
A Gas Prominence Prediction Model Based on Entropy-Weighted Gray Correlation and MCMC-ISSA-SVM
Abstract
:1. Introduction
2. Data Collection and MCMC Fills in the Missing Data
3. Entropy-Weighted Gray Correlation Analysis
- (1)
- There are n evaluation objects and m evaluation indicators, and the evaluation matrix is R′.
- (2)
- Determining the reference series.
- (3)
- The dimensionless processing of the filled data gives the following matrix.
- (4)
- Calculate the absolute difference between the elements corresponding to the comparison sequence and the reference sequence.
- (5)
- Determining the maximum and minimum difference.
- (6)
- To determine the degree of association between the comparison series and the reference series, the gray correlation coefficient is calculated. ρ is the resolution factor and takes values in the range [0, 1].
- (7)
- Pij is the weight of the characteristics of the jth evaluation object under the ith evaluation indicator, called the contribution degree.
- (8)
- ej is the total contribution of the jth indicator, called the entropy value.
- (9)
- is the entropy weight of the jth indicator; calculate the entropy weight.
- (10)
- Calculating the entropy-weighted gray correlation. The entropy-weighted gray correlation was calculated, and the results are shown in Table 2.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicators | X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | X9 |
|---|---|---|---|---|---|---|---|---|---|
| ri | 0.010 | 0.016 | 0.009 | 0.017 | 0.015 | 0.013 | 0.011 | 0.011 | 0.012 |
| sort | 8 | 2 | 9 | 1 | 3 | 4 | 6 | 7 | 5 |
4. Building MCMC-ISSA-SVM Prediction Model
4.1. Sparrow Search Algorithm
4.2. Improved Sparrow Search Algorithm
5. Coal and Gas Prominence Prediction
5.1. Conduct Group Experiments to Select the Best Parameter Indicators
5.2. Prediction of Coal and Gas Prominence by MCMC-ISSA-SVM Model
6. Results
- (1)
- The MCMC filling algorithm was used to fill the missing values and compared with the mean, RF, and KNN filling results. The mean value of MCMC-filled data is 2.28 and the standard deviation is 0.19, which is closer to the mean and standard deviation of the original dataset than the mean and standard deviation of other models, indicating that MCMC-filled data is the best. The results indicate that the MCMC algorithm performs well in filling missing values and can optimize the dataset effectively.
- (2)
- The parameter indicators of the prominence data were ranked by entropy-weighted gray correlation analysis and divided into four experimental groups with different numbers of parameter indicators according to the entropy-weighted gray correlation, which were input into the MCMC-SVM model for prominence prediction experiments. The last group of experimental coal and gas prominence predictions has the best effect. The results show that the entropy-weighted gray correlation analysis can effectively filter the prediction parameters, reduce the interference of other parameters, and improve the prediction accuracy.
