1. Introduction
Energy integration in batch processes is challenging due to intermittent availability of process streams. With increasing popularity of batch processes (due to production flexibility, resource sharing, target-driven production, etc.), and environmental concerns necessitating reduced consumption of conventional energy sources, energy integration in batch processes has been gaining increased attention [
1]. In continuous processes, heat integration depends on the temperature difference between hot and cold streams (temperature-constraint), but, in batch processes, energy integration additionally depends on the co-existence of hot and cold streams at the same time (time-constraint). Because of these time-constraints, energy integration in batch processes is closely tied with production scheduling.
For energy-integrated batch process systems, scheduling is a combination of optimization of a production function (profit maximization or make-span minimization) and minimization of utility consumption. These two objectives can be handled sequentially or simultaneously. Papageorgious et al. [
2] incorporated heat integration as an integral part of scheduling formulation. They extended the state-task network (STN) based scheduling formulation [
3] to incorporate energy integration, and recast the resulting problem as a mixed-integer linear programming (MILP) formulation. Lee and Reklaitis [
4] developed a discrete-time MILP formulation for scheduling heat-integrated batch processes in a campaign (multiple similar batches in a sequence) mode. They introduced a concept of repeating patterns of heat integrating units to reduce the size, and ultimately the computation time of the scheduling problem. In a different vein, Ierapetritou and Floudas [
5] developed a continuous time-based optimization framework to simplify optimization formulation. This framework was successfully extended by Majozi [
6] for energy-integrated batch processes wherein the initial mixed integer nonlinear programming (MINLP) formulation was linearized using Glover transformation. Holczinger et al. [
7] extended the S-graph-based scheduling framework [
8] to simultaneously solve the heat integration and production scheduling problem. Chen and Ciou [
9] extended the resource-task network (RTN) based scheduling framework [
10] to solve scheduling and heat recovery problem in a unified manner. Alternatively, Halim and Srinivasan [
11] presented a sequential methodology for scheduling of heat-integrated batch systems, wherein the original problem is decomposed into two sequential problems of production scheduling and heat integration. In the first step, the schedule is optimized for the given production objective. In the next step, a stochastic search-based integer cut procedure is applied to generate alternate schedules with near-optimal values and minimum utility targets are achieved through energy integration analysis. In a different