Abstract
System identification has been a major advancement in the evolution of engineering. As it is by default the first step towards a significant set of adaptive control techniques, it is imperative for engineers to apply it in order to practice control. Given that system identification could be useful in creating a digital twin, this work focuses on the initial stage of the procedure by discussing simplistic system order identification. Through specific numerical examples, this study constitutes an investigation on the most “natural” method for estimating the order from responses in a convenient and seamless way in time-domain. The method itself, originally proposed by Ho and Kalman and utilizing linear algebra, is an intuitive tool retrieving information out of the data themselves. Finally, with the help of the limitations of the methods, the potential future outlook is discussed, under the prism of forming a digital twin.
1. Introduction
Adaptive control has been quite popular over the last fifty years [1,2], with a variety of methodologies available [3]. As a matter of fact, as early as 1955, the adaptive techniques have been reported to be widely utilized in industry and this can be come across in literature [4]. The comparative advantage, being the lack of the model, has helped in creating huge related literature. Even nowadays, with Industry 4.0-like movements across the Globe being the main streams of digitalization trends in industry [5,6], the cognitive functionalities of automation (exploiting Cyber–Physical Systems and Internet of Things) have been integrated to a great extent and the use of adaptive control techniques has been spread even more. Also, there have been reported works [7], where the well-established technology of adaptive system identification has been presented as an underlying technology for a digital twin.
Applications of adaptive control can be found literally everywhere. From domestic applications [8], to engineering [9] and manufacturing [10], it is highly evident that adaptive control is very useful. Indicatively, recently, identification techniques had been used to model a system response originating from Partial Differential Equations [11] and attempting to control it in an empirical, yet adaptive way. In the case of a digital twin formation, automatic operation is highly important, so the identification phase is of utmost importance.
A brief, yet full, review on the State-of-The-Art on methods of identification techniques—and more specifically on the issue of choosing the order of the model—reveals initially the use of empirical methods such as trial and error [12], estimation utilizing the frequency domain [13], and maximum a posteriori (MAP) method [14]. Works have been done previous on the choice the the most suitable method [15]. Furthermore, the co-variances matrix and the residual whiteness are two more methods [16,17] that are often discussed. Moreover, the set of Bayesian information criterion (BIC)/Akaike information criterion (AIC)/generalized information criterion (GIC) methodologies is another set of methods [18,19] highly utilized; in the literature there has also been a practical comparison between residual sum of squares (RSS) and BIC [20]. It is worth mentioning at this point that the later method(s) implies the integration of the concept of information.
What seems to be missing, however, is a numerical illustration on the simplest, intuitive way to extract such information (meaning the order of the system) from data (the responses themselves). To this end, this work attempts to investigate numerically a simple method for the estimation of the system order, in time domain, utilizing the linear dependence between the sampled data. The concept of the rank of the matrix is utilized as the tool to perform this, as originally suggested by Ho and Kalman [21]. The paper is structured as follows: Firstly, an underlying framework is given. Thus, the methodology of creating a digital twin for a manufacturing process through data-driven models is illustrated. Also, the significance of introducing automated order estimation techniques to such digital twins is pointed out. Next, the Ho–Kalman algorithm is presented and is compared against other methods. In continuation, numerical examples are given on the efficiency of the Ho–Kalman algorithm in various cases. Finally, conclusions are extracted on the significance and the usability of the algorithm.
2. Framework
Regarding manufacturing processes digital twins, it is extremely useful that they are “near-real-time” [22]. This could be defined as having a running time of at least one order of magnitude smaller than process time constants. This way, control and optimization would be feasible. Data-driven problems in particular are very flexible towards this end, as they can be based on adaptive control techniques. However, the estimation of system order may be yet another loophole as proved with numerical examples herein. The framework implied herein is based on such technologies and the order estimation is discussed.
Under the current framework, the Ho–Kalman estimation is considered as an order estimation algorithm. As proved hereafter, the algorithm could be applied with great success in some cases and the scope of the current work is to examine the applicability of this method. The framework, in full description, is described in the list below, given the fact that the main module of the digital twin is a dynamic system. The main functionality is the control of the physical system (process), but other scopes can be defined on top of that, such as running the simulation to respond to What-if scenarios and be able to find proper working conditions (process parameters). Figure 1 is used to illustrate the operation of such a control-based digital twin.
