Abstract
Recent advancements in image processing and machine-learning technologies have significantly improved vehicle monitoring and identification in road transportation systems. Vehicle classification (VC) is essential for effective monitoring and identification within large datasets. Detecting and classifying vehicles from surveillance videos into various categories is a complex challenge in current information acquisition and self-processing technology. In this paper, we implement a dual-phase procedure for vehicle selection by merging eXtreme Gradient Boosting (XGBoost) and the Multi-Objective Optimization Genetic Algorithm (Mob-GA) for VC in vehicle image datasets. In the initial phase, vehicle images are aligned using XGBoost to effectively eliminate insignificant images. In the final phase, the hybrid form of XGBoost and Mob-GA provides optimal vehicle classification with a pioneering attribute-selection technique applied by a prominent classifier on 10 publicly accessible vehicle datasets. Extensive experiments on publicly available large vehicle datasets have been conducted to demonstrate and compare the proposed approach. The experimental analysis was carried out using a myRIO FPGA board and HUSKY Lens for real-time measurements, achieving a faster execution time of 0.16 ns. The investigation results show that this hybrid algorithm offers improved evaluation measures compared to using XGBoost and Mob-GA individually for vehicle classification.
1. Introduction
In modern times, swift progression is occurring with remarkable consequences in the vehicle manufacturing industry. Currently, automobiles in these industries are produced with different intensities, designs, and external factors, which have a huge impact on VC [1,2]. Especially during congested traffic conditions, vehicle mobility monitoring is a serious task in cases of traffic violations, toll plaza monitoring, and missing vehicle tracking. Variations in illumination, occlusion, imperfect detection, camera position, and its properties have powerful consequences on effective classification [3,4]. Machine learning (ML) algorithms resolve these issues, helping us to recognize meaningful features in image classification. These algorithms are robust in real-world situations, since they are used in decision support systems. Differentiating subordinate images through visual categories is very difficult, and the issue is addressed by a subset of ML algorithms using Convolutional Neural Networks (CNNs) [5,6]. Similarly, the imbalanced data are classified using high-level global descriptors. Along with the CNN, the transfer learning process is included for VC, which provides more training efficiency and a prediction accuracy of 98% [7,8]. Vehicle image segmentation, identification, location, and classification are performed based on ML algorithms. These algorithms learn from the features, which help in image classification.
The automatic localization of vehicles provides calculation by avoiding error-prone and manual methods, which are the conventional approaches [9,10]. Nonlinearity and variable interdependency are also considered by ML algorithms. Unsupervised learning uses unlabeled data to make predictions, while supervised learning builds a model using labeled data (target) to predict the output value for a new set of data. The most commonly used supervised algorithms are Artificial Neural Networks (ANNs), Support Vector Machines (SVMs), Discriminant Analysis (DA), Naive Bayes (NB), Random Forests (RFs), decision trees (DTs), and K-Nearest Neighbors (KNNs) [11,12,13]. The selection of a suitable ML algorithm is of prime importance in solving the difficult task of finding a solution to a given classification problem [14,15]. The selection of network/model parameters, such as the input, target, size of the training dataset, and regularization parameters, determines the performance of the ML algorithm. In intelligent transportation systems, the use of ML algorithms has greatly contributed to enhancing the accuracy of the detection and classification of vehicles. Figure 1 illustrates the general block diagram of VC.
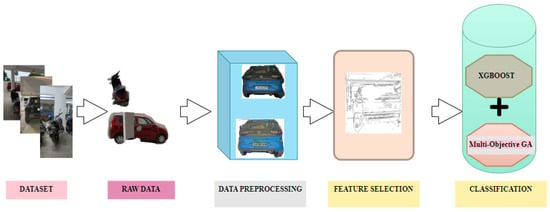
Figure 1.
General block diagram for vehicle classification using machine learning.
2. Related Work and Problem Description
The major steps of the supervised learning technique are feature extraction, representation, and classification for automatic vehicle detection processes [16,17]. The classifier algorithms allocate labels to the data to be classified and transform them into determined data. These classifiers are utilized for VC under varying factors like shape, color, and environment. The heights and the number of axles for different classes of vehicles were classified using various classifiers like RFs, SVMs, XGBoost, and CatBoost [18,19]. Using roadside sensors, vehicles were classified using a linear regression (LR) classifier, with an average accuracy rate of 93.4% [20,21]. The stumbling blocks in the LR classifier include a low bias and high variance. Similarly, by employing the velocity of the automobiles, vehicles were classified with an accuracy of 75% using the Naive Bayes classifier [22,23]. In the case of the KNN classifier, only cars were identified and localized, with an accuracy of 84% [24,25]. The major drawback of this classifier is that its accuracy relies on the quality of the data. In the case of the SVM classifier, Gabor extraction was utilized for feature extraction and the SVM was utilized for VC [26,27].
The improper background complexities of VC were easily handled by this classifier, with an accuracy of 87.67% [28,29]. With the help of the acoustic signal of the vehicle, the vehicle was classified using GA optimization along with the SVM classifier, achieving a classification accuracy of over 70% [30,31]. The pitfall of this classifier is its inability to handle a huge dataset. However, a huge dataset can be handled by an RF classifier for classifying vehicles. The Random Forest classifier can evaluate missing data and provide accurate values [32,33]. Two stages of the Random Forest classifier were incorporated for autonomous parking [34,35]. Similarly, decision trees are also prone to noise and were used for both the regression and classification of vehicle images [36,37]. Another classifier, the ANN, validated the response of the prediction over the categories of vehicles, ranging from medium to high [38,39]. Among the different kinds of vehicles, it is tough to identify a particular one from massive traffic. To solve this issue, the most prevalent method practiced in the area of ML is attribute selection. It nominates a subset of attributes with a strong correlation to minimize the dimensionality of the dataset from the original one. The term attribute is otherwise known as a feature.
Generally, a dataset contains high-dimensional problems. To overcome this problem and also to boost the classification performance, the attribute-selection method is essential. In recent years, the most frequent methods carried out for attribute selection were the ensemble, filter, wrapper, and embedded techniques. These methods are used as preprocessing techniques to remove or eliminate unwanted attributes, which are free from repeated learning rates. The classifier is trained with the examined properties of the data. The correlation between the classes and attributes, along with analytical details of the training periods, are utilized to estimate the performance of the attribute subset. In the modern era, filter methods like t-tests, f-tests, and regression measures are used. The induction algorithm is used to investigate the attribute subset with the help of the wrapper technique. The wrapper method is considered to provide better classification performance. During classifier training, the objective function is optimized to select attributes using the embedded technique. Embedded techniques are independent of the loop partitioning of trained datasets into subcategories. Since there is no need for an iterative training processes, the selection of optimal attributes is performed faster. Even dual stages of attribute selection are experimented with. At first, the hybrid method is utilized, which combines all of the top attributes, followed by the genetic algorithm for the hyperparameters.
As mentioned, the filter and wrapper methods are widely used for attribute-selection techniques. There are various hybrid attribute-selection methods depending on the filter and wrapper methods utilized for improving the accuracy of the model. Moreover, the investigation based on embedded design is deficient. Since XGBoost is an enhancement of gradient decision trees, it has tremendous advantages in attribute selection. XGBoost focuses on calibrating model training, which can also be applied to the attribute selection. This algorithm is also useful for the evaluation of clustering and resampling data [40,41]. Similarly, XGBoost could handle tedious conditions and various pharmaceutical data to meet the basic requirements of a fast time diagnosis prediction, with greater accuracy in the classification [42,43]. Heart disease was predicted using an optimized XGBoost algorithm with an accuracy of 94.7% [44,45]. A hybrid method, principal component analysis (PCA) with XGBoost, was used for the classification of coal gangue with a 98.33% accuracy rate [46,47]. Vehicles were classified using XGBoost and CatBoost [48,49] with statistical features. Few tasks have been performed on attribute selection and classification in vehicle datasets, and those that have mainly concerned the XGBoost and genetic algorithms.
To be more accurate in risk prediction, several selection methods are used to enhance the interpretability, facilitate easy modeling, reduce the learning time, and improve the generalization. PCA and GA were implemented to train vehicle door failure classification with an accuracy of 99.8% [50,51]. Deep neural network evolution was used as a model for VC with a 78% accuracy. However, it had limitations, such as inflexible linkage levels, resulting in only minimal accuracy for the prediction assessment [52,53]. The paper by [54] proposed a hybrid attribute-selection algorithm combining the deep CNN and GA to reduce unwanted attributes across eight different classes. The major drawback of this paper was the limited dataset, considering only 8000 images. From the literature survey, it is observed that maximum label considerations, slow training processes, and imprecise vehicle classifications are common issues. Hence, in this paper, a hybrid attribute-selection method is performed using XGBoost and a Multi-Objective Genetic Algorithm, named XGBoost-MOB-GA, to address the stated problems. This procedure initially ranks the primary attributes based on XGBoost, eliminating low-range parameters and acquiring the initial attributes. Consequently, the attained attribute subset is processed using the MOB-GA to acquire the ideal attribute subset. Depending on both attribute-selection procedures, the ideal attribute subset can be nominated from the real dataset. An equivalence and evaluation of the investigation results substantiate the merits of XGBoost-MOB-GA in terms of numerous parameters and computation times, improving the classification performance. In all of the above-stated methods, identifying the optimal number of selected attributes as a framework is necessary. Each is energized by the potential of XGBoost for attribute selection and the universal exploration potential of the genetic algorithm. From the outcome of this analysis, hybrid attribute selection is proposed to select the attributes of vehicle divisions from large surveillance vehicle datasets. The major contribution of this research work is the consideration of minimal labels from a huge dataset to classify vehicles more precisely.
The structure of this paper is organized as follows: Section 3 summarizes the postulates of XGBoost and MOB-GA in detail. Section 4 presents the implementation of a hybrid algorithm on 10 publicly accessible vehicle datasets. Section 5 presents the experiment and result analysis of the large datasets. Section 6 includes the conclusion of the work.
3. Materials and Methodology
In this section, the hybrid vehicle attribute-selection technique named XGBoost-MOB-GA is initially put forward. Section 3.1 and Section 3.2 offer the postulation of XGBoost-MOB-GA consecutively.
3.1. eXtreme Gradient Boosting Algorithm
XGBoost (eXtreme Gradient Boosting) is a gradient boosting algorithm widely used in ML for huge datasets to achieve the performance of classification and regression [20,21,22]. Its library is written in the C++ language. Decision trees are generated in the subsequent structures and weights are added to autonomous variables, which are fed as inputs to the decision trees to provide the prediction results. Wrongly predicted weighted variables have increments in the tree and are given to the second decision tree. This unique classifier is structured as an ensemble to produce an efficient model. The regularization of the objective function depends on real factors that will limit the overfitting and regulate the convergence. XGBoost is highly advantageous over other algorithms in attribute selection. These algorithms can easily select the most relevant attribute at the beginning of the selection process. The unknown attributes are categorized based on the predicted and determined parameters. The given dataset is considered in the form of dimensions. These CART (Classification and Regression Tree) sets are produced in the form of decision trees. The sample map is given to the leaf node of the organized tree. The node count and score are then noted, which need to be arranged into an optimal model so to detect its own factors. These models are then used for the XGBoost modeling. The objective function contains the errors and complexities of the model, which are expressed as follows:
In Equation (1), the term () is the deviation of the square loss function with the real and predicted values. Similarly, indicates the regularization term. α and β express the difficulties in the co-efficient of the splitting tree for the tree formation and to reduce the overfitting issues. Once the iteration is completed, the predicted value can be given by the following:
The objective function is expressed as follows:
The loss function relies on Taylor’s formula, with a higher convergence rate and a higher accuracy than real decision trees. The final objective function is manifested as follows:
Equation (5) evaluates the nodes and minimizes the loss function.
3.2. Multi-Objective Genetic Algorithm
A genetic algorithm (GA) is a chronic adaptive technique that provokes an issue so to clear up the genetic development method. Afterward, it creates another generation solution via duplication, crossover, and mutation, which minimizes the fitness value. Generally, the GA is used for attribute extraction [55,56]. The GA is also used to concurrently find various spot data. The purpose of this investigation is to avoid the iteration of spot dropping into a neighborhood ideal solution. Mob-GA is relatively more able to solve optimization issues than other algorithms. Under its unique code, the input data are encoded in the form of discrete and floating-point data formats.
