1. Introduction
In the pharmaceutical industry, mathematical models are an integral part of the quality by design (QbD) paradigm [
1,
2,
3]. Mathematical models may be white-box (mechanistic), black-box (empirical), or gray-box (hybrid). White-box models are based on a mechanistic understanding of the underlying physical, chemical phenomena that are well understood (e.g., the Arrhenius equation). Black-box models are data-driven models that do not consider any physics behind an operation and are valid only in a very specific region of operation. Gray-box models combine both a theoretical understanding and empirical data. As complete mechanistic models can be very expensive to build, most models used in the industry fall in the empirical or hybrid categories.
Inevitably, the experimental data used to build such a model affects the estimated values of the model parameters and hence the model predictions. A modeler must thus carefully design the experiment such that the information content in the data is maximized to obtain the most accurate parameter estimates [
4]. However, even with well designed and accurate experiments, some variability is inherent to the modeling process. This variability arises from a lack of measurement samples (both number and repetitions), the noise that corrupts measurements, and the intrinsic stochastic nature of certain processes such as breakage or aggregation [
5]. Uncertainty refers to the precision of the parameters estimated from given data. In many cases, this uncertainty is described by the confidence interval of the parameter estimate. If decisions must be made using models with uncertain parameters, it is important that how uncertainty affects model prediction is known.
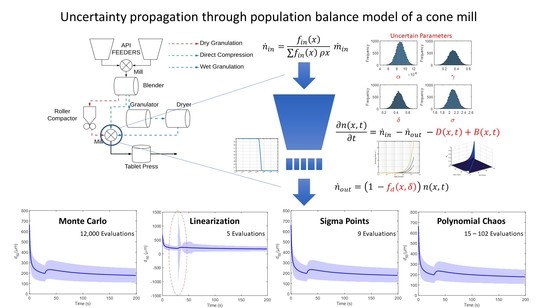
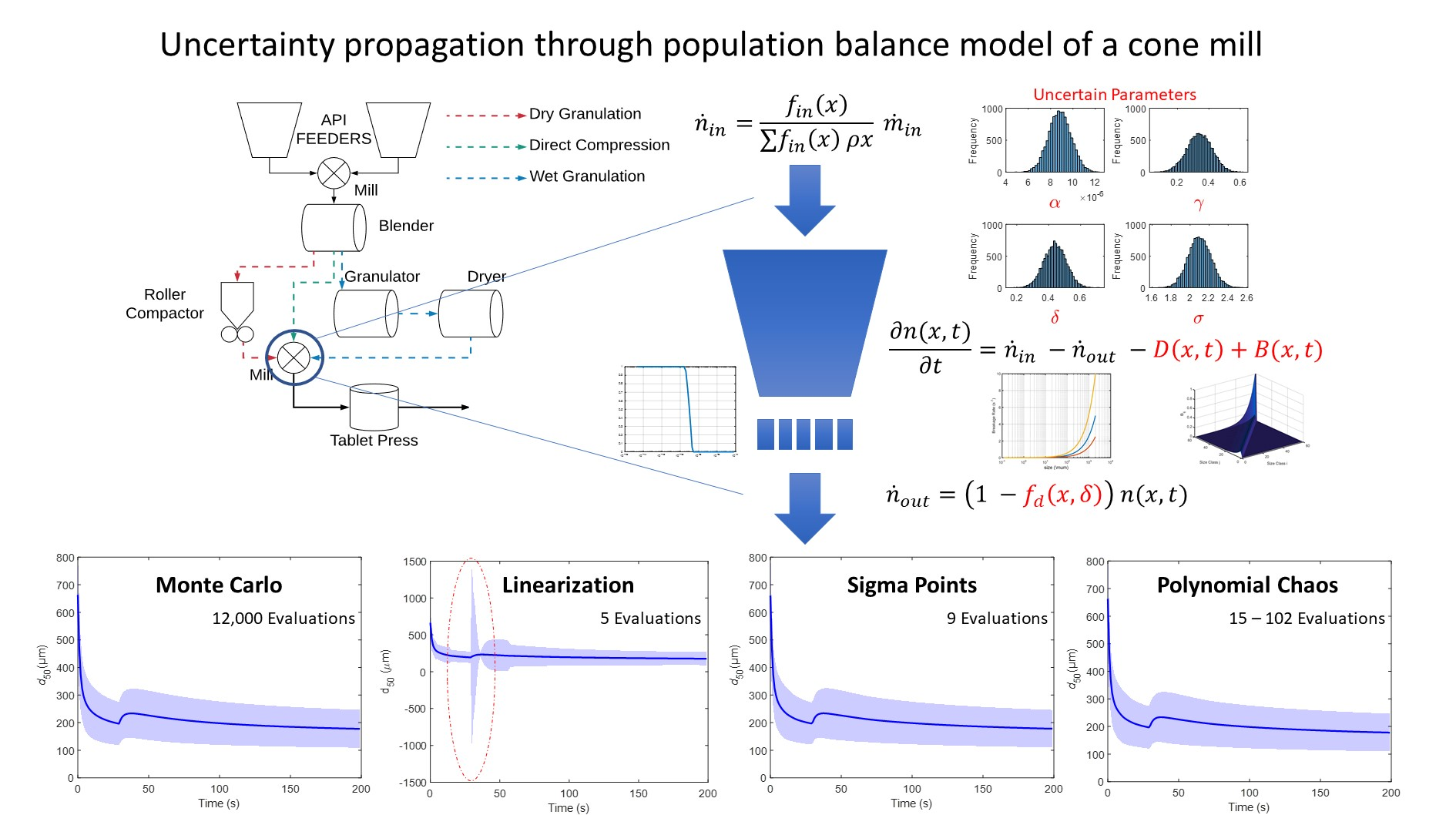
This work describes how the accuracy of a model prediction can be described from the confidence intervals of the estimated parameters. The focus lies on model of conical screen mill developed by Barasso et al. [
6]. The conical screen mill is a popular size reduction equipment used to delump blended active pharmaceutical ingredients (APIs), break tablets for recovery, or deliver a specific reduced particle size. A classical way of modeling milling equipment is by using the population balance framework [
7]. Under the assumption of well-mixedness, population balance models (PBMs) are hybrid models which can describe the temporal change in the particle number density in a physical volume through
with initial condition
describes the particle number density as a function of time,
t, and the
internal state vector,
. The internal state vector defines the properties which are used to describe the number densities in the distribution, e.g., concentration, porosity, and particle size. The second term in the equation describes the continuous change over the internal state vector arising from processes such as crystal growth, consolidation, or evaporation. Processes involving the appearance or disappearance of particles at discrete points in the internal state vector (e.g., aggregation or breakage) are not taken into account by this term but by the birth and death terms on the right-hand side:
and
, respectively. In many cases, a one-dimensional (1D) PBM is formulated using only the particle size (
x) as the internal state vector. However, multidimensional PBMs considering properties such as concentration or porosity can easily be formulated to account for complex situations that can arise. In case of a pure breakage process, such as the conical screen mill, the above equation can be reduced to a one-dimensional PBM as
The term on the right-hand side of the equation represents the birth of the particle by the breakage process. The breakage function is the probability function describing the formation of particles with size x by the breakage of the particles with size y. The selection function describes the rate of breakage of particles with size x. The term on the right describes the death of the particle because of breakage. The selection function and the breakage distribution function are normally empirical functions whose parameters need to be estimated from a given experimental dataset.