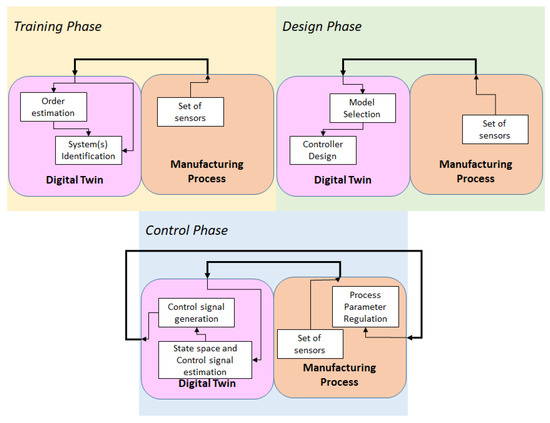
Figure 1.
Underlying framework that takes order estimation into account.
Training phase:
- Data are aggregated for various cases (i.e., different materials)
- Ho–Kalman algorithm is applied to estimate the order of the system
- Plain estimation techniques are applied (i.e., mean least squares) to retrieve the transfer function(s)
Design phase:
- Sensors are used to detect the model that should be applied
- The controller is designed (i.e., Proportional–Integral–Derivative)
Control phase:
- Sensors are used to measure input and output of the system
- (optional) An observer is used to estimate the state (inner variables) of the system
- The control signal is generated and control is applied (these may be two different steps depending on the implementation)
3. Method
As briefly aforementioned, the method investigated here is based on the fact that linear systems response values at time n (in the case of discrete systems) are linear combinations of previous values at time , for some . Therefore, the concept of linear independence is exploited, through the concept of ranks of matrices. To achieve this, a matrix is formed, containing translated versions of the response, as shown in Equation (1), given a response .
The order of the system S that had as a response, is expected to be equal to the rank of this matrix, namely . Even in the marginal case where the N is taken to be equal to (with M being the order of the system) it is evident that the rank of the matrix is equal to the order of the system, as shown in Equation (2).
In the next sections, the numerical performance of this algorithm is investigated with respect to the complexity of the system; the order itself, the system structure and potential noise interfering.
Comparison to Other Methods and Correlation to Information
For reasons of completeness, this simple method should be compared against other ones. So, to this end, the following response of Equation (3) is utilized. The investigated method gives out explicitly (and correctly) an order of 5. However, AIC-based order estimation gives out 8, as shown in Figure 2, while Co-variant Matrix Method leads to inclusive results, as showed in Table 1 (a potential adoption of order 3 could take place).
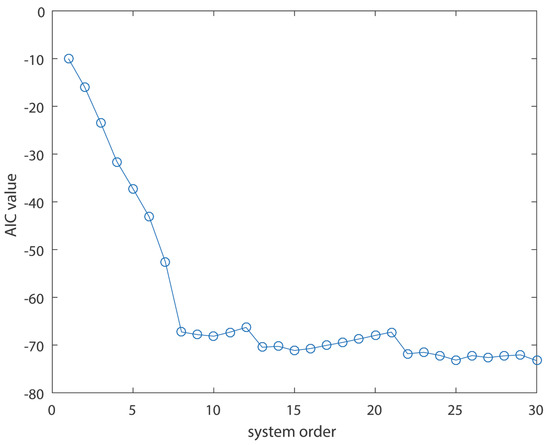
Figure 2.
Akaike information criterion (AIC) values as a function of the system order (for system of Equation (3)).

Table 1.
Co-variance Matrix Results.
This small numerical example has pointed out the numerical superiority of this algorithm—in a case where the method is applicable in its current form. Interestingly enough, the whole point of modelling with a differences equation is of course to be able to reproduce a sequence by a finite (smaller) number of numbers. This slightly reminds one of Chaitin’s work [23] on linking compression with theory (the concept of statistical inference is also relevant). The only difference herein is that instead of utilizing bits, one tries to compress numbers into numbers, regardless of digits. The same principle lies behind the use of auto-encoders, as illustrated in Figure 3. The objective is to utilize a representative feature or equivalently representative compressed signal or image. Thus, the complexity and the dimensionality of the data is reduced. This is very useful for cases where the computational effort has to be reduced. The rank of the responses matrix (even in its full infinite version) is an index of such a complexity (information). So, transformation metrics related to invertibility can also be used, such as the determinant or the eigenvalues distribution. Alternatively, the Lagrangian (or instead a custom Liapunov function) of the system can be used as a different metric. Such a function is of degree higher than linear, thus there is link to correlation matrix method as well. This kind of compression has been very useful in cases where the complexity is simply measured by the rank of the system, such as the case of tool-wear [24].
