Development of Indicator of Data Sufficiency for Feature-based Early Time Series Classification with Applications of Bearing Fault Diagnosis



Abstract
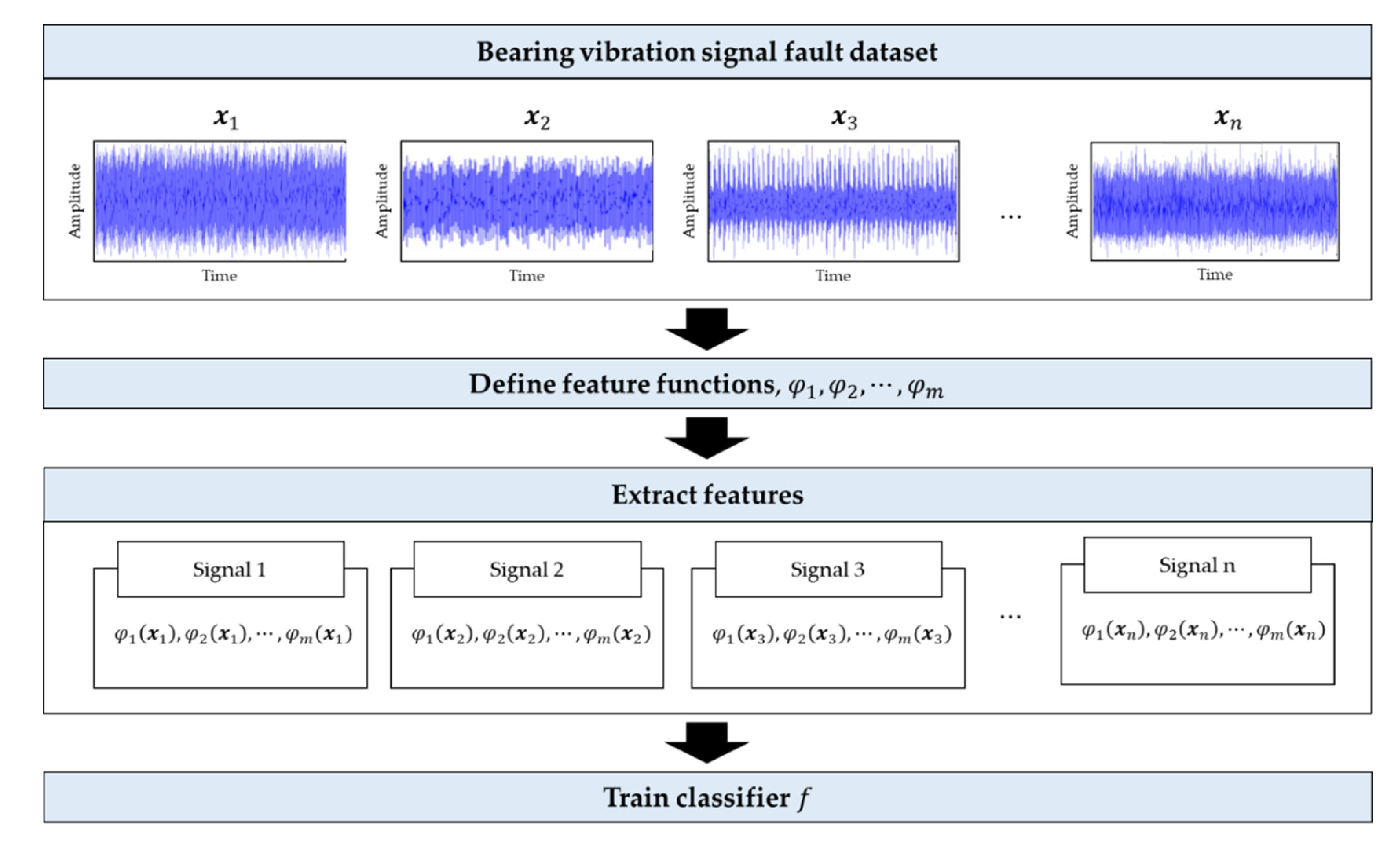
:1. Introduction
2. Early Bearing Fault Diagnosis
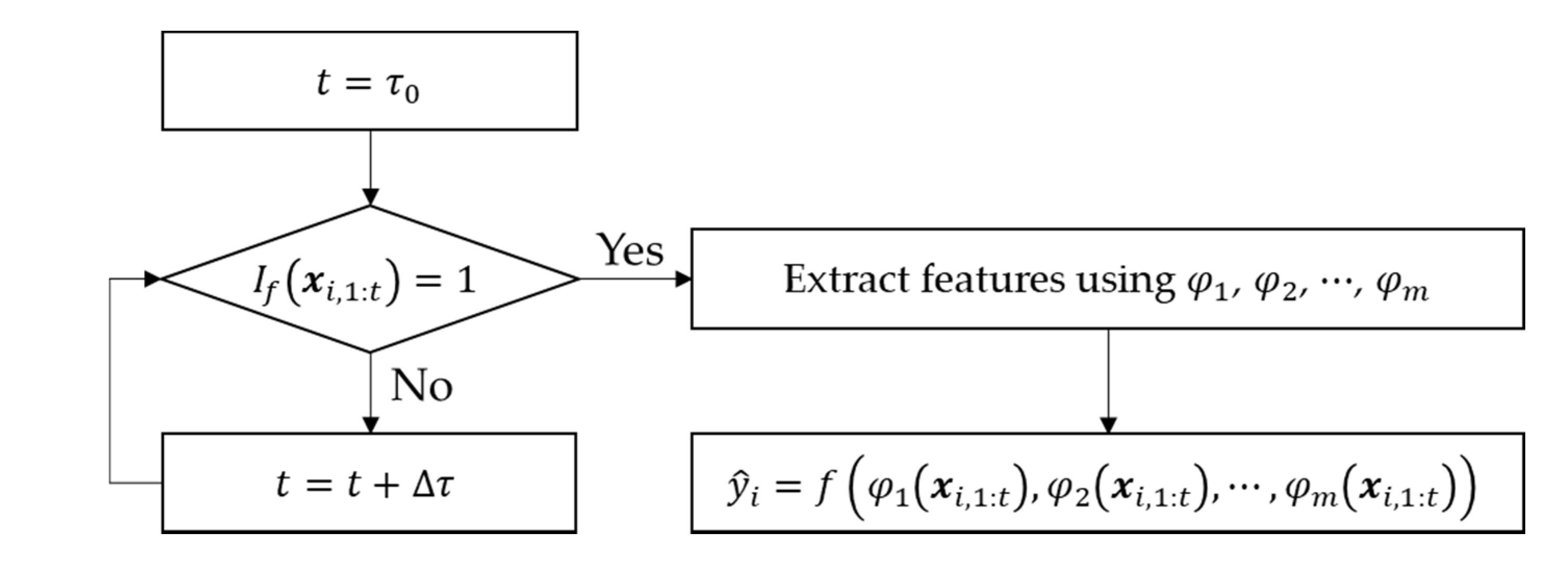
3. Proposed Indicator
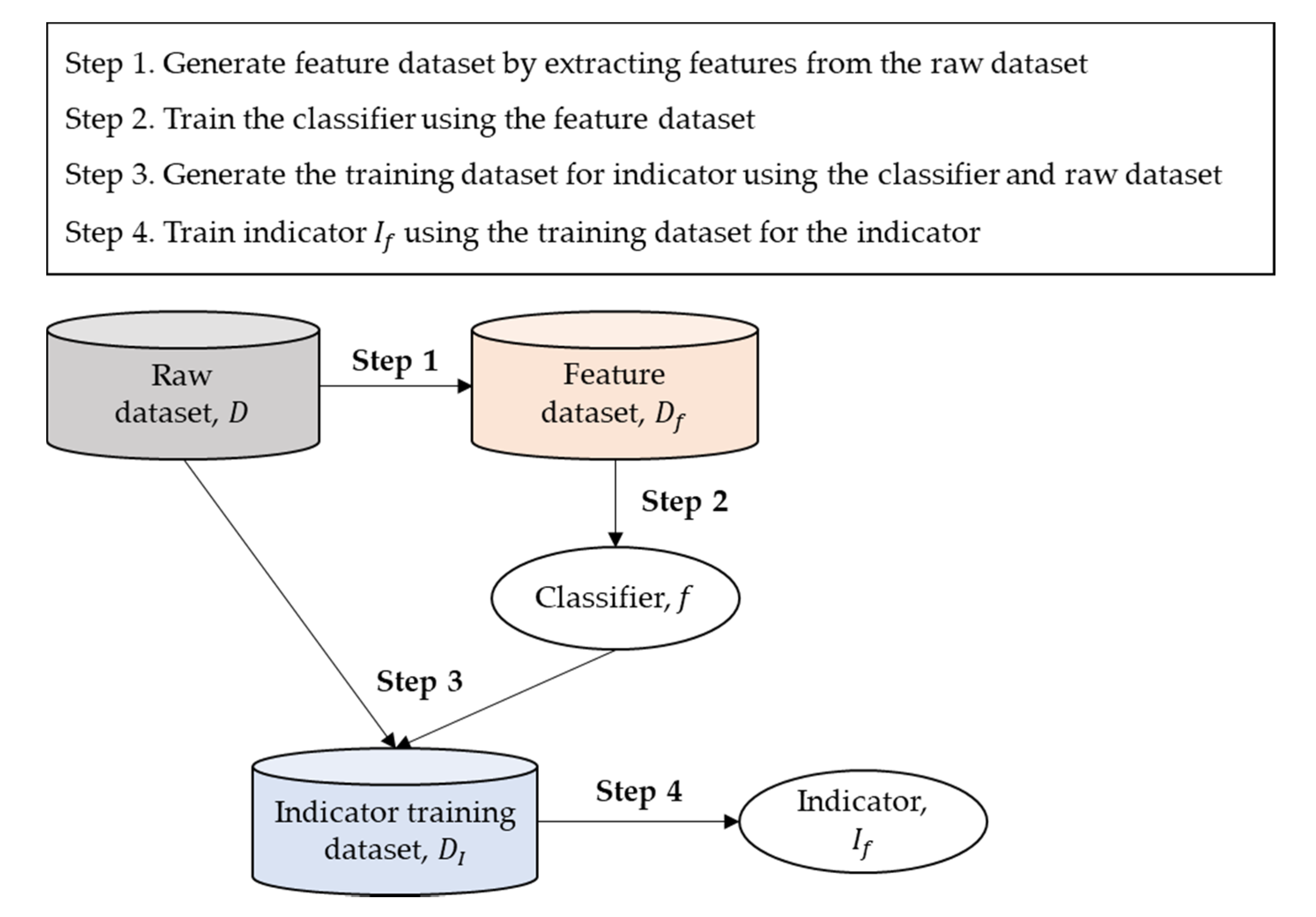
| Algorithm 1. Generation of the indicator training dataset. | |
| Input | , , for , , , |
| Procedure |
|
| Output | |
4. Experiment
4.1. Objective and Process
- Step 1.
- The dataset is randomly split into a training and test dataset for objective evaluation of the proposed indicator. Specifically, the set of indices of time series instances is randomly separated to and with a ratio of 7:3. That is, 70% of samples is randomly selected whose indices are in and is used to train the model, and the remaining 30% of samples in is to test it.
- Step 2.
- A classifier and an indicator are trained using the training dataset , as depicted in Figure 4. We selected ANN and SVM as a classifier, because they have been most frequently used as a feature-based time series classifiers in previous research, e.g., in [14,15,16,17]. Each classifier is trained by means of all features presented in Table 1, as was done in [26].
- Step 3.
- The trained classifier is tested using the test dataset, , in terms of the micro f1-score. It is employed as an accuracy measure because it is a proper measure of multiclass classification, which may have a class imbalance problem. The micro f1-score, which is the harmonic mean of micro precision and recall, is calculated as follows:where micro precision and recall are calculated as follows:where , , and indicate true positive, false positive, and false negative, respectively, when class is regarded as positive.
- Step 4.
