
A Novel Ensemble Model on Defects Identification in Aero-Engine Blade



Abstract
1. Introduction
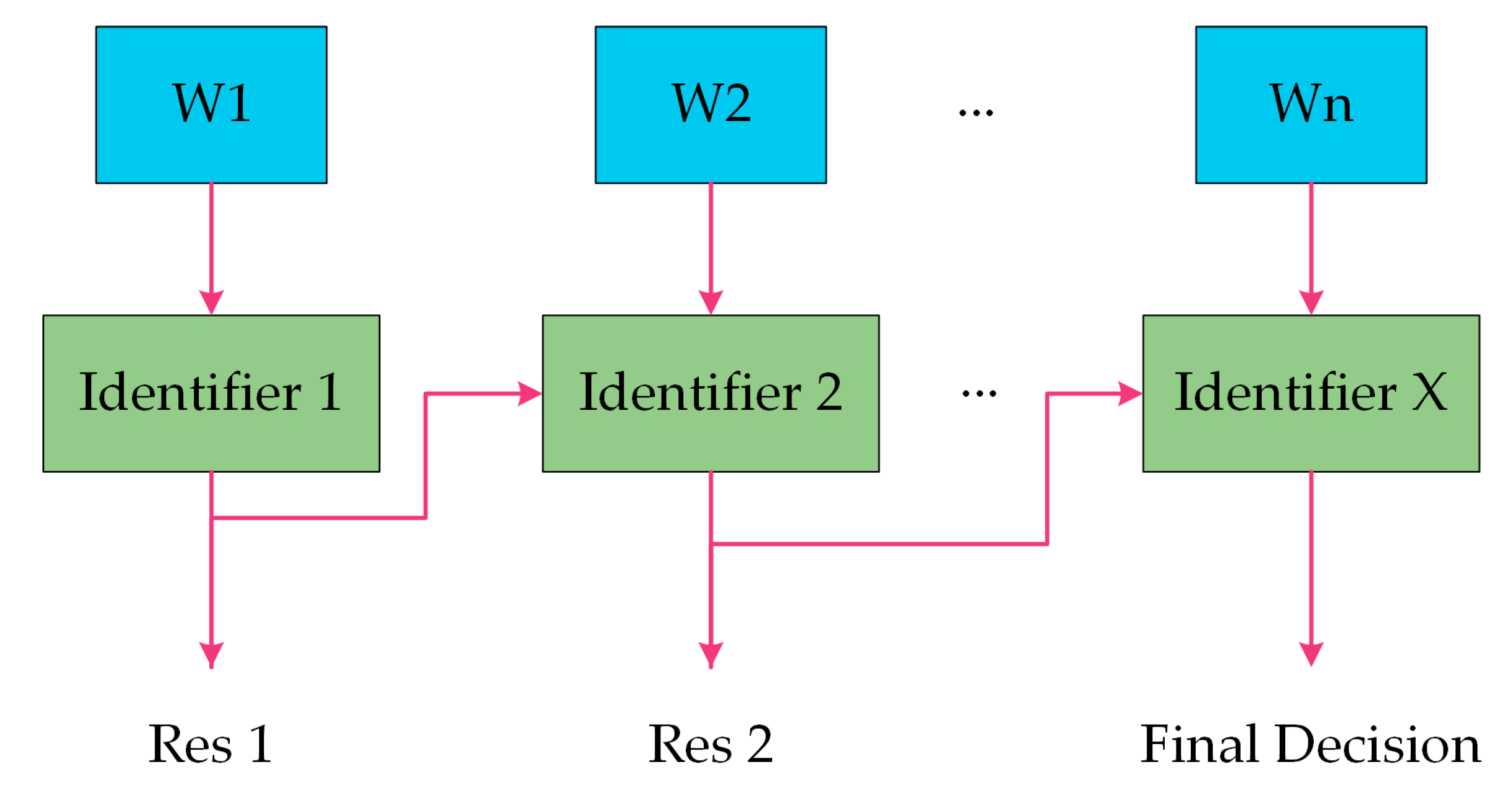
2. Ensemble Learning
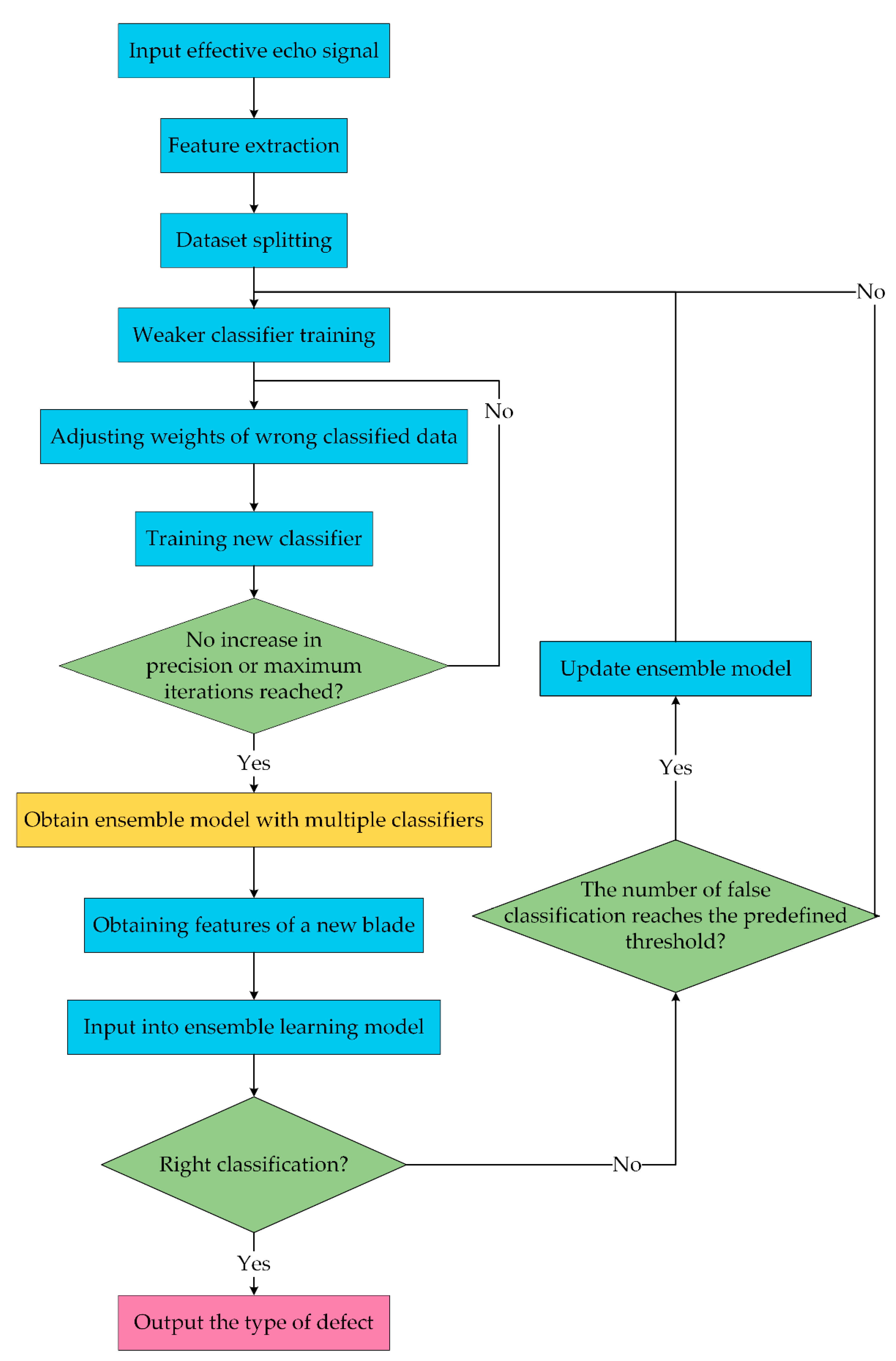
3. Proposed Processing Chain
3.1. Denoising Overview
3.2. The Details of CEEMD Algorithm
3.3. Determination of Signal Domain and Noise Domain
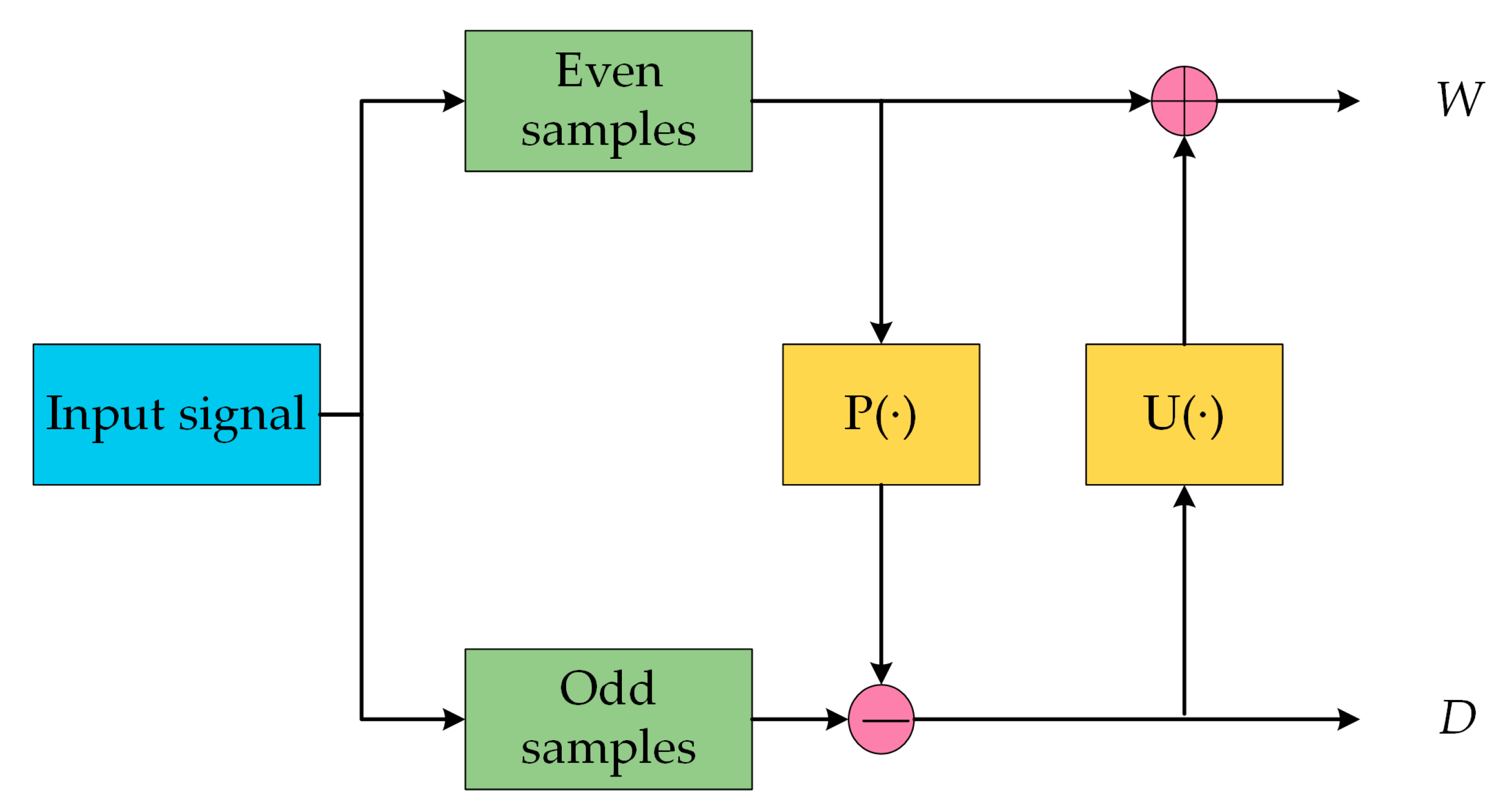
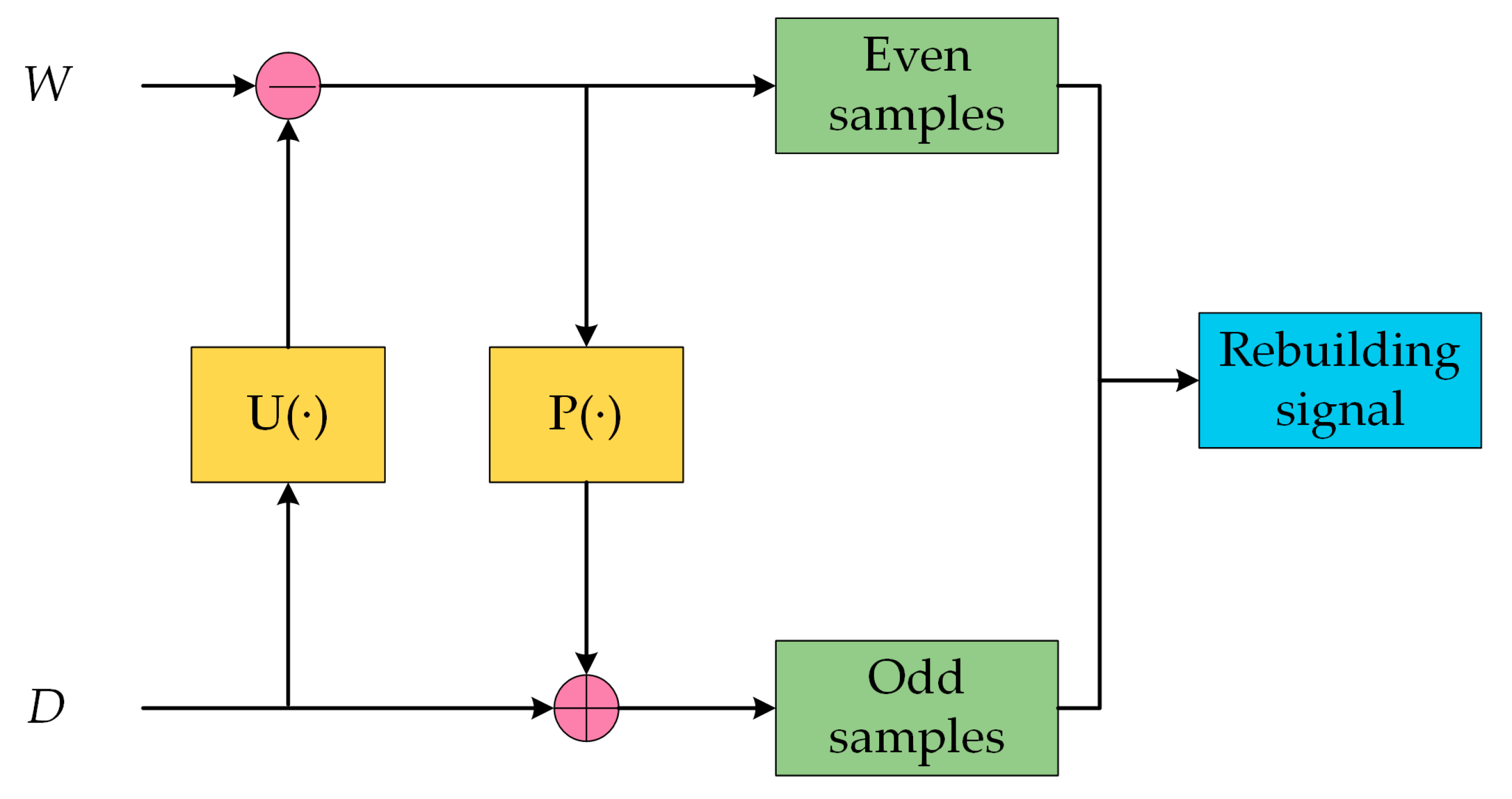
3.4. The Details of SGWT
4. Experiment Setup and Datasets
4.1. Experiment Setup
4.2. Dataset Collection and Augmentation
4.3. Evaluation Metrics
4.4. Baseline Approaches
5. Evaluation
6. Related Works
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhu, R.; Liang, Q.; Zhan, H. Analysis of aero-engine performance and selection based on fuzzy comprehensive evaluation. Procedia Eng. 2017, 174, 1202–1207. [Google Scholar] [CrossRef]
- Wang, C.; Lu, N.; Cheng, Y.; Jiang, B. A data-driven aero-engine degradation prognostic strategy. IEEE Trans. Cybern. 2019, 99, 1–11. [Google Scholar] [CrossRef]
- Zhang, K.; Liu, Y.; Liu, S.; Zhang, X.; Qian, B.; Zhang, C.; Tu, S. Coordinated bilateral ultrasonic surface rolling process on aero-engine blades. Int. J. Adv. Manuf. Technol. 2019, 105, 4415–4428. [Google Scholar] [CrossRef]