vein, thermal integration of batch process with district cooling systems or power grids has shown a great potential for optimal operation through variable production scheduling and utilization of available energy storage facilities [
12,
13,
14].
In essence, the scheduling problem of energy-integrated batch processes requires mixed-integer formulation (MILP or MINLP). Achieving optimal solution for such formulations is tricky and computationally expensive, especially for large system size and/or long scheduling horizon. This severely restricts their application for online rescheduling as a response to operational disturbances (such as equipment breakdown, target fluctuations, etc.) [
15,
16]. Motivated by this, the objective of our current work is to develop a scheduling formulation to reduce computation time while handling such situations. Previously, it has been shown that significant reduction in problem size and computation time can be achieved by identifying repeating patterns in schedules of energy-integrated batch systems [
4,
17]. In our previous work, we argued that time-constraints of energy integration result in specific repeating patterns in optimal schedules and these patterns can be used to predict optimal schedules without solving a mixed-integer optimization problem [
18]. In this paper, we extend and generalize this pattern-based scheduling method. Additionally, we demonstrate that this method can also be effectively integrated with mixed-integer optimization, wherein the pattern-based solution guides the mixed-integer optimization to the optimal solution and significantly reduces the computation time.
The rest of the paper is organized as follows. We first present three motivating examples to demonstrate the existence of patterns in the optimal schedules of energy-integrated batch systems.
Section 3 describes the proposed pattern-based scheduling algorithm.
Section 4 illustrates the application of this method to the motivating examples and discusses its integration with mixed-integer optimization. Lastly, concluding remarks and possible extensions of the current work are presented.
3. Method
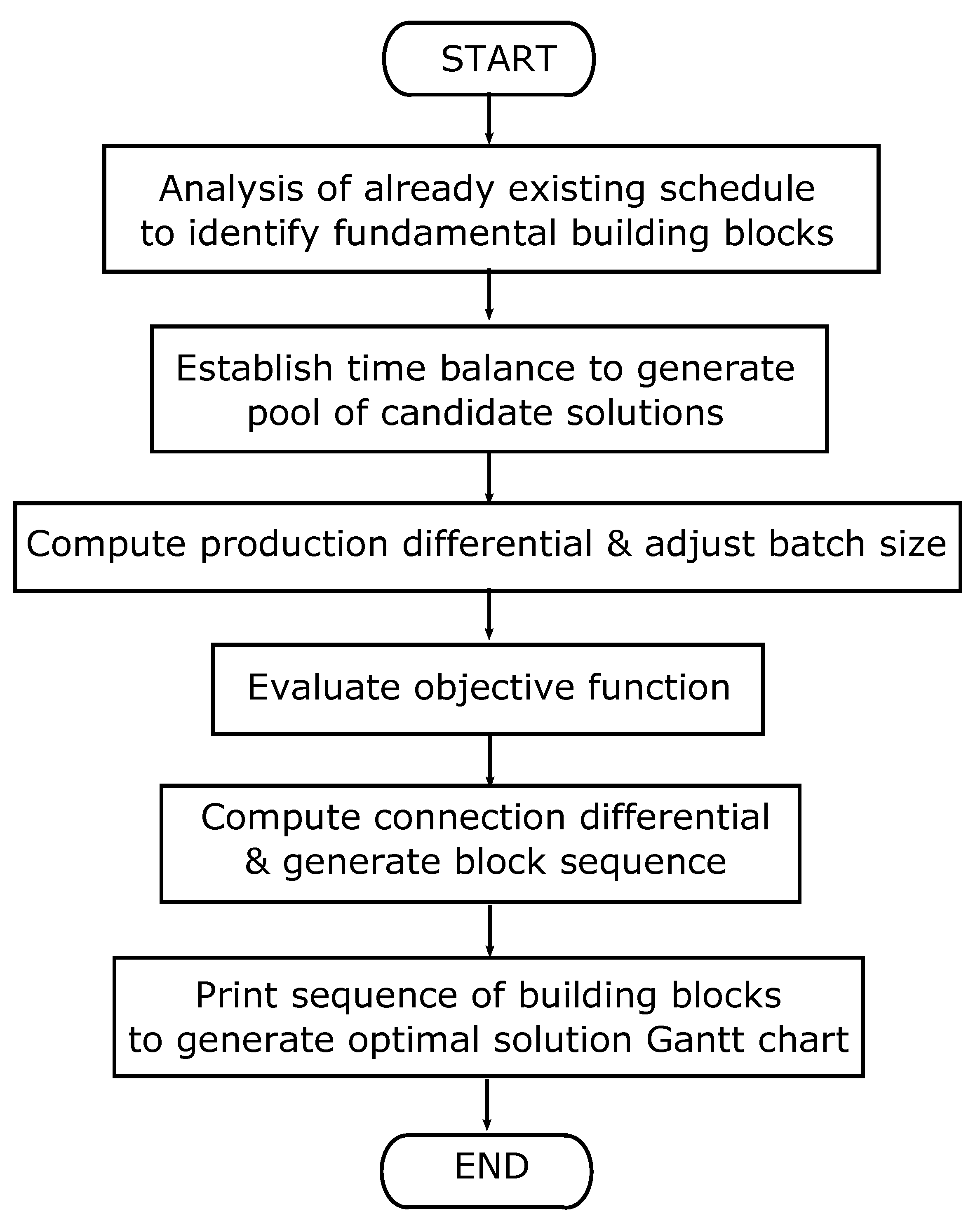
Let us now formulate a framework to construct optimal schedules for energy-integrated batch systems using fundamental building blocks. The corresponding algorithm is depicted in
Figure 9. The key steps of the algorithm are discussed below.
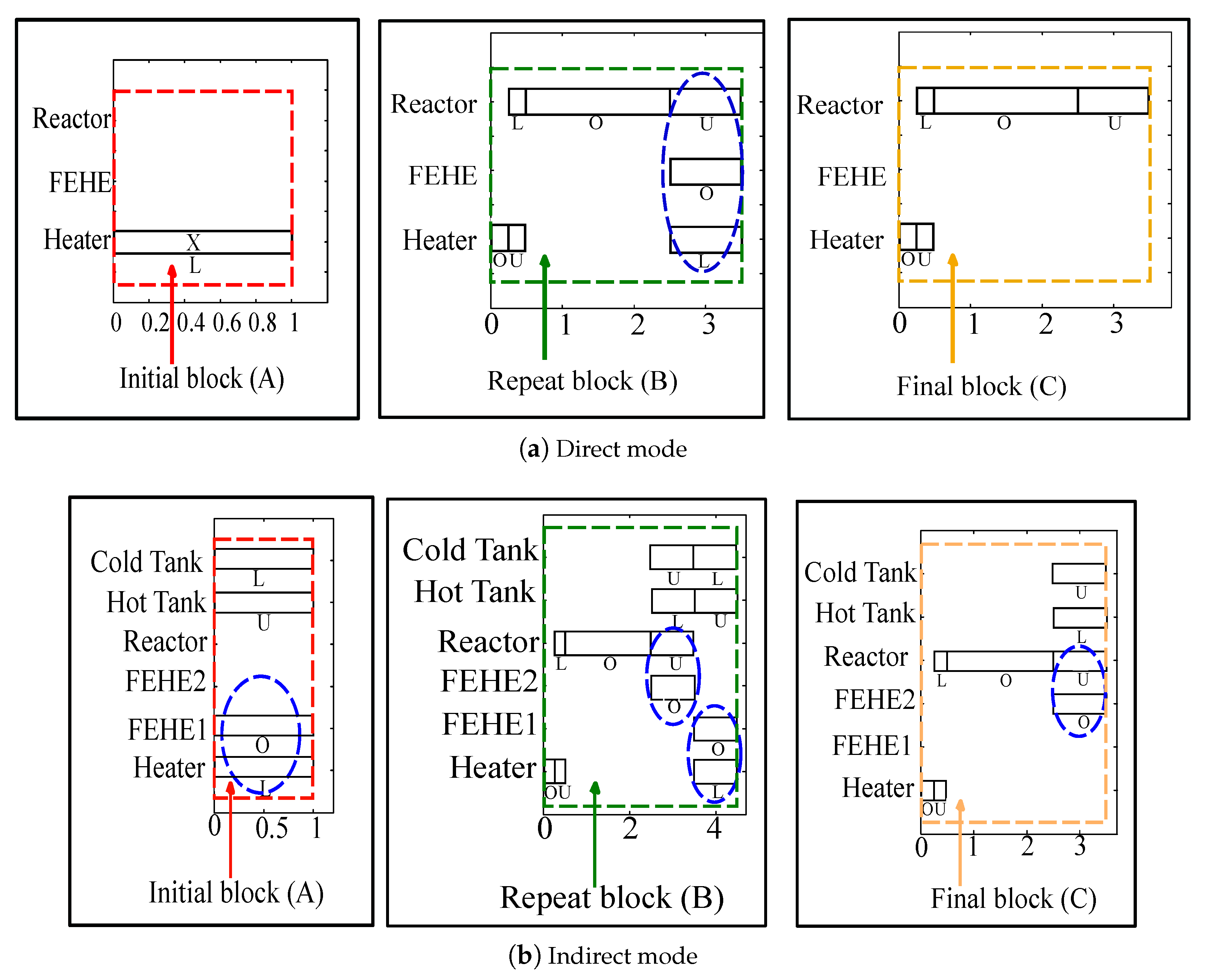
Step 1: Identify fundamental building blocks
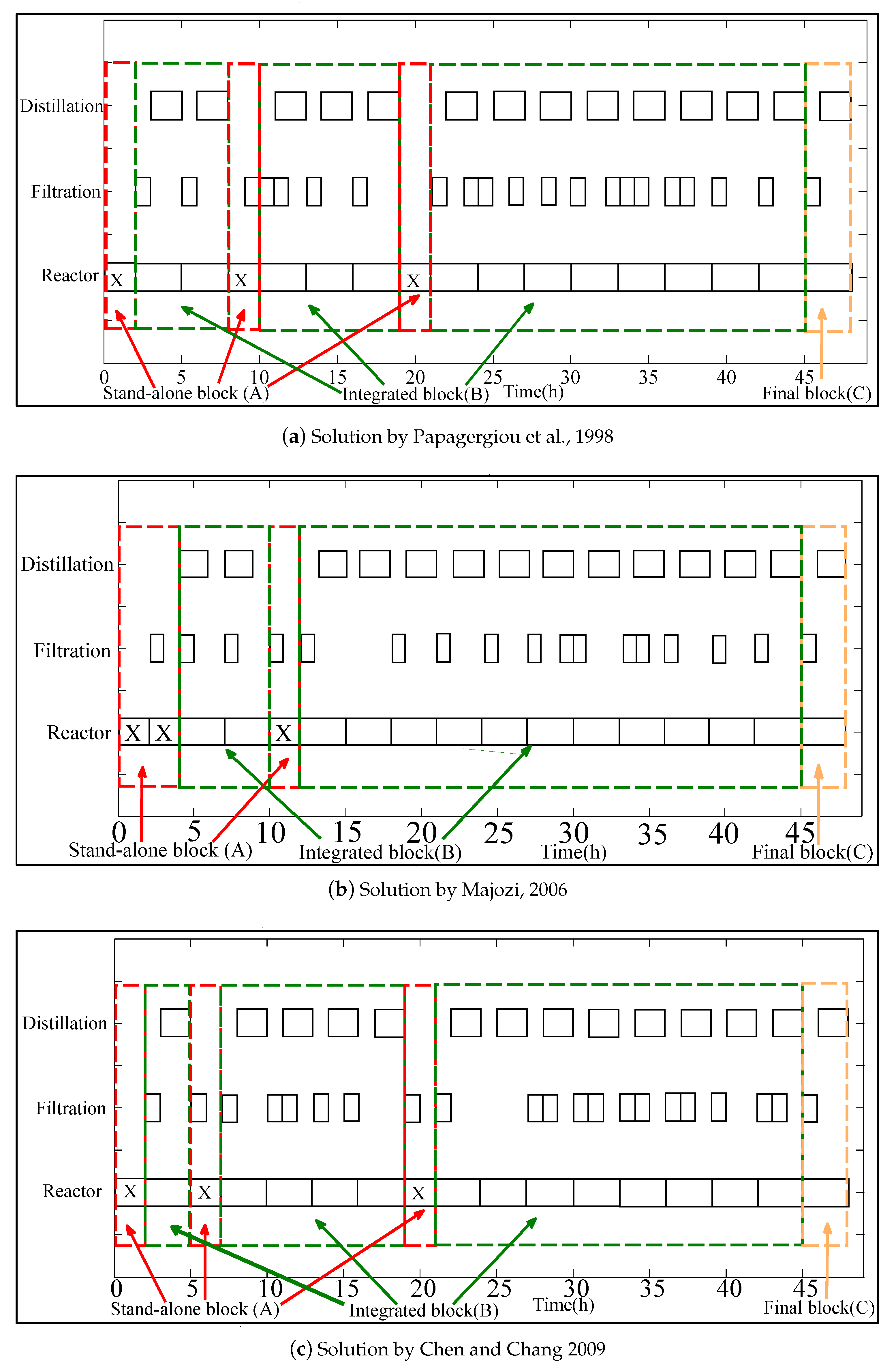
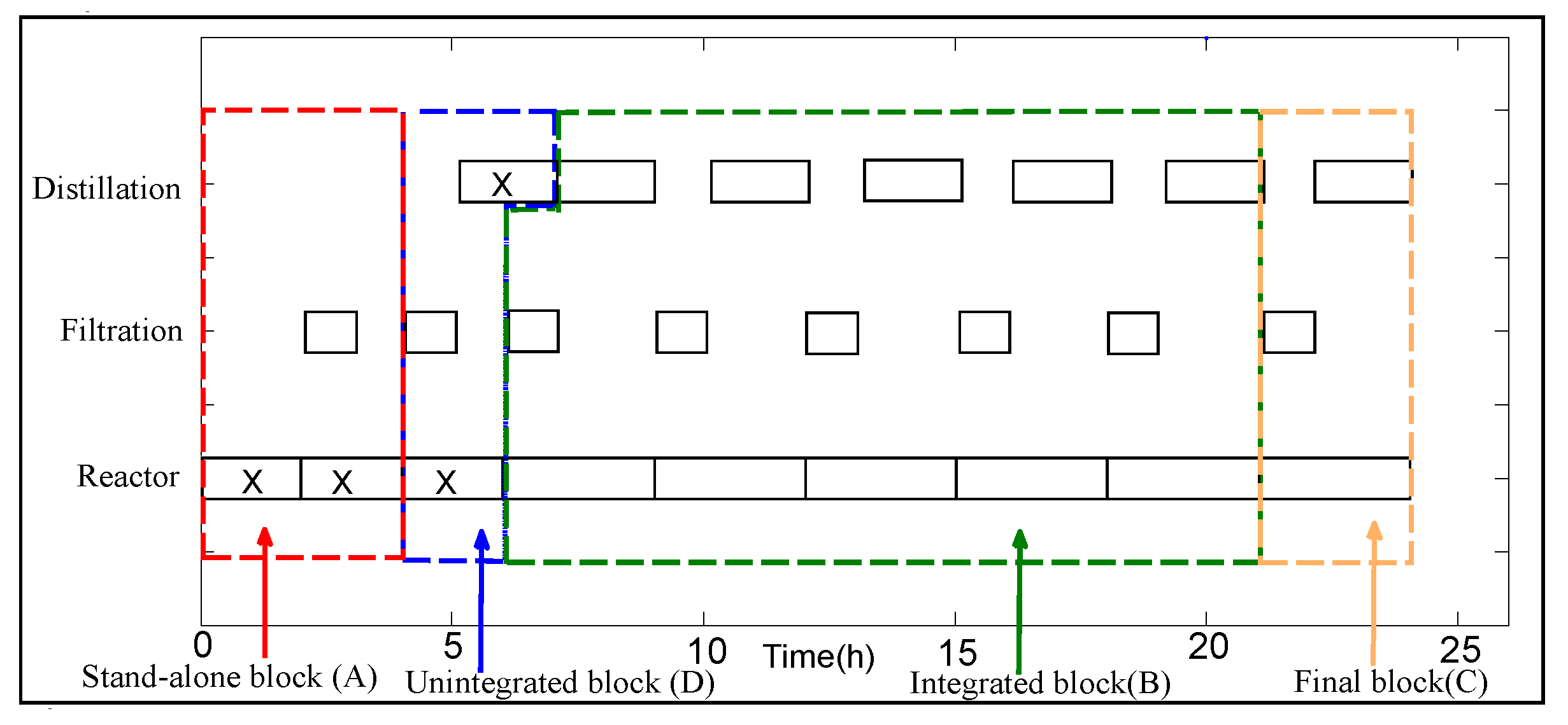
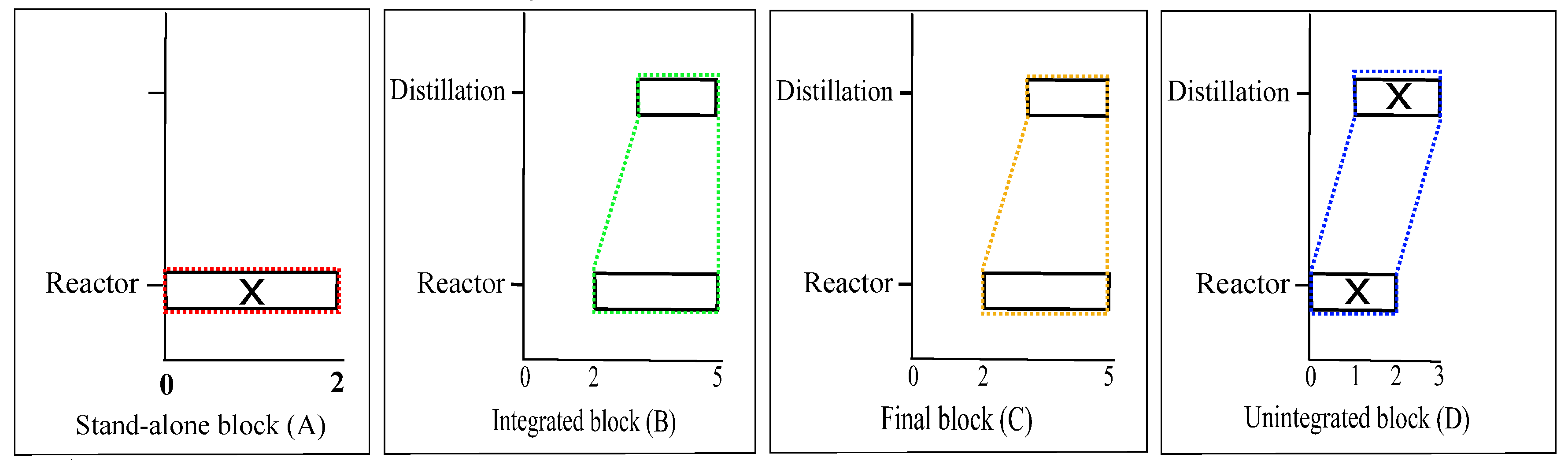
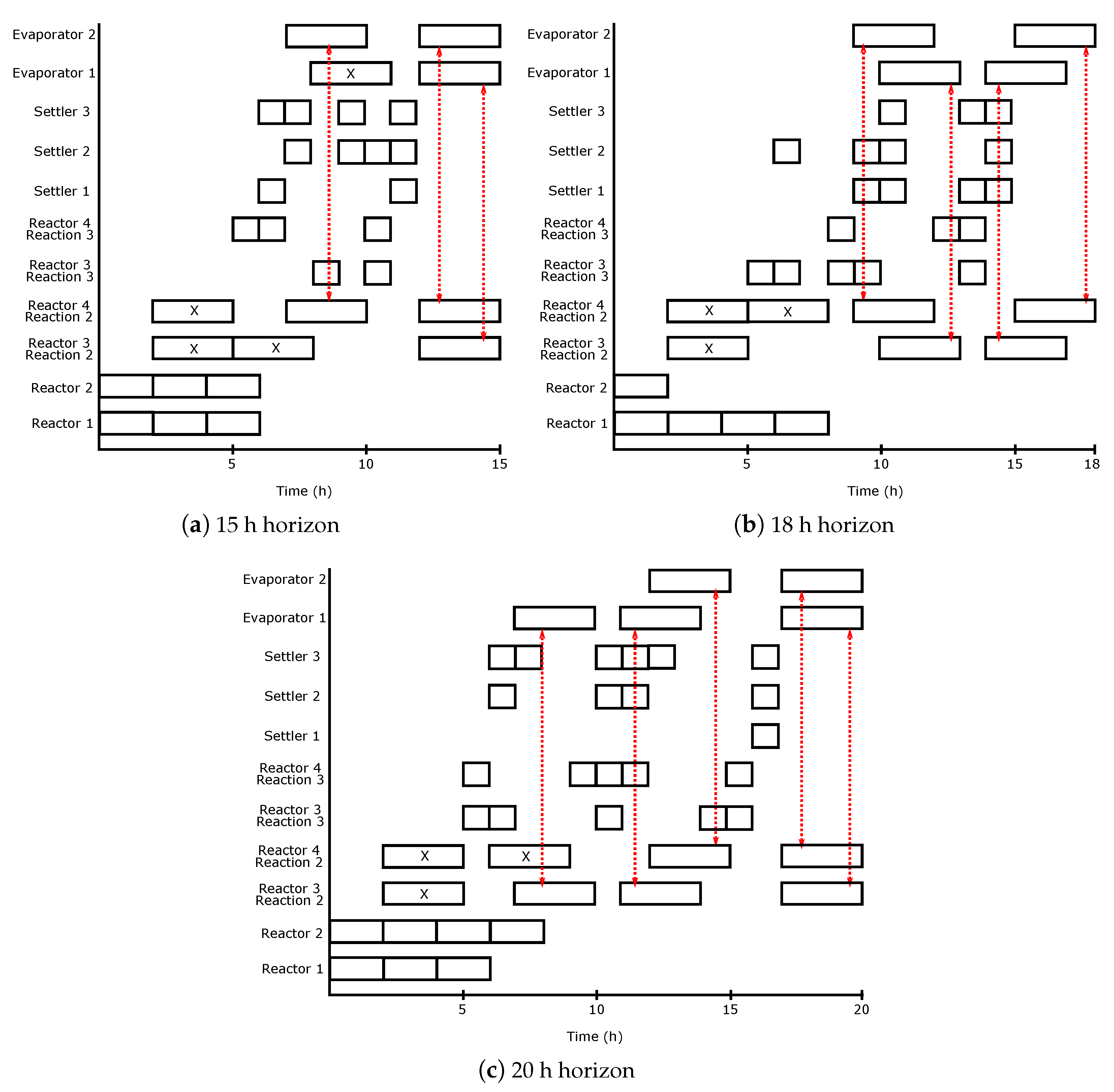
The algorithm starts with the identification of fundamental building blocks present in the optimal solution for any scheduling horizon. Such an optimal solution is obtained by using any of the mixed integer optimization formulations cited in the introduction section. The