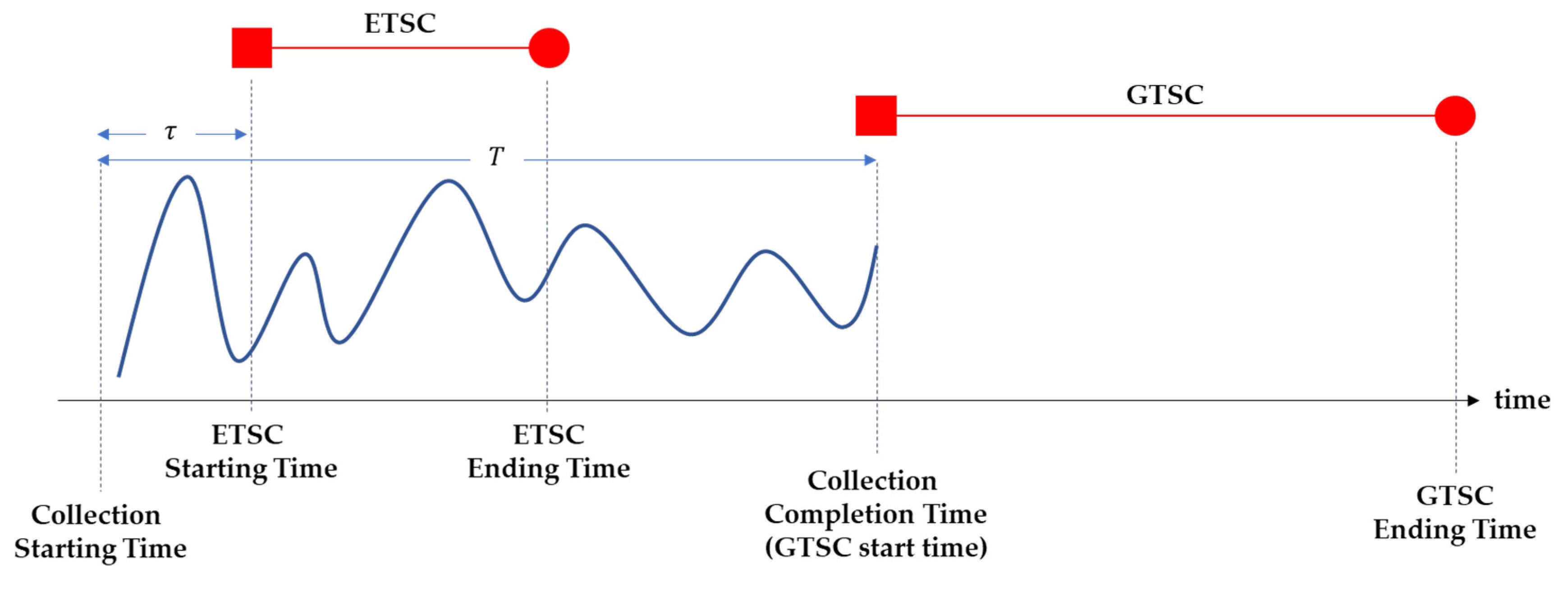
- The accuracy and earliness of the classifier trained with the proposed indicator are calculated using , where indicates the minimum value among satisfying (i.e., ). Earliness is calculated as follows:where denotes the classification start time for time series instance . For accurate and efficient decision for the indicator, our computational experience shows that α should be equal to or bigger than 0.9. and ∆τ can be determined as proposed in the final paragraph of Section 3.
- Step 5.
- The accuracy and earliness of the classifier trained with the CWRO approach are calculated using , where indicates the maximum value among satisfying the standard deviation of .
- Step 6.
- Accuracy and earliness obtained from Steps 4 and 5 are compared.
