Bird Droppings Defects Detection in Photovoltaic Modules Based on CA-YOLOv5


Abstract
1. Introduction
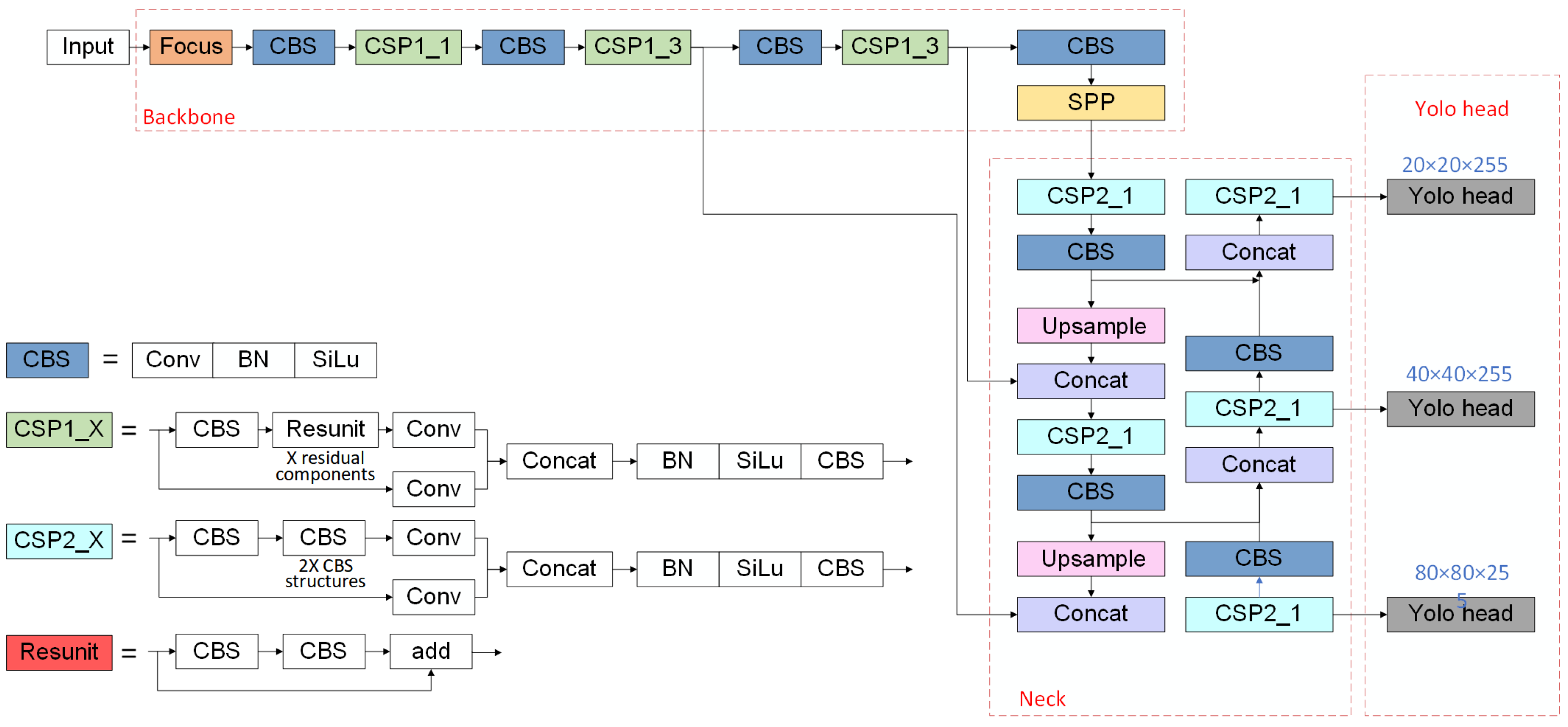
2. YOLOv5 Network Model Introduction
3. Improved CA-YOLOv5 Algorithm
- Coordinate Attention is added to the Backbone network to enable the model to process specific parts of the feature map more accurately to improve the capability of feature extraction and, thus, the accuracy of the network model.
