

Intelligent Classification of Volcanic Rocks Based on Honey Badger Optimization Algorithm Enhanced Extreme Gradient Boosting Tree Model: A Case Study of Hongche Fault Zone in Junggar Basin

Abstract
:1. Introduction
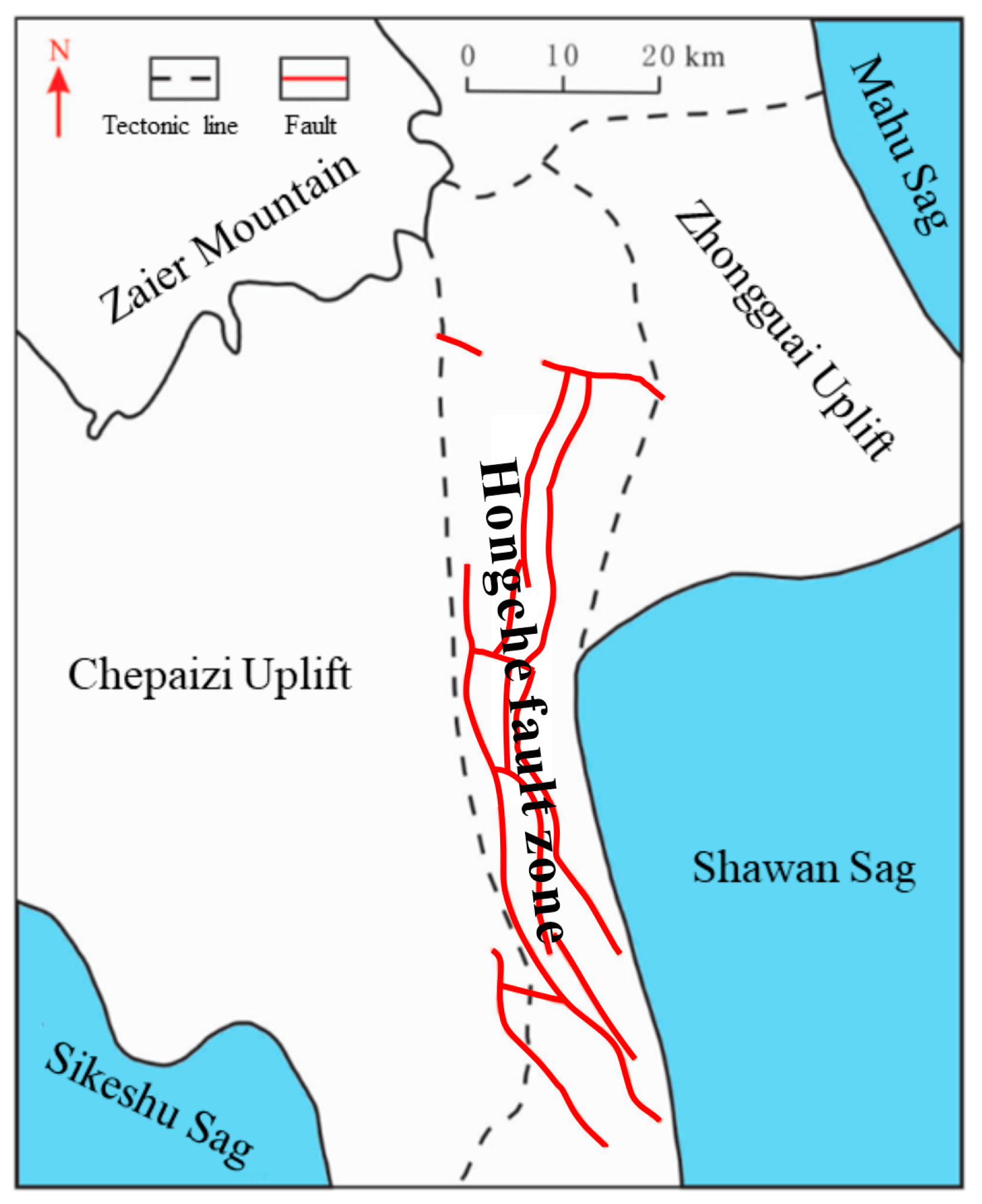
2. Geological Settings
3. Principle of the HBA-XGBoost Model
3.1. Honey Badger Algorithm
3.2. XGBoost Model Principle
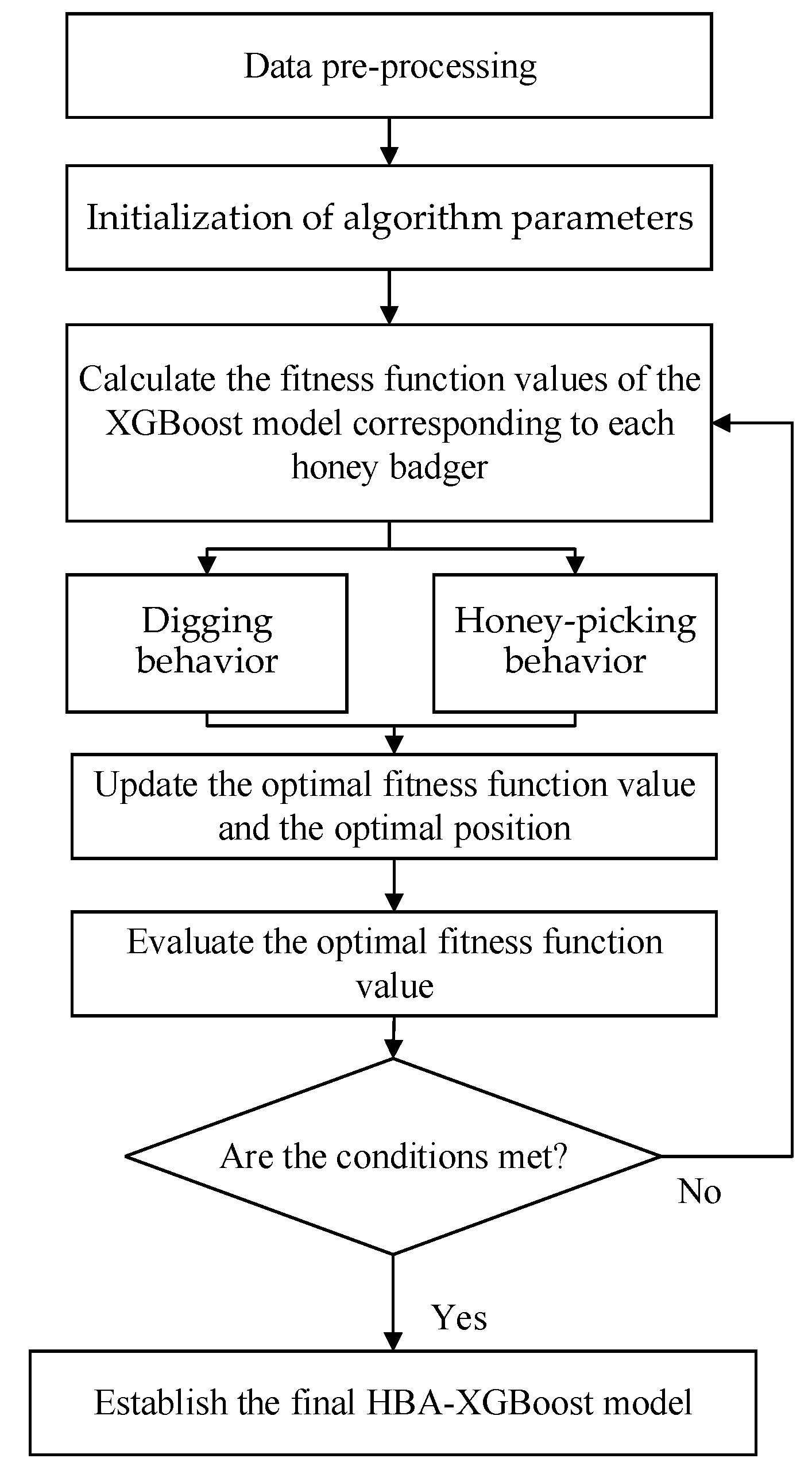
3.3. HBA-XGBoost Model Principle
- Data cleaning of the volcanic rock data set, missing value processing, log curve standardization, data feature selection, data set division and other pre-processing work are carried out to ensure data quality and consistency.
