3.1. Privacy-Preserving ART Prediction
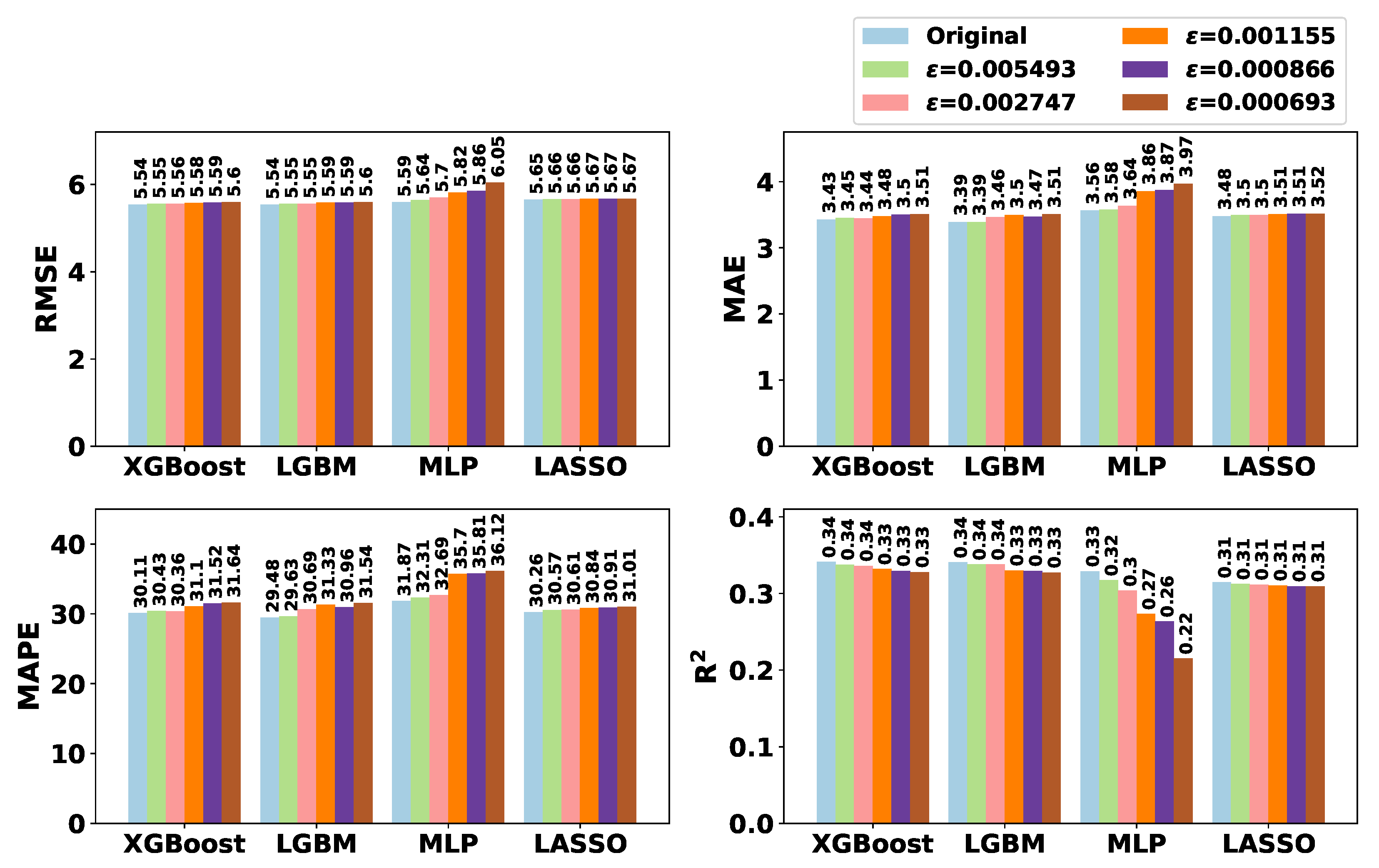
Figure 4 illustrates the impact of the level of GI for each ML model to predict ART according to each metric. As one can notice in this figure, for XGBoost, LGBM, and LASSO, there were minor differences between training models with original location data or sanitized ones. On the other hand, models trained with MLP performed poorly with GI-based data. In addition, by analyzing models trained with original data, while the smaller RMSE for LASSO is about 5.65, for more complex ML-based models, RMSE is less than 5.6, achieving 5.54 with XGBoost and LGBM. In comparison with the results of existing literature, lower
scores and similar RMSE and MAE results were achieved in [
11] to predict ART while using original location data only. With more details,
Table A2 in
Appendix A numerically exhibits the results from
Figure 4.