4.2. Datasets
4.3. Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Jin, X.; Zhao, M.; Chow, T.W.; Pecht, M. Motor bearing fault diagnosis using trace ratio linear discriminant analysis. IEEE Trans. Ind. Electron. 2013, 61, 2441–2451. [Google Scholar] [CrossRef]
- Gupta, P.; Pradhan, M.K. Fault detection analysis in rolling element bearing: A review. Mater. Today 2017, 4, 2085–2094. [Google Scholar] [CrossRef]
- Jin, X.; Sun, Y.; Que, Z.; Wang, Y.; Chow, T.W. Anomaly detection and fault prognosis for bearings. IEEE Trans. Instrum. Meas. 2016, 65, 2046–2054. [Google Scholar] [CrossRef]
- Singleton, R.K.; Strangas, E.G.; Aviyente, S. Extended Kalman filtering for remaining-useful-life estimation of bearings. IEEE Trans. Ind. Electron. 2014, 62, 1781–1790. [Google Scholar] [CrossRef]
- Caesarendra, W.; Tjahjowidodo, T. A review of feature extraction methods in vibration-based condition monitoring and its application for degradation trend estimation of low-speed slew bearing. Machines 2017, 5, 21. [Google Scholar] [CrossRef]
- Li, B.; Chow, M.Y.; Tipsuwan, Y.; Hung, J.C. Neural-network-based motor rolling bearing fault diagnosis. IEEE Trans. Ind. Electron. 2000, 47, 1060–1069. [Google Scholar] [CrossRef] [Green Version]
- Kankar, P.K.; Sharma, S.C.; Harsha, S.P. Fault diagnosis of ball bearings using machine learning methods. Expert. Syst. Appl. 2011, 38, 1876–1886. [Google Scholar] [CrossRef]
- Baydogan, M.G.; Runger, G.; Tuv, E. A bag-of-features framework to classify time series. IEEE Trans. Pattern. Anal. 2013, 35, 2796–2802. [Google Scholar] [CrossRef]
- Povinelli, R.J.; Johnson, M.T.; Lindgren, A.C.; Ye, J. Time series classification using Gaussian mixture models of reconstructed phase spaces. IEEE Trans. Knowl. Data. Eng. 2004, 16, 779–783. [Google Scholar] [CrossRef] [Green Version]
- Pourbabaee, B.; Roshtkhari, M.J.; Khorasani, K. Deep convolutional neural networks and learning ECG features for screening paroxysmal atrial fibrillation patients. IEEE Trans. Syst. Man. Cybern. Syst. 2018, 48, 2095–2104. [Google Scholar] [CrossRef]
- Van Wyk, B.J.; Van Wyk, M.A.; Qi, G. Difference histograms: A new tool for time series analysis applied to bearing fault diagnosis. Pattern. Recognit. Lett. 2009, 30, 595–599. [Google Scholar] [CrossRef]
- Liu, C.L.; Hsaio, W.H.; Tu, Y.C. Time series classification with multivariate convolutional neural network. IEEE Trans. Ind. Electron. 2018, 66, 4788–4797. [Google Scholar] [CrossRef]
- Jeong, Y.S.; Jayaraman, R. Support vector-based algorithms with weighted dynamic time warping kernel function for time series classification. Knowl Based. Syst. 2015, 75, 184–191. [Google Scholar] [CrossRef]
- Wu, S.D.; Wu, P.H.; Wu, C.W.; Ding, J.J.; Wang, C.C. Bearing fault diagnosis based on multiscale permutation entropy and support vector machine. Entropy 2012, 14, 1343–1356. [Google Scholar] [CrossRef] [Green Version]
- Goyal, D.; Choudhary, A.; Pabla, B.; Dhami, S.S. Support vector machines based non-contact fault diagnosis system for bearings. J. Intell. Manuf. 2019, 30, 1–15. [Google Scholar] [CrossRef]
- Gunerkar, R.S.; Jalan, A.K.; Belgamwar, S.U. Fault diagnosis of rolling element bearing based on artificial neural network. J. Mech. Sci. Technol. 2019, 33, 505–511. [Google Scholar] [CrossRef]
- Zhao, D.; Wang, T.; Chu, F. Deep convolutional neural network based planet bearing fault classification. Comput. Ind. 2019, 107, 59–66. [Google Scholar] [CrossRef]
- Ahn, G.; Hur, S. Efficient genetic algorithm for feature selection for early time series classification. Comput. Ind. Eng. 2020, 142, 106345. [Google Scholar] [CrossRef]