- Using the honey badger optimization algorithm, the honey badger population is initialized according to the XGBoost hyperparameter feature. Each honey badger represents a combination of XGBoost hyperparameter features. Initial conditions are defined, such as density factors (α), sign to change direction (F) and the honey badger’s ability to catch prey (β).
- The XGBoost model is used as the fitness evaluation function of the HBA model. The XGBoost model is trained according to each individual of the badger population. The model performance is evaluated by cross-validation, and the calculated performance index is passed to the HBA model.
- The HBA model uses Equations (2) and (3) to update the positions of the individuals of the badger population to complete the foraging behavior according to the badger’s two foraging strategies (digging behavior and honey-picking behavior), that is, the its seeks the best combination of hyperparameters. After the population position is updated, the fitness function is recalculated and the population positions are continuously iterated. Finally, the globally optimal individual is selected as the optimal hyperparameter combination.
- The XGBoost model is trained with the globally optimal hyperparameter combination, and the HBA-XGBoost optimization model is obtained to evaluate and predict the lithology of volcanic rock.
3.4. Model Evaluation Index
4. Data Analysis and Processing
- For all samples x in the sedimentary tuff, the Euclidean distance to other samples is calculated to obtain K-nearest neighbor samples.
- The oversampling coefficient is determined according to the proportion of sedimentary tuff and most samples. For each sample of sedimentary tuff, xi, n samples are obtained by oversampling with Equation (10) to increase the number of minority samples.
- 3.
- After increasing the number of samples, the redundant and repeated data samples are deleted to prevent over-fitting in subsequent training.
- 4.
- The data set is standardized after sampling, eliminating the influence of different dimensions, increasing the operation speed and preparing for the following modeling.
5. Results
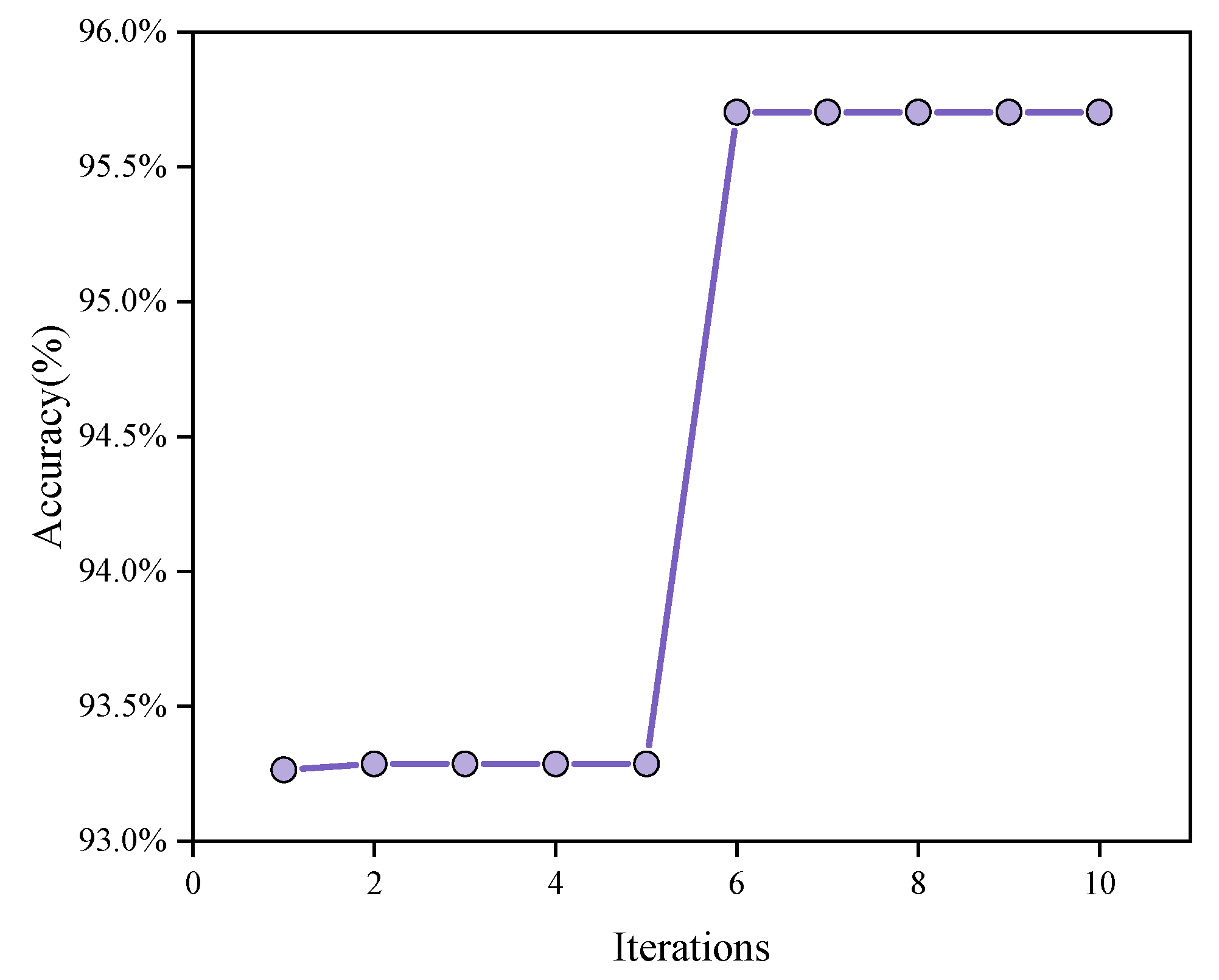
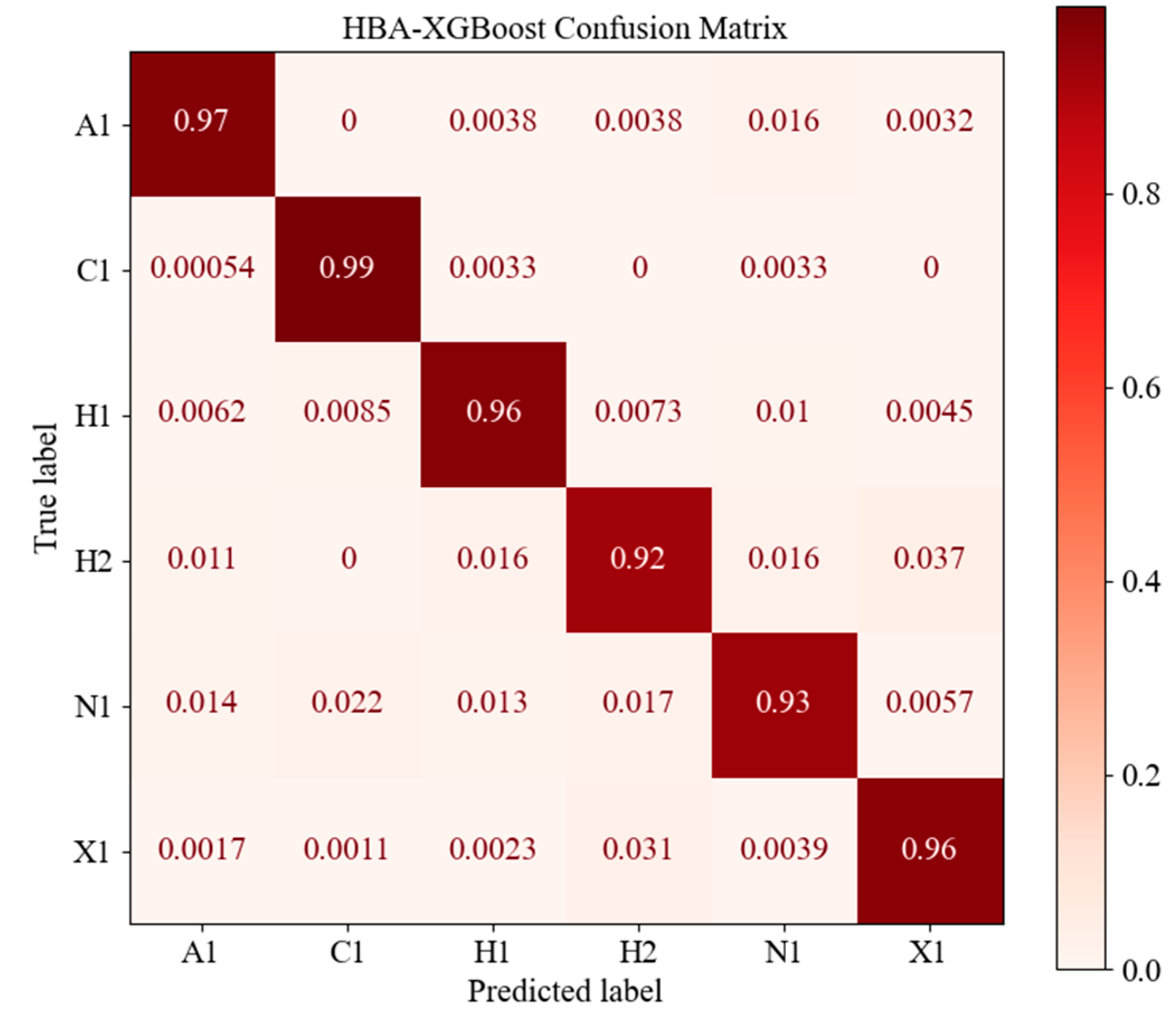
5.1. HBA-XGBoost Application Effect
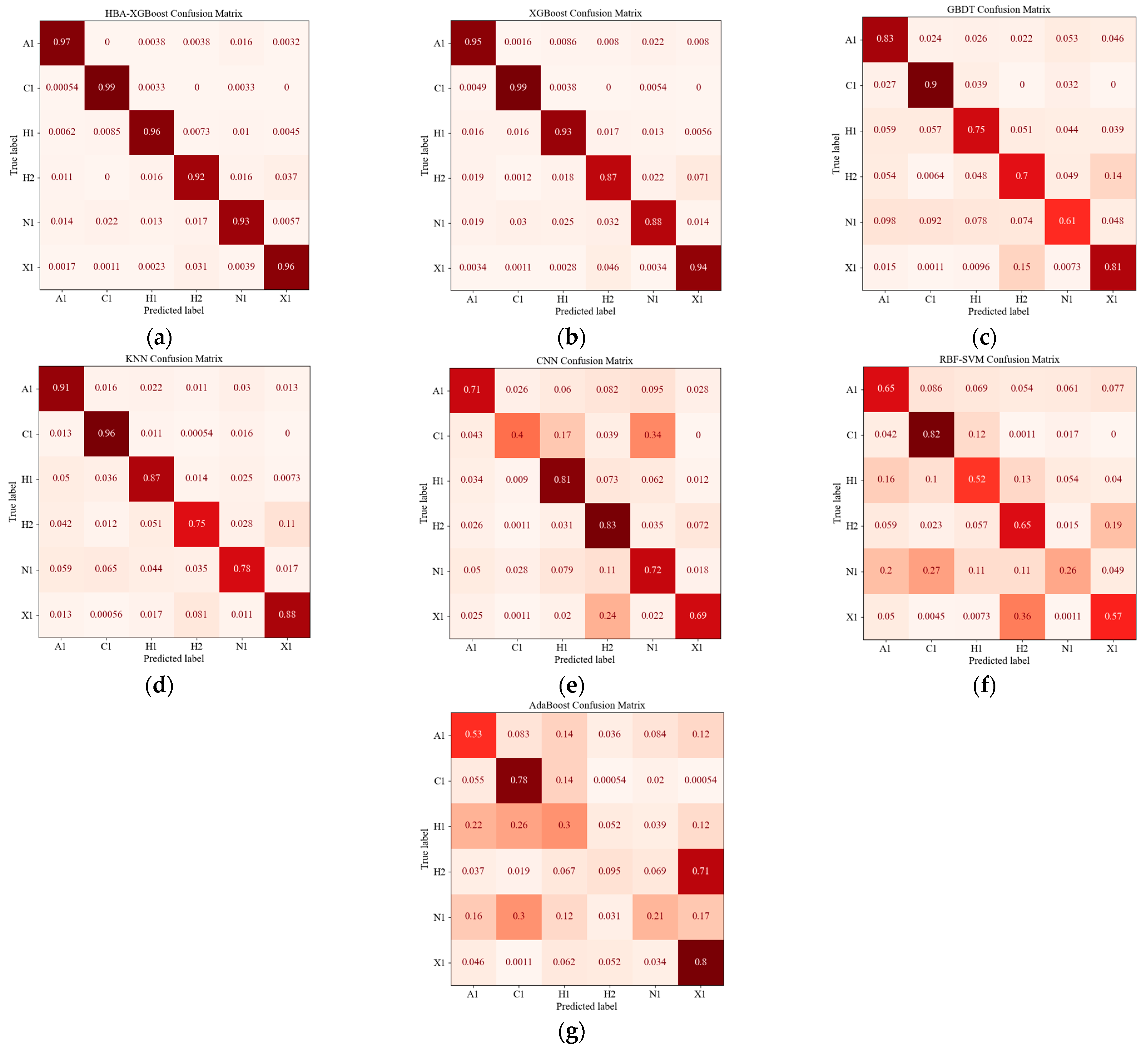
5.2. Model Comparison
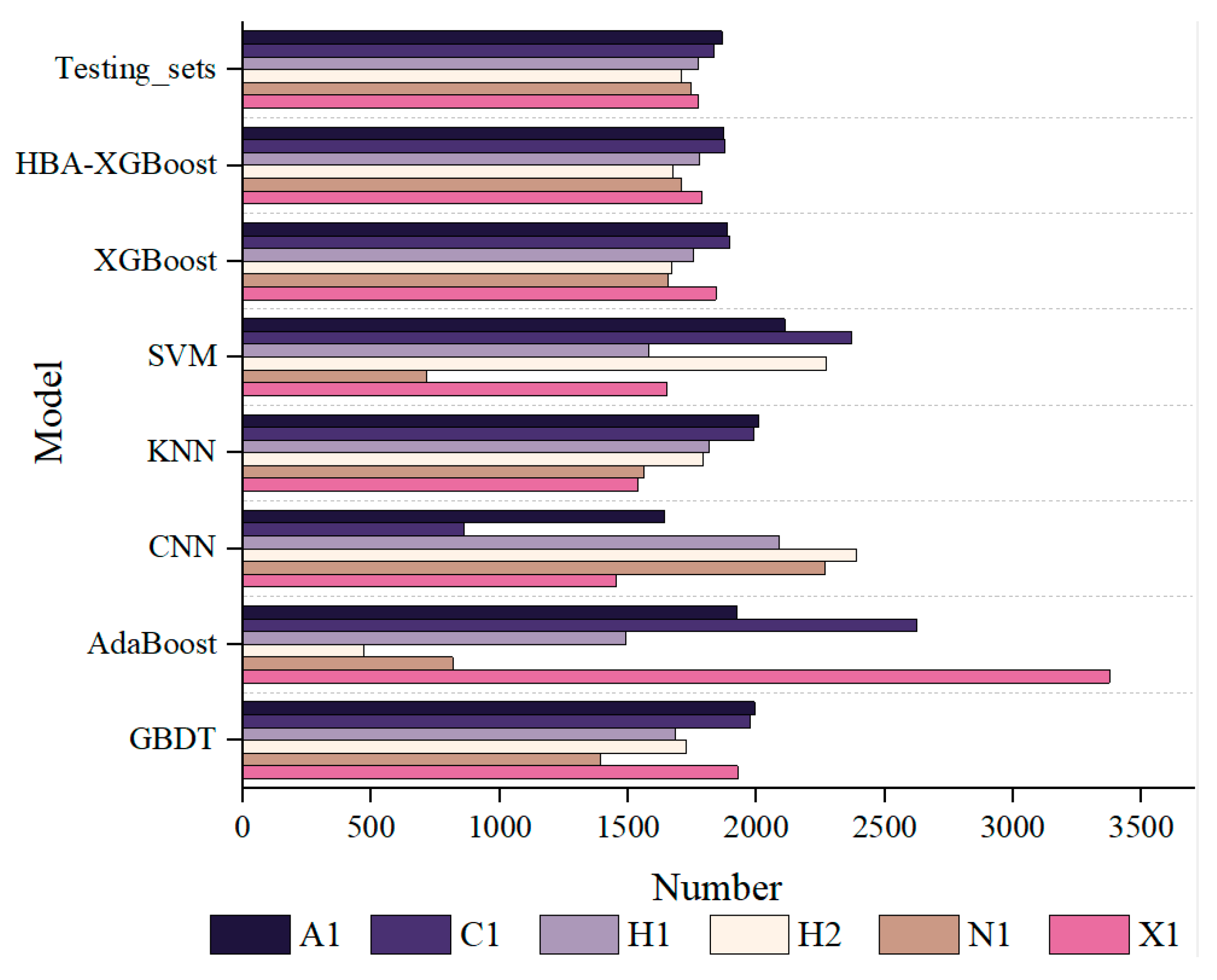
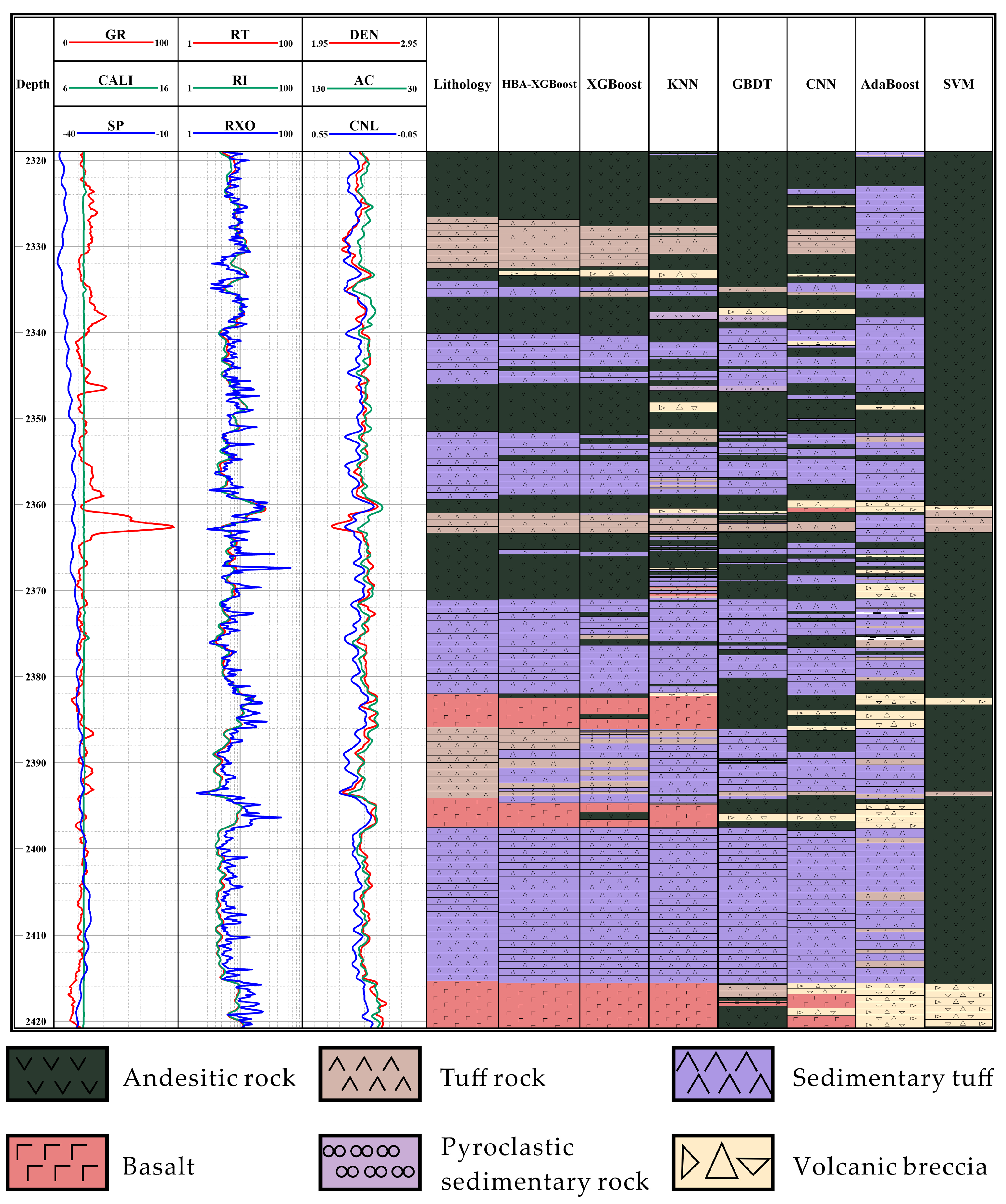