Indeed, among the four tested models, LGBM and XGBoost achieve similar metric results while favoring the LGBM model. Thus,
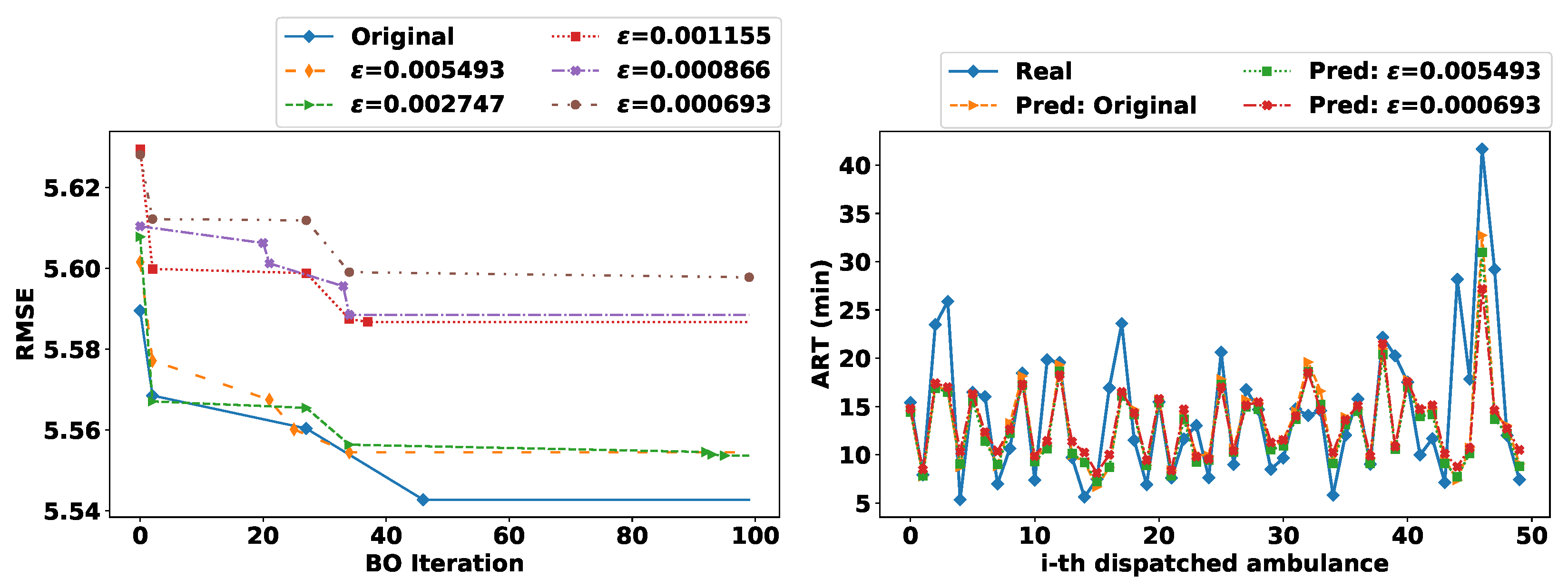
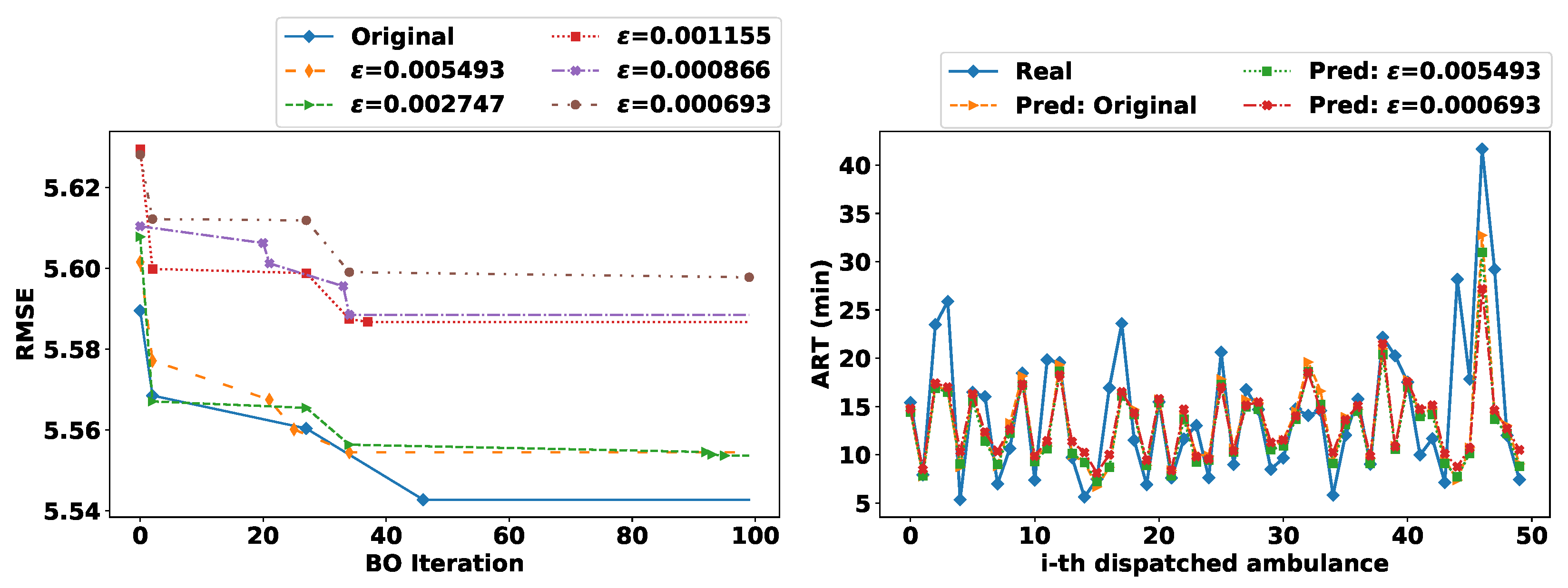
Figure 5 illustrates the BO iterative process for LGBM models trained with original and sanitized data according to the RMSE metric (left-hand plot); and ART prediction results for 50 dispatched ambulances in 2020 out of 8709 ones (right-hand plot) with an LGBM model trained with original data (Pred: original) and with two LGBM models trained sanitized data, i.e., with
(low privacy level) and with
(high privacy level).
As one can notice in the left-hand plot of
Figure 5, once data are sanitized with different levels of
-GI, the hyperparameters optimization via BO is also perturbed. This way, local minimums were achieved in different steps of the BO (i.e., the last marker per curve indicates the local minimum). For instance, even though
is stricter than
, results were still better for the former since, in the last steps of BO, three better local minimums were found. Moreover, prospective predictions were achieved with either original or sanitized data. For instance, in the right-hand plot of
Figure 5, even for the high peak-value of ART around 40 min, LGBM’s prediction achieved some reasonable estimation. Although several features were perturbed due to the sanitization of the emergency scene (e.g., city, zone, etc.), the models could still achieve similar predictions as the model trained with original location data.
Furthermore, in terms of training time, for both original and sanitized datasets, the LASSO method was the fastest to fit our data. On the other hand, MLP models took the longest time to execute than all other methods. Between both decision-tree methods, LGBM models were faster than XGBoost ones. Lastly, the importance of the features, taking into account LASSO coefficients and decision trees’ importance