A PSO-SVM for Burst Header Packet Flooding Attacks Detection in Optical Burst Switching Networks


Abstract
:1. Introduction
2. Background
2.1. Related Work
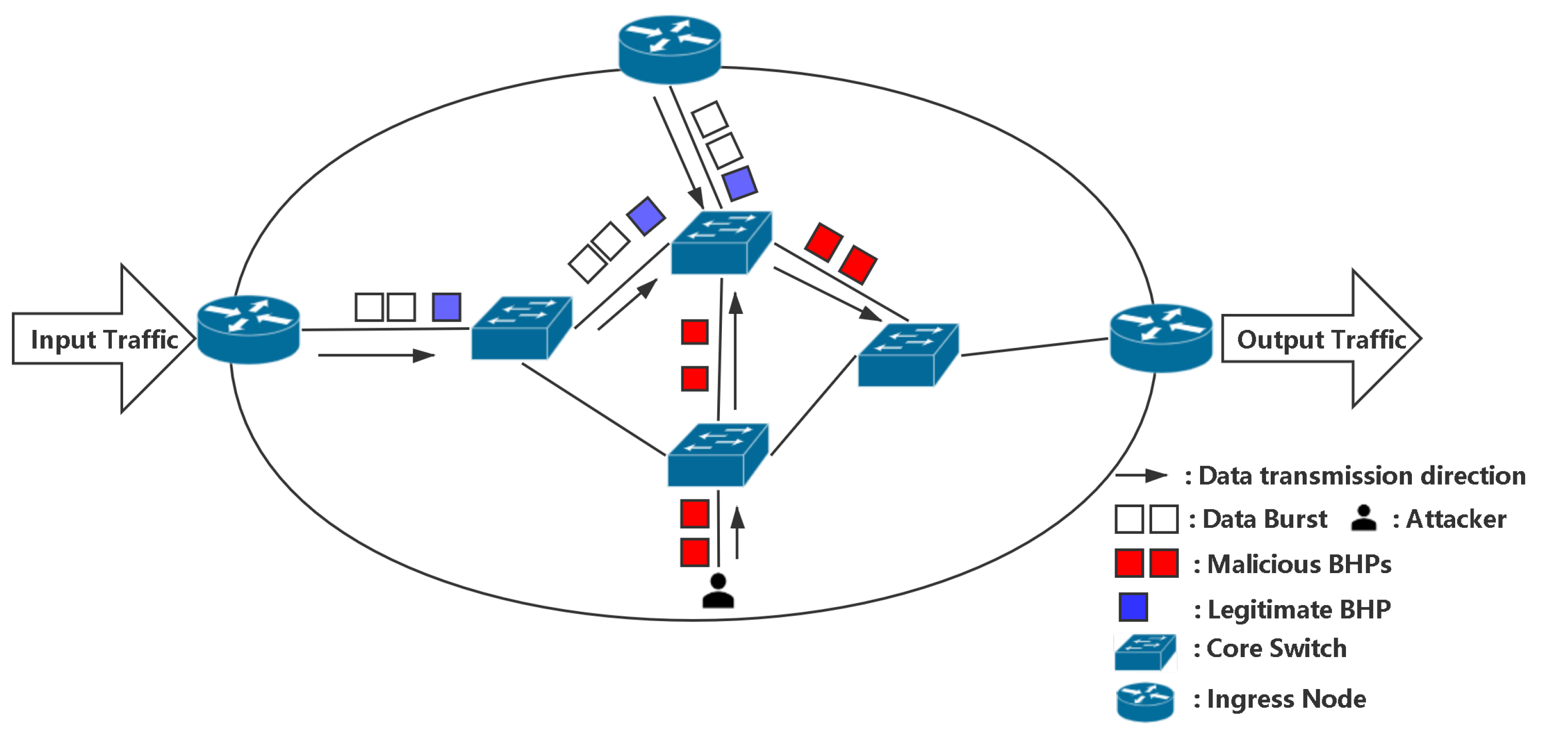
2.2. Problem Definition
2.3. Packet Data
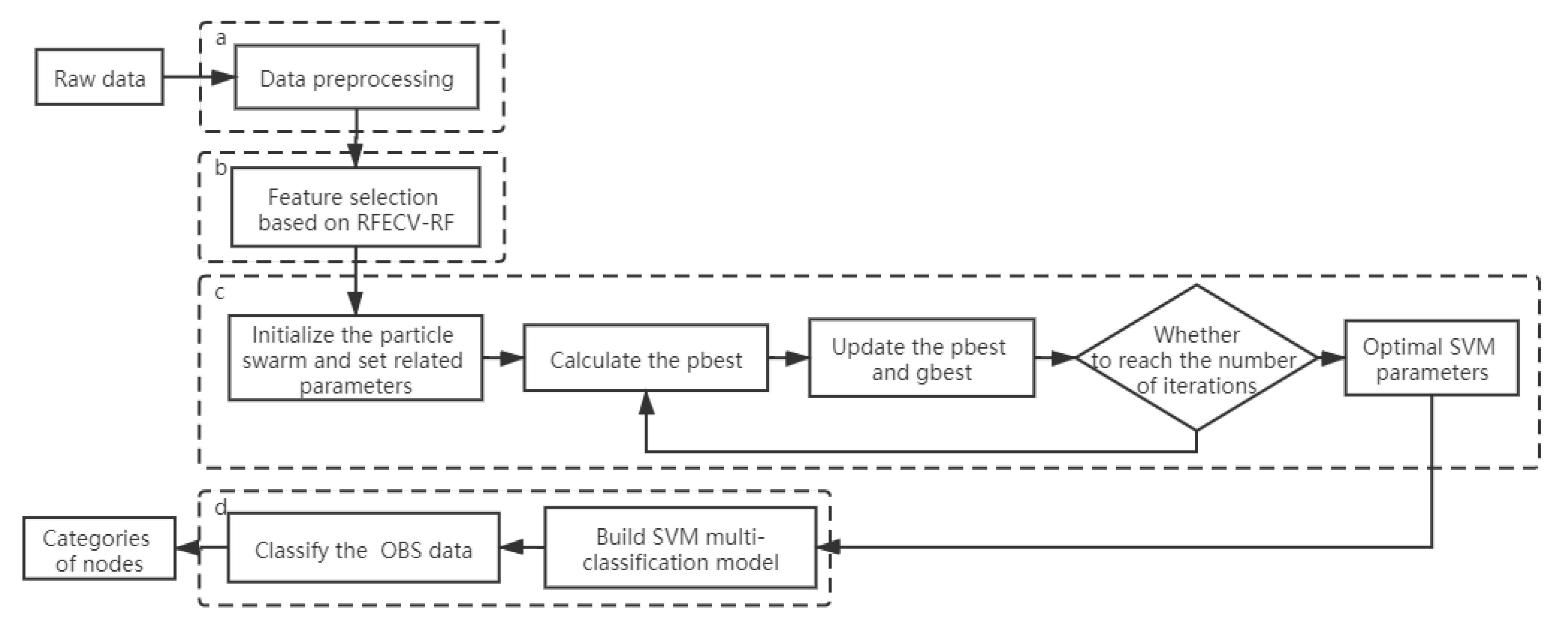
3. The Proposed PSO-SVM Model for the BHP Flooding Attack
- Data preprocessing. The data is preprocessed accordingly so that our model can recognize it.
- Feature selection. Feature selection is performed on the data using RFECV-RF to find the most suitable subset of data for model classification based on classification accuracy values and cross-validation. The optimal feature set is segmented for model training and testing.
- Parameter tuning. PSO is introduced to find the two parameters of the given SVM model by finding the optimal combination of parameters.
- The OBS network intrusion detection model. The best combination of parameters is input to train the data, the trained model is tested against the test set, output the predicted result, and use the evaluation indexes, confusion matrix, etc. to evaluate the PSO-SVM model.