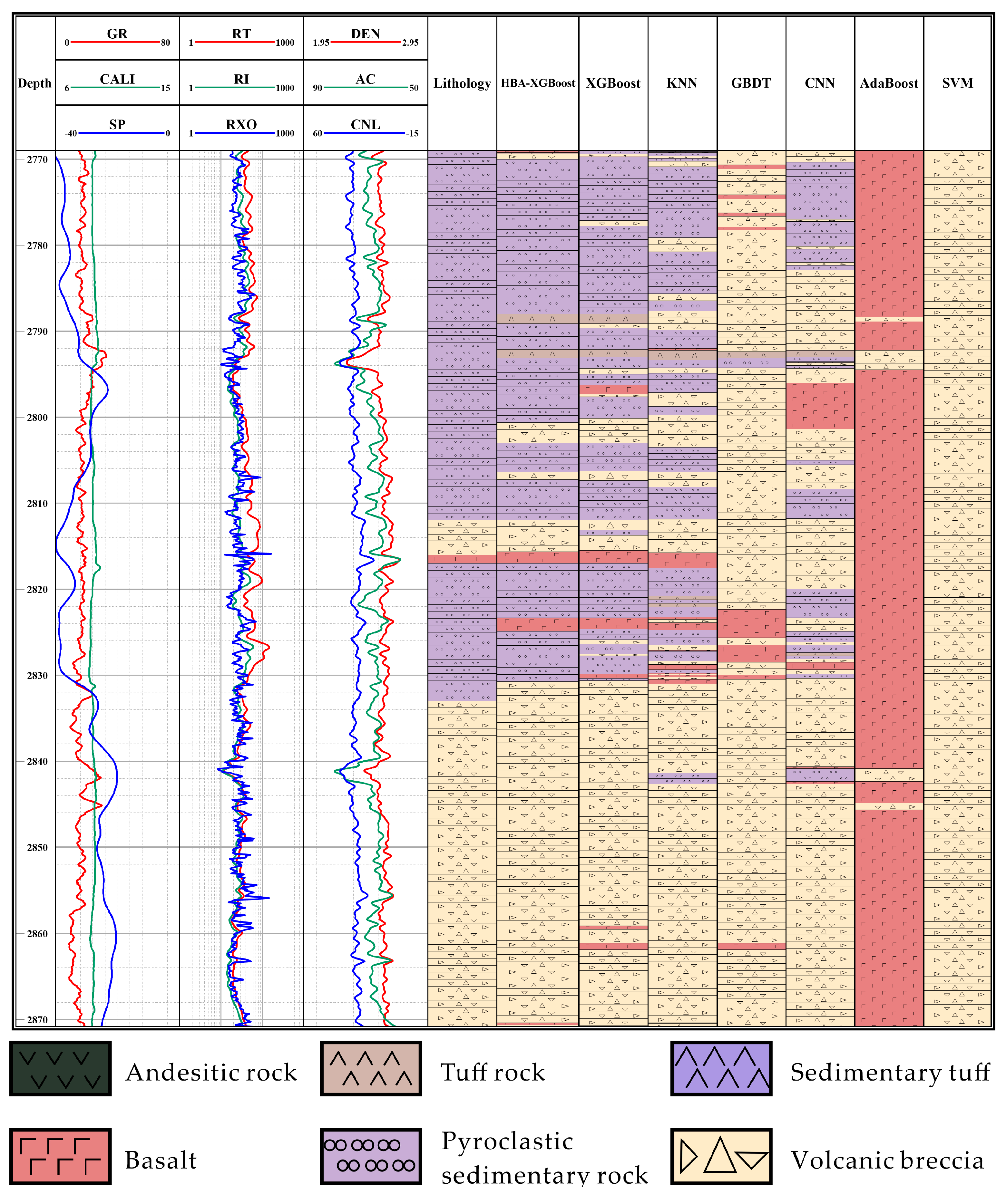
5.3. Practical Application Effect
6. Discussion and Prospects
7. Conclusions
- Based on the log data of the Hongche fault zone, a volcanic rock lithology data set was established. The data set includes eight curve features: GR, CALI, SP, RT, RXO, DEN, AC and CNL. There are six dominant lithologies: pyroclastic sedimentary rock, volcanic breccia, sedimentary tuff, tuff, andesite and basalt.
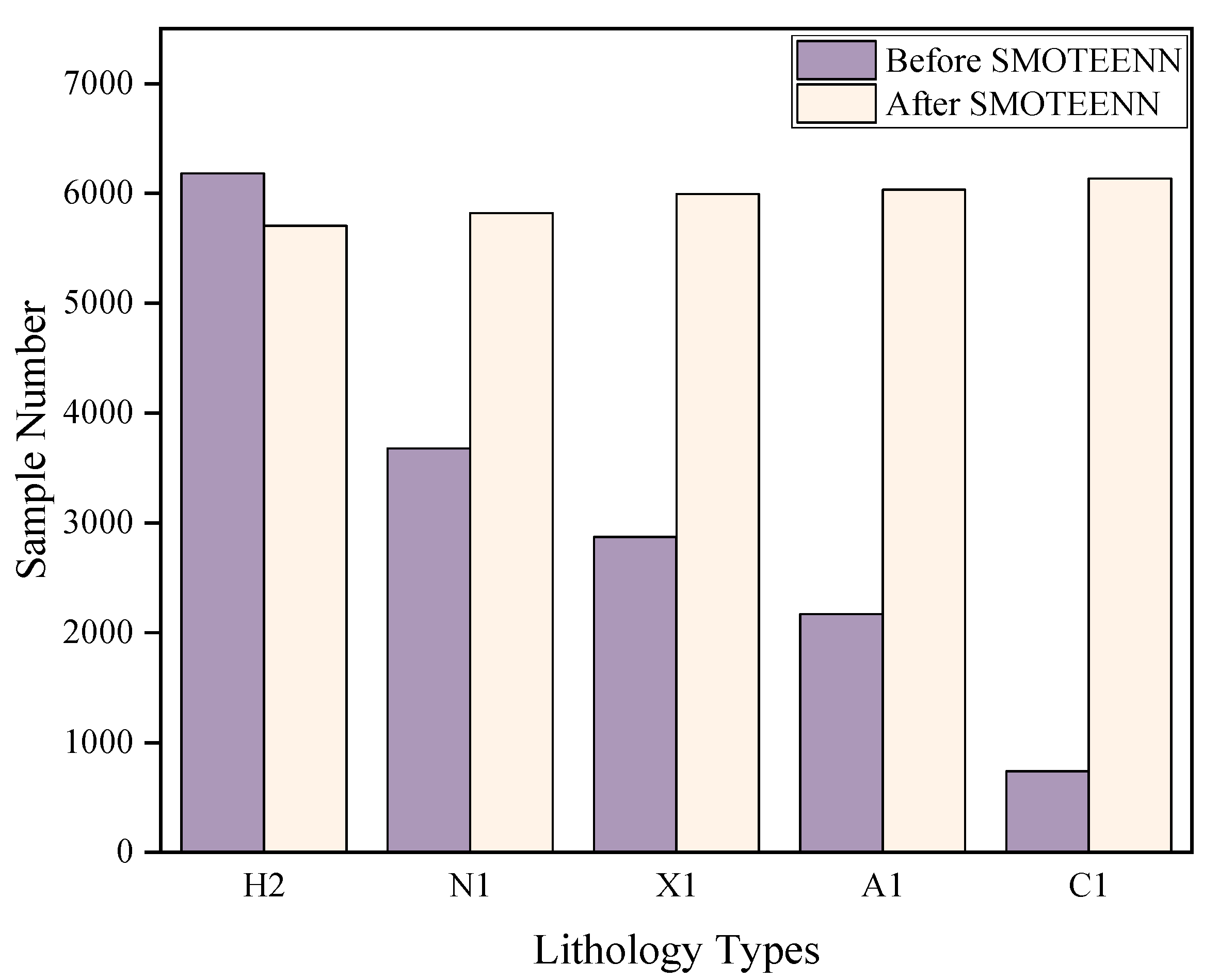
- SMOTEENN can effectively solve the problem of the unbalanced data scale of different dominant lithologies in a data set, increasing the sample size when there is a small number of samples, reducing the sample size when there is a large number of samples, and balancing the amount of data for various lithology labels.
