
A Study of a Domain-Adaptive LSTM-DNN-Based Method for Remaining Useful Life Prediction of Planetary Gearbox
Abstract
:1. Introduction
- A domain-based adaptive LSTM-DNN prediction algorithm is proposed, which utilizes the respective strengths of LSTM and DNN and combines transfer learning algorithms to reduce data distribution differences.
- Experiments on planetary gearboxes were built, and the proposed network model was compared with other network models to show that the prediction accuracy is better by considering the regression loss and metric loss based on the dataset and the effectiveness and superiority of the proposed domain adaptive LSTM-DNN RUL prediction method for life prediction under different operating conditions were verified using the experiments.
- The network model proposed in this paper is more accurate than the lifetime prediction method using a single LSTM, as evaluated with Root Mean Square Error (RMSE) and Mean Absolute Error (MAE), and the results show that the method outperforms its single algorithm model.
2. Theoretical Analysis
2.1. Definition of the Problem
2.2. LSTM Neural Networks
2.3. LSTM-DNN Prediction Model
2.4. Domain Adaptive
- (1)
- Maximum Mean Difference (MMD)
- (2)
- Training optimization
- (3)
- Assessment indicators
3. Experiments
4. RUL Forecast
4.1. Feature Extraction and Analysis
4.2. Forecasting Models
4.3. Comparison with Related Transfer Learning Models
4.4. Comparison with LSTM Model
5. Conclusions
- Compared with traditional transfer learning models, the method not only accurately predicts the remaining lifespan but also has better feature extraction capability and enhanced adaptivity of data distribution compared to other adaptive methods.
- The model proposed in this paper can effectively extract degradation features from condition monitoring data under various operating conditions. Through domain adaption, the generalization capability of the data-driven RUL prediction model can be effectively improved, and to a certain extent, it can adapt to the RUL prediction tasks under different operating conditions, making up for the limitations of the traditional data-driven model.
- The model has made predictions under different working conditions and obtained better prediction results, which facilitate engineers to make effective maintenance plans in advance and shorten maintenance intervals, which can further save maintenance costs, thus realizing planetary gearbox life prediction and health management.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, Z.; Bai, H.; Yan, H.; Zhan, X.; Guo, C.; Jia, X. Intelligent Fault Diagnosis Method for Gearboxes Based on Deep Transfer Learning. Processes 2023, 11, 68. [Google Scholar] [CrossRef]