- Yao, S.; Cao, X.; Liu, S.; Gong, C.; Zhang, K.; Zhang, C.; Zhang, X. Two-sided ultrasonic surface rolling process of aeroengine blades based on on-machine noncontact measurement. Front. Mech. Eng. 2020, 15, 240–255. [Google Scholar] [CrossRef]
- Gao, C.; Meeker, W.Q.; Mayton, D. Detecting cracks in aircraft engine fan blades using vibrothermography nondestructive evaluation. Reliab. Eng. Syst. Saf. 2014, 131, 229–235. [Google Scholar] [CrossRef]
- Li, W.; Zhou, Z.; Li, Y. Inspection of butt welds for complex surface parts using ultrasonic phased array. Ultrasonics 2019, 96, 75–82. [Google Scholar] [CrossRef]
- Li, J.J.; Yan, C.F.; Rui, Z.Y.; Zhang, L.D.; Wang, Y.T. A Quantitative Evaluation Method of Aero-engine Blade Defects Based on Ultrasonic C-Scan. In Proceedings of the 2020 IEEE Far East NDT New Technology & Application Forum (FENDT), Nanjing, China, 20–22 November 2020; pp. 91–95. [Google Scholar] [CrossRef]
- Fortunato, J.; Anand, C.; Braga, D.F.; Groves, R.M.; Moreira, P.M.G.P.; Infante, V. Friction stir weld-bonding defect inspection using phased array ultrasonic testing. Int. J. Adv. Manuf. Technol. 2017, 93, 3125–3134. [Google Scholar] [CrossRef]