3.1. Data Preprocessing
3.2. Feature Selection
3.3. Support Vector Machine
3.4. Optimization of the SVM by PSO
4. Experiments and Results
4.1. Experimental Settings
4.1.1. Dataset
4.1.2. PSO Experimental Setting
4.1.3. Evaluation Indexes
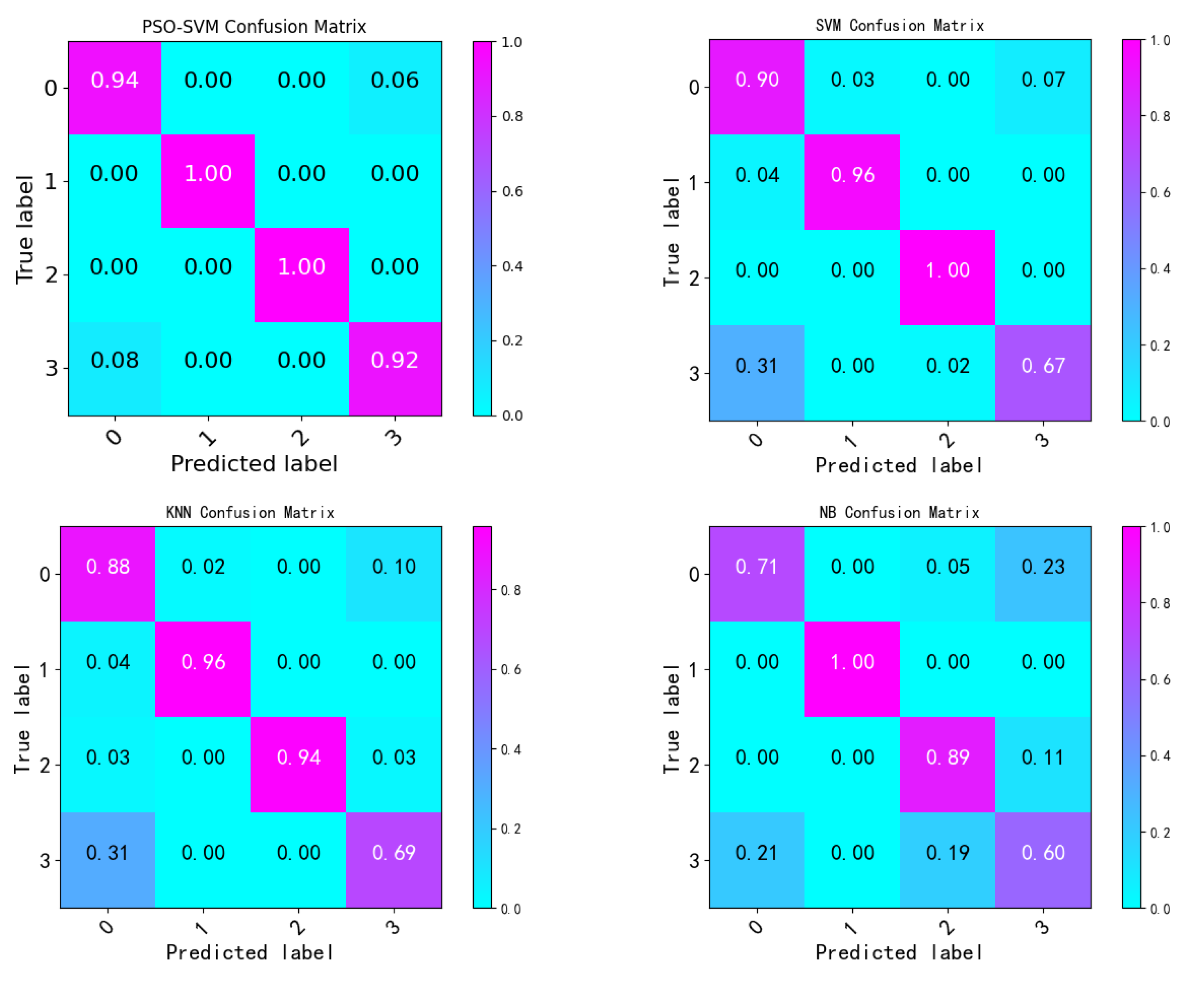
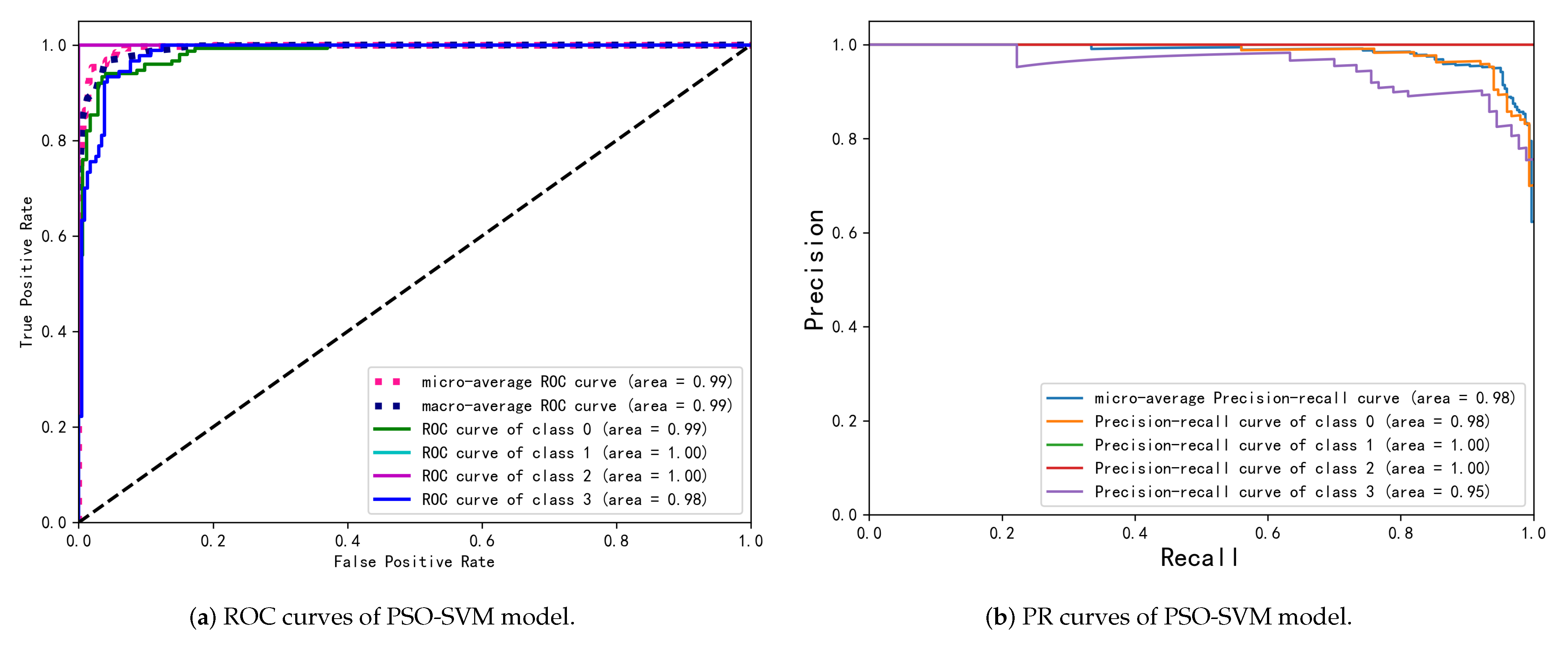
4.2. Experimental Results
4.3. Discussion
4.3.1. The Feature Selection
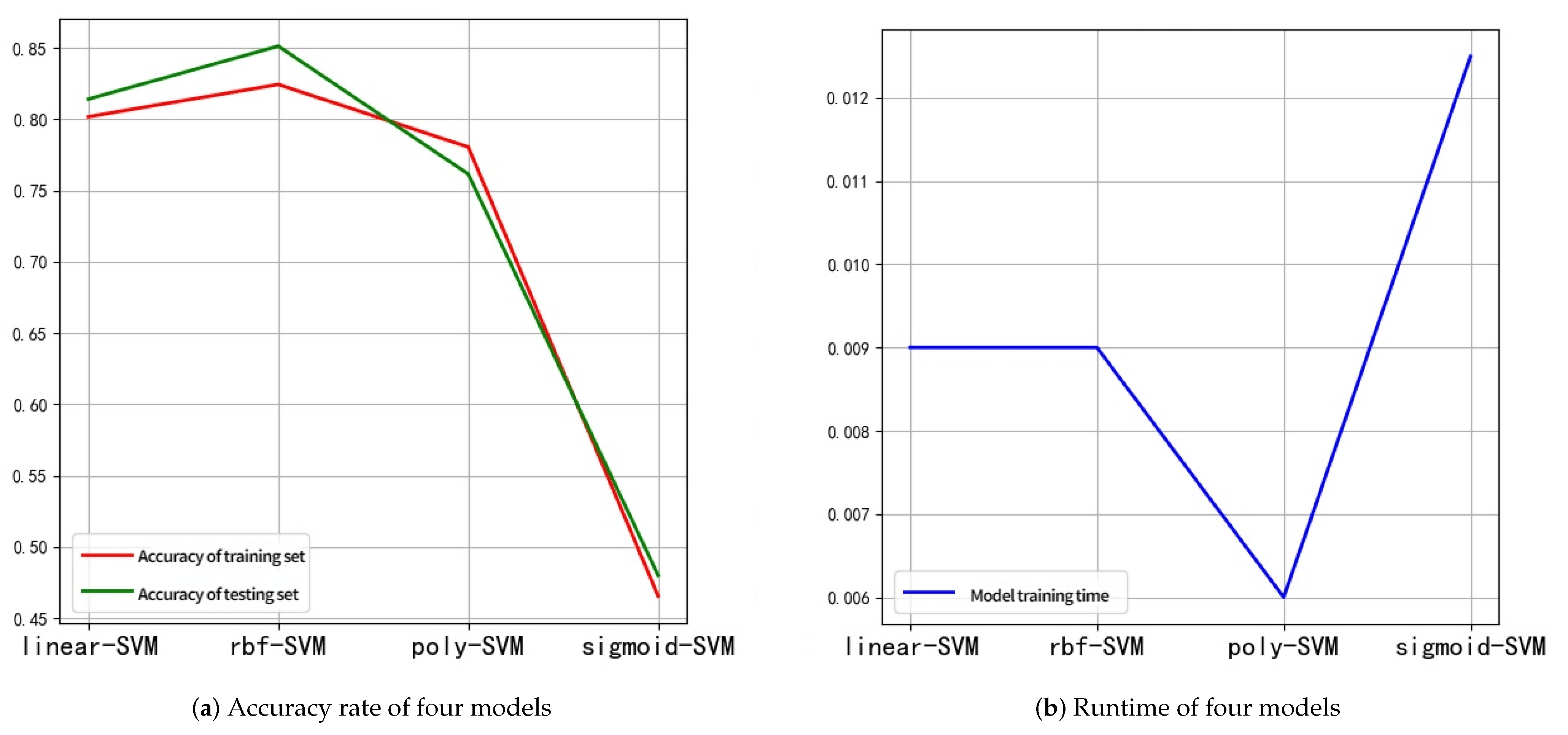
4.3.2. Kernel Function Selection
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Qiao, C.; Yoo, M. Optical burst switching (OBS)—A new paradigm for an Optical Internet. J. High Speed Netw. 1999, 8, 69–84. [Google Scholar]
- Al-Shargabi, M.A.; Shaikh, A.; Ismail, A.S. Enhancing the quality of service for real time traffic over Optical Burst Switching (OBS) networks with ensuring the fairness for other traffics. PLoS ONE 2016, 11, e0161873. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dumych, S. Study on traffic aggregation algorithms for edge nodes of optical burst switching network. In Proceedings of the 2016 13th International Conference on Modern Problems of Radio Engineering, Telecommunications and Computer Science (TCSET), Lviv, Ukraine, 23–26 February 2016; pp. 947–949. [Google Scholar]
- Oh, S.Y.; Hong, H.H.; Kang, M. A data burst assembly algorithm in optical burst switching networks. Etri J. 2002, 24, 311–322. [Google Scholar] [CrossRef]
