
A Novel ARX-Based Approach for the Steady-State Identification Analysis of Industrial Depropanizer Column Datasets


Abstract
:1. Introduction
2. Steady-State Identification Techniques
2.1. F-Like Test
- A filtering value is estimated from the data:where X is the process variable, Xf is the filtered value of X, λ1 is a filter factor and i is the time sampling index.
- The initial variances are calculated by the following exponentially weighted moving average:in which is the filtered value of a measure of variance based on the difference between process data and filtered values. Furthermore, is the previous variance filtered value, and λ2 is a filter factor for the variance.
- The second filtered variance estimate is computed as:where, once again, is the filtered value of a measure of variance based on the difference between data at different time units, is the previous filtered value and λ3 is another filter factor for the variance.
- The ratio based on the two variances corresponds to the SSI index and is obtained by the following equation:
2.2. Adaptive Polynomial
2.3. Wavelet-Based Method
2.4. Proposed ARX-Based Approach
3. Description of Case Studies
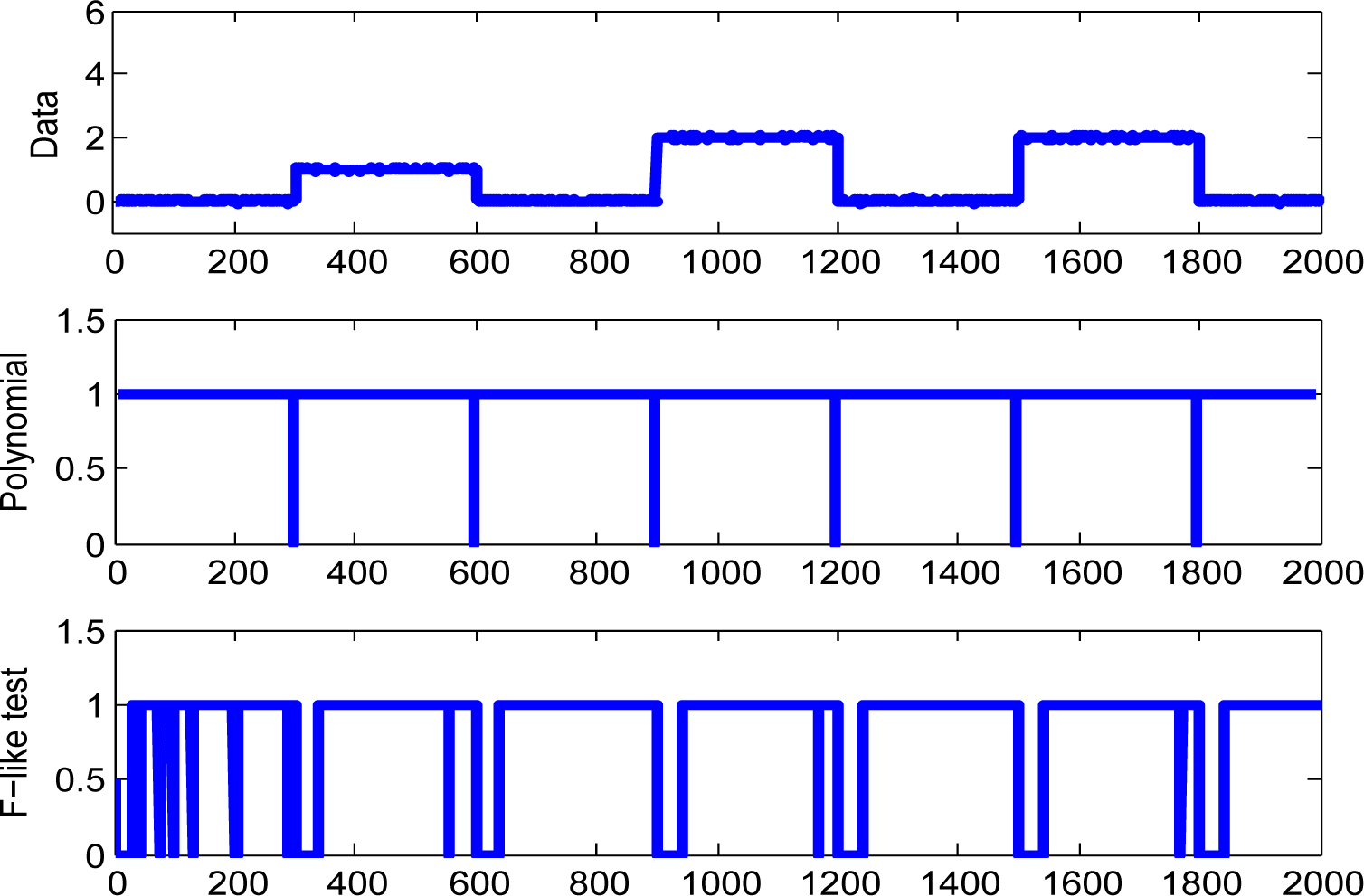
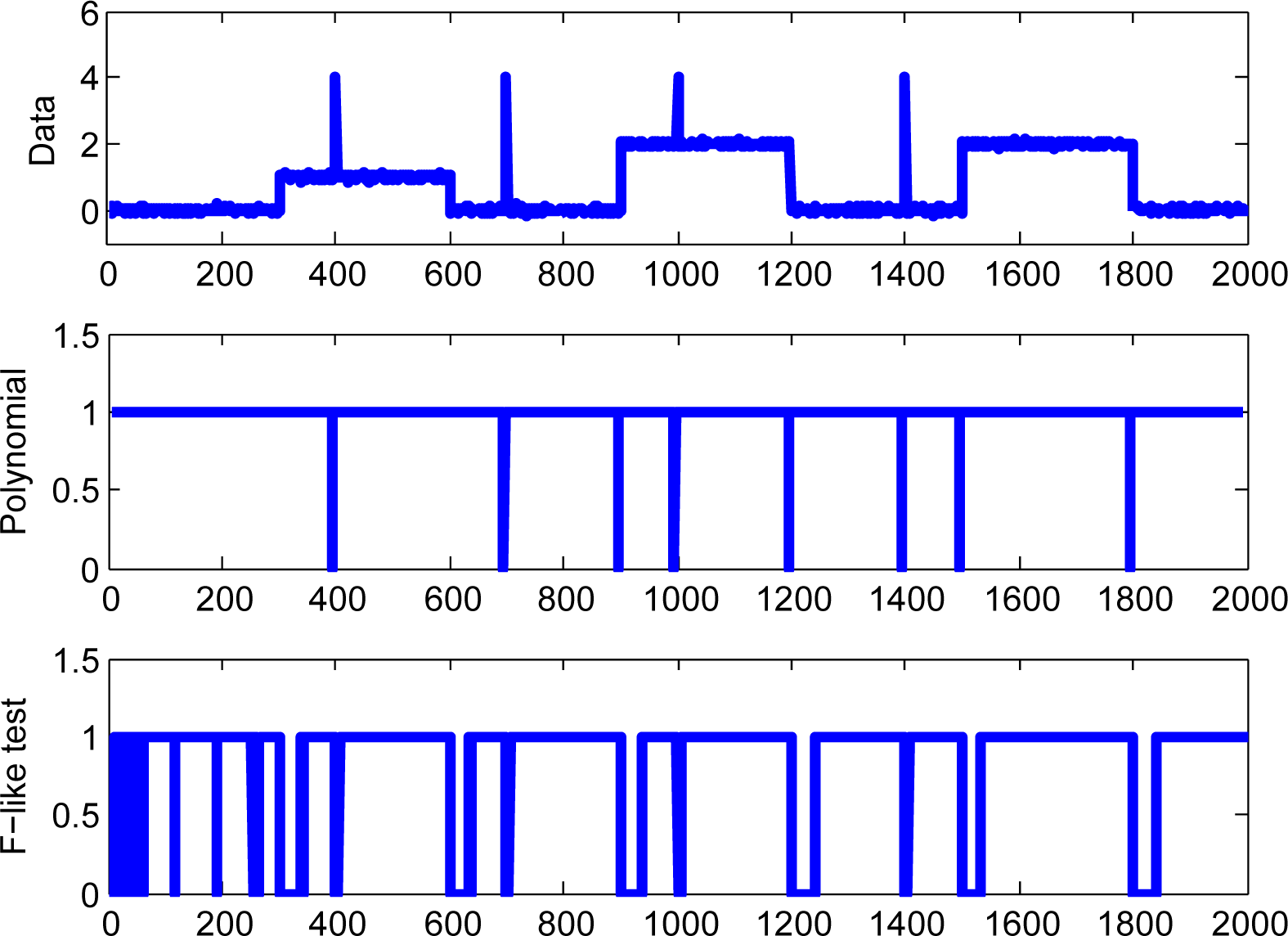
3.1. Simulated Dataset
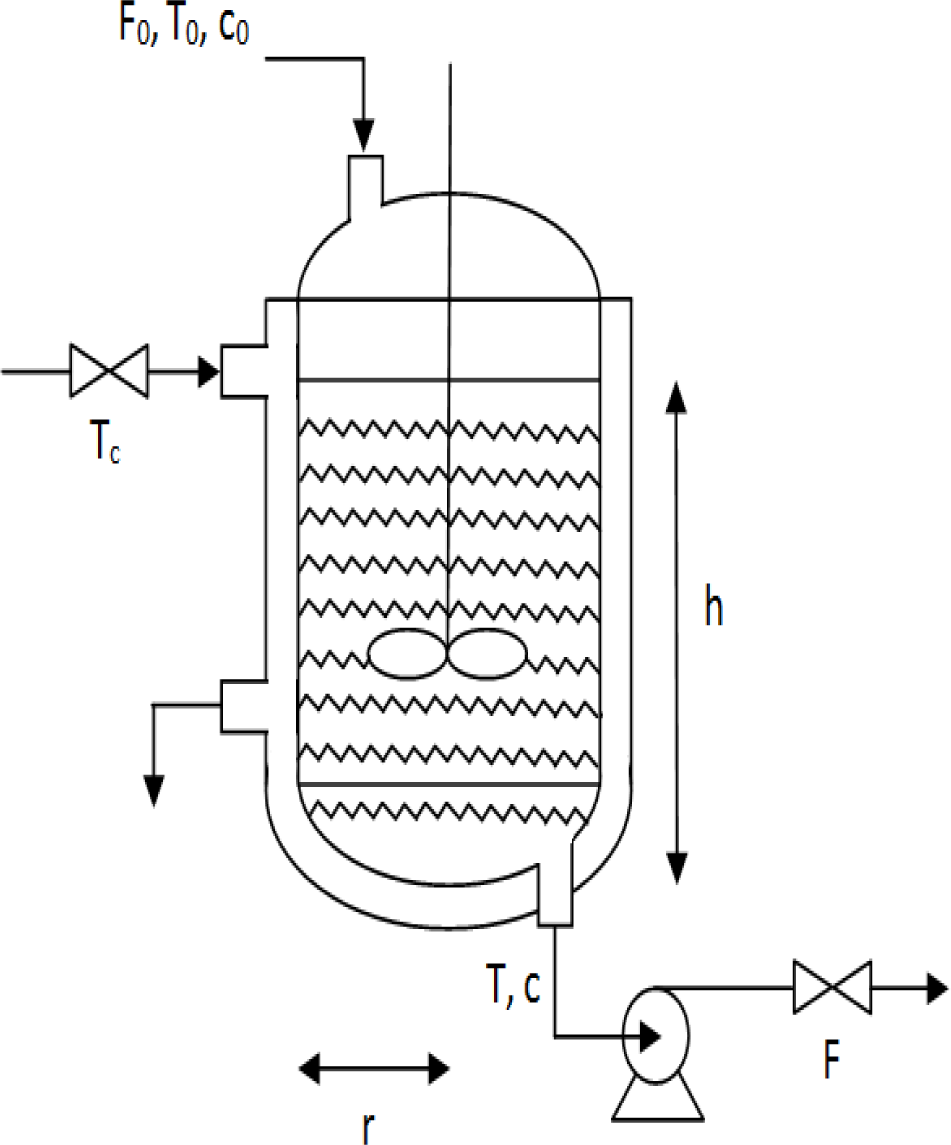
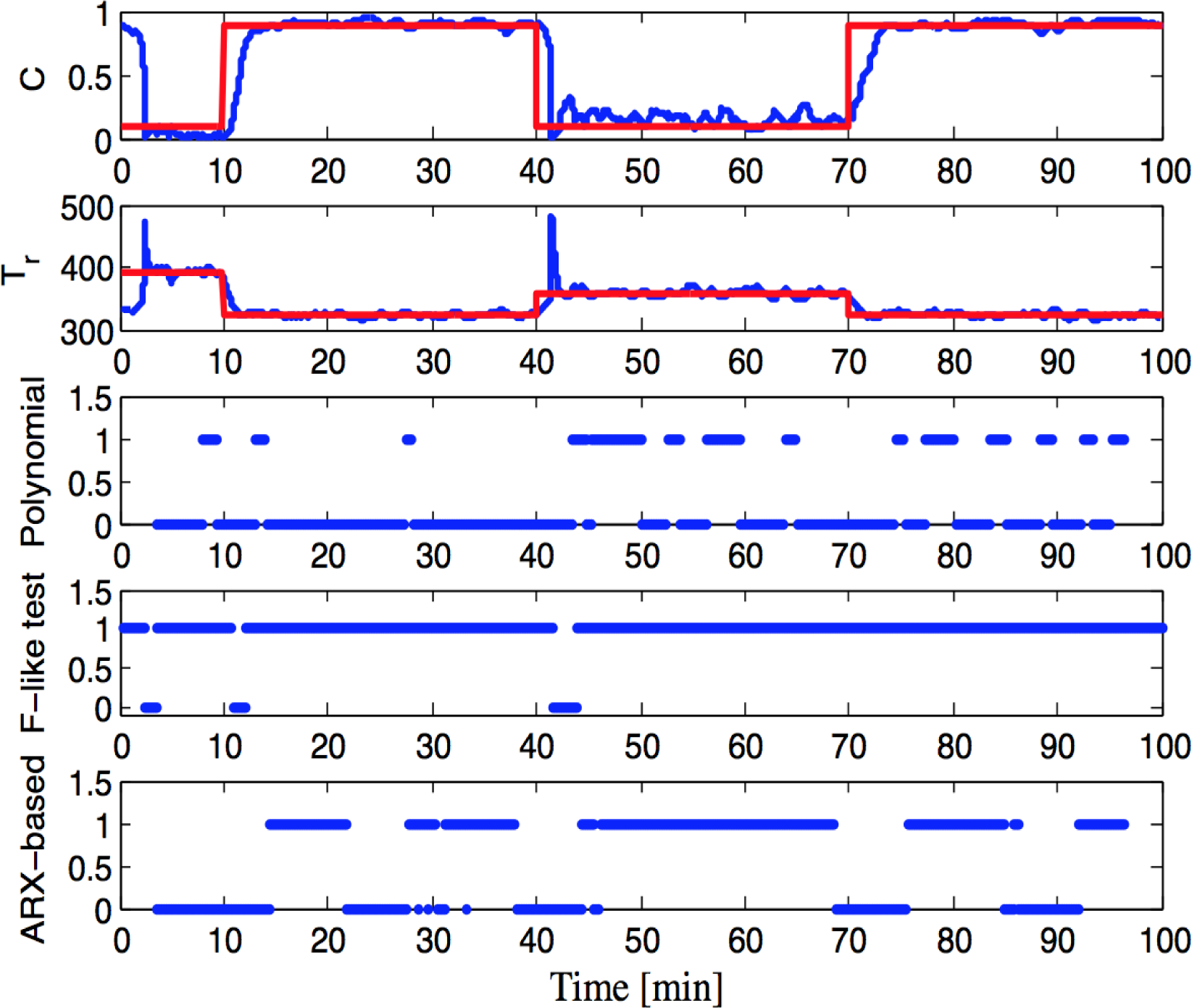
3.2. CSTR System
3.3. Industrial Depropanizer Column
4. Steady-State Identification Results
4.1. Simulated Data Example
4.2. CSTR System
4.3. Industrial Depropanizer Column
