Abstract
The goal in multiobjective optimization is to determine the so-called Pareto set. Our optimization problem is governed by a parameter-dependent semi-linear elliptic partial differential equation (PDE). To solve it, we use a gradient-based set-oriented numerical method. The numerical solution of the PDE by standard discretization methods usually leads to high computational effort. To overcome this difficulty, reduced-order modeling (ROM) is developed utilizing the reduced basis method. These model simplifications cause inexactness in the gradients. For that reason, an additional descent condition is proposed. Applying a modified subdivision algorithm, numerical experiments illustrate the efficiency of our solution approach.
1. Introduction
Multiobjective optimization plays an important role in many applications, e.g., in industry, medicine, or engineering. One of the mentioned examples is the minimization of costs with simultaneous quality optimization in production or the minimization of CO2 emission in energy generation and simultaneous cost minimization. These problems lead to multiobjective optimization problems (MOPs), where we want to achieve an optimal compromise with respect to all given objectives at the same time. Normally, the different objectives are contradictory such that there exists an infinite number of optimal compromises. The set of these compromises is called the Pareto set. The goal is to approximate the Pareto set in an efficient way, which turns out to be more expensive than solving a single objective optimization problem.
As multiobjective optimization problems are of great importance, there exist several algorithms to solve them. Among the most popular methods are scalarization methods, which transform MOPs into scalar problems. For example, in the weighted sum method [1,2,3,4], convex combinations of the original objectives are optimized. Another popular approach is to use non-deterministic methods like evolutionary algorithms, cf., e.g., [5]. Furthermore, as multiobjective problems are generalizations of scalar problems, some solution methods can be generalized from the scalar to the multiobjective case [6,7,8].
In addition to the classical methods above, there are set-based strategies for the solution of MOPs. Continuation methods [9,10,11] use the fact that the Pareto set is typically (the projection of) a smooth manifold. Subdivision methods [12,13,14,15] use tools from the area of dynamical systems to generate a covering of the Pareto set via hypercubes. However, especially when the objective functions and their gradients are expensive to evaluate, e.g., as an underlying PDE has to be solved for every evaluation, the computational time of these methods can quickly become very large. In the presence of PDE constraints, surrogate models offer a promising tool to reduce the computational effort significantly [16]. Examples are dimensional reduction techniques such as the Reduced Basis (RB) Method [17,18]. In an offline phase, a low-dimensional surrogate model of the PDE is constructed by using, e.g., the greedy algorithm, cf. [17]. In the online phase, only the RB model is used to solve the PDE, which saves a lot of computing time.
In this article, we combine an extension of the set-oriented method presented in [12] based on inexact gradient evaluations of the objective functions with an RB approach and a discrete empirical interpolation method (DEIM) [19,20] for semi-linear elliptic PDEs. In order to deal with the inexactness introduced by the surrogate model, we combine the first-order optimality conditions for multiobjective optimization problems with error estimates for the RB-DEIM method and derive an additional condition for the descent direction [9] to get a tight superset of the Pareto set. This approach allows us to better control the quality of the result by controlling the errors for the objective functions independently. In order to obtain an even tighter superset of the Pareto set, we update these error estimates in our subdivision algorithm after each iteration step.
The article is organized as follows. In Section 2, we recall the basic concepts of multiobjective optimization problems and review results on descent directions with exact and inexact gradients. Furthermore, we develop a set-oriented method to solve these problems, where only inexact gradient information is utilized. In Section 3, the PDE-constrained multiobjective optimization problem and the underlying semi-linear PDE are introduced. Subsequently, we show how reduced-order modeling can be applied efficiently. In Section 4, numerical results concerning both the subdivision and the modified algorithm are presented. Finally, we give a conclusion and discuss possible future work in Section 5.
2. A Set-Oriented Method for Multiobjective Optimization with Inexact Objective Gradients
In this section, we briefly recall the basic concepts of multiobjective optimization. Furthermore, we develop a set-oriented method to solve these problems, where only inexact gradient information is utilized.
2.1. Multiobjective Optimization
Let with be arbitrary. We define the convex and compact parameter set . Now, the goal is to solve the constrained multiobjective optimization problem
with a given objective and .
Compared to scalar optimization, we do not have a natural total order of for . Therefore, we cannot expect that there is a single point in that minimizes all objectives simultaneously. For this reason, we make use of the following definition.
Definition 1.
- (a)
- A point is called (globally) Pareto optimal, if there is no satisfying . In that case we call a Pareto point.
- (b)
- The set of all Pareto points in is called Pareto set and is denoted by
- (c)
- The image of the Pareto set under is called the Pareto front.
If is continuously differentiable on an open set containing , then there exists a first-order necessary condition for Pareto optimality. To formulate this condition, we define the convex, closed, and bounded set
Further, the row vector
stands for the gradient of the i-th objective with .
Definition 2.
If for a given there exists an with
then we call Pareto critical, where
denotes the Jacobi matrix of at μ. The set of all Pareto critical points is called the Pareto critical set, denoted by .