- Add a new small target detection layer to the original network structure and integrate the location information of the shallow network with the semantic information of the deep network to enhance the multi-scale target detection capability of the network structure and improve the accuracy of small target detection.
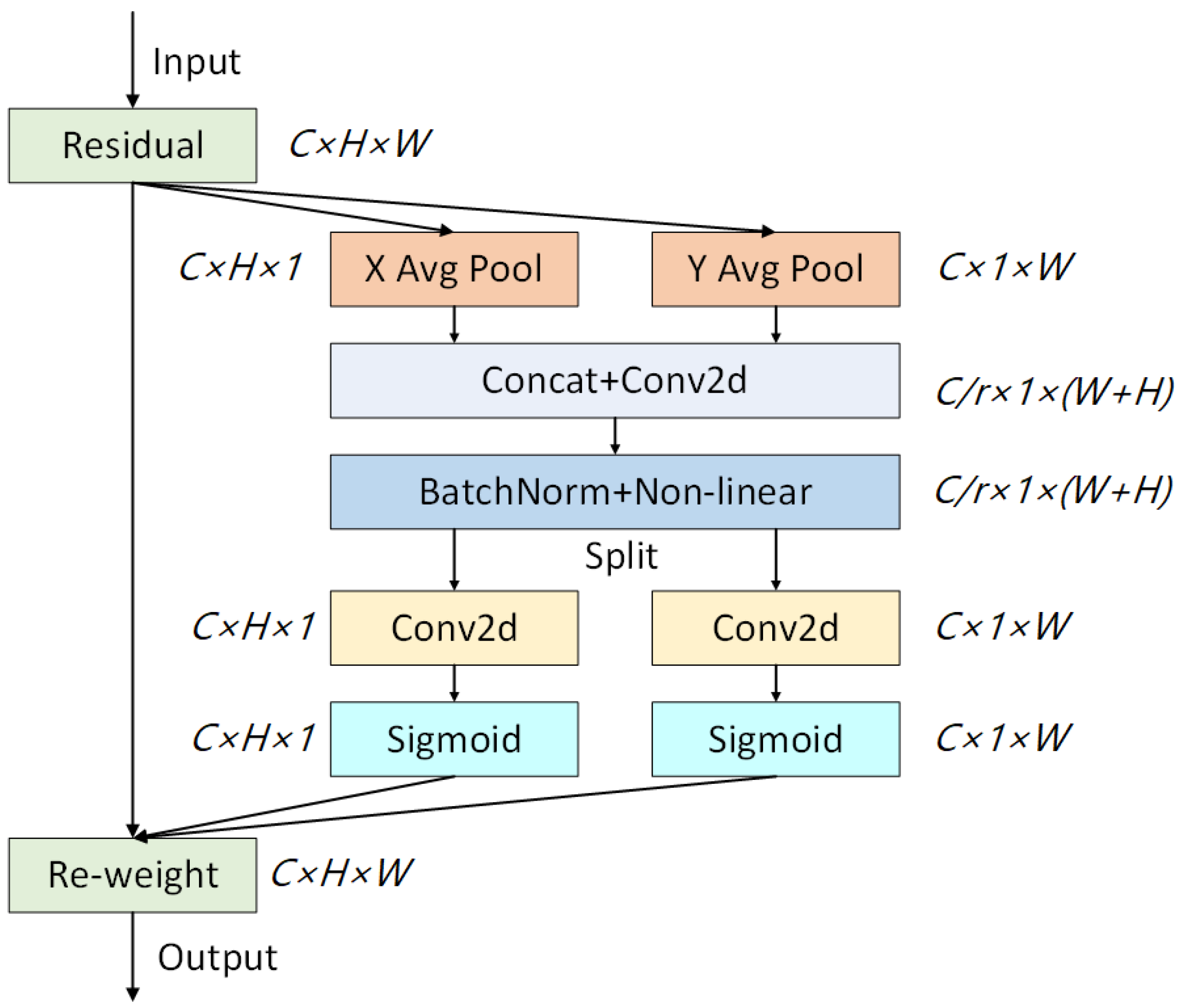
3.1. The Coordinate Attention Module
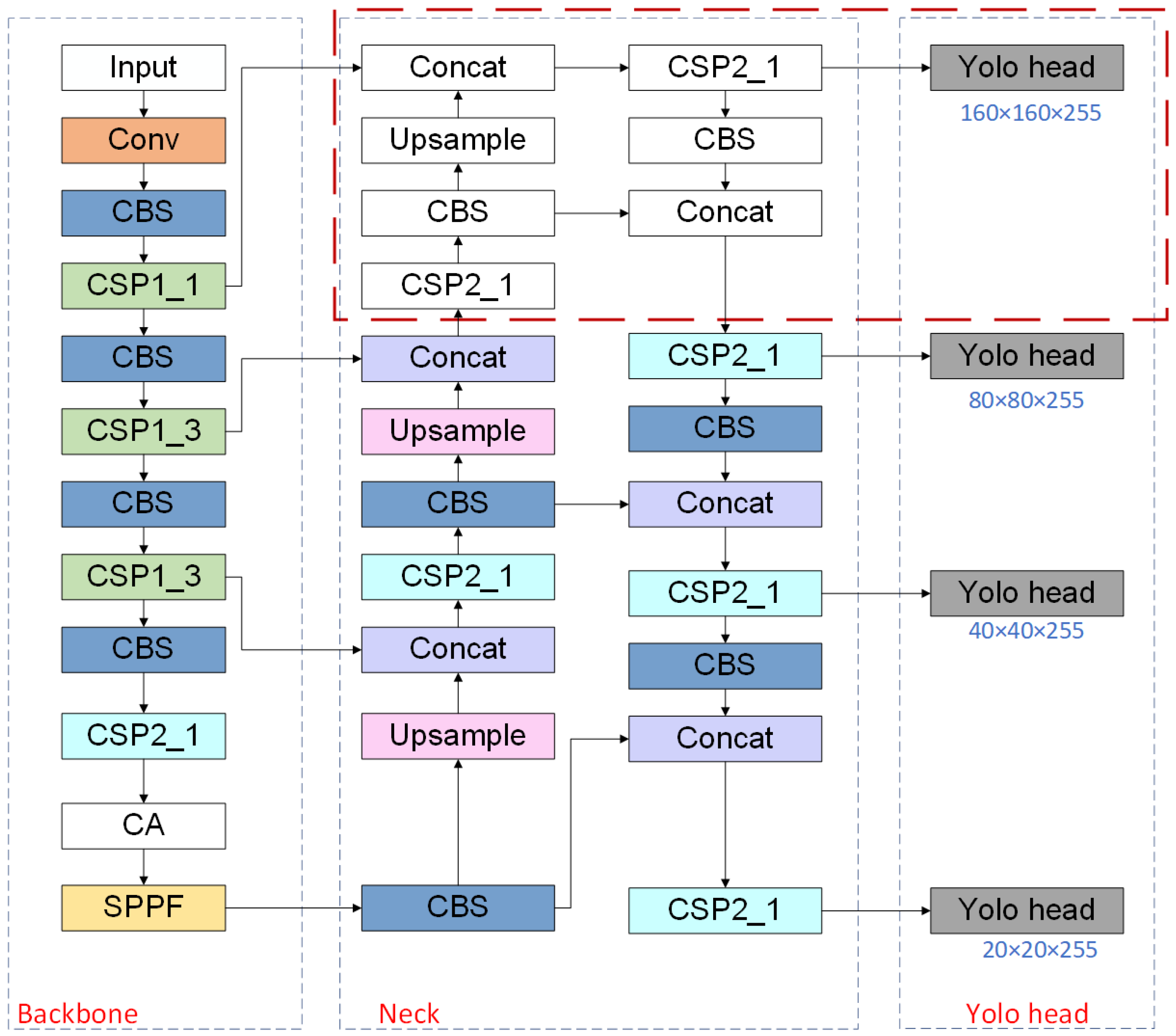
3.2. Multi-Scale Small Target Detection Layer
4. Methodology
- Data processing stage
- Data set collection. The appropriate UAV equipment and camera were selected to collect image data from the photovoltaic site, and a total of 457 photovoltaic picture data from different locations and different illuminations were collected. Post-processing of the captured photos, including flipping, rotating, adjusting color, adjusting contrast, and other operations, was carried out to obtain better image effects. The photovoltaic module pictures collected are shown in Figure 6. The main type of surface defect is bird droppings.