Lastly, the vehicle dataset values are in discrete and binary forms, where the parallel encrypting successions are obtained. But, in this paper, several attributes were organized for various attributes acquired in the first stage of the attribute selection through the XGBoost algorithm. Fitness was individually calculated with huge value probabilities for the forthcoming generation existence. Using the Mob-GA technique, the fitness value was manipulated. The distance, average, and classification methods can be designated with the Mob-GA processes for attribute selection. The embedded method was implemented for the classification achievement used for fitness purposes. In the KNN classification model, the patterns’ fitness values were calculated by the following:
where P represents the patterns, t is the pattern label, and acc shows the accuracy. Mob-GA utilizes attribute selection with probability for the next existence and Darwin’s theory of survival of the fittest. A fitness-proportionate selection method was performed to select individuals randomly. The fitness function was allotted to the favorable solutions, in which each scheme N of individuals was selected out of the offspring population. The process was repeated until the original population size was recovered. Following the selection operation, the crossover was carried out. In this paper, Davi’s order (OX1) crossover method was implemented to form two new individuals based on the crossover probability.
To enrich the variation (having different patterns) of the population and the potential to flee from local optima, random bit flipping was used. Initially, particular individuals were arbitrarily nominated from the population. In this encoding process, the one bit flip in the heterozygote completely transferred the classification in a phenotype form. This process was executed since the Mob-GA processes are low. Under the termination state, the maximum iteration was implemented to conclude the algorithm. Similarly, when the bottom-most boundary was computed, with the advancement outreach variation, the algorithm was also concluded; even with no more changes in the solution, the execution was stopped. To attain the maximum label achievement, the first method was implemented.
3.3. eXtreme Gradient Boosting Algorithm and Multi-Objective Genetic Algorithm-Based Hybrid Algorithm
In the architecture of the ML prototype for building the model selection of specific factors, the neural network and kernel parameters instantaneously have influence in the accuracy and generalization of the model. Attribute selection is the predominant method used in the establishment of the model, which is unable to store data and represent the accurate real data. Ensemble learning is the most important task for the classification, since it needs to combine the models most productively. The factors which affect the attribute selection for the image classification are the segmentation of attributes with a low speed, as more attributes need to be considered, the greater execution time, difficulty in handling the objectives, constraints, encoding, scaling, the unreliability of estimation, metric non-availability, handling large datasets, missing values, low performance, and the accuracy of the classification. These listed factors are overcome by the XGBoost and Mob-GA-based hybrid algorithm. A detailed explanation of this hybrid algorithm is presented in the forthcoming section.
4. Implementation of the Hybrid Algorithm Using eXtreme Gradient Boosting Algorithm and Multi-Objective Genetic Algorithm-Based Hybrid Algorithm
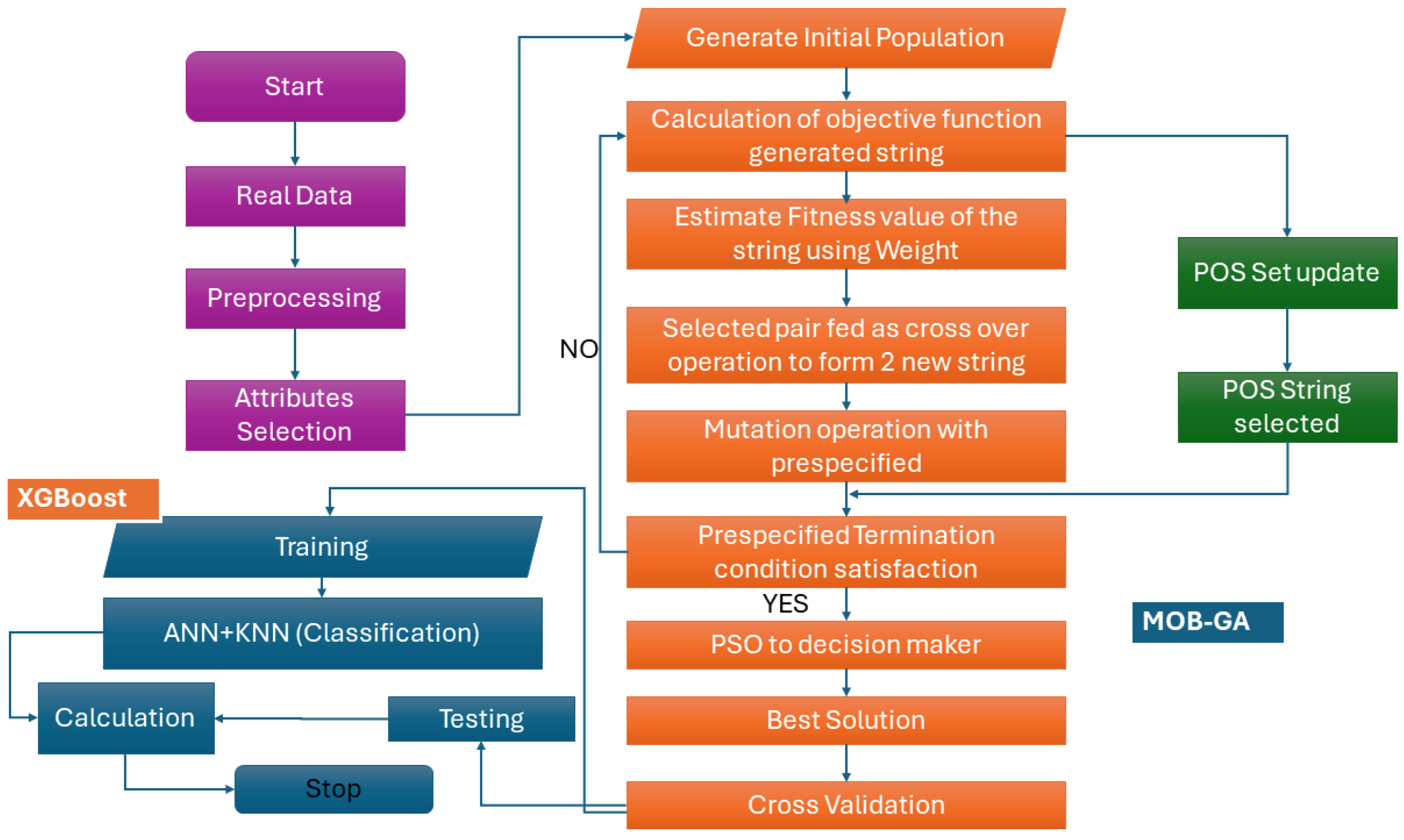
In this phase, a dual-phase attribute-selection method, eXtreme Gradient Boosting merged with the Multi-Objective Genetic Algorithm, namely, XGBoost-Mob-GA for VC in vehicle datasets, is proposed. The schematic flow diagram of the hybrid XGBoost and Mob-GA is presented in Figure 2. In the initial phase, the label is categorized through XGBoost, and a score greater than zero retains the labels. This phase can detach unwanted labels and combine them with those most pertinent to the class. In the second phase, XGBoost-Mob-GA finds the most pertinent group for the optimal label subset by using Mob-GA.
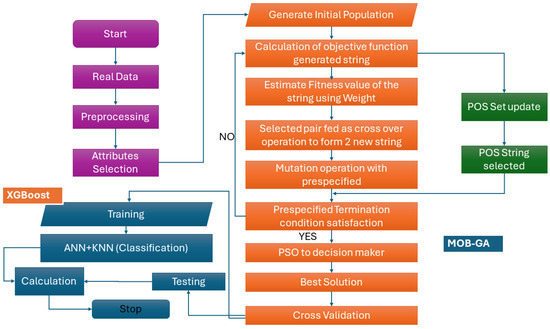
Figure 2.
Flowchart for vehicle classification using XGBoost and Mob-GA.
This further brings out the superfluous label while still extending the VC. In Algorithm 1, the XGBst() function computes the score of each label, similarly to the pn() function, thus building the embryonic population. In Table 1, we provide the parameter settings of XGBoost and Mob-GA, respectively. Prior to the training process, a few hyperparameters were identified with definite values, and are utilized for the entire research work, as these hyperparameters play an important role in the vehicle selection outcome of XGBoost, as demonstrated in Table 1. Preceded by this, the XGBoost-Mob-GA computational complexity is explained.

Table 1.
Parameters of XGBoost and MOB-GA.
The time of the computational problem is based on the initial label selection and the identification of the optimum subset of the label. In the case of the label selection, the logarithmic of the label is taken with respect to the samples and similarly, while the second computational problem is calculated by an embedded method based on iteration and the population size from the label subset. For the vehicle dataset, the sample size will be smaller when compared to the label and its population size. XGBoost, Python, the sci-kit-feature, and learn are the publicly available software products and languages utilized for the implementation of the hybrid Mob-GA classification algorithm.
| Algorithm 1: eXtreme Gradient Boosting and Multi-Objective Genetic Algorithm |
| input: A(B1, B2, B3, B4 …. Bn, C) output: Afinest initialize a variable with an arrays chromosome is zero B-significance is equivalent to XGBst(A) for(int i = 0; i < n; i++) if B-significance[i] > 0 increase feature i into initialize data chromosome increased by the variable 1 finest population with the array of variable finest–score are same as variable of array for(int j = 0; j < recurrence; j++) Initialize the population which is equal to pn(Initialize data, c) Sum initialize of population into finest population Initialize variable-score = ANN + KNN–fitness (initialize population) Add initialize variable-score into finest-score If (initialize variable–score ≥ allotted variable-score) Or Select = fitness candidate crossover () mutation () initialise population of crossover (), mutation (), chromosome Outcome = maximum (finest-score) Afinest = finest population of outcome return Afinest |
5. Experiments
The experiments were performed on the suggested procedure to authenticate the performance. The dataset is essential for the experimental investigation, and the VC procedure, the similarities in the attribute-selection methods, the outcome, and the analysis are furnished in this section. The developed hybrid Mob-GA algorithm was run on a personal computer outfit with a corei7-12600K and 3.7 G of memory.
5.1. Datasets
The experiment was conducted on 10 publicly accessible vehicle datasets, along with the real data shown in Figure 3. The properties of the 10 vehicle datasets include the number of attributes, samples and multi-classes. The number of attributes ranged from 1000 to 50,456, and the number of samples was 4250. The dataset of the comp cars contained a tri-class dataset, while the rest of the datasets were binary. In some of the vehicle datasets containing multi-classes and particular cases, the attributes were binary with misplaced data. The vehicle dataset contained lost data, and some of the interposed data were incorporated to sort out the issue of misplaced data. In this paper, attribute scaling was carried out to restore the lost data. Each sample of lost data was assigned by attribute scaling in the training phase. Once the lost value was refined, the advanced systematized data were captured to route the second data value (0, 1).

Figure 3.
Collection of different publicly accessible vehicle datasets (A–J) utilized for the training and testing of the real data (K).
5.2. Hardware/Software Experimentation
The experiments were performed with a double classifier including various archetypes, i.e., K-Nearest Neighbors (KNNs) and Artificial Neural Networks (ANNs), to estimate the selected attributes for each attribute-selection method. Subsequently, the 10-fold cross-validation for the classification output was monitored. XGBoost, Python, the ssci-kit-feature, and learn were the publicly available software products and languages utilized for the classification algorithms. In this paper, the KNN classifier was used to find the class of an image based on weighted frequency analysis; hence, it is a parametric-less classifier. The ANN classifier is a disbursed collateral processor which contains three layers. Depending on the weight and biases, the input and the output were recorded. The efficiency was calculated by the mean square error (MSE). Based on various metrics, it provides different outputs. There were various evaluation measures employed based on the accuracy (Ac), F1 score (Sc), precision (Pr), and recall (Re) [57,58]. An identical weight was added to each class in the multi-classification issue to compute the above measures.
5.2.1. Software Experimentation
The average value of the measure is the final outcome. To impose the performance of the classification algorithm, KNN and ANN classifiers were used. A 10-fold cross-validation was performed with the classifiers on different labels to produce a moderate outcome. The components of XGBoost-Mob-GA were compared to authenticate the persuasiveness of the combination. In addition to this, the different attribute-selection approaches were nominated to determine the merit of this hybrid method. The number of labels was selected by three different methods. With the reference, the number of labels was taken from the original dataset. The number of labels adopted in this work was lower when compared to the prototypical dataset [18].
