data that have enough data points to fit.
The variables of crude distillation have the characteristics of high coupling and nonlinearity, which are easily affected by operating parameters and the external environment. When random disturbance is added, there will be noise in the collected data center. Noise will affect the prediction accuracy of the LSTM model, so data noise reduction is a prerequisite for the accurate prediction of energy efficiency [
25]. The SG filter can directly smooth the data from the time domain without the traditional filter between the frequency domain and time conversion, so the filter is widely used for data smoothing and denoising [
24].
2.5. Distance-Coded Heat Map
Euclidean distance [
26,
27] is an intuitive distance measurement method used to measure the absolute distance between two points in space. The formula is shown in Equation (5).
Euclidean distance can be used to determine the degree of similarity between data. The smaller the calculated value, the higher the degree of similarity between individuals. This paper introduces the method to calculate the difference of operating parameters in different working conditions. The similarity between operating parameters can be reflected according to the Euclidean distance value.
A heat map is a matrix that reflects data through color changes, which can show the correlation between different indicators and different data. Data can be visually displayed through the heat map, enhancing readability and visualization. In this paper, a distance-coded heat map is introduced to calculate the values between different working conditions by using Euclidean distance, and the differences between the data of different working conditions are reflected in the way of a heat map.
3. Process Simulation of Crude Distillation
3.1. Process Description
Crude oil is mainly composed of C, H, S, N, O, and other elements. In addition, there are trace metal elements and other non-metallic elements. In refineries, crude oil is usually cut into several fractions and evaluated using crude distillation curves. A true boiling point distillation curve (TBP) can well represent the relationship between oil temperature and composition. Under the condition of a mass reflux ratio of 5:1, a separation distillation column with a theoretical plate number of 14–18 was used to separate the light and heavy fractions. A temperature interval of 10 °C or a mass fraction of 3% is generally used as a narrow fraction to calculate the total yield or the yield per component. The real boiling point distillation curve of crude oil is shown in
Figure 4, where the vertical axis is the percentage of distillate, and the horizontal axis is the distillation temperature. This curve can reflect the true boiling point of each component in the distillate.
The crude distillation device is mainly composed of an electric desalting device, pre-flash column, heating furnace, atmospheric column, vacuum column, and so on. After the flash treatment, the flash top gas enters the atmospheric column, and the flash bottom oil enters the atmospheric tower after being heated by the atmospheric furnace. The process of vaporizing, separating, and cooling crude oil runs under atmospheric operating conditions. In order to effectively utilize the heat of the steam and regulate the gas phase load in the tower, three steam lift towers and three mid-pumparound refluxes are set up.
In atmospheric distillation, product fractions with different boiling points can be separated by controlling the temperature at the top of the tower, the extraction temperature at each sideline, the amount of stripping steam, and the flow of reflux in each middle section. Kerosene and diesel oil are obtained on the sideline, and fuel gas is obtained on the top of the tower. The residue obtained at the bottom of the tower is heated by a vacuum furnace and then enters the vacuum column.
If the heavy oil is distilled at atmospheric pressure, the colloid, asphaltene, and some unstable groups in the heavy oil will trigger cracking and a condensation reaction, resulting in product quality reduction and cooking equipment. The components simulated in this study are mostly organic compounds, and the Antoine equation is usually used to calculate the relationship between the temperature and vapor pressure of organic compounds. As shown in Equation (6), the Antoine equation considers the relationship between vapor pressure and molecular weight, chemical structure, system temperature, and other factors. Compared with other complex equations, the calculation accuracy of the Antoine equation is accurate with simple steps.
where P is the vapor pressure of the component, T is the system temperature, and A, B, C is the physical property constant of the component.
In order to further treat atmospheric residual oil, it is necessary to reduce the external pressure to reduce the boiling point of the substance. The vacuum column is set up by three middle refluxes, and the bottom of the tower concentrates most of the gum, asphaltene, and a very high boiling point of the oil. The simulation diagram of the crude distillation device is shown in
Figure 5.
3.2. Crude Distillation Simulation Parameter
Aspen Hysys is used to establish the steady-state model of crude distillation. The parameters of the model are state parameters of the chemical process. MAE is introduced to reflect the fluctuation range of dynamic values to prove the representativeness and reliability of steady-state operating parameters. As a result, the dynamic behaviors of parameters fluctuate around the steady-state value, and the MAE value is less than 0.5. The parameters of the steady-state simulation are set as follows.
In the process simulation, the atmospheric column adopts a plat tower, the plate number is 50, the top temperature is 142 °C, the top pressure is 150 kPa, and the total tower pressure drop is 125 kPa. A condenser is set at the top of the tower, and its temperature is set at 71 °C. The temperature and flow parameters of lateral oil are shown in
Table 1.
In the atmospheric tower, we set up three mid-pumparounds. The circulation reflux takes heat from the high temperature and returns it to the tower from the upper part. The relevant parameters of mid-pumparounds are shown in
Table 2.
