Multi-Label Classification Based on Random Forest Algorithm for Non-Intrusive Load Monitoring System

Abstract
:1. Introduction
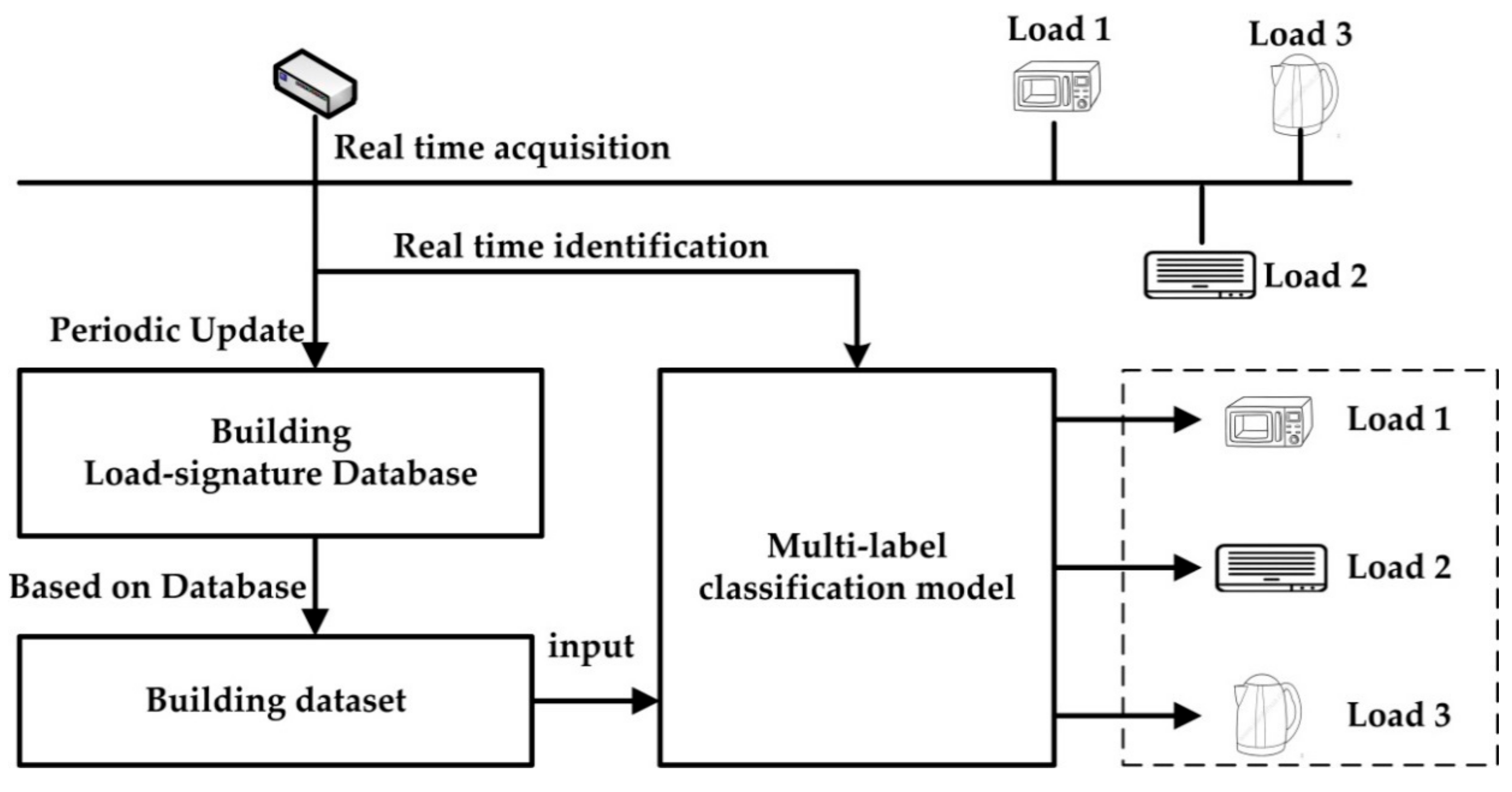
2. Implementation and Principles
2.1. Principle of Data Set Building
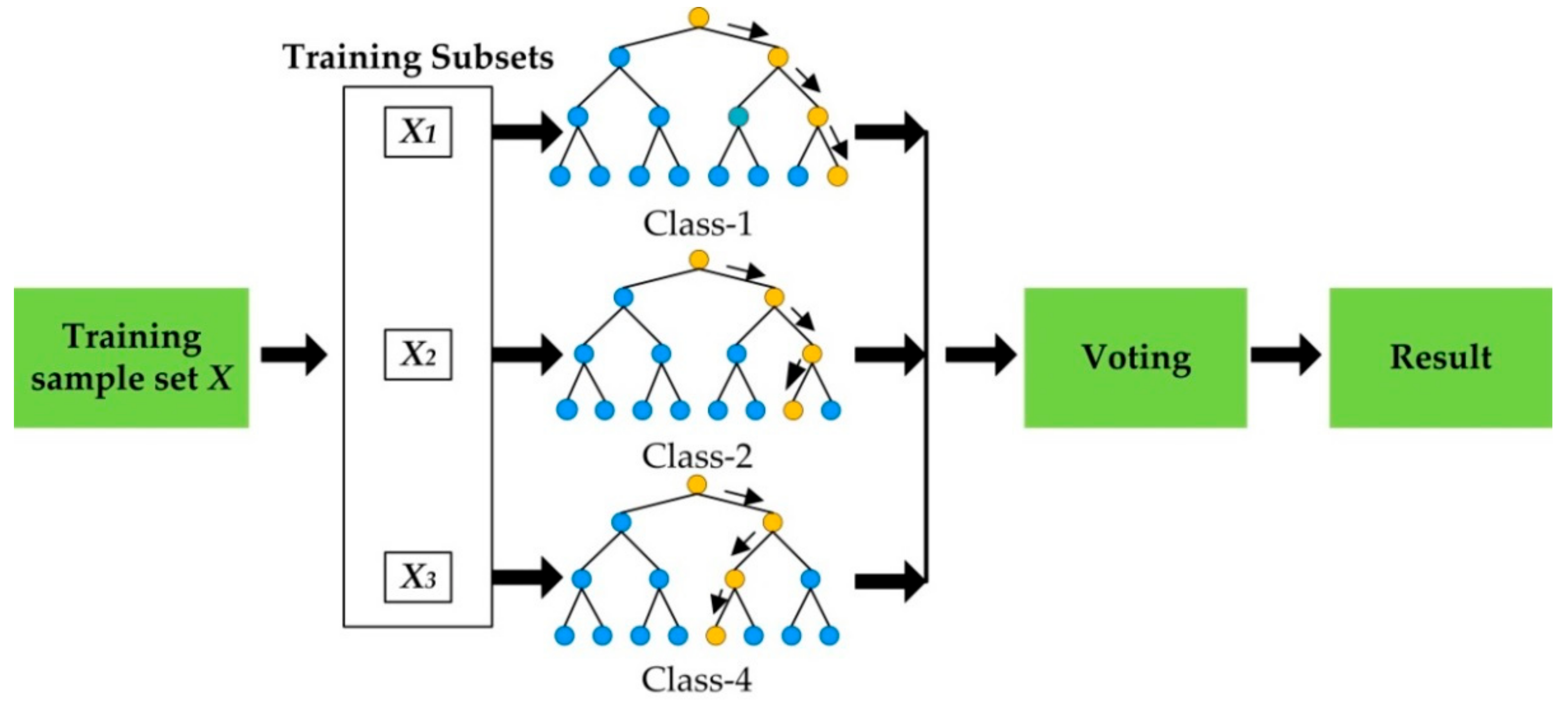
2.2. Principle of Random Forest
3. Experiment Design
3.1. Experimental Condition
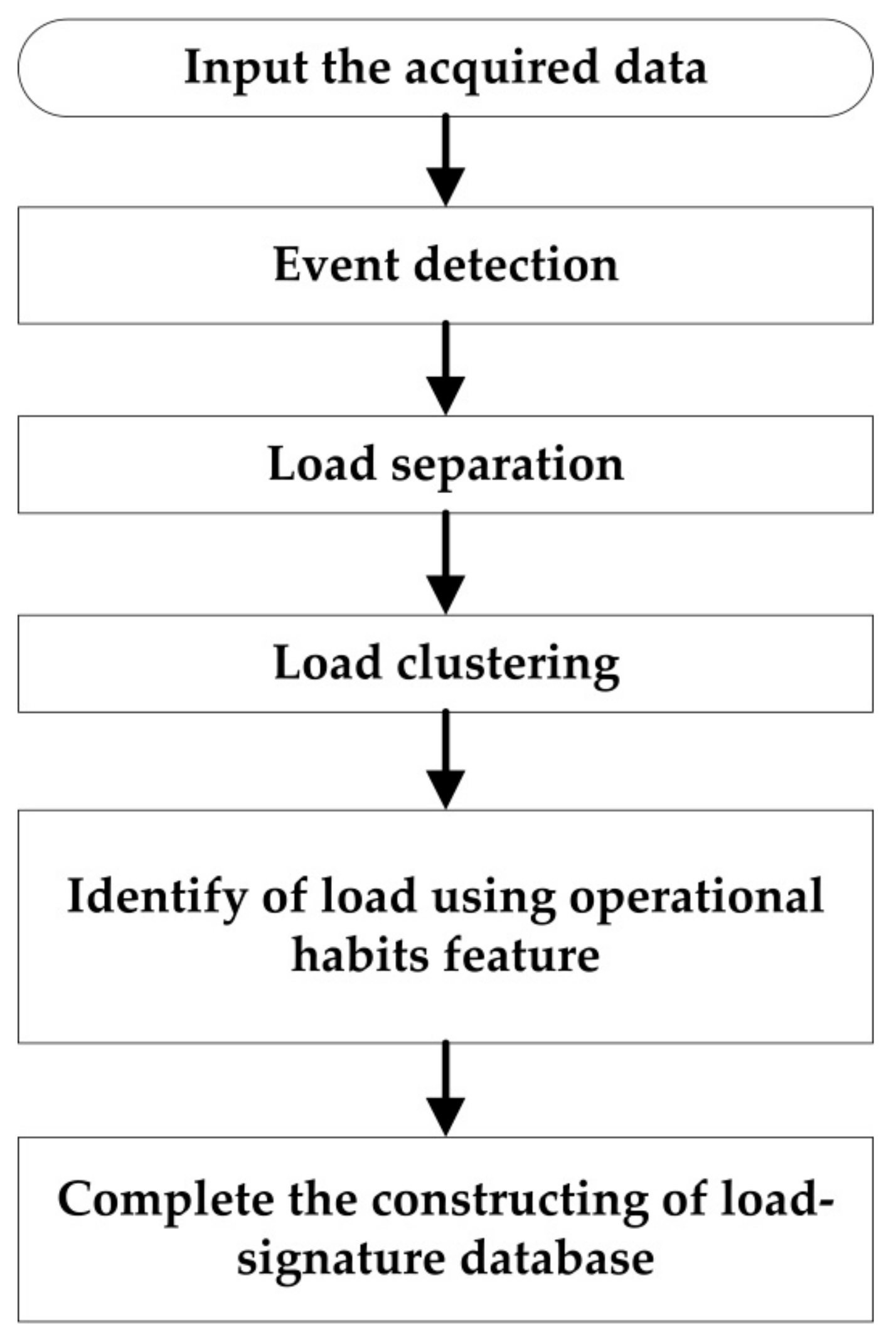
3.2. Building of Load-Signature Database
3.3. Building of Data Set
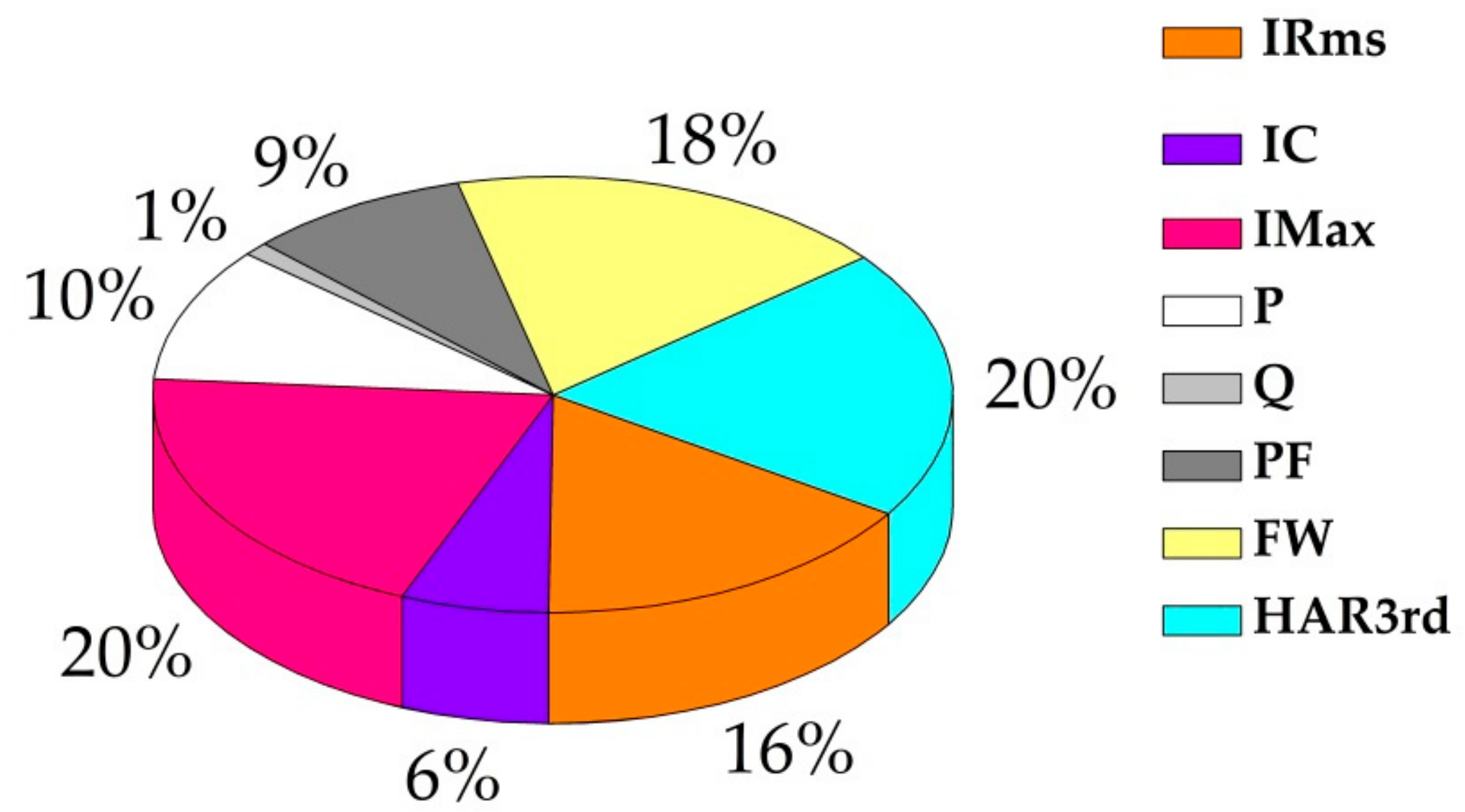
3.4. Feature Importance
3.5. Model Development
3.5.1. Multi-Label Classification Model
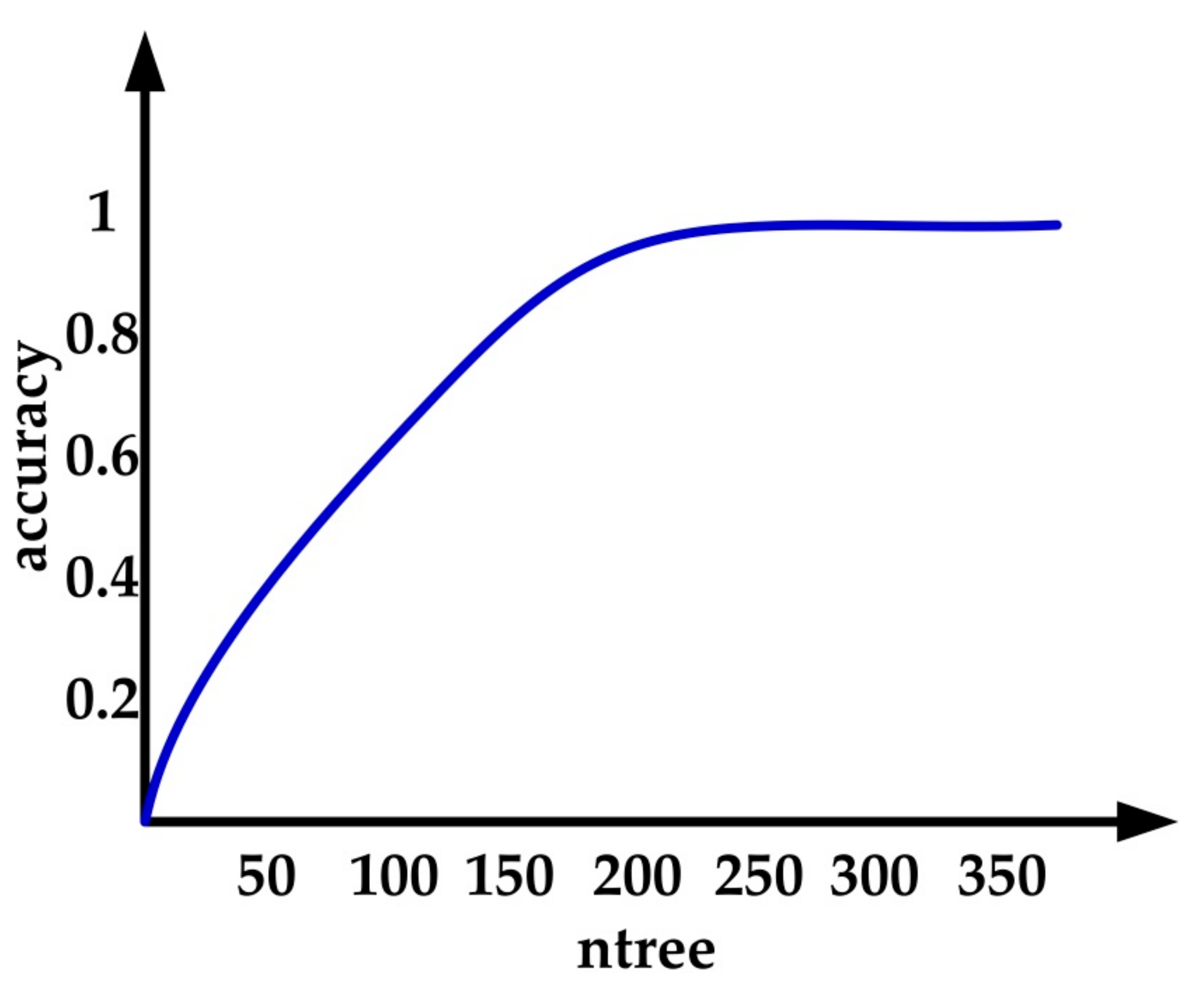
3.5.2. Important Parameters of Model
3.5.3. Evaluation of Model
4. Experimental Result
4.1. Building Load-Signature Database for Laboratory
4.2. Building of Data Set
4.3. Feature Importance Comparison
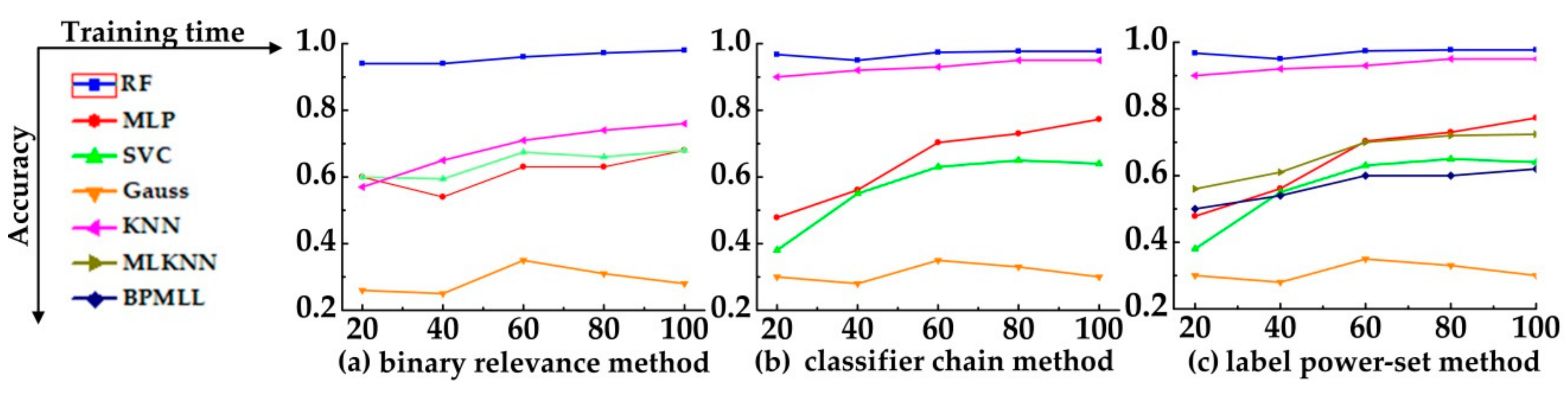
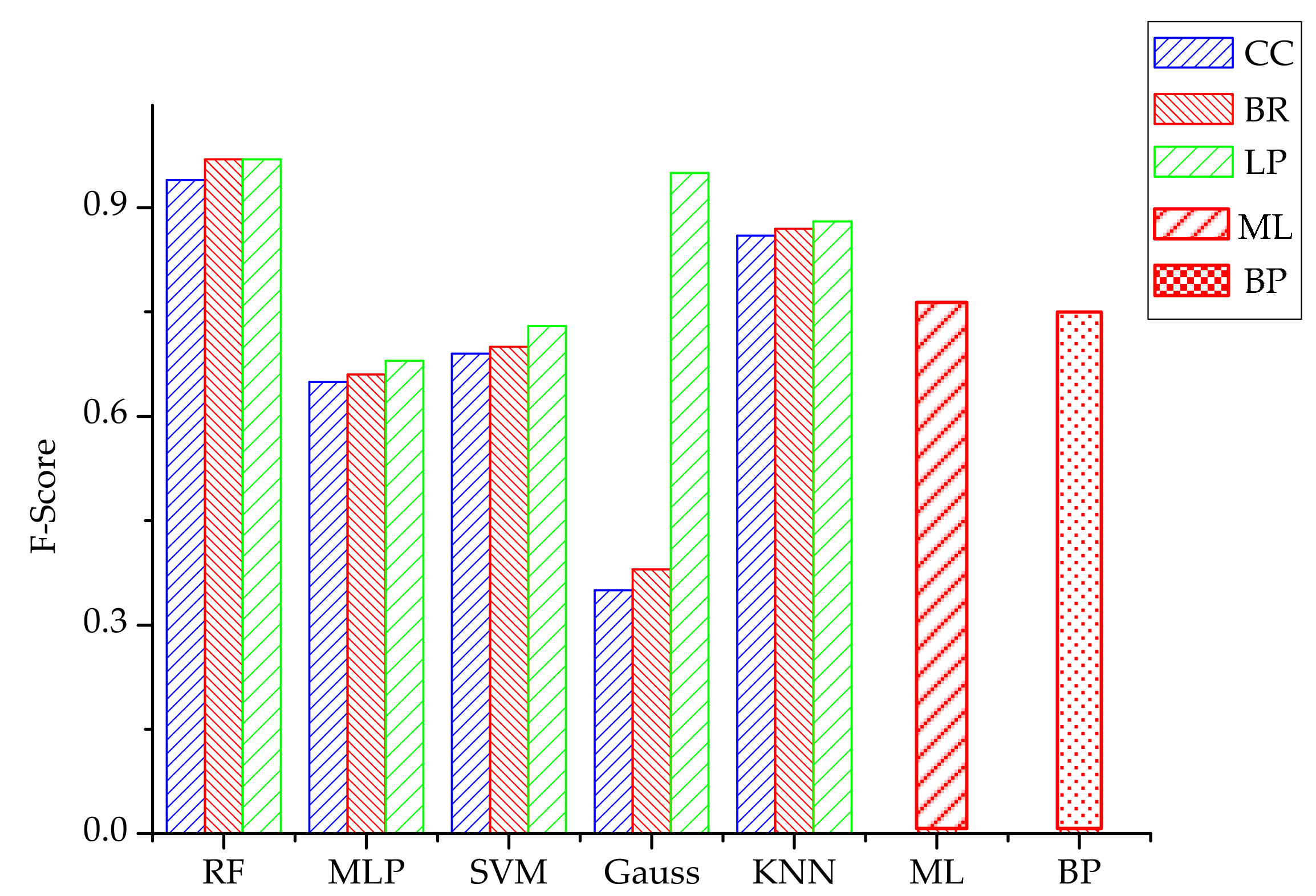
4.4. Classification Algorithm Comparison
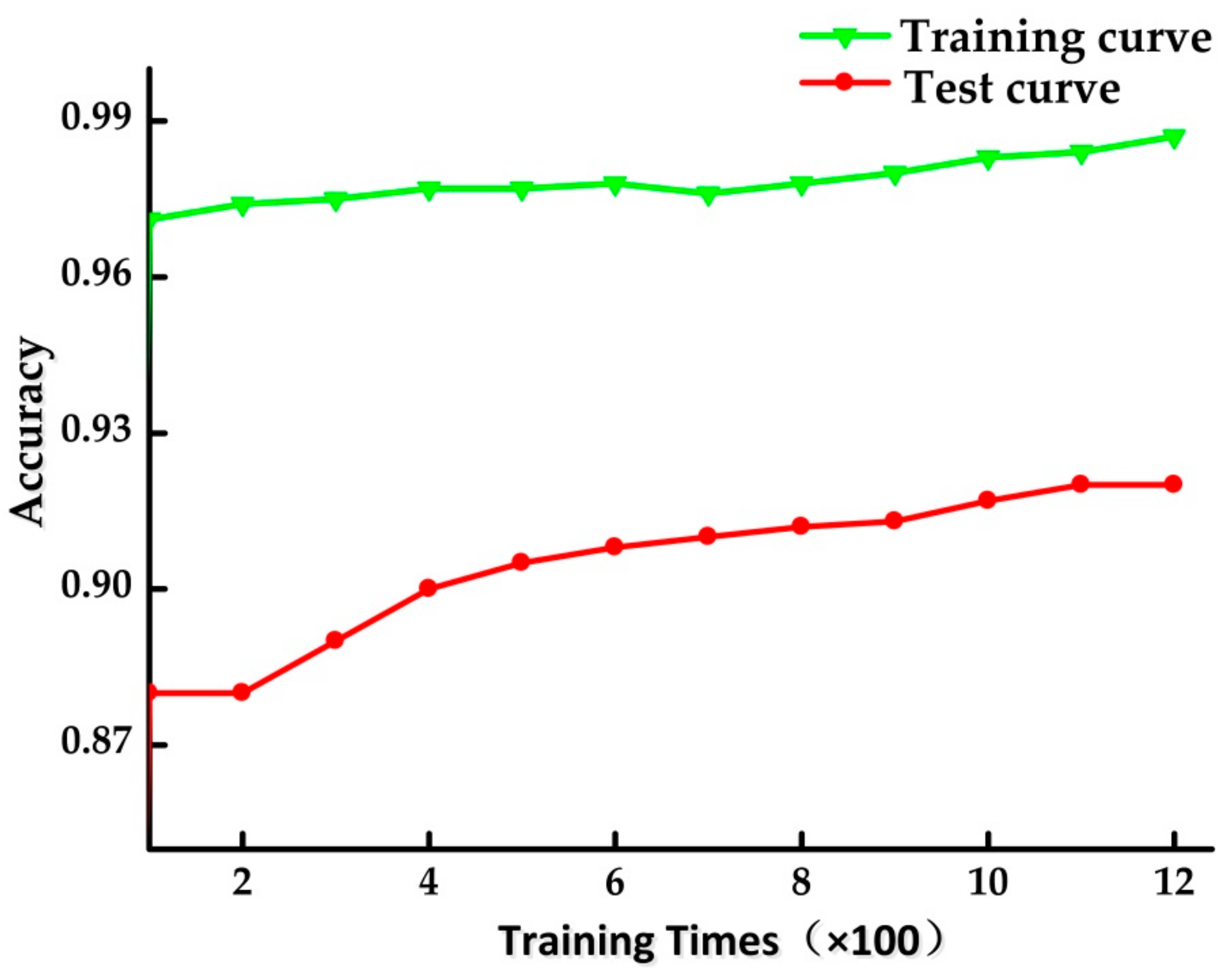
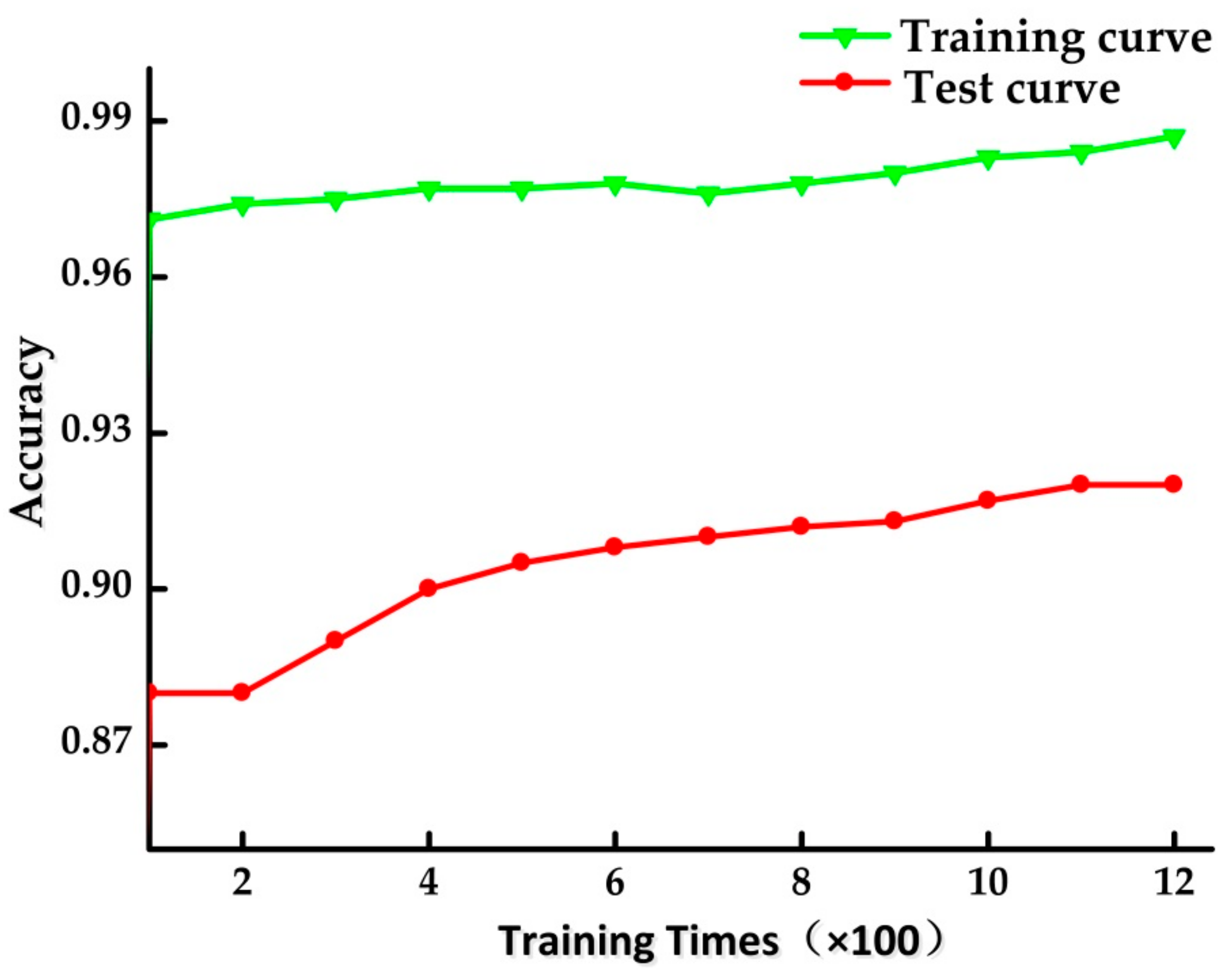
4.5. The Performance of RF for Test Data Set
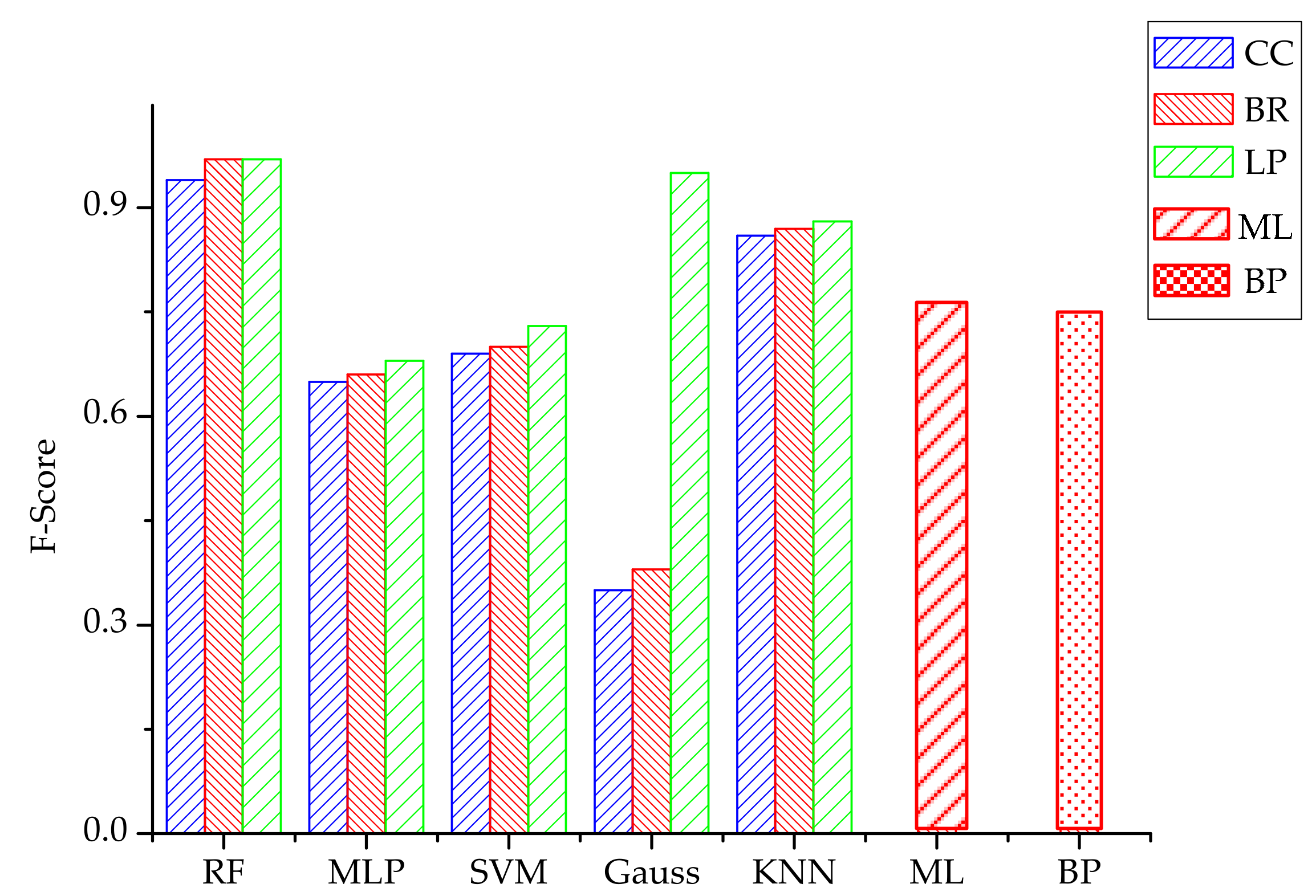
