
RUL Prediction of Rolling Bearings Based on Multi-Information Fusion and Autoencoder Modeling

Abstract
:1. Introduction
- In view of the problem that it is difficult to accurately characterize the running state with a single running feature, multi-information entropy feature extraction is carried out for vibration signals, and multi-entropy indicators are used to improve the characterization ability and provide a basis for the subsequent construction of HI.
- At present, the extracted feature indicators in some studies have too much information, which belongs to high-dimensional feature information, excessive redundant information, and difficult screening. In traditional feature use, it is easy to cause the omission of important feature information or the calculation time is too long, and it is difficult to ensure the accuracy and overall feature extraction. In this paper, DAE was used for multi-information entropy fusion and dimensionality reduction, HI was constructed to evaluate the running state of bearings, and significant root mean square (RMS) value jump time was found as the failure threshold of HI to evaluate the running state of bearings.
- Aiming at the problem of large amounts of calculation and time required when LSTM deals with long sequence problems, the powerful feature extraction ability of CAE is used to extract the unsupervised features of vibration signals, and the hidden features are input into BiLSTM for RUL prediction.
2. Theoretical Backgrounds
2.1. Denoising Autoencoder
2.2. Convolutional Autoencoder
2.3. Bidirectional Long Short Term Memory Network
2.4. Multi-Information Selection Indicator
2.5. Health Index Construction Method
- (1)
- Bearing lifetime vibration acceleration signal is obtained through bearing data set.
- (2)
- Take the first 2048 frequency points of each data set as the training samples of the model.
- (3)
- The characteristic indexes of ReEn, ApEn, PeEn, FuEn, DisEn, and SDEn are calculated for the intercepted training samples.
- (4)
- Adam was selected as the optimizer and the DAE was trained using the training set. The loss function was as follows:where k is the number of feature samples contained in the input data, is the eigenvalue of the number i sample after the reconstruction of the characteristic sample, is the characteristic value of the number i sample of the input data, is L2 regularization coefficient, m is the number of weights in the neural network, and is the number i weight in the neural network.
- (5)
- When the loss value stops falling, it can be judged that the training is complete, and an encoder capable of effectively extracting features and dimensionality reduction can be obtained.
- (1)
- The data at the initial moment of the data set are stacked after multi-entropy feature index calculation, and input into the trained DAE to obtain the bearing characteristics in the health state.
- (2)
- Calculate the multi-entropy feature indicators of the data at the current time, and also input these indicators into the trained DAE to obtain the degraded state characteristics of the bearing under the current state.
- (3)
- Calculate the Bray–Curtis distance between the health state feature and the degraded state feature [28], and take these index data as the running state HI of the bearing.
2.6. Failure Threshold Construction Method
- (1)
- Obtain the HI value of the current moment and then insert it into the HI sequence in chronological order.
- (2)
- In order to obtain a smoother HI sequence, the moving average filter is used to filter the current HI sequence.
- (3)
- Calculate the RMS value of the HI sequence at the current moment, and compare the HI value at the current moment with the failure threshold (4); if the failure threshold is reached, the bearing has reached the degradation stage. Set the HI value at this time as the failure threshold of the bearing. The RMS calculation formula is as follows:where N is the number of HI samples at the current time; xi is the current time HI value.