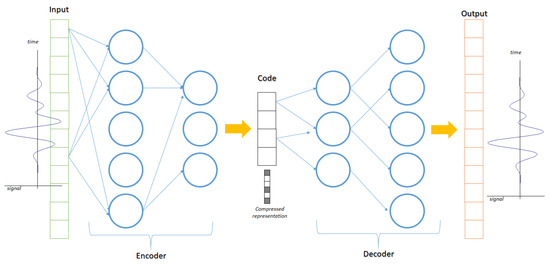
Figure 3.
The use of an auto-encoder for data reduction and information compression.
4. Numerical Behaviour and Applicability
So, in the context of finding the numerical limitations of this simple method, various systems have been studied in terms of system order identification. In this section particularly, the applicability and the limitations of the method are shown and discussed through specific paradigms.
4.1. Simple Numerical Examples
To begin with, a first-order system—that would give a response of the form —is utilized (Equation (4)). Thus, a responses matrix of dimensions would be given by .
Even using symbolic matrices, without specific values, the rank of the matrix, for various dimensions, is equal to 1, as also computationally shown in Figure 4, for a specific value of Q. This is easily proved, as each row (or column) is the product of the previous one with .
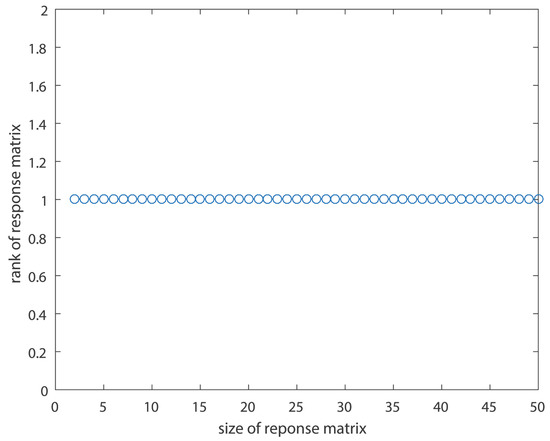
Figure 4.
The rank of the responses matrices as a function of the responses matrix dimensions for the case of a first order system.
So far, everything seems to work well. However, in reality, the sampled values of the responses contain noise, either from measurement, or from sampling itself. Therefore, in this section, noise is going to be regarded, as this is the case in all measured responses. To simulate this, a uniform random number is added after sampling the response, which is regarded in continuous time. Supposing that the continuous-time response is a simplified version of the above one, sampling is applied. In the case where the amplitude of the noise is relatively small, then, as shown in Figure 5, the convergence is rather rapid. However, if the noise amplitude is increased by one order of magnitude (same Figure), then the convergence becomes much slower. Oddly enough, the unitary signal () has been added to the response on purpose. It has been observed that if the mean value of the response is increased by an offset, then the method converges much faster. Also, the adoption of a row-echelon form of the responses matrix also seems to accelerate the convergence of the method. Furthermore, to study the effect of the poles’ proximity on a second-order system, the following response of Equation (5) is regarded given that .
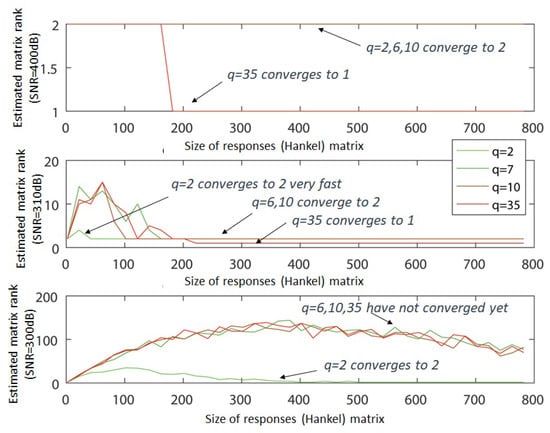
Figure 5.