scores were: averaged ART per categorical features (e.g., center, city, hour); OSRM API-based features (i.e., estimated driving distance and estimated travel time); the great-circle distance between the center and the emergency scene; the number of interventions in the previous hour, and the number of interventions still active. Immediately thereafter, it appeared the weather data, which were added as “real-time” features, i.e., using the date of the intervention to retrieve the features. Penultimate, the traffic data, which are indicators provided by [
31] at the beginning of each year and, which might have shown more influence if they had been retrieved in real time. Finally, it appeared some temporal variables such as weekend indicators, start/end of the month, and the day of the year.
3.2. Discussion
The medical literature has mainly focused attention on the analysis of ART [
3,
34,
43] and its association with trauma [
2,
30] and cardiac arrest [
1,
4,
6], for example. To reduce ART, some works propose reallocation of ambulances [
5,
44], operation demand forecasting [
5,
7,
8,
22,
45], travel time prediction [
12], simulation models [
35,
46], and EMS response time predictions [
11,
12]. The work in [
11] propose a real-time system for predicting ARTs for the San Francisco fire department, which closely relates to this paper. The authors processed about
million EMS calls using original location data to predict ART using four ML models, namely linear regression, linear regression with elastic net regularization, decision-tree regression, and random forest. However, no privacy-preserving experiment was performed because the main objective of their paper was proposing a scalable, ML-based, and real-time system for predicting ART. Besides, we also included weather data that the authors in [
11] did not consider in their system, which could help to recognize high ARTs due to bad weather conditions, for example.