- Lu, Y.-W.; Hsu, C.-Y.; Huang, K.-C. An Autoencoder Gated Recurrent Unit for Remaining Useful Life Prediction. Processes 2020, 8, 1155. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, D.; Zhang, W.A. MSWR-LRCN: A new deep learning approach to remaining useful life estimation of bearings. Control Eng. Pract. 2022, 118, 104969. [Google Scholar] [CrossRef]
- Fu, J.; Chu, J.C.; Guo, P.; Chen, Z. Condition Monitoring of Wind Turbine Gearbox Bearing Based on Deep Learning Model. IEEE Access 2019, 7, 57078–57087. [Google Scholar] [CrossRef]
- He, K.; Su, Z.; Tian, X.; Yu, H.; Luo, M. RUL prediction of wind turbine gearbox bearings based on self-calibration temporal convolutional network. IEEE Trans. Instrum. Meas. 2022, 71, 3501912. [Google Scholar] [CrossRef]
- Mao, W.; He, J.; Zuo, M.J. Predicting remaining useful life of rolling bearings based on deep feature representation and transfer learning. IEEE Trans. Instrum. Meas. 2019, 69, 1594–1608. [Google Scholar] [CrossRef]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 2010, 22, 199–210. [Google Scholar] [CrossRef] [Green Version]
- Dorri, F.; Ghodsi, A. Adapting Component Analysis. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining, Brussels, Belgium, 10–13 December 2012; pp. 846–851. [Google Scholar]
- Duan, L.; Tsang, I.W.; Xu, D. Domain transfer multiple kernel learning. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 465–479. [Google Scholar] [CrossRef]
- Hsiao, P.H.; Chang, F.J.; Lin, Y.Y. Learning discriminatively reconstructed source data for object recognition with few examples. IEEE Trans. Image Process. 2016, 25, 3518–3532. [Google Scholar] [CrossRef]
- Long, M.; Wang, J.; Ding, G.; Sun, J.; Yu, P.S. Transfer feature learning with joint distribution adaptation. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 2200–2207. [Google Scholar]
- Wang, J.; Chen, Y.; Feng, W.; Yu, H.; Huang, M.; Yang, Q. Transfer learning with dynamic distribution adaptation. ACM Trans. Intell. Syst. Technol. (TIST) 2020, 11, 1–25. [Google Scholar] [CrossRef] [Green Version]
- Ding, Y.; Ding, P.; Zhao, X.; Cao, Y.; Jia, M. Transfer learning for remaining useful life prediction across operating conditions based on multisource domain adaptation. IEEE/ASME Trans. Mechatron. 2022, 27, 4143–4152. [Google Scholar] [CrossRef]
- Cheng, H.; Kong, X.; Wang, Q.; Ma, H.; Yang, S.; Chen, G. Deep transfer learning based on dynamic domain adaptation for remaining useful life prediction under different working conditions. J. Intell. Manuf. 2023, 34, 587–613. [Google Scholar] [CrossRef]
