
Modified Harmony Search Algorithm for Resource-Constrained Parallel Machine Scheduling Problem with Release Dates and Sequence-Dependent Setup Times



Abstract
:1. Introduction
2. Problem Formulation
2.1. Problem Definition
2.2. Lower Bound
2.2.1. First Lower Bound (LB1)
2.2.2. Second Lower Bound (LB2)
2.2.3. Third Lower Bound (LB3)
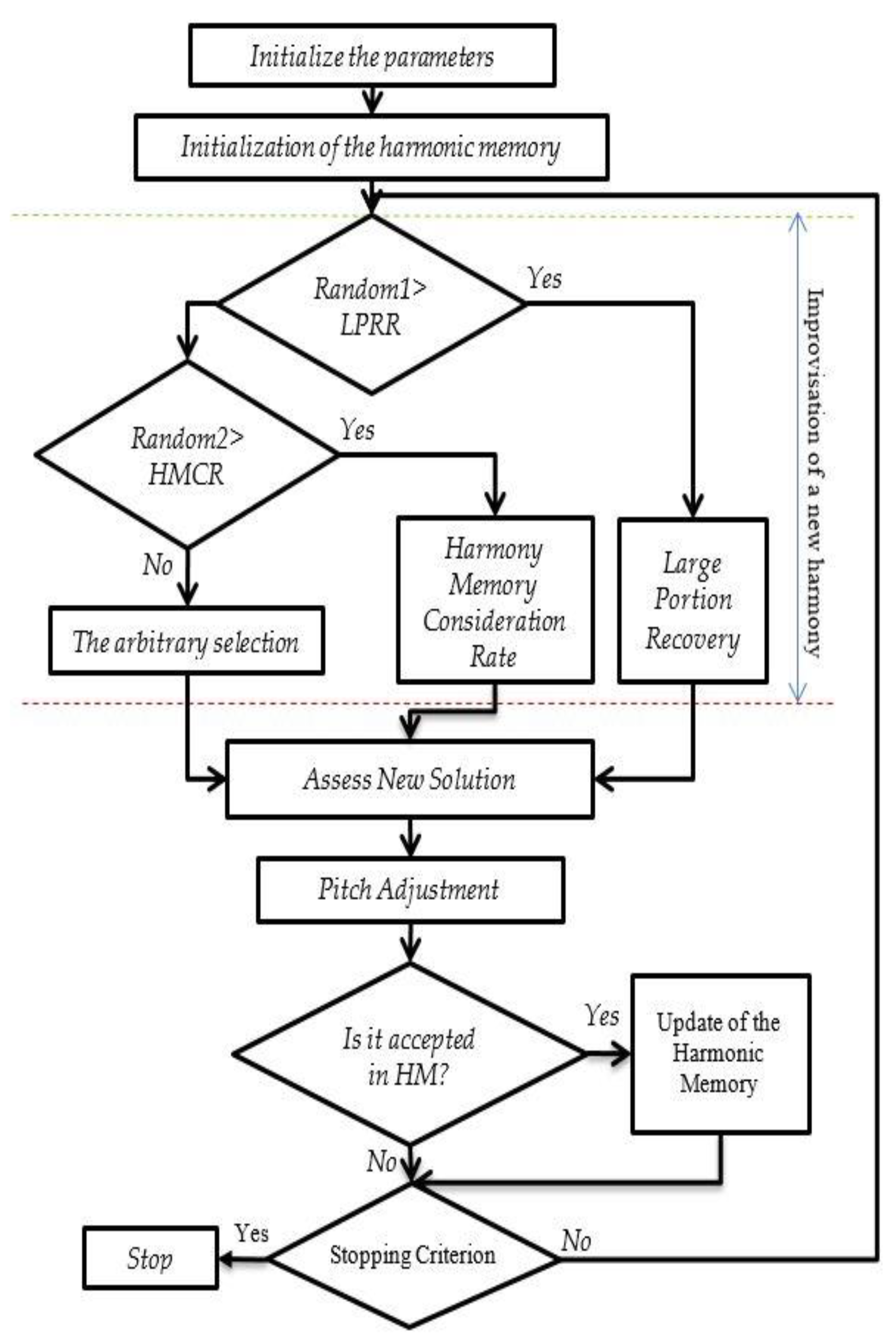
3. Modified Harmony Search
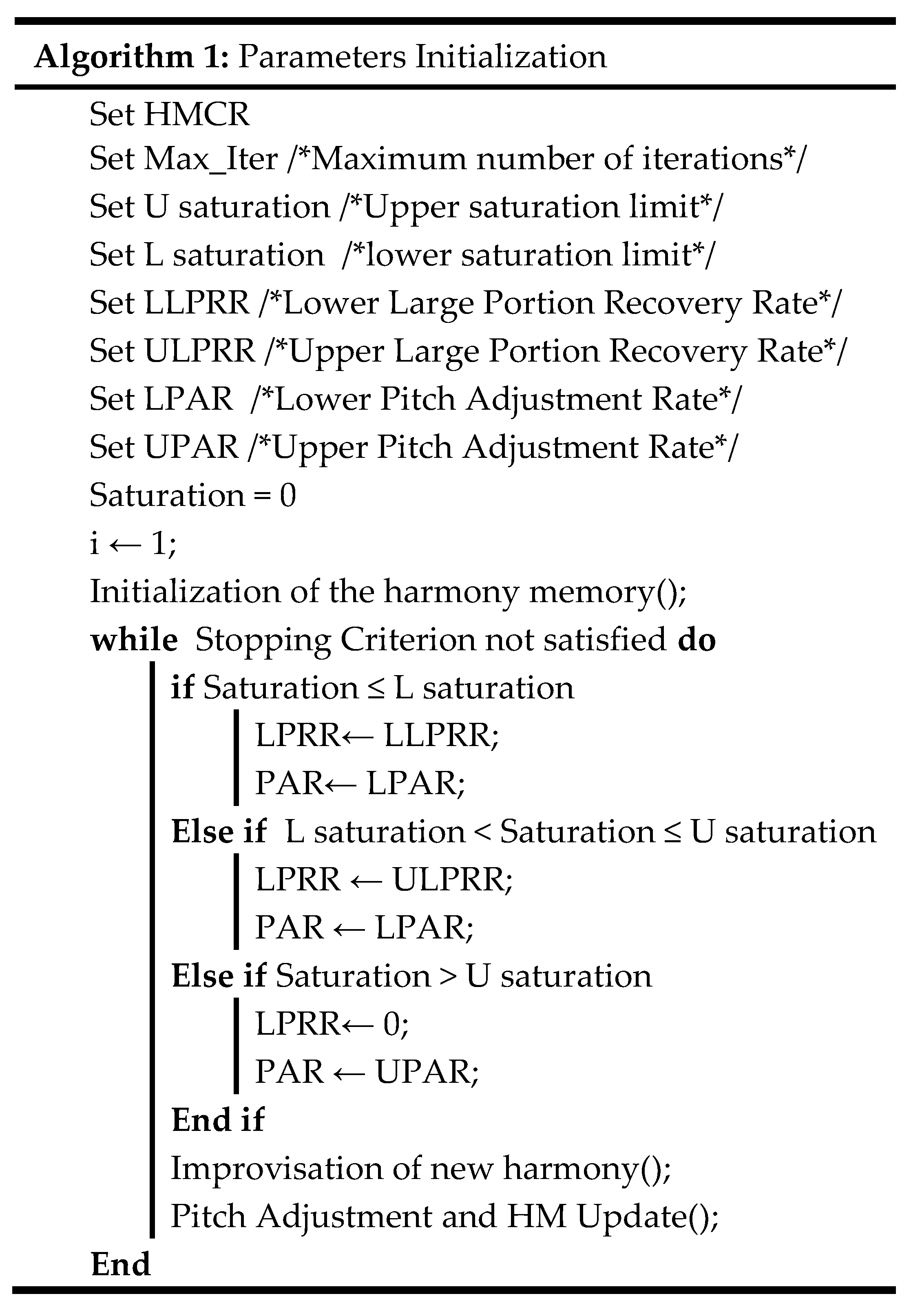
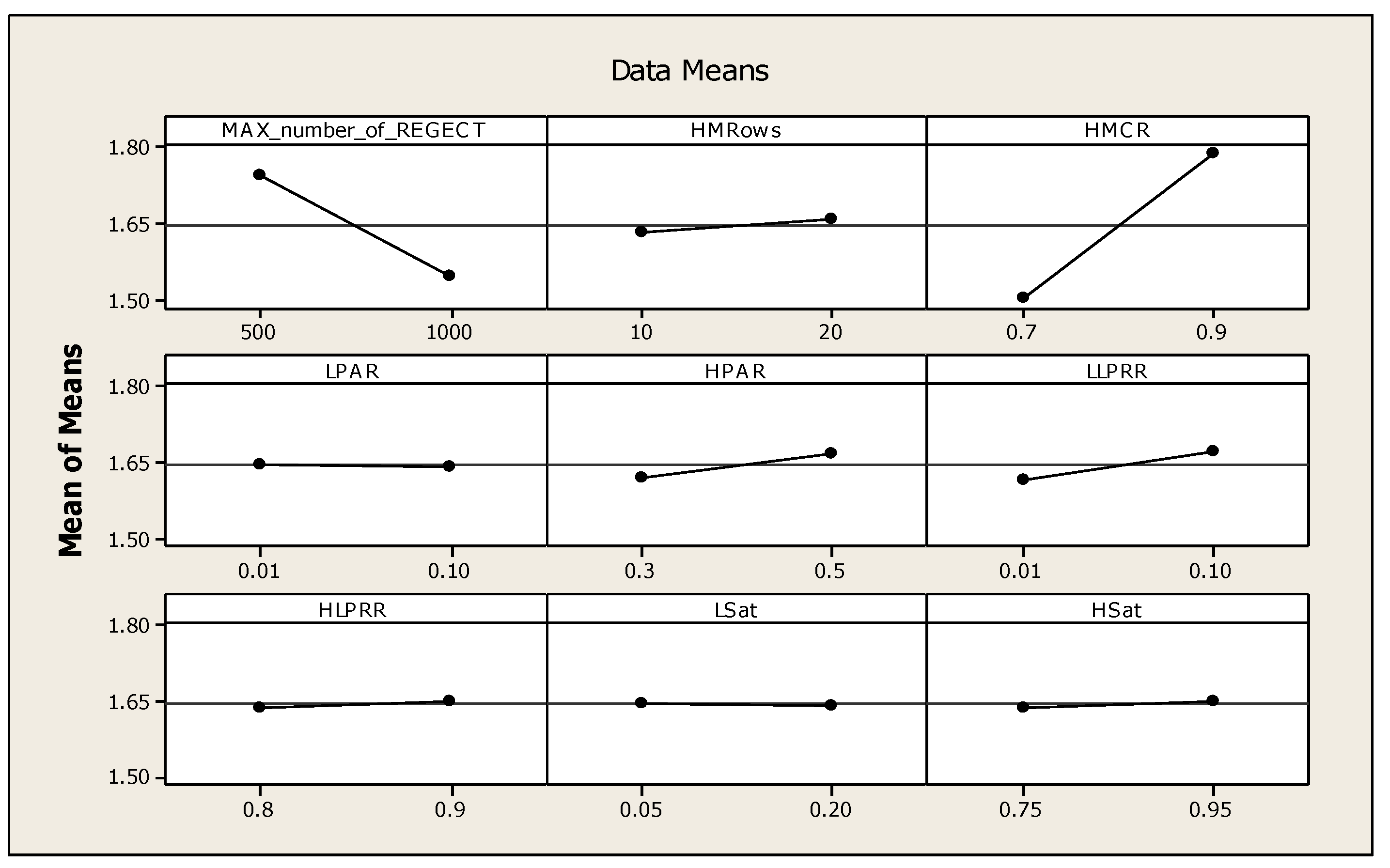
3.1. Initiation of the Parameters
- The harmony memory size (HMS) represents the number of solutions “rows” in the harmony matrix, which represents the actual repertoire of the musician.