Now, we recall the first-order necessary optimality conditions for (1).
Theorem 1.
Let be continuously differentiable and Pareto-optimal. Then, is Pareto-critical, i.e., it holds . Condition (2) is called the Karush–Kuhn–Tucker (KKT) condition for multiobjective optimization problems.
Proof.
The claim follows from ([1] Theorem 3.25) and the specific choice of . □
Remark 1.
- (a)
- Let belong to the interior of , i.e., . Then (2) is equivalent toorsee also in [21].
- (b)
- Throughout the paper, we only calculate the Pareto critical points in the interior of and make use of (3). The idea is to choose sufficiently large so that we get .
- (c)
- Due to Theorem 1, we haveprovided holds true. ◊
2.2. Descent Direction with Exact Gradients
Next, we introduce the notion of a descent direction for the vector valued objective function at a non-Pareto critical point . From now on, we assume that is continuously differentiable (on an open set containing ).
Definition 3.
The vector is a descent direction for in , if we have
and if there is at least one with .
One way to compute a descent direction is to solve a constrained quadratic optimization problem in as shown in the following theorem. For a proof we refer to the work in [8]. A similar result was shown in [22].
Theorem 2.
For given let be a (global) solution of the convex constrained quadratic minimization problem
Then, we have either or is a descent direction for in μ.
Combined with a backtracking Armijo line search, the descent direction from Theorem 2 can be used to construct the steepest descent method in Algorithm 1.
| Algorithm 1: Steepest descent method. |
 |
Remark 2.
- (a)
- If Algorithm 1 terminates after a finite number l of iterations, then is a Pareto critical point.
- (b)
- Assume that Algorithm 1 does not stop after a finite number of iterations. Then, every accumulation point of the sequence generated by Algorithm 1 is a Pareto critical point. A proof based on ([7], Theorem 1) can be found in ([23] Theorem 5.2.5). ◊
2.3. Descent Direction with Inexact Gradients
Suppose that we have continuously differentiable approximations of the objective function satisfying
for given tolerances . By we denote the Pareto set for and by the Pareto set for . If we write , we mean the Pareto-critical set for and is the Pareto-critical set for . Note that, in general, we have neither nor .
In this section, our goal is to compute an approximation of based on the approximation of the objective function and the error bounds . We begin by investigating the relationship between the KKT conditions of the original objective function and its approximation.
Lemma 1.
Let (5) be satisfied and be Pareto-critical for with the KKT-condition vector . Then, it holds that
with , where we set .
Proof.
From and Remark 1-a) we infer that holds. Therefore,
which gives the desired results. □
Based on estimate (6), we define two approximation sets for the Pareto-critical set of .
Definition 4.
Let us introduce the two sets
and
Lemma 2.
It holds that
Proof.
Let be a Pareto-critical point of , then there exists with . From Lemma 1, it follows that .
Next, we assume that is a Pareto-critical point of , then there exists with This implies
Therefore, we have
Let . Then, there exists with
Thus, we get which implies . □
Our goal is to compute the set via a descent method like Algorithm 1. To this end, the following theorem presents a modified version of the descent direction (4), which additionally takes the error bounds into account.
Theorem 3.
Let with and be given. Assume that is a minimizer of the quadratic problem
Then, we have that or is a descent direction for in μ.
Proof.
The Lagrange functions for (7) is given as
As is a minimizer of (7), we get Lagrangian multipliers and with
If we multiply (8) with from the left, we get
which implies
First case:, then holds and we are done.
Second case:, then holds. In this case, we show that is a descent direction in for every objective function with :
Define
If we can show that holds for every , we know that is a descent direction for every objective function in .
Choose . Then, there exists an with , and using (8) we obtain
Therefore, is a descent direction in for every objective function , . □
The descent direction from the previous theorem will be referred to as the modified descent direction. Based on this direction, we can now construct a descent method for the computation of , which is shown in Algorithm 2.
| Algorithm 2: Descent method with inexact gradients. |
 |
Remark 3.
- (a)
- If Algorithm 2 terminates after l iteration steps, then is contained in .
- (b)
- Assume that Algorithm 2 does not terminate after a finite number of iteration steps. Then, every accumulation point of the sequence generated by Algorithm 2 is in the set . A proof based on ([7] Theorem 1) can be found in ([23] Theorem 5.3.5).
- (c)
- Note that the tolerance ε is constant for all l throughout Algorithm 2. In Section 2.5, we will adapt ε in each iteration. ◊
2.4. Subdivision Algorithm
As mentioned in the introduction, there exist set-based solution methods for MOPs which globally approximate the Pareto set via sets (instead of a finite number of points). Here, we will consider the subdivision algorithm [12,13,15], which computes an approximation of the Pareto set as a covering of hypercubes (or boxes). The idea is to start with a large box containing the Pareto set which is then iteratively subdivided into smaller boxes, while eliminating boxes that do not contain part of the Pareto set.