- Droubi, M.G.; Faisal, N.H.; Orr, F.; Steel, J.A.; El-Shaib, M. Acoustic emission method for defect detection and identification in carbon steel welded joints. J. Constr. Steel Res. 2017, 134, 28–37. [Google Scholar] [CrossRef]
- Hauser, M.; Amamcharla, J.K. Development of a method to characterize high-protein dairy powders using an ultrasonic flaw detector. J. Dairy Sci. 2016, 99, 1056–1064. [Google Scholar] [CrossRef] [PubMed]
- Mogilner, L.Y.; Smorodinskii, Y.G. Ultrasonic flaw detection: Adjustment and calibration of equipment using samples with cylindrical drilling. Russ. J. Nondestruct. Test. 2018, 54, 630–637. [Google Scholar] [CrossRef]
- Ding, H.; Qian, Q.; Li, X.; Wang, Z.; Li, M. Casting Blanks Cleanliness Evaluation Based on Ultrasonic Microscopy and Morphological Filtering. Metals 2020, 10, 796. [Google Scholar] [CrossRef]
- Sambath, S.; Nagaraj, P.; Selvakumar, N. Automatic defect classification in ultrasonic NDT using artificial intelligence. J. Nondestruct. Eval. 2011, 30, 20–28. [Google Scholar] [CrossRef]