Currently, many private and public organizations collect and analyze data about their associates, customers, and patients. Because most of these data are personal and confidential (e.g., location), there is a need for privacy-preserving techniques for processing and using these data. Location privacy is an emergency research topic [
13,
14] due to the ubiquity of LBSs. Within our context, using and/or sharing the exact location of an emergency raises many privacy issues. For instance, the Seattle Fire Department [
47] displays live EMS response information with the precise location and reason for the incident. Although the intention of some fire departments [
11,
47] is laudable, there are many ways for (mis)using this information, which can jeopardize users’ privacy. Even if the intervention’s
reason could be an indicator of the call urgency, we did not consider this sensitive attribute in our data analysis nor privacy-preserving prediction models. This is because, for SDIS 25, the ARTs limits are defined by the zone [
9]. Additionally, we also did not include the victims’ personal data (e.g., gender, age) in our predictions or analysis since, during the calls, the operator may not acquire such information, e.g., when a third party activates the SDIS 25 for unidentified victims. This way, we focused our attention on the
location privacy of each intervention.
To address location privacy, the authors in [
15] proposed the concept of GI, which is based on a generalization [
29] of the state-of-the-art DP [
16] model. As highlighted in [
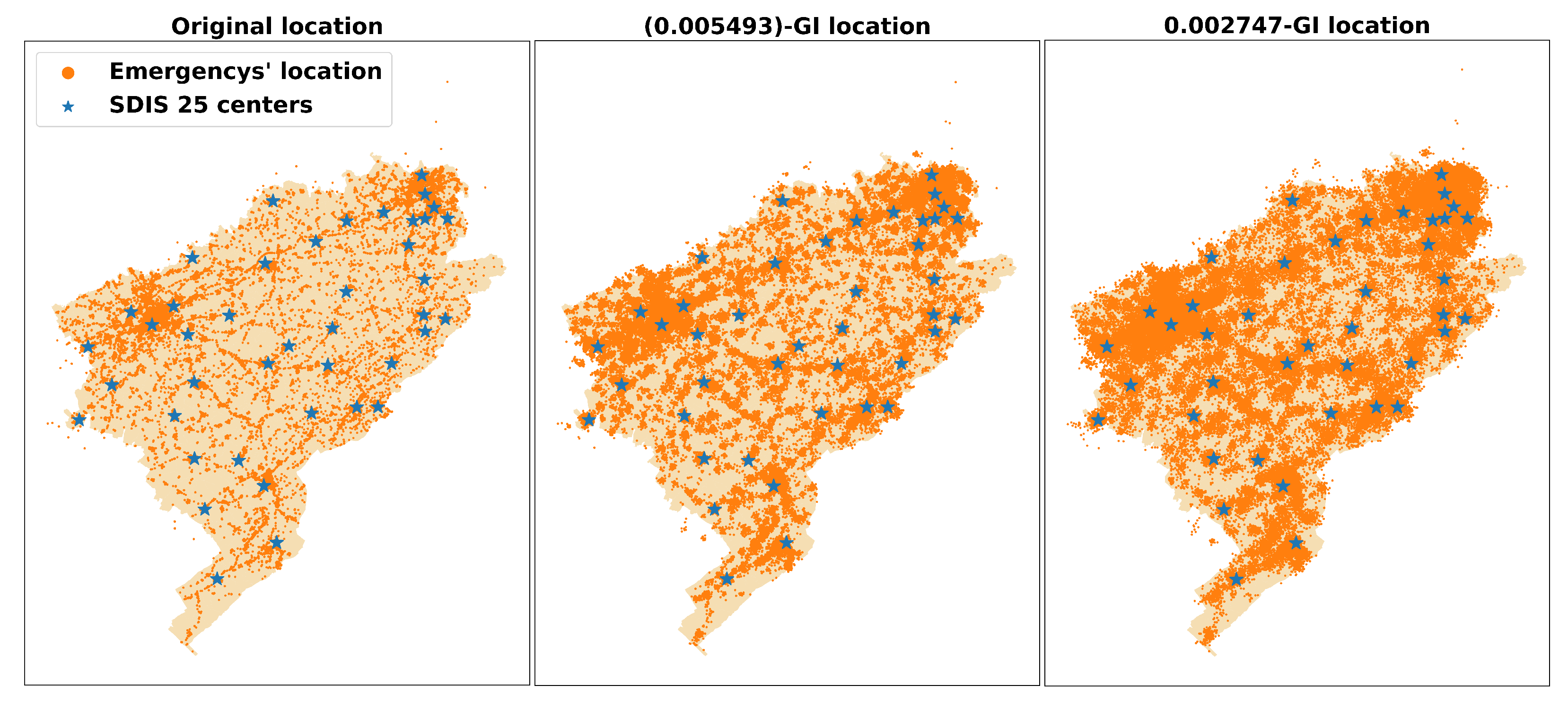
15], attackers in LSBs may have side information about the user’s reported location, e.g., knowing that the user is probably visiting the Eiffel Tower instead of swimming in the Seine river. However, this does not apply in our context because someone may have drowned, and EMS had to intervene. Similarly, even for the dataset with intermediate (and high) privacy in which locations are spread out in the Doubs region (
cf. map with
-GI location in
Figure 3), someone may have been lost in the forest and EMS would have to interfere. For these reasons, using (or sharing datasets with) approximate emergency locations (e.g., sanitized with GI) is a prospective direction since many locations are possible emergency scenes. Indeed, we are not interested in hiding the emergency’s location completely since some approximate information is required to retrieve other features (e.g., city, zone, estimated distance) to use for predicting ART.
Moreover, learning and extracting meaningful patterns from data, e.g., through ML, play a key role in advancing and understanding several behaviors. However, on the one hand, storing and/or sharing original personal data with trusted curators may still lead to data breaches [
48] and/or misuse of data, which compromises users’ privacy. On the other hand, training ML models with original data can also leak private information. For instance, in [