4.6. Comparison with Other Methods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhao, B.; Stankovic, L.; Stankovic, V. On a training-less solution for non-intrusive appliance load monitoring using graph signal processing. IEEE Access 2016, 4, 1784–1799. [Google Scholar] [CrossRef]
- Iglesias, F.; Palensky, P.; Cantos, S.; Kupzog, F. Demand side management for stand-alone hybrid power systems based on load identification. Energies 2012, 5, 4517–4532. [Google Scholar] [CrossRef]
- Chakraborty, D.; Elzarka, H. Advanced machine learning techniques for building performance simulation: A comparative analysis. J. Build. Perf. Simul. 2019, 12, 193–207. [Google Scholar] [CrossRef]
- Smarra, F.; Jain, A.; de Rubeis, T.; Ambrosini, D.; D’Innocenzo, A.; Mangharam, R. Data-Driven Model Predictive Control using random forest for building energy optimization and climate control. Appl. Energy 2018, 226, 1252–1272. [Google Scholar] [CrossRef]
- Madhur, B.; Francesco, S.; Rahul, M. DR-advisor: A data-driven demand response recommender system. Appl. Energy 2016, 170, 30–46. [Google Scholar]
- Hart, G.W. Nonintrusive appliance load monitoring. Proc. IEEE 1992, 80, 1870–1891. [Google Scholar] [CrossRef]
- Rahimpour, A.; Qi, H.; Fugate, D.; Kuruganti, T. Non-intrusive energy disaggregation using non-negative matrix factorization with Sum-to-k constraint. IEEE Trans. Power Syst. 2017, 32, 4430–4441. [Google Scholar] [CrossRef]