In this work, the cone mill model developed in [
6] is used as a predictive model. The uncertainty in the parameters is propagated to the median particle size
. The
is a common size indicator used in the pharmaceutical industry to describe the size of an API. In many cases, design decisions are based on the
, making it a critical quality attribute (CQA). As such, it is important that the accuracy of the
value predicted from the model is known. In the pharmaceutical industry, the most common method used is the Monte Carlo method. This method works well for relatively simple models which are not computationally expensive. However, for complex expensive models, Monte Carlo quickly becomes unattractive due to the computational time required. The aim of this work is to present other methods that can be used to propagate uncertainty through a nonlinear model, without requiring excessive sampling as in the Monte Carlo method. Three uncertainty propagation techniques are considered for comparison: linearization, sigma points, and polynomial chaos expansion (PCE). As no analytical steady state solution is available for the PBM, these methods will be evaluated against the Monte Carlo method. In case the analytical solution is available, the accuracy of the techniques could be compared using an error norm (e.g., [
8]). All four methods are described in detail in
Section 2.1. The cone mill model and its parameters are described in
Section 2.2. The numerical method used to solve the PBM is briefly described in
Section 2.3. This study will not discuss or compare the various discretization schemes available to solve the PBMs numerically.
3. Results
Four parameters-critical screen parameter
, the two selection function parameters
, and breakage distribution parameter
, are considered uncertain for this study. These parameters are assumed to be Gaussian random variables, with the mean as the nominal value and the standard deviation described in
Table 1.
The model is used to predict the
of the API exiting the mill. The mill is operated with a 1575
m sieve and an impeller speed of 4923 RPM. After
of operation, the impeller speed is changed to 1500 RPM. This is done to highlight the benefits and drawbacks of the various methods considered here. All the computations are carried out in MATLAB 2017b (The MathWorks Inc., Natick, MA, USA). The PBM is solved by discretizing the model using the fixed pivot technique described in
Section 2.3. The discretization leads to a system of differential algebraic equations, which was solved using a variable order numerical difference formula (
ode15s function). Normally, the choice of discretization also affects the solution. In this study, only the fixed pivot method with 100 grid points is considered. A comparison of various discretization schemes for the cone mill is provided in [
25].
