
Identification Method of Stuck Pipe Based on Data Augmentation and ATT-LSTM
Abstract
:1. Introduction
2. Methodology
2.1. Brief Process
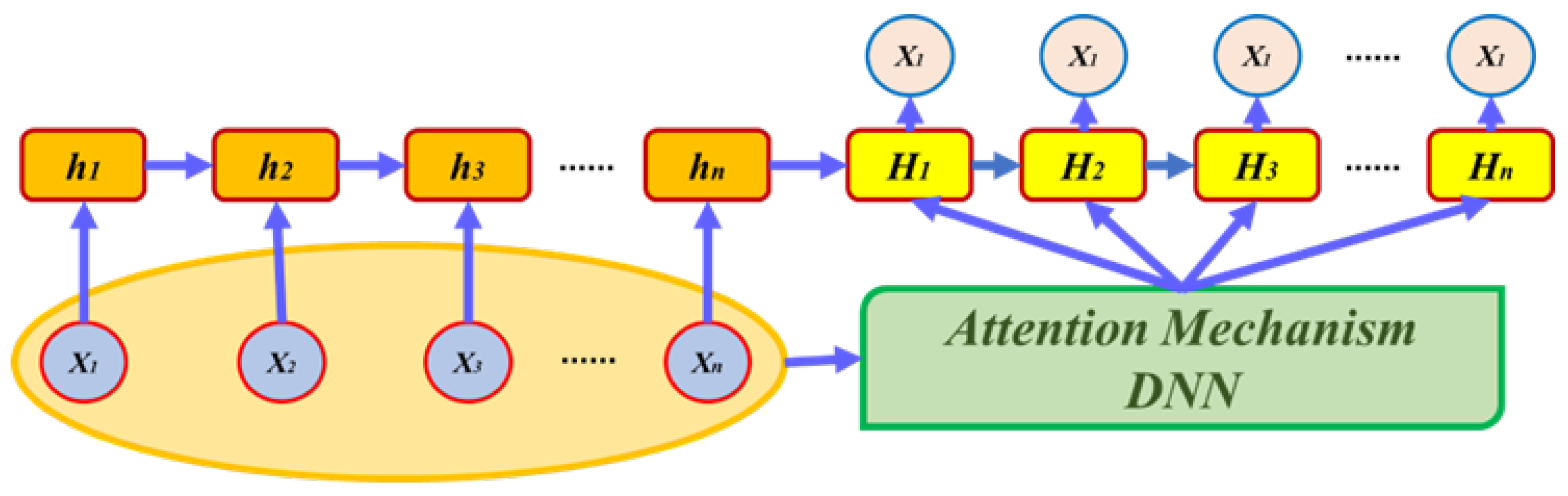
2.2. Long Short-Term Memory (LSTM) and Attention Mechanism
2.3. Few-Shot Learning and Data Augmentation
2.4. Method Limitations
3. Data Processing
3.1. Data Sources
3.2. Parameter Selection
3.3. Data Augmentation
3.4. Data Normalization
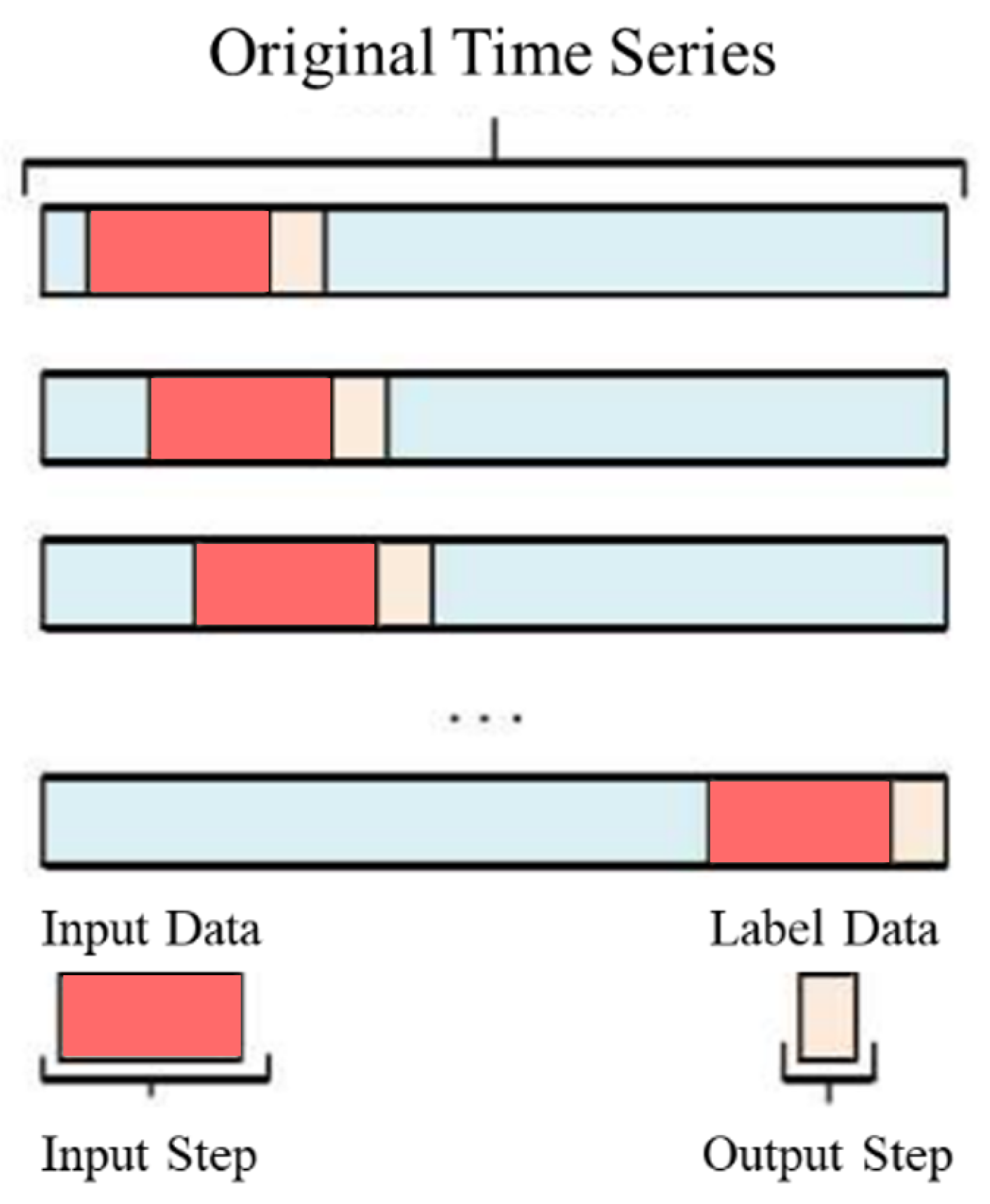
3.5. Dataset Construction
4. Model Construction
5. Experimental Results and Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| LSTM | Long Short-Term Memory |
| ATT-LSTM | Long Short-Term Memory with Attention Mechanism Neural Network |
| GAN | Generative Adversarial Network |
| FSL | Few-Shot Learning |
| MSE | Mean Squared Error |
| GRU | Gated Recurrent Unit |
| MLP | Multilayer Perceptron |
| SVM | Support Vector Machine |
| RMSE | Root Mean Squared Error |
| MAE | Mean Absolute Error |
| ACC | Accuracy |
References
- Zhao, C. System analysis of factors influencing stuck pipe incidents. Xinjiang Pet. Sci. Technol. 1998, 2, 1–6+25. [Google Scholar]
- Zhang, L. Analysis and treatment of stuck drill pipes downhole. Mar. Pet. 2007, 27, 112–115. [Google Scholar]
- Yu, R. Research on prediction technology for stuck drill pipes. Drill. Technol. 1996, 24, 15–17. [Google Scholar]
- Zhao, C.; He, Y. Review of stuck drill pipe prediction technology. Xinjiang Pet. Technol. 1998, 4–8. [Google Scholar]
- Zhu, S.; Song, X.; Li, G.; Zhu, Z.; Yao, X. Intelligent real-time analysis and stuck drill pipe trend prediction of drill string torsional friction torque. Oil Drill. Prod. Technol. 2021, 43, 428–435. [Google Scholar]
- Naraghi, M.E.; Ezzatyar, P.; Jamshidi, S. Adaptive Neuro Fuzzy Inference System and Artificial Neural Networks: Reliable approaches for pipe stuck prediction. Aust. J. Basic Appl. Sci. 2013, 7, 604–618. [Google Scholar]
- Salminen, K.; Cheatham, C.; Smith, M.; Valiulin, K. Stuck Pipe Prediction Using Automated Real-Time Modeling and Data Analysis. In Proceedings of the SPE/IADC International Drilling Conference and Exhibition, Society of Petroleum Engineers, Fort Worth, TX, USA, 1–3 March 2016. [Google Scholar]