There are essentially two versions of the subdivision scheme: one is gradient free and, thus, is particularly useful in the case when the evaluation of gradients is computationally expensive. We refer to the work in [12], where this variant is utilized to numerically realize a reduced-order approach for a PDE-constrained multiobjective optimization problem. The other one is directly based on a dynamical systems approach and utilizes gradient information in a similar way to memetic algorithms, see in [8]. Here, we will generalize the latter to the case of inexact gradients.
For a stepsize , let us formulate a descent step of the optimization procedure by
where and are the descent directions given by Theorems 2 and 3, respectively, with the choice . Depending on the descent step that we use, we either want to compute the Pareto-critical set or the superset or of . As these sets are the sets of fixed points for their respective descent step, we want to find the subset satisfying or .
To generate the set , we will use a subdivision method. This method produces an outer approximation of the set in the form of a nested sequence of sets , where denotes the power set of and each is a subset of in the sense that
holds and consists of finitely many subsets B covering for all . For each set , we define a diameter through . Algorithm 3 shows the classical subdivision method (based on Theorem 2) and our modified descent direction (based on Theorem 3).
| Algorithm 3: Subdivision algorithm. |
 |
Remark 4.
In order to realize the subdivision algorithm numerically we choose a similar way as described in ([13] Remark 2.4). Instead of working explicitly with the centers and radii of the boxes, these are stored within a binary tree in the subdivision step, whereby the memory requirement is noticeably reduced. The selection step is implemented using a certain number of sample points in each box. These sample points are chosen either on an a priori defined grid or randomly within the boxes. Afterwards, is evaluated in these points. For more details, we refer the reader to ([24] Section 5). ◊
2.5. Modified Subdivision Algorithm for Inexact Gradients
In Algorithm 2, we utilize the same error bounds with , , in each iteration step l. Note that the larger the , the greater the difference between and or . In the algorithm, we produce an outer approximation of the set with a nested sequence of sets by
As it holds that , we have
Now we modify Algorithm 3 by utilizing the descent directions introduced in Theorem 3 and update after every iteration step l to generate a better approximation of the set . For updating , we use the formula
and set . Due to the nested choice of the box coverings, we have for and . In iteration step l, we generate the descent direction by computing
Then, we set
3. Multiobjective Optimization of a Semi-Linear Elliptic PDE
In this section, we introduce a multiobjective parameter optimization problem governed by a semi-linear elliptic PDE. Further, we show how reduced-order modeling can be applied efficiently.
3.1. Problem Formulation
Let , , be a bounded domain with Lipschitz-continuous boundary . Then, we consider the problem
subject to the elliptic boundary value problem
where is the state variable and the parameter. We suppose that with , , , and . Moreover, b, c, and d are non-negative constants with .
As is a bounded connected open set with smooth boundary, it is known that V is a Hilbert space endowed with the inner product
and the induced norm for , see ([25], p. 133) for instance.
3.2. The Parameter Dependent Semi-Linear Elliptic PDE
In this subsection, we study the state equation (11b). First, we define the nonlinear operator by
Recall that implies , cf. ([26] Section 7). Therefore, the operator is well defined. Moreover, for the functional is given by
Now, we define a weak solution to the state Equation (11b).
Definition 5.
A weak solution of (11b) is a function satisfying
The following result is proved, e.g., in ([26] Section 4.2.3).
Proposition 1.
For a fixed parameter , there exists a unique solution to (11b). This solution is even continuous on , and for a constant it holds that
Remark 5.
We define the state space , which is a Banach space endowed with the natural norm
Motivated by Proposition 1 , we define the parameter-to-state mapping as follows: For a given parameter , the function is the solution to (11b). It follows by standard arguments that is continuously Fréchet-differentiable, see ([23] Sections 2 and 4). ◊
3.3. Reduced Formulation and Adjoint Approach
Utilizing the parameter-to-state mapping , we define the reduced cost functional
with
and . Now, the reduced problem is given as
If is a locally optimal solution to (13), then the pair is a locally optimal solution to (11). Conversely, if solves (11) locally, the parameter is a locally optimal solution to (13).
To apply the subdivision algorithm, the reduced objective function has to be Fréchet-differentiable, following immediately from the fact that the parameter-to-state operator is Fréchet-differentiable, cf. Remark 5. The gradient of can be expressed by introducing adjoint variables. For that purpose, we define the operators , , as
for . Next, we define adjoint variables.
Definition 6.
Let a parameter be given and . For every , we call the solution to
the adjoint variable associated with the objective.
Remark 6.
3.4. Finite Element (FE) Galerkin Discretization
Let us briefly introduce a standard finite element (FE) method based on a triangulation of the spatial domain . Here, we utilize piecewise linear FE ansatz functions , which are linearly independent. We define the finite-dimensional subspace supplied with the same topology as in V.