- Mao, W.; Liu, J.; Chen, J.; Liang, X. An interpretable deep transfer learning-based remaining useful life prediction approach for bearings with selective degradation knowledge fusion. IEEE Trans. Instrum. Meas. 2022, 71, 3508616. [Google Scholar] [CrossRef]
- Xie, B.; Duan, Z.; Zheng, B.; Liu, L. Research on target object recognition based on transfer-learning convolutional SAE in intelligent urban construction. IEEE Access 2019, 7, 125357–125368. [Google Scholar] [CrossRef]
- Li, C.; Zhang, S.; Qin, Y.; Estupinan, E. A systematic review of deep transfer learning for machinery fault diagnosis. Neurocomputing 2020, 407, 121–135. [Google Scholar] [CrossRef]
- Han, T.; Zhou, T.; Xiang, Y.; Jiang, D. Cross-machine intelligent fault diagnosis of gearbox based on deep learning and parameter transfer. Struct. Control Health Monit. 2021, 29, e2898. [Google Scholar] [CrossRef]
- Wang, F.; Gomez, W.; Amogne, Z.E.; Rahardjo, B. Transfer learning based deep learning model and control chart for bearing useful life prediction. Qual. Reliab. Eng. Int. 2023, 39, 837–852. [Google Scholar] [CrossRef]
- Wang, L.; Liu, H.; Pan, Z.; Fan, D.; Zhou, C.; Wang, Z. Long Short-Term Memory Neural Network with Transfer Learning and Ensemble Learning for Remaining Useful Life Prediction. Sensors 2022, 22, 5744. [Google Scholar] [CrossRef]
- Yan, H.; Bai, H.; Zhan, X.; Wu, Z.; Wen, L.; Jia, X. Combination of VMD Mapping MFCC and LSTM: A New Acoustic Fault Diagnosis Method of Diesel Engine. Sensors 2022, 22, 8325. [Google Scholar] [CrossRef] [PubMed]
- Borgwardt, K.M.; Gretton, A.; Rasch, M.J.; Kriegel, H.P.; Schölkopf, B.; Smola, A.J. Integrating structured biological data by Kernel Maximum Mean Discrepancy. Bioinformatics 2006, 22, e49–e57. [Google Scholar] [CrossRef] [Green Version]
- Gretton, A.; Borgwardt, K.; Rasch, M.; Schölkopf, B.; Smola, A. A Kernel method for the two-sample problem. arXiv 2008, arXiv:0805.2368. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Working Condition | Speed | Load |
|---|---|---|
| A | 1000 rpm | 1.0 A |
| B | 1000 rpm | 1.4 A |
| C | 1000 rpm | 1.2 A |
| D | 1000 rpm | 0.8 A |
| Characteristic Parameters | |
|---|---|
| Time domain characteristic parameters | Mean Square Value, RMS, Average amplitude, Square root amplitude, Variance, Standard Variance, Waveform Index, Residual clearance factor |
| Frequency domain characteristic parameters | FC, RMSF, STDF |
| Layer Name | Details | |
|---|---|---|
| Feature extractor | LSTM layer | Units = 96 × 3,dropout = 0.8 |
| Regression | Fully connected layer(FFC1) | Layer_size = 128 |
| Fully connected layer(FFC2) | Layer_size = 64 | |
| Fully connected layer(FFC3) | Layer_size = 32 | |
| Fully connected layer(RFC1) | Layer_size = 1 | |
| Output layer(ROL) | Layer_size = 1 |