- (3)
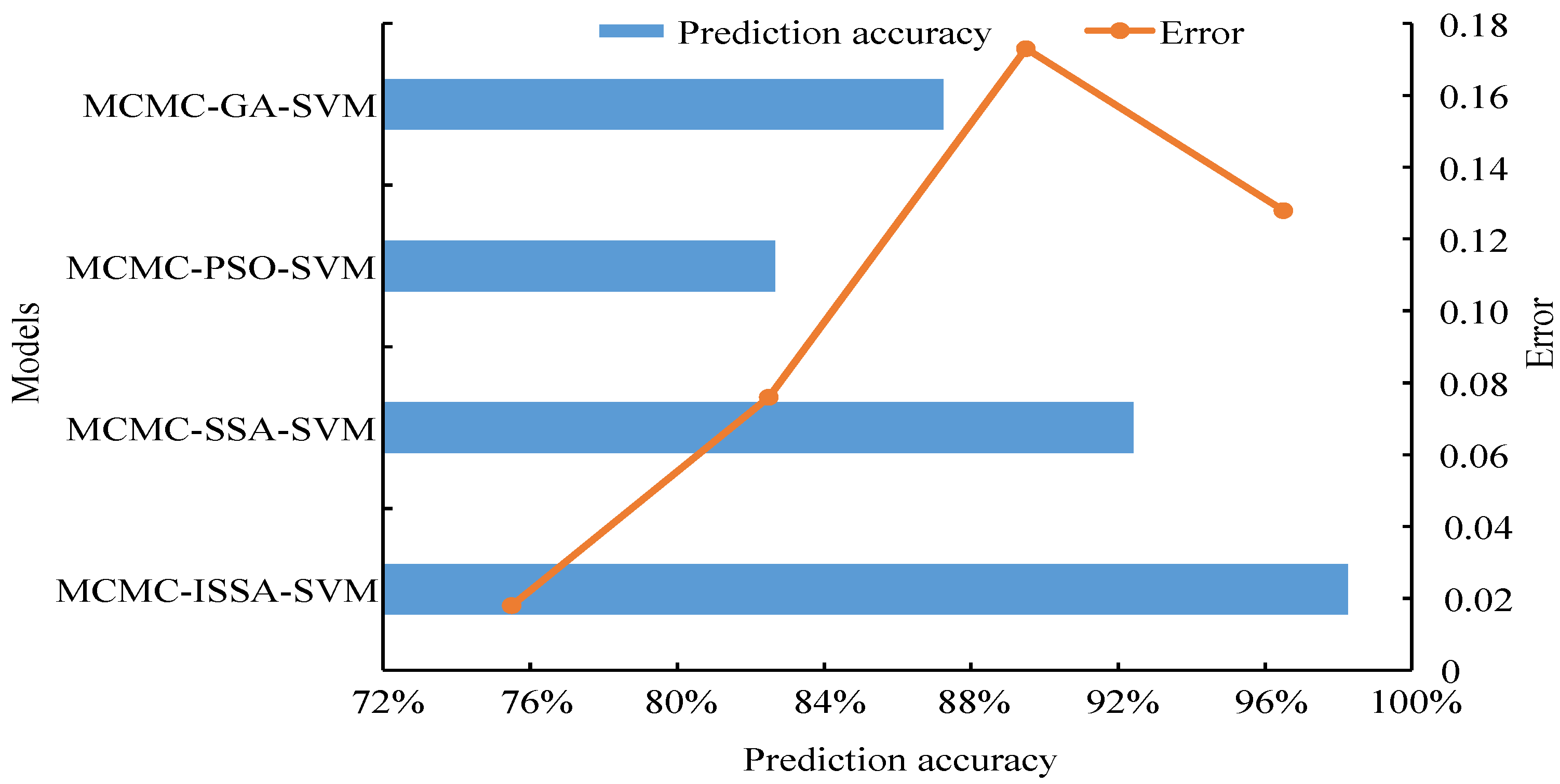
- An improved sparrow search algorithm is proposed to enhance sparrow population diversity by adding an adaptive t-distribution variation operator and improving the update position of vigilantes. The MCMC-ISSA-SVM model is established and compared with the MCMC-SSA-SVM model for experiments, and it is found that the improved prediction accuracy is improved by 5.84%, the error is reduced by 0.060, the number of iterations is reduced by 5, and the best and average fitness are increased by about 5%. The results show that the improvement of the algorithm is effective.