5.2.2. Hardware Experimentation
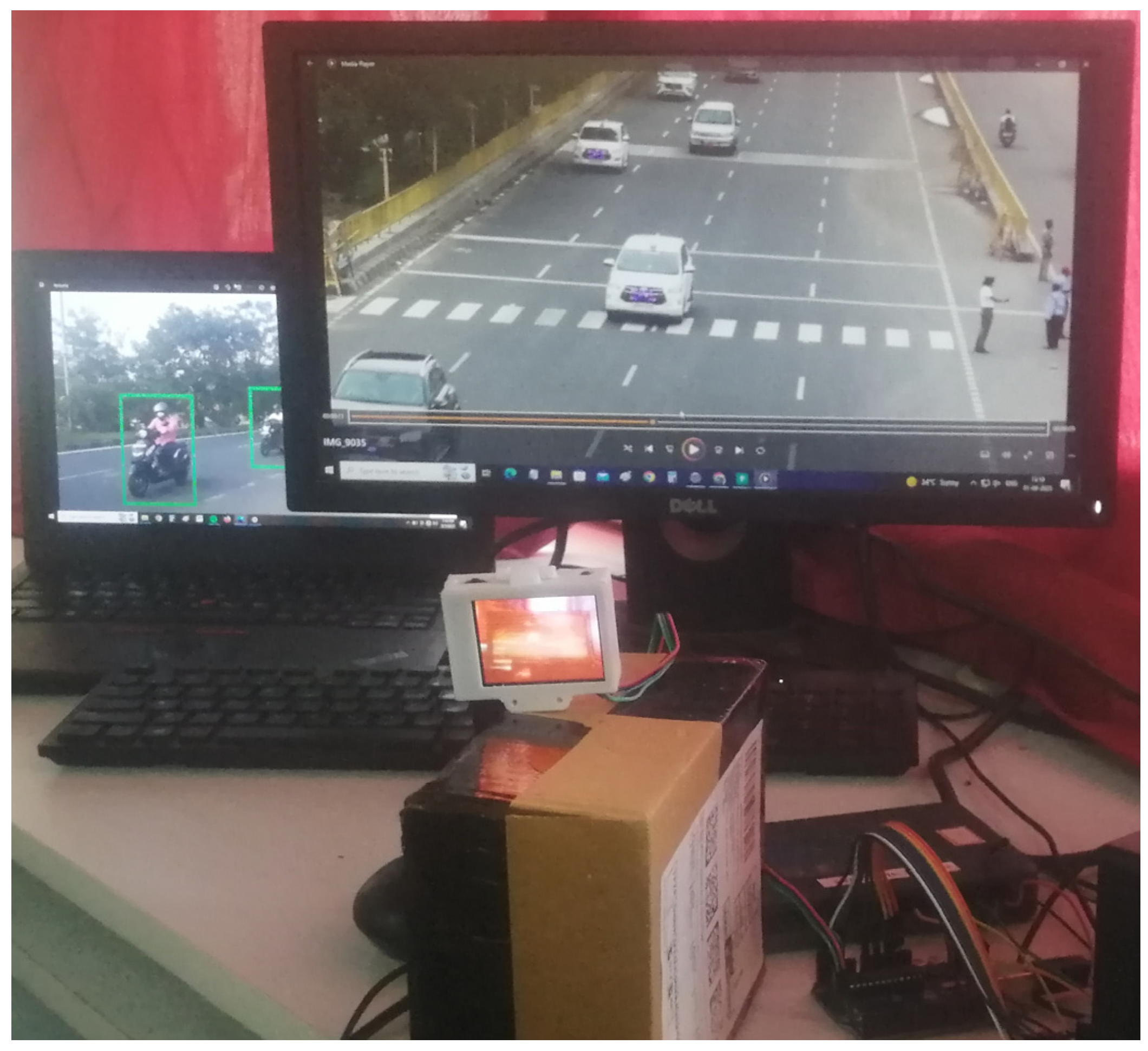
XGBoost opts for fewer labels from the raw dataset. XGBoost-Mob-GA was chosen for its low number of labels when compared to the individual algorithms [40]. In Figure 4, the vehicle is classified under various conditions using the hybrid algorithm with a given experimental setup. Then, in each and every experiment, an average of the outcomes was attained for the huge dataset computation in order to perform an easy comparison. The experiment was carried out, including the FPGA implementation, using the myRIO board to sense the color and track the vehicle images in complex environments. The specifications include a Xilinx Z-7010 processor with a frequency of 667 MHz and a non-volatile memory of 256 MB, and a double data rate third generation (DDR3) of 512 MB with a frequency 533 MHz and containing 16 bits. Figure 5 shows the final prototype of the XGBoost and MOBGA classifier implemented on the myRIO board. In addition, the classification performance was calculated using receiver operating characteristic (ROC) analysis to validate the results, as shown in Figure 6. As depicted in Figure 7, the performance of the VC is defined.

Figure 4.
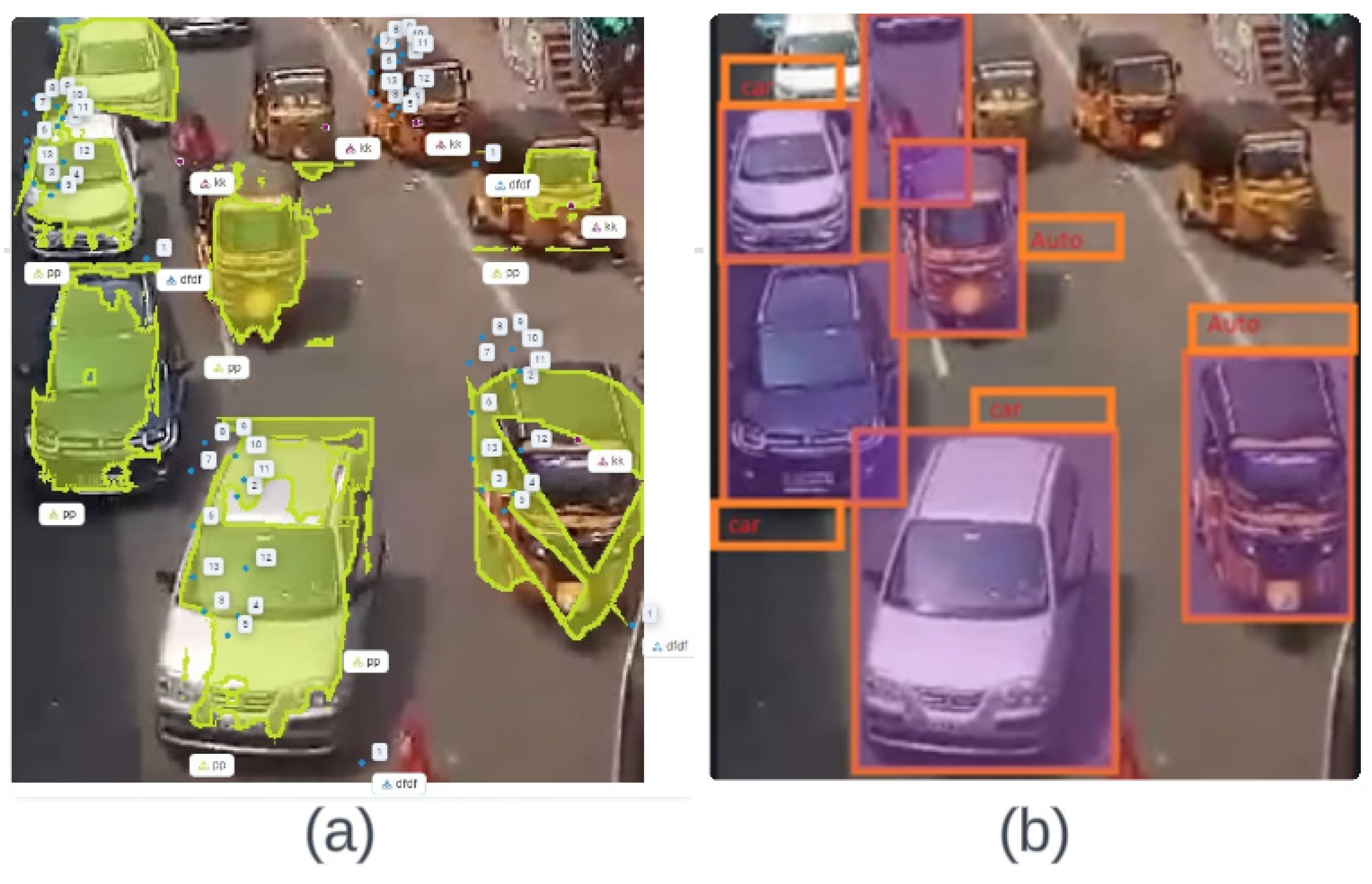
Classification of the vehicles using XGBoost and Mob-GA under various conditions: (a) fog; (b) cloudy; (c) dark.
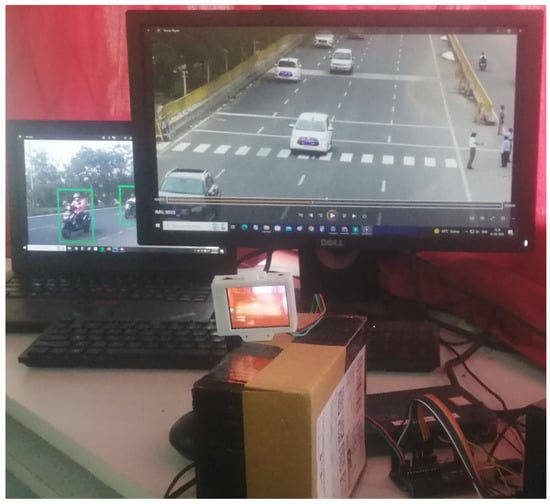
Figure 5.
Embedded processor package of the NI myRIO for the classification of vehicles.
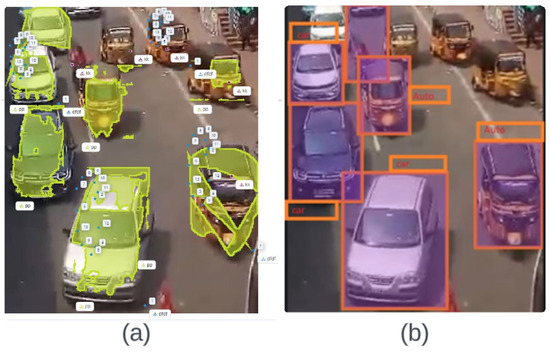
Figure 6.
Simulation output using Xilinx Z-7010 with the frequency of 667 MHz: (a) labels; (b) classes of the vehicles under a traffic environment.
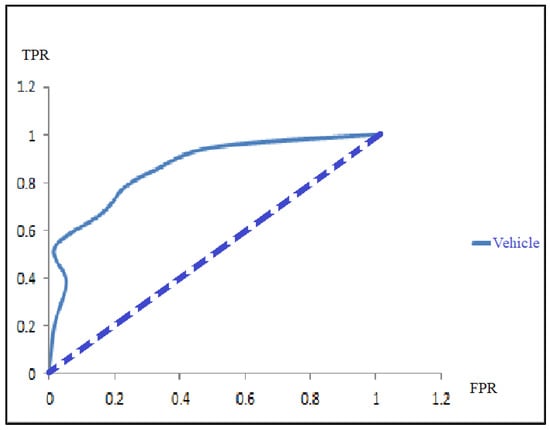
Figure 7.