Next, we replace (12) by a FE Galerkin scheme: For each , the FE solution solves
It follows by the same arguments as for (12) that the FE problem (16) has a unique solution for every . Therefore, the parameter-to-state FE mapping , is well defined. For there exist coefficients , , satisfying
Inserting (17) into (16), we can express (16) as a nonlinear algebraic system. For that purpose, we introduce the -matrices
the N-vectors
and the nonlinearity function given as
Remark 7.
The difficulty of (18) lies in the fact that we cannot assemble efficiently in terms of a matrix-vector multiplication. Therefore, we use mass lumping to compute approximately. For an introduction into mass lumping see, e.g., ([27] Section 15) or ([28] Section 17.2). With that we can write (18) as a root finding problem of
with and the lumped mass matrix defined by
Further details can be found in [23,29]. Let us refer to in [30], where mass lumping is utilized in optimal control. ◊
Now, the FE objectives are given as
3.5. Reduced-Order Modelling (ROM)
To generate the Pareto-critical set of the MOP (11), we need to evaluate the reduced objectives , , and their gradients many times. Therefore, the state and adjoint equations have to be solved numerically very often. Therefore, the use of ROM is a suitable option. In this paper, we will use the Reduced Basis (RB) method. The main idea is to construct a low-dimensional (i.e., ) subspace of the FE space spanned by FE solutions of the state and adjoint equation for appropriately chosen parameters . Here, this strategy is realized by greedy algorithms. We refer to the works in [17,18,31] for a general explanation and to ([23] Section 3.2) for our specific problem (11). This is an iterative procedure where in each iteration FE solutions of the state and adjoint equation at a specific parameter value are added to the basis. An essential ingredient of greedy algorithms is the choice of an error indicator . Here, we use the maximal true error between the FE and the ROM gradients, i.e., we set
Our subdivision scheme is based on gradient information. To be able to generate or for the approximation of , we have to ensure that the approximated objective function based on the ROM model satisfies the inequality in (5). The idea is to generate a new basis element in every step until the maximum error on a discrete training set , which approximates good enough, is smaller than a tolerance . For more details, see Algorithm 4.
| Algorithm 4: Greedy algorithm. |
 |
As is a subset of V, we endow with the V-topology. Due to (), there exists a coefficient matrix such that
Now, we replace (16) by an RB Galerkin scheme: For each , the RB solution solves
We suppose that (22) has a unique solution for every . Therefore, the parameter-to-state RB mapping , is well defined.
Inserting (21) and into (22), we derive the nonlinear algebraic system (cf. (18))
with the matrices , , and and the ℓ-vectors and .
Remark 8.
As mentioned in Remark 7, we apply mass lumping to evaluate the nonlinear function more efficiently. With that we can write (23) as a root finding problem of
with and the matrix . However, in the RB Galerkin scheme the evaluation of the nonlinearity is still as costly as in the FE case. Here, discrete empirical interpolation (DEIM) is applied, cf. [19,20]. We skip the detailed description here and refer the reader to ([23] Section 3.2). ◊
3.6. Convergence Analysis
We prove the convergence of the RB solution with mass lumping to the weak solution of the state and adjoint equation.
Remark 9.
As the FE space is a finite dimensional space, the error for the state and adjoint equation converges for increasing dimension of the RB space to zero. Therefore, the RB solution converges for increasing accuracy in the Greedy algorithm to the FE solution. We skip a detailed description of the proof here and refer the reader to ([23], Section 3.2). ◊
Theorem 4.
Let with be a growing sequence of training sets and choose a monotone sequence satisfying
Then, we get
Proof.
Let be an arbitrary parameter. It holds that
with . From Theorem A1 (see Appendix A), we infer that the first summand converges to zero for increasing N. For the second summand, we refer the reader to ([23] Section 3.2.5); in this section we proved the convergence of the RB solution to the FE solution. For the adjoint equation, we can do the same and the claim follows. □
4. Numerical Experiments
In this section, we use our algorithm to solve multiobjective optimization problems with PDE constraints and interpret the numerical results. All computations were executed on a computer with a 2.9 GHz Intel Core i7 CPU, 8 GB of RAM, and an Intel HD Graphic 4000 1536 MB GPU. The algorithms were implemented in Matlab R2017b. For the subdivision method, we used the implementation from https://math.uni-paderborn.de/en/ag/chair-of-applied-mathematics/research/software.
In this example, we will numerically investigate the application of the modified subdivision algorithm presented in Section 2.5 to the PDE-constrained multiobjective optimization problem using the RB-DEIM solver from Section 3.5. For the underlying PDE, we set , with elements , , and ; the right-hand side , , , and ; and the boundary condition . This leads to the following PDE:
In Figure 1, the corresponding solutions of the state equation are shown for three values of .
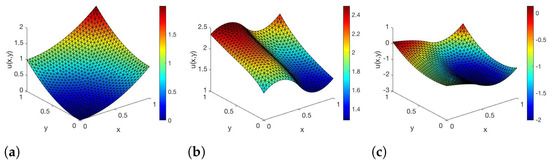
Figure 1.
FE solutions of (25) for parameters (a) , (b) and (c) .