2.7. RUL Model Based on CAE-BiLSTM
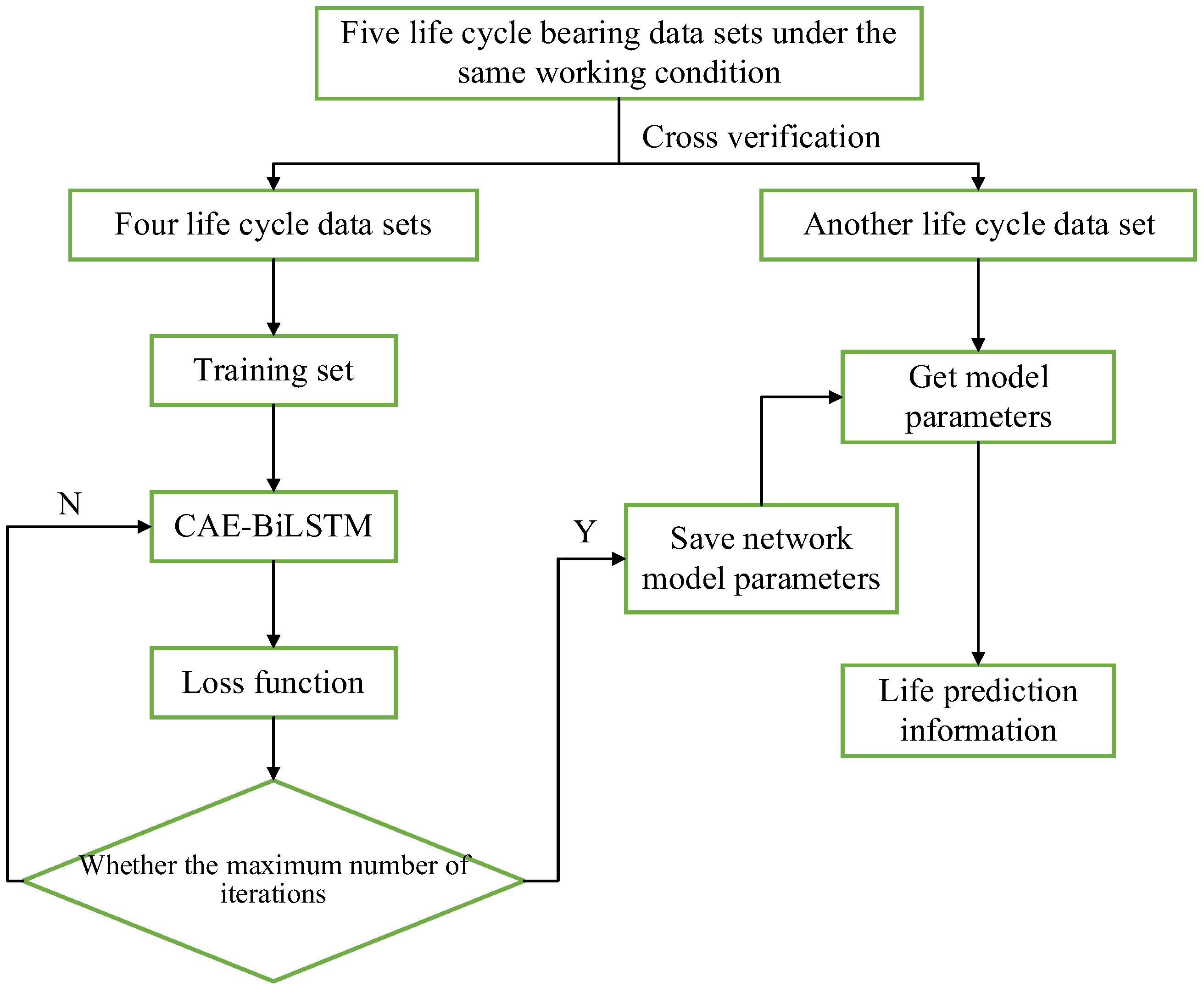
- (1)
- Firstly, the data are preprocessed, and after the data are normalized, the time domain data are converted into envelope spectrum data by Hilbert yellow transformation for model training.
- (2)
- Initialize the parameters of the CAE-BiLSTM network, process the data, adjust the input data according to the characteristics of the network model, and prepare to train the network. According to the test data, the remaining four data sets under the same working conditions are used as the training set.