All the methods will be compared at time just after the impeller speed is changed. This region represents the maximum dynamic change in the model and, as such, can be used to critically evaluate the methods. As the set point change is induced after 30 s, the evaluation is carried out on the value at 31 s. The uncertainty bands in all cases refer to the 95% confidence intervals calculated based on the F-distribution.
3.1. The Monte Carlo Method
The Monte Carlo variance decays as
, with
N being the number of samples. Thus, if a large number of samples are used, the Monte Carlo method can be considered the most accurate. However, the results of the Monte Carlo depend on the number of samples that are drawn from the given distribution. Some studies discuss the methods for determining the number of iterations required in the Monte Carlo method. However, these calculations are not always feasible in practice. Thus, the appropriate number of iterations must be determined empirically.
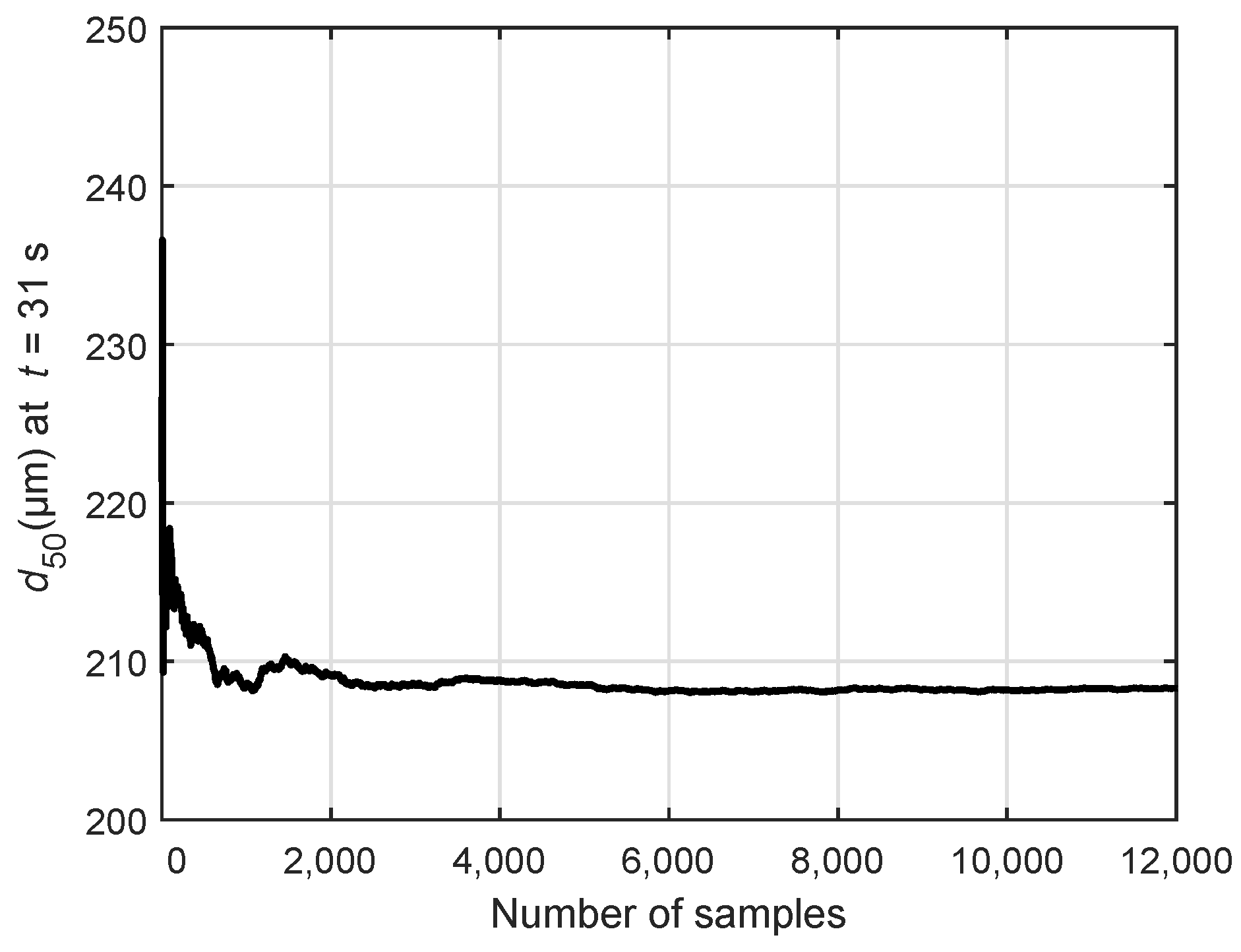
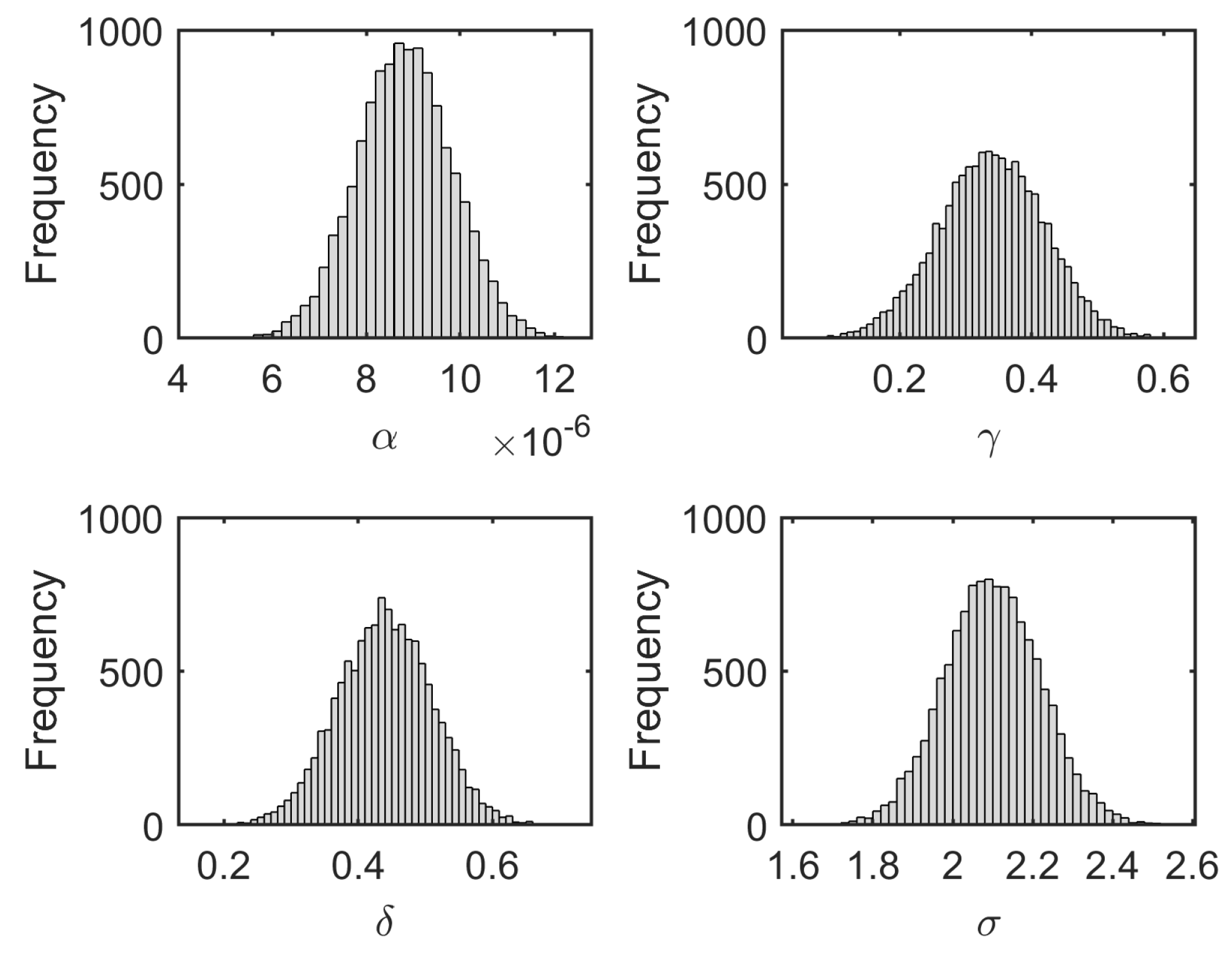
Figure 1 illustrates the mean value of the
for a different number of samples. It can be seen that the mean value stabilizes above 4000 samples. Thus, at least 5000 samples should be used to obtain reliable information from the Monte Carlo simulations. For further comparison, 12,000 samples are drawn from a normal distribution as depicted in
Figure 2. The
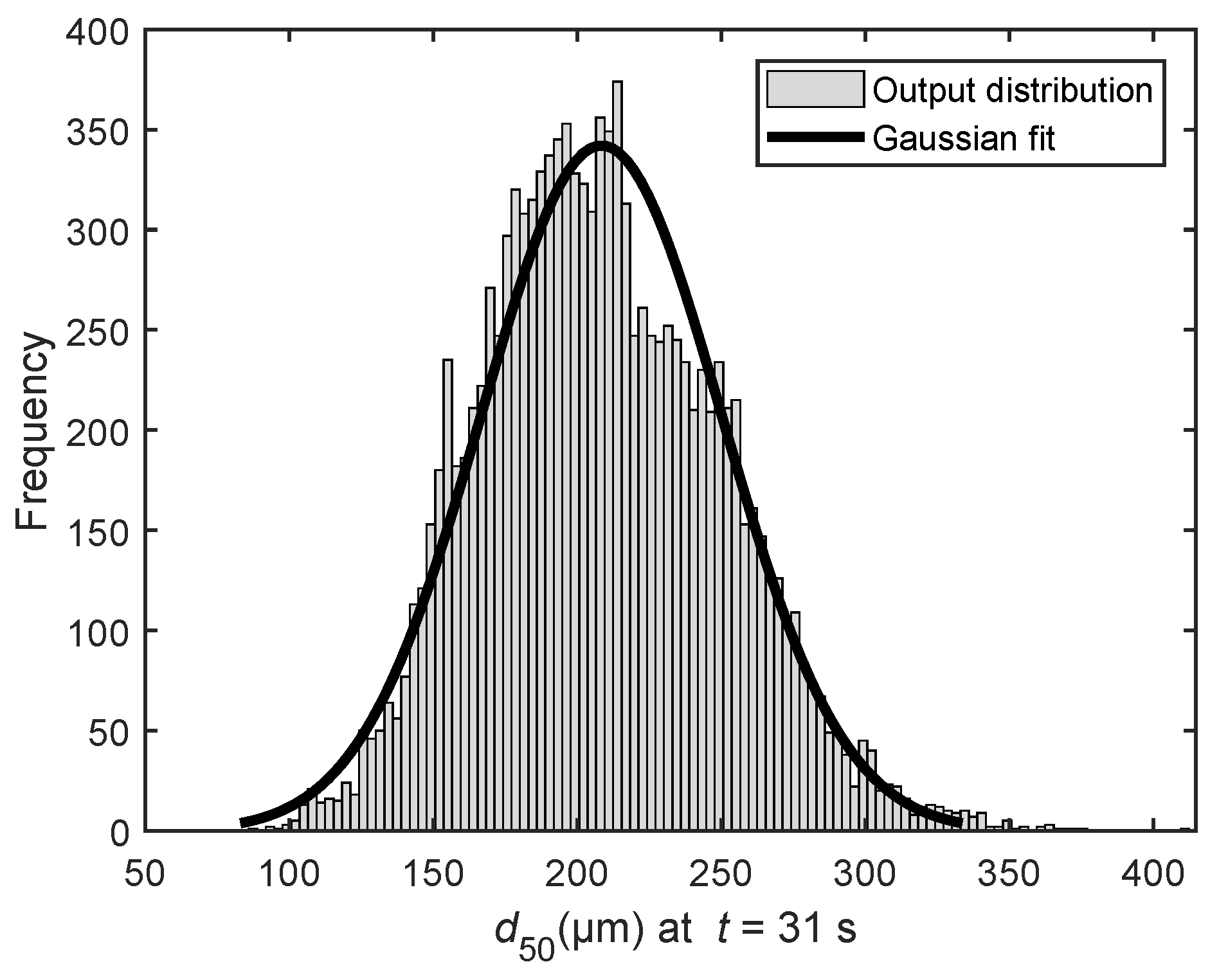
distribution at 31 s is depicted in