As shown in
Table 3, the feed temperature of the atmospheric column is 350 °C, the feed flow rate is 568.8 t/h, and the feed pressure is 267.3 kPa. The temperature at the top of the tower is 142 °C, and the temperature at the bottom is 357 °C. The top pressure is 150 kPa, and the tower pressure drop is 125 kPa.
The atmospheric residual oil enters the vacuum column after being heated by the heating furnace. The number of vacuum column plates is 44 layers. The temperature of the tower top is 209.8 °C, the pressure of the tower top is 4 kPa, and the pressure drop of the whole tower is 25.61 kPa. Vapor extraction steam is set at the bottom of the tower to reduce the partial pressure of oil and gas and to improve the gasification rate of the feed material. The temperature and flow parameters of lateral oil are shown in
Table 4.
In the vacuum tower, we also take the way of mid-pumparounds to take the heat, the gas–liquid load in the tower is evenly distributed, and energy is saved. The relevant parameters of mid-pumparounds are shown in
Table 5.
As shown in
Table 6, the feed temperature of the vacuum tower is 326.2 °C, the feed flow rate is 454.8 t/h, and the feed pressure is 22.52 kPa. The temperature at the top of the tower is 209.8 °C, and the temperature at the bottom is 382.1 °C. The top pressure is 4 kPa, and the tower pressure drop is 25.61 kPa.
Steady-state processes are generally temporary and relative. The actual production process is always subject to various fluctuations, disturbances, and changes in conditions. Therefore, after building a steady-state model, controllers and control loops are added to realize the dynamic simulation of the device.
3.3. Energy-Efficiency Analysis
The energy consumption of crude distillation is affected by many factors, such as the nature of crude oil, plant load, equipment operation, and production cycle. Predicting and improving operating conditions is also an important way to save energy and reduce consumption. At present, the energy saving of crude distillation is mainly focused on reducing the consumption of fuel gas, electricity, steam, and water. Fuel consumption accounts for a large proportion of the total energy consumption, mainly consumed in the heating furnace, so it is very necessary to analyze the fuel consumption of equipment. Stripping steam is needed in the process of crude distillation, and stripping steam is mainly used at the bottom of atmospheric and vacuum towers, as well as stripping towers. The cost of stripping steam is high, and the demand is great. Therefore, it is necessary to monitor the steam pressure at each site and analyze the relevant energy consumption. The main consumption of water is interrupted by circulation water and condenser water. The main power consumption equipment is the machine pump, which is responsible for the transportation and compression of materials.
It is necessary to establish a set of indexes to evaluate the energy efficiency according to the energy consumption characteristics of crude distillation in order to guide enterprises to improve energy-saving schemes and improve the level of energy efficiency. Energy consumption is the sum of fuel energy consumption, steam energy consumption, cooling water energy consumption, and electricity energy consumption. Energy efficiency is a comprehensive index that combines production input and output [
28]. Its definition is as follows:
where product output is the production of crude distillation, and the unit is kg/h. Energy consumption is the sum of all the energy consumed, and the unit is kW. By definition, the higher the level of energy efficiency, the better the enterprise’s energy use and the greater the economic benefits.
The operating parameters of the process are characterized by high coupling and nonlinearity. Different operating parameters will affect the energy efficiency of the unit. The fluctuation of energy consumption and output is caused by the change in operating conditions, such as the amount of crude oil feed, temperature, and steam at the bottom of the tower during production. The single working condition is not able to reasonably evaluate the energy-efficiency level and better train the LSTM energy-efficiency prediction model. Therefore, when predicting and analyzing the energy efficiency of crude distillation, the division of working conditions is required.
5. Conclusions
An energy-efficiency prediction method based on mechanism modeling and artificial intelligence is proposed for the crude distillation process to accurately predict and evaluate energy efficiency. The study can be summarized as follows. Firstly, four working conditions of crude distillation are simulated to obtain sample sets for subsequent prediction of energy efficiency. Secondly, the distance-encoded heat map is introduced to visualize specific process parameter changes under abnormal operating conditions to demonstrate the variability in different working conditions. Thirdly, sample sets obtained from each condition are smoothed through SG filters with the aim of reducing data noise while retaining the original features. Finally, the energy-efficiency values predicted by the deep learning LSTM model are compared with real values to assess the reasonableness of the production parameters. The results show that MAE, MSE, and MAPE predicted by the LSTM model are lower than 1.3872%, 0.0307%, and 0.2555% under different working conditions.
This study shows that the LSTM model has high reliability and suitable reference in energy-efficiency prediction in guiding operators to make decisions for operating parameters optimization, energy-efficiency diagnoses, and optimal production strategies design. However, the method proposed belongs to supervised learning. How to carry out unsupervised learning in process data will be the focus of future research. Therefore, we will further study the application of unsupervised learning in energy-efficiency prediction. In addition, we will study and integrate other methods to study the early warning problem of energy efficiency and optimize the operating parameters of the device.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}