influence of time-constraints arising from energy integration should be evident in the most frequently appearing building block. For example, in the case of BR-FEHE system with direct integration, the unloading phase of the reactor, the operating phase of the FEHE and the loading phase of the heater will be scheduled at the same time slot and thus would be part of a building block. In the case of BR-S system, Blocks B and C arise due to energy integration time-constraints. Similarly, for the multipurpose industrial example, energy integration between the evaporation task and the Reaction 2 task forces Reactor 3 (or 4) to be scheduled at the same time as Evaporator 1 (or 2), resulting in the repeating patterns shown in
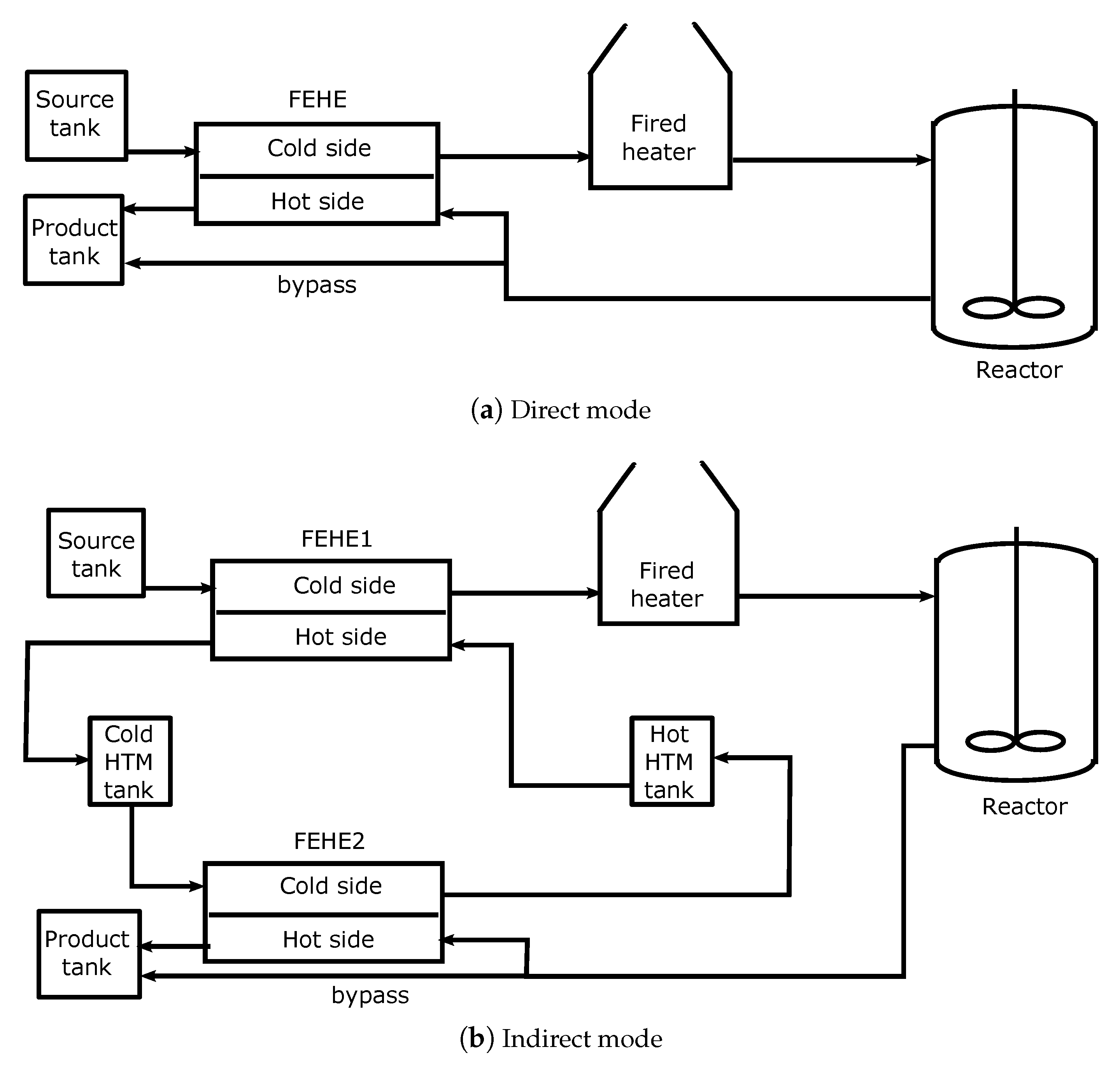
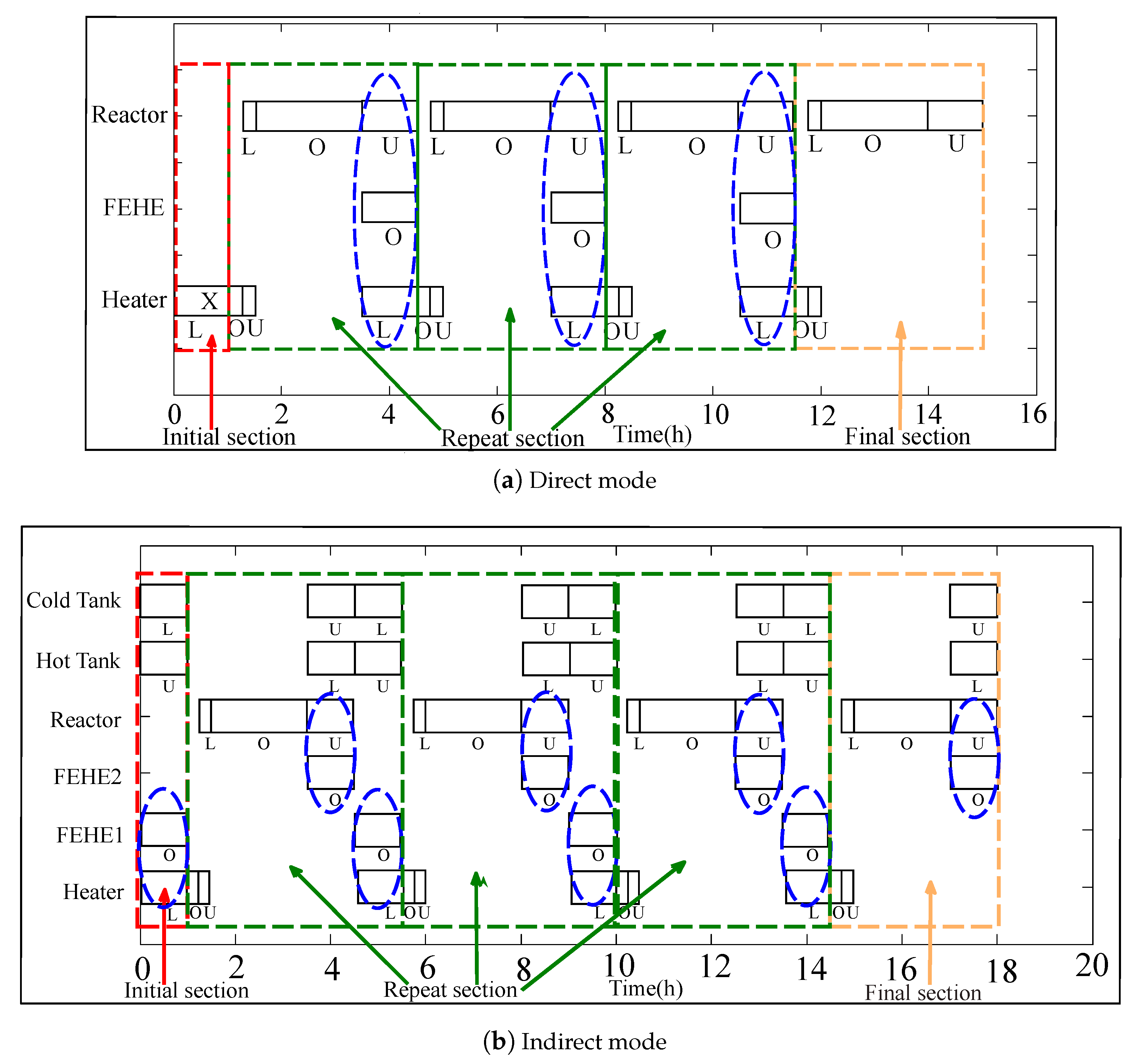
Figure 8. In some cases, the physics of the system will decide position and/or location of some of the building blocks. For example, for the BR-FEHE system in direct mode, the initial section acts as a startup phase and is then taken over by the repeat section. On the other hand, for the BR-S system, the final block acts as a closing phase and therefore the optimal schedule will always have one (and only) final block at the end of the scheduling horizon.
Step 2: Establish time balance
Any optimal schedule avoids keeping key/limiting process equipment idle. Naturally, when fundamental building blocks are stitched together to generate the optimal schedule, it is desired that there is minimum idle phase (gap between the building blocks). This is ensured by forcing a time balance constraint and backing off to obtain integer multiplicity for each building block. This can be accomplished by solving the following integer optimization problem:
where
T is the scheduling horizon,
is the duration of the
ith building block, and
and
represent the minimum and maximum multiplicity of the
ith building block. Depending on the batch system, the above formulation can have multiple solutions and we generate a pool of candidate optimal solutions.
Step 3: Compute production differential and adjust batch size
This step involves meeting the material balance constraints for the intermediate components. Production differential () for an intermediate is defined as the net amount of the intermediate present at the end of the production campaign. It can be computed as the summation of production differential of the individual building blocks () over the scheduling horizon.
where
is the net intermediate product produced by the
jth instance of the
ith block. An optimal schedule requires minimal production differential for all the intermediates. Initially, production differentials are computed for all the candidate solutions obtained in the previous step assuming that all the units/blocks operate at their maximum capacity. Depending on the value of
, the following actions are taken to minimize
by adjusting capacities of some of the blocks.