- The HBA model can optimize the hyperparameter space of XGBoost, obtain the optimal hyperparameter combination of XGBoost, optimize the model structure of XGBoost and improve the indicators of the XGBoost model in volcanic rock lithology prediction. The overall prediction accuracy was improved by about 3%. The recognition accuracy of HBA-XGBoost for various lithologies in the study area was above 92%, whick is higher than the prediction accuracy of XGBoost, KNN, GBDT, AdaBoost, CNN and SVM.
- The proposed model was applied to the lithology identification of data from two actual wells in the study area. The HBA-XGBoost model accurately and continuously predicted different lithologies, and also accurately predicted at the boundaries of lithology changes. Compared with other models, the prediction accuracy was higher, and provides a certain reference for the lithology identification of volcanic rocks.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sun, J.; Li, Q.; Chen, M.; Ren, L.; Huang, G.; Li, C.; Zhang, Z. Optimization of models for a rapid identification of lithology while drilling-A win-win strategy based on machine learning. J. Pet. Sci. Eng. 2019, 176, 321–341. [Google Scholar] [CrossRef]
- Dev, V.A.; Eden, M.R. Formation lithology classification using scalable gradient boosted decision trees. Comput. Chem. Eng. 2019, 128, 392–404. [Google Scholar] [CrossRef]
- Chen, H.Q.; Shi, W.W.; Du, Y.J.; Deng, X.J. Advances in volcanic facies research of volcanic reservoir. Chin. J. Geol. (Sci. Geol. Sin.) 2022, 4, 1307–1323. [Google Scholar]
- He, Z.J.; Zeng, Q.C.; Chen, S.; Dai, C.M.; Wang, X.J.; Yang, Y.D. Volcanic reservoir prediction method and application in the Well Yongtan 1, southwest Sichuan. Sci. Technol. Eng. 2021, 21, 10661–10669. [Google Scholar]
- Xie, Y.X.; Zhu, C.Y.; Zhou, W.; Li, Z.D.; Liu, X.; Tu, M. Evaluation of machine learning methods for formation lithology identification: A comparison of tuning processes and model performances. J. Pet. Sci. Eng. 2018, 160, 182–193. [Google Scholar] [CrossRef]
- Zhang, Y.; Pan, B.Z. Application of SOM Neural Network Method to Volcanic Lithology Recognition Based on Principal Components Analysis. Well Logging Technol. 2009, 33, 550–554. [Google Scholar]
- Zhu, Y.X.; Shi, G.R. Identification of lithologic characteristics of volcanic rocks by support vector machine. Acta Pet. Sin. 2013, 34, 312–322. [Google Scholar]
- Zhang, Y.; Pan, B.Z. The Application of SVM and FMI to the Lithologic Identification of Volcanic Rocks. Geophys. Geochem. Explor. 2011, 35, 634–638+642. [Google Scholar]
- Wang, P.; Wang, Z.Q.; Ji, Y.L.; Duan, W.H.; Pan, L. Identification of Volcanic Rock Based on Kernel Fisher Dis-criminant Analysis. Well Logging Technol. 2015, 39, 390–394. [Google Scholar]
- Wang, H.F.; Jiang, Y.L.; Lu, Z.K.; Wang, Z.W. Lithologic identification and application for igneous rocks in eastern depression of Liaohe oil field. World Geol. 2016, 35, 510–516+525. [Google Scholar]
- Ye, T.; Wei, A.J.; Deng, H.; Zeng, J.C.; Gao, K.S.; Sun, Z. Study on volcanic lithology identification methods based on the data of conventional well logging data: A case from Mesozoic volcanic rocks in Bohai bay area. Prog. Geophys. 2017, 32, 1842–1848. [Google Scholar]
- Xiang, M.; Qin, P.B.; Zhang, F.W. Research and application of logging lithology identification for igneous reservoirs based on deep learning. J. Appl. Geophys. 2020, 173, 103929. [Google Scholar]
- Mou, D.; Zhang, L.C.; Xu, C.L. Comparison of Three Classical Machine Learning Algorithms for Lithology Identification of Volcanic Rocks Using Well Logging Data. J. Jilin Univ. (Earth Sci. Ed.) 2021, 51, 951–956. [Google Scholar]
- Yang, X.; Wang, Z.Z.; Zhou, Z.Y.; Wei, Z.C.; Qu, K.; Wang, X.Y.; Wang, R.Y. Lithology classification of acidic volcanic rocks based on parameter-optimized AdaBoost algorithm. Acta Pet. Sin. 2019, 40, 457–467. [Google Scholar]
- Han, R.Y.; Wang, Z.W.; Wang, W.H.; Xu, F.H.; Qi, X.H.; Cui, Y.T. Lithology identification of igneous rocks based on XGboost and conventional logging curves, a case study of the eastern depression of Liaohe Basin. J. Appl. Geophys. 2021, 195, 104480. [Google Scholar]
- Han, R.Y.; Wang, Z.W.; Wang, W.H.; Xu, F.H.; Qi, X.H.; Cui, Y.T.; Zhang, Z.T. Igneous rocks lithology identification with deep forest: Case study from eastern sag, Liaohe basin. J. Appl. Geophys. 2023, 208, 104892. [Google Scholar] [CrossRef]
- Sun, Y.S.; Huang, Y.; Liang, T.; Ji, H.C.; Xiang, P.F.; Xu, X.R. Identification of complex carbonate lithology by logging based on XGBoost algorithm. Lithol. Reserv. 2020, 32, 98–106. [Google Scholar]
- Yu, Z.C.; Wang, Z.Z.; Zeng, F.C.; Song, P.; Baffour, B.A.; Wang, P.; Wang, W.F.; Li, L. Volcanic lithology identification based on parameter-optimized GBDT algorithm: A case study in the Jilin Oilfield, Songliao Basin, NE China. J. Appl. Geophys. 2021, 194, 104443. [Google Scholar] [CrossRef]
- Zhang, C.; Pan, M.; Hu, S.Q.; Hu, Y.F.; Yan, Y.Q. A machine learning lithologic identification method combined with vertical reservoir information. Bull. Geol. Sci. Technol. 2023, 42, 289–299. [Google Scholar]
- Liu, M.J.; Li, H.T.; Jiang, Z.B. Application of genetic-BP neural network model in lithology identification by logging data in Binchang mining area. Coal Geol. Explor. 2011, 39, 8–12. [Google Scholar]
- Ren, Q.; Zhang, H.B.; Zhang, D.L.; Zhao, X. Lithology identification using principal component analysis and particle swarm optimization fuzzy decision tree. J. Pet. Sci. Eng. 2023, 220, 111233. [Google Scholar] [CrossRef]