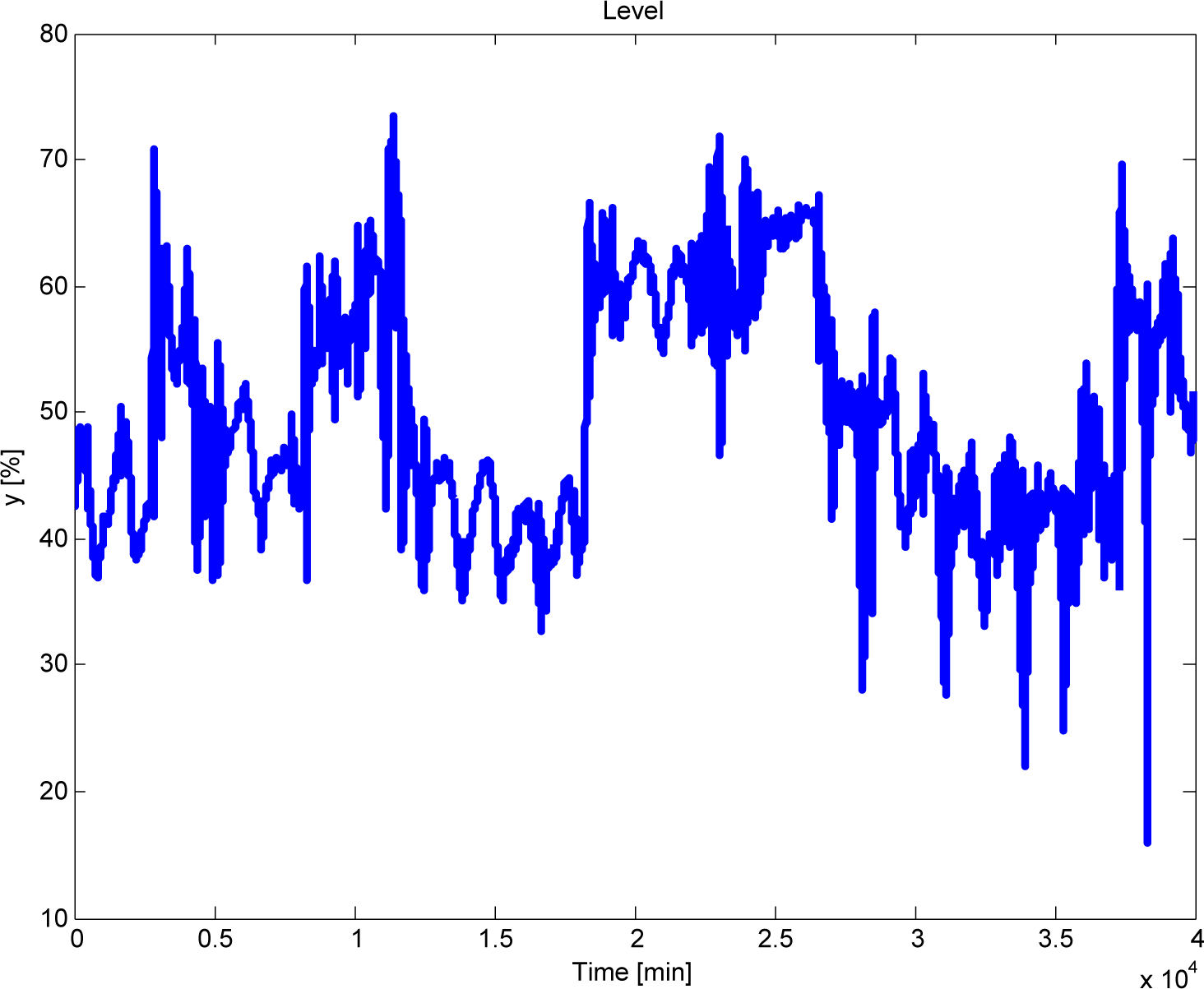
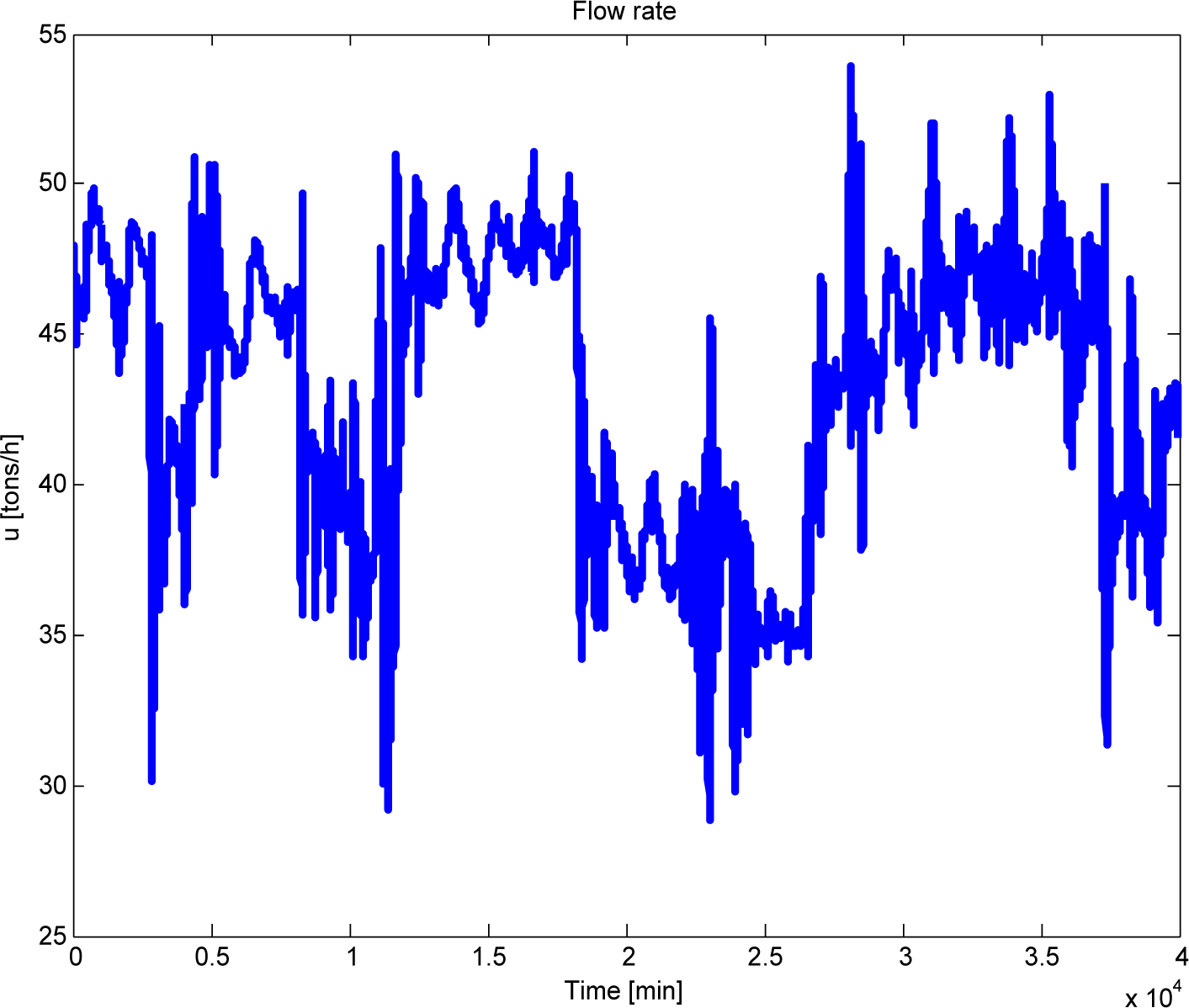
4.3.1. Analysis of the Reflux Drum (TA1)
4.3.2. Loop Data from the Heat Exchanger (HX4)
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Biegler, L.T.; Lang, Y.; Lin, W. Multi-scale optimization for process systems engineering. Comput. Chem. Eng. 2014, 60, 17–30. [Google Scholar]
- Korbel, M.; Bellec, S.; Jiang, T.; Stuart, P. Steady state identification for on-line data reconciliation based on wavelet transform and filtering. Comput. Chem. Eng. 2014, 63, 206–218. [Google Scholar]
- Rhinehart, R.R. Automated steady and transient state identification in noise processes. Proceedings of the American Control Conference, Washington, DC, USA, 17–19 June 2013; pp. 4477–4493.