| Source Domain | Target Domain | BDA-LSTM-DNN | TCA-LSTM-DNN | JDA-LSTM-DNN | JGSA-LSTM-DNN | Proposed Model | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | ||
| A | B | 0.205 | 0.276 | 0.176 | 0.272 | 0.225 | 0.298 | 0.199 | 0.282 | 0.066 | 0.162 |
| A | C | 0.200 | 0.272 | 0.249 | 0.333 | 0.168 | 0.245 | 0.222 | 0.306 | 0.070 | 0.162 |
| A | D | 0.141 | 0.203 | 0.262 | 0.347 | 0.194 | 0.279 | 0.138 | 0.241 | 0.058 | 0.145 |
| B | A | 0.280 | 0.345 | 0.137 | 0.184 | 0.259 | 0.336 | 0.181 | 0.228 | 0.072 | 0.166 |
| B | C | 0.104 | 0.180 | 0.132 | 0.243 | 0.124 | 0.201 | 0.116 | 0.193 | 0.070 | 0.155 |
| B | D | 0.316 | 0.348 | 0.269 | 0.332 | 0.452 | 0.560 | 0.184 | 0.233 | 0.062 | 0.118 |
| C | A | 0.335 | 0.397 | 0.178 | 0.274 | 0.238 | 0.332 | 0.237 | 0.300 | 0.038 | 0.087 |
| C | B | 0.136 | 0.248 | 0.093 | 0.196 | 0.191 | 0.257 | 0.129 | 0.211 | 0.050 | 0.118 |
| C | D | 0.332 | 0.397 | 0.270 | 0.345 | 0.512 | 0.626 | 0.323 | 0.367 | 0.083 | 0.170 |
| D | A | 0.197 | 0.303 | 0.214 | 0.329 | 0.151 | 0.275 | 0.165 | 0.302 | 0.097 | 0.145 |
| D | B | 0.317 | 0.368 | 0.158 | 0.239 | 0.340 | 0.415 | 0.226 | 0.298 | 0.090 | 0.185 |
| D | C | 0.210 | 0.288 | 0.270 | 0.324 | 0.223 | 0.275 | 0.226 | 0.314 | 0.071 | 0.119 |
| Total | 0.231 | 0.302 | 0.201 | 0.285 | 0.256 | 0.342 | 0.196 | 0.273 | 0.069 | 0.144 | |
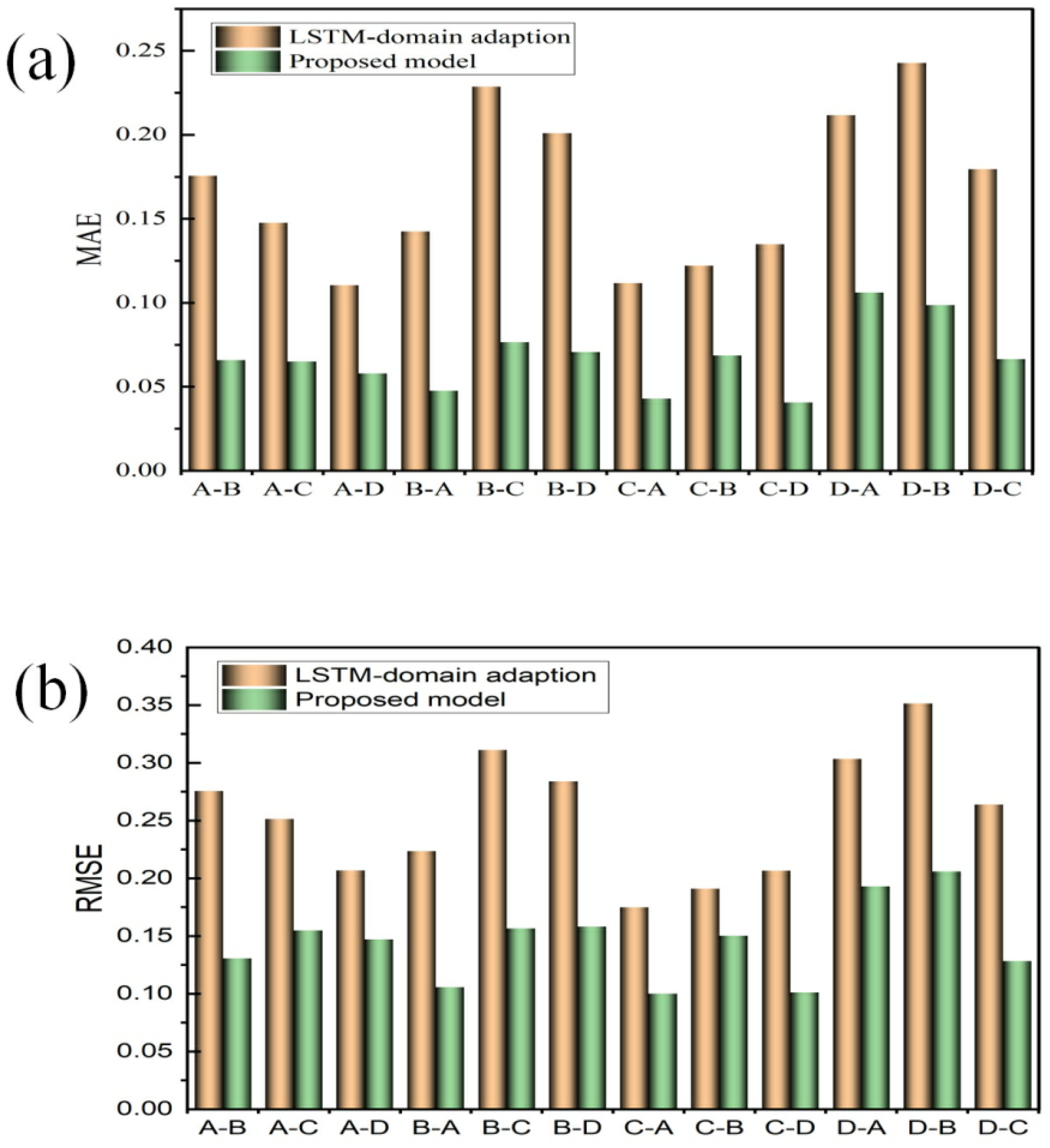
| Source Domain | Target Domain | LSTM | Proposed Model | ||
|---|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | ||
| A | B | 0.175 | 0.275 | 0.065 | 0.130 |
| A | C | 0.147 | 0.251 | 0.065 | 0.154 |
| A | D | 0.110 | 0.206 | 0.057 | 0.147 |
| B | A | 0.142 | 0.223 | 0.047 | 0.105 |
| B | C | 0.228 | 0.311 | 0.076 | 0.156 |
| B | D | 0.201 | 0.284 | 0.070 | 0.158 |
| C | A | 0.111 | 0.174 | 0.042 | 0.100 |
| C | B | 0.122 | 0.191 | 0.068 | 0.150 |
| C | D | 0.134 | 0.206 | 0.040 | 0.101 |
| D | A | 0.211 | 0.303 | 0.106 | 0.193 |
| D | B | 0.242 | 0.351 | 0.098 | 0.206 |
| D | C | 0.179 | 0.263 | 0.066 | 0.128 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Tan, C.; Liu, Y.; Li, H.; Cui, B.; Zhang, X. A Study of a Domain-Adaptive LSTM-DNN-Based Method for Remaining Useful Life Prediction of Planetary Gearbox. Processes 2023, 11, 2002. https://doi.org/10.3390/pr11072002
Liu Z, Tan C, Liu Y, Li H, Cui B, Zhang X. A Study of a Domain-Adaptive LSTM-DNN-Based Method for Remaining Useful Life Prediction of Planetary Gearbox. Processes. 2023; 11(7):2002. https://doi.org/10.3390/pr11072002
Chicago/Turabian StyleLiu, Zixuan, Chaobin Tan, Yuxin Liu, Hao Li, Beining Cui, and Xuanzhe Zhang. 2023. "A Study of a Domain-Adaptive LSTM-DNN-Based Method for Remaining Useful Life Prediction of Planetary Gearbox" Processes 11, no. 7: 2002. https://doi.org/10.3390/pr11072002