- Cruz, F.C.; Simas Filho, E.F.; Albuquerque, M.C.S.; Silva, I.C.; Farias, C.T.T.; Gouvêa, L.L. Efficient feature selection for neural network based detection of flaws in steel welded joints using ultrasound testing. Ultrasonics 2017, 73, 1–8. [Google Scholar] [CrossRef]
- Alsaeedi, A.; Khan, M.Z. Software defect prediction using supervised machine learning and ensemble techniques: A comparative study. J. Softw. Eng. Appl. 2019, 12, 85–100. [Google Scholar] [CrossRef]
- Xiao, H.; Chen, D.; Xu, J.; Guo, S. Defects identification using the improved ultrasonic measurement model and support vector machines. NDT E Int. 2020, 111, 102223. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Sayadi, H.; Patel, N.; PD, S.M.; Sasan, A.; Rafatirad, S.; Homayoun, H. Ensemble learning for effective run-time hardware-based malware detection: A comprehensive analysis and classification. In Proceedings of the 2018 55th ACM/ESDA/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 24–28 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Liang, S.; Wang, L.; Zhang, L.; Wu, Y. Research on recognition of nine kinds of fine gestures based on adaptive AdaBoost algorithm and multi-feature combination. IEEE Access 2018, 7, 3235–3246. [Google Scholar] [CrossRef]