- (4)
- The prediction accuracy of MCMC-ISSA-SVM is 98.25% with an error of 0.018, which is significantly better than the other three models. In addition, its convergence speed is the fastest, the number of iterations is the least, and the best fitness and average fitness are the highest among the four models. The results verified that ISSA outperformed SSA, PSO, and GA in terms of optimization seeking, and the proposed MCMC-ISSA-SVM model could indeed significantly improve the prediction accuracy and effectively enhance the generalization ability.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| Symbols | Explanation |
| MCMC | Markov chain Monte Carlo |
| SSA | sparrow search algorithm |
| ISSA | improved sparrow search algorithm |
| SVM | support vector machine |
| GA | genetic algorithm |
| PSO | particle swarm optimization |
| MCMC-ISSA-SVM | improved sparrow search algorithm optimized support vector machine based on Markov chain Monte Carlo filling algorithm |
| MCMC-SSA-SVM | sparrow search algorithm optimized support vector machine based on Markov chain Monte Carlo filling algorithm |
| MCMC-GA-SVM | genetic algorithm optimized support vector machine based on Markov chain Monte Carlo filling algorithm |
| MCMC-PSO-SVM | particle swarm optimization algorithm optimized support vector machine based on Markov chain Monte Carlo filling algorithm |
| RF | random forest |
| KNN | K-nearest neighbor |
| RE | relative error |
| REmax | maximum relative error |
| MRE | average relative error |
| RMSE | root mean square error |
| R2 | coefficient of determination |
| GASA | genetic simulated annealing algorithm |
| BP | back propagation |
| ρ | resolution factor |
| Pij | the weight of the characteristics of the jth evaluation object under the ith evaluation indicator |
| ej | entropy value of the jth indicator |
| the entropy weight of the jth indicator | |
| ri | entropy-weighted gray correlation |
| ST | safety value |
| R2 | warning value |
| c | penalty parameters for support vector machines |
| g | kernel function parameter for support vector machine |
| λt(r) | variation operator |
| P | variation probability |
| rand | random number |
| r | the number of iterations |
| rmax | the maximum number of iterations |
References
- Lu, X.M.; Kan, S.T. Key technologies and outlook of power hazard ontogenetic warning methods in coal mines. J. Coal 2020, 45, 128–139. [Google Scholar] [CrossRef]
- Shao, L.S.; Wang, Z.; Li, C.M. A mine ventilation optimization algorithm based on simulated annealing and improved particle swarm. J. Syst. Simul. 2021, 33, 2085–2094. [Google Scholar] [CrossRef]
- Lu, Y.Y.; Peng, Z.Y.; Xia, B.W.; Yu, P.; Ou, C. Multifunctional physical simulation experimental system for deep coal rock engineering—Coal and gas protrusion simulation experiment. J. Coal 2020, 45, 272–283. [Google Scholar] [CrossRef]