In [23], we have already observed that the error between the FE- and RB-DEIM-solution of the state and adjoint equation decreases if the FE grids get finer. We skip the detailed description here and refer the reader to ([23] Section 5).
Notice that solves (25) for . For the FE-solver, we used linear finite elements with and the finite elements have 762 degrees of freedom. We choose the following two objective functions:
with . For the desired state , we take the FE solution for , i.e., . Thus, is a piecewise linear approximation of . The associated FE objectives are now given as
with . The gradients are
where is the FE solution to (15), and . The associated RB objective functions have the form
with . In [23], we have already observed good agreement between the approximated Pareto critical sets with the FE- and RB-DEIM-solver, if the error between the gradients is sufficiently small. However, we cannot always guarantee this agreement. Thus, we will instead use the supersets and from Section 2.3 for the approximation of (and ), which is only based on the reduced objective function and the error bounds . To generate , we compute the steepest descent direction for all components of . Similar to Algorithm 1, we first calculate as solution of (4) for . Then, the descent direction is . As a stopping condition, we choose and set if it holds that
To generate , we use Algorithm 2.
To save computational time during the modified subdivision algorithm, we calculate
before the algorithm starts (i.e., in an offline phase) on a training set , which approximates and store these errors. During the subdivision algorithm, we use them to generate the new faster and without calculating the FE solution again.
To see a significant difference between the modified subdivision algorithm and the subdivision algorithm and and , we need to have a big error between the gradients. To achieve this, we choose a rough training set
with . For the Greedy algorithm, we choose the tolerance and the true error as error indicator, for the DEIM algorithm we choose the tolerance .
With these settings, we generate an RB-basis with six elements and a DEIM-basis with 18 elements. This leads to the following estimations for the gradients of and :
To generate these estimations, we chose a training set with 3105 equally distributed test points and generate the error for these points. Thus, we have
Now, we test the subdivision and the modified subdivision algorithm with the following conditions. To compute the descent direction, we use the Matlab function fmincon and solve (4) or (7). The algorithm stops when the box size is small enough, which is after 25 iteration steps in our case. In every step, we halve the boxes. We choose five sample points in each box during the first five iteration steps, four sample points in the next five iteration steps, three sample points for the iteration steps ten to 14, two sample points for the next five steps, and one sample points for the last five iteration steps, see Remark 4. Figure 2 shows the generated approximated Pareto sets for the FE-solver after 20 and 25 iteration steps.
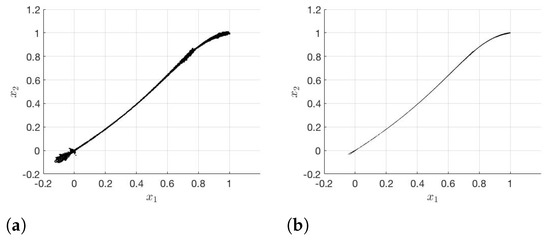
Figure 2.
Pareto-critical set in iteration step (a) 20 and (b) 25 for the FE-solver.
The results with the subdivision algorithm and RB-DEIM-solver are shown in Figure 3.
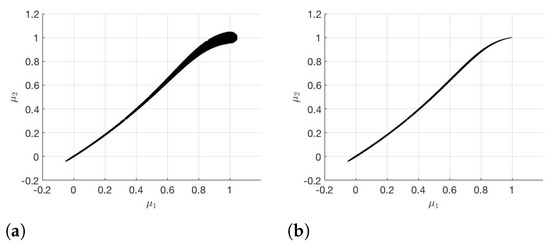
Figure 3.
(a) and (b) generated with the subdivision algorithm.
The modified subdivision algorithm and RB-DEIM-solver lead to the results plotted in Figure 4.
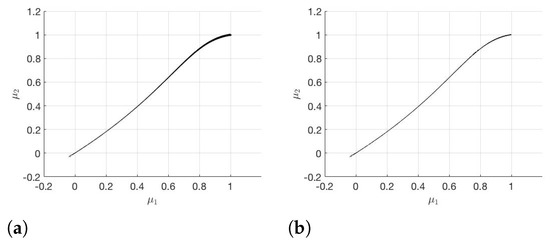
Figure 4.
(a) and (b) generated with the modified subdivision algorithm.
The runtime, number of boxes and number of function and gradient evaluations needed in iteration step 10, 15, 20, and 25 are shown in Table 1, Table 2, Table 3, Table 4 and Table 5. The total runtime and number of function and gradient evaluations needed for the different methods and the speed-up are shown in Table 6.

Table 1.
The performance of the subdivision algorithm with the FE-solver and the steepest descent method.
Table 2.
Subdivision algorithm with the steepest descent method.
Table 3.
Subdivision algorithm with the modified descent direction.
Table 4.
Modified subdivision algorithm with the steepest descent method.
Table 5.
Modified subdivision algorithm with the modified descent direction.
Table 6.
Total runtime, number of function, and gradient evaluations for the different methods and the speed-up.