- Data set production. After screening the collected photovoltaic image data, a total of 433 images with photovoltaic module defects were selected. Due to the small number of images collected, it is necessary to preprocess the photovoltaic data and expand the photovoltaic data set. In this paper, batch cropping of these photovoltaic data was carried out, and each image was cut into quarters on average, and a total of 1729 photovoltaic module images were obtained.
- Data set labeling. The LabelImg tool was used to screen and mark 1729 pictures after cutting. The marked pictures of photovoltaic modules are shown in Figure 7. A total of 842 defective photovoltaic module images were screened out, and a category of bird droppings-related defects was created to mark all the bird droppings-related defects in the photovoltaic module images. The program was written to modify the format of all marked data sets and randomly divide them according to the proportion of the training set 80%, test set 10%, and verification set 10%, of which 674 were in the training set, 84 were in the verification set, and 84 were in the test set.
- 2.
- Model training stage
- After the Mosaic operation at the input end, images were clipped, scaled, and then randomly distributed for Mosaic to enrich the data set.
- After data are output from the input, a feature map of size 320 × 320 × 64 is output through a layer of convolution.
- After several CBS and CSP structures, the feature mapping of the base layer is divided into two parts first, and then they are combined through the cross-stage hierarchy to output the feature maps of different scales, respectively.
- Through a layer of Coordinate Attention, the location information is embedded into the feature vector so that the network can obtain a wider range of features.
- Using the SPPF structure to serialize inputs through multiple MaxPool layers of 5 × 5 size and concatenate outputs.
- After the FPN and PAN stages, a small target detection layer is added in the modified feature fusion stage, and the feature maps of four scales are output.
- The upper layer output features are finally input to the detection head for specific image detection, and the target box is filtered by NMS to obtain the prediction box.
- 3.
- Model testing stage
5. Results
5.1. Evaluation Index
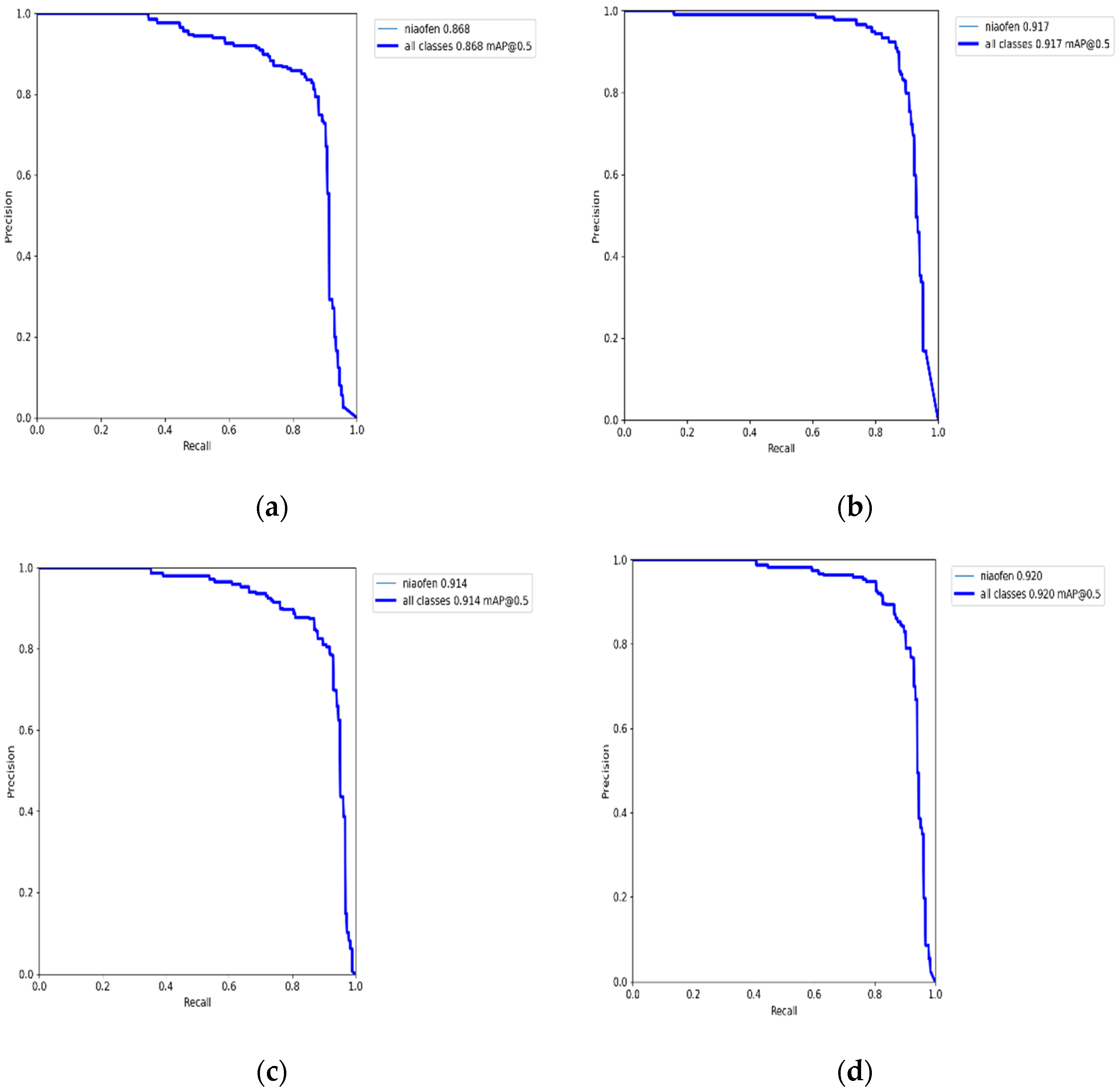
5.2. Ablation Study
6. Discussion
6.1. Comparison Experiment
6.2. Algorithm Effect and Analysis