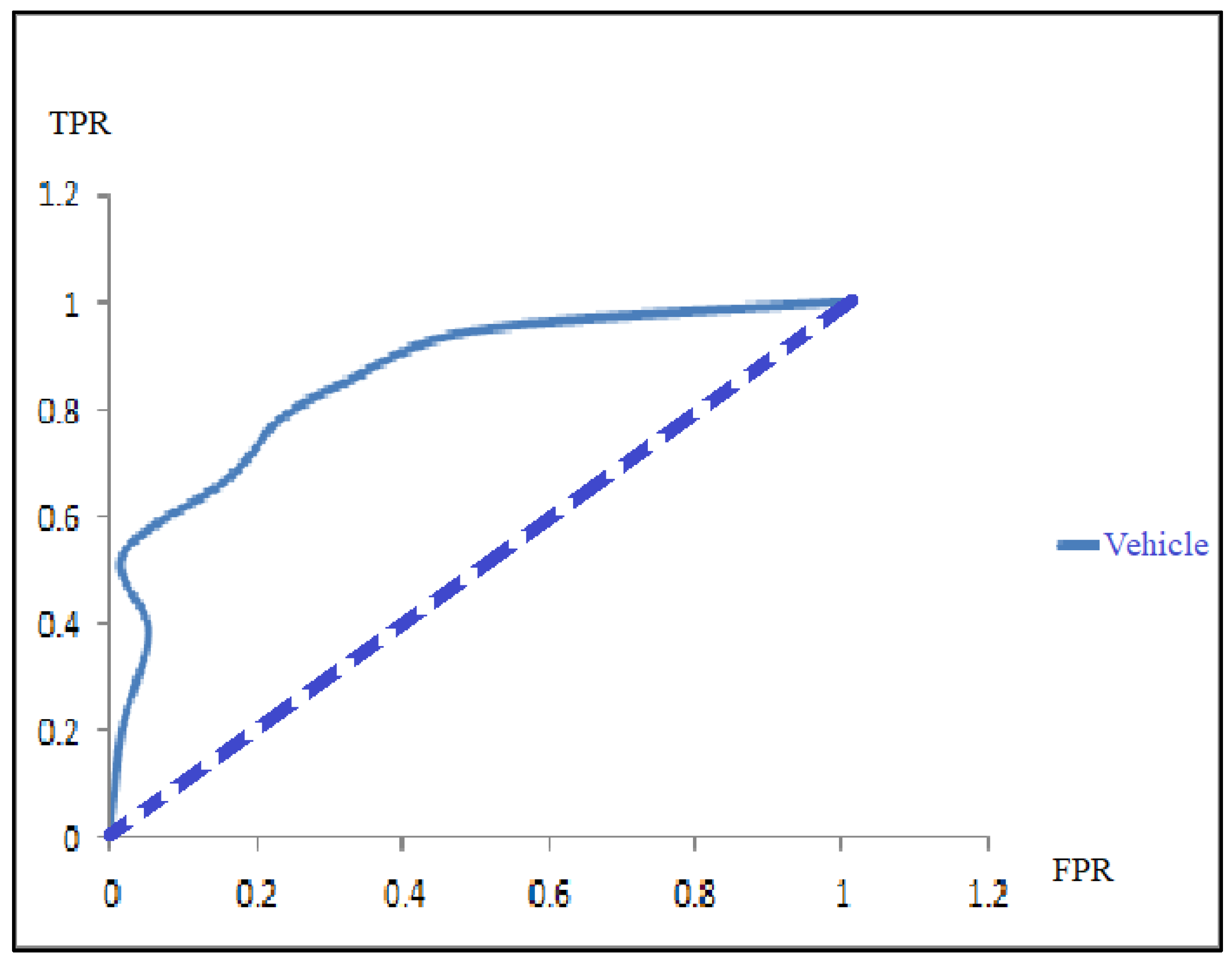
ROC curves based on the calculated preliminary array values using CDF.
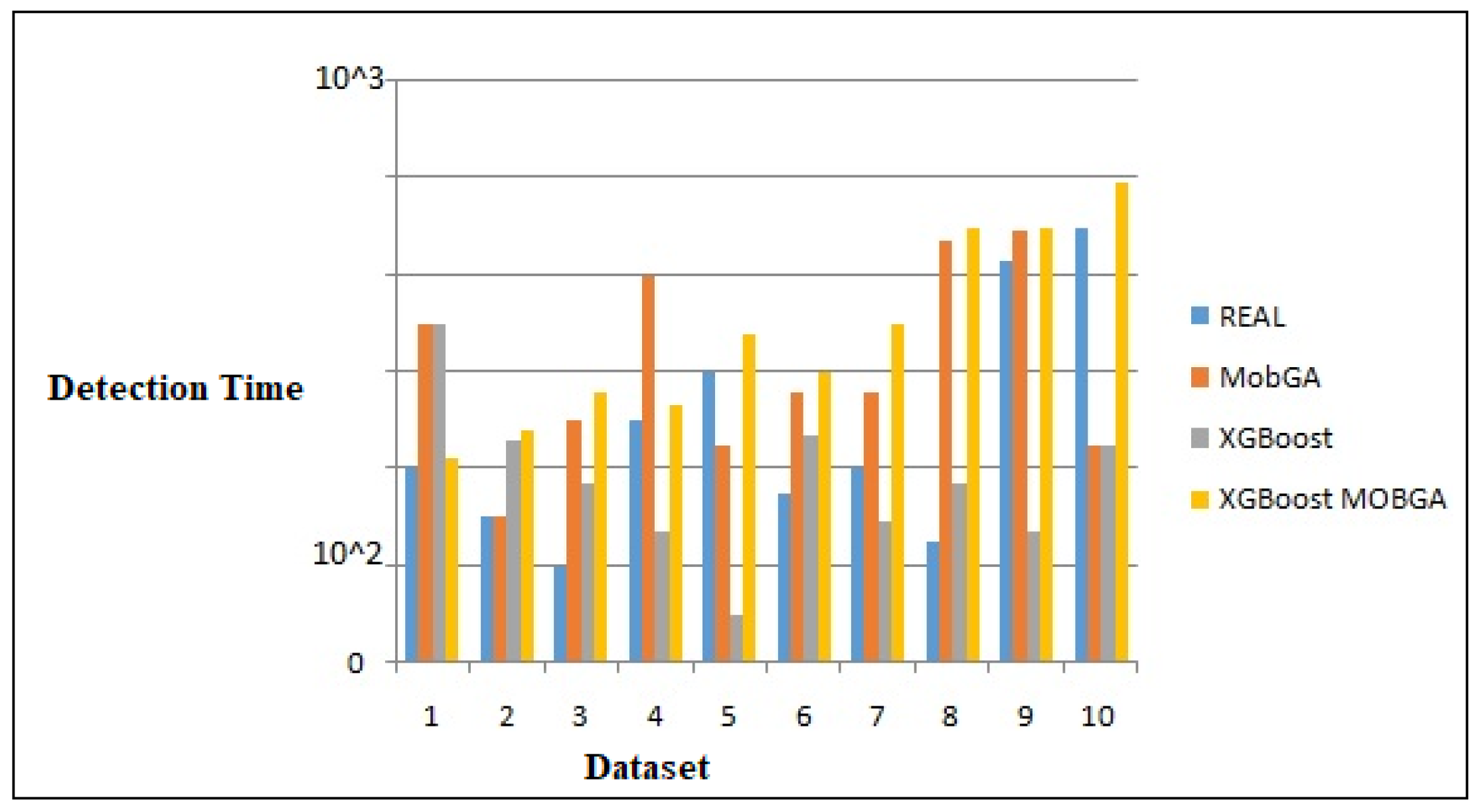
Table 2 shows the number of labels nominated by Mob-GA, XGBoost, and XGBoost-Mob-GA. The major purpose was to furnish the table with datasets in a way which was not sporadic, as these datasets were not highly focused in other studies. The Vehicle Re-identification (VeRi) dataset [59,60] was built for vehicle re-identification from an original surveillance scene, which was labeled with various attributes and which contains 50 k images captured from different camcorders covering a distance of 1 km. The sample of labeled parameters with spatiotemporal factors includes boxes of plates, strings of plates, and timestamps of different vehicles. In the case of the comprehensive cars (CompCars) dataset [61,62], it contains 1, 36,726 images of cars captured in a web and surveillance context.
Table 2.
Number of selected labels by the real data, XGBoost, Mob-GA, and XGBoost-MO-GA.
The labeled part includes boxes and viewpoints enclosing the attributes of the maximum speed, displacement, door and seat counts, and the types of cars. The VehicleX dataset [63,64] is a synthetic dataset containing 3D models with complete modifiable attributes of 1362 vehicles. This dataset includes all-inclusive real-world and re-identification data to reduce the problem complexity. The UFPR–ALPR [65,66] dataset includes 45,000 images that are completely annotated in real-world scenarios, with pixel sizes of 1920 × 1080, taken from go pro hero 4 silver, Huawei P9 Lite, and iPhone 7 plus equipment.
The labels of the portrayed attributes include the manufacturer, models and years of the cars and motorcycles, as well as the position, identification, and characters of the license plates (LP) of the vehicles. The Tsinghua–Tencent [67,68] dataset contains 100 K images with 30 K traffic signs. From these, 10 K images of vehicles are considered for our VC research work. Bounding boxes and pixel masks are considered for the labels of the attributes of the vehicles. In the Stanford car dataset [33], 16,185 images with 196 different classes of cars are accommodated. The makes, models, and years of the cars are considered as the labels, and the classes are equally spitted for the training and testing. For the testing, either the real data or the raw data were fed into the classifier.
In the TRANCOS dataset [69,70], 1244 images with 46,796 vehicles are annotated and captured from a CCTV system in Spain. The region of interest (ROI) of the road region identification, the location, and the count of the vehicles are illustrated. The Indian Vehicle dataset includes around 50 K images of Indian vehicles captured from both urban and rural areas, with pixel sizes of 1920 × 1080 and above. Only seven classes of vehicles are noted in this dataset. In our research work, out of the 50 K images, only 35 K images are considered for the VC. In the multi-view vehicle-type recognition (MVVTR) [71,72] dataset, seven major vehicle types and 4793 images are included, while 1000 images were chosen for the VC in our work. Up–left, up–right, down–left, down–right, center, and mirrored vehicles comprise the classification of vehicles as labeled parts in this dataset. The Vehicle–Rear [73,74] dataset contains 3 h of high-resolution surveillance video. Labels include the makes, models, colors, and years of the vehicles, and the accurate location and detection of LP information is also provided. Furthermore, the numbers of labels in the real dataset are given for reference. It was inferred that the number of labels opted by Mob-GA was less than half of the real dataset, while XGBoost [75,76] chose even fewer labels from the real dataset.
Table 3 postulates the average performances of the 10 publicly accessible datasets for the two classifiers based on the evaluation metrics. Furthermore, it displays a list of the proposed approaches and benchmark methods with detailed descriptions. Additionally, the performance of the KNN and ANN methods is also used as a comparison with our proposed method. In the proposed method, extensive experiments on publicly available large vehicle datasets—VeRi and VehicleX—have determined the superiority over the MVVTR dataset, with gain percentages of 44.44%, 58.67%, 58.79%, and 46.68% in the accuracy, F1 score, precision, and recall.
Table 3.
Number of selected labels by the real data, XGBoost, Mob-GA, and XGBoost-Mob-GA.
The MVVTR dataset has faced challenges due to the occlusion of the vehicles. This has led to minimum accuracy in vehicle classification. Compared with the real dataset, XGBoost, and Mob-GA, the proposed XGBoost-Mob-GA technique provides better results in terms of the accuracy, F1 score, precision, and recall in most of the criteria. The proportion of the hybrid algorithm has an optimal accuracy of 9/10 and 9/10 for the above-considered classifiers, respectively. Specifically, XGBoost-Mob-GA attained the prime performance on the KNN classifier. As shown in Table 3, XGBoost-Mob-GA achieved 100% on the five datasets of the KNN classifier based on four evaluation cases.
In the case of the XGBoost approach with the KNN classifier, three datasets gained a 100% classification performance. The performances of the VeRi and Vehicle X datasets reached 100% in the four methods based on the KNN classifier. XGBoost and XGBoost-Mob-GA equally achieved a 100% classification performance on the three and four datasets with the ANN classifier. The results of the four evaluation criteria demonstrate that XGBoost-Mob-GA performed the best, thereby validating the efficiency of XGBoost-Mob-GA.
In order to simulate the vehicle color extraction, a color extraction model was mounted on an NI myRIO. Figure 5 shows the hardware experimental setup with the NI myRIO package for the vehicle classification. The NI myRIO consists of a processor, the FPGA, software, and an I/O port. This system includes timing control with a high-performance I/O hardware circuit. After testing the good condition of the myRIO, the LabVIEW 2015 programming environment was used to identify the myRIO project to organize the particular algorithm using it as a virtual instrument. The color of the vehicles was the major attribute considered for the representation and tracking. The model had a computation speed of 0.16 ns. In the test environment, the vehicle images were captured under different illumination conditions such as dark, fog, etc. In Figure 6, the hardware simulation output is shown, where the attributes are displayed in the form of the nodes and types of the vehicles, which are portrayed with the evaluation metrics of each vehicle.
The results of the processes included populated arrays with different class test probabilities, denoting the true-positive rate and false-positive rate for the given vehicle dataset. Figure 7 depicts the ROC curve depending upon the calculated primary array values by means of the cumulative distribution function (CDF). For each iteration over a different value of the threshold, the ROC is formed. At the starting stage, the ROC is not generated due to the lack of the presence of minimum data points shifting from the original to the new array. Figure 7 shows the threshold value of 0.64 at the early iteration of the ROC curve, and both positive and negative arrays are less than 30.