The Greedy algorithm and DEIM together take 14.06 s in the offline phase. To ensure the error (cf. (5)) for the gradients on the training set , it takes s. It follows from Figure 3 and Figure 4 that is significantly smaller than for the subdivision algorithm as well as for the modified subdivision algorithm. Therefore, we have a much better approximation for if we choose instead of . If we compare the two different subdivision algorithms, we notice that with the modified subdivision algorithm we have a better approximation of than with the subdivision algorithm.
The reason for this is that in the modified subdivision algorithm we have a monotonically decreasing sequence . In Figure 5, the error between and is plotted on the parameter set . The black markers are some points on the Pareto critical set . It turns out that the difference between the two gradients is significantly smaller near than in other regions of . Due to this, in the modified subdivision algorithm, the sequence decreases noticeably so that it is useful to update after each iteration step. As we have already mentioned, is a better approximation of . If is generated by the modified subdivision algorithm, the result is even better. Comparing Figure 2b and Figure 4b, there is no significant difference between the two sets. Therefore, the modified subdivision algorithm yields a good approximation for , although the error is not small.
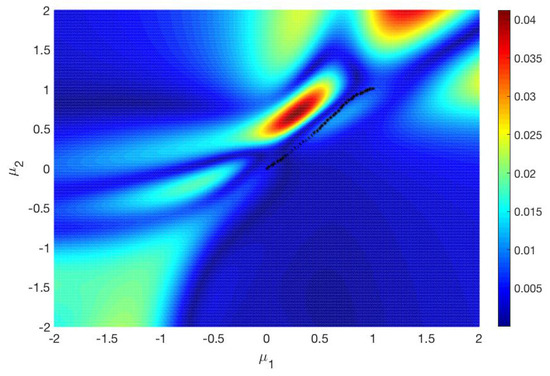
Figure 5.
Difference for .
Regarding the computational time (cf. Table 1, Table 2, Table 3, Table 4, Table 5 and Table 6), we notice that in the first 20 iterations the four methods take almost the same time. In these iteration steps, the FE-solver takes between 19 and 30 times more time for one iteration step than the four RB-based methods. Only in the subsequent iteration steps a significant difference in the four RB-based methods appears. For these iteration steps, the FE-solver takes between and times as much time as one of the four methods for one iteration step. We notice that the computation of takes around two times as much time as the computation of with the subdivision algorithm. The main reason for this is the much larger number of function and gradient evaluations that we have for . This, in turn, can be attributed to the significantly larger number of boxes for . If we use the modified subdivision algorithm, the computation of takes slightly more time than the computation of . The main reason for this is again the larger number of function and gradient evaluations. Unlike the previous case, this can not be lead back to the number of boxes, but probably to the calculation of the modified descent method, which requires more function and gradient evaluations. Nevertheless, the difference in the computational time is marginal (a factor about ) for the modified subdivision algorithm. For , we notice another behavior: Here, the generation of with the modified subdivision algorithm is 2 times faster than with the subdivision algorithm. This is mainly because of the larger number of function evalutions, which is due to the larger number of boxes. The FE-solver takes approximately times as much time as the computation of and approximately times as much as the time as the computation of with the modified subdivsion. This is another advantage of the modified subdivision algorithm. As we get a better approximation in this algorithm, we have fewer boxes in the iteration steps, and therefore we have a smaller number of function and gradient evaluations than we have for the subdivision algorithm. Finally, we see that the modified subdivision algorithm works better and faster than the subdivision algorithm. As is a tighter approximation of , it is better to generate rather than .
5. Conclusions
In this article, we present a way to solve multiobjective parameter optimization problems of semilinear elliptic PDEs by combining an RB approach and DEIM with the set-oriented method based on gradient evaluations. To deal with the error introduced by the surrogate model, we derived an additional condition for the descent direction, which allows us to consider the errors for the objective functions independently and derive a superset of the Pareto-critical set . To get an even tighter superset, we update these error bounds in our subdivision algorithm after each iteration step. To summarize the numerical results, we first investigated the influence of the error bounds for the gradients of the objective functions. By individually adapting the components of the error bounds, we obtained a tighter covering of the Pareto critical set. When we additionally adjusted the error bounds in each iteration step, the result became even tighter and almost coincided with the exact solution of the MOP (solution with the FE-solver and the steepest descent method). Furthermore, we compared the computational time for each method. The FE-solver needed between times and times more time than the four different RB-based methods we presented in this work. For future work, it could be interesting to improve the results in ([23] Section 3.2.4) and to develop an efficient a posteriori error estimator for the error in the objectives and their gradients, cf., e.g., [32,33,34]. These error bounds can then be used in a weak greedy algorithm and beyond that for the error bounds which are needed in the subdivision algorithm.
Author Contributions
The authors contributed equally to this work. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded partially by Deutsche Forschungsgemeinschaft grant number Priority Programme 1962.