- Sliti, M.; Hamdi, M.; Boudriga, N. A novel optical firewall architecture for burst switched networks. In Proceedings of the 2010 12th International Conference on Transparent Optical Networks, Munich, Germany, 27 June–1 July 2010; pp. 1–5. [Google Scholar]
- Sliti, M.; Boudriga, N. BHP flooding vulnerability and countermeasure. Photonic Netw. Commun. 2015, 29, 198–213. [Google Scholar] [CrossRef]
- Sreenath, N.; Muthuraj, K.; Kuzhandaivelu, G.V. Threats and vulnerabilities on TCP/OBS networks. In Proceedings of the 2012 International Conference on Computer Communication and Informatics, Coimbatore, India, 10–12 January 2012; pp. 1–5. [Google Scholar]
- Eddy, W. TCP SYN Flooding Attacks and Common Mitigations. Technical Report, RFC 4987. 2007. Available online: http://www.rfc-editor.org/info/rfc4987 (accessed on 1 June 2021). [CrossRef] [Green Version]
- Rajab, A.; Huang, C.T.; Al-Shargabi, M.; Cobb, J. Countering burst header packet flooding attack in optical burst switching network. In International Conference on Information Security Practice and Experience; Springer: Berlin/Heidelberg, Germany, 2016; pp. 315–329. [Google Scholar]
- Coulibaly, Y.; Al-Kilany, A.A.I.; Abd Latiff, M.S.; Rouskas, G.; Mandala, S.; Razzaque, M.A. Secure burst control packet scheme for Optical Burst Switching networks. In Proceedings of the 2015 IEEE International Broadband and Photonics Conference (IBP), Bali, Indonesia, 23–25 April 2015; pp. 86–91. [Google Scholar]