Figure 3. This output is tested for normality using the Kolmogrov–Smirnov (KS) test. It should be noted that, even after 12,000 model evaluations, the KS test rejects the hypothesis that the output could be drawn from a normal distribution. Thus, more samples would be required to evaluate the true variance of the distribution. For this study, the distribution is fit to a normal curve. It is observed that, for the
value at 31 s, the distribution fit has a mean of 208.366 ± 0.741
m and a standard deviation of 41.7409 ± 0.5177
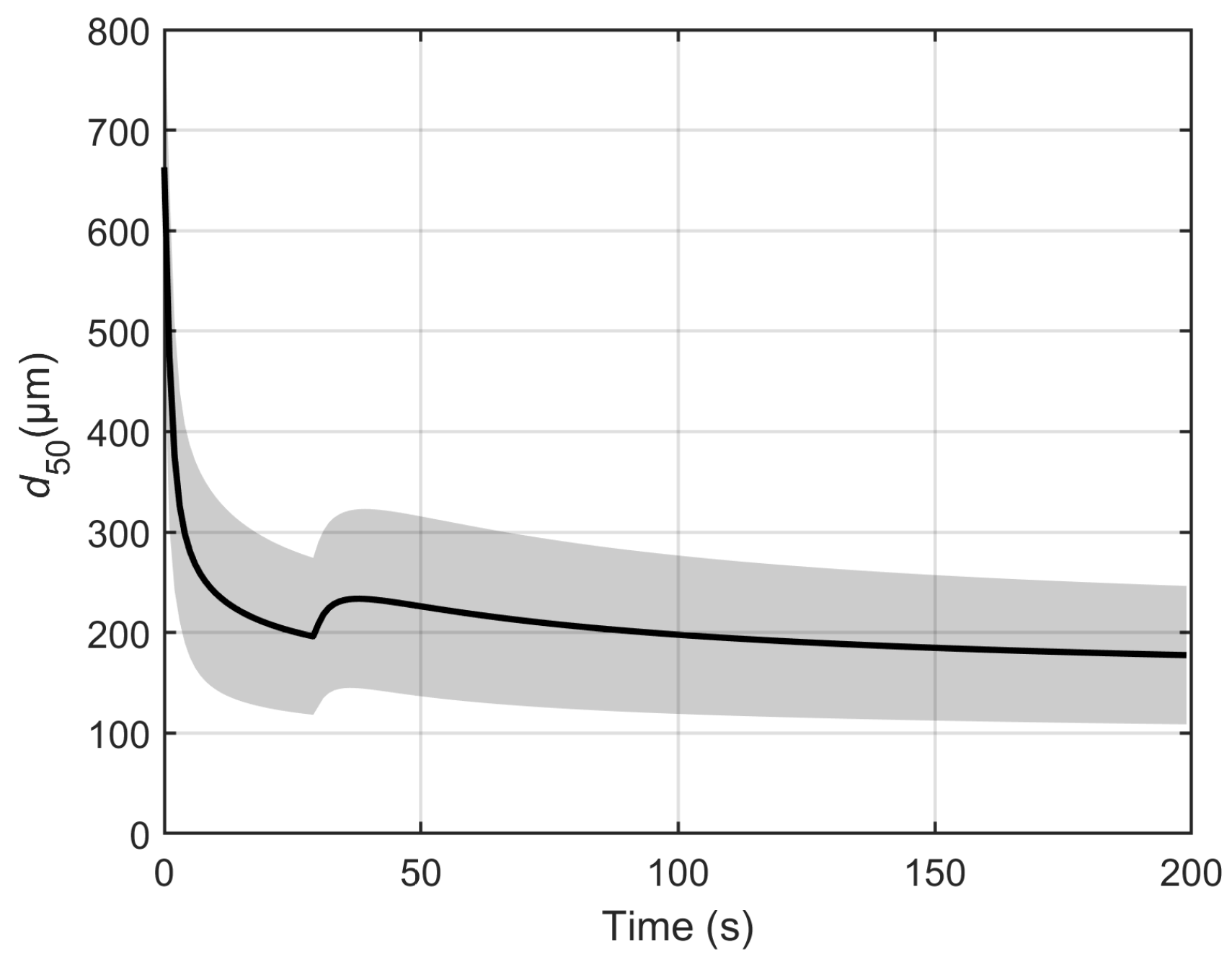
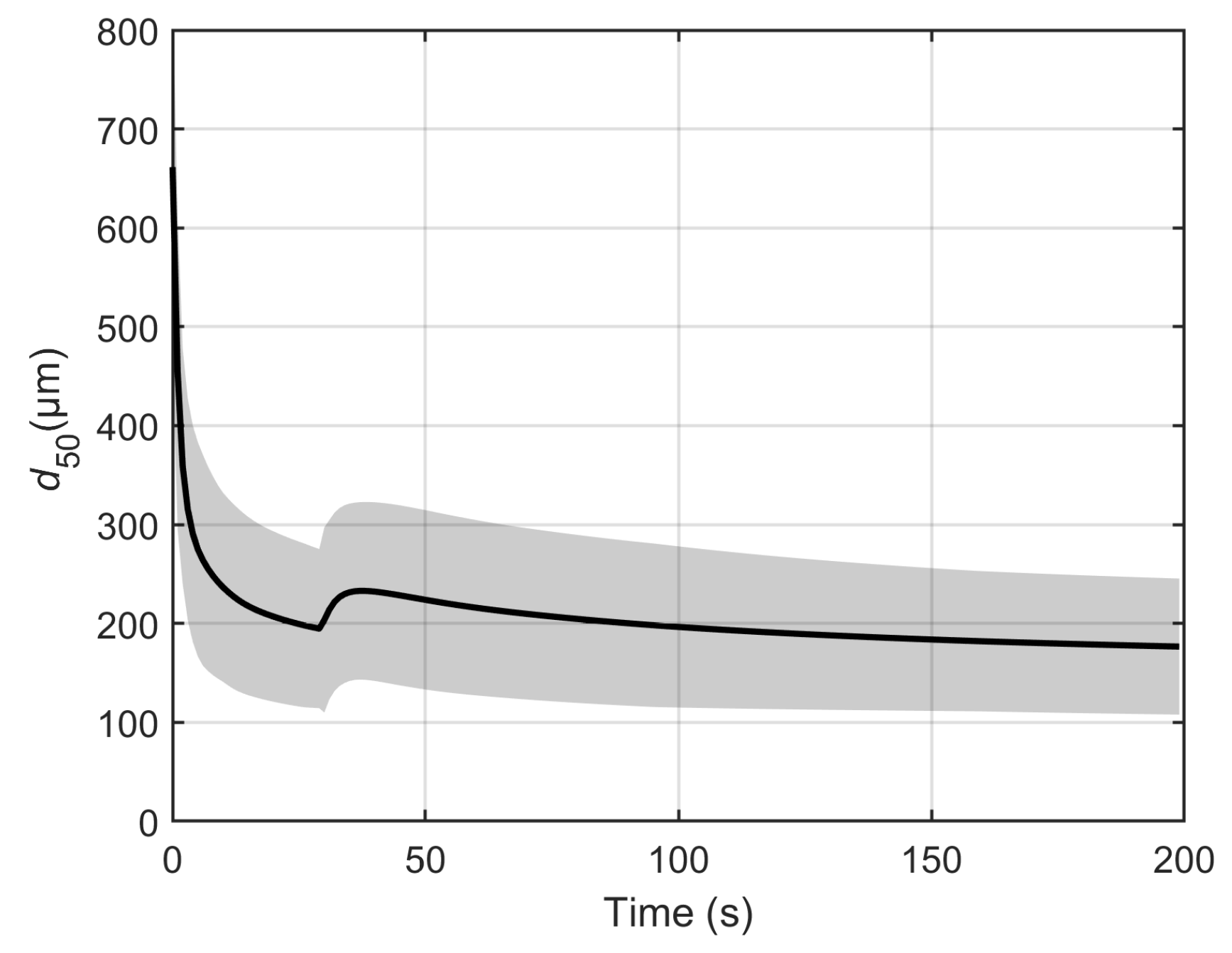
m. This fit is considered good enough to use 12,000 Monte Carlo samples to quantify the uncertainty. The result of the Monte Carlo simulation over the entire time is shown in
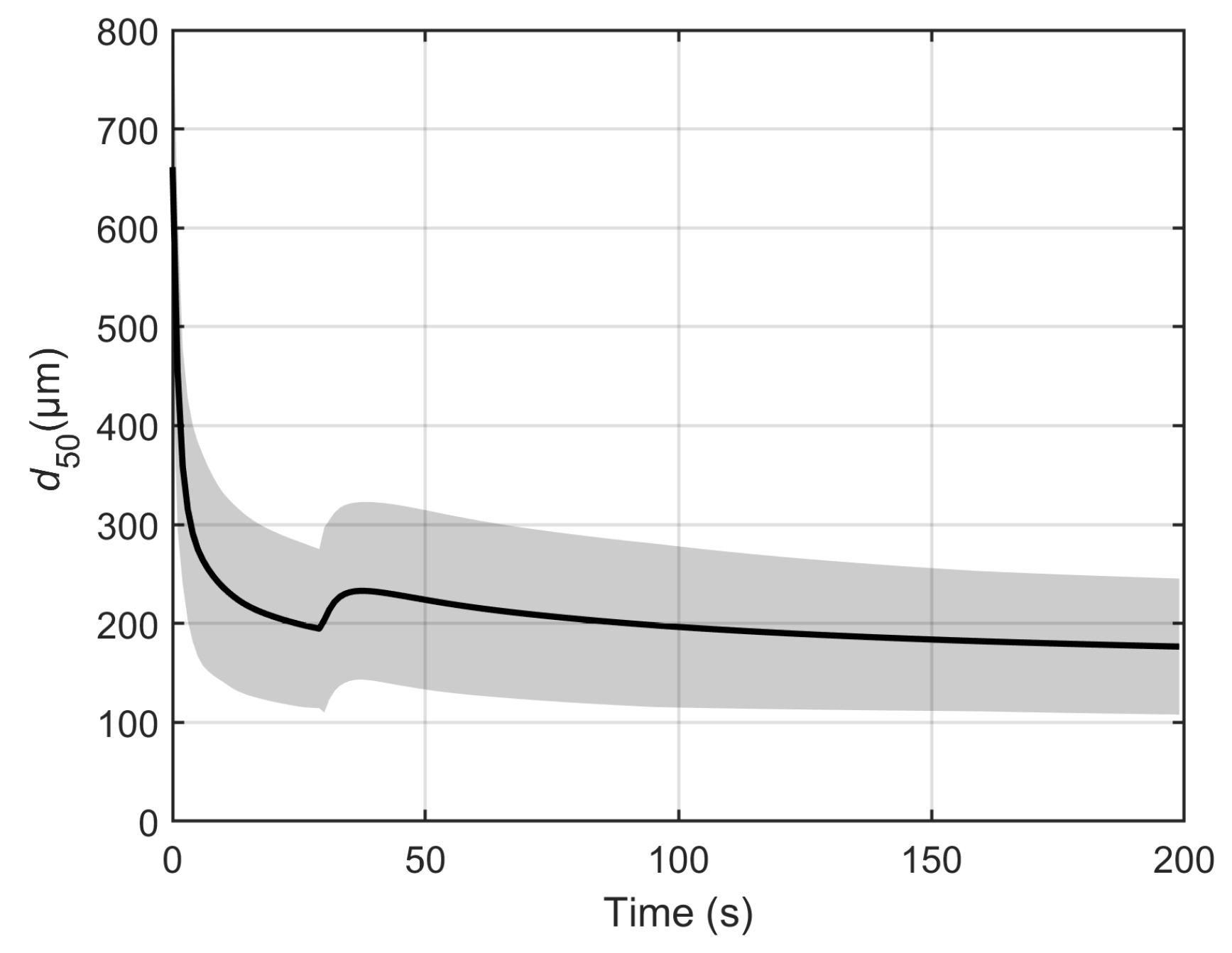
Figure 4.
As such, the three other methods will be compared to the solution from the Monte Carlo method.
3.2. Linearization Method
The main advantage of the linearization method is its ease of implementation and relatively low computational burden. The Jacobian matrix required can be calculated numerically. In this study, a simple finite difference scheme is used to calculate the Jacobian.
The deviation was chosen to be times the nominal parameter value. Thus, for the current system, with four uncertain parameters, the linearization method is required to evaluate the model five times to determine the Jacobian.
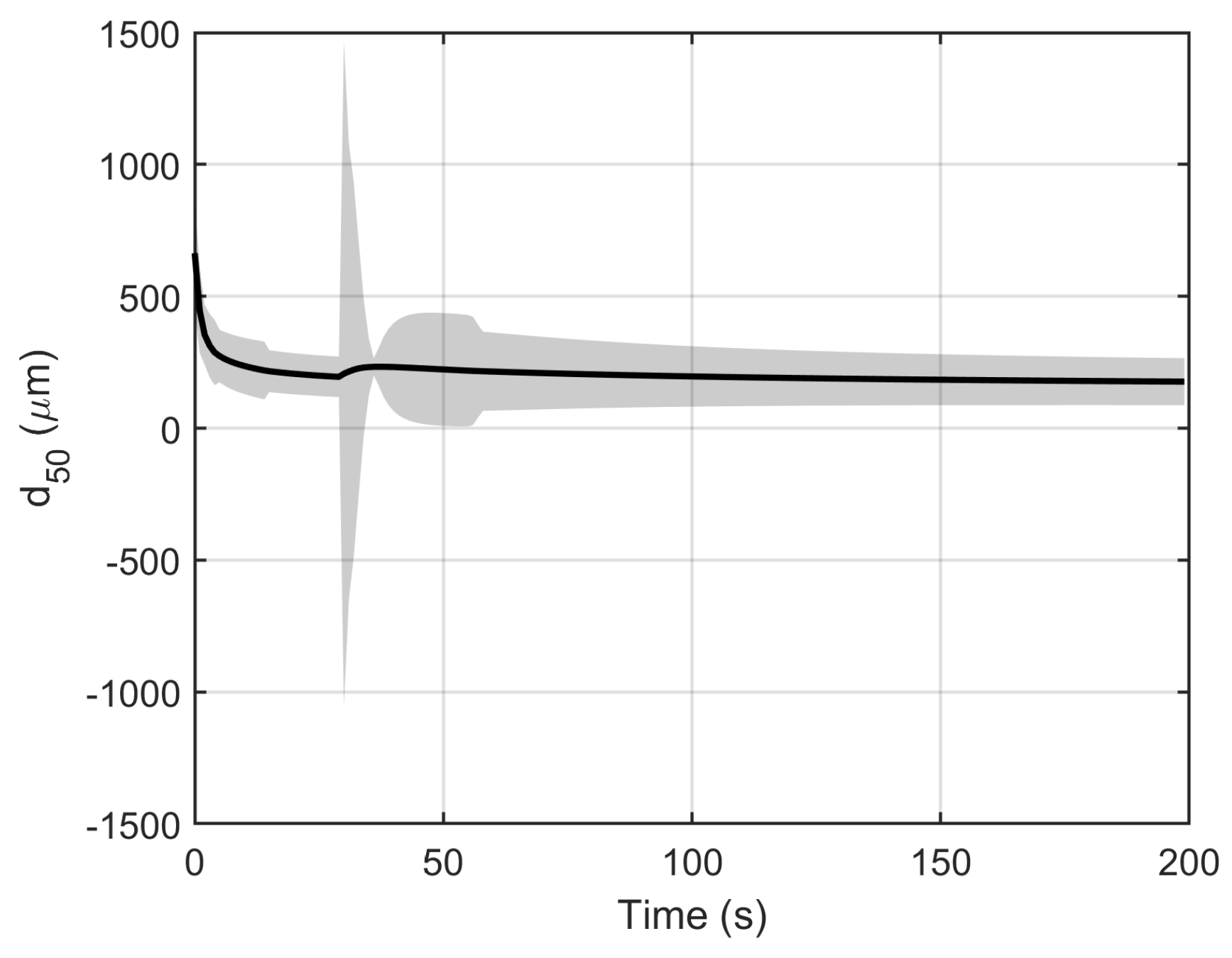