- Hatami, N.; Chira, C. Classifiers with a reject option for early time-series classification. In Proceedings of the IEEE Symposium on Computational Intelligence and Ensemble Learning, Singapore, 16–19 April 2013. [Google Scholar]
- He, G.; Duan, Y.; Peng, R.; Jing, X.; Qian, T.; Wang, L. Early classification on multivariate time series. Neurocomputing 2015, 149, 777–787. [Google Scholar] [CrossRef]
- Xing, Z.; Pei, J.; Yu, P.S.; Wang, K. Extracting interpretable features for early classification on time series. In Proceedings of the SIAM International Conference on Data Mining, Mesa, AZ, USA, 28–30 April 2011. [Google Scholar]
- Ghalwash, M.F.; Obradovic, Z. Early classification of multivariate temporal observations by extraction of interpretable shapelets. BMC Bioinform. 2012, 13, 195. [Google Scholar] [CrossRef] [Green Version]
- Mori, U.; Mendiburu, A.; Dasgupta, S.; Lozano, J.A. Early classification of time series by simultaneously optimizing the accuracy and earliness. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 4569–4578. [Google Scholar] [CrossRef]
- Marti, G.; Andler, S.; Nielsen, F.; Donnat, P. Clustering Financial Time Series: How Long Is Enough? In Proceedings of the Twenty-Fifth International Joint Conference on Artificial intelligence, New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Tran, Q.H.; Hasegawa, Y. Topological time-series analysis with delay-variant embedding. Phys. Rev. E 2019, 99, 032209. [Google Scholar]
- Wei, Z.; Wang, Y.; He, S.; Bao, J. A novel intelligent method for bearing fault diagnosis based on affinity propagation clustering and adaptive feature selection. Knowl Based. Syst. 2017, 116, 1–12. [Google Scholar] [CrossRef]
- Rauber, T.W.; de Assis Boldt, F.; Varejão, F.M. Heterogeneous feature models and feature selection applied to bearing fault diagnosis. IEEE Trans. Ind. Electron. 2014, 62, 637–646. [Google Scholar] [CrossRef]
- Prieto, M.D.; Cirrincione, G.; Espinosa, A.G.; Ortega, J.A.; Henao, H. Bearing fault detection by a novel condition-monitoring scheme based on statistical-time features and neural networks. IEEE Trans. Ind. Electron. 2012, 60, 3398–3407. [Google Scholar] [CrossRef]
- Williams, T.; Ribadeneira, X.; Billington, S.; Kurfess, T. Rolling element bearing diagnostics in run-to-failure lifetime testing. Mech. Syst. Signal. Pr. 2001, 15, 979–993. [Google Scholar] [CrossRef]
- Xia, P.; Zhang, L.; Li, F. Learning similarity with cosine similarity ensemble. Inf. Sci. 2015, 307, 39–52. [Google Scholar] [CrossRef]
- Huang, H.; Baddour, N. Bearing vibration data collected under time-varying rotational speed conditions. Data. Brief. 2018, 21, 1745–1749. [Google Scholar] [CrossRef] [PubMed]
- Staszewski, W.J.; Worden, K.; Tomlinson, G.R. Time–frequency analysis in gearbox fault detection using the Wigner–Ville distribution and pattern recognition. Mech. Syst. Signal. Pr. 1997, 11, 673–692. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domain | Feature Function | Formula |
|---|---|---|
| Time domain | Mean | |
| Standard deviation | ||
| Root mean square | ||
| Peak | ||
| Shape factor | ||
| Crest factor | ||
| Impulse factor | ||
| Clearance factor | ||
| Skewness | ||
| Kurtosis | ||
| Frequency domain | Mean frequency | |
| Center frequency | ||
| Root mean square frequency | ||
| Standard deviation frequency |
| Dataset | Data Type | Sampling Frequency (Hz) | Sampling Duration (s) | Class Variable Distribution | Reference |
|---|---|---|---|---|---|