18] the authors evaluate how some models can memorize sensitive information from the training data, and in [
19], the authors investigate how ML models are susceptible to membership inference attacks. To address these problems, some works [
7,
20,
21,
22,
23,
24,
25,
49] propose to train ML models with sanitized data, which is also known as input perturbation [
26] in the privacy-preserving ML literature.
Input perturbation-based ML and GI are linked directly with local DP [
26] in which each sample is sanitized independently, either by the user during the data collection process or by the trusted curator, which aims to preserve privacy of each data sample. This way, data are protected from data leakage and are more difficult to reconstruct, for example. In [
23,
49], the authors investigate how input perturbation through applying controlled Gaussian noise on data samples can guarantee
-DP on the final ML model. This means, since ML models are trained with perturbed data, there is a perturbation on the gradient and on the final parameters of the model too.
In this paper, rather than Gaussian noise, the emergency scenes were sanitized with Algorithm 1, i.e., adding two-dimensional Laplacian noise centered at the exact user location
. In addition, this sanitization also perturbs other associated and calculated features such as: city, district, zone (e.g., urban or not), great-circle distance, estimated driving distance, and estimated travel time (
cf. Table 3). As well as the optimization of hyperparameters, i.e., once data are differentially private, one can apply any function on it and, therefore, we also noticed perturbation on the BO procedure. Yet, as shown in the results, prospective ART predictions were achieved with either original or sanitized data. Furthermore, even with a high level of sanitization (
) there was a good privacy-utility trade-off. According to [
50], if the mean absolute percentage error (i.e., MAPE) is greater than 20% and less than 50%, the forecast is reasonable, which is the results we have in this paper with MAPE around 30%.
Lastly, some limitations of this work are described in the following. We analyzed ARTs using the data and operation procedures of only one EMS in France, namely SDIS 25. Although it may represent a sufficient number of samples, other public and private organizations are also responsible for EMS calls, e.g., the SAMU (Urgent Medical Aid Service in English) analyzed in [
46]. Moreover, there is the possibility of human error when using the mechanical system to report (i.e., record) the arrival on-scene time “
ADate”. For instance, the crew may have forgotten to record status on arrival and may have registered later, or conversely, where the crew may have accidentally recorded before arriving at the location. Additionally, it is noteworthy to mention that the arrival on-scene does not mean arriving at the victim’s side, e.g., in some cases the real location of a victim is at the
n-th stage of a building as investigated in [
43].







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}