- Cao, S.; Rhinehart, R.R. An efficient method for on-line identification of steady state. J. Proc. Cont. 1995, 5, 363–374. [Google Scholar]
- Cao, S.; Rhinehart, R.R. Critical values for a steady-state identifier. J. Proc. Cont. 1997, 7, 149–152. [Google Scholar]
- Shrowti, N.; Vilankar, K.; Rhinehart, R.R. Type-II critical values for a steady-state identifier. J. Proc. Cont. 2010, 20, 885–890. [Google Scholar]
- Rhinehart, R.R. Automated steady-state identification: Experimental demonstrations. J. Proc. Anal. Chem. 2002, 7, 1–4. [Google Scholar]
- Rhinehart, R.R. A statistically based filter. ISA Trans. 2002, 41, 167–175. [Google Scholar]
- Vennavelli, A.N.; Resetarits, M.R. Demonstration of the SS and TS Identifier at the Fractionation Research, Inc. (FRI) Distillation Unit, Proceedings of the American Control Conference, Washington, DC, USA, 17–19 June 2013; pp. 4494–4497.
- Brown, P.R.; Rhinehart, R.R. Demonstration of a method for automated steady-state identification in multivariable system. Hydrocarb. Process 2000, 79, 79–83. [Google Scholar]
- Iyer, M.S.; Rhinehart, R.R. A novel method to stop neural network training. Proceedings of the American Control Conference, Chicago, IL, USA, 28–30 June 2000; pp. 929–933.
- Rhinehart, R.R.; Su, M.; Manimegalai-Sridhar, U. Leapfrogging and synoptic Leapfrogging: A new optimization approach. Comput. Chem. Eng. 2012, 40, 67–81. [Google Scholar]
- Bhat, A.S.; Saraf, D.N. Steady-state identification, gross error detection, and data reconciliation for industrial process units. Ind. Eng. Chem 2004, 43, 4323–4336. [Google Scholar]
- Kim, M.; Yoon, S.H.; Domanski, P.A.; Payne, W.V. Design of a steady-state detector for fault detection and diagnosis of a residential air conditioner. Int. J. Refriger 2008, 31, 790–799. [Google Scholar]
- Kelly, J.D.; Hedengren, J.D. A steady-state detection (SSD) algorithm to detect non-stationary drifts in processes. J. Proc. Cont. 2013, 23, 326–331. [Google Scholar]
- Flehmig, F.; Marquardt, W. Inference of multi-variable trends in unmeasured process quantities. J. Proc. Cont. 2008, 18, 491–503. [Google Scholar]
- Jiang, T.; Chen, B.; He, X. Industrial application of Wavelet Transform to the on-line prediction of side draw qualities of crude unit. Comput. Chem. Eng 2000, 24, 507–512. [Google Scholar]
- Jiang, T.; Chen, B.; He, X.; Stuart, P. Application of steady-state detection method based on wavelet transform. Comput. Chem. Eng. 2002, 27, 569–578. [Google Scholar]
- Korbel, M.; Bellec, S.; Jiang, T.; Stuart, P. Steady state identification for on-line data reconciliation based on wavelet transform and filtering. Comput. Chem. Eng. 2014, 63, 206–218. [Google Scholar]
- Yao, Y.; Zhao, C.; Gao, F. Batch-to-batch steady state identification based on variable correlation and mahalanobis distance. Ind. Eng. Chem. 2009, 48, 11060–11070. [Google Scholar]
- Le Roux, G.A.C.; Santoro, B.F.; Sotelo, F.F.; Teissier, M.; Joulia, X. Improving steady-state identification, Proceedings of the 18th European Symposium on Computer Aided Process Engineering, ESCAPE 18, Lyon, France, 1–4 June 2008; pp. 459–464.