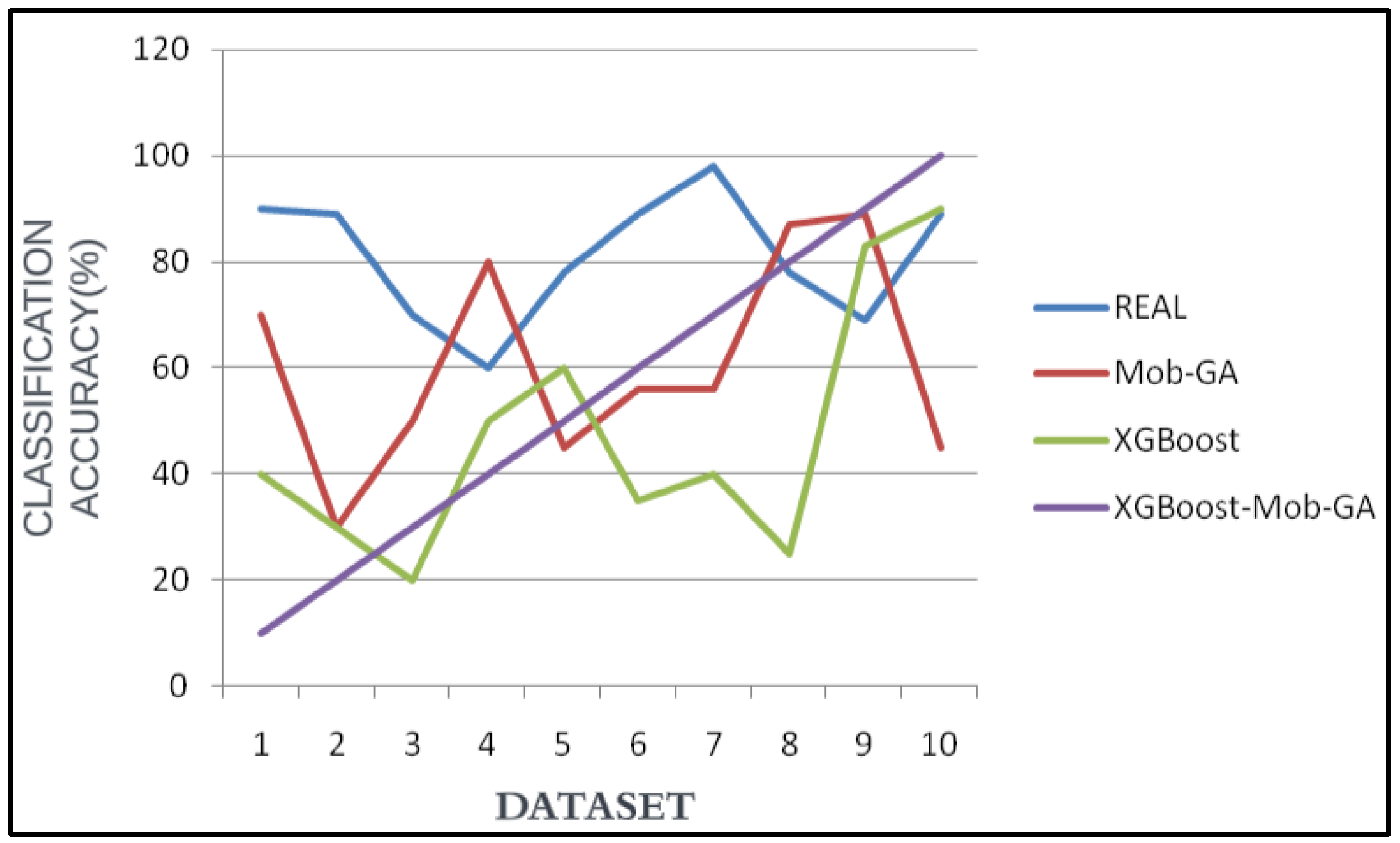
Figure 8 portrays the accuracy rates of each proposed technique concerning the various sizes of the vehicle images. Here, the output shows that XGBoost-Mob-GA has the highest accuracy rate of 99.8%. Mob-GA and XGBoost follow with an 80–89% accuracy. The accuracy rate is the same as the Python and hardware implementations on the FPGA. The results of the software implementation are provided directly. Although finding the best vehicle classification attribute value results is a crucial procedure, precautions should be taken with the interpretation of these outcomes when designing the hardware, because the architecture of the design of the attributes requires more pixels and consumes larger areas in the FPGA. Thus, the Xilinx used in the cases with complex architectures are unreal. The XGBoost–Mob-GA exceeds the LUT by up to 32 × 32 pixels in the KNN and ANN.
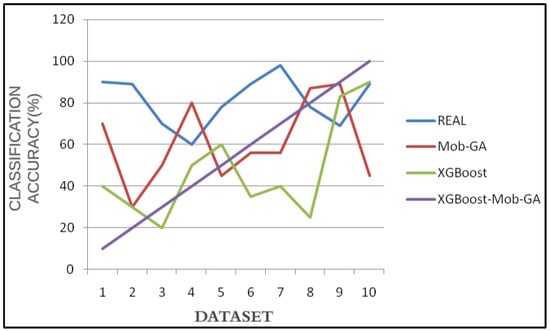
Figure 8.
Classification accuracy over 10 datasets based on different attributes.
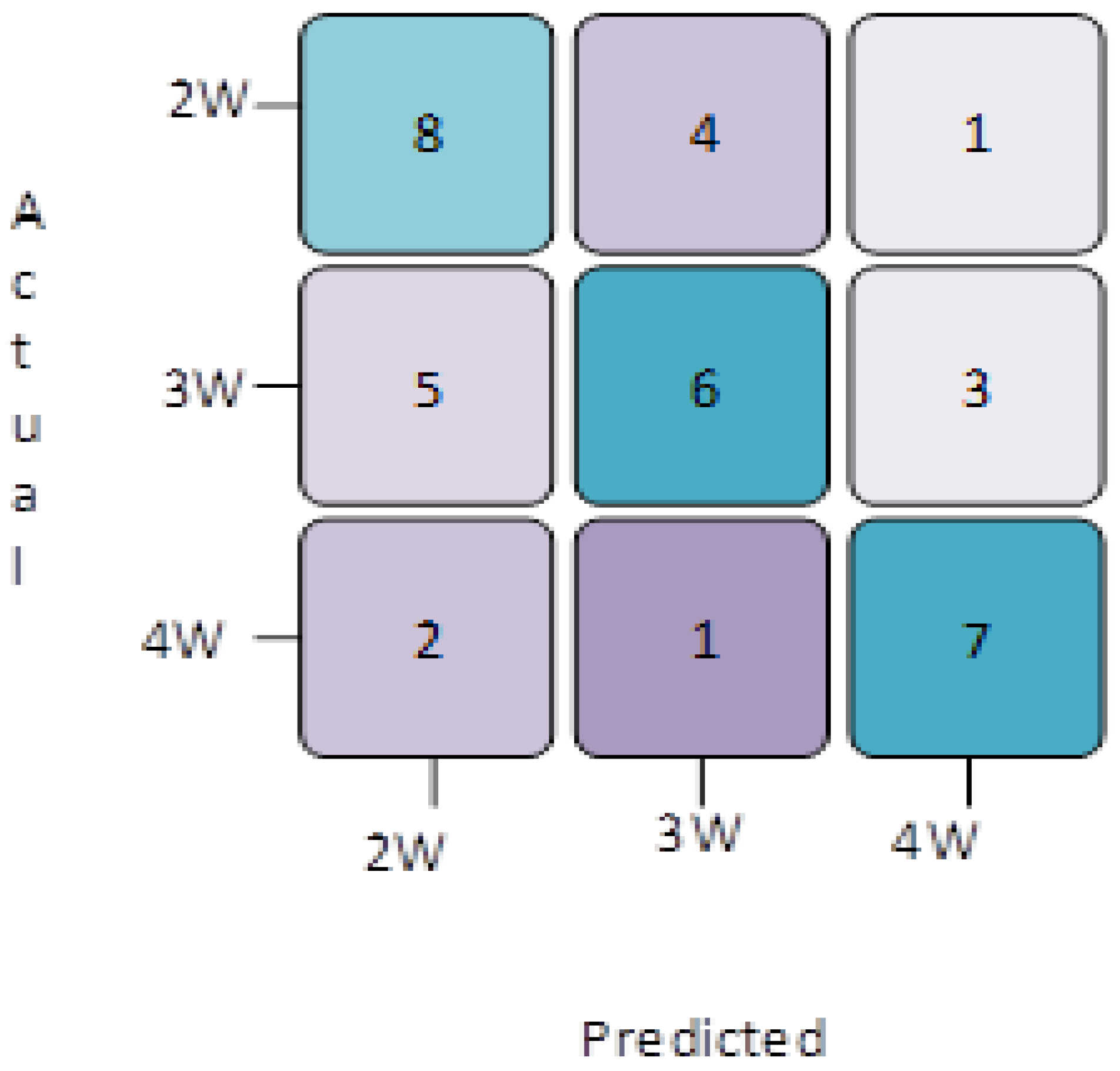
Similarly, the confusion matrix for the classification of the 2 W, 3 W, and 4 W vehicles of the AlexNet network are portrayed in Figure 9. The results in Figure 9 show that the texture and shape are easily predicted as the strongest matches by the network, which may be due to the confined labels of the images from the dataset. A total of 90% of the dataset was used for training, while the remaining 10% was used for testing the model; these testing models provide the accuracy rate of the utilization. A total of 203 general images and 537 vehicle images were used for testing. The results of the classification can be observed in the confusion matrix in the AlexNet models. As demonstrated by the comprehensive investigation of the classification metrics, the performance of the system is percipient, as shown in Figure 9.
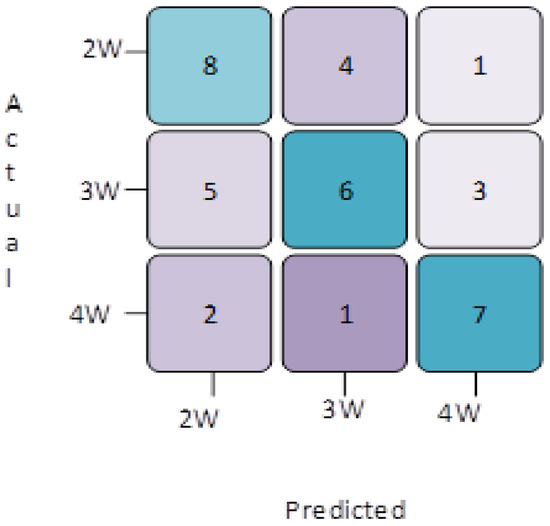
Figure 9.
Confusion matrices illustrating the vehicle classification based on the XGBoost and MOB-GA classifiers.