| Dataset #1 | Vibration | 200,000 | 10 | Healthy: 12 Inner race fault: 12 Outer race fault: 12 | [31] |
| Dataset #2 | Vibration | 200,000 | 10 | Healthy: 12 Inner race fault: 12 Outer race fault: 12 Ball fault: 12 | |
| Dataset #3 | Rotational speed | 200,000 | 10 | Healthy: 12 Inner race fault: 12 Outer race fault: 12 Ball fault: 12 | |
| Dataset #4 | Vibration | 12,000 | 40 | Healthy: 5 Inner race fault: 16 Outer race fault: 16 Ball fault: 16 | [32] |
| Dataset | Classifier | Model | Parameter | Accuracy | Earliness |
|---|---|---|---|---|---|
| Dataset #1 | SVM | GTSC | None | 0.6667 | 0.0000 |
| CWRO | 0.6667 | 0.9950 | |||
| 0.6667 | 0.0000 | ||||
| 0.6667 | 0.0000 | ||||
| 0.6667 | 0.0000 | ||||
| Proposed model | 0.6667 | 0.9950 | |||
| 0.7778 | 0.9750 | ||||
| 0.8889 | 0.9050 | ||||
| ANN | GTSC | None | 0.6667 | 0.0000 | |
| CWRO | 0.6667 | 0.0000 | |||
| 0.6667 | 0.0000 | ||||
| 0.6667 | 0.0000 | ||||
| 0.6667 | 0.0000 | ||||
| Proposed model | 0.7778 | 0.9750 | |||
| 0.7778 | 0.9750 | ||||
| 0.7778 | 0.9750 | ||||
| Dataset #2 | SVM | GTSC | None | 0.5786 | 0.0000 |
| CWRO | 0.3333 | 0.9950 | |||
| 0.3333 | 0.9950 | ||||
| 0.3333 | 0.9000 | ||||
| 0.3333 | 0.9000 | ||||
| Proposed model | 0.5786 | 0.9950 | |||
| 0.5786 | 0.9850 | ||||
| 0.5786 | 0.9000 | ||||
| ANN | GTSC | None | 0.5786 | 0.0000 | |
| CWRO | 0.3333 | 0.9000 | |||
| 0.3333 | 0.9000 | ||||
| 0.3333 | 0.9000 | ||||
| 0.3333 | 0.9000 | ||||
| Proposed model | 0.5786 | 0.9950 | |||
| 0.5786 | 0.9850 | ||||
| 0.5786 | 0.9000 | ||||
| Dataset #3 | SVM | GTSC | None | 0.2500 | 0.0000 |
| CWRO | 0.1333 | 0.9950 | |||
| 0.1333 | 0.9950 | ||||
| 0.1333 | 0.9000 | ||||
| 0.1333 | 0.9000 | ||||
| Proposed model | 0.2500 | 0.9950 | |||
| 0.2500 | 0.9950 | ||||
| 0.2500 | 0.9000 | ||||
| ANN | GTSC | None | 0.2500 | 0.0000 | |
| CWRO | 0.1333 | 0.9000 | |||
| 0.1333 | 0.9000 | ||||
| 0.1333 | 0.9000 | ||||
| 0.1333 | 0.9000 | ||||
| Proposed model | 0.2500 | 0.9000 | |||
| 0.2500 | 0.9000 | ||||
| 0.2500 | 0.9000 | ||||
| Dataset #4 | SVM | GTSC | None | 0.5294 | 0.0000 |
| CWRO | 0.7059 | 0.9792 | |||
| 0.7059 | 0.9792 | ||||
| 0.4705 | 0.7015 | ||||
| 0.4705 | 0.7015 | ||||
| Proposed model | 0.7692 | 0.9413 | |||
| 0.7692 | 0.9413 | ||||
| 0.7892 | 0.8544 | ||||
| ANN | GTSC | None | 0.8235 | 0.0000 | |
| CWRO | 0.5294 | 0.7000 | |||
| 0.5294 | 0.7000 | ||||
| 0.5294 | 0.7000 | ||||
| 0.5294 | 0.7000 | ||||
| Proposed model | 0.6956 | 0.8544 | |||
| 0.5714 | 0.8131 | ||||
| 0.5294 | 0.7000 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahn, G.; Lee, H.; Park, J.; Hur, S. Development of Indicator of Data Sufficiency for Feature-based Early Time Series Classification with Applications of Bearing Fault Diagnosis. Processes 2020, 8, 790. https://doi.org/10.3390/pr8070790
Ahn G, Lee H, Park J, Hur S. Development of Indicator of Data Sufficiency for Feature-based Early Time Series Classification with Applications of Bearing Fault Diagnosis. Processes. 2020; 8(7):790. https://doi.org/10.3390/pr8070790
Chicago/Turabian StyleAhn, Gilseung, Hwanchul Lee, Jisu Park, and Sun Hur. 2020. "Development of Indicator of Data Sufficiency for Feature-based Early Time Series Classification with Applications of Bearing Fault Diagnosis" Processes 8, no. 7: 790. https://doi.org/10.3390/pr8070790
APA StyleAhn, G., Lee, H., Park, J., & Hur, S. (2020). Development of Indicator of Data Sufficiency for Feature-based Early Time Series Classification with Applications of Bearing Fault Diagnosis. Processes, 8(7), 790. https://doi.org/10.3390/pr8070790