- Yu, B.F. Research on the mechanism of coal and gas protrusion. Coal Sci. Technol. 1979, 8, 34–42. [Google Scholar] [CrossRef]
- Zhan, X.F. Research on Analysis and Prediction of Coal and Gas Protrusion Accidents. Master’s Thesis, Liaoning Technical University, Fuxin, China, 2020. [Google Scholar] [CrossRef]
- Wang, L.Y. Coal and Gas Prominence Class Prediction Based on Optimal Kernel Limit Learning Machine. Master’s Thesis, Liaoning Technical University, Fuxin, China, 2022. [Google Scholar] [CrossRef]
- Lin, H.F.; Zhou, J.; Jin, H.W.; Li, S.; Zhao, P.; Liu, S. Collaborative coal and gas protrusion hazard level prediction method based on feature selection and machine learning. J. Min. Saf. Eng. 2023, 40, 361–370. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, C.-L.; Li, X.-C.; Li, Z.-B.; Li, Y. Mechanism and Classification of Coal and Gas Outbursts in China. Adv. Civ. Eng. 2021, 2021, 5519853. [Google Scholar] [CrossRef]
- Dong, G.W.; Liang, X.M.; Wang, Q.X. A New Method for Predicting Coal and Gas Outbursts. Shock. Vib. 2020, 2020, 8867476. [Google Scholar] [CrossRef]
- Zhang, C.; Jiao, D.; Dong, Z.; Zhang, H. Risk assessment method of coal and gas outburst based on improved comprehensive weighting and cloud theory. Energy Explor. Exploit. 2022, 40, 777–799. [Google Scholar] [CrossRef]
- Yuan, L.; Wang, W.; Wang, H.P.; Zhang, B.; Liu, Z.; Yu, G.; Zuo, Y. Simulation test system for coal and gas protrusion induced by coal uncovering in roadway excavation. J. China Univ. Min. Technol. 2020, 49, 205–214. [Google Scholar] [CrossRef]
- Lei, Y.; Cheng, Y.; Ren, T.; Tu, Q.; Li, Y.; Shu, L. Experimental Investigation on the Mechanism of Coal and Gas Outburst: Novel Insights on the Formation and Development of Coal Spallation. Rock Mech. Rock Eng. 2021, 54, 5807–5825. [Google Scholar] [CrossRef]
- Fu, G.; Xie, X.; Jia, Q.; Tong, W.; Ge, Y. Accidents analysis and prevention of coal and gas outburst: Understanding human errors in accidents. Process Saf. Environ. Prot. 2020, 134, 1–23. [Google Scholar] [CrossRef]
- Black, D.J. Review of coal and gas outburst in Australian underground coal mines. Int. J. Min. Sci. Technol. 2019, 29, 815–824. [Google Scholar] [CrossRef]
- Song, D.Z.; He, X.Q.; Dou, L.M.; Zu, Z.; Wang, A.; Li, Z. Research on microseismic area detection technology for coal seam protrusion hazard. Chin. J. Saf. Sci. 2021, 31, 89–94. [Google Scholar] [CrossRef]
- Tang, J.P.; Hao, N.; Pan, Y.S.; Sun, S. Experimental study on the characteristics of coal and gas protrusion precursors based on acoustic emission energy analysis. J. Rock Mech. Eng. 2021, 40, 31–42. [Google Scholar] [CrossRef]