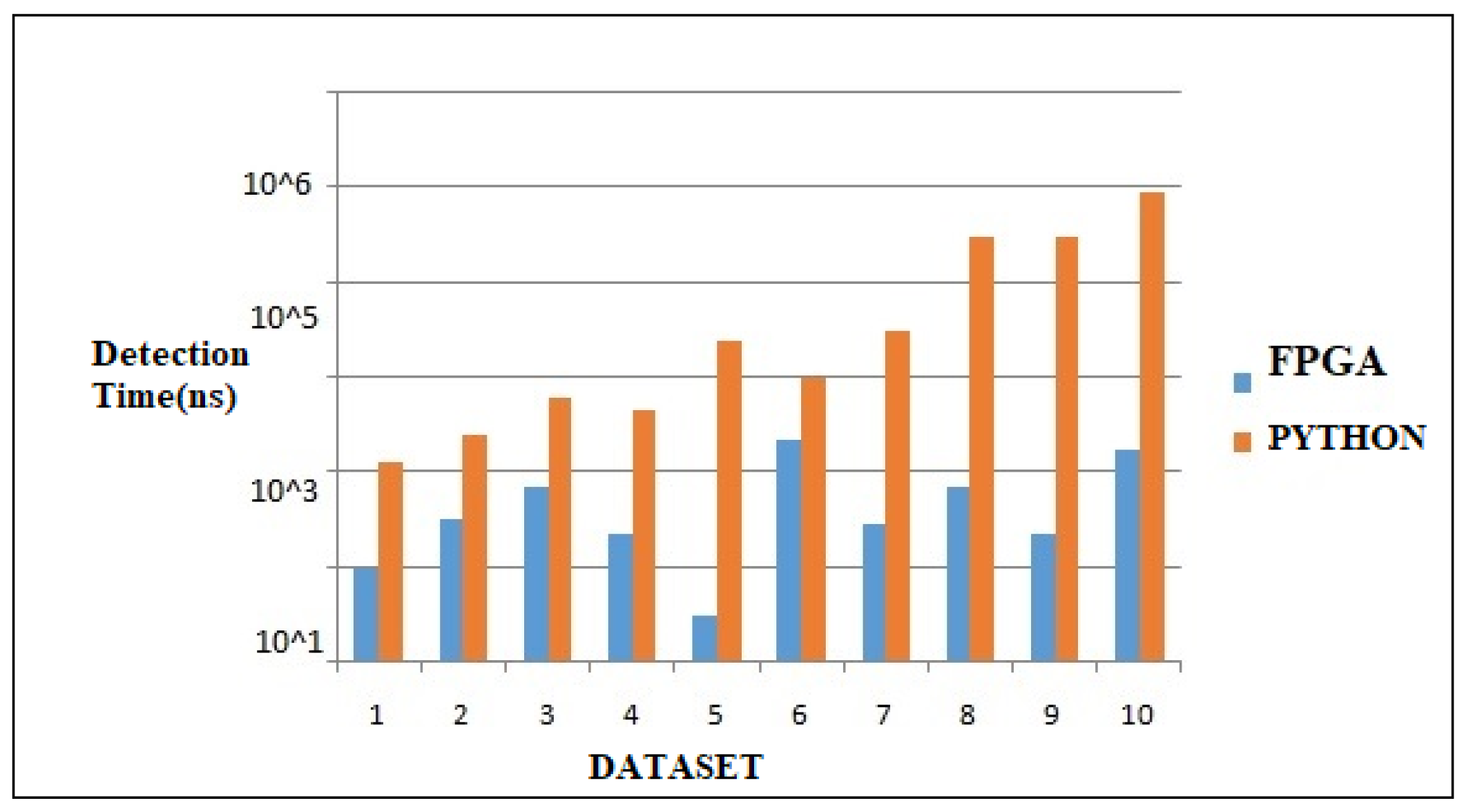
Figure 10 demonstrates the classification algorithm running times of the vehicle images on the software and hardware. The fastest hardware design is the KNN at 42.34 ns, followed by the ANN at 52.78 ns and XGBoost-Mob at 300.62 ns. The classifier time for detection in Python is 7834 ns, while for the KNN and for the ANN and decision tree, it is 62,535 ns. The most prominent analysis is that the classification algorithms implemented on the FPGA are quicker than Python. Figure 11 indicates the LUT limit on the FPGA for the design with the 8 × 8, 16 × 16, and 32 × 32 pixel attributes. The XGBOOST-MOB-GA gained highest accuracy percentage with the minimum pixel attribute of 8 × 8, whereas XGBoost and MOB-GA gained the highest accuracies with the 16 × 16 pixel attribute. Figure 12 indicates the stimulation results of the types of vehicles and evaluation metrics. Table 3 examines the XGBOOST-MOB-GA hardware design success in the LUT in detail.
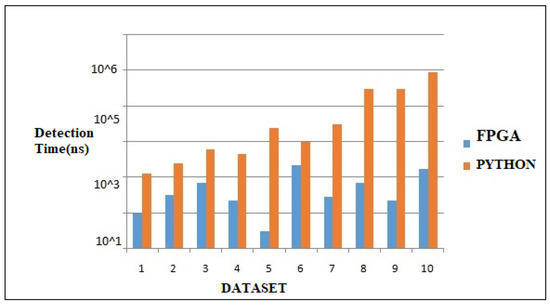
Figure 10.
Comparison of the detection times between the hardware and simulation.
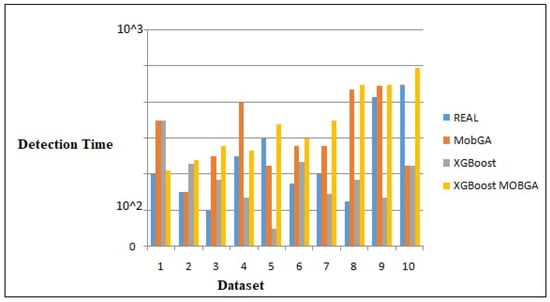
Figure 11.
Comparison of the detection times among different algorithms.
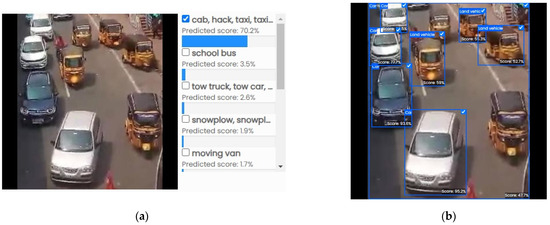
Figure 12.
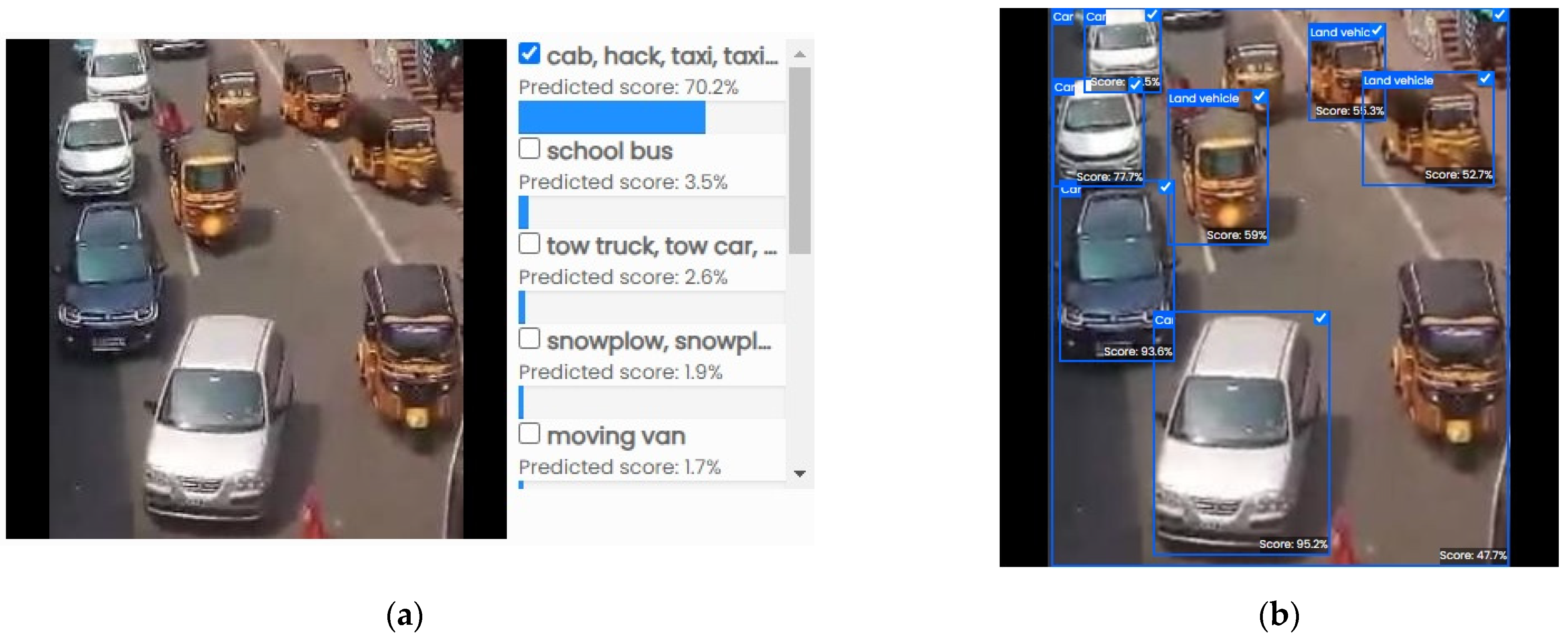
Vehicle classification results: (a) test data; (b) evaluated results.
Figure 9 illustrates the confusion matrices for vehicle classification with the image processing techniques and the machine learning algorithm. The color in each square indicates the range of the cell. The brighter colors show the maximum matches. The values along the diagonal of the confusion matrix show the matches, whereas the off-diagonals indicate fewer match types for the vehicles. The following are the mathematical formulae used to calculate the different metrics in the proposed work.
- Mean Square Error (MSE): The MSE measures the average of the squares of the errors, which are the differences between the predicted and actual values.
- Accuracy: Accuracy is the ratio of the number of correctly predicted instances to the total number of instances.
- Precision: Precision is the ratio of the number of true-positive instances to the total number of instances predicted as positive.
- Recall: Recall (also known as the sensitivity or the true-positive rate) is the ratio of the number of true-positive instances to the total number of actual positive instances.
Figure 10 shows the comparision of different hardware simulations for the vehicle classification in different datasets. The orange color bar chart indicates the MATLAB simulation versus the classification time of the vehicle images. Similarly, the blue color indicates the FPGA simulation versus the classification time.
Figure 11 shows the resource utilization time of the proposed technique using the FPGA implementation for vehicle classification under complex environments.
Figure 12a shows the different types of vehicle classifications from the testing data. In Figure 12b, the evaluation metrics are shown for various types of vehicles under tedious conditions. Hence, the proposed hybrid approach combining eXtreme Gradient Boosting (XGBoost) and the Multi-Objective Optimization Genetic Algorithm (Mob-GA) to enhance the vehicle classification (VC) from image datasets addresses the challenges in the detection and classification of vehicles from surveillance videos; the proposed method focuses on effective attribute selection and the elimination of insignificant images. Initially, XGBoost aligns the vehicle images, followed by a hybrid phase where XGBoost and Mob-GA optimize the attribute selection for improved classification. Evaluated on 10 publicly accessible vehicle datasets, including VeRi and VehicleX, the method achieved significant improvements in the accuracy (44.44%), F1 score (58.67%), precision (58.79%), and recall (46.68%) compared to the MVVTR dataset. A real-time implementation using an FPGA board demonstrated a fast execution time of 0.16 ns, indicating low computation costs and rapid processing capabilities. This study highlights the hybrid approach’s ability to handle large datasets efficiently, providing superior performance metrics over existing methods. However, limitations include the reliance on specific hardware, the limited dataset scope, and the need for further investigation into the scalability and real-time performance under diverse conditions. Overall, this research contributes a robust method for vehicle classification, demonstrating significant advancements in the accuracy and efficiency which are suitable for intelligent transportation systems.
5.3. Summary Discussion
The main objective of this paper was to propose an XGBoost–Mob-GA approach towards realizing an efficient embedded vehicle class classification system from a complex dataset. This paper aimed to contribute to the existing challenges and bottlenecks in the latest literature. This paper was highly focused on converging the arduous constraints of embedded systems development with a higher accuracy rate. The real-time implementation in the FPGA platform made the proposed approach more suitable for VC with a shorter detection time. In this research, the proposed method has following merits when compared to conventional ML approaches:
- (i)
- It can furnish more robust and accurate results, and it is hard to overfit when compared to traditional approaches such as SVMs, ANNs, and RFs.
- (ii)
- When compared to single-objective optimization, our proposed method can optimize the classification accuracy and efficiency.
- (iii)
- Our proposed method was superior to XGBoost, since the optimized parameters led to a considerable potency in the performance of the classification results.
- (iv)
- The proposed method provides a lower computation cost when compared to complex GUIs.
- (v)
- Minimum labels were taken from the complex dataset and used to classify vehicles under complex environments.
- (vi)
- This hybrid method provides notable accuracy for vehicle classification.
5.4. Limitations and Applications
Vehicle classification plays a vital role in image processing. The proposed method is used to classify vehicles from complex datasets. The limitations of this paper include the following:
- This study only considers 10 publicly accessible vehicle datasets. While these datasets provide a good starting point, the performance of the proposed method on other datasets, especially those with different characteristics or larger volumes, was not evaluated. This could limit the generalizability of the results to different real-world scenarios.
- The implementation and performance evaluation were carried out using specific hardware, namely, the myRIO FPGA board and HUSKY Lens. The reliance on specialized hardware might limit the accessibility and applicability of the proposed method to environments where such hardware is unavailable or impractical to use.
- The proposed method primarily focuses on the attribute selection process and its impact on vehicle classification. While this is crucial, other aspects of the machine-learning pipeline, such as data preprocessing, model interpretability, and robustness to noise or variations in the data, are not addressed in detail, which could affect the overall performance and usability.
- Although the study claims fast execution times and improved performance, the scalability of the proposed method to handle even larger datasets or to operate in real-time under varying traffic conditions is not thoroughly explored. Future work should investigate the method’s performance under different scales and real-time constraints to ensure its practical applicability.The following are the major applications of the proposed work:
- Traffic Monitoring and Management: Real-time vehicle classification can help in monitoring traffic flow, identifying congestion points, and optimizing traffic signal timings to improve traffic management.