Acknowledgments
The authors gratefully acknowledge partial support by the German DFG-Priority Program 1962. Furthermore, S. Banholzer acknowledges his partial funding by the Landesgraduiertenförderung of Baden-Württemberg.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MOP | Multiobjective optimization problem |
| DEIM | Discrete Empirical Interpolation Method |
| FE | Finite Element |
| GS | Gram–Schmidt |
| KKT | Karush–Kuhn–Tucker |
| PDE | Partial-differential equation |
| POD | Proper Orthogonal Decomposition |
| RB | Reduced Basis |
| ROM | Reduced Order Modeling |
Appendix A. Mass Lumping
We follow the work in [35]. Let , be an open, bounded Lipschitz domain, e.g., . We set and , where V is endowed with the inner product
and its induced norm. Let denote an underlying triangulation of and denote the set of interior vertices of , and let be the set of vertices belonging to and be the FE space generated by first order Lagrange elements. It holds that .
Define for a lumped mass region by joining the centroids of the triangles, which have as a common vertex, to the midpoint of the edges, which have as a common extremity. We define the two sets
and the operator
We consider the following semi-linear elliptic partial differential equation:
A weak solution of (A1) is a function such that
The function f is supposed to be sufficiently smooth, bounded, and measurable for a fixed y; monotonically increasing; and satisfies . Moreover, and with . Then, there exists a unique solution of (A1), c.f. [26], for instance. This solution is even continuous, and for a constant it holds that
The lumped mass finite element approximation of (A1) is to find such that
holds for all and for .
Remark A1.
For any , it holds that . Therefore, for , which implies
◊
Proof.
Because y solves (A2), it holds that . Let be the interpolation polynomial of y in . Then, it follows that . Utilizing (A3), we derive
Let be an arbitrary tolerance. For N large enough, we have . Furthermore, we have and . From (A4), we conclude
Utilizing , , and , it follows that
Inserting this estimation into the equality before thus gives
with . In the last inequality, we used the fact that for . Therefore, we get
and it follows for . □
Remark A2.
For and we find
For the last step we use
A detailed proof for this equality can be found in ([36], Appendix A). ◊
References
- Ehrgott, M. Multicriteria Optimization; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Iapichino, L.; Ulbrich, S.; Volkwein, S. Multiobjective PDE-constrained optimization using the reduced-basis method. Adv. Comput. Math. 2017, 43, 945–972. [Google Scholar] [CrossRef]
- Miettinen, K. Nonlinear Multiobjective Optimization; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1999. [Google Scholar]
- Zadeh, L. Optimality and non-scalar-valued performance criteria. IEEE Trans. Autom. Control 1963, 8, 59–60. [Google Scholar] [CrossRef]
- Deb, K. Multi-Objective Optimization Using Evolutionary Algorithms; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2001. [Google Scholar]
- Fliege, J.; Graña Drummond, L.M.; Svaiter, B.F. Netwon’s Method for multiobjective optimization. SIAM J. Optim. 2008, 20, 602–626. [Google Scholar] [CrossRef]
- Fliege, J.; Svaiter, B.F. Steepest descent methods for multicriteria optimization. Math. Methods Oper. Res. 2000, 51, 479–494. [Google Scholar] [CrossRef]
- Schäffler, S.; Schultz, R.; Weinzierl, K. Stochastic method for the solution of unconstrained vector optimization problems. J. Optim. Theory Appl. 2002, 114, 209–222. [Google Scholar] [CrossRef]
- Banholzer, S.; Gebken, B.; Dellnitz, M.; Peitz, S.; Volkwein, S. ROM-based multiobjective optimization of elliptic PDEs via numerical continuation. arXiv 2019, arXiv:1906.09075v1. [Google Scholar]
- Hillermeier, C. Nonlinear Multiobjective Optimization: A Generalized Homotopy Approach; Birkhäuser: Cambridge, MA, USA, 2001. [Google Scholar]
- Schütze, O.; Dell’Aere, A.; Dellnitz, M. On continuation methods for the numerical treatment of multi-objective optimization problems. In Practical Approaches to Multi-Objective Optimization; Branke, J., Deb, K., Miettinen, K., Steuer, R.E., Eds.; Dagstuhl Seminar Proceedings: Dagstuhl, Deutschland, 2005. [Google Scholar]
- Beermann, D.; Dellnitz, M.; Peitz, S.; Volkwein, S. Set-oriented multiobjective optimal control of PDEs using proper orthogonal decomposition. In Reduced-Order Modeling (ROM) for Simulation and Optimization: Powerful Algorithms as Key Enablers for Scientific Computing; Springer International Publishing: Cham, Switzerland, 2018; pp. 47–72. [Google Scholar]
- Dellnitz, M.; Schütze, O.; Hestermeyer, T. Covering Pareto sets by multilevel subdivision techniques. J. Optim. Theory Appl. 2005, 124, 113–136. [Google Scholar] [CrossRef]