- (3)
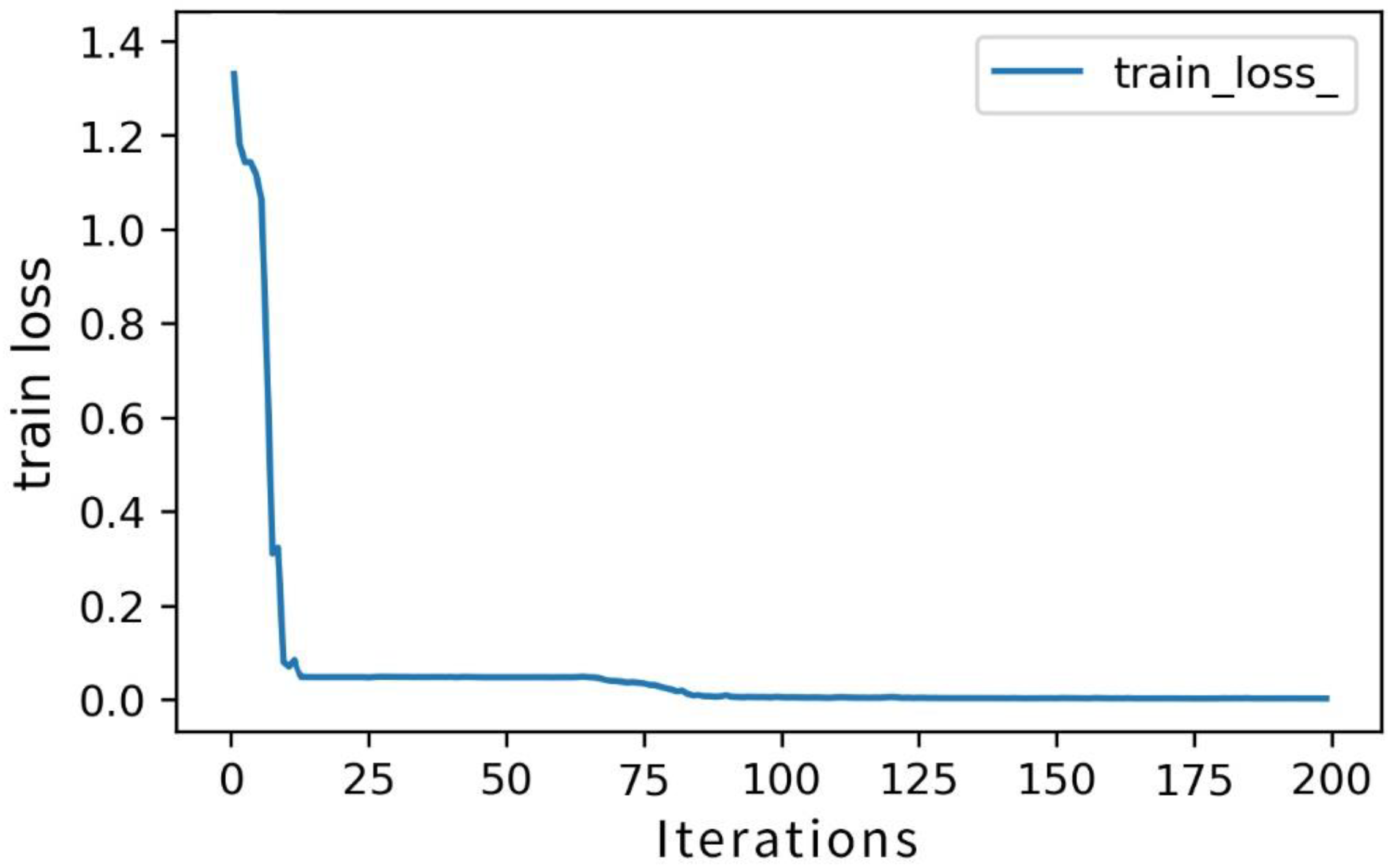
- Conduct network training, construct loss function, calculate loss function value, and optimize the network through optimization algorithm.
- (4)
- Determine whether the maximum number of iterations is reached. If the maximum number of iterations is reached, the training is completed; otherwise, return to step (3).
- (5)
- Save the trained model parameters, input the test data into the trained CAE-BiLSTM network, and obtain the prediction results.