- Zhang, T.; Li, Y.P.; Liu, X.Y.; Li, M.Y.; Wang, J.J. Lithology interpretation of deep metamorphic rocks with well logging based on APSO-LSSVM algorithm. Prog. Geophys. 2022, 38, 382–392. [Google Scholar]
- Zhang, J.L.; He, Y.B.; Zhang, Y.; Li, W.F.; Zhang, J.J. Well-Logging-Based Lithology Classification Using Machine Learning Methods for High-Quality Reservoir Identification: A Case Study of Baikouquan Formation in Mahu Area of Junggar Basin, NW China. Energies 2022, 15, 3675. [Google Scholar] [CrossRef]
- Sun, Z.X.; Jiang, B.S.; Li, X.L.; Li, J.K.; Xiao, K. A data-driven approach for lithology identification based on parameter-optimized ensemble learning. Energies 2020, 13, 3903. [Google Scholar] [CrossRef]
- Andic, C.; Ozumcan, S.; Ozturk, A.; Turkay, B. Honey Badger Algorithm Based Tuning of PID Conroller for Load Frequency Control in Two-Area Power System Including Electric Vehicle Battery. In Proceedings of the 2022 4th Global Power, Energy and Communication Conference (GPECOM), Cappadocia, Turkey, 14–17 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 307–310. [Google Scholar]
- Akdağ, O. A Developed Honey Badger Optimization Algorithm for Tackling Optimal Power Flow Problem. Electr. Power Compon. Syst. 2022, 50, 331–348. [Google Scholar] [CrossRef]
- Jaiswal, G.K.; Nangia, U.; Jain, N.K. Optimal Reactive Power Dispatch Using Honey Badger algorithm (HBA). In Proceedings of the 2022 IEEE 10th Power India International Conference (PIICON), New Delhi, India, 25–27 November 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Su, P.D.; Qin, Q.R.; Yuan, Y.F.; Jiang, F.D. Characteristics of Volcanic Reservoir Fractures in Upper Wall of HongChe Fault Belt. Xinjiang Pet. Geol. 2011, 32, 457–460. [Google Scholar]
- Liu, Y.; Wu, K.Y.; Wang, X.; Liu, B.; Guo, J.X.; Du, Y.N. Architecture of buried reverse fault zone in the sedimentary basin: A case study from the Hong-Che Fault Zone of the Junggar Basin. J. Struct. Geol. 2017, 105, 1–17. [Google Scholar] [CrossRef]
- Jiang, Q.J.; Li, Y.; Liu, X.J.; Wang, J.; Ma, W.Y.; He, Q.B. Controlling factors of multi-source and multi-stage complex hydrocarbon accumulation and favorable exploration area in the Hongche fault zone, Junggar Basin. Nat. Gas Geosci. 2023, 34, 807–820. [Google Scholar]
- Gan, X.Q.; Jiang, Y.Y.; Qin, Q.R.; Song, W.Y. Characteristics of the Carboniferous volcanic reservoir in the Hongche fault zone. Spec. Oil Gas Reserv. 2011, 18, 45–17+137. [Google Scholar]
- Yao, W.J.; Dang, Y.F.; Zhang, S.C.; Zhi, D.M.; Xing, C.Z.; Shi, J.A. Formation of Carboniferous Reservoir in Hongche Fault Belt, Northwestern Margin of Junggar Basin. Nat. Gas Geosci. 2010, 21, 917–923. [Google Scholar]
- Feng, Z.Y.; Yin, W.; Zhong, Y.T.; Yu, J.; Zhao, L.; Feng, C. Lithologic identification of igneous rocks based on conventional log: A case study of Carboniferous igneous reservoir in Hongche Fault Zone in Northwestern Junggar Basin. J. Northeast Pet. Univ. 2021, 45, 95–108. [Google Scholar]
- Dong, X.M.; Li, J.; Pan, T.; Xu, Q.; Chen, L.; Ren, J.M.; Jin, K. Hydrocarbon accumulation conditions and exploration potential of Hongche fault zone in Junggar Basin. Acta Pet. Sin. 2023, 44, 748–764. [Google Scholar]
- Zhong, W.J.; Huang, X.H.; Zhang, Y.H.; Jia, C.M.; Wu, K.Y. Structural characteristics and reservoir forming control of Hongche fault zone in Junggar Basin. Complex Hydrocarb. Reserv. 2018, 11, 1–5. [Google Scholar]
- Fan, C.H.; Qin, Q.R.; Yuan, Y.F.; Wang, X.D.; Zhu, Y.P. Structure characteristics and fracture development pattern of the Carboniferous in Hongche fracture belt. Spec. Oil Gas Reserv. 2010, 17, 47–49. [Google Scholar]
- Hashim, F.A.; Houssein, E.H.; Hussain, K.; Mabrouk, M.S.; AI-Atabany, W. Honey Badger Algorithm: New metaheuristic algorithm for solving optimization problems. Math. Comput. Simul. 2022, 192, 84–110. [Google Scholar] [CrossRef]
- Chen, T.Q.; Carlos, G. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Fu, G.M.; Yan, J.Y.; Zhang, K.; Hu, H.; Luo, F. Current status and progress of lithology identification technology. Prog. Geophys. 2017, 32, 26–40. [Google Scholar]
- Muntasir Nishat, M.; Faisal, F.; Jahan Ratul, I.; Al-Monsur, A.; Ar-Rafi, A.M.; Nasrullah, S.M.; Khan, M.R.H. A comprehensive investigation of the performances of different machine learning classifiers with SMOTE-ENN over-sampling technique and hyperparameter optimization for imbalanced heart failure dataset. Sci. Program. 2022, 2022, 3649406. [Google Scholar]
- Zou, Y.; Chen, Y.; Deng, H. Gradient boosting decision tree for lithology identification with well logs: A case study of zhaoxian gold deposit, shandong peninsula, China. Nat. Resour. Res. 2021, 30, 3197–3217. [Google Scholar] [CrossRef]
- Lai, Q.; Wei, B.Y.; Wu, Y.Y.; Pan, B.Z.; Xie, B.; Guo, Y.H. Classification of Igneous Rock Lithology with K-nearest Neighbor Algorithm Based on Random Forest (RF-KNN). Spec. Oil Gas Reserv. 2021, 28, 62–69. [Google Scholar]
- Asante-Okyere, S.; Shen, C.; Osei, H. Enhanced machine learning tree classifiers for lithology identification using Bayesian optimization. Appl. Comput. Geosci. 2022, 16, 100100. [Google Scholar] [CrossRef]
- Liang, H.B.; Chen, H.F.; Guo, J.H.; Bai, J.; Jiang, Y.J. Research on lithology identification method based on mechanical specific energy principle and machine learning theory. Expert Syst. Appl. 2022, 189, 116142. [Google Scholar] [CrossRef]
- Han, J.; Lu, C.H.; Cao, Z.M.; Mu, H.W. Integration of deep neural networks and ensemble learning machines for missing well logs estimation. Flow Meas. Instrum. 2020, 73, 101748. [Google Scholar]