- Jahn, J. Multiobjective search algorithm with subdivision technique. Comput. Optim. Appl. 2006, 35, 161–175. [Google Scholar] [CrossRef]
- Schütze, O.; Witting, K.; Ober-Blöbaum, S.; Dellnitz, M. Set oriented methods for the numerical treatment of multiobjective optimization problems. In EVOLVE—A Bridge between Probability, Set Oriented Numerics and Evolutionary Computation; Tantar, E., Tantar, A.-A., Bouvry, P., Del Moral, P., Legrand, P., Coello Coello, C.A., Schütze, O., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 447, pp. 187–219. [Google Scholar]
- Schilders, W.H.; Van der Vorst, H.A.; Rommes, J. Model Order Reduction; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Hesthaven, J.S.; Rozza, G.; Stamm, B. Certified Reduced Basis Methods for Parametrized Partial Differential Equations; SpringerBriefs in Mathematics: Heidelberg, Germany, 2016. [Google Scholar]
- Patera, A.T.; Rozza, G. Reduced Basis Approximation and A Posteriori Error Estimation for Parametrized Partial Differential Equations. MIT Pappalardo Graduate Monographs in Mechanical Engineering: Cambridge, MA, USA, 2007. [Google Scholar]
- Chaturantabut, S.; Sorensen, D.C. Nonlinear model reduction via discrete empirical interpolation. SIAM J. Sci. Comput. 2010, 32, 2737–2764. [Google Scholar] [CrossRef]
- Chaturantabut, S.; Sorensen, D.C. A state space estimate for POD-DEIM nonlinear model reduction. SIAM J. Numer. Anal. 2012, 50, 46–63. [Google Scholar] [CrossRef]
- Gebken, B.; Peitz, S.; Dellnitz, M. A descent method for equality and inequality constrained multiobjective optimization problems. In Numerical and Evolutionary Optimization—NEO 2017; Trujillo, L., Schütze, O., Maldonado, Y., Valle, P., Eds.; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Graña Drummond, L.M.; Svaiter, B.F. A steepest descent method for vector optimization. J. Comput. Appl. Math. 2005, 175, 395–414. [Google Scholar] [CrossRef]
- Reichle, L. Set-Oriented Multiobjective Optimal Control of Elliptic Non-Linear Partial Differential Equations Using POD Objectives and Gradient. Master’s Thesis, University of Konstanz, Konstanz, Germany, 2020. Available online: http://nbn-resolving.de/urn:nbn:de:bsz:352-2-1h6pp1cxptbap6 (accessed on 15 April 2021).
- Dellnitz, M.; Hohmann, A. A subdivision algorithm for the computation of unstable manifolds and global attractors. Numer. Math. 1997, 75, 293–316. [Google Scholar] [CrossRef]
- Dautray, R.; Lions, J.-L. Mathematical Analysis and Numerical Methods for Science and Technology. Volume 2: Functional and Variational Methods; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Tröltzsch, F. Optimal Control of Partial Differential Equations: Theory, Methods and Applications; American Mathematical Society: Providence, RI, USA, 2010; Volume 112. [Google Scholar]
- Thomée, V. Galerkin Finite Element Methods for Parabolic Problems; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Zienkiewicz, O.C.; Taylo, R.L. The Finite Element Method, 5th ed.; Butterworth-Hienemann: Oxford, UK, 2000; Volume 3. [Google Scholar]
- Brenner, S.; Scott, R. The Mathematical Theory of Finite Element Methods; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Rösch, A.; Wachsmuth, G. Mass lumping for the optimal control of elliptic partial differential equations. SIAM J. Numer. Anal. 2017, 55, 1412–1436. [Google Scholar] [CrossRef]
- Quarteroni, A.; Manzoni, A.; Negri, F. Reduced Basis Methods for Partial Differential Equations; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Grepl, M.A.; Maday, Y.; Nguyen, N.C.; Patera, A.T. Efficient reduced-basis treatment of nonaffine and nonlinear partial differential equations. ESAIM Math. Model. Numer. Anal. 2007, 41, 575–605. [Google Scholar] [CrossRef]
- Hinze, M.; Korolev, D. Reduced basis methods for quasilinear elliptic PDEs with applications to permanent magnet synchronous motors. arXiv 2020, arXiv:2002.04288. [Google Scholar]
- Rogg, S.; Trenz, S.; Volkwein, S. Trust-region POD using a-posteriori error estimation for semilinear parabolic optimal control problems. Konstanz. Schr. Math. 2017, 359. Available online: https://kops.uni-konstanz.de/handle/123456789/38240 (accessed on 15 April 2021).
- Zeng, J.; Yu, H. Error estimates of the lumped mass finite element method for semilinear elliptic problems. J. Comput. Appl. Math. 2012, 236, 993–2004. [Google Scholar] [CrossRef]
- Bernreuther, M. RB-Based PDE-Constrained Non-Smooth Optimization. Master’s Thesis, University of Konstanz, Konstanz, Germany, 2019. Available online: http://nbn-resolving.de/urn:nbn:de:bsz:352-2-t4k1djyj77yn3 (accessed on 15 April 2021).





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).