
The TPRF: A Novel Soft Sensing Method of Alumina–Silica Ratio in Red Mud Based on TPE and Random Forest Algorithm


Abstract
:1. Introduction
2. Research Method
2.1. TPE Model
2.2. Random Forest Model
2.3. TPRF Model
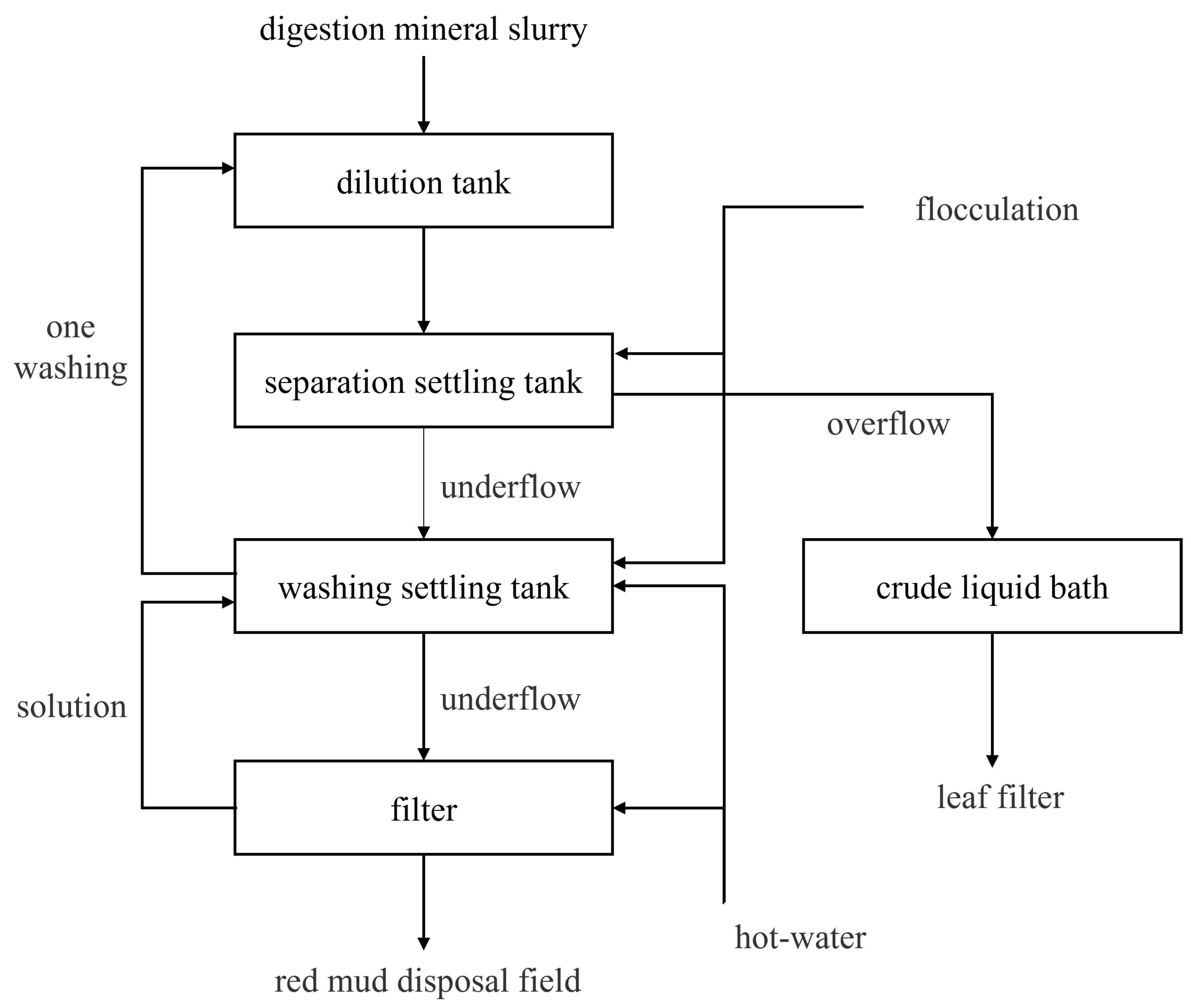
3. Data Preprocessing
3.1. Data Collection and Determination of Associated Variables
3.2. Outlier Determination and Missing Value Padding
3.3. Data Normalization
4. Result and Discussion
4.1. The Result of the Model Prediction
4.2. Evaluation of Performance Indication
4.3. Model Performance Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, C.; Wang, K.; Wang, Y.; Yuan, X. Learning Deep Multimanifold Structure Feature Representation for Quality Prediction with an Industrial Application. IEEE Trans. Ind. Inform. 2022, 18, 5849–5858. [Google Scholar] [CrossRef]
- Yuan, X.; Gu, Y.; Wang, Y.; Yang, C.; Gui, W. A Deep Supervised Learning Framework for Data-Driven Soft Sensor Modeling of Industrial Processes. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4737–4746. [Google Scholar] [CrossRef]
- Ren, L.; Meng, Z.; Wang, X.; Zhang, L.; Yang, L.T. A Data-Driven Approach of Product Quality Prediction for Complex Production Systems. IEEE Trans. Ind. Inform. 2021, 17, 6457–6465. [Google Scholar] [CrossRef]
- Perera, Y.S.; Ratnaweera, D.A.A.C.; Dasanayaka, C.H.; Abeykoon, C. The Role of Artificial Intelligence-Driven Soft Sensors in Advanced Sustainable Process Industries: A Critical Review. Eng. Appl. Artif. Intell. 2023, 121, 105988. [Google Scholar] [CrossRef]
- Curreri, F.; Patanè, L.; Xibilia, M.G. RNN- and LSTM-Based Soft Sensors Transferability for an Industrial Process. Sensors 2021, 21, 823. [Google Scholar] [CrossRef]
- Zhou, P.; Wang, X.; Chai, T. Multiobjective Operation Optimization of Wastewater Treatment Process Based on Reinforcement Self-Learning and Knowledge Guidance. IEEE Trans. Cybern. 2023, 53, 6896–6909. [Google Scholar] [CrossRef]
- Sun, Y.-N.; Qin, W.; Hu, J.-H.; Xu, H.-W.; Sun, P.Z.H. A Causal Model-Inspired Automatic Feature-Selection Method for Developing Data-Driven Soft Sensors in Complex Industrial Processes. Engineering 2023, 22, 82–93. [Google Scholar] [CrossRef]
- Yuan, X.; Li, L.; Shardt, Y.A.W.; Wang, Y.; Yang, C. Deep Learning with Spatiotemporal Attention-Based LSTM for Industrial Soft Sensor Model Development. IEEE Trans. Ind. Electron. 2021, 68, 4404–4414. [Google Scholar] [CrossRef]