- Magana-Mora, A.; Gharbi, S.; Alshaikh, A.; Al-Yami, A. AccuPipePred: A framework for the accurate and early detection of stuck pipe for real-time drilling operations. In Proceedings of the SPE Middle East Oil and Gas Show and Conference, OnePetro, Manama, Bahrain, 21–23 October 2019. [Google Scholar]
- Liu, G.; Tao, Y.; Zhu, D. Application research of ARMA modeling in neural network stuck drill pipe prediction method. Mod. Electron. Tech. 2013, 36, 17–19. [Google Scholar]
- Liu, D.; Wang, C.; Yang, L.; Wang, P.; Chen, M. Analysis of causes of oil drilling stuck drill pipe accidents based on accident tree. J. Cent. South Univ. Nat. Sci. Ed. 2017, 14, 51–53. [Google Scholar]
- Wu, J.; Zang, Y.; Chen, X. Stuck drill pipe type identification analysis based on pattern recognition theory. Min. Eng. Rock Soil Boring Eng. 2015, 42, 31–34. [Google Scholar]
- Li, T.; Zhang, Q. Research on neural network prediction of stuck drill pipe accidents based on PSO-BP. Changjiang Inf. Commun. 2021, 75–77. [Google Scholar]
- Mopuri, K.R.; Bilen, H.; Tsuchihashi, N.; Wada, R.; Inoue, T.; Kusanagi, K.; Nishiyama, T.; Tamamura, H. Early sign detection for the stuck pipe scenarios using unsupervised deep learning. J. Pet. Sci. Eng. 2022, 208, 109489. [Google Scholar] [CrossRef]
- Elmgerbi, A.; Thonhauser, G. Holistic autonomous model for early detection of downhole drilling problems in real-time. Process Saf. Environ. Prot. 2022, 164, 418–434. [Google Scholar] [CrossRef]
- Kim, K.; Jeong, J. Real-time monitoring for hydraulic states based on convolutional bidirectional LSTM with attention mechanism. Sensors 2020, 20, 7099. [Google Scholar] [CrossRef] [PubMed]
- Dan, Z.; Shao, W.; Chen, J. Application research of artificial neural network in real-time prediction of stuck drill pipes. Geol. Prospect. 2000, 36, 10–12. [Google Scholar]
- Tao, Y. Research on Stuck Drill Pipe Prediction Methods Based on Time Series. Ph.D. Thesis, Xi’an University of Petroleum, Xi’an, China, 2014. [Google Scholar]
- Tianyi, D.; Gengpei, Z. Study on optimization of small sample model generalization performance based on meta-learning and data augmentation. Mod. Inf. Technol. 2024, 93–96. [Google Scholar]