- Parson, O.; Ghosh, S.; Weal, M.; Rogers, A. An unsupervised training method for non-intrusive appliance load monitoring. Artif. Intell. 2014, 217, 1–19. [Google Scholar] [CrossRef]
- Tabatabaei, S.M.; Dick, S.; Xu, W. Toward non-intrusive load monitoring via multi-label classification. IEEE Trans. Smart Grid. 2017, 8, 26–40. [Google Scholar] [CrossRef]
- Rahimi, S.; Chan, A.D.C.; Goubran, R.A. Nonintrusive load monitoring of electrical devices in health smart homes. In Proceedings of the IEEE International Instrumentation and Measurement Technology Conference, Graz, Austria, 13–16 May 2012; pp. 2313–2316. [Google Scholar]
- Chahine, K.; Drissi, K.E.K.; Pasquier, C.; Kerroum, K.; Faure, C.; Jouannet, T.; Michou, M. Electric load disaggregation in smart metering using a novel feature extraction method and supervised classification. Energy Procedia 2011, 6, 627–632. [Google Scholar] [CrossRef]
- Rahayu, D.; Narayanaswamy, B.; Krishnaswamy, S.; Labbé, C.; Seetharam, D.P. Learning to be energy-wise: Discriminative methods for load disaggregation. In Proceedings of the 3rd International Conference on Future Energy Systems: Where Energy, Computing and Communication Meet, Madrid, Spain, 9–11 May 2012; pp. 1–4. [Google Scholar]