- Tao, L.; Li, C.; Kong, X.; Qian, F. Steady-state identification with gross errors for industrial process units, Proceedings of the 10th World Congress on Intelligent Control and Automation, Beijing, China, 6–8 July 2012; pp. 4151–4154.
- Pannocchia, G.; Rawlings, J.B. Disturbance models for offset-free model-predictive control. AIChE J 2003, 49, 426–437. [Google Scholar]
- Henson, M.A.; Seborg, D.E. Nonlinear Process Control; Prentice Hall PTR: Upper Saddle River, NJ, USA, 1997. [Google Scholar]
- Findeisen, R.; Allgöwer, F. An introduction to nonlinear model predictive control. Proceedings of the 21st Benelux Meeting on Systems and Control, Veldhoven, The Netherlands, 19–21 March 2002; 11, pp. 119–141.
- Brooke, A.; Kendrick, D.; Meeraus, A.; Raman, R. User’s Guide; GAMS Development Corporation: Washington DC, USA, 1998. Available online: http://www.gams.com accessed on 4 January 2015.
- Wachter, A.; Biegler, L.T. On the implementation of primal-dual interior point filter line search algorithm for large-scale nonlinear programming. Math. Program 2006, 106, 25–57. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Name | Value |
|---|---|---|
| k0 | frequency factor | 7.210 × 1010 min−1 |
| F0 | inlet flow rate | 0.1 m3/min |
| C0 | concentration of A in the inlet flow | 1 mol/m3 |
| r | radius of the tank | 0.219 m |
| Tc | coolant liquid temperature | 300 K |
| U | heat transfer coefficient | 54,936 J/(min m2 K) |
| h | level of the tank | 0.659 m |
| E/R | activation energy and gas constant | 8.75 × 103 |
| T0 | temperature of the inlet flow | 350 K |
| −∆H | heat of reaction | 5.7 J/mol |
| ρ | density | 1 × 103 kg/K |
| Cp | specific heat capacity | 239 J/(kg K) |
| Frequency | F-Like Test | Wavelet | ARX-Based |
|---|---|---|---|
| 1 | 37% | 30% | 46% |
| 3 | 50% | 60% | 83% |
| 5 | 56% | 88% | 92% |
© 2015 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rincón, F.D.; Roux, G.A.C.L.; Lima, F.V. A Novel ARX-Based Approach for the Steady-State Identification Analysis of Industrial Depropanizer Column Datasets. Processes 2015, 3, 257-285. https://doi.org/10.3390/pr3020257
Rincón FD, Roux GACL, Lima FV. A Novel ARX-Based Approach for the Steady-State Identification Analysis of Industrial Depropanizer Column Datasets. Processes. 2015; 3(2):257-285. https://doi.org/10.3390/pr3020257
Chicago/Turabian StyleRincón, Franklin D., Galo A. C. Le Roux, and Fernando V. Lima. 2015. "A Novel ARX-Based Approach for the Steady-State Identification Analysis of Industrial Depropanizer Column Datasets" Processes 3, no. 2: 257-285. https://doi.org/10.3390/pr3020257