- Rajab, A.; Huang, C.T.; Al-Shargabi, M. Decision tree rule learning approach to counter burst header packet flooding attack in optical burst switching network. Opt. Switch. Netw. 2018, 29, 15–26. [Google Scholar] [CrossRef]
- Jayaraj, A.; Venkatesh, T.; Murthy, C.S.R. Loss classification in optical burst switching networks using machine learning techniques: Improving the performance of tcp. IEEE J. Sel. Areas Commun. 2008, 26, 45–54. [Google Scholar] [CrossRef]
- Mata, J.; de Miguel, I.; Duran, R.J.; Merayo, N.; Singh, S.K.; Jukan, A.; Chamania, M. Artificial intelligence (AI) methods in optical networks: A comprehensive survey. Opt. Switch. Netw. 2018, 28, 43–57. [Google Scholar] [CrossRef]
- Ibrahim, L.M. Anomaly network intrusion detection system based on distributed time-delay neural network (DTDNN). J. Eng. Sci. Technol. 2010, 5, 457–471. [Google Scholar]
- Hasan, M.Z.; Hasan, K.Z.; Sattar, A. Burst header packet flood detection in optical burst switching network using deep learning model. Procedia Comput. Sci. 2018, 143, 970–977. [Google Scholar] [CrossRef]
- Boutaba, R.; Salahuddin, M.A.; Limam, N.; Ayoubi, S.; Shahriar, N.; Estrada-Solano, F.; Caicedo, O.M. A comprehensive survey on machine learning for networking: Evolution, applications and research opportunities. J. Internet Serv. Appl. 2018, 9, 16. [Google Scholar] [CrossRef] [Green Version]
- De Sanctis, M.; Bisio, I.; Araniti, G. Data mining algorithms for communication networks control: Concepts, survey and guidelines. IEEE Netw. 2016, 30, 24–29. [Google Scholar] [CrossRef]