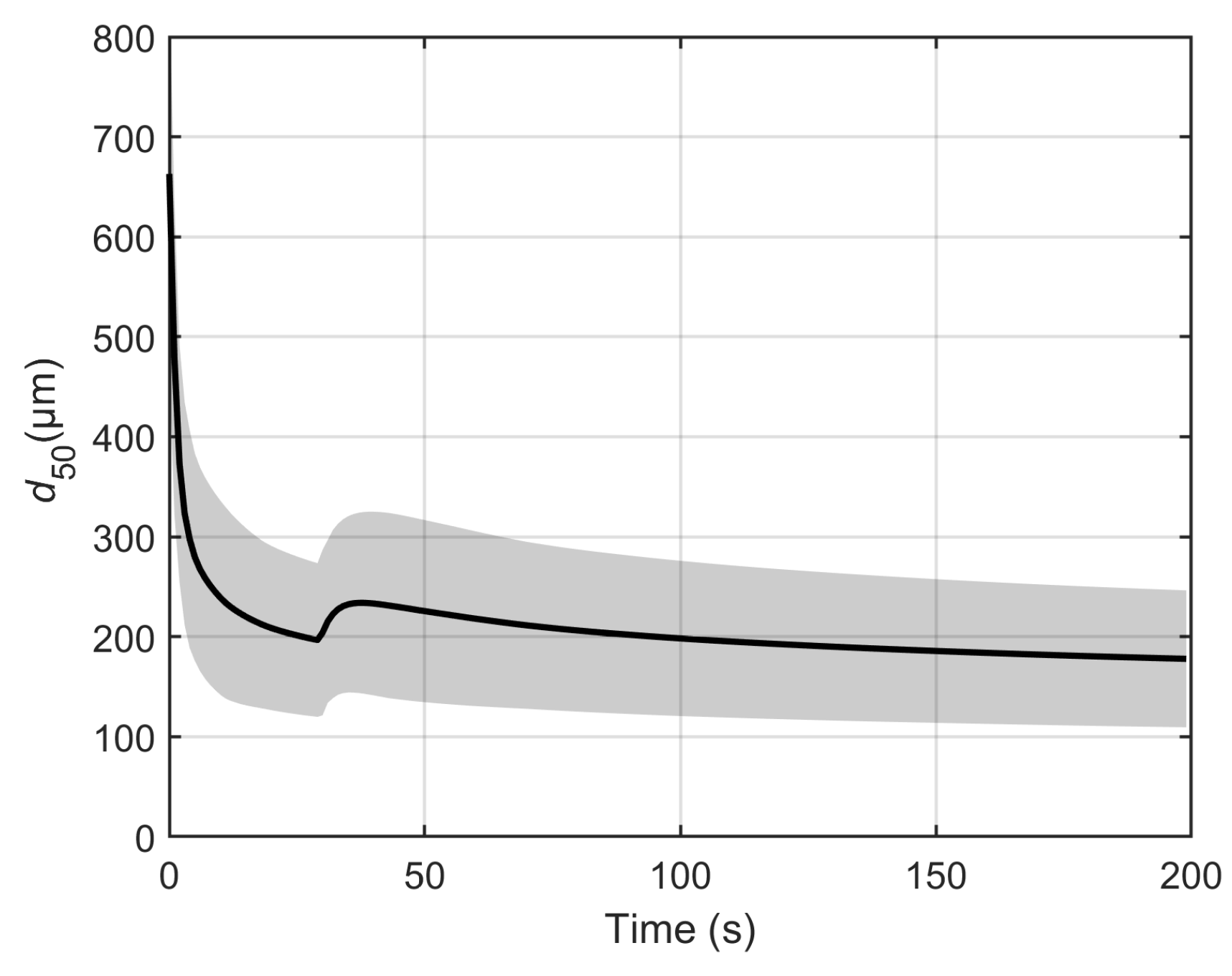
The result of the linearization method is depicted in
Figure 5. It can be observed that, in some regions of operation (after 100 s), the linearization method yields a good approximation of the uncertainty. However, it overpredicts the uncertainty in regions of high system dynamics. As the evaluation of Jacobian is extremely sensitive to model curvature, linearization completely fails in regions of high model dynamics. This is evident from
Figure 5. At the moment the setpoint change is induced (30 s), linearization grossly overpredicts the uncertainty associated with model prediction. Thus, linearization should be used with caution, especially when there are dynamic conditions to which the model is sensitive.
3.3. Sigma Point Method
With four uncertain parameters, nine sigma points need to be calculated, and the model is evaluated at these sampling points. As can be observed from
Figure 6, the results of the sigma point method closely mimic the Monte Carlo simulations even in the region of the setpoint change.
This shows that the sigma point approach is more reliable than the linearization approach. The performance comes at a cost, as more function evaluations are required. However, the number of iterations is still orders of magnitude smaller than that for the Monte Carlo method. The major drawback of the sigma point method is that it requires the parameters to be normally distributed.