The rank of the responses matrices as a function of the responses matrix dimensions and the proximity of the poles in the case of a second order system. Noise is present.
The elaboration of such a system has as a goal to study the numerical limitations of the method, as the system tends to be a double-pole system in the limit of q approaching infinity. Simultaneously, the effect of the dominance of one pole is studied. The results are shown in Figure 5. Evidently, the rank remains equal to 2, for values of and , depending also on Signal-to-Noise Ratio (SNR) value. As proved with this numerical study, it seems that for extreme cases of poles’ proximity, if the SNR becomes substantially small, then it requires a lot of data for the order estimation alone. For precise calculations in some applications, specifically where this almost double pole affects the controller design, then the response size has to reach up to thousands of samples. Regarding the implementation of the training phase, this affects the use of higher storage capacity, higher memory for processing and faster processors, potentially prohibiting the use of low-performance embedded systems.
4.2. Performance on Systems of Higher Order
To move on to higher order systems, the (arbitrarily chosen) following response (Equation (6)) consisting of terms is considered:
The choice of this series as a system leads to a very interesting diagram of as a function of N. The results are given in Figure 6 and Figure 7, for and , respectively. It is quite interesting that in the case of sinusoidal functions, some sort of numerical effect takes place. This drives the rank estimation evolution (since it is a function of responses matrix size) to converge to the value of at a “faster” rate. This should be investigated to a further extent, through the consideration of a case of a system of even larger order. This is not the case when dealing with exponential functions, probably due to bad condition number of the responses matrix. Also, since often there can be responses of high order [25], i.e., close to 100 [26], similar case have also been included here.
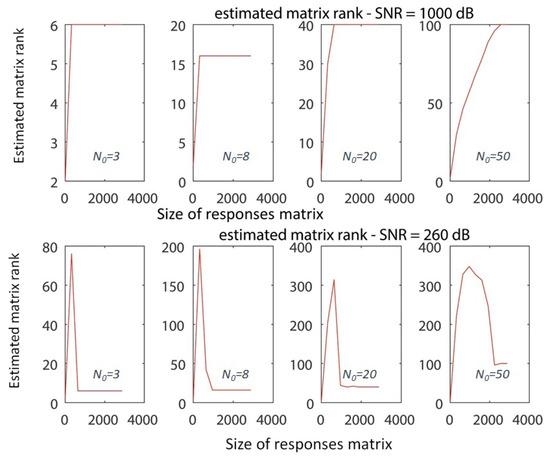
Figure 6.
The rank of the responses matrices as a function of the responses matrix dimensions, for the case of Equation 6, where and the upper limit of the sum varies. The values of are shown within the plots.
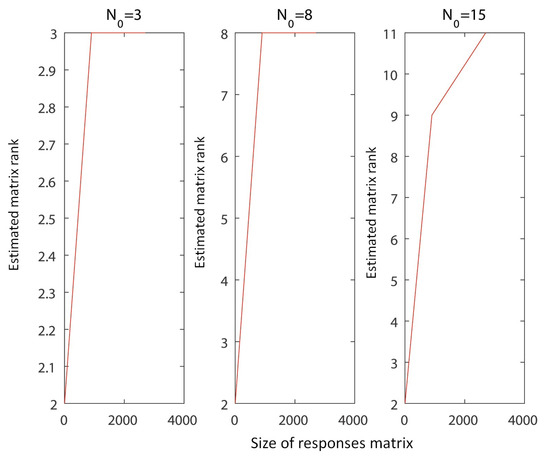
Figure 7.
The rank of the responses matrices as a function of the responses matrix dimensions, for the case of Equation 6, where and the upper limit of the sum varies. The values of are shown above the plots.
4.3. Non-Homogeneous Systems
Moving on to a different kind of complexity, one can form a matrix for the case of for a non-homogeneous system, such as in the case of . The rank of a responses matrix would be equal to , where the Z is the number of Zeros and P the number of poles (1 and 1 respectively). If one augments this matrix to be or , padding with (translated) excitation function values to the bottom or to the right, as shown in Equation (7) below, then the rank remains equal to 2. This indicates that the order of the differential equation is equal to P (equal to 1 in this case), as the input and the output have linearly dependent terms.