- Hothorn, T.; Lausen, B. Double-bagging: Combining classifiers by bootstrap aggregation. Pattern Recognit. 2003, 36, 1303–1309. [Google Scholar] [CrossRef]
- Thong-un, N.; Hirata, S.; Orino, Y.; Kurosawa, M.K. A linearization-based method of simultaneous position and velocity measurement using ultrasonic waves. Sens. Actuators A Phys. 2015, 233, 480–499. [Google Scholar] [CrossRef]
- Wu, B.; Huang, Y.; Krishnaswamy, S. A Bayesian approach for sparse flaw detection from noisy signals for ultrasonic NDT. NDT E Int. 2017, 85, 76–85. [Google Scholar] [CrossRef]
- Zhai, M.Y. Seismic data denoising based on the fractional Fourier transformation. J. Appl. Geophys. 2014, 109, 62–70. [Google Scholar] [CrossRef]
- Zhao, R.M.; Cui, H.M. Improved threshold denoising method based on wavelet transform. In Proceedings of the 2015 7th International Conference on Modelling, Identification and Control (ICMIC), Sousse, Tunisia, 8–20 December 2015; pp. 1–4. [Google Scholar] [CrossRef]
- Tian, P.; Cao, X.; Liang, J.; Zhang, L.; Yi, N.; Wang, L.; Cheng, X. Improved empirical mode decomposition based denoising method for lidar signals. Opt. Commun. 2014, 325, 54–59. [Google Scholar] [CrossRef]
- Mohammadi, M.H.D. Improved Denoising Method for Ultrasonic Echo with Mother Wavelet Optimization and Best-Basis Selection. Int. J. Electr. Comput. Eng. 2016, 6, 2742. [Google Scholar] [CrossRef][Green Version]
- Torres, M.E.; Colominas, M.A.; Schlotthauer, G.; Flandrin, P. A complete ensemble empirical mode decomposition with adaptive noise. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 4144–4147. [Google Scholar] [CrossRef]
- Erçelebi, E. Second generation wavelet transform-based pitch period estimation and voiced/unvoiced decision for speech signals. Appl. Acoust. 2003, 64, 25–41. [Google Scholar] [CrossRef]
- Zheng, H.; Dang, C.; Gu, S.; Peng, D.; Chen, K. A quantified self-adaptive filtering method: Effective IMFs selection based on CEEMD. Meas. Sci. Technol. 2018, 29, 085701. [Google Scholar] [CrossRef]
- Yeh, J.R.; Shieh, J.S.; Huang, N.E. Complementary ensemble empirical mode decomposition: A novel noise enhanced data analysis method. Adv. Adapt. Data Anal. 2010, 2, 135–156. [Google Scholar] [CrossRef]