: All the processing units are operated at their maximum capacity as it maximizes production while satisfying material balance constraints.
: In this case, the rate of consumption of the intermediate is more than the rate of production. Some of the blocks with net intermediate consumption should therefore be operated at a reduced capacity to satisfy material balance constraints (by increasing to zero). The capacity reduction can be uniform across all the blocks or only few of the blocks can share the capacity reduction. This decision depends on the dependence of the objective function on batch capacity. In case of a linear dependence (or no dependence), both these options result in the same objective function value.
: This is a reverse of the previous case. Production differential in this case can be reduced to zero by operating net intermediate producing blocks at a reduced capacity. As in the previous case, the capacity reduction can be uniform or staggered.
Step 4: Evaluate objective function
Once all the candidate solutions satisfy material balance constraint (), the objective function is evaluated for each of these candidates to select the optimal solution. This step thus fixes the multiplicity of each of the building blocks () in the optimal solution.
Step 5: Compute connection differential and generate block sequence
As each of the building blocks can have different intermediate production capacities, the relative position of these blocks affects the dynamic inventory of the intermediate (and determines the intermediate storage requirement). To this end, connection differential () is defined to capture the net change in the inventory of the intermediate when the ith block is connected with the jth block. As the building blocks are stitched together, the cumulative sum of these connection differentials () signifies the corresponding inventory of the intermediate. In order to satisfy dynamic material balance constraint with respect to the intermediate, should be non-negative throughout the schedule. The maximum value of during the schedule represents the required intermediate storage capacity.
Unlimited or minimum intermediate storage represent two extreme policies considered while solving scheduling problems. The sequence of building blocks can be different for these policies even though the objective function (which typically depends on the number and type of the building blocks) remains the same.
The case of unlimited intermediate storage policy is trivial as it can be accomplished by stacking all the intermediate producing connections () together before placing the intermediate consuming connections (). If minimum intermediate storage is desired, each intermediate producing connection should be followed by few intermediate consuming connections without violating material balance constraint (). This distributes inventory of the intermediate uniformly over the scheduling horizon, thereby minimizing the storage requirement. For example, if , , and , minimum intermediate storage will be achieved by following a sequence of the form “⋯ABBBBABBBBA⋯” with intermediate storage requirement of 30 units.
The Gantt chart for the optimal solution can now be printed by stitching the building blocks as per the above-obtained sequence.