- Rahimi, S. Usage Monitoring of Electrical Devices in a Smart Home. Ph.D. Thesis, Carleton University, Ottawa, ON, Canada, 2012. [Google Scholar]
- Figueiredo, M.; de Almeida, A.; Ribeiro, B. Home electrical signal disaggregation for non-intrusive load monitoring (NILM) systems. Neurocomputing 2012, 96, 66–73. [Google Scholar] [CrossRef]
- Berges, M.; Goldman, M.; Matthews, H.; Soibelman, L.; Anderson, K. User-centered nonintrusive electricity load monitoring for residential buildings. J. Comput. Civil Eng. 2011, 25, 471–480. [Google Scholar] [CrossRef]
- Chang, H.; Lin, L.; Chen, N.; Lee, W. Particle-swarm-optimization-based nonintrusive demand monitoring and load identification in smart meters. IEEE Trans. Ind. Appl. 2013, 49, 2229–2236. [Google Scholar] [CrossRef]
- Chang, H. Non-intrusive demand monitoring and load identification for energy management systems based on transient feature analyses. Energies 2012, 5, 4569–4589. [Google Scholar] [CrossRef]
- Semwal, S.; Singh, M.; Prasad, R.S. Group control and identification of residential appliances using a nonintrusive method. Turk. J. Elect. Eng. Comput. Sci. 2015, 23, 1805–1816. [Google Scholar] [CrossRef]