- Sweldens, W. The lifting scheme: A construction of second generation wavelets. SIAM J. Math. Anal. 1998, 29, 511–546. [Google Scholar] [CrossRef]
- Calderbank, A.R.; Daubechies, I.; Sweldens, W.; Yeo, B.L. Lossless image compression using integer to integer wavelet transforms. In Proceedings of the International Conference on Image Processing, Santa Barbara, CA, USA, 26–29 October 1997; Volume 1, pp. 596–599. [Google Scholar] [CrossRef]
- Chiou, C.P.; Schmerr, L.W.; Thompson, R.B. Review of Progress in Quantitative Nondestructive Evaluation; Springer: Boston, MA, USA, 1993; p. 789. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
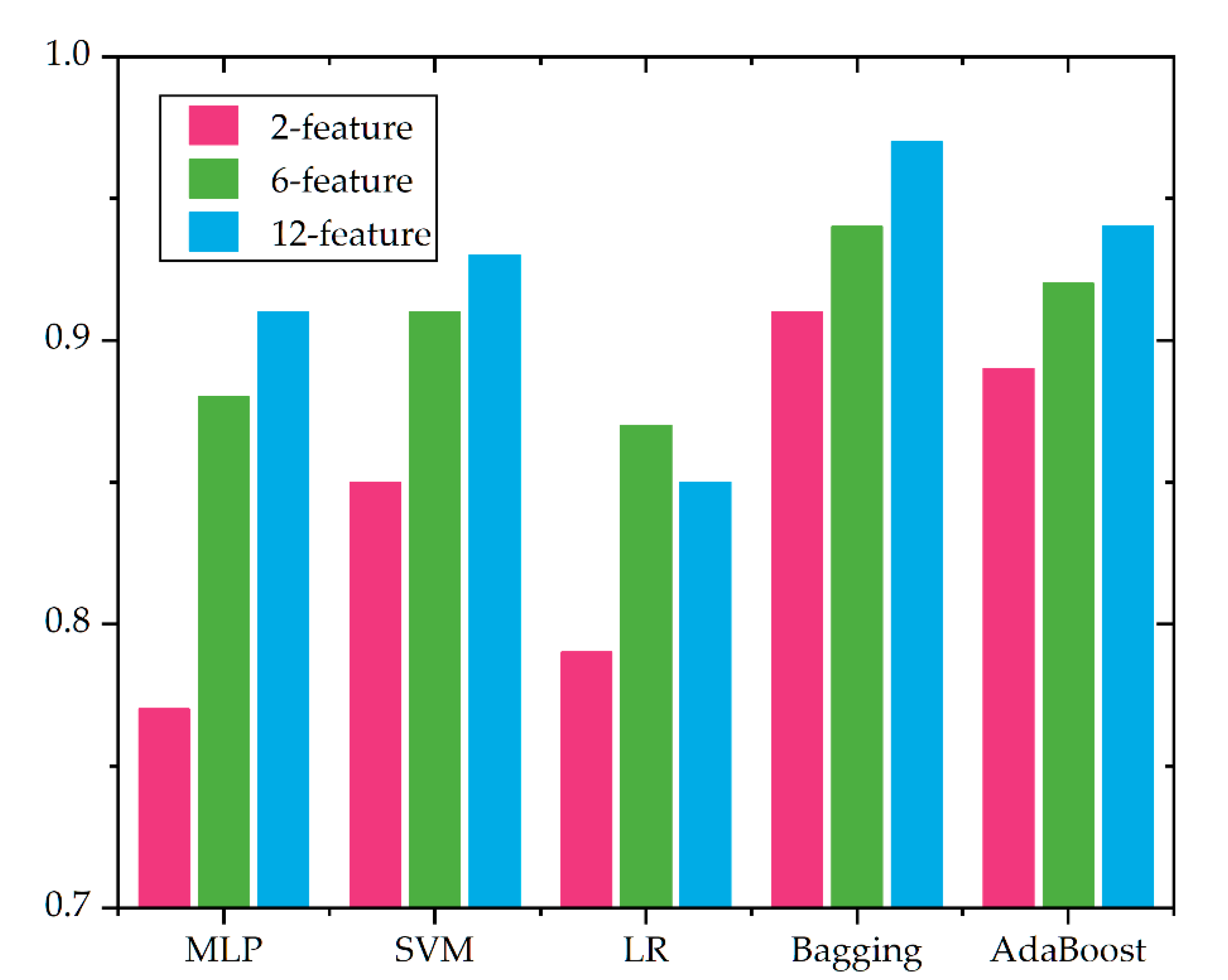
| MLP | SVM | LR | Bagging | AdaBoost | |
|---|---|---|---|---|---|
| 2-feature | 0.77 | 0.85 | 0.79 | 0.91 | 0.89 |
| 6-feature | 0.88 | 0.91 | 0.87 | 0.94 | 0.92 |
| 12-feature | 0.91 | 0.93 | 0.85 | 0.97 | 0.94 |
| MLP | SVM | LR | Bagging | AdaBoost | |
|---|---|---|---|---|---|
| Cavity | 0.65 | 0.73 | 0.70 | 0.90 | 0.88 |
| Crack | 0.99 | 1.00 | 1.00 | 1.00 | 1.00 |
| Inclusion | 0.54 | 0.69 | 0.55 | 0.72 | 0.67 |
| Longitudinal Normal | 0.70 | 0.85 | 0.3 | 0.92 | 0.90 |
