1. Introduction
Dynamic simulation is widely used by chemical engineers to better understand the process [
1]. The simulator based on the first principles model has a wide range of applications on existing processes, and can also have certain predictions for some new processes, which has been proved to be effective in the past few decades. With the development of the fourth industrial revolution and the maturity of the big data environment, data-driven modeling becomes more widely accepted [
2]. However, the corner case cannot be well modeled, such as start-up, shutdown, and fault if the data-driven elements are used only in modeling. In addition, the application of typical data-driven methods, such as model predictive control, optimal control, and reinforcement learning in the complex chemical process may be infeasible without the initial data provided by the first-principles modeling simulator in the way shown in
Figure 1 [
3]. Thus, the development of data-driven methods highly depends on the accuracy and speed of solving the first-principles modeling simulator. Modeling combining mechanistic and data-driven elements can reveal the character of the chemical process better.
For a single unit operation or small-scale process, Luyben [
4] reported that the default model exported by Aspen plus cannot accurately predict the corner case because “the default heat-exchanger models do not account for heat-exchanger dynamics”. Hecht et al. [
5] further reported a similar problem in the reactor. For the plantwide scale, one of the most commonly used and discussed process simulators is the Tennessee Eastman process (TEP) simulator which is carried out by Downs and Vogel [
6] based on the simulation model by the Eastman company. The model was built according to the real process but the components, kinetics, process, and operating conditions were modified. There are seven components and five unit operations in the TEP model, and it also balances accuracy and difficulty in model solving, which can run at a satisfactory speed.
In recent years, chemical engineering processes have been experiencing an increase in complexity and scale. At the same time, the accuracy of modeling and solving such processes is definitely required. However, solving a more accurate mechanism model is often slower, especially for the large-scale process or multiple components. The efficiency of these process simulation is unacceptable for data generation. At the same time, the simulator must run faster than the real process and leave sufficient margin for optimization and control algorithms to meet the requirements of the application. Otherwise, it can not act as a predictor when combined with the real process. Thus, it is very important to implement an accurate and fast process simulator.
To balance the accuracy and difficulty of modeling and solving, model simplifying and solver accelerating have been tried. Sahlodin et al. [
7] used non-smooth differential-algebraic equations (DAE) to model the dynamic phase change, which replaced the optimization problems solved by the original modeling method and reduced the time cost greatly. Connolly et al. [
8] used a reduced variables method to simplify the hydrocarbon-water phase-equilibrium model. Li et al. [
9] used a deep neural network model to simplify the solving of complex fluid mixtures NVT flash problem with given moles, volume, and temperature. These simplified models work well in the scope of simplification, but the previous full mechanism modeling cannot be used effectively.
In recent years, parallel computing has been widely used in chemical process simulation to realize the solver acceleration. Wang et al. [
10] summarized that chemical process simulation and optimization could be divided into high-level and low-level parallelization, and discussed the problems of parallelization scale, load balance, and parallel efficiency. Washington and Swartz [
11] solved the uncertain dynamic optimization problem using the direct multiple shooting method in parallel and applied it to design the chemical process. Laird et al. [
12] also carried out a parallel solving process of dynamic DAE constrained optimization problems, which ran in parallel during the solving process of Karush–Kuhn–Tucker (KKT) system. These methods mainly run in parallel during optimization and dynamic integration, which are typical high-level parallelism, but model solving was not parallelized. Vegeais and Stadtherr [
13], Mallaya et al. [
14] reported that it was a typical low-level parallel algorithm to solve the efficiency problem of the linear solver by dividing the large sparse matrix into blocks. However, there are still a lot of non-linear models in the process of dynamic simulation, so there is still much room to improve the non-linear parallel solver. Chen et al. [
15] realized coarse-grained and fine-grained parallelism on CPU and GPU. Further, Weng et al. [
16] developed a dynamic simulation of molecular weight distribution of multisite polymerization with coarse-grained multithreading parallelism.
In the past few decades, Moore’s law has predicted the growth of CPU single-core performance, and the speed of the same program also become faster without modification. However, the performance growth has encountered a bottleneck in recent years. More cores and vectorized instructions are added to the new CPU to maintain performance growth, which provides parallel computing capabilities on a single CPU chip. Unfortunately, parallel computing needs modifications on the program. At present, an effective solution of increasing solving speed is to convert the problem into multiple sub-problems without dependence on each other and solve these sub-problems in parallel with the new CPU.
In this paper, we design a parallel dynamic simulation taking into account the character of process and the development of computer. Multithreading and vectorization parallel computing modifications are carried out based on General dynamic simulation & optimization system (DSO), which make full use of the features of modern CPU. Compared to the previous research, we use high-level multithreading parallelism and assign tasks according to unit operations which brings clearer task allocation and lower communication costs. The effect of parallel computing modifications is tested on a 500 ethylbenzene process simulator.