- Zhang, Y. Research on Small Sample Learning Methods Based on Data Augmentation and Model Fine-Tuning. Master’s Thesis, Shanxi University of Finance and Economics, Taiyuan, China, 2023. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factor | Max | Min | Mean | Standard Deviation |
|---|---|---|---|---|
| Bit Depth (m) | 4990.14 | 3632.43 | 4475.33 | 415.22 |
| Hook Load (kN) | 2142.15 | 113.3 | 984.39 | 708.79 |
| Drilling Weight (MPa) | 1149.35 | 0 | 0.005 | 14.32 |
| Hook Height (m) | 36.89 | 6.85 | 24.54 | 10.26 |
| Rotary Speed (rpm) | 36.43 | 0 | 4.27 | 10.98 |
| Torque (N·m) | 33.46 | 0 | 1.41 | 2.93 |
| Stand Pipe Pressure (MPa) | 25.74 | 0 | 3.44 | 7.94 |
| Inlet Flow (m3/s) | 52.53 | 0 | 44.34 | 14.67 |
| Outlet Flow (m3/s) | 82.3 | 0 | 62.96 | 24.50 |
| Casing Pressure (MPa) | 0.36 | 0 | 0.19 | 0.09 |
| Total Pump Strokes (L/s) | 32,374.74 | 14,137.29 | 22,947.51 | 4574.47 |
| Total Mud Volume (m3) | 118.24 | 106.03 | 110.78 | 3.33 |
| Model | Architecture | Number of Parameters |
|---|---|---|
| LSTM | Input layer, hidden layer, output layer | 128 neurons |
| ATT-LSTM | Input layer, attention mechanism, hidden layer, output layer | 128 neurons |
| Model | RMSE’s Mean | RMSE’s Std | MAE’s Mean | MAE’s Std | ACC’s Mean | ACC’s Std |
|---|---|---|---|---|---|---|
| Att-LSTM | 80.0 | 3.5 | 33.1 | 1.4 | 0.967 | 0.04 |
| LSTM | 85.2 | 4.1 | 41.2 | 1.9 | 0.934 | 0.06 |
| GRU | 98.5 | 5.6 | 56.3 | 4.6 | 0.852 | 0.12 |
| MLP | 123.7 | 6.1 | 58.5 | 4.9 | 0.851 | 0.16 |
| Random Forest | 121.8 | 7.2 | 61.4 | 5.5 | 0.845 | 0.18 |
| Xgboost | 125.4 | 6.6 | 59.8 | 5.2 | 0.847 | 0.17 |
| SVM | 135.1 | 3.5 | 33.1 | 1.4 | 0.967 | 0.04 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Dong, P.; Yang, Y.; Zhang, Q.; Sun, Y.; Song, X.; Zhu, Z. Identification Method of Stuck Pipe Based on Data Augmentation and ATT-LSTM. Processes 2024, 12, 1296. https://doi.org/10.3390/pr12071296
Zhang X, Dong P, Yang Y, Zhang Q, Sun Y, Song X, Zhu Z. Identification Method of Stuck Pipe Based on Data Augmentation and ATT-LSTM. Processes. 2024; 12(7):1296. https://doi.org/10.3390/pr12071296
Chicago/Turabian StyleZhang, Xiaocheng, Pinghua Dong, Yanlong Yang, Qilong Zhang, Yuan Sun, Xianzhi Song, and Zhaopeng Zhu. 2024. "Identification Method of Stuck Pipe Based on Data Augmentation and ATT-LSTM" Processes 12, no. 7: 1296. https://doi.org/10.3390/pr12071296