3.4. Polynomial Chaos Expansion
As the parameters in this study are assumed to be normally distributed, Hermite polynomials are used based on the Weiner–Askey scheme [
14]. PCEs of order 1 (PCE1) and 2 (PCE2) are studied, and the linear regression method is used to determine the coefficients of the PCEs. Based on Equation (
15), PCE1 leads to 5 unknown coefficients, and PCE2 to 15 unknown coefficients. A major issue in application of PCE is sampling. To determine the coefficients, a set of
K (
) samples from the random variables is sampled. Generally,
samples are considered to be sufficient for a robust solution. However, the choice of samples highly affects the accuracy of the results. Thus, a variety of sampling techniques are proposed in the literature [
26,
27]. In this study, we use sigma points from
Section 3.3 augmented by a Latin-hypercube-based design [
28] to sample in the feasible space denoted by the parameter confidence interval. The results of PCE1 (with nine sampling points chosen to be the sigma points) are depicted in
Figure 7, and the results of PCE2 (with 32 sampling points) are depicted in
Figure 8. In
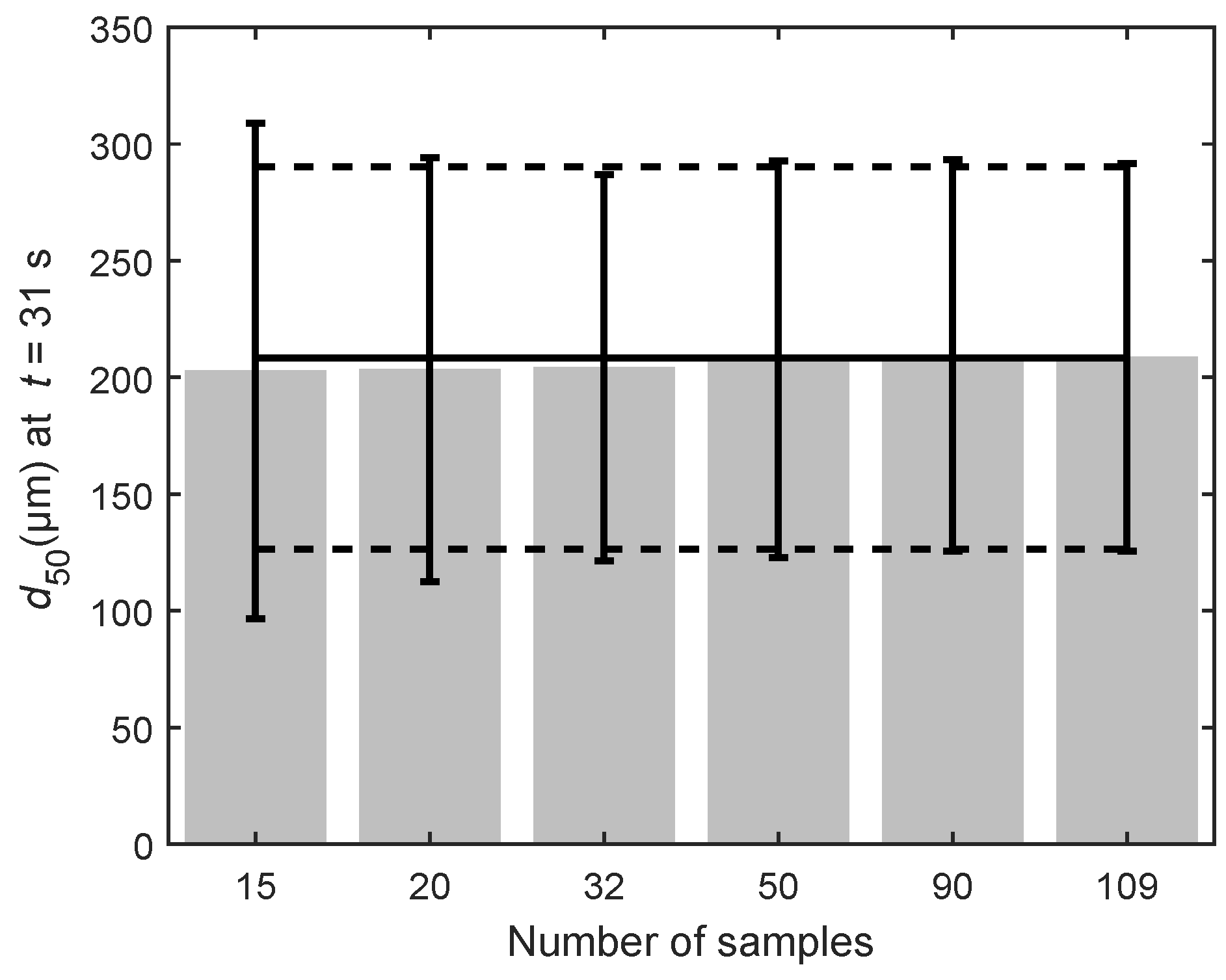
Figure 9, the accuracy of the PCE2 method is evaluated based on the number of samples used. The mean
value (bars), and its variance (error bars) starts to converge towards the Monte Carlo value (solid & dashed horizontal line) with an increasing number of samples. Although not used here, PCE can easily be expanded to use third-order polynomials. However, in that case, the number of samples will increase to a minimum of 72. Generally, the increase in accuracy achieved by higher-order PCE is not enough to warrant the increased computational burden [
13]. In general, we can say that PCE methods with adequate sampling approximate the mean and variance accurately.
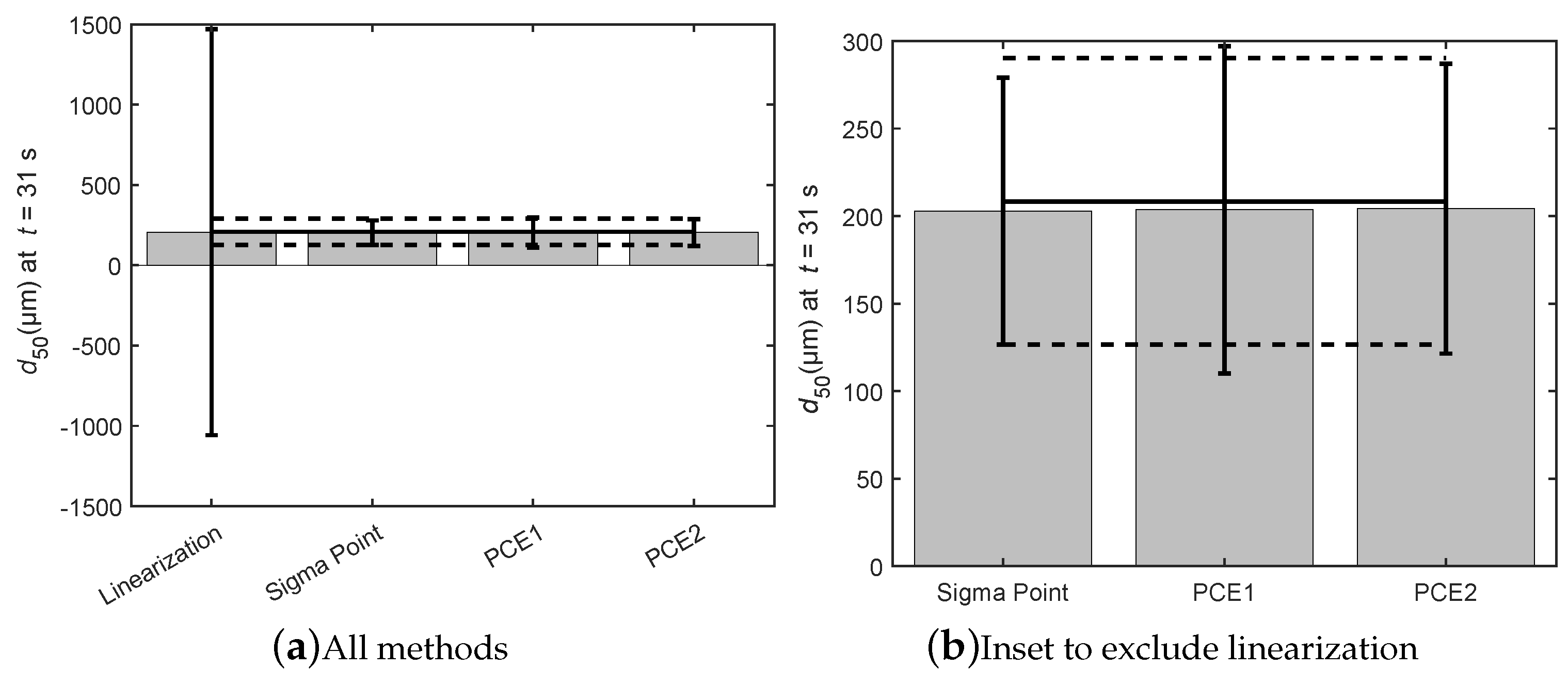
In
Figure 10, the four methods are compared using the
evaluated at 31 s. It is clearly seen that linearization performs the worst of all the methods. As previously mentioned, this is due to the change in model curvature induced due to step change in the impeller speed at 30 s. The other techniques—sigma point, PCE1, and PCE2—result in values that are comparable to each other. The sigma point method slightly underestimates the variance, while the PCE1 method slightly overestimates the variance. The performance of the PCE methods can be improved by using more sampling points or using a higher-order polynomial. For all practical purposes, the performance of these three methods in terms of accuracy can be considered the same.