- Srinivasan, D.; Ng, W.S.; Liew, A.C. Neural-network-based signature recognition for harmonic source identification. IEEE Trans. Power Deliv. 2006, 21, 398–405. [Google Scholar] [CrossRef]
- Ruzzelli, A.G.; Nicolas, C.; Schoofs, A.; O’Hare, G.M.P. Real-time recognition and profiling of appliances through a single electricity sensor. In Proceedings of the 7th Annual IEEE Communications Society Conference on Sensor, Mesh and Ad Hoc Communications and Networks (SECON), Boston, MA, USA, 21–25 June 2010; pp. 1–9. [Google Scholar]
- Du, L. Support vector machine-based methods for non-intrusive identification of miscellaneous electric loads. In Proceedings of the 38th Annual Conference on IEEE Industrial Electronics Society, Montreal, QC, Canada, 25–28 October 2012; pp. 4866–4871. [Google Scholar]
- Jiang, L.; Li, J.; Luo, S.; West, S.; Platt, G. Power load event detection and classification based on edge symbol analysis and support vector machine. Appl. Comput. Intell. Soft Comput. 2012, 2012, 27. [Google Scholar] [CrossRef]
- Hoogsteen, G.; Krist, J.O.; Bakker, V.; Smit, G.J.M. Nonintrusive appliance recognition. In Proceedings of the 3rd IEEE PES Innovative Smart Grid Technologies Europe (ISGT Europe), Berlin, Germany, 14–17 October 2012; pp. 1–7. [Google Scholar]