- The harmony memory consideration rate (HMCR) represents the selection rate for the new element from the ith column of the harmony matrix HM by considering the goodness of objective function. This parameter imitates the artist’s behavior, where most of them tend to reuse parts of the past work “repertoire.”
- The purpose of pitch adjustment rate (PAR) is to select a random job and change its positions in its neighborhood. Pitch adjustment mimics the slight modification by the artist of melodies for some notes. PAR is used after a new solution is built and can be applied to each job position of the solution. In this case, the position of each job can be modified with PAR probability.
- Large portion recovery (LPR) was introduced by Zammori et al. [35] as a new feature in MHS. This feature tries to mimic the human nature of a musician, who mixes different earlier melodies or reuses their large sequence to create new harmonies.
- Saturation is also a new feature that is presented in MHS by Zammori et al. [35]. The purpose of computing saturation is to help the search process escape being trapped in local optima in which the similarity of HM vectors is tested. When the value of saturation is equal to zero, all the vectors in HM are different. In addition, saturation is computed as follows:
- Stopping criterion for the search is when a specific number of iterations is reached without improvement (No_imp).
3.2. Initialization of Harmony Memory
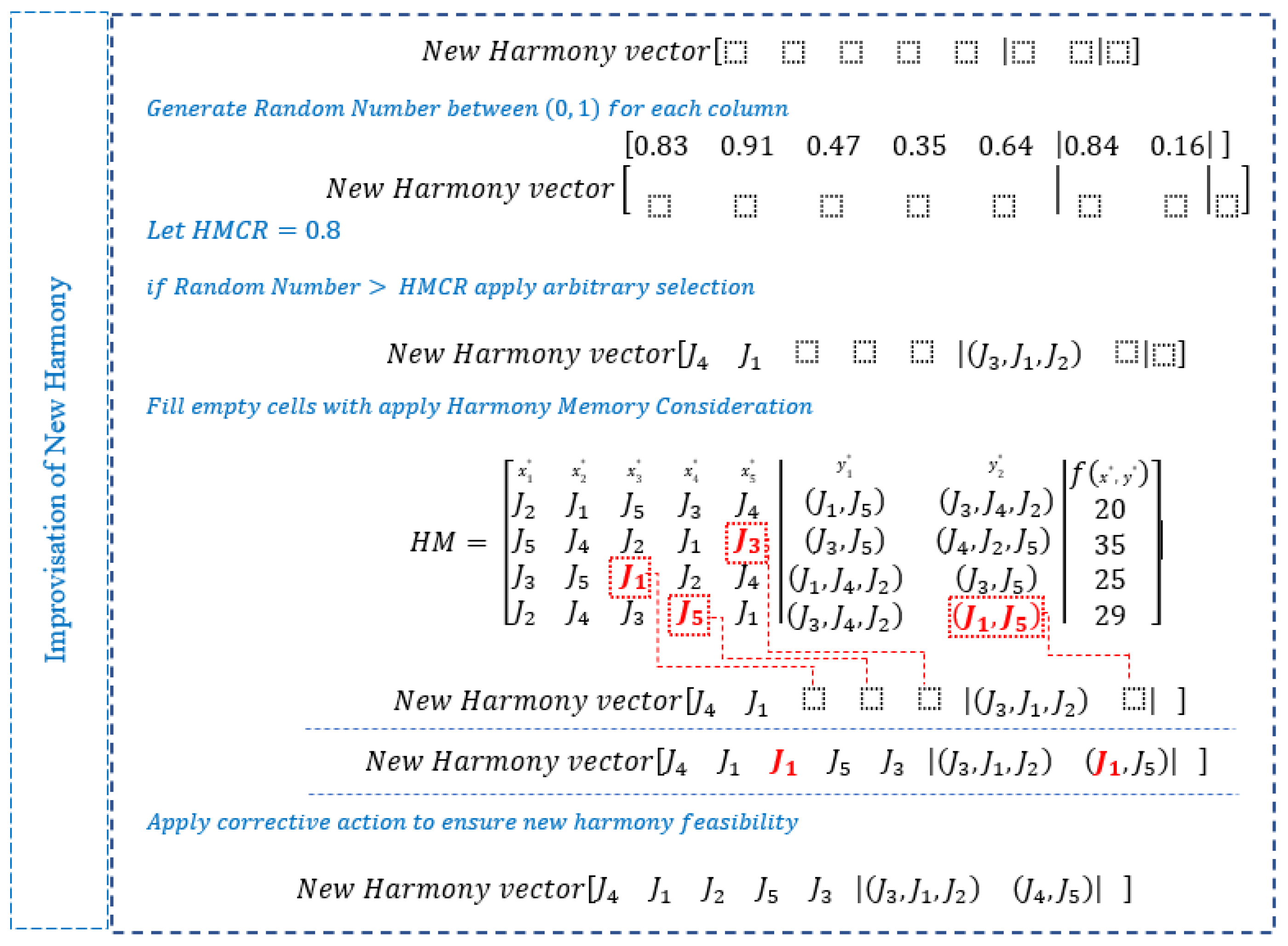
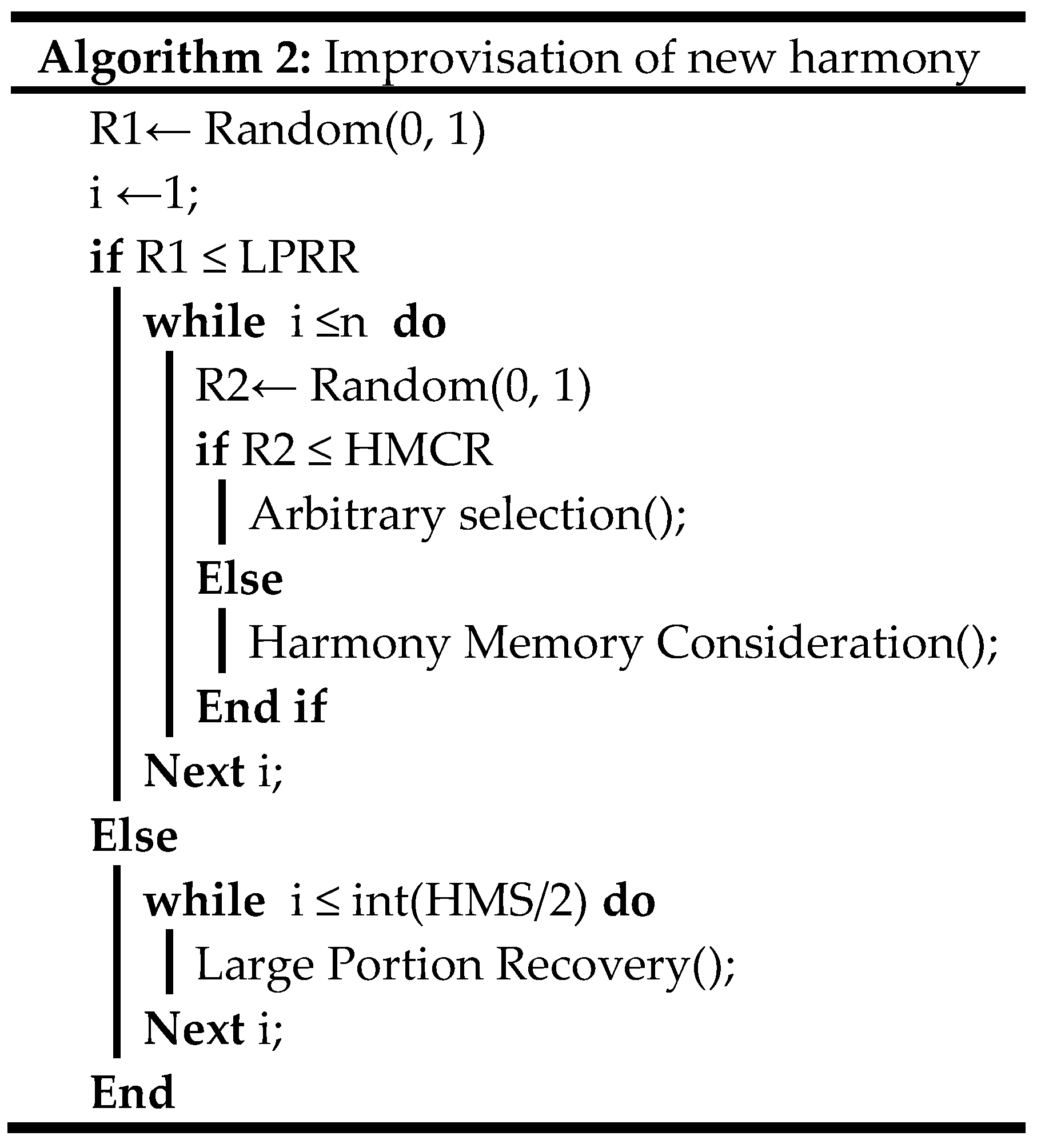
3.3. Improvisation of New Harmony
3.3.1. Arbitrary Selection
3.3.2. Harmony Memory Consideration Rate (HMCR)
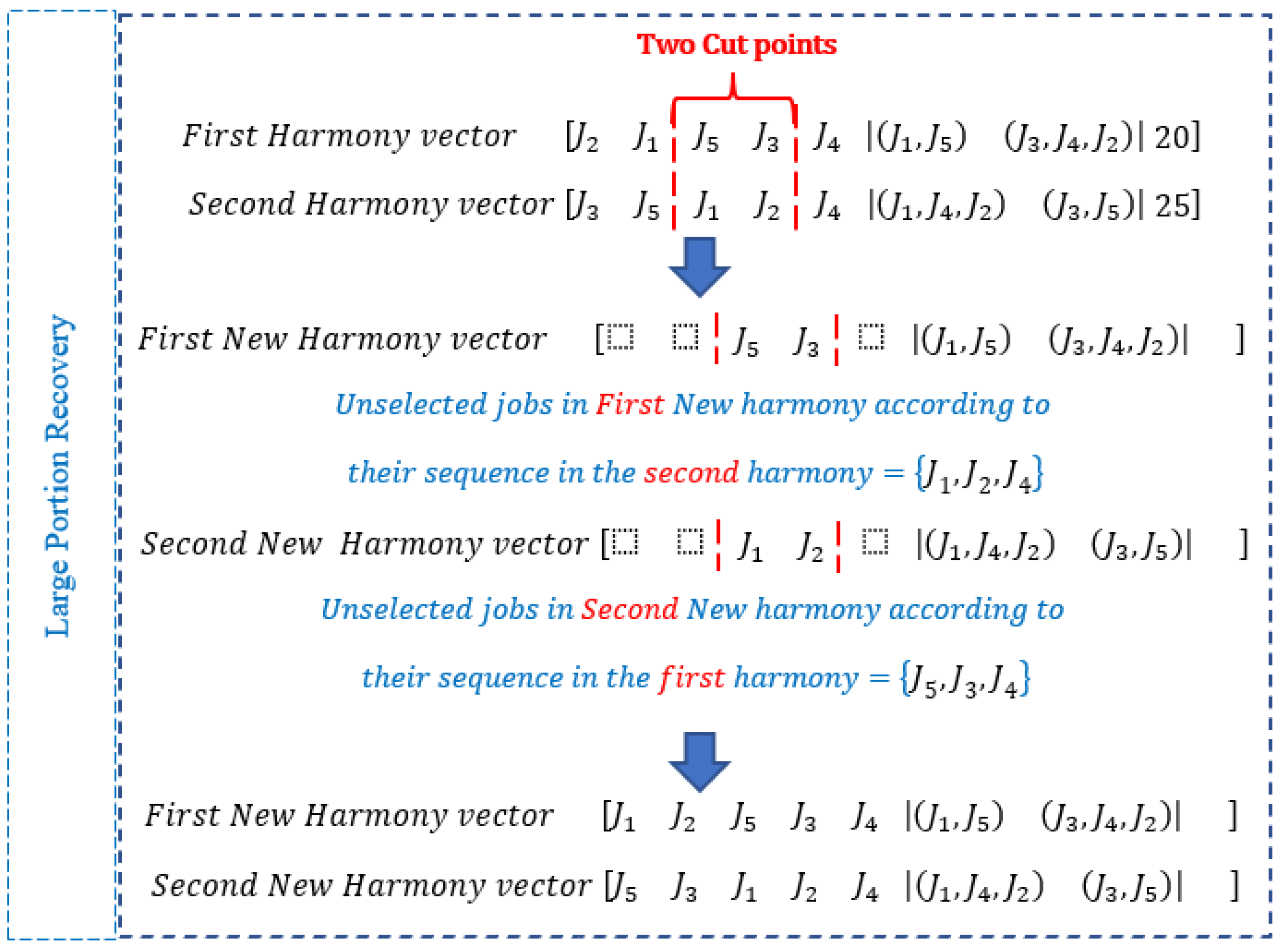
3.3.3. Large Portion Recovery (LPR)
3.4. Pitch Adjustment Rate
3.5. Update Harmony Memory and Stopping Criterion
3.6. Tuning of Parameters for MHS
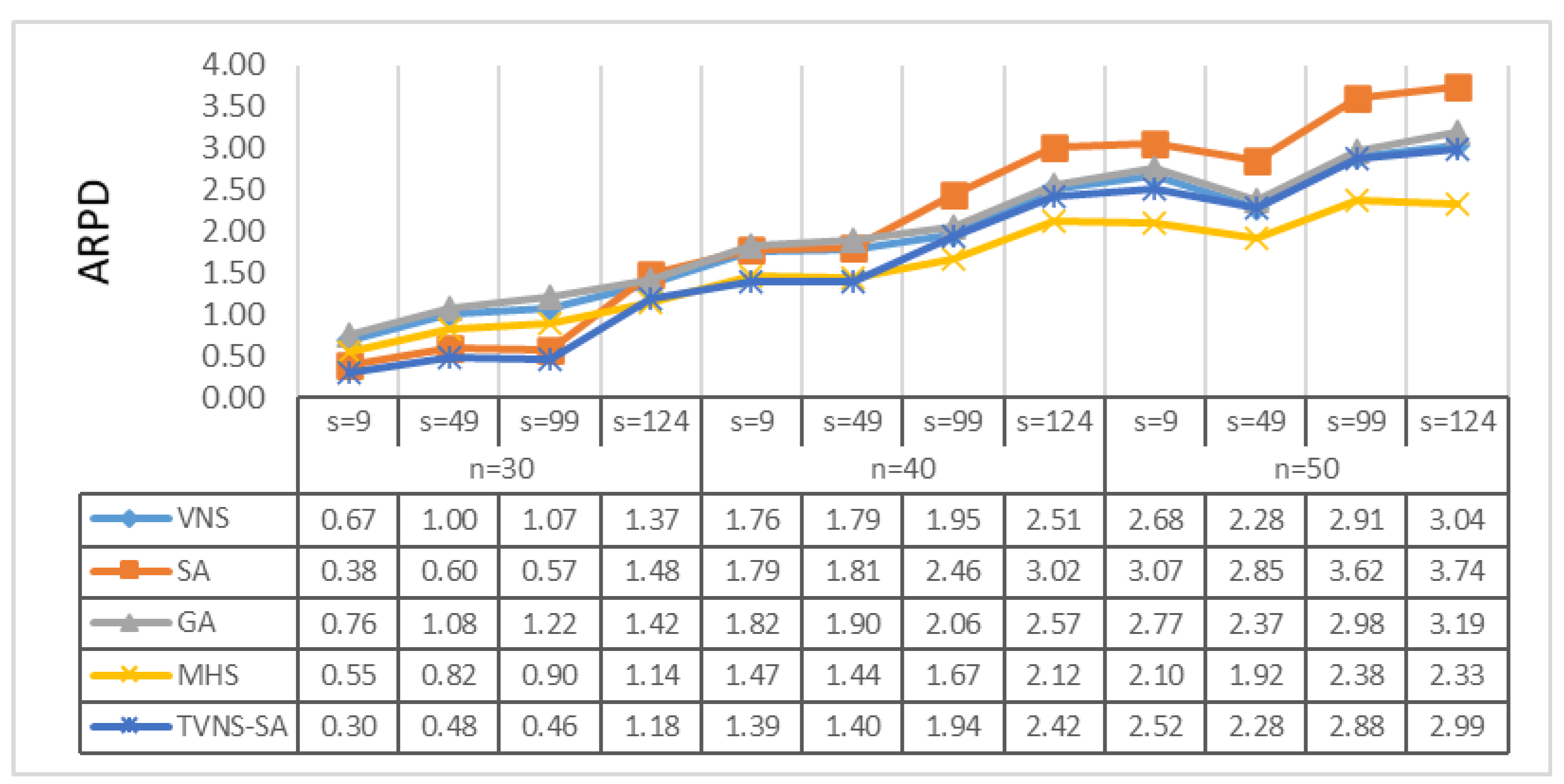
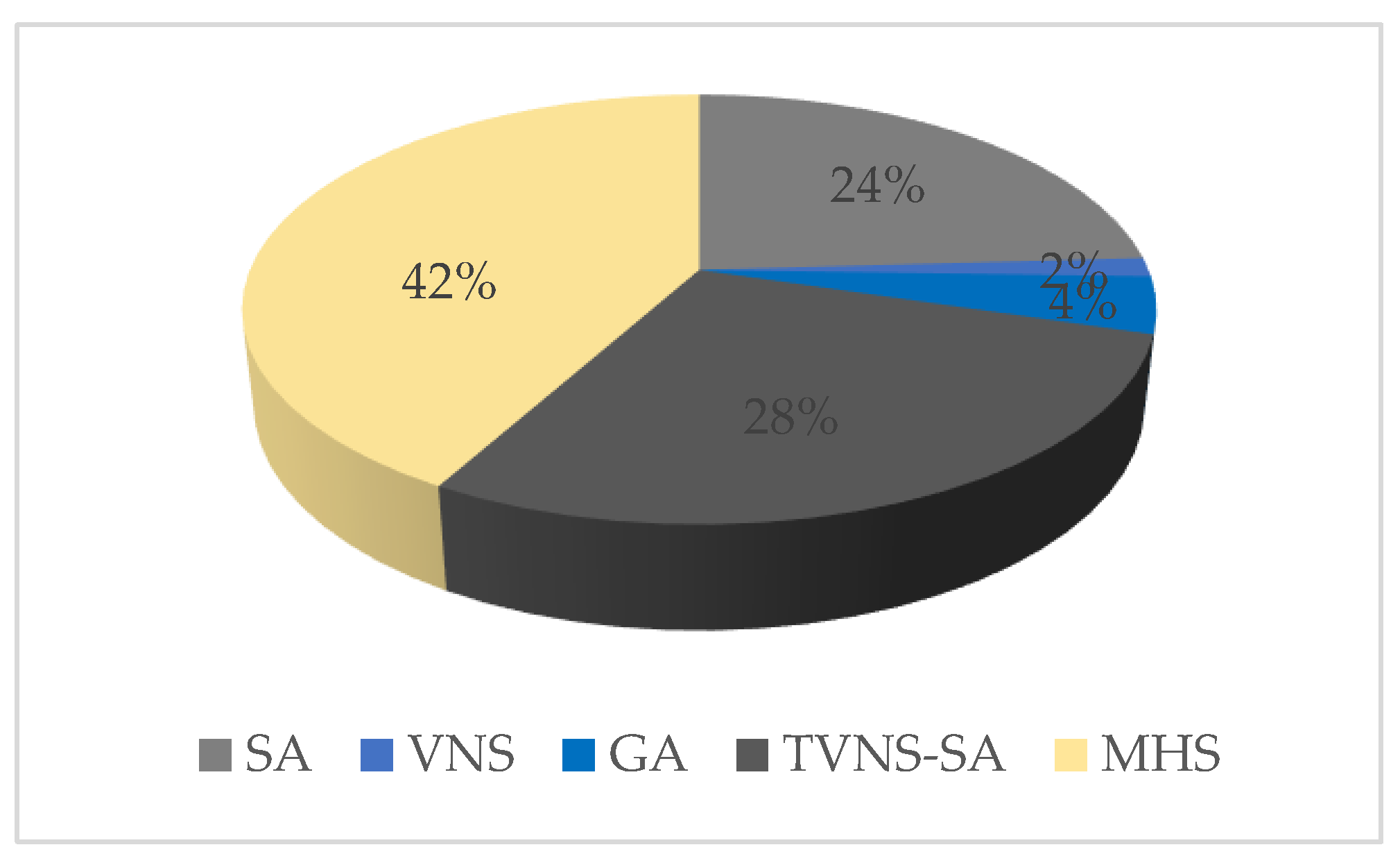