- Mou, J.; Liu, H.; Zou, Y.; Li, Q. A new method to determine the sensitivity of coal and gas outburst prediction index. Arab. J. Geosci. 2020, 13, 465. [Google Scholar] [CrossRef]
- Zhao, X.; Sun, H.; Cao, J.; Ning, X.; Liu, Y. Applications of online integrated system for coal and gas outburst prediction: A case study of Xinjing Mine in Shanxi, China. Energy Sci. Eng. 2020, 8, 1980–1996. [Google Scholar] [CrossRef]
- Zhu, B.H.; Zheng, B.Y.; Dai, Y.J.; Liu, C. Prediction of coal and gas protrusion hazard in tunnels based on nonlinear support vector machine. Mod. Tunn. Technol. 2020, 57, 20–25. [Google Scholar] [CrossRef]
- Wang, Y.H.; Sun, F.C.; Fu, H.; Xu, Y. Coal and gas prominence prediction based on optimized quantum gate node neural network. Inf. Control. 2020, 49, 249–256. [Google Scholar] [CrossRef]
- Wang, K.; Du, F. Coal-gas compound dynamic disasters in China: A review. Process Saf. Environ. Prot. 2020, 133, 1–17. [Google Scholar] [CrossRef]
- Wang, C.; Wei, L.; Hu, H.; Wang, J.; Jiang, M. Early Warning Method for Coal and Gas Outburst Prediction Based on Indexes of Deep Learning Model and Statistical Model. Front. Earth Sci. 2022, 10, 811978. [Google Scholar] [CrossRef]
- Wang, W.; Wang, H.; Zhang, B.; Wang, S.; Xing, W. Coal and gas outburst prediction model based on extension theory and its application. Process Saf. Environ. Prot. 2021, 154, 329–337. [Google Scholar] [CrossRef]
- Wu, Y.Q.; Gao, R.L.; Yang, J.Z. Prediction of coal and gas outburst: A method based on the BP neural network optimized by GASA. Process Saf. Environ. Prot. 2020, 133, 64–72. [Google Scholar] [CrossRef]
- Gong, S.H.; Pan, T.L.; Wu, D.H.; Ji, Z. Research on MCMC-based method for filling missing micro grid PV data. Renew. Energy 2018, 36, 346–350. [Google Scholar] [CrossRef]
- Xue, J.K.; Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control. Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]
- Song, J.; Cong, Q.M.; Yang, S.S.; Yang, J. Improved sparrow search algorithm for water quality prediction in RBF neural networks. Comput. Syst. 2023, 4, 255–261. [Google Scholar] [CrossRef]
- Chen, X.R.; Wu, L.F.; Yang, X.Z. Fractional-order PID parameter tuning based on improved sparrow search algorithm. Control. Decis. Mak. 2023, 1–7. [Google Scholar] [CrossRef]
- Xu, K.; Zheng, H.; Tu, Y.C.; Wu, S. Improved sparrow algorithm and Q-Learning optimized integrated learning for rail circuit fault diagnosis. J. Railw. Sci. Eng. 2023, 1–13. [Google Scholar] [CrossRef]
- He, J.; Liu, S.-M.; Chen, H.-T.; Wang, S.-L.; Guo, X.-Q.; Wan, Y.-R. Flood Control Optimization of Reservoir Group Based on Improved Sparrow Algorithm (ISSA). Water 2022, 15, 132. [Google Scholar] [CrossRef]