- Gu, R.; Yang, Z.; Ji, Y. Machine learning for intelligent optical networks: A comprehensive survey. J. Netw. Comput. Appl. 2020, 157, 102576. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Pan, Y.; Chen, J.; Ouyang, Y.; Rao, J.; Jiang, Q. Indicator element selection and geochemical anomaly mapping using recursive feature elimination and random forest methods in the Jingdezhen region of Jiangxi Province, South China. Appl. Geochem. 2020, 122, 104760. [Google Scholar] [CrossRef]
- Li, X.; Chen, W.; Zhang, Q.; Wu, L. Building auto-encoder intrusion detection system based on random forest feature selection. Comput. Secur. 2020, 95, 101851. [Google Scholar] [CrossRef]
- Hu, J.; Zeng, J.; Wei, L.; Yan, F. Improving the Diagnosis Accuracy of Hydrothermal Aging Degree of V2O5/WO3–TiO2 Catalyst in SCR Control System Using an GS–PSO–SVM Algorithm. Sustainability 2017, 9, 611. [Google Scholar] [CrossRef] [Green Version]
- Du, J.; Liu, Y.; Yu, Y.; Yan, W. A prediction of precipitation data based on support vector machine and particle swarm optimization (PSO-SVM) algorithms. Algorithms 2017, 10, 57. [Google Scholar] [CrossRef]
- Rajab, A. Burst Header Packet (BHP) Flooding Attack on Optical Burst Switching (OBS) Network Data Set. University of California Irvine Data Repository. 2017. Available online: https://archive.ics.uci.edu/ml/datasets/Burst+Header+Packet+%28BHP%29+flooding+attack+on+Optical+Burst+Switching+%28OBS%29+Network (accessed on 1 June 2021).