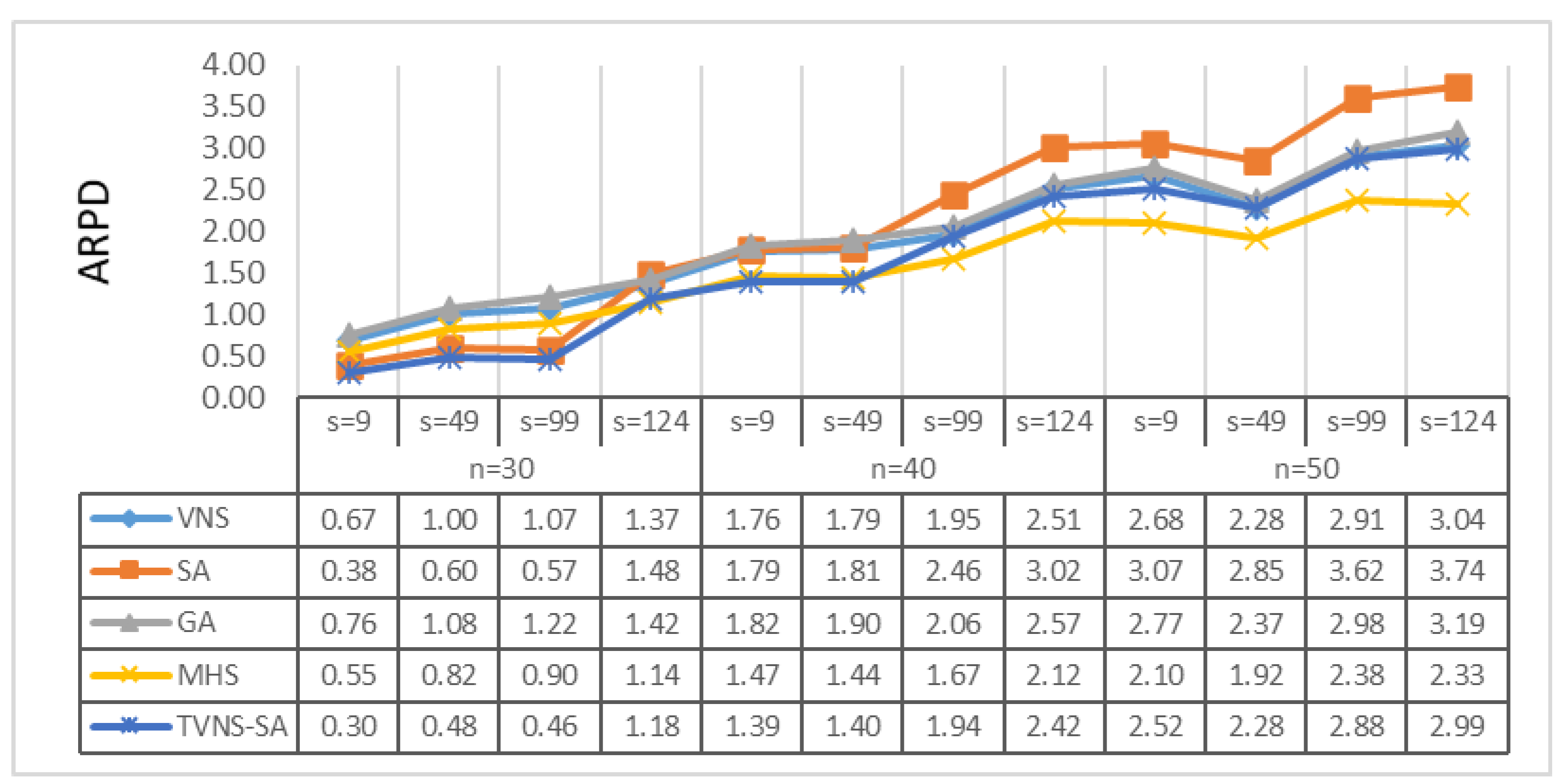
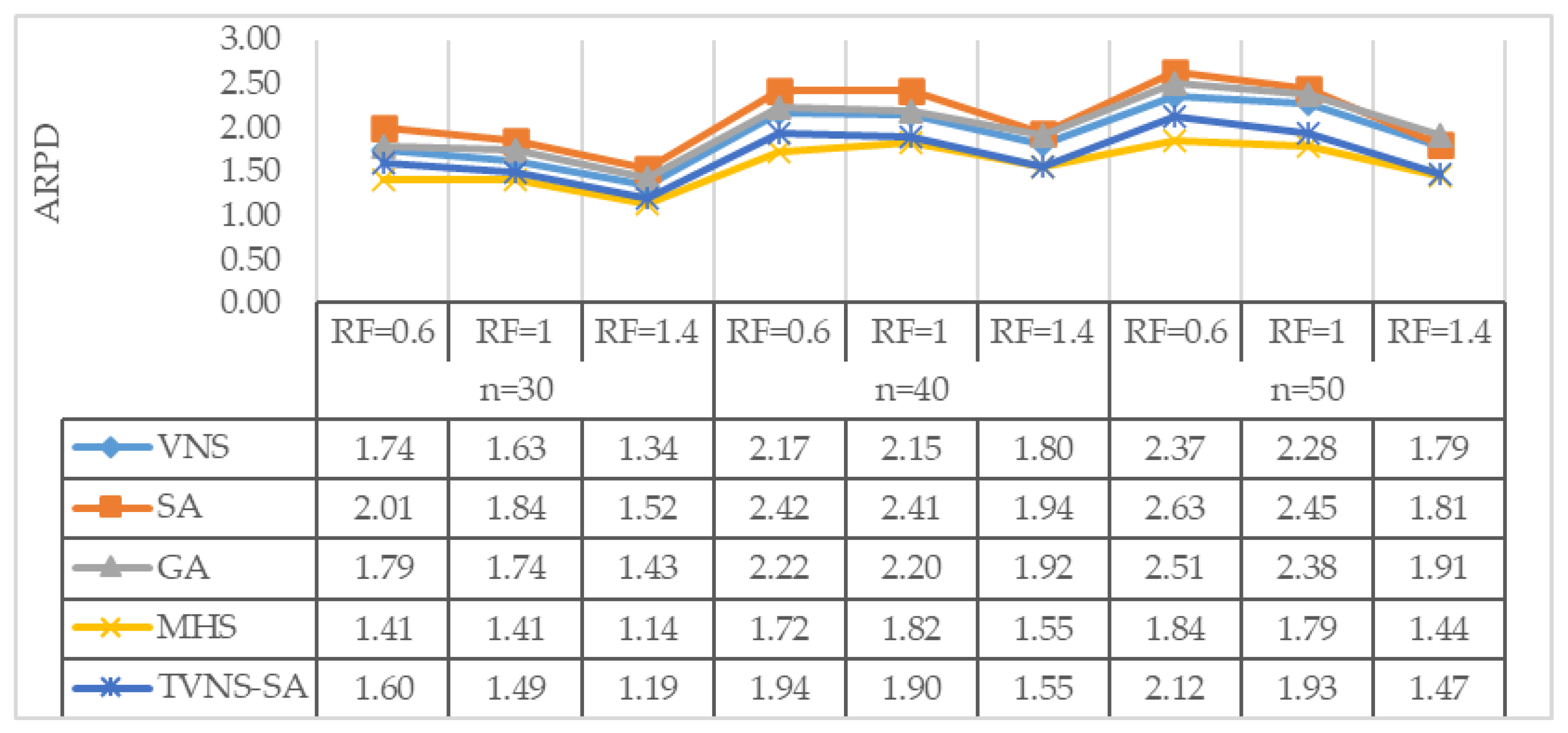
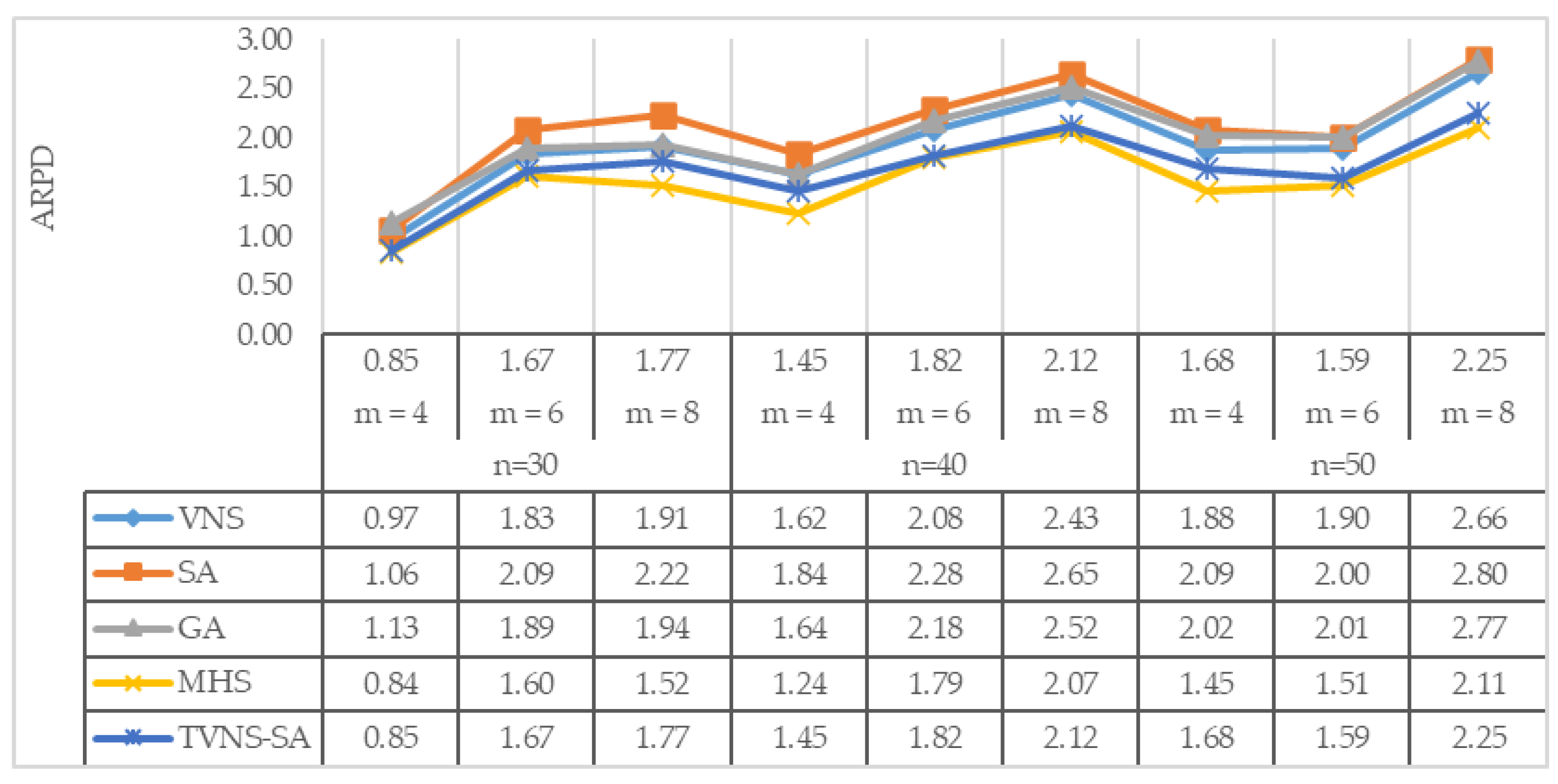
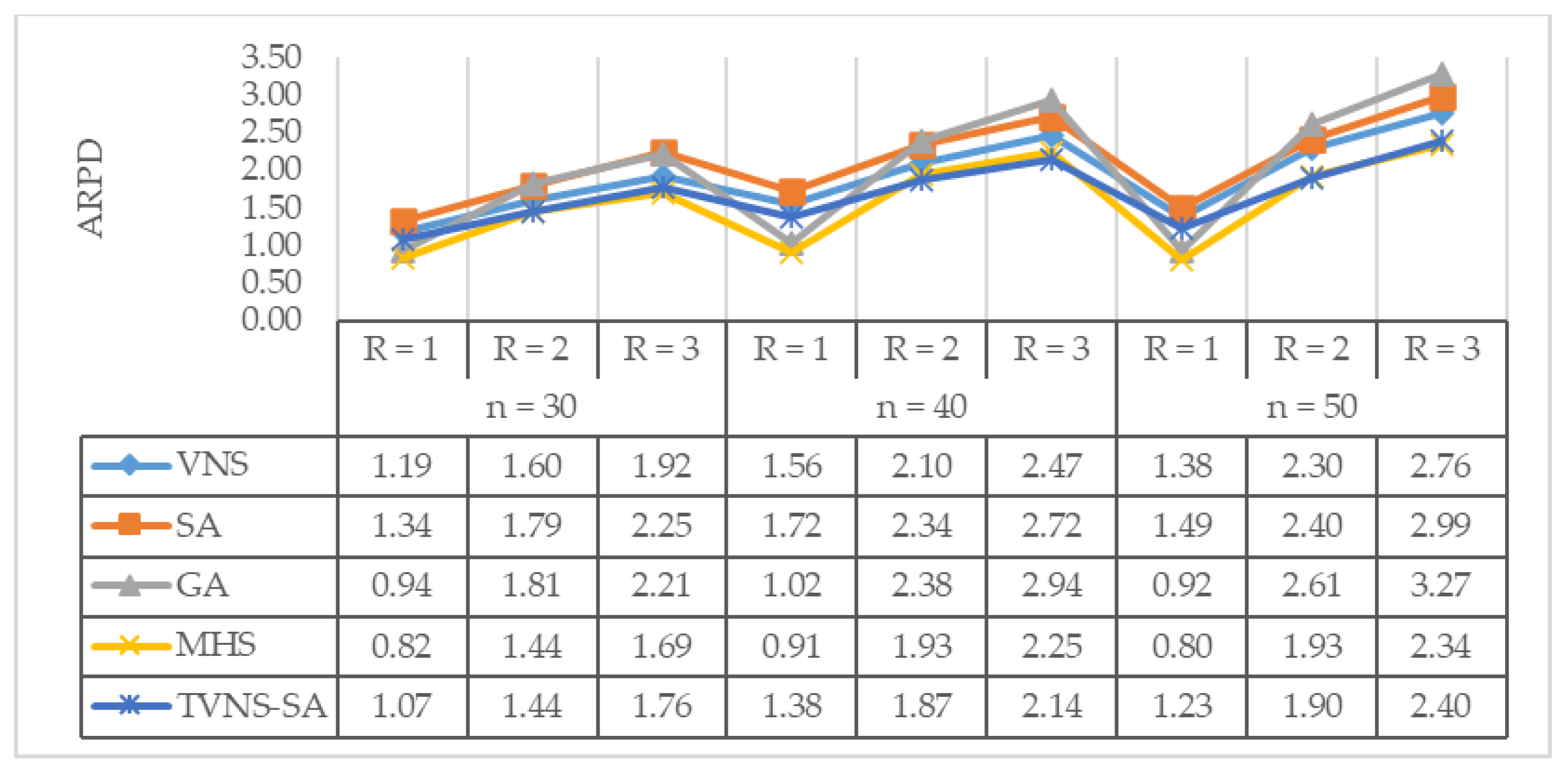
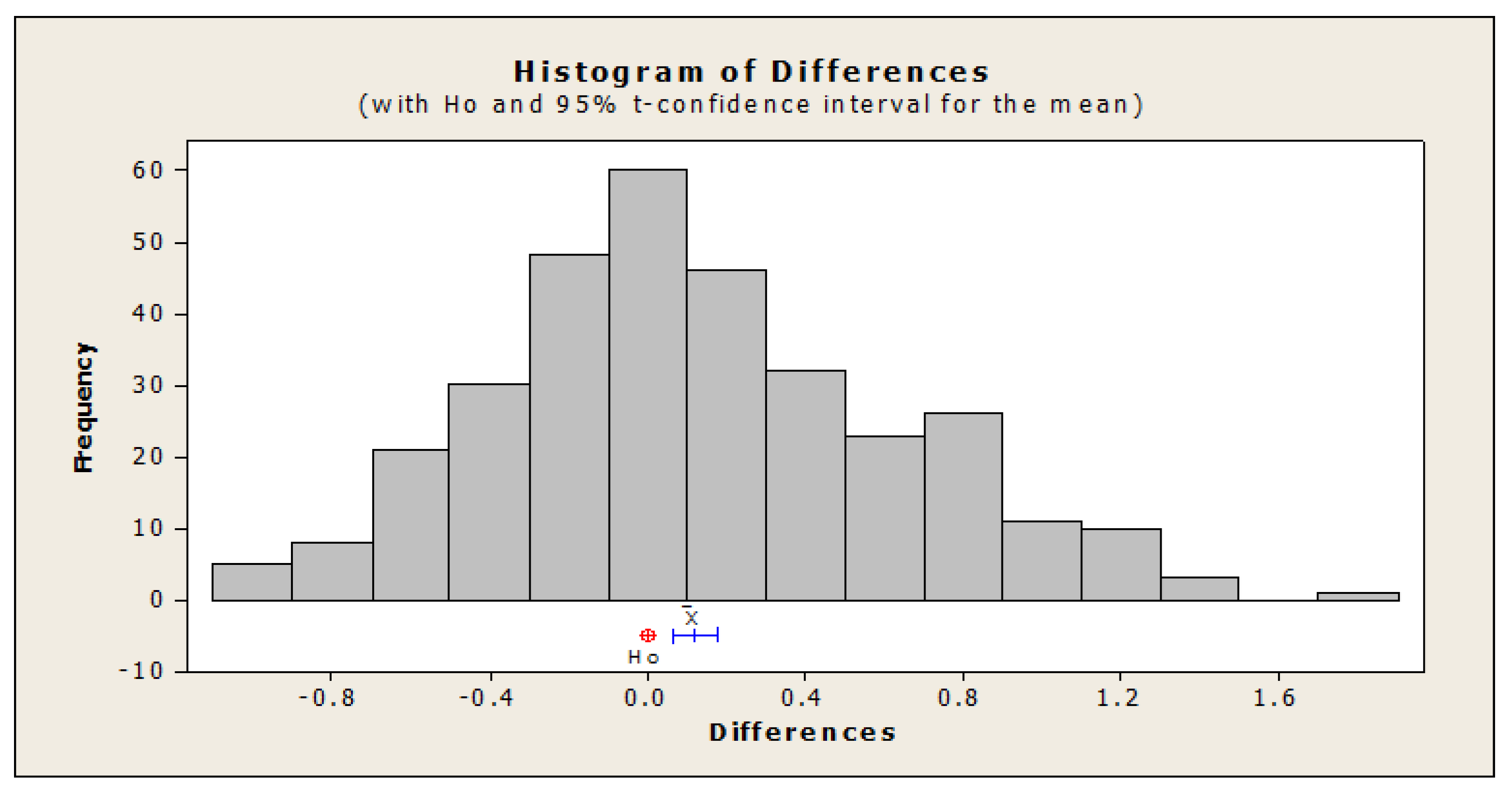
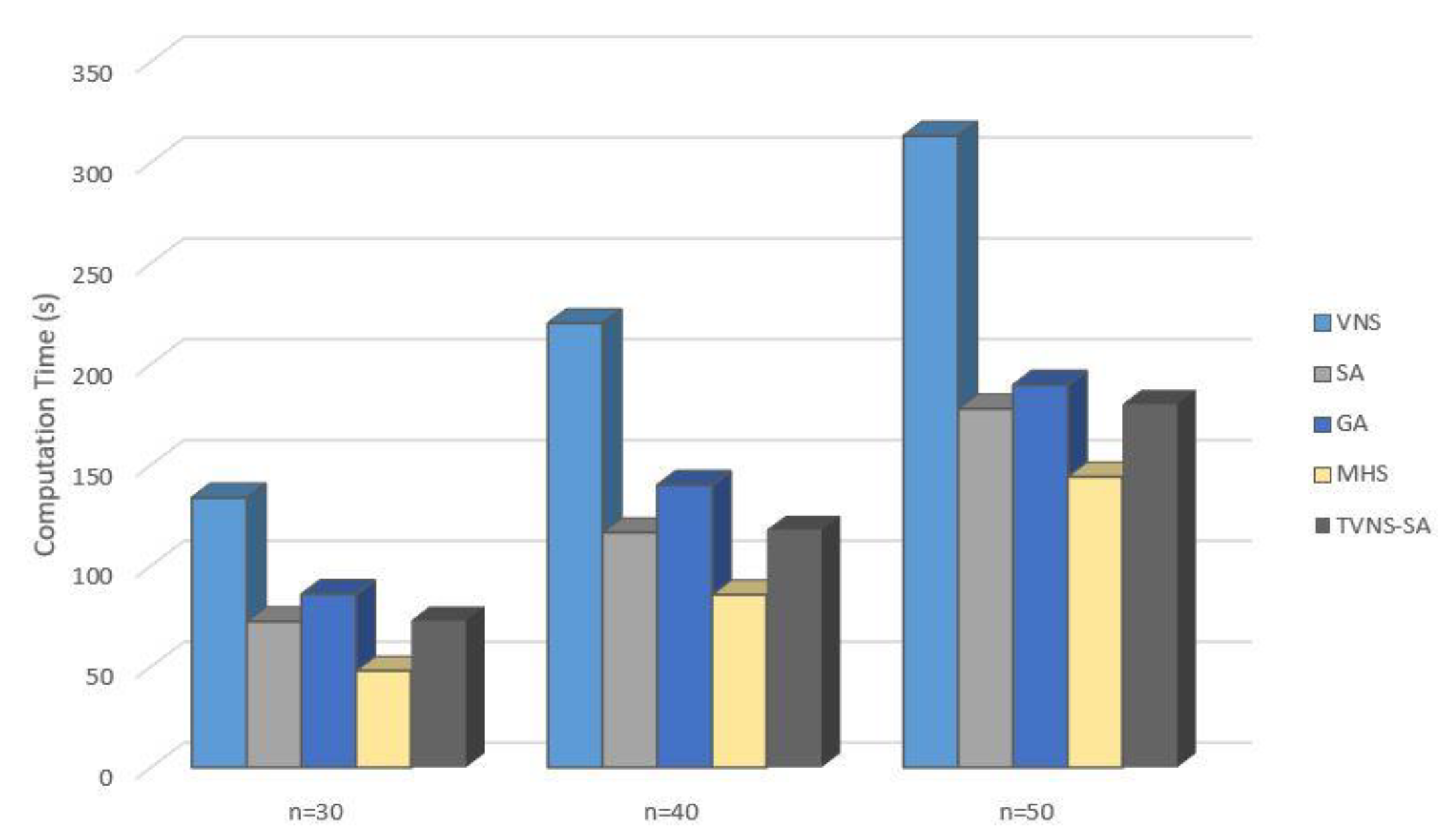
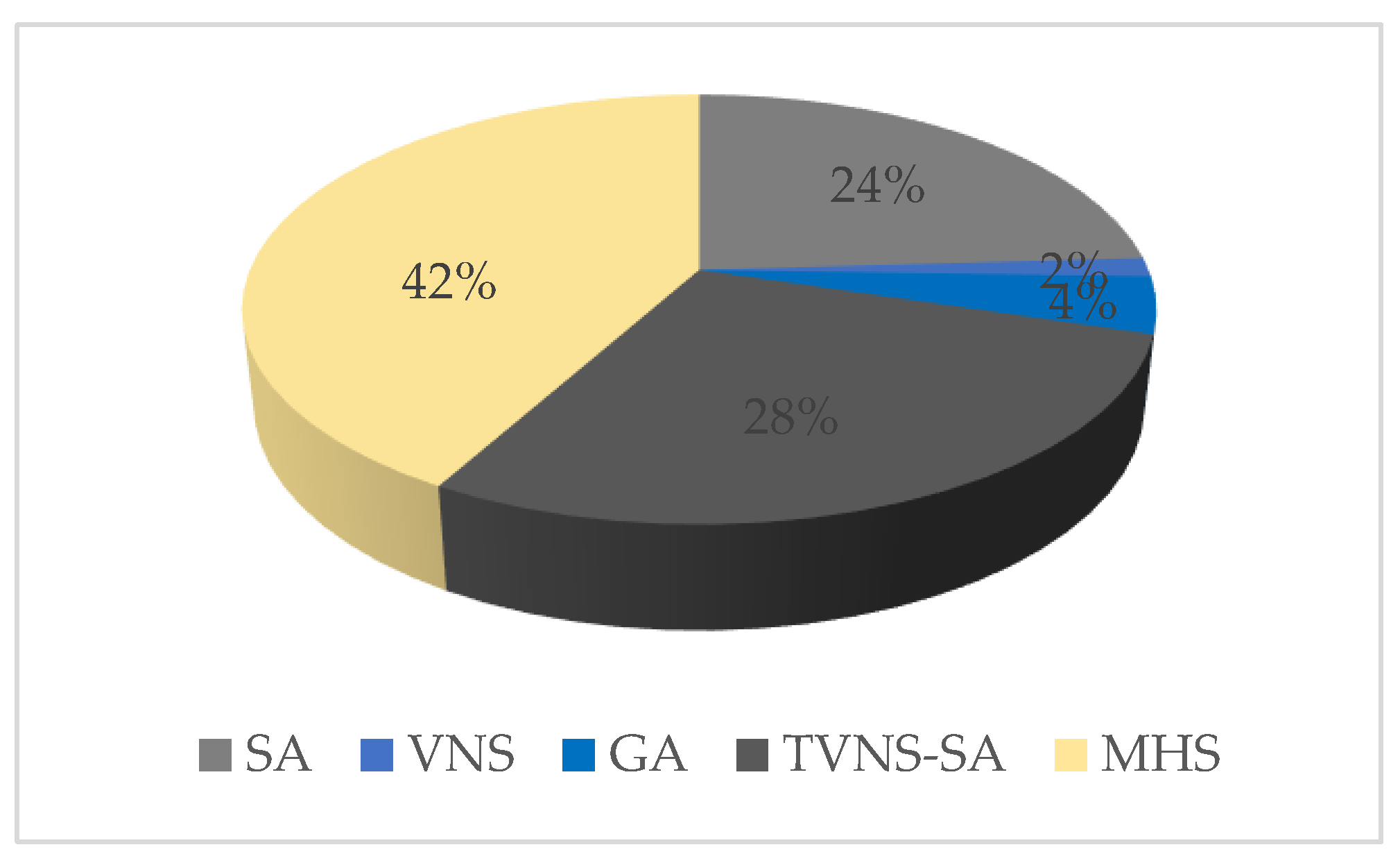
4. Computational Results
- Average relative percentage deviation (ARPD): average gap “RPD” between the obtained result;
- Lower bound for all instances with the same level of generation condition.