- Shi, H.Y.; Chen, M.X. A two-stage transformer fault diagnosis method based multi-filter interactive feature selection integrated adaptive sparrow algorithm optimized support vector machine. IET Electr. Power Appl. 2022, 17, 341–357. [Google Scholar] [CrossRef]
- Chen, G.J.; Chen, G.F. An Improved Sparrow Algorithm Based on Small Habitats in Cooperative Communication Power Allocation. Electronics 2023, 12, 1153. [Google Scholar] [CrossRef]
- Li, N.; Xue, J.K.; Shu, H.S. UAV trajectory planning based on adaptive t-distribution variational sparrow search algorithm. J. Donghua Univ. (Nat. Sci. Ed.) 2022, 48, 69–74. [Google Scholar] [CrossRef]






| X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | X9 | X10 |
|---|---|---|---|---|---|---|---|---|---|
| 3.00 | 15.50 | 0.36 | 7.78 | 0.29 | 3.20 | 351.00 | 2.40 | 36.00 | 1.00 |
| 3.00 | 15.70 | 0.36 | 7.76 | 0.19 | 3.40 | 366.00 | 2.40 | 62.00 | 1.00 |
| 2.00 | 15.75 | 0.36 | 7.81 | 0.26 | 3.20 | 366.00 | 2.40 | 78.00 | 1.00 |
| 2.00 | 15.56 | 0.36 | 7.30 | 0.34 | 3.80 | 367.00 | 2.40 | 47.00 | 1.00 |
| 3.00 | 15.80 | 0.36 | 7.05 | 0.23 | 3.13 | 364.00 | 2.40 | 21.00 | 1.00 |
| 3.00 | 15.58 | 0.36 | 7.68 | 0.23 | 3.27 | 364.00 | 2.40 | 3.00 | 1.00 |
| 3.00 | 17.40 | 0.36 | 7.98 | 0.26 | 3.33 | 365.00 | 2.40 | 35.00 | 1.00 |
| 3.00 | 17.52 | 0.36 | 8.68 | 0.26 | 3.13 | 365.00 | 2.40 | 35.00 | 1.00 |
| 3.00 | 17.43 | 0.36 | 8.77 | 0.22 | 3.07 | 368.00 | 2.10 | 11.00 | 1.00 |
| 3.00 | 15.32 | 0.36 | 8.35 | 0.25 | 3.33 | 365.00 | 2.60 | 43.00 | 1.00 |
| 3.00 | 15.56 | 0.36 | 7.92 | 0.28 | 3.40 | 363.00 | 2.60 | 37.00 | 1.00 |
| 3.00 | 15.56 | 0.36 | 7.86 | 0.21 | 3.27 | 365.00 | 2.50 | 9.00 | 1.00 |
| 3.00 | 15.42 | 0.36 | 7.84 | 0.25 | 3.53 | 365.00 | 2.50 | 20.00 | 1.00 |
| 3.00 | 15.35 | 0.36 | 8.21 | 0.27 | 3.53 | 364.00 | 2.50 | 31.00 | 1.00 |
| 2.00 | 15.45 | 0.36 | 8.35 | 0.25 | 3.53 | 364.00 | 2.10 | 42.00 | 1.00 |
| 2.00 | 16.02 | 0.36 | 7.68 | 0.20 | 3.33 | 366.00 | 2.10 | 29.00 | 1.00 |
| 3.00 | 16.22 | 0.36 | 8.30 | 0.29 | 3.47 | 365.00 | 2.40 | 10.00 | 1.00 |
| 3.00 | 16.31 | 0.36 | 7.85 | 0.23 | 3.47 | 365.00 | 2.40 | 22.00 | 1.00 |
| 3.00 | 15.89 | 0.36 | 7.66 | 0.18 | 3.47 | 366.00 | 2.40 | 22.00 | 1.00 |
| 3.00 | 15.86 | 0.36 | 7.48 | 0.20 | 3.53 | 369.00 | 2.30 | 13.00 | 1.00 |
| 3.00 | 16.02 | 0.36 | 8.66 | 0.28 | 3.40 | 365.00 | 2.30 | 4.00 | 1.00 |
| 3.00 | 17.66 | 0.28 | 9.32 | 0.30 | 3.27 | 365.00 | 2.40 | 38.00 | 2.00 |
| 3.00 | 17.56 | 0.36 | 10.10 | 0.29 | 3.33 | 365.00 | 2.40 | 47.00 | 2.00 |
| 3.00 | 18.62 | 0.36 | 9.84 | 0.28 | 3.27 | 368.00 | 2.10 | 43.00 | 2.00 |
| 3.00 | 16.35 | 0.36 | 9.63 | 0.32 | 3.27 | 366.00 | 2.10 | 26.00 | 2.00 |
| 3.00 | 16.58 | 0.36 | 10.10 | 0.30 | 3.27 | 366.00 | 2.10 | 15.00 | 2.00 |
| 3.00 | 18.35 | 0.36 | 10.50 | 0.28 | 3.20 | 367.00 | 2.10 | 5.00 | 2.00 |
| 3.00 | 18.55 | 0.36 | 9.92 | 0.30 | 3.33 | 367.00 | 2.10 | 5.00 | 2.00 |