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shi, Y.; Dai, F.; Yang, C. Defect detection of solar photovoltaic cells. J. Electron. Meas. Instrum. 2020, 34, 157–164. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; IEEE: New York, NY, USA, 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision–ECCV 2016: Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Mandi, India, 16–19 December 2017; IEEE: New York, NY, USA, 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; IEEE: New York, NY, USA, 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern. Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Kong, S.; Xu, Z.; Lin, X.; Zhang, C.; Jiang, G.; Zhang, C.; Wang, K. Infrared thermal imaging defect detection of photovoltaic modules based on improved YOLO v5 algorithm. Infrared Technol. 2023, 45, 974–981. [Google Scholar]
- Chen, W.; Jia, X.; Zhu, X.; Ran, E.; Xie, H. Object detection in UAV aerial image based on DSM-YOLO v5. Comput. Eng. Appl. 2023, 59, 226–233. [Google Scholar]
- Xie, L.; Zhu, W.; Xie, K.; Xiao, S. EL defect image detection model of photovoltaic cell based on improved YOLOv5s. Foreign Electron. Meas. Technol. 2023, 42, 93–102. [Google Scholar]
- Yu, J.; Jia, Y. Improved small target Detection Algorithm of YOLOv5. Comput. Eng. Appl. 2019, 59, 201–207. [Google Scholar]
- Guo, L.; Liu, Z. Defect detection of photovoltaic modules based on improved YOLOv5. Adv. Laser Opto Electron. 2019, 60, 148–156. [Google Scholar]
- Wang, Y.; Gao, R.; Li, M.; Sun, Q.; Li, X.; Hu, X. Defects detection of photovoltaic modules based on YOLOv5 LiteX algorithm. Acta Sol. Energy Sin. 2023, 44, 101–108. [Google Scholar]
- Zhou, Y.; Ye, H.; Wang, T.; Chang, M. Defects identification of photovoltaic modules based on multi-scale CNN. Acta Sol. Energy Sin. 2022, 43, 211–216. [Google Scholar]
- Yan, H.; Dai, J.; Gong, X.; Wu, Y.; Wang, J. Defect detection of photovoltaic panel based on multi-source image fusion. Infrared Technol. 2023, 45, 488–497. [Google Scholar]
- Tian, H.; Zhou, Q.; He, C. Photovoltaic modules defect detection based on multi-scale feature fusion. Comput. Eng. Appl. 2023, 60, 340–347. [Google Scholar]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for small object detection. arXiv 2019, arXiv:1902.07296. [Google Scholar]
- Chen, J.; Wang, X. Improved YOLOv5 UAV Aerial Image Dense small target Detection Algorithm. Comput. Eng. Appl. 2019, 60, 100–108. [Google Scholar]
- Song, P.; Chen, H.; Gou, H. Improved UAV target Detection Algorithm based on YOLOv5s. Comput. Eng. Appl. 2019, 59, 108–116. [Google Scholar]