2. Process Dynamic Simulation
2.1. Current Program
For dynamic simulation, the solving of temperature, pressure, liquid level, concentration, and other parameters changing with time is an initial value problem of DAE with the constraints of the pipeline network. The form is given by Equation (
1), where
is time and
y are process variables.
For the chemical process, the improved Euler method is used to solve the problem. The iterative form is given by Equation (
2), where
h is the integral step [
17].
Due to the input of intermediate control variables during the dynamic simulation, the actual model form to be solved is given by Equation (
3), where
c are input control variables.
The existing diagram of solving the model in DSO is divided into four parts: solving unit operation model, pipeline network equations, control model, and numerical integration. The solving sequence is shown in
Figure 2a.
2.2. The Choice of Parallel Level
Parallel processing means that the process of solving the problem is divided into several smaller parts and run on multiple processors at the same time to reduce the running time, and then the parts are combined to produce the final result. When there are dependencies in the problem pieces, the calculation process has to be carried out in serial. Partitioning, communication, synchronization, and load balancing are four typical considerations in the design of parallel programs [
18].
The parallel part is designed according to the character of dynamic simulation. The numerical integration cannot be parallelized because it is mostly iterative and changes based on past iteration. During solving the unit operation model, the mass balance equation, heat balance equation, physical property, thermodynamic parameters method, and reactions are under consideration. As the short step size is selected, the calculation of a single unit operation in a one-step integral iteration can be seen as independent of other unit operations, and the numerical integration inside the unit operation is independent of other unit operations. During solving the control system model, there is dependence in the cascade controller in one-step iteration. The pipeline network model is dependent because it needs to be solved iteratively in the field of directly connected pipes.
First of all, from the perspective of partitioning in the design of the parallel program, hotspots are found according to the debugging call tree shown in
Figure 3 and the most time-consuming function is listed in
Table 1. We find that solving unit operation model takes about 75% of time in the whole program, and the most frequently called subroutines are the calculation of enthalpy, volume, and flash, which is close to the thermodynamic and physical property calculation time reported by Harrison [
19]. The single unit operation model solving subroutines should be paralleled, and the thermodynamic and physical property calculation should also be optimized to reduce the hotspot time cost in solving the unit operation model.
As there are control variables given instantly by the operator or external program during simulation, the simulator is sensitive to delay. At the same time, the workload of the non-dependent parallelizable part is small. From the perspective of the communication and synchronization cost, the shared-memory system is selected. Considering the existing CPU specifications, especially the rapid growth of the number of cores, we choose shared-memory multi-threaded programming to modify the existing program. It avoids the high delay in offloading tasks to heterogeneous computing such as GPU and the difficulty of using network connections for multiple machines. Combining the problem characteristics and computer characteristics, the multithreaded parallel is selected to accelerate the unit operation model solving process as shown in
Figure 2b.
Despite parallelizing the unit operation with multithreading, it is also necessary to rewrite the enthalpy, volume calculation, and flash result calculation functions because they are called for many times. As this calculation involves a lot of same calculations for each component, the vectorization parallel can speed up the calculation on the previous basis by using the vector processors of modern CPU which can deal with multiple datasets at the same time, so the vectorization parallel is used to rewrite the calculation functions of enthalpy, volume, and flash results.
Therefore, we decided to use multithreaded parallel on solving unit operation model and vectorization parallel on thermodynamic and physical property calculation.
2.3. The Limit of Parallel Speedup
The speed-up (
S) shown in Equation (
4) is usually used to measure the effect of parallel acceleration, where
is the time used in serial and
is time used in parallel. According to Amdahl’s law [
20] as Equation (
5), the upper limit of speed-up with the fixed workload is determined depending on the proportion
p of parallelizable parts and the number
n of parallelizable parts. The proportion
p of parallelizable parts is about 75% according to the previous analysis so the upper limit of speed-up is 4 as shown in Equation (
6).
2.4. Test Case
The program performance test in the following sections is carried out on a computer with AMD Ryzen™ 9 3900X with 12 cores and 64 GB RAM. As the CPU has precision boost technology, which can raise clock speed automatically, the clock speed is manually set to 2.16 GHz to prevent the clock speed change during the performance test. The compiler toolchain used is MSVC 14.28, and compilation options are the same without specified in each test. The iteration times and inter-process communication times of single system timer calls are modified to reduce the influence of system call time fluctuation. The simulation project used in the test is a nearly stable state of the ethylbenzene process and the integration time step is set to 0.125 s. The simulation time in the test is five hours, and the wall clock running time is recorded. The effect of parallel computing modification is tested on a 500 ethylbenzene process simulator.
The simulated process is based on Sinopec Research Institute of Petroleum Processing (RIPP) liquid-phase benzene alkylation, and the process flowsheet diagram is shown in
Figure 4 [
21]. There are two fresh feeds (benzene and ethylene) and the main reaction is benzene reacts with ethylene to produce ethylbenzene shown in Equation (
7).