- Automated Toll Collection: The system can be used to classify vehicles for automated toll collection systems, ensuring accurate toll charges based on vehicle type and size.
- Smart Parking Systems: In smart parking systems, real-time vehicle classification can assist in managing parking spaces by directing different types of vehicles to appropriate parking areas and ensuring efficient space utilization.
- Law Enforcement and Surveillance: Law enforcement agencies can use the system for real-time surveillance, identifying and tracking specific types of vehicles involved in criminal activities or traffic violations.
- Fleet Management: Companies with large fleets can use this technology to monitor and manage their vehicles in real-time, optimizing routes, scheduling maintenance, and improving overall operational efficiency.
6. Conclusions
In this study, we implemented a hybrid attribute-selection approach using XGBoost and Mob-GA for vehicle classification (VC) in vehicle datasets, as well as utilizing Python 3.11.5, the sci-kit-feature, and learn. The hardware implementation on an FPGA board demonstrated a computation speed of 0.16 ns. We considered 10 publicly accessible vehicle datasets, and by applying the hybrid attribute-selection technique, we identified the most significant labels. These labels were transformed and processed at a high speed using an embedded approach, leading to an improved VC performance. Extensive experiments on large vehicle datasets, including VeRi and VehicleX, showed that the proposed method outperformed the MVVTR dataset, achieving gains of 44.44%, 58.67%, 58.79%, and 46.68% in the accuracy, F1 score, precision, and recall, respectively. The FPGA-based implementation resulted in lower computation costs, faster training processes, and a more advanced model for classifying vehicles from large datasets. Our advanced evaluation metrics, such as the accuracy, F1 score, and recall, confirmed the superior performance of the hybrid XGBoost-MOB-GA approach for vehicle classification.
Author Contributions
Conceptualization, P.M. and P.R.G.K.; methodology, N.R.; software, P.M.; validation, N.R., P.M. and M.A.; formal analysis, A.A.; investigation, P.M.; resources, N.R.; data curation, P.R.G.K.; writing—original draft preparation, P.M.; writing—review and editing, N.R.; visualization, P.R.G.K.; supervision, P.R.G.K.; project administration, R.A.; funding acquisition, A.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Taif University, Taif, Saudi Arabia (TU-DSPP-2024-17).
Data Availability Statement
Data are contained within the article.
Acknowledgments
The author extend their appreciation to Taif University, Saudi Arabia, for supporting this work through project number (TU-DSPP-2024-17).
Conflicts of Interest
The authors declare no conflicts of interest.
Nomenclature
| Acronyms | |
| VC | Vehicle classification |
| XGBoost | eXtreme gradient boosting |
| XGBoost-Mob-GA | Multi-objective optimization genetic algorithm |
| ML | Machine learning |
| CNN | Convolution neural network |
| ANN | Artificial neural network |
| SVM | Support vector machine |
| DA | Discriminant analysis |
| RF | Random forest |
| NB | Naive Bayes |
| DT | Decision trees |
| KNN | K-nearest neighbor |
| LR | Linear regression |
| CB | CatBoost |
| PCA | Principle component analysis |
| CART | Classification and regression trees |
| GA | Genetic algorithm |
| ROCs | Receiver operating characteristics |
| VeRi | Vehicle Re-identification |
| CompCars | Comprehensive cars |
| ROI | Region of interest |
| MVVTR | Multi-view vehicle-type recognition |
| NI | National Instruments |
| CDF | Cumulative distribution function |
| FPGA | Field-programmable gate array |
| Variable Definition | |
| Objective function for the model | |
| Number of trees | |
| Functional space | |
| Real data | |
| Predicted data | |
| Regularization parameter | |
| Co-efficient of splitting trees | |
| Label of the pattern | |
| Testing data | |
References
- Maungmai, W.; Nuthong, C. Vehicle Classification with Deep Learning. In Proceedings of the 2019 IEEE 4th International Conference on Computer and Communication Systems (ICCCS), Singapore, 23–25 February 2019; pp. 294–298. [Google Scholar] [CrossRef]
- Sarikan, S.S.; Ozbayoglu, A.M.; Zilci, O. Automated Vehicle Classification with Image Processing and Computational Intelligence. Procedia Comput. Sci. 2017, 114, 515–522. [Google Scholar] [CrossRef]
- Yu, S.; Zhao, C.; Song, L.; Li, Y.; Du, Y. Understanding traffic bottlenecks of long freeway tunnels based on a novel location-dependent lighting-related car-following model. Tunn. Undergr. Space Technol. 2023, 136, 105098. [Google Scholar] [CrossRef]
- Yin, Y.; Guo, Y.; Su, Q.; Wang, Z. Task Allocation of Multiple Unmanned Aerial Vehicles Based on Deep Transfer Reinforcement Learning. Drones 2022, 6, 215. [Google Scholar] [CrossRef]
- Zhao, T.; He, J.; Lv, J.; Min, D.; Wei, Y. A Comprehensive Implementation of Road Surface Classification for Vehicle Driving Assistance: Dataset, Models, and Deployment. IEEE Trans. Intell. Transp. Syst. 2023, 24, 8361–8370. [Google Scholar] [CrossRef]
- Xu, X.; Wei, Z. Dynamic pickup and delivery problem with transshipments and LIFO constraints. Comput. Ind. Eng. 2023, 175, 108835. [Google Scholar] [CrossRef]
- Ottoni, A.L.C.; de Amorim, R.M.; Novo, M.S.; Costa, D.B. Tuning of data augmentation hyperparameters in deep learning to building construction image classification with small datasets. Int. J. Mach. Learn. Cybern. 2023, 14, 171–186. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.; Chen, S.; Xiao, Z.; Hu, J.; Liu, J.; Dustdar, S. Pa-Count: Passenger Counting in Vehicles Using Wi-Fi Signals. IEEE Trans. Mob. Comput. 2023, 23, 2684–2697. [Google Scholar] [CrossRef]
- Hu, M.; Bai, L.; Fan, J.; Zhao, S.; Chen, E. Vehicle color recognition based on smooth modulation neural network with multi-scale feature fusion. Front. Comput. Sci. 2023, 17, 173321. [Google Scholar] [CrossRef]
- Xiao, Z.; Fang, H.; Jiang, H.; Bai, J.; Havyarimana, V.; Chen, H.; Jiao, L. Understanding Private Car Aggregation Effect via Spatio-Temporal Analysis of Trajectory Data. IEEE Trans. Cybern. 2023, 53, 2346–2357. [Google Scholar] [CrossRef]
- Tighkhorshid, A.; Tousi, S.M.A.; Nikoofard, A. Car depth estimation within a monocular image using a light CNN. J. Supercomput. 2023, 79, 17944–17961. [Google Scholar] [CrossRef]
- Dai, X.; Xiao, Z.; Jiang, H.; Chen, H.; Min, G.; Dustdar, S.; Cao, J. A Learning-Based Approach for Vehicle-to-Vehicle Computation Offloading. IEEE Internet Things J. 2023, 10, 7244–7258. [Google Scholar] [CrossRef]
- Kim, H. Multiple vehicle tracking and classification system with a convolutional neural network. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 1603–1614. [Google Scholar] [CrossRef]
- Xiao, Z.; Li, H.; Jiang, H.; Li, Y.; Alazab, M.; Zhu, Y.; Dustdar, S. Predicting Urban Region Heat via Learning Arrive-Stay-Leave Behaviors of Private Cars. IEEE Trans. Intell. Transp. Syst. 2023, 24, 10843–10856. [Google Scholar] [CrossRef]
- Maity, S.; Bhattacharyya, A.; Singh, P.K.; Kumar, M.; Sarkar, R. Last Decade in Vehicle Detection and Classification: A Comprehensive Survey. Arch. Comput. Methods Eng. 2022, 29, 5259–5296. [Google Scholar] [CrossRef]
- Sun, G.; Zhang, Y.; Yu, H.; Du, X.; Guizani, M. Intersection Fog-Based Distributed Routing for V2V Communication in Urban Vehicular Ad Hoc Networks. IEEE Trans. Intell. Transp. Syst. 2020, 21, 2409–2426. [Google Scholar] [CrossRef]
- Shvai, N.; Hasnat, A.; Meicler, A.; Nakib, A. Accurate classification for automatic vehicle-type recognition based on ensemble classifiers. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1288–1297. [Google Scholar] [CrossRef]
- Sun, G.; Song, L.; Yu, H.; Chang, V.; Du, X.; Guizani, M. V2V Routing in a VANET Based on the Autoregressive Integrated Moving Average Model. IEEE Trans. Veh. Technol. 2019, 68, 908–922. [Google Scholar] [CrossRef]
- Gupta, B.B.; Gaurav, A.; Marín, E.C.; Alhalabi, W. Novel graph-based machine learning technique to secure smart vehicles in intelligent transportation systems. IEEE Trans. Intell. Transp. Syst. 2022, 24, 8483–8491. [Google Scholar] [CrossRef]
- Sun, G.; Zhang, Y.; Liao, D.; Yu, H.; Du, X.; Guizani, M. Bus-Trajectory-Based Street-Centric Routing for Message Delivery in Urban Vehicular Ad Hoc Networks. IEEE Trans. Veh. Technol. 2018, 67, 7550–7563. [Google Scholar] [CrossRef]
- Ahmad, A.B.; Saibi, H.; Belkacem, A.N.; Tsuji, T. Vehicle Auto-Classification Using Machine Learning Algorithms Based on Seismic Fingerprinting. Computers 2022, 11, 148. [Google Scholar] [CrossRef]
- Sun, G.; Sheng, L.; Luo, L.; Yu, H. Game Theoretic Approach for Multipriority Data Transmission in 5G Vehicular Networks. IEEE Trans. Intell. Transp. Syst. 2022, 23, 24672–24685. [Google Scholar] [CrossRef]
- Basheer Ahmed, M.I.; Zaghdoud, R.; Ahmed, M.S.; Sendi, R.; Alsharif, S.; Alabdulkarim, J.; Saad, B.A.A.; Alsabt, R.; Rahman, A.; Krishnasamy, G. A real-time computer vision based approach to detection and classification of traffic incidents. Big Data Cogn. Comput. 2023, 7, 22. [Google Scholar] [CrossRef]
- Qu, Z.; Liu, X.; Zheng, M. Temporal-Spatial Quantum Graph Convolutional Neural Network Based on Schrödinger Approach for Traffic Congestion Prediction. IEEE Trans. Intell. Transp. Syst. 2022, 24, 8677–8686. [Google Scholar] [CrossRef]
- Shokravi, H.; Shokravi, H.; Bakhary, N.; Heidarrezaei, M.; Koloor, S.S.R.; Petrů, M. A review on VC and potential use of smart vehicle-assisted techniques. Sensors 2020, 20, 3274. [Google Scholar] [CrossRef] [PubMed]
- Luo, J.; Wang, G.; Li, G.; Pesce, G. Transport infrastructure connectivity and conflict resolution: A machine learning analysis. Neural Comput. Appl. 2022, 34, 6585–6601. [Google Scholar] [CrossRef]
- Prarthana, V.; Hegde, S.N.; Sushmitha, T.P.; Savithramma, R.M.; Sumathi, R. A Comparative Study of Artificial Intelligence based VC Algorithms used to Provide Smart Mobility. In Proceedings of the 2022 4th International Conference on Advances in Computing, Communication Control and Networking (ICAC3N), Greater Noida, India, 16–17 December 2022; IEEE: New York, NY, USA, 2022; pp. 2341–2348. [Google Scholar]
- Sun, R.; Dai, Y.; Cheng, Q. An Adaptive Weighting Strategy for Multisensor Integrated Navigation in Urban Areas. IEEE Internet Things J. 2023, 10, 12777–12786. [Google Scholar] [CrossRef]
- Bhatt, P.; Maclean, A.L. Comparison of high-resolution NAIP and unmanned aerial vehicle (UAV) imagery for natural vegetation communities classification using machine learning approaches. GISci. Remote Sens. 2023, 60, 2177448. [Google Scholar] [CrossRef]