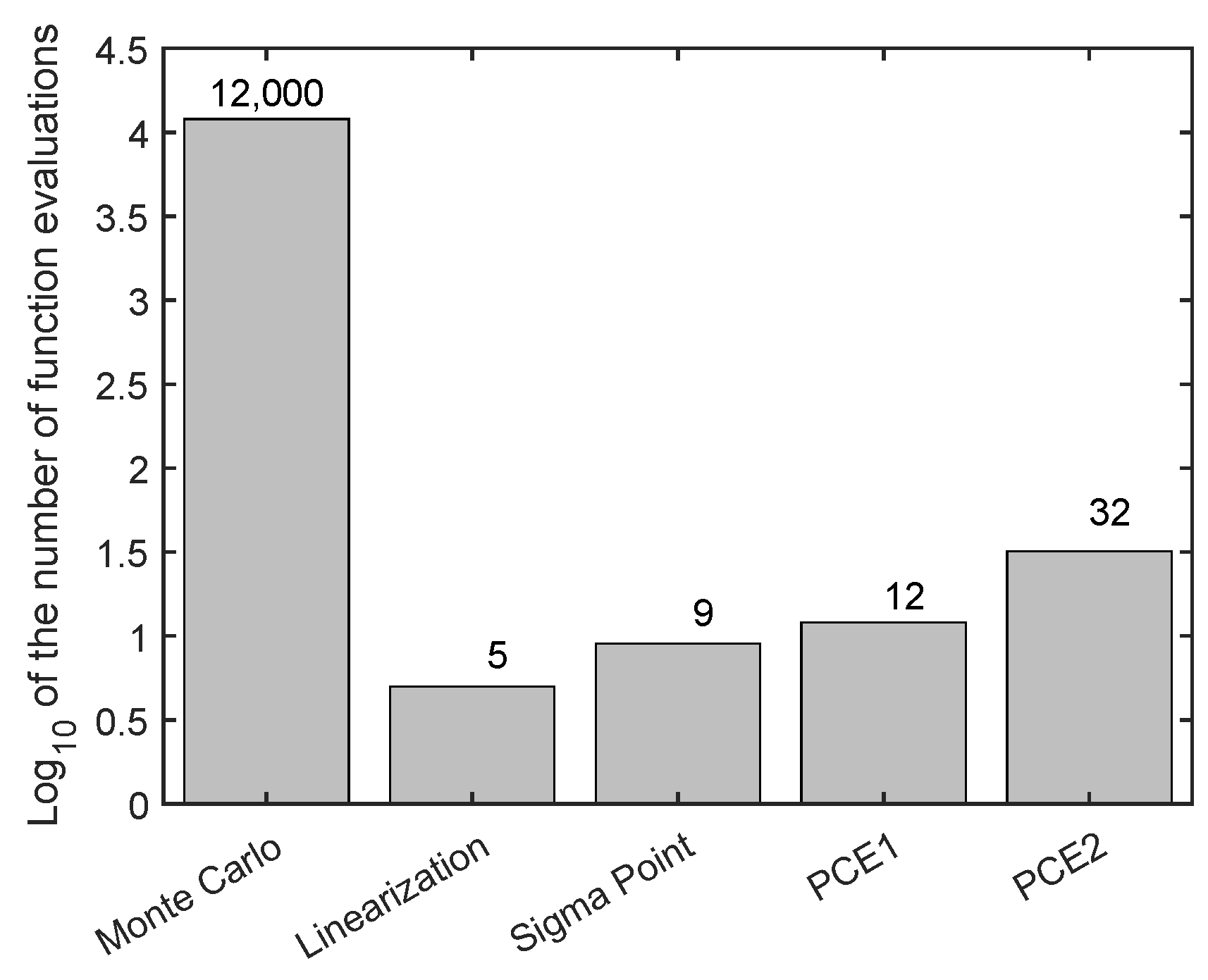
Figure 11 compares the number of function evaluations required for each technique. Monte Carlo performs the worst in terms of computational time with 12,000 function evaluations. All other methods require a significantly lower number of evaluations. For the current case, SP methods seem the most suitable, as we know the parameters to be normally distributed.
4. Conclusions
Firstly, it can be concluded that the model in consideration is not adequate for any decision making, as the prediction uncertainty in terms of 95% confidence interval is high. The model needs to be improved either by using more experimental data to estimate the parameters or, if that fails, by improving the model structure.
However, the aim of the study is to discuss the selection of methods for uncertainty propagation to provide an accurate representation of the model prediction uncertainty in the breakage population balance models. The results demonstrate that, although computationally the cheapest, linearization does not provide a reliable estimate of the uncertainty. If it is known a priori that the model under consideration is smooth and not extremely nonlinear, linearization can be a good option to achieve a first estimate of the prediction uncertainty. However, in the case of highly nonlinear dynamics, other approaches are deemed necessary.
The Monte Carlo method is the most accurate way of predicting the uncertainty, but due to the difficulty in knowing the number of samples required, the method can quickly become very computationally demanding. Recently, Monte-Carlo-based methods such as multi-level Monte Carlo (MLMC) and quasi Monte Carlo (QMC) methods have gained popularity, as they reduce the computational time of the full Monte Carlo method. MLMC tries to minimize the computational time by approximating the final mean as a sum of predicted means obtained at lower accuracy (which in many cases means a lower computational time) [
29]. Thus, even though MLMC leads to a larger number of function evaluations, the total computational cost could be lower than a standard Monte Carlo method. The QMC, on the other hand, relies on smart sampling strategies to reduce the number of function evaluations, thus reducing the computational time [
30]. These methods, although interesting, would still lead to a fairly high computational cost and can be justified when there is no information on the distribution of uncertain parameters. However, as in the case under study, the parameters are known to be normally distributed, the other methods are more attractive.
The deterministic sampling of the model parameters in the sigma point method give it an advantage over the random sampling of the Monte Carlo method The sigma point method reduced the number of samples and function evaluations from more than 12,000 to only 9 and still provided an accurate representation of uncertainty. However, sigma point methods can only be applied when the distribution of the uncertain parameters is symmetric and unimodal.
PCE methods also lead to an extensive reduction of sampling points compared with the Monte Carlo method and provide accurate predictions on model uncertainty. PCE methods can be complex to implement. The choice of polynomials and collocation points for sampling plays an important role and, as such, is non-trivial. If the uncertain parameters are characterized by asymmetric and/or multimodal distributions, the PCE method has to be used to replace the Monte Carlo method. The choice of orthogonal polynomials depends on the distribution of the uncertain parameters and follows the Wiener–Askey scheme [
14].
Thus, we can conclude by stating that the sigma point method is the most attractive method for applications such as the PBM studied here because of its ease of implementation, its accuracy in representing model uncertainty, and its computational efficiency. PCE methods become attractive when the parameter distributions are known a priori to be asymmetric or multimodal. However, when no information about parameter distributions is available, the Monte Carlo method has to be used. In such a situation, MLMC or QMC methods can reduce the computational burden.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}