- Tariq, Z.; Elkatatny, S.; Mahmoud, M.; Abdulraheem, A. A new artificial intelligence based empirical correlation to predict sonic travel time. In Proceedings of the 2016 International Petroleum Technology Conference, Bangkok, Thailand, 14–16 November 2016. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| True Label | Predicted Label | |
|---|---|---|
| Positive | Negative | |
| Positive | TP (True Positive) | FN (False Negative) |
| Negative | FP (False Positive) | TN (True Negative) |
| GR | CALI | SP | RT | RXO | DEN | AC | CNL | |
|---|---|---|---|---|---|---|---|---|
| H1 | 7.89~92.25 | 7.66~11.66 | −45.81~18.00 | 0.21~2.36 | −0.06~2.65 | 2.01~2.75 | 54.61~127.92 | 0.13~49.82 |
| (43.24) | (8.98) | (−13.60) | (1.10) | (1.11) | (2.45) | (76.88) | (24.54) | |
| N1 | 6.02~95.28 | 7.66~10.68 | −67.67~22.20 | 0.10~2.75 | −0.36~2.08 | 1.75~2.78 | 56.16~124.06 | 0.16~53.44 |
| (43.20) | (8.84) | (−16.26) | (1.34) | (1.31) | (2.45) | (75.36) | (22.60) | |
| H2 | 3.75~75.67 | 7.63~12.02 | −63.02~17.09 | 0.41~2.97 | 0.21~3.24 | 2.18~2.77 | 52.94~102.12 | 0.17~46.10 |
| (19.77) | (8.83) | (−22.69) | (1.59) | (1.52) | (2.54) | (67.64) | (26.50) | |
| A1 | 7.63~88.12 | 8.07~10.14 | −52.17~10.92 | 0.46~2.68 | 0.02~3.02 | 2.18~2.81 | 53.54~98.29 | 0.10~41.17 |
| (39.35) | (8.65) | (−18.13) | (1.41) | (1.40) | (2.53) | (69.64) | (17.51) | |
| X1 | 5.15~95.78 | 7.64~10.91 | −85.20~1.16 | 0.33~3.27 | −0.20~3.21 | 2.10~2.83 | 52.00~107.24 | 0.09~46.36 |
| (18.04) | (8.65) | (−23.84) | (1.72) | (1.65) | (2.60) | (63.61) | (22.04) | |
| C1 | 15.99~89.40 | 8.17~9.84 | −61.93~16.46 | 0.22~1.74 | −0.36~2.46 | 1.55~2.58 | 60.76~120.88 | 0.23~56.06 |
| (54.73) | (8.63) | (−13.10) | (0.93) | (1.00) | (2.40) | (82.05) | (23.57) |
| Hyperparameter | Default Value | Hyperparameter Meaning | Region of Search | Global Optimum |
|---|---|---|---|---|
| n_estimators | 100 | Number of weak classifiers | [50~200] | 196 |
| learning_rate | 0.3 | Learning rate | [0.01~1.0] | 0.4987 |
| subsample | 1 | Proportion of samples taken from a sample | [0.5~1.0] | 0.8154 |
| max_depth | 6 | Maximum weak classifier depth | [3~10] | 9 |
| gamma | 0 | Decrease of the minimum objective function required for weak classifier branching | [0~5] | 0 |
| min_child_weight | 1 | Minimum sample weight required on the leaf node of the weak classifier | [0.01~10] | 0.01 |
| colsample_bytree | 1 | Proportion of features extracted by constructing a weak classifier for all features | [0.5~1.0] | 0.97 |
| Precision (%) | Recall (%) | F1-Score (%) | Accuracy (%) | |
|---|---|---|---|---|
| A1 | 96.91 | 97.32 | 97.11 | 95.70 |
| C1 | 97.02 | 99.29 | 98.14 | |
| H1 | 96.23 | 96.34 | 96.28 | |
| H2 | 93.80 | 92.04 | 92.91 | |
| N1 | 94.85 | 92.84 | 93.84 | |
| X1 | 95.14 | 96.00 | 95.57 | |
| Mean value | 95.66 | 95.64 | 95.64 |
| Model | Performance Index | A1 | C1 | H1 | H2 | N1 | X1 | Mean Value | Accuracy |
|---|---|---|---|---|---|---|---|---|---|
| HBA-XGBoost | Precision | 0.97 | 0.97 | 0.96 | 0.94 | 0.95 | 0.95 | 0.96 | 0.96 |
| Recall | 0.97 | 0.99 | 0.96 | 0.92 | 0.93 | 0.96 | 0.96 | ||
| F1-score | 0.97 | 0.98 | 0.96 | 0.93 | 0.94 | 0.96 | 0.96 | ||
| XGBoost | Precision | 0.94 | 0.95 | 0.94 | 0.89 | 0.93 | 0.91 | 0.93 | 0.93 |
| Recall | 0.95 | 0.99 | 0.93 | 0.87 | 0.88 | 0.94 | 0.93 | ||
| F1-score | 0.95 | 0.97 | 0.94 | 0.88 | 0.9 | 0.93 | 0.93 | ||
| KNN | Precision | 0.85 | 0.89 | 0.86 | 0.84 | 0.87 | 0.86 | 0.86 | 0.86 |
| Recall | 0.91 | 0.96 | 0.87 | 0.75 | 0.78 | 0.88 | 0.86 | ||
| F1-score | 0.88 | 0.92 | 0.86 | 0.79 | 0.82 | 0.87 | 0.86 | ||
| GBDT | Precision | 0.78 | 0.84 | 0.79 | 0.69 | 0.76 | 0.75 | 0.77 | 0.77 |
| Recall | 0.83 | 0.90 | 0.75 | 0.70 | 0.61 | 0.81 | 0.77 | ||
| F1-score | 0.80 | 0.87 | 0.77 | 0.69 | 0.68 | 0.78 | 0.77 | ||
| CNN | Precision | 0.73 | 0.61 | 0.77 | 0.77 | 0.73 | 0.77 | 0.73 | 0.75 |
| Recall | 0.71 | 0.40 | 0.81 | 0.83 | 0.72 | 0.69 | 0.69 | ||
| F1-score | 0.72 | 0.48 | 0.79 | 0.80 | 0.73 | 0.73 | 0.71 | ||
| SVM | Precision | 0.58 | 0.63 | 0.59 | 0.49 | 0.63 | 0.62 | 0.59 | 0.58 |
| Recall | 0.65 | 0.82 | 0.52 | 0.65 | 0.26 | 0.57 | 0.58 | ||
| F1-score | 0.61 | 0.71 | 0.55 | 0.56 | 0.36 | 0.60 | 0.57 | ||
| AdaBoost | Precision | 0.52 | 0.55 | 0.36 | 0.35 | 0.46 | 0.42 | 0.44 | 0.46 |
| Recall | 0.53 | 0.78 | 0.30 | 0.10 | 0.21 | 0.80 | 0.46 | ||
| F1-score | 0.53 | 0.64 | 0.33 | 0.15 | 0.29 | 0.55 | 0.42 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Deng, X.; Shan, X.; Feng, Z.; Zhao, L.; Zong, X.; Feng, C. Intelligent Classification of Volcanic Rocks Based on Honey Badger Optimization Algorithm Enhanced Extreme Gradient Boosting Tree Model: A Case Study of Hongche Fault Zone in Junggar Basin. Processes 2024, 12, 285. https://doi.org/10.3390/pr12020285
Chen J, Deng X, Shan X, Feng Z, Zhao L, Zong X, Feng C. Intelligent Classification of Volcanic Rocks Based on Honey Badger Optimization Algorithm Enhanced Extreme Gradient Boosting Tree Model: A Case Study of Hongche Fault Zone in Junggar Basin. Processes. 2024; 12(2):285. https://doi.org/10.3390/pr12020285
Chicago/Turabian StyleChen, Junkai, Xili Deng, Xin Shan, Ziyan Feng, Lei Zhao, Xianghua Zong, and Cheng Feng. 2024. "Intelligent Classification of Volcanic Rocks Based on Honey Badger Optimization Algorithm Enhanced Extreme Gradient Boosting Tree Model: A Case Study of Hongche Fault Zone in Junggar Basin" Processes 12, no. 2: 285. https://doi.org/10.3390/pr12020285
APA StyleChen, J., Deng, X., Shan, X., Feng, Z., Zhao, L., Zong, X., & Feng, C. (2024). Intelligent Classification of Volcanic Rocks Based on Honey Badger Optimization Algorithm Enhanced Extreme Gradient Boosting Tree Model: A Case Study of Hongche Fault Zone in Junggar Basin. Processes, 12(2), 285. https://doi.org/10.3390/pr12020285