3. Results
3.1. Multi-Entropy Extraction Process
3.2. Construction of Health Indicator and Failure Threshold
3.3. Results of RUL Prediction
- (1)
- First, the order of the predicted data is divided into stationary trend terms and random covectors .where is the sample point of the predicted data and is the eigenvalue of the sample point.
- (2)
- The EWMA is calculated as follows:where , the value in this paper is 0.9, and is obtained by averaging the previous values.
4. Discussion
- (1)
- Calculate the residual Er between the real value of the data and the predicted value:
- (2)
- Divide the obtained residual data Er into the first half Era and Erb, and the data length of each part is half of the length of the whole residual data.
- (3)
- Score A is calculated by traversing the two parts of the split residual data, and the calculated score is added to the respective arrays grade_a and grade_b. The calculation rules are as follows:
- (4)
- Calculate the mean and of the two score arrays, and obtain the total score Score by weighting.
5. Conclusions
- (1)
- In this paper, the running state monitoring of rolling bearings is taken as the research goal, and the multi-entropy fusion method is adopted to make up for the poor information representation in the single entropy feature. The multi-entropy feature index of the XJTU-SY data set was extracted, and the multi-entropy feature was fused and dimensionality reduced by CAE.
- (2)
- After dimensionality reduction, the health data of the fusion index in the early stage are regarded as the normal operation data, and the operation data at the current time are extracted. After that, the Bray–Curtis distance method is used to construct HI, and the RMS jump time of HI is set as the failure threshold. Comparative analysis of the test results shows that the proposed method can accurately evaluate the running state of the rolling bearing and accurately locate the failure time. Finally, the frequency spectrum of the original data is analyzed by fast Fourier transform, and the failure time is again located in accordance with the monitoring method in this paper, which verifies the effectiveness and superiority of the proposed method.
- (3)
- Aiming at the time-consuming problem of label selection in the RUL process, a CAE-BiLSTM unsupervised model is proposed to convert XJTU-SY data into envelope spectrum data for model training and testing. The RUL curve of the model was smooched by EWMA to reduce the fluctuation of sample points. The analysis of the test results showed that the RUL of most data sets could be realized except for the data set whose life information of the health stage was stable at a high level. Finally, the performance evaluation index is introduced to compare the proposed model, and the results show that the proposed method has good prediction accuracy and robustness.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, X.; Yang, J.; Yang, X. Residual Life Prediction of Rolling Bearings Based on a CEEMDAN Algorithm Fused with CNN–Attention-Based Bidirectional LSTM Modeling. Processes 2024, 12, 8. [Google Scholar] [CrossRef]
- Wang, Q.; Deng, L.; Zhao, R. Fault diagnosis of rolling bearing based on one-dimensional convolutional neural network transfer learning. J. Vib. Meas. Diagn. 2023, 43, 24–30+195. [Google Scholar]