5. Summary and Future Outlook
The simplest and most intuitive method for estimating the order of the model by the responses themselves in time-domain, utilizing the rank of the responses matrix, has been reviewed as a candidate method for forming automatically a digital twin. It has been proved to be quite successful in many cases, with the efficiency of the algorithm depending highly on the order of the problem as well as the available response dataset size. More specifically, the algorithm appears to work successfully under any kind of system, even though a large amount of data is needed when SNR becomes smaller. The use of this large amount of data seems to cancel the uncertainty introduced by noise. However, its extension towards practical rank estimation algorithms or iterative decomposition of responses is required so that it is able to handle highly noisy data. This iterative method, may be loosely correlated to the Gram–Schmidt procedure [27], however, one must have in mind the issue of orthogonality of signals. Nevertheless, the Ho–Kalman algorithm has been proved a very promising tool that may be really useful in slightly noisy data of high dimensionality. In addition to the above, it can be very useful in terms of clustering, in a two-fold way; speeding up computations and offering intuition to a human operator. Also, it seems to be a powerful tool towards compression of data. It has the capability to represent a whole signal through some sort of complexity abstraction.
The extensibility of the Ho–Kalman method in non-linear systems ought to be further investigated. The first barrier in this direction is expected to be the very formation of a responses matrix. However, more elaborate tools can be used towards this. Moreover, it seems that as far as the formation of a digital twin is concerned, the use of such a method is promising, however, in the presence of noise, the method has to be combined with the use of another method. Digital twins, either for continuous manufacturing processes, such as plastic extrusion and chemical reactions, or discrete manufacturing processes, such as laser welding and additive manufacturing, will highly benefit from order estimation techniques. This benefit is highly linked to the automated decision making procedure, as the order estimation will not be some kind of fuzzy process that the engineer has to go through. The digital twin will automatically select the values of the (data-driven) model parameters and the control signals generation will be performed automatically and seamlessly.
Funding
This research was partially funded as per the acknowledgement.
Acknowledgments
This work is under the framework of EU Project STREAM-0d. This project has received funding from the European Union’s Horizon 2020 research and innovation program under grant agreement No 723082. The dissemination of results herein reflects only the authors’ view and the Commission is not responsible for any use that may be made of the information it contains.

Conflicts of Interest
The authors declare no conflict of interest.
References
- Seborg, D.; Edgar, T.; Shah, S. Adaptive control strategies for process control: A survey. AIChE J. 1986, 32, 881–913. [Google Scholar] [CrossRef]
- Dumont, G.A.; Huzmezan, M. Concepts, methods and techniques in adaptive control. In Proceedings of the American Control Conference, Anchorage, AK, USA, 10 May 2002; Volume 2, pp. 1137–1150. [Google Scholar]
- Yechiel, O.; Guterman, H. A Survey of Adaptive Control. Int. Rob. Auto J. 2017, 3, 00053. [Google Scholar] [CrossRef]
- Aseltine, J.; Mancini, A.; Sarture, C. A survey of adaptive control systems. IRE Trans. Autom. Control. 1958, 6, 102–108. [Google Scholar] [CrossRef]
- Trotta, D.; Garengo, P. Industry 4.0 key research topics: A bibliometric review. In Proceedings of the 2018 7th International Conference on Industrial Technology and Management (ICITM), Oxford, UK, 9 March 2018; pp. 113–117. [Google Scholar]
- Mourtzis, D.; Vlachou, E.; Milas, N. Industrial Big Data as a result of IoT adoption in manufacturing. Procedia CIRP 2016, 55, 290–295. [Google Scholar] [CrossRef]
- Brandtstaedter, H.; Ludwig, C.; Hübner, L.; Tsouchnika, E.; Jungiewicz, A.; Wever, U. Digital twins for large electric drive trains. In Proceedings of the 2018 Petroleum and Chemical Industry Conference Europe (PCIC Europe), Antwerp, Belgium, 7 June 2018; pp. 1–5. [Google Scholar]
- Han, D.M.; Lim, J.H. Design and implementation of smart home energy management systems based on zigbee. IEEE Trans. Consum. Electron. 2010, 56, 1417–1425. [Google Scholar] [CrossRef]
- Nivison, S.A.; Khargonekar, P. A Sparse Neural Network Approach to Model Reference Adaptive Control with Hypersonic Flight Applications. In Proceedings of the 2018 AIAA Guidance, Navigation, and Control Conference, Kissimmee, FL, USA, 12 January 2018; p. 0842. [Google Scholar]
- Chryssolouris, G. Manufacturing Systems: Theory and Practice; Springer: New York, NY, USA, 2006. [Google Scholar]
- Papacharalampopoulos, A.; Stavridis, J.; Stavropoulos, P.; Chryssolouris, G. Cloud-based control of thermal based manufacturing processes. Procedia CIRP 2016, 55, 254–259. [Google Scholar] [CrossRef][Green Version]
- Matlab Model Structure. Available online: https://www.mathworks.com/help/ident/ug/model-structure-selection-determining-model-order-and-input-delay.html (accessed on 1 February 2019).