- Hosseini, S.M.; Carli, R.; Dotoli, M. Model predictive control for real-time residential energy scheduling under uncertainties. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018; pp. 1386–1391. [Google Scholar]
- Sperstad, I.B.; Korpås, M. Energy Storage Scheduling in Distribution Systems Considering Wind and Photovoltaic Generation Uncertainties. Energies 2019, 12, 1231. [Google Scholar] [CrossRef]
- Carli, R.; Dotoli, M. Energy scheduling of a smart home under nonlinear pricing. In Proceedings of the 53rd IEEE Conference on Decision and Control, Los Angeles, CA, USA, 15–17 December 2014; pp. 5648–5653. [Google Scholar]
- Wu, X.; Han, X.; Liu, L.Y.; Qi, B. A load identification algorithm of frequency domain filtering under current underdetermined separation. IEEE Access 2018, 6, 37094–37107. [Google Scholar] [CrossRef]
- Strobl, C.; Malley, J.; Tutz, G. An introduction to recursive partitioning: Rationale, application and characteristics of classification and regression trees, bagging and random forests. Psychol. Methods 2009, 14, 323–348. [Google Scholar] [CrossRef]
- Dietterich, T.G. An experimental comparison of three methods for constructing ensembles of decision trees: Bagging, boosting, and randomization. Mach. Learn. 2000, 40, 139–157. [Google Scholar] [CrossRef]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Anderson, K.; Ocneanu, A.; Benitez, D.; Carlson, D.; Rowe, A.; Berges, M. BLUED: A fully labeled public dataset for event-based non-intrusive load monitoring research. In Proceedings of the 2012 Workshop on Data Mining Applications in Sustainability (SustKDD 2012), Beijing, China, 12–16 August 2012. [Google Scholar]
- Bundit, B.; Waranyu, W.; Pattana, R. A non-intrusive load monitoring system using multi-label classification approach. Sustain. Cities Soc. 2018, 39, 621–630. [Google Scholar]
- Wang, Z.Y.; Wang, Y.R.; Zeng, R.C.; Srinivasan, R.S.; Ahrentzen, S. Random Forest based hourly building energy prediction. Energy Build. 2018, 171, 11–25. [Google Scholar] [CrossRef]
- Amit, Y.; Geman, D. Shape quantization and recognition with randomized trees. Neural Comput. 1997, 9, 1545–1588. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IRMS | IC | IMAX | P | Q | PF | FW | HAR3rd | Printer | Cp1 | Cp2 | Kettle | Microwave |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10.36 | 0.59 | 17.70 | 4995 | 131.71 | 126.38 | 14.11 | 3.55 | 1 | 1 | 1 | 1 | 1 |
| 10.29 | 0.59 | 17.36 | 4820 | 236 | 126.80 | 14.00 | 3.52 | 1 | 0 | 1 | 1 | 1 |