- CPU running time: consumed time for an algorithm to obtain the final result
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, P.; Gong, H.; Fan, B.; Rudek, R.; Damodaran, P.; Tang, G. Recent advances in scheduling and its applications. Discret. Dyn. Nat. Soc. 2015, 2015, 1–2. [Google Scholar] [CrossRef]
- Afzalirad, M.; Rezaeian, J.J.E.O. Design of high-performing hybrid meta-heuristics for unrelated parallel machine scheduling with machine eligibility and precedence constraints. Eng. Optim. 2016, 48, 706–726. [Google Scholar] [CrossRef]
- Bitar, A.; Dauzère-Pérès, S.; Yugma, C.; Roussel, R.J.J.O.S. A memetic algorithm to solve an unrelated parallel machine scheduling problem with auxiliary resources in semiconductor manufacturing. J. Sched. 2016, 19, 367–376. [Google Scholar] [CrossRef] [Green Version]
- Allahverdi, A.; Gupta, J.N.D.; Aldowaisan, T. A review of scheduling research involving setup considerations. Omega-Int. J. Manag. S 1999, 27, 219–239. [Google Scholar] [CrossRef]
- Allahverdi, A.; Ng, C.; Cheng, T.E.; Kovalyov, M.Y. A survey of scheduling problems with setup times or costs. Eur. J. Ope.r Res. 2008, 187, 985–1032. [Google Scholar] [CrossRef] [Green Version]
- Allahverdi, A. The third comprehensive survey on scheduling problems with setup times/costs. Eur. J. Oper. Res. 2015, 246, 345–378. [Google Scholar] [CrossRef]
- Lin, S.W.; Ying, K.C. ABC-based manufacturing scheduling for unrelated parallel machines with machine-dependent and job sequence-dependent setup times. Comput. Oper. Res. 2014, 51, 172–181. [Google Scholar] [CrossRef]
- Ezugwu, A.E.; Akutsah, F. An Improved Firefly Algorithm for the Unrelated Parallel Machines Scheduling Problem with Sequence-Dependent Setup Times. IEEE Access 2018, 6, 54459–54478. [Google Scholar] [CrossRef]
- Afzalirad, M.; Rezaeian, J. A realistic variant of bi-objective unrelated parallel machine scheduling problem: NSGA-II and MOACO approaches. Appl. Soft Comput. 2017, 50, 109–123. [Google Scholar] [CrossRef]
- Weng, M.X.; Lu, J.; Ren, H.Y. Unrelated parallel machine scheduling with setup consideration and a total weighted completion time objective. Int. J. Prod. Econ. 2001, 70, 215–226. [Google Scholar] [CrossRef]
- Lin, Y.K.; Hsieh, F.Y. Unrelated parallel machine scheduling with setup times and ready times. Int. J. Prod. Res. 2014, 52, 1200–1214. [Google Scholar] [CrossRef]
- Emami, S.; Moslehi, G.; Sabbagh, M. A Benders decomposition approach for order acceptance and scheduling problem: A robust optimization approach. Comput. Appl. Math. 2017, 36, 1471–1515. [Google Scholar] [CrossRef]
- Bektur, G.; Sarac, T. A mathematical model and heuristic algorithms for an unrelated parallel machine scheduling problem with sequence-dependent setup times, machine eligibility restrictions and a common server. Comput. Oper. Res. 2019, 103, 46–63. [Google Scholar] [CrossRef]
- Obeid, A.; Dauzere-Peres, S.; Yugma, C. Scheduling job families on non-identical parallel machines with time constraints. Ann. Oper. Res. 2014, 213, 221–234. [Google Scholar] [CrossRef]
- Zeidi, J.R.; MohammadHosseini, S. Scheduling unrelated parallel machines with sequence-dependent setup times. Int. J. Adv. Manuf. Technol. 2015, 81, 1487–1496. [Google Scholar] [CrossRef]
- Rabadi, G.; Moraga, R.J.; Al-Salem, A. Heuristics for the unrelated parallel machine scheduling problem with setup times. J. Intell. Manuf. 2006, 17, 85–97. [Google Scholar] [CrossRef]
- Hamzadayi, A.; Yildiz, G. Modeling and solving static m identical parallel machines scheduling problem with a common server and sequence dependent setup times. Comput. Ind. Eng. 2017, 106, 287–298. [Google Scholar] [CrossRef]
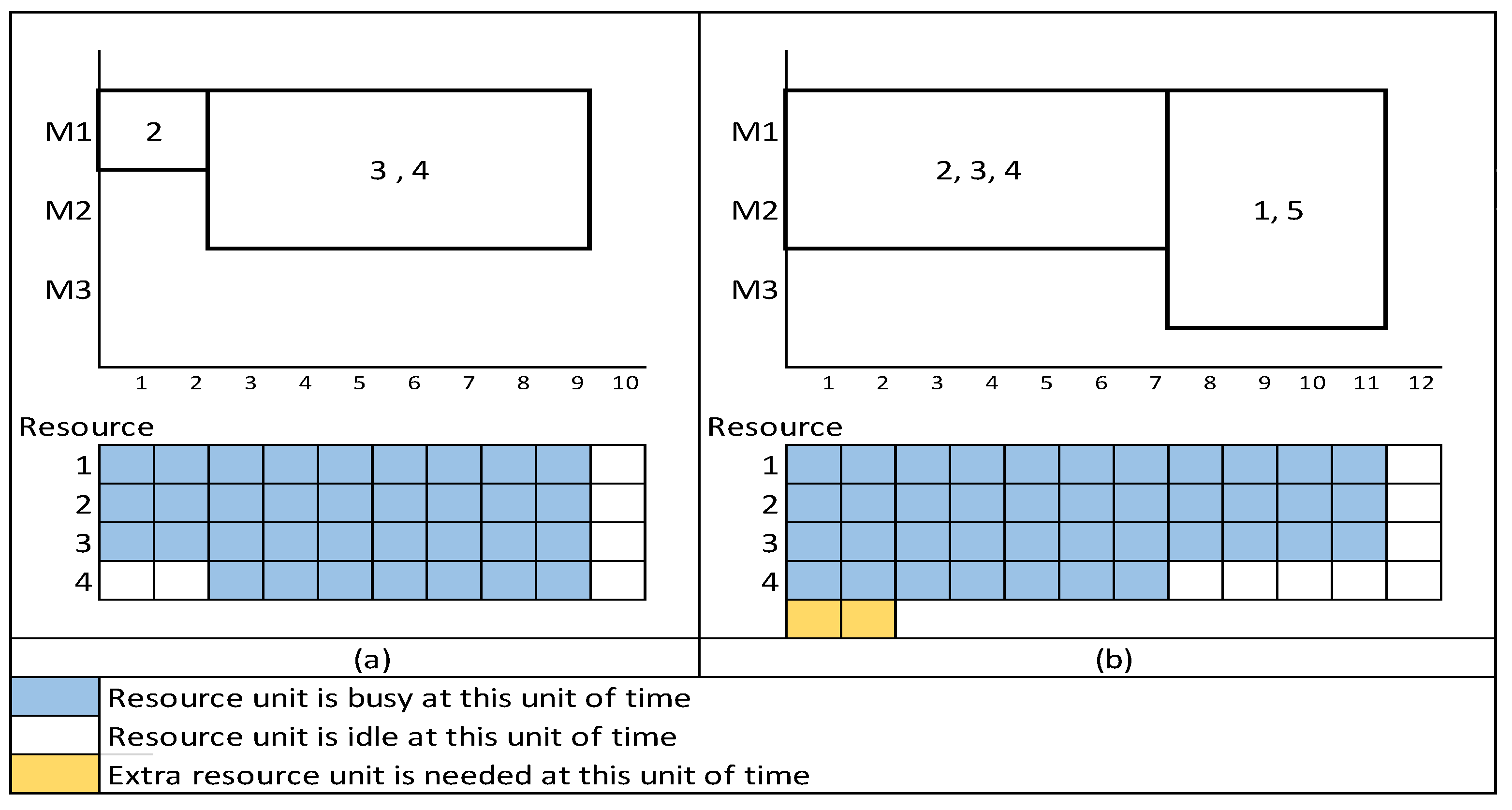
- Edis, E.B.; Oguz, C.; Ozkarahan, I. Parallel machine scheduling with additional resources: Notation, classification, models and solution methods. Eur. J. Oper. Res. 2013, 230, 449–463. [Google Scholar] [CrossRef]
- Gyorgyi, P. A PTAS for a resource scheduling problem with arbitrary number of parallel machines. Oper. Res. Lett. 2017, 45, 604–609. [Google Scholar] [CrossRef] [Green Version]
- Gyorgyi, P.; Kis, T. Approximability of scheduling problems with resource consuming jobs. Ann. Oper. Res. 2015, 235, 319–336. [Google Scholar] [CrossRef] [Green Version]
- Gyorgyi, P.; Kis, T. Approximation schemes for parallel machine scheduling with non-renewable resources. Eur. J. Oper. Res. 2017, 258, 113–123. [Google Scholar] [CrossRef] [Green Version]
- Hebrard, E.; Huguet, M.J.; Jozefowiez, N.; Maillard, A.; Pralet, C.; Verfaillie, G. Approximation of the parallel machine scheduling problem with additional unit resources. Discret. Appl. Math 2016, 215, 126–135. [Google Scholar] [CrossRef] [Green Version]
- Kis, T. Approximability of total weighted completion time with resource consuming jobs. Oper. Res. Lett. 2015, 43, 595–598. [Google Scholar] [CrossRef] [Green Version]
- Zheng, X.L.; Wang, L. A two-stage adaptive fruit fly optimization algorithm for unrelated parallel machine scheduling problem with additional resource constraints. Expert Syst. Appl. 2016, 65, 28–39. [Google Scholar] [CrossRef]
- Afzalirad, M.; Shafipour, M. Design of an efficient genetic algorithm for resource-constrained unrelated parallel machine scheduling problem with machine eligibility restrictions. J. Intell. Manuf. 2018, 29, 423–437. [Google Scholar] [CrossRef]
- Vallada, E.; Villa, F.; Fanjul-Peyro, L. Enriched metaheuristics for the resource constrained unrelated parallel machine scheduling problem. Comput. Oper. Res. 2019, 111, 415–424. [Google Scholar] [CrossRef]
- Li, K.; Yang, S.L.; Leung, J.Y.T.; Cheng, B.Y. Effective meta-heuristics for scheduling on uniform machines with resource-dependent release dates. Int. J. Prod. Res. 2015, 53, 5857–5872. [Google Scholar] [CrossRef]
- Abdeljaoued, M.A.; Saadani, N.E.H.; Bahroun, Z. Heuristic and metaheuristic approaches for parallel machine scheduling under resource constraints. Oper. Res. 2018, 20, 1–24. [Google Scholar] [CrossRef]
- Ozpeynirci, S.; Gokgur, B.; Hnich, B. Parallel machine scheduling with tool loading. Appl. Math. Model. 2016, 40, 5660–5671. [Google Scholar] [CrossRef]
- Furugyan, M.G. Optimal correction of execution intervals for multiprocessor scheduling with additional resource. J. Comput. Syst. Sci. Int. 2015, 54, 268–277. [Google Scholar] [CrossRef]