- Brincker, R.; Zhang, L.; Andersen, P. Modal identification from ambient responses using frequency domain decomposition. In Proceedings of the 18th International Modal Analysis Conference (IMAC), San Antonio, TX, USA, 7–10 February 2000. [Google Scholar]
- Karimian-Azari, S.; Jensen, J.R.; Christensen, M.G. Fundamental frequency and model order estimation using spatial filtering. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 9 May 2014; pp. 5964–5968. [Google Scholar]
- Stoica, P.; Selen, Y. Model-order selection: A review of information criterion rules. IEEE Signal Process. Mag. 2004, 21, 36–47. [Google Scholar] [CrossRef]
- Choi, B. ARMA Model Identification; Springer Science & Business Media: New York, NY, USA, 2012. [Google Scholar]
- McQuarrie, A.D.; Tsai, C.L. Regression and Time Series Model Selection; World Scientific: Singapore, 1998. [Google Scholar]
- Burnham, K.P.; Anderson, D.R. Multimodel inference: Understanding AIC and BIC in model selection. Sociol. Methods Res. 2004, 33, 261–304. [Google Scholar] [CrossRef]
- Fabozzi, F.J.; Focardi, S.M.; Rachev, S.T.; Arshanapalli, B.G. The Basics of Financial Econometrics: Tools, Concepts, and Asset Management Applications; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Kapsalas, C.; Sakellariou, J.; Koustoumpardis, P.; Aspragathos, N. An ARX-based method for the vibration control of flexible beams manipulated by industrial robots. Robot. Comput. Integr. Manuf. 2018, 52, 76–91. [Google Scholar] [CrossRef]
- Ho, B.; Kalman, R.E. Effective construction of linear state-variable models from input/output functions. Automatisierungstechnik 1966, 14, 545–548. [Google Scholar] [CrossRef]
- Papacharalampopoulos, A.; Stavropoulos, P. Towards a Digital Twin for Thermal Processes: Control-centric approach. Procedia CIRP 2019, 86, 110–115. [Google Scholar] [CrossRef]
- Chaitin, G.J. Meta math! The quest for omega. arXiv 2004, arXiv:math/0404335. [Google Scholar]
- Stavropoulos, A.; Papacharalampopoulos, A.; Souflas, T. Indirect online tool wear monitoring and model-based identification of process-related signal. AIME 2020. submitted. [Google Scholar]
- Stavropoulos, P.; Papacharalampopoulos, A.; Vasiliadis, E.; Chryssolouris, G. Tool wear predictability estimation in milling based on multi-sensorial data. Int. J. Adv. Manuf. Technol. 2016, 82, 509–521. [Google Scholar] [CrossRef]
- Spanos, N.; Sakellariou, J.; Fassois, S. Vibration–response–only Statistical Time Series SHM methods: A critical assessment via a lab–scale wind turbine jacket foundation structure and two sensor types. In Proceedings of the ISMA 2016–International Conference on Noise and Vibration Engineering, Leuven, Belgium, 21 September 2016; pp. 4081–4095. [Google Scholar]
- Havlicek, H.; Svozil, K. Dimensional lifting through the generalized Gram–Schmidt process. Entropy 2018, 20, 284. [Google Scholar] [CrossRef]







© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).