- Xiao, X.; Liu, J.; Liu, D.; Tang, Y.; Qin, S.; Zhang, F. A normal behavior-based condition monitoring method for wind turbine main bearing using dual attention mechanism and Bi-LSTM. Energies 2022, 15, 8462. [Google Scholar] [CrossRef]
- Yang, S.; Tang, B.; Wang, W.; Yang, Q.; Hu, C. Physics-informed multi-state temporal frequency network for RUL prediction of rolling bearings. Reliab. Eng. Syst. Saf. 2024, 242, 109716. [Google Scholar] [CrossRef]
- Wen, P.; Li, Y.; Chen, S.; Zhao, S. Remaining useful life prediction of IIoT-Enabled complex industrial systems with hybrid fusion of multiple information sources. IEEE Internet Things J. 2021, 8, 9045–9058. [Google Scholar] [CrossRef]
- Zheng, Y.; Hu, J.; Jia, M.; Xu, F.; Tong, Q. A method for rolling bearing fault feature extraction based on parametric optimization VMD. J. Vib. Shock. 2020, 39, 195–202. [Google Scholar]
- Wang, H.; Duan, X.; Shan, G.; Sun, J.; Qiu, J. A fault prediction method based on correlation entropy fusion and improved echo state network. J. Vib. Shock 2019, 38, 226–233. [Google Scholar]
- Zhang, T.; Zhou, L.; Li, J.; Niu, H. Health Management of Bearings Using Adaptive Parametric VMD and Flying Squirrel Search Algorithms to Optimize SVM. Processes 2024, 12, 433. [Google Scholar] [CrossRef]
- Hinton, G.; Salakhutdinov, R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Tao, S.; Zhang, T.; Yang, J.; Wang, X.; Lu, W. Bearing fault diagnosis method based on stacked autoencoder and softmax regression. In Proceedings of the 2015 34th Chinese Control Conference (CCC), Hangzhou, China, 28–30 July 2015; pp. 6331–6335. [Google Scholar]
- Wang, F.; Liu, X.; Dun, B.; Deng, G.; Han, Q.; Li, H. Application of Kernel Auto-encoder Based on Firefly Optimization in Intershaft Bearing Fault Diagnosis. J. Mech. Eng. 2019, 55, 58–64. [Google Scholar] [CrossRef]
- Wang, J.; Dong, J.; Zhang, X.; Li, Y. A multiple feature fusion-based intelligent optimization ensemble model for carbon price forecasting. Process Saf. Environ. Prot. 2024, 187, 1558–1575. [Google Scholar] [CrossRef]
- Jiao, R.; Peng, K.; Dong, J. Remaining Useful Life Prediction for a Roller in a Hot Strip Mill Based on Deep Recurrent Neural Networks. IEEE CAA J. Autom. Sin. 2021, 8, 1345–1354. [Google Scholar] [CrossRef]
- Shi, J.; Zhong, J.; Zhang, Y.; Xiao, B.; Xiao, L.; Zheng, Y. A dual attention LSTM lightweight model based on exponential smoothing for remaining useful life prediction. Reliab. Eng. Syst. Saf. 2024, 3, 243. [Google Scholar] [CrossRef]
- Wang, Z.; Cheng, J.; Zheng, H.; Zou, X.; Tao, F. Multistage Convolutional Autoencoder and BCM-LSTM Networks for RUL Prediction of Rolling Bearings. IEEE Trans. Instrum. Meas. 2023, 72, 2527713. [Google Scholar] [CrossRef]
- Nie, L.; Zhang, L.; Xu, S.; Cai, W.; Yang, H. Remaining Useful Life Prediction of Milling Cutters Based on CNN-BiLSTM and Attention Mechanism. Symmetry 2022, 14, 2243. [Google Scholar] [CrossRef]
- Guo, J.; Wang, J.; Wang, Z.; Gong, Y.; Qi, J.; Wang, G.; Tang, C. A CNN-BiLSTM-Bootstrap integrated method for remaining useful life prediction of rolling bearings. Qual. Reliab. Eng. Int. 2023, 39, 1796–1813. [Google Scholar] [CrossRef]