- Ke, W.; Huang, D.; Yang, F.; Jiang, Y. Soft Sensor Development and Applications Based on LSTM in Deep Neural Networks. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Pan, H.; Su, T.; Huang, X.; Wang, Z. LSTM-Based Soft Sensor Design for Oxygen Content of Flue Gas in Coal-Fired Power Plant. Trans. Inst. Meas. Control 2021, 43, 78–87. [Google Scholar] [CrossRef]
- Hua, L.; Zhang, C.; Sun, W.; Li, Y.; Xiong, J.; Nazir, M.S. An Evolutionary Deep Learning Soft Sensor Model Based on Random Forest Feature Selection Technique for Penicillin Fermentation Process. ISA Trans. 2023, 136, 139–151. [Google Scholar] [CrossRef]
- Miettinen, J.; Tiainen, T.; Viitala, R.; Hiekkanen, K.; Viitala, R. Bidirectional LSTM-Based Soft Sensor for Rotor Displacement Trajectory Estimation. IEEE Access 2021, 9, 167556–167569. [Google Scholar] [CrossRef]
- Yuan, X.; Li, L.; Wang, Y. Nonlinear Dynamic Soft Sensor Modeling with Supervised Long Short-Term Memory Network. IEEE Trans. Ind. Inform. 2020, 16, 3168–3176. [Google Scholar] [CrossRef]
- Yan, W.; Tang, D.; Lin, Y. A Data-Driven Soft Sensor Modeling Method Based on Deep Learning and Its Application. IEEE Trans. Ind. Electron. 2017, 64, 4237–4245. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Koopialipoor, M.; Marto, A.; Yagiz, S. Application of Several Optimization Techniques for Estimating TBM Advance Rate in Granitic Rocks. J. Rock Mech. Geotech. Eng. 2019, 11, 779–789. [Google Scholar] [CrossRef]
- Liao, Z.; Pan, H.; Fan, X.; Zhang, Y.; Kuang, L. Multiple Wavelet Convolutional Neural Network for Short-Term Load Forecasting. IEEE Internet Things J. 2021, 8, 9730–9739. [Google Scholar] [CrossRef]
- Wang, X.; Hu, T.; Tang, L. A Multiobjective Evolutionary Nonlinear Ensemble Learning with Evolutionary Feature Selection for Silicon Prediction in Blast Furnace. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 2080–2093. [Google Scholar] [CrossRef] [PubMed]
- Yuan, X.; Huang, B.; Wang, Y.; Yang, C.; Gui, W. Deep Learning-Based Feature Representation and Its Application for Soft Sensor Modeling with Variable-Wise Weighted SAE. IEEE Trans. Ind. Inform. 2018, 14, 3235–3243. [Google Scholar] [CrossRef]