| 3.00 | 17.66 | 0.36 | 10.60 | 0.28 | 3.27 | 368.00 | 2.10 | 24.00 | 2.00 |
| 3.00 | 16.48 | 0.36 | 11.10 | 0.20 | 3.07 | 368.00 | 2.10 | 9.00 | 2.00 |
| 3.00 | 15.67 | 0.36 | 10.70 | 0.26 | 3.40 | 370.00 | 2.10 | 8.00 | 2.00 |
| 3.00 | 16.35 | 0.36 | 9.30 | 0.26 | 3.33 | 369.00 | 2.00 | 11.60 | 2.00 |
| 3.00 | 17.20 | 0.36 | 8.78 | 0.30 | 3.33 | 370.00 | 2.00 | 6.80 | 2.00 |
| 3.00 | 16.33 | 0.36 | 8.82 | 0.22 | 3.33 | 367.00 | 2.00 | 28.00 | 2.00 |
| 2.00 | 16.23 | 0.28 | 10.20 | 0.34 | 3.40 | 363.00 | 2.60 | 28.00 | 2.00 |
| 2.00 | 16.55 | 0.28 | 11.20 | 0.33 | 3.47 | 363.00 | 2.60 | 15.00 | 2.00 |
| 2.00 | 17.50 | 0.30 | 10.50 | 0.37 | 3.13 | 368.00 | 2.00 | 20.00 | 2.00 |
| 3.00 | 17.63 | 0.30 | 10.90 | 0.22 | 3.47 | 363.00 | 2.40 | 3.00 | 2.00 |
| 3.00 | 16.88 | 0.36 | 9.80 | 0.29 | 3.47 | 364.00 | 2.30 | 16.00 | 2.00 |
| 3.00 | 17.06 | 0.36 | 10.20 | 0.30 | 3.27 | 362.00 | 2.30 | 22.00 | 2.00 |
| 3.00 | 16.69 | 0.30 | 13.90 | 0.36 | 3.27 | 368.00 | 2.10 | 9.00 | 3.00 |
| 2.00 | 17.52 | 0.28 | 13.50 | 0.33 | 3.80 | 360.00 | 2.30 | 8.00 | 3.00 |
| 2.00 | 18.21 | 0.30 | 12.90 | 0.38 | 3.60 | 363.00 | 2.00 | 11.00 | 3.00 |
| 3.00 | 15.69 | 0.36 | 7.46 | 0.26 | 3.33 | 365.00 | 2.20 | 26.49 | 1.00 |
| 2.00 | 16.20 | 0.36 | 7.90 | 0.26 | 3.33 | 365.00 | 2.30 | 27.12 | 1.00 |
| 3.00 | 16.55 | 0.36 | 8.75 | 0.25 | 3.33 | 368.00 | 2.10 | 18.40 | 2.00 |
| 3.00 | 16.32 | 0.36 | 10.10 | 0.35 | 3.53 | 360.00 | 2.20 | 20.49 | 2.00 |
| 3.00 | 16.53 | 0.36 | 9.70 | 0.33 | 3.53 | 365.00 | 2.10 | 17.54 | 2.00 |
| 3.00 | 15.85 | 0.36 | 9.80 | 0.32 | 3.67 | 360.00 | 2.30 | 17.02 | 2.00 |
| 3.00 | 16.21 | 0.30 | 12.90 | 0.34 | 3.33 | 370.00 | 2.10 | 12.45 | 3.00 |
| Name of Experimental Group | Included Parameter Indicators | Entropy-Weighted Gray Correlation |
|---|---|---|
| 1 | X1~X9 | ri > 0.008 |
| 2 | X2, X4, X5, X6, X7, X8, X9 | ri > 0.010 |
| 3 | X2, X4, X5, X6, X9 | ri > 0.012 |
| 4 | X2, X4, X5, X6 | ri > 0.013 |
| Experimental Group | REmax | MRE | RMSE | R2 |
|---|---|---|---|---|
| 1 | 0.500 | 0.111 | 0.226 | 0.981 |
| 2 | 1.000 | 0.083 | 0.323 | 0.945 |
| 3 | 0.500 | 0.063 | 0.177 | 0.989 |
| 4 | 0.500 | 0.042 | 0.144 | 0.993 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, L.; Gao, Y. A Gas Prominence Prediction Model Based on Entropy-Weighted Gray Correlation and MCMC-ISSA-SVM. Processes 2023, 11, 2098. https://doi.org/10.3390/pr11072098
Shao L, Gao Y. A Gas Prominence Prediction Model Based on Entropy-Weighted Gray Correlation and MCMC-ISSA-SVM. Processes. 2023; 11(7):2098. https://doi.org/10.3390/pr11072098
Chicago/Turabian StyleShao, Liangshan, and Yingchao Gao. 2023. "A Gas Prominence Prediction Model Based on Entropy-Weighted Gray Correlation and MCMC-ISSA-SVM" Processes 11, no. 7: 2098. https://doi.org/10.3390/pr11072098