- Dosa, G.; Kellerer, H.; Tuza, Z. Restricted assignment scheduling with resource constraints. Theor. Comput. Sci. 2019, 760, 72–87. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.C.; Wang, M.J.; Lin, S.C. Selection of cutting conditions for power constrained parallel machine scheduling. Robot. Comput.-Integr. Manuf. 2017, 43, 105–110. [Google Scholar] [CrossRef]
- Labbia, W.; Boudhara, M.; Oulamara, A. Scheduling two identical parallel machines with preparation constraints. Int. J. Prod. Res. 2017, 55, 1531–1548. [Google Scholar] [CrossRef]
- Li, J.Q.; Duan, P.Y.; Sang, H.Y.; Wang, S.; Liu, Z.M.; Duan, P. An Efficient Optimization Algorithm for Resource-Constrained Steelmaking Scheduling Problems. IEEE Access 2018, 6, 33883–33894. [Google Scholar] [CrossRef]
- Zammori, F.; Braglia, M.; Castellano, D. Harmony search algorithm for single-machine scheduling problem with planned maintenance. Comput. Ind. Eng. 2014, 76, 333–346. [Google Scholar] [CrossRef]
- Afzalirad, M.; Rezaeian, J. Resource-constrained unrelated parallel machine scheduling problem with sequence dependent setup times, precedence constraints and machine eligibility restrictions. Comput. Ind. Eng. 2016, 98, 40–52. [Google Scholar] [CrossRef]
- Qamhan, M.A.; Qamhan, A.A.; Al-Harkan, I.M.; Alotaibi, Y.A. Mathematical Modeling and Discrete Firefly Algorithm to Optimize Scheduling Problem with Release Date, Sequence-Dependent Setup Time, and Periodic Maintenance. Math. Probl. Eng. 2019, 2019. [Google Scholar] [CrossRef] [Green Version]
- Geem, Z.W.; Kim, J.H.; Loganathan, G.V. A new heuristic optimization algorithm: Harmony search. Simulation 2001, 76, 60–68. [Google Scholar] [CrossRef]
- Vallada, E.; Ruiz, R. A genetic algorithm for the unrelated parallel machine scheduling problem with sequence dependent setup times. Eur. J. Oper. Res. 2011, 211, 612–622. [Google Scholar] [CrossRef] [Green Version]
- Velez-Gallego, M.C.; Maya, J.; Torres, J.R.M. A beam search heuristic for scheduling a single machine with release dates and sequence dependent setup times to minimize the makespan. Comput. Oper. Res. 2016, 73, 132–140. [Google Scholar] [CrossRef]
- Al-Harkan, I.M.; Qamhan, A.A. Optimize Unrelated Parallel Machines Scheduling Problems With Multiple Limited Additional Resources, Sequence-Dependent Setup Times and Release Date Constraints. IEEE Access 2019, 7, 171533–171547. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Job | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 3 | 15 | 1 | 13 | 3 | ||
| 8 | 6 | 5 | 7 | 7 | ||
| 5 | 2 | 10 | 7 | 8 | ||
| 4 | 4 | 7 | 8 | 7 | ||
| 1 | 3 | 2 | 2 | 1 |
| Setup Times Matrix on Machine 1 | Setup Times Matrix on Machine 2 | Setup Times Matrix on Machine 3 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Job | 1 | 2 | 3 | 4 | 5 | Job | 1 | 2 | 3 | 4 | 5 | Job | 1 | 2 | 3 | 4 | 5 |
| 0 | 4 | 3 | 1 | 4 | 5 | 0 | 5 | 1 | 2 | 5 | 2 | 0 | 5 | 3 | 4 | 3 | 4 |
| 1 | - | 1 | 5 | 2 | 3 | 1 | - | 5 | 1 | 3 | 5 | 1 | - | 2 | 4 | 2 | 4 |
| 2 | 4 | - | 4 | 3 | 3 | 2 | 3 | - | 5 | 5 | 2 | 2 | 4 | - | 2 | 3 | 3 |
| 3 | 4 | 5 | - | 4 | 2 | 3 | 5 | 3 | - | 2 | 4 | 3 | 3 | 1 | - | 2 | 2 |
| 4 | 3 | 3 | 2 | - | 3 | 4 | 3 | 1 | 5 | - | 3 | 4 | 3 | 3 | 5 | - | 3 |
| 5 | 3 | 4 | 1 | 2 | - | 5 | 5 | 2 | 1 | 3 | - | 5 | 5 | 3 | 5 | 2 | - |
| Job | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 3 | 15 | 1 | 13 | 3 | ||
| 5 | 2 | 5 | 7 | 7 | ||
| 3 | 1 | 1 | 2 | 2 | ||
| 1 | 3 | 2 | 2 | 1 |
| Musical Process | Optimization Process |
|---|---|
| Musical harmony | Feasible solution |
| Musical improvisation | Iteration |
| Musical instrument | Decision variable |
| Tone | Value of a decision variable |
| Quality of harmony | Objective function |
| Parameters | Level | |
|---|---|---|
| Low | High | |
| MAX_number_of_REGECT | 500 | 1000 |
| HMRows | 10 | 20 |
| HMCR | 0.7 | 0.9 |
| LPAR | 0.01 | 0.1 |
| HPAR | 0.3 | 0.5 |
| LLPRR | 0.01 | 0.1 |
| HLPRR | 0.8 | 0.9 |
| LSat | 0.05 | 0.2 |
| HSat | 0.75 | 0.95 |
| Group | Parameter Range | Reference Paper |
|---|---|---|
| Processing times | U(1, 99) | Vallada and Ruiz [39] |
| Setup times | U(1, 9), U(1, 49), U(1, 99), and U(1, 124) | |
| Release dates | U (1, L) Where L is computed as L = n*ρ*Rf/m n = number of jobs and m = number of machines ρ = expected processing time Release range factor (Rf) = { 0.6, 1.0, 1.4} | Velez-Gallego et al. [40] |
| The available amount of each resource (AR) | U(1, 5) | Afzalirad and Rezaeian [36] |
| Resource requirements | U(0, AR) |
| Algorithm | Parameter | Considered Values | Selected Values |
|---|---|---|---|
| SA | Initial temperature | 100–1000 | 100 |
| Cooling rate | 0.009–0.09 | 0.09 | |
| Stopping condition | Number of nonimprovements (150–300) | 300 | |
| VNS | Number of neighborhoods | 10–20 | 10 |
| Number of nonimprovements in the local search | 150–300 | 300 | |
| HTVN-SA | Initial temperature | 100–1000 | 100 |
| Cooling rate | 0.009–0.09 | 0.09 | |
| Number of neighborhoods | 10–20 | 10 | |
| Number of nonimprovements in the local search | 150–300 | 300 | |
| GA | Population size | 40, 50, 60 | 50 |
| Crossover rate (Pc) | 0.6, 0.75, 0.9 | 0.75 | |
| Mutation rate (Pm) | 0.05, 0.15, 0.25 | 0.25 | |
| Stopping condition | Maximum iterations (120, 170, 220) | 220 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-harkan, I.M.; Qamhan, A.A.; Badwelan, A.; Alsamhan, A.; Hidri, L. Modified Harmony Search Algorithm for Resource-Constrained Parallel Machine Scheduling Problem with Release Dates and Sequence-Dependent Setup Times. Processes 2021, 9, 654. https://doi.org/10.3390/pr9040654
Al-harkan IM, Qamhan AA, Badwelan A, Alsamhan A, Hidri L. Modified Harmony Search Algorithm for Resource-Constrained Parallel Machine Scheduling Problem with Release Dates and Sequence-Dependent Setup Times. Processes. 2021; 9(4):654. https://doi.org/10.3390/pr9040654
Chicago/Turabian StyleAl-harkan, Ibrahim M., Ammar A. Qamhan, Ahmed Badwelan, Ali Alsamhan, and Lotfi Hidri. 2021. "Modified Harmony Search Algorithm for Resource-Constrained Parallel Machine Scheduling Problem with Release Dates and Sequence-Dependent Setup Times" Processes 9, no. 4: 654. https://doi.org/10.3390/pr9040654
APA StyleAl-harkan, I. M., Qamhan, A. A., Badwelan, A., Alsamhan, A., & Hidri, L. (2021). Modified Harmony Search Algorithm for Resource-Constrained Parallel Machine Scheduling Problem with Release Dates and Sequence-Dependent Setup Times. Processes, 9(4), 654. https://doi.org/10.3390/pr9040654