- Shi, W.; Dai, C.; Zhao, Y.; Wang, Y.; Wang, Z. Image Feature Fusion Change Detection Based on Stacked Denoising Auto-encoder. J. Geomat. Sci. Technol. 2021, 38, 391–397. [Google Scholar]
- Zhang, G. Study on Gated Recurrent Unit and Convolution Auto Encoder for Fault Diagnosis and Remaining Useful Life Prediction. Master’s Thesis, Yanshan University, Qinhuangdao, China, June 2021. [Google Scholar]
- Wu, C. Detection of Pulmonary Nodules Based on Convolutional Auto Encoder Neural Network. Master’s Thesis, Huazhong University of Science & Technology, Wuhan, China, May 2017. [Google Scholar]
- Zhou, Q.; Ma, H.; Liu, M.; Li, X.; Wen, B. Fatigue damage identification based on Kullback-Leibler relative entropy for raw acoustic emission waveform. Mech. Syst. Signal Process. 2024, 220, 111658. [Google Scholar] [CrossRef]
- Li, W.; Ma, J.; Lei, X. Research on Fault Diagnosis for Asynchronous Motor Based on Approximate Entropy and Support Vector Machine. Mach. Tool Hydraul. 2021, 49, 173–176+155. [Google Scholar]
- David, C. Permutation entropy: Influence of amplitude information on time series classification performance. Math. Biosci. Eng. MBE 2019, 16, 6842–6857. [Google Scholar]
- Xiao, J.; Jin, J.; Li, C.; Xu, Z.; Sun, K. Research on Bearing Fault Diagnosis Based on Ceemdan Fuzzy Entropy and Convolutional Neural Network. J. Mech. Strength 2023, 45, 26–33. [Google Scholar]
- Fan, Y.; Yuan, R.; Lv, Y.; Dang, Z.; Song, H.; Zhu, W. Improved multiscale coded dispersion entropy: A novel quadratic-coded health indicator of rolling bearings. Meas. Sci. Technol. 2024, 35, 086120. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Y.; Han, Y.; Huangfu, P.; Ma, Z.; Shi, W.; Feng, K. The double-feature extraction method based on slope entropy and symbolic dynamic entropy for the fault diagnosis of rolling bearing. Signal Image Video Process. 2024, 18 (Suppl. S1), 211–226. [Google Scholar] [CrossRef]
- Zhou, J.; Xiong, W.; Yin, W.; Li, J.; Gao, S. Performance Degradation Assessment Model of Rolling Bearings Combining VMD Symbol Entropy and SVDD. Mech. Sci. Technol. Aerosp. Eng. 2023, 42, 31–37. [Google Scholar]
- Zhao, Z.; Li, L.; Yang, S.; Li, Q. An Unsupervised Bearing Health Indicator and Early Fault Detection Method. China Mech. Eng. 2022, 33, 1234–1243. [Google Scholar]
- Xiang, S.; Zhao, C.; Hao, S.; Li, K.; Li, W. A reliability evaluation method for electromagnetic relays based on a novel degradation-threshold-shock model with two-sided failure thresholds. Reliab. Eng. Syst. Saf. 2023, 240, 109549. [Google Scholar] [CrossRef]
- Ding, W.; Li, J.; Mao, W.; Meng, Z.; Shen, Z. Rolling bearing remaining useful life prediction based on dilated causal convolutional DenseNet and an exponential model. Reliab. Eng. Syst. Saf. 2023, 232, 109072. [Google Scholar] [CrossRef]
- Wang, B.; Lei, Y.; Li, N.; Li, N. A hybrid prognostics approach for estimating remaining useful life of rolling element bearings. IEEE Trans. Reliab. 2020, 68, 401–412. [Google Scholar] [CrossRef]
- Lei, Y.; Han, T.; Wang, B.; Li, N.; Yan, T.; Yang, J. XJTU-SY Rolling Element Bearing Accelerated Life Test Datasets: A Tutorial. J. Mech. Eng. 2019, 55, 1–6. [Google Scholar]