- National Chiao Tung University. NCTUns. Available online: http://nsl.csie.nctu.edu.tw/nctuns.html (accessed on 1 June 2021).
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Attribute | Description |
|---|---|---|
| D1 | Node | The label of the sending node. |
| D2 | Utilized Bandwidth Rate | Normalize the bandwidth rate that can be reserved. |
| D3 | Packet Drop Rate | The ratio of the number of lost packets per node to the data sent. |
| D4 | Full Bandwidth | This is the initially reserved bandwidth allocated by the user to each node. |
| D5 | Average Delay Time Per Sec | This is the average delay of each node per second. |
| D6 | Percentage Of Lost Packet Rate | Percentage of packet loss per node. |
| D7 | Percentage Of Lost Byte Rate | Byte loss rate per node. |
| D8 | Packet Received Rate | The number of data packets received by each node per second on the reserved bandwidth. |
| D9 | Used Bandwidth | The amount of bandwidth that each node can use in the allocated bandwidth (D4). |
| D10 | Lost Bandwidth | The amount of bandwidth lost by each node in the allocated bandwidth (D4). |
| D11 | Packet Size Byte | The byte packet size allocated for each node. |
| D12 | Packet Transmitted | The total number of data packets transmitted by each node per second in the allocated bandwidth (D4). |
| D13 | Packet Received | The total number of packets received by each node per second in the allocated bandwidth (D4). |
| D14 | Packet Lost | The total number of packets lost per second per node in the lost bandwidth (D10). |
| D15 | Transmitted Byte | Bytes transferred per second per node. |
| D16 | Received Byte | Number of bytes received by each node per second in the reserved bandwidth. |
| D17 | 10-Run-AVG-Drop-Rate | The average value of the packet loss rate (D3) obtained after 10 simulation runs. |
| D18 | 10-Run-AVG-Bandwidth-Use | The average value of used bandwidth (D9) obtained after 10 simulation runs. |
| D19 | 10-Run-Delay | The average delay time obtained after 10 simulation runs. |
| D20 | Node Status | Divide node status into behaving, not behaving, and potentially not behaving. |
| D21 | Flood Status | Flood rate of each node. |
| D22 | Class | Four categories of nodes, Block, No Block (NB), NB-No Block, NB-Wait. |
| D1 | D2 | D3 | D4 | D5 | D6 | D7 | D8 | D9 | D10 | D11 |
|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 0.623081 | 0.387489 | 200 | 0.000426 | 38.715738 | 38.748895 | 0.612511 | 124.61625 | 75.38375 | 1440 |
| 9 | 0.861525 | 0.151567 | 500 | 0.000961 | 15.152253 | 15.156679 | 0.848433 | 430.7625 | 69.2375 | 1440 |
| 3 | 0.559238 | 0.450597 | 100 | 0.000704 | 44.993369 | 45.059682 | 0.549403 | 55.92375 | 44.07625 | 1440 |
| 9 | 0.867038 | 0.146063 | 1000 | 0.000633 | 14.598556 | 14.606306 | 0.853937 | 867.0375 | 132.9625 | 1440 |