- Nkulikiyinka, P.; Yan, Y.; Güleç, F.; Manovic, V.; Clough, P.T. Prediction of Sorption Enhanced Steam Methane Reforming Products from Machine Learning Based Soft-Sensor Models. Energy AI 2020, 2, 100037. [Google Scholar] [CrossRef]
- Arhab, M.; Huang, J. Determination of Optimal Predictors and Sampling Frequency to Develop Nutrient Soft Sensors Using Random Forest. Sensors 2023, 23, 6057. [Google Scholar] [CrossRef]
- Wan, Y.; Liu, D.; Ren, J.-C. A Modeling Method of Wide Random Forest Multi-Output Soft Sensor with Attention Mechanism for Quality Prediction of Complex Industrial Processes. Adv. Eng. Inform. 2024, 59, 102255. [Google Scholar] [CrossRef]
- Balakrishnan, R.; Geetha, V.; Kumar, M.R.; Leung, M.-F. Reduction in Residential Electricity Bill and Carbon Dioxide Emission through Renewable Energy Integration Using an Adaptive Feed-Forward Neural Network System and MPPT Technique. Sustainability 2023, 15, 14088. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input variables | |||||
| Number | Variable | Unit | Number | Variable | Unit |
| 1 | Grinding AO | t | 5 | Circulating mother liquor Rp | % |
| 2 | Grinding Si | t | 6 | Feed solid content | |
| 3 | Dissolution temperature | 7 | Dissolution Rp | % | |
| 4 | Circulating mother liquor flow rate | ||||
| Target variable | |||||
| Number | Variable | Unit | Number | Variable | Unit |
| 1 | Red mud aluminum–silicon ratio | % | |||
| Model | MAPE/% | RMSE/% | MAE | |
|---|---|---|---|---|
| Linear | 0.0237 | 0.03455 | 0.02634 | 0.0672 |
| SVR | 0.0153 | 0.02201 | 0.01705 | 0.6023 |
| GRU | 0.0117 | 0.01664 | 0.01291 | 0.7800 |
| RF | 0.0036 | 0.00908 | 0.00397 | 0.9344 |
| TPRF | 0.0015 | 0.00378 | 0.00162 | 0.9893 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, F.; Shi, Z.; Song, Y. The TPRF: A Novel Soft Sensing Method of Alumina–Silica Ratio in Red Mud Based on TPE and Random Forest Algorithm. Processes 2024, 12, 663. https://doi.org/10.3390/pr12040663
Meng F, Shi Z, Song Y. The TPRF: A Novel Soft Sensing Method of Alumina–Silica Ratio in Red Mud Based on TPE and Random Forest Algorithm. Processes. 2024; 12(4):663. https://doi.org/10.3390/pr12040663
Chicago/Turabian StyleMeng, Fanguang, Zhiguo Shi, and Yongxing Song. 2024. "The TPRF: A Novel Soft Sensing Method of Alumina–Silica Ratio in Red Mud Based on TPE and Random Forest Algorithm" Processes 12, no. 4: 663. https://doi.org/10.3390/pr12040663