- Gao, S. Research and Application Platform Development of Bearing Fault Diagnosis and Life Prediction Method Based on Deep Learning. Master’s Thesis, Hangzhou Dianzi University, Hangzhou, China, March 2023. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Working Condition | Data Set | Sample Count | Basic Rated Life | Actual Life | Fault Type |
|---|---|---|---|---|---|
| 1 | Bearing1_1 | 123 | 5.600–9.677 h | 2 h 3 min | Outer ring |
| Bearing1_2 | 161 | 2 h 41 min | Outer ring | ||
| Bearing1_3 | 158 | 2 h 32 min | Outer ring | ||
| Bearing1_4 | 122 | 2 h 2 min | Cage | ||
| Bearing1_5 | 52 | 52 min | Outer ring, Inner ring | ||
| 2 | Bearing2_1 | 491 | 6.786–11.726 h | 8 h 14 min | Inner ring |
| Bearing2_2 | 161 | 2 h 41 min | Outer ring | ||
| Bearing2_3 | 533 | 8 h 38 min | Cage | ||
| Bearing2_4 | 339 | 5 h 39 min | Outer ring | ||
| Bearing2_5 | 42 | 42 min | Outer ring | ||
| 3 | Bearing3_1 | 2538 | 8.468–14.632 h | 42 h 18 min | Outer ring |
| Bearing3_2 | 2496 | 41 h 36 min | Inner ring, Outer ring, Cage, rolling body | ||
| Bearing3_3 | 371 | 6 h 11 min | Inner ring | ||
| Bearing3_4 | 1515 | 25 h 15 min | Inner ring | ||
| Bearing3_5 | 114 | 1 h 54 min | Outer ring |
| CAE-BiLSTM | CAE | BiLSTM | |||||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | Score | RMSE | MAE | Score | RMSE | MAE | Score | |
| Bearing1_1 | 0.1286 | 0.1061 | 0.9978 | 0.3189 | 0.2845 | 0.9901 | 0.2674 | 0.1664 | 0.9871 |
| Bearing1_2 | 0.1227 | 0.0979 | 0.9967 | 0.4861 | 0.4257 | 0.9878 | 0.2784 | 0.1983 | 0.9886 |
| Bearing1_3 | 0.2303 | 0.1865 | 0.9977 | 0.4057 | 0.3745 | 0.9831 | 0.2458 | 0.2238 | 0.9926 |
| Bearing1_4 | 0.5411 | 0.4601 | 0.9931 | 0.7851 | 0.7032 | 0.9786 | 0.5987 | 0.5542 | 0.9884 |
| Bearing1_5 | 0.2198 | 0.1734 | 0.9970 | 0.3571 | 0.3020 | 0.9889 | 0.2978 | 0.2049 | 0.9912 |
| Bearing2_1 | 0.4114 | 0.3362 | 0.9947 | 0.5479 | 0.4204 | 0.9801 | 0.4687 | 0.4297 | 0.9857 |
| Bearing2_2 | 0.1988 | 0.1668 | 0.9972 | 0.2354 | 0.1876 | 0.9902 | 0.2025 | 0.1691 | 0.9924 |
| Bearing2_3 | 0.1745 | 0.1552 | 0.9967 | 0.3470 | 0.3057 | 0.9898 | 0.2671 | 0.2125 | 0.9935 |
| Bearing2_4 | 0.2088 | 0.1726 | 0.9912 | 0.4251 | 0.3584 | 0.9851 | 0.4114 | 0.3259 | 0.9854 |
| Bearing2_5 | 0.1796 | 0.1412 | 0.9964 | 0.2249 | 0.1754 | 0.9924 | 0.2003 | 0.1155 | 0.9945 |
| Bearing3_1 | 0.2864 | 0.2466 | 0.9939 | 0.3932 | 0.3230 | 0.9912 | 0.2871 | 0.2410 | 0.9910 |
| Bearing3_2 | 0.3997 | 0.3340 | 0.9900 | 0.5048 | 0.4125 | 0.9856 | 0.4125 | 0.3699 | 0.9849 |
| Bearing3_3 | 0.1540 | 0.1138 | 0.9977 | 0.3574 | 0.3061 | 0.9934 | 0.2579 | 0.2197 | 0.9918 |
| Bearing3_4 | 0.2907 | 0.2491 | 0.9906 | 0.3334 | 0.3091 | 0.9845 | 0.3082 | 0.2596 | 0.9890 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guan, P.; Zhang, T.; Zhou, L. RUL Prediction of Rolling Bearings Based on Multi-Information Fusion and Autoencoder Modeling. Processes 2024, 12, 1831. https://doi.org/10.3390/pr12091831
Guan P, Zhang T, Zhou L. RUL Prediction of Rolling Bearings Based on Multi-Information Fusion and Autoencoder Modeling. Processes. 2024; 12(9):1831. https://doi.org/10.3390/pr12091831
Chicago/Turabian StyleGuan, Peng, Tianrui Zhang, and Lianhong Zhou. 2024. "RUL Prediction of Rolling Bearings Based on Multi-Information Fusion and Autoencoder Modeling" Processes 12, no. 9: 1831. https://doi.org/10.3390/pr12091831