| 3 | 0.262688 | 0.741437 | 300 | 0.000473 | 74.103056 | 74.143659 | 0.258563 | 78.80625 | 221.19375 | 1440 |
| 9 | 0.542763 | 0.465611 | 900 | 0.000406 | 46.55864 | 46.5611 | 0.534389 | 488.48625 | 411.51375 | 1440 |
| D12 | D13 | D14 | D15 | D16 | D17 | D18 | D19 | D20 | D21 | D22 |
|---|---|---|---|---|---|---|---|---|---|---|
| 18,096 | 11,084 | 7012 | 2.605824 × 10 | 1.59096 × 10 | 0.290617 | 0.560773 | 0.000422 | P NB | 0.063936 | NB-No Block |
| 45,188 | 38,339 | 6849 | 6.507072 × 10 | 5.520816 × 10 | 0.103065 | 0.85291 | 0.000913 | B | 0 | No Block |
| 9048 | 4971 | 4077 | 1.302912 × 10 | 7,158,240 | 0.3019 | 0.492129 | 0.000683 | P NB | 0.06038 | NB-No Block |
| 90,324 | 77,131 | 13,193 | 1.3006656 × 10 | 1.1106864 × 10 | 0.091862 | 0.841026 | 0.000627 | B | 0 | No Block |
| 27,092 | 7005 | 20,087 | 3.901248 × 10 | 1.00872 × 10 | 0.533834 | 0.225911 | 0.001336 | NB | 0.400376 | Block |
| 81,276 | 43,433 | 37,843 | 1.1703744 × 10 | 6.254352 × 10 | 0.35852 | 0.466776 | 0.00656 | P NB | 0.136238 | NB-Wait |
| Parameters | Values |
|---|---|
| Population iterations | 10 |
| Population size | 100 |
| Local learning factor | 0.2 |
| Global learning factor | 0.5 |
| Inertia weight | 0.5 |
| Penalty factor | 0.01 < <100 |
| Kernel function parameter | 0.01 < <10 |
| Evaluation Index | Format |
|---|---|
| Accuracy | |
| Precision | |
| Recall (TPR) | |
| F1 score |
| Models | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| PSO-SVM (our) | 0.950 | 0.963 | 0.966 | 0.965 |
| SVM | 0.854 | 0.882 | 0.881 | 0.878 |
| KNN | 0.845 | 0.886 | 0.868 | 0.875 |
| NB | 0.743 | 0.748 | 0.800 | 0.763 |
| DT [11] | 0.87 | 0.593 | 0.574 | 0.583 |
| DCNN [15] | 0.99 | 0.99 | 0.99 | 0.99 |
| D1 | D2 | D3 | D4 | D5 | D6 | D7 | D8 | D9 | D10 |
|---|---|---|---|---|---|---|---|---|---|
| False | True | True | False | True | True | True | True | True | True |
| D12 | D13 | D14 | D15 | D16 | D17 | D18 | D19 | D20 | D21 |
|---|---|---|---|---|---|---|---|---|---|
| False | True | True | False | True | True | True | True | False | True |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Liao, X.; Shi, H. A PSO-SVM for Burst Header Packet Flooding Attacks Detection in Optical Burst Switching Networks. Photonics 2021, 8, 555. https://doi.org/10.3390/photonics8120555
Liu S, Liao X, Shi H. A PSO-SVM for Burst Header Packet Flooding Attacks Detection in Optical Burst Switching Networks. Photonics. 2021; 8(12):555. https://doi.org/10.3390/photonics8120555
Chicago/Turabian StyleLiu, Susu, Xun Liao, and Heyuan Shi. 2021. "A PSO-SVM for Burst Header Packet Flooding Attacks Detection in Optical Burst Switching Networks" Photonics 8, no. 12: 555. https://doi.org/10.3390/photonics8120555
APA StyleLiu, S., Liao, X., & Shi, H. (2021). A PSO-SVM for Burst Header Packet Flooding Attacks Detection in Optical Burst Switching Networks. Photonics, 8(12), 555. https://doi.org/10.3390/photonics8120555