- Ren, Y.; Lan, Z.; Liu, L.; Yu, H. EMSIN: Enhanced Multi-Stream Interaction Network for Vehicle Trajectory Prediction. IEEE Trans. Fuzzy Syst. 2024. [Google Scholar] [CrossRef]
- Thomas, A.; Harikrishnan, P.M.; Palanisamy, P.; Gopi, V.P. Moving vehicle candidate recognition and classification using inception-resnet-v2. In Proceedings of the 2020 IEEE 44th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 13–17 July 2020; IEEE: New York, NY, USA, 2020; pp. 467–472. [Google Scholar]
- Mou, J.; Gao, K.; Duan, P.; Li, J.; Garg, A.; Sharma, R. A Machine Learning Approach for Energy-Efficient Intelligent Transportation Scheduling Problem in a Real-World Dynamic Circumstances. IEEE Trans. Intell. Transp. Syst. 2023, 24, 15527–15539. [Google Scholar] [CrossRef]
- Ma, Y.; Wang, Z.; Yang, H.; Yang, L. Artificial intelligence applications in the development of autonomous vehicles: A survey. IEEE/CAA J. Autom. Sin. 2020, 7, 315–329. [Google Scholar] [CrossRef]
- Tang, Y.; Wang, C.; Gao, J.; Hua, P. Intelligent Detection Method of Forgings Defects Detection Based on Improved EfficientNet and Memetic Algorithm. IEEE Access 2022, 10, 79553–79563. [Google Scholar] [CrossRef]
- Rani, P.; Sharma, R. Intelligent transportation system for internet of vehicles based vehicular networks for smart cities. Comput. Electr. Eng. 2023, 105, 108543. [Google Scholar] [CrossRef]
- Fu, Z.; Hu, M.; Guo, Q.; Jiang, Z.; Guo, D.; Liao, Z. Research on anti-rollover warning control of heavy dump truck lifting based on sliding mode-robust control. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2023. [Google Scholar] [CrossRef]
- Laxman, K.C.; Ross, A.; Ai, L.; Henderson, A.; Elbatanouny, E.; Bayat, M.; Ziehl, P. Determination of vehicle loads on bridges by acoustic emission and an improved ensemble artificial neural network. Constr. Build. Mater. 2023, 364, 129844. [Google Scholar]
- Deng, Z.W.; Zhao, Y.Q.; Wang, B.H.; Gao, W.; Kong, X. A preview driver model based on sliding-mode and fuzzy control for articulated heavy vehicle. Meccanica 2022, 57, 1853–1878. [Google Scholar] [CrossRef]
- Yang, J.; Liang, N.; Pitts, B.J.; Prakah-Asante, K.O.; Curry, R.; Blommer, M.; Swaminathan, R.; Yu, D. Multimodal Sensing and Computational Intelligence for Situation Awareness Classification in Autonomous Driving. IEEE Trans. Hum.-Mach. Syst. 2023, 53, 270–281. [Google Scholar] [CrossRef]
- Peng, J.J.; Chen, X.G.; Wang, X.K.; Wang, J.Q.; Long, Q.Q.; Yin, L.J. Picture fuzzy decision-making theories and methodologies: A systematic review. Int. J. Syst. Sci. 2023, 54, 2663–2675. [Google Scholar] [CrossRef]
- Li, S.; Zhang, X. Research on orthopedic auxiliary classification and prediction model based on XGBoost algorithm. Neural Comput. Appl. 2020, 32, 1971–1979. [Google Scholar] [CrossRef]
- Wu, Z.; Zhu, H.; He, L.; Zhao, Q.; Shi, J.; Wu, W. Real-time stereo matching with high accuracy via Spatial Attention-Guided Upsampling. Appl. Intell. 2023, 53, 24253–24274. [Google Scholar] [CrossRef]
- Srinivas, P.; Katarya, R. hyOPTXg: OPTUNA hyper-parameter optimization framework for predicting cardiovascular disease using XGBoost. Biomed. Signal Process. Control. 2022, 73, 103456. [Google Scholar] [CrossRef]
- Wu, W.; Zhu, H.; Yu, S.; Shi, J. Stereo Matching With Fusing Adaptive Support Weights. IEEE Access 2019, 7, 61960–61974. [Google Scholar] [CrossRef]
- Zhou, M.; Lai, W. Coal gangue recognition based on spectral imaging combined with XGBoost. PLoS ONE 2023, 18, e0279955. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.; Hu, J.; Ghosh, B.K. Finite-time tracking control of heterogeneous multi-AUV systems with partial measurements and intermittent communication. Sci. China Inf. Sci. 2024, 67, 152202. [Google Scholar] [CrossRef]
- Pemila, M.; Pongiannan, R.K.; Megala, V. Implementation of Vehicles Classification using Extreme Gradient Boost Algorithm. In Proceedings of the 2022 Second International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), Bhilai, India, 21–22 April 2022; IEEE: New York, NY, USA, 2022; pp. 1–6. [Google Scholar]
- Hu, J.; Wu, Y.; Li, T.; Ghosh, B.K. Consensus Control of General Linear Multiagent Systems With Antagonistic Interactions and Communication Noises. IEEE Trans. Autom. Control 2019, 64, 2122–2127. [Google Scholar] [CrossRef]
- Ma, J.; Hu, J. Safe consensus control of cooperative-competitive multi-agent systems via differential privacy. Kybernetika 2022, 58, 426–439. [Google Scholar] [CrossRef]
- Tang, Q.; Qu, S.; Zhang, C.; Tu, Z.; Cao, Y. Effects of impulse on prescribed-time synchronization of switching complex networks. Neural Netw. 2024, 174, 106248. [Google Scholar] [CrossRef] [PubMed]
- Zhao, L.; Xu, H.; Qu, S.; Wei, Z.; Liu, Y. Joint Trajectory and Communication Design for UAV-Assisted Symbiotic Radio Networks. IEEE Trans. Veh. Technol. 2024. [Google Scholar] [CrossRef]
- Hao, J.; Chen, P.; Chen, J.; Li, X. Multi-task federated learning-based system anomaly detection and multi-classification for microservices architecture. Future Gener. Comput. Syst. 2024, 159, 77–90. [Google Scholar] [CrossRef]
- Zhao, J.; Song, D.; Zhu, B.; Sun, Z.; Han, J.; Sun, Y. A Human-Like Trajectory Planning Method on a Curve Based on the Driver Preview Mechanism. IEEE Trans. Intell. Transp. Syst. 2023, 24, 11682–11698. [Google Scholar] [CrossRef]
- Yang, L.; Luo, P.; Loy, C.C.; Tang, X. A large-scale car dataset for fine-grained categorization and verification. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3973–3981. [Google Scholar] [CrossRef]
- Zhu, B.; Sun, Y.; Zhao, J.; Han, J.; Zhang, P.; Fan, T. A Critical Scenario Search Method for Intelligent Vehicle Testing Based on the Social Cognitive Optimization Algorithm. IEEE Trans. Intell. Transp. Syst. 2023, 24, 7974–7986. [Google Scholar] [CrossRef]
- Zhou, Z.; Wang, Y.; Liu, R.; Wei, C.; Du, H.; Yin, C. Short-Term Lateral Behavior Reasoning for Target Vehicles Considering Driver Preview Characteristic. IEEE Trans. Intell. Transp. Syst. 2022, 23, 11801–11810. [Google Scholar] [CrossRef]
- Chen, J.; Wang, Q.; Cheng, H.H.; Peng, W.; Xu, W. A Review of Vision-Based Traffic Semantic Understanding in ITSs. IEEE Trans. Intell. Transp. Syst. 2022, 23, 19954–19979. [Google Scholar] [CrossRef]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Li, B.; Hu, S. Traffic-sign detection and classification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2110–2118. [Google Scholar]
- Chen, J.; Wang, Q.; Peng, W.; Xu, H.; Li, X.; Xu, W. Disparity-Based Multiscale Fusion Network for Transportation Detection. IEEE Trans. Intell. Transp. Syst. 2022, 23, 18855–18863. [Google Scholar] [CrossRef]
- Qi, H.; Zhou, Z.; Irizarry, J.; Lin, D.; Zhang, H.; Li, N.; Cui, J. Automatic Identification of Causal Factors from Fall-Related Accident Investigation Reports Using Machine Learning and Ensemble Learning Approaches. J. Manag. Eng. 2024, 40, 04023050. [Google Scholar] [CrossRef]
- Krause, J.; Stark, M.; Jia, D.; Li, F.-F. 3D Object Representations for Fine-Grained Categorization. In Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops, Sydney, NSW, Australia, 2–8 December 2013; pp. 554–561. [Google Scholar] [CrossRef]
- Liu, W.; Zhong, J.; Liang, P.; Guo, J.; Zhao, H.; Zhang, J. Towards explainable traffic signal control for urban networks through genetic programming. Swarm Evol. Comput. 2024, 88, 101588. [Google Scholar] [CrossRef]
- Zou, W.; Sun, Y.; Zhou, Y.; Lu, Q.; Nie, Y.; Sun, T.; Peng, L. Limited Sensing and Deep Data Mining: A New Exploration of Developing City-Wide Parking Guidance Systems. IEEE Intell. Transp. Syst. Mag. 2022, 14, 198–215. [Google Scholar] [CrossRef]
- Rong, Y.; Xu, Z.; Liu, J.; Liu, H.; Ding, J.; Liu, X.; Gao, J. Du-Bus: A Realtime Bus Waiting Time Estimation System Based On Multi-Source Data. IEEE Trans. Intell. Transp. Syst. 2022, 23, 24524–24539. [Google Scholar] [CrossRef]
- Wang, R.; Gu, Q.; Lu, S.; Tian, J.; Yin, Z.; Yin, L.; Zheng, W. FI-NPI: Exploring Optimal Control in Parallel Platform Systems. Electronics 2024, 13, 1168. [Google Scholar] [CrossRef]
- Sheng, H.; Wang, S.; Chen, H.; Yang, D.; Huang, Y.; Shen, J.; Ke, W. Discriminative Feature Learning With Co-Occurrence Attention Network for Vehicle ReID. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 3510–3522. [Google Scholar] [CrossRef]
- Cao, B.; Li, Z.; Liu, X.; Lv, Z.; He, H. Mobility-Aware Multiobjective Task Offloading for Vehicular Edge Computing in Digital Twin Environment. IEEE J. Sel. Areas Commun. 2023, 41, 3046–3055. [Google Scholar] [CrossRef]
- Cao, B.; Zhang, W.; Wang, X.; Zhao, J.; Gu, Y.; Zhang, Y. A memetic algorithm based on two_Arch2 for multi-depot heterogeneous-vehicle capacitated arc routing problem. Swarm Evol. Comput. 2021, 63, 100864. [Google Scholar] [CrossRef]
- Feng, J.; Wang, Y.; Liu, Z. Joint impact of service efficiency and salvage value on the manufacturer’s shared vehicle-type strategies. Rairo-Oper. Res. 2024, 58, 2261–2287. [Google Scholar] [CrossRef]
- Guerrero-Gómez-Olmedo, R.; Torre-Jiménez, B.; López-Sastre, R.; Maldonado-Bascón, S.; Onoro-Rubio, D. Extremely overlapping vehicle counting. In Pattern Recognition and Image Analysis: 7th Iberian Conference, IbPRIA 2015, Santiago de Compostela, Spain, 17–19 June 2015; Proceedings; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; Volume 7, pp. 423–431. [Google Scholar]
- Chen, Z.; Ying, C.; Lin, C.; Liu, S.; Li, W. Multi-View Vehicle Type Recognition With Feedback-Enhancement Multi-Branch CNNs. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 2590–2599. [Google Scholar] [CrossRef]
- Pemila, M.; Pongiannan, R.K.; Pandey, V.; Mondal, P.; Bhaumik, S. An Efficient Classification for Light Motor Vehicles using CatBoost Algorithm. In Proceedings of the 2023 Fifth International Conference on Electrical, Computer and Communication Technologies (ICECCT), Erode, India, 22–24 February 2023; IEEE: New York, NY, USA, 2023; pp. 1–7. [Google Scholar]
- Wang, X.; Zhang, W.; Wu, X.; Xiao, L.; Qian, Y.; Fang, Z. Real-time vehicle type classification with deep convolutional neural networks. J. Real-Time Image Process. 2019, 16, 5–14. [Google Scholar] [CrossRef]
- Jahan, N.; Islam, S.; Foysal, M.F.A. Real-time vehicle classification using CNN. In Proceedings of the 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020; IEEE: New York, NY, USA, 2020; pp. 1–6. [Google Scholar]
- Mithun, N.C.; Rashid, N.U.; Rahman, S.M. Detection and classification of vehicles from video using multiple time-spatial images. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1215–1225. [Google Scholar] [CrossRef]
- Wang, R.; Zhang, L.; Xiao, K.; Sun, R.; Cui, L. EasiSee: Real-time vehicle classification and counting via low-cost collaborative sensing. IEEE Trans. Intell. Transp. Syst. 2013, 15, 414–424. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).