| Surface Normal | 0.98 | 1.00 | 1.00 | 1.00 | 1.00 |
| MLP | SVM | LR | Bagging | AdaBoost | |
|---|---|---|---|---|---|
| Cavity | 0.61 | 0.76 | 0.69 | 0.83 | 0.66 |
| Crack | 0.98 | 1.00 | 1.00 | 1.00 | 0.99 |
| Inclusion | 0.46 | 0.66 | 0.53 | 0.73 | 0.67 |
| Longitudinal Normal | 0.76 | 0.86 | 0.77 | 0.91 | 0.85 |
| Surface Normal | 0.98 | 1.00 | 1.00 | 1.00 | 1.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiao, Y.; Li, Z.; Zhu, J.; Xue, B.; Zhang, B. A Novel Ensemble Model on Defects Identification in Aero-Engine Blade. Processes 2021, 9, 992. https://doi.org/10.3390/pr9060992
Jiao Y, Li Z, Zhu J, Xue B, Zhang B. A Novel Ensemble Model on Defects Identification in Aero-Engine Blade. Processes. 2021; 9(6):992. https://doi.org/10.3390/pr9060992
Chicago/Turabian StyleJiao, Yingkui, Zhiwei Li, Junchao Zhu, Bin Xue, and Baofeng Zhang. 2021. "A Novel Ensemble Model on Defects Identification in Aero-Engine Blade" Processes 9, no. 6: 992. https://doi.org/10.3390/pr9060992
APA StyleJiao, Y., Li, Z., Zhu, J., Xue, B., & Zhang, B. (2021). A Novel Ensemble Model on Defects Identification in Aero-Engine Blade. Processes, 9(6), 992. https://doi.org/10.3390/pr9060992