6. Conclusions
In order to improve the speed of dynamic simulation to fit the current needs of increasing complexity in chemical processes and data-driven methods, a parallel scheme for dynamic simulation is designed based on the calculation and solving characteristics of dynamic simulation. The parallel part separated by unit operation is more in accord with the laws of process. With a ethylbenzene process test case, the theoretical analysis shows that the speed-up limit is 4. The multithreading parallel is used first, parallel machines scheduling problem solved by greedy algorithm is used to replace the dependence analysis by DAG. The results of the multithreading parallel show that the number of parallel cores is not the more the better because the distillation column will be a serial control step. The highest efficiency appears in in our test case. In addition, we also used vectorized parallelism. The CAV is not enough to make full use of the CPU performance. By manually rewriting part of the hot functions and changing the data structure to the SoA, the parallel speed-up effect can be further improved.
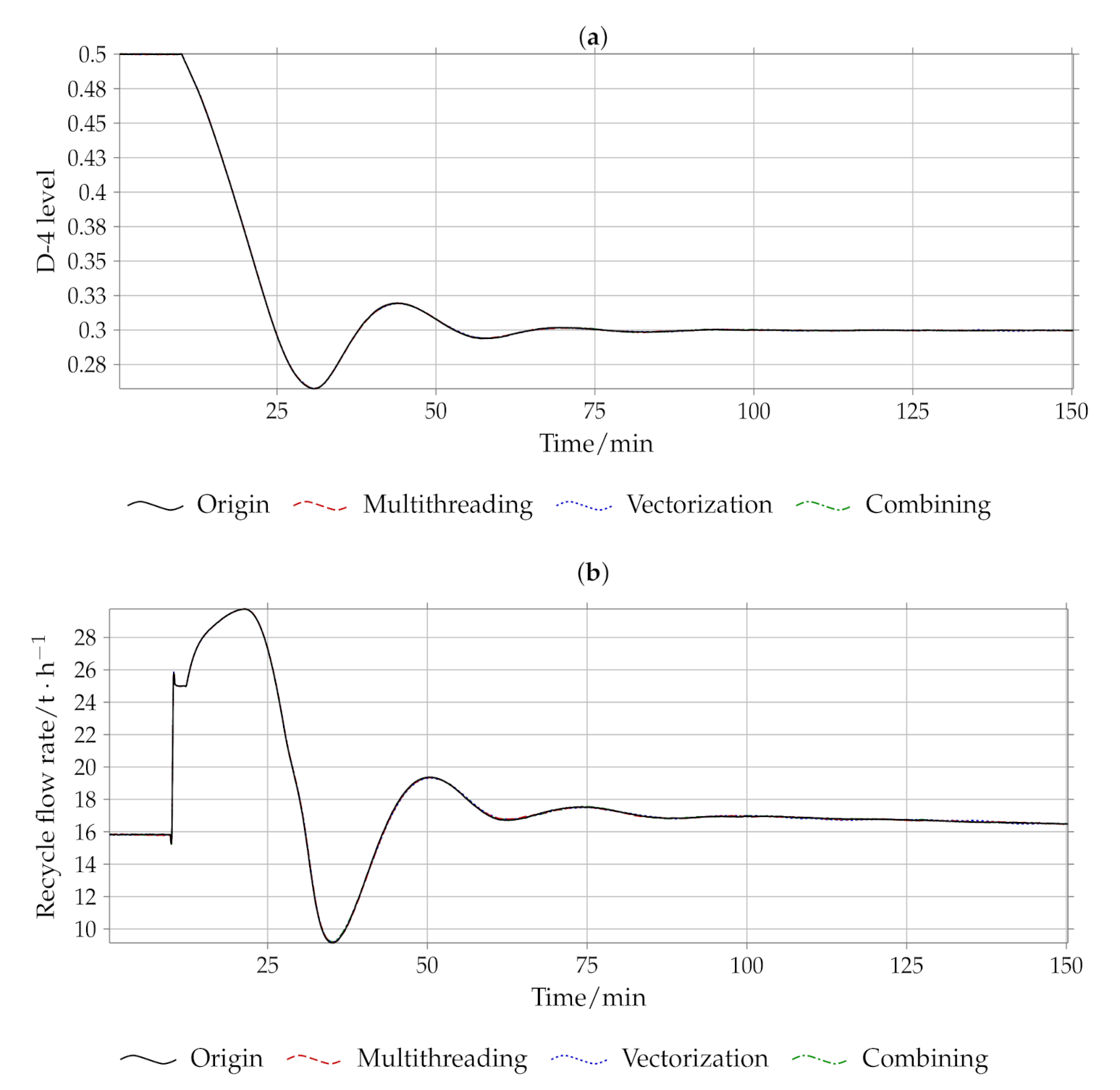
Through these two kinds of parallel methods, the efficiency of the simulator can be effectively improved without affecting the results, which can be increased to 261% of the original program, and the simulation speed can reach 253.59 times of the real-time speed, which can better meet the various needs of the simulator.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}