Remark 1. The starting point of the proposed method is an optimal solution obtained using rigorous mixed integer optimization. As the entire analysis is pursued with the assumption of optimality of this solution, starting with a non-optimal schedule will severely affect the effectiveness of the method. In such a case, the new schedules obtained by the pattern-based method will also be sub-optimal.
Remark 2. Identification of the repeating patterns and the corresponding fundamental building blocks in the optimal schedule can be done manually or in automated fashion. For the examples considered in this paper, such blocks are identified manually. One can also automate this process by using graph-based pattern recognition methods available in the published literature [22]. Remark 3. The proposed method considers two extreme intermediate storage policies in Step 5. One can easily extend these to any other intermediate storage policy. For example, in the case of fixed intermediate storage, instead of distributing intermediate inventory uniformly, one can stack intermediate producing connections () up to the fixed capacity. This will be followed by few intermediate consuming connections without violating material balance constraint ().
5. Conclusions
In the context of online rescheduling as a policy to reject operational disturbances, there is a need to repeatedly generate optimal schedules via computationally efficient methods. To this end, we present a pattern-based method to generate schedules for energy-integrated batch process systems. The framework is based on the observation that time-constraints in energy integration give rise to specific repeating patterns in the optimal schedules. Furthermore, it is shown that these optimal schedules consist of combinations of few building blocks. A pattern-based scheduling algorithm is therefore developed to obtain the number and optimal sequence of these building blocks, and thus allows for constructing optimal schedule for any scheduling horizon.
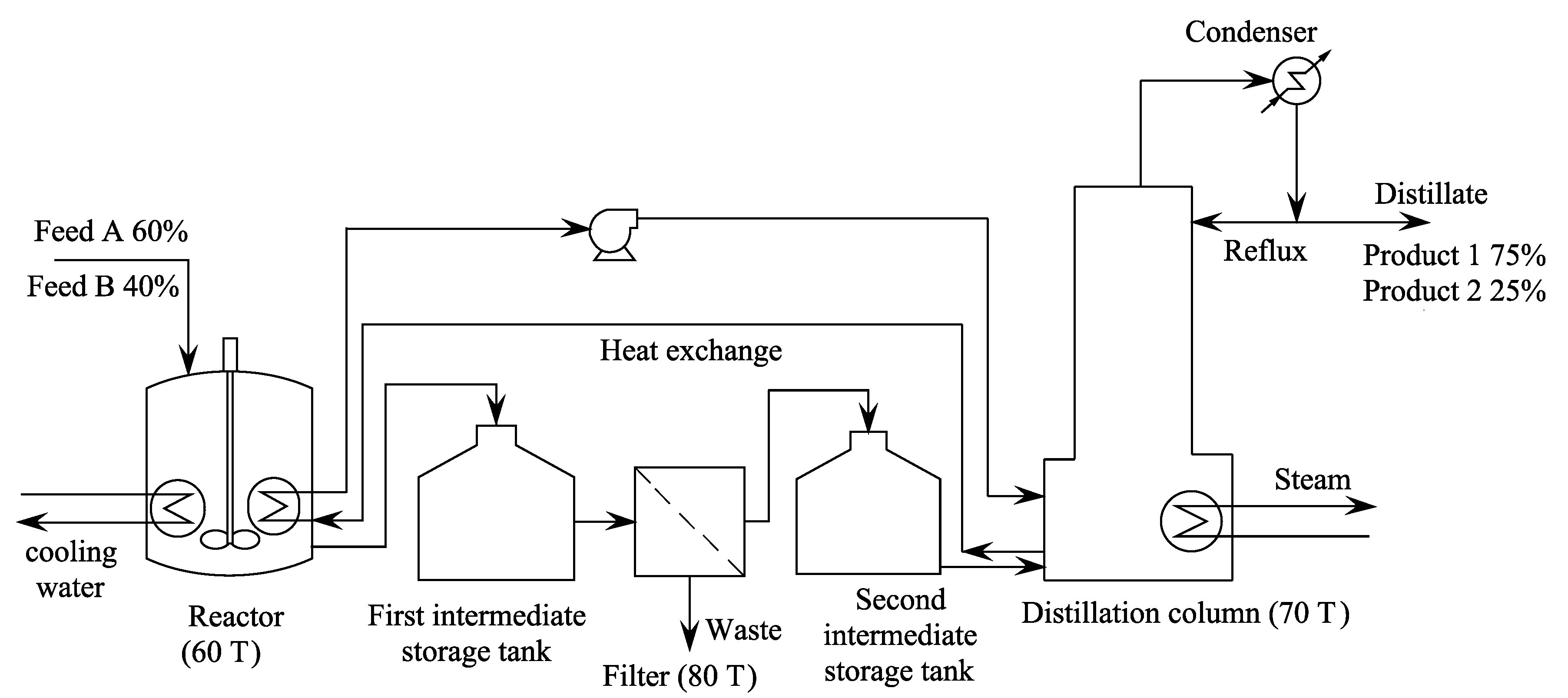
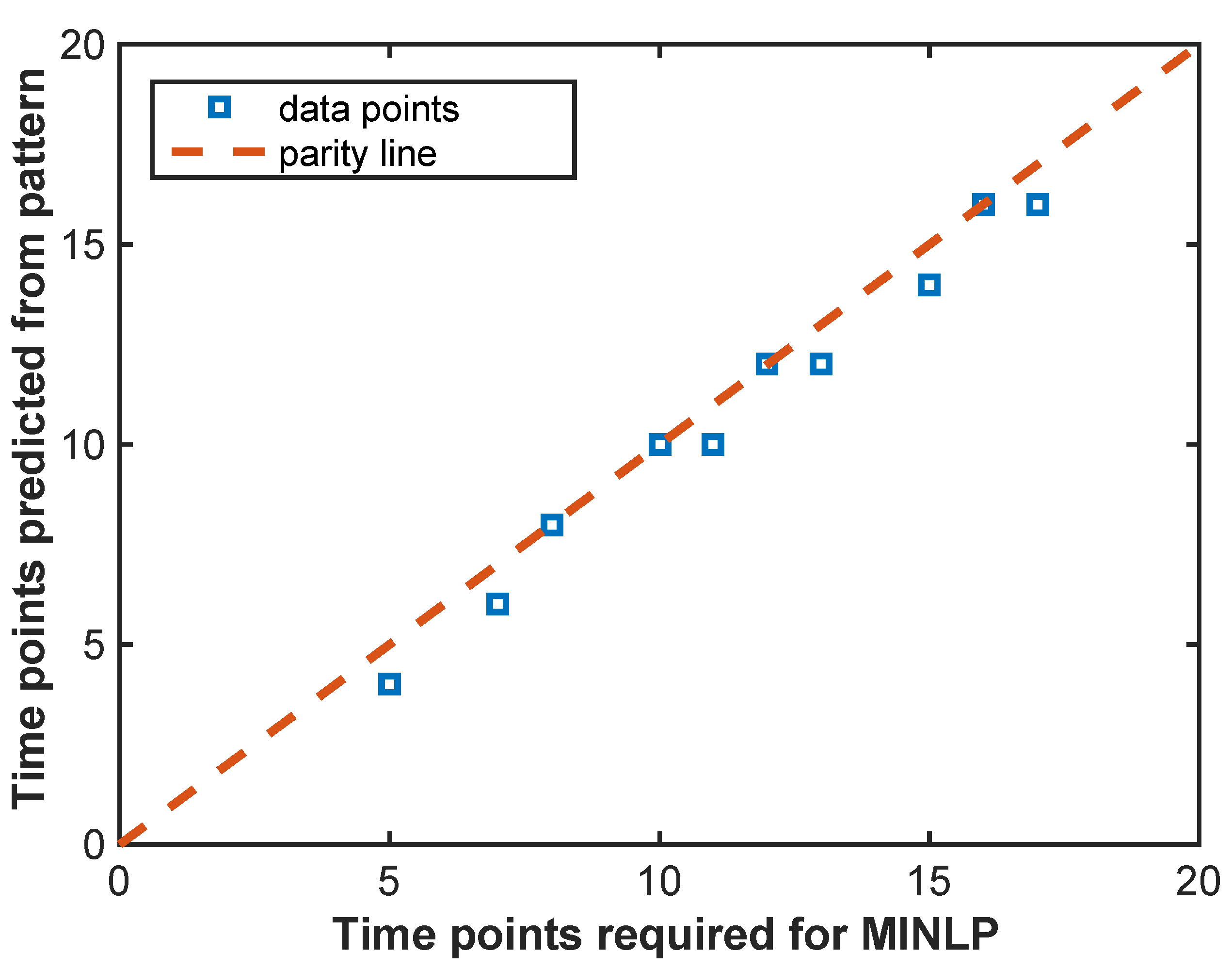
With the help of a benchmark example system of a reactor and a distillation column, it is shown that the proposed method is able to generate optimal schedules which match solution of rigorous mixed-integer optimization and requires significantly less computation time. The method is scalable to larger scheduling horizons and helps identify scheduling horizons which can reduce intermediate storage or maximize utilization of equipment. Furthermore, the method can also be coupled with mixed-integer optimization to significantly reduce the computation time of the latter through prediction of the required number of time points and simplification of the scheduling formulation. Thus, the proposed method is a suitable candidate for application in online rescheduling.
The proposed method is developed for profit maximization in the case of a single product train with fixed duration. In principle, it can also be developed for the case of batch size-dependent duration, makespan minimization or more complex arrangements such as multi-product or multi-purpose schemes. Our ongoing research is exploring such extensions.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}