| 10.23 | 0.60 | 17.02 | 4927 | 91.13 | 128.11 | 13.92 | 3.46 | 1 | 1 | 0 | 1 | 1 |
| 7.03 | 0.55 | 12.73 | 3206 | 303.86 | 81.26 | 9.12 | 3.57 | 1 | 1 | 1 | 0 | 1 |
| 4.86 | 0.65 | 7.57 | 2365 | 526.7 | 284.28 | 6.83 | 0.76 | 1 | 1 | 1 | 1 | 0 |
| Classification Algorithm | Building Time(s) | Identification Time(s) |
|---|---|---|
| RF | 1.2 | 0.35 |
| k-NN | 2.5 | 0.78 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, X.; Gao, Y.; Jiao, D. Multi-Label Classification Based on Random Forest Algorithm for Non-Intrusive Load Monitoring System. Processes 2019, 7, 337. https://doi.org/10.3390/pr7060337
Wu X, Gao Y, Jiao D. Multi-Label Classification Based on Random Forest Algorithm for Non-Intrusive Load Monitoring System. Processes. 2019; 7(6):337. https://doi.org/10.3390/pr7060337
Chicago/Turabian StyleWu, Xin, Yuchen Gao, and Dian Jiao. 2019. "Multi-Label Classification Based on Random Forest Algorithm for Non-Intrusive Load Monitoring System" Processes 7, no. 6: 337. https://doi.org/10.3390/pr7060337
APA StyleWu, X., Gao, Y., & Jiao, D. (2019). Multi-Label Classification Based on Random Forest Algorithm for Non-Intrusive Load Monitoring System. Processes, 7(6), 337. https://doi.org/10.3390/pr7060337