- Luo, X.; Liu, Y.; Chu, G.; Pu, H. UAV Image Object Detection Algorithm Based on Improved YOLOv5. Radio Eng. 2023, 53, 1528–1535. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Net works for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 936–944. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: New York, NY, USA, 2018; pp. 8759–8768. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: New York, NY, USA, 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Zhou, M.; Tang, Q.; Shi, T.; Luo, T.; Zhang, Z.; Xue, Y. Rail Surface Crack detection Algorithm based on improved YOLOv5s. Chin. J. Liq. Cryst. Disp. 2019, 38, 666–679. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Coordinate Attention | The Small Target Detection Layer | P | R | mAP@.5 | Model Size |
|---|---|---|---|---|---|---|
| YOLOv5s | × | × | 0.836 | 0.859 | 0.868 | 14.4 MB |
| YOLOv5s+CA | √ | × | 0.924 | 0.864 | 0.917 | 15.4 MB |
| YOLOv5s+Detect | × | √ | 0.874 | 0.87 | 0.914 | 16.3 MB |
| CA-YOLOv5s | √ | √ | 0.893 | 0.864 | 0.92 | 16.1 MB |
| Model | Parameter | P | R | mAP@.5 | Model Size |
|---|---|---|---|---|---|
| YOLOv3 | 61497430 | 0.854 | 0.891 | 0.905 | 123.5 MB |
| YOLOv3-tiny | 8666692 | 0.924 | 0.858 | 0.902 | 17.4 MB |
| YOLOv3-spp | 62546518 | 0.89 | 0.837 | 0.898 | 125.6 MB |
| YOLOv5s | 7012822 | 0.836 | 0.859 | 0.868 | 14.4 MB |
| YOLOv5m | 20852934 | 0.892 | 0.853 | 0.905 | 42.2 MB |
| YOLOv5l | 46108278 | 0.888 | 0.864 | 0.909 | 92.8 MB |
| YOLOv5n | 1760518 | 0.895 | 0.788 | 0.873 | 3.9 MB |
| YOLOv5x | 86173414 | 0.881 | 0.848 | 0.902 | 173.1 MB |
| CA-YOLOv5s | 7599256 | 0.893 | 0.864 | 0.92 | 16.1 MB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, L.; Li, Q.; Liao, X.; Wu, W. Bird Droppings Defects Detection in Photovoltaic Modules Based on CA-YOLOv5. Processes 2024, 12, 1248. https://doi.org/10.3390/pr12061248
Liu L, Li Q, Liao X, Wu W. Bird Droppings Defects Detection in Photovoltaic Modules Based on CA-YOLOv5. Processes. 2024; 12(6):1248. https://doi.org/10.3390/pr12061248
Chicago/Turabian StyleLiu, Linjun, Qiong Li, Xu Liao, and Wenbao Wu. 2024. "Bird Droppings Defects Detection in Photovoltaic Modules Based on CA-YOLOv5" Processes 12, no. 6: 1248. https://doi.org/10.3390/pr12061248
APA StyleLiu, L., Li, Q., Liao, X., & Wu, W. (2024). Bird Droppings Defects Detection in Photovoltaic Modules Based on CA-YOLOv5. Processes, 12(6), 1248. https://doi.org/10.3390/pr12061248