
Use of Multivariate Statistics in the Processing of Data on Wine Volatile Compounds Obtained by HS-SPME-GC-MS




Abstract
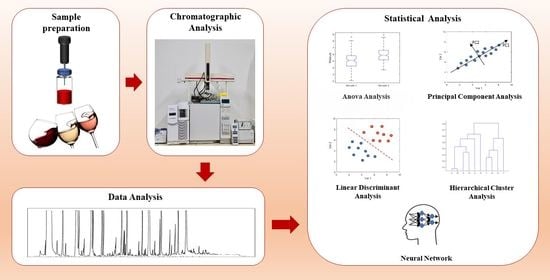
1. Introduction
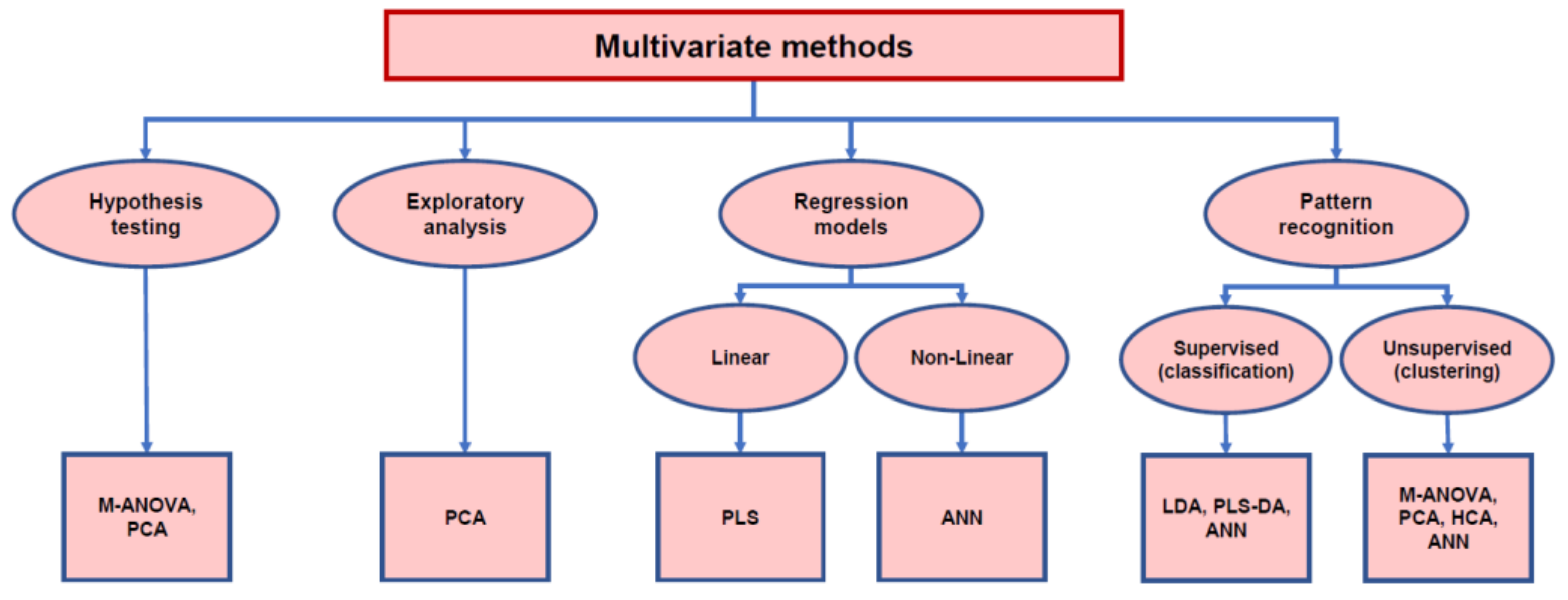
2. Processing of HS-SPME-GC-MS Data on Wine Volatiles by Multivariate Statistics
2.1. ANOVA-MANOVA
2.2. Principal Component Analysis
2.3. Hierarchical Cluster Analysis
2.4. Linear Discriminant Analysis
2.5. Partial Least Squares
2.6. Artificial Neural Networks
3. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ribéreau-Gayon, P.; Dubourdie, D.; Donèche, B.; Lovaud, A. Handbook of Enolgy; John Wiley Sons, Ltd.: Hoboken, NJ, USA, 2006; ISBN 0-470-01034-7. [Google Scholar]
- Alanon, M.E.; Perez-Coello, M.S.; Marina, M.L. Wine science in the metabolomics era. TRAC-Trend Anal. Chem. 2015, 74, 1–20. [Google Scholar] [CrossRef]
- Diez-Simon, C.; Mumm, R.; Hall, R.D. Mass spectrometry-based metabolomics of volatiles as a new tool for understanding aroma and flavour chemistry in processed food products. Metabolomics 2019, 15, 41. [Google Scholar] [CrossRef] [PubMed]
- Cozzolino, D.; Cynkar, W.U.; Shah, N.; Dambergs, R.G.; Smith, P.A. A brief introduction to multivariate methods in grape and wine analysis. Int. J. Wine Res. 2009, 1, 123–130. [Google Scholar] [CrossRef]
- Bordiga, M.; Rinaldi, M.; Locatelli, M.; Piana, G.; Travaglia, F. Characterization of Muscat wines aroma evolution using comprehensive gas chromatography followed by a post-analytic approach to 2D contour plots comparison. Food Chem. 2013, 140, 57–67. [Google Scholar] [CrossRef]
- Ruiz-Bejarano, M.J.; Castro-Mejías, R.; Rodríguez-Dodero, M.C.; García-Barroso, C. Study of the content in volatile compounds during the aging of sweet Sherry wines obtained from grapes cv. Muscat and fermented under different conditions. Eur. Food Res. Technol. 2013, 237, 905–922. [Google Scholar] [CrossRef]
- Zhang, M.; Pan, Q.; Yan, G.; Duan, C. Using headspace solid phase microextraction for analysis of aromatic compounds during alcoholic fermentation of red wine. Food Chem. 2011, 125, 743–749. [Google Scholar] [CrossRef]
- Ziółkowska, A.; Wąsowicz, E.; Jeleń, H.H. Differentiation of wines according to grape variety and geographical origin based on volatiles profiling using SPME-MS and SPME-GC/MS methods. Food Chem. 2016, 213, 714–720. [Google Scholar] [CrossRef]
- Panighel, A.; Flamini, R. Applications of solid-phase microextraction and gas chromatography/mass spectrometry (SPME-GC/MS) in the study of grape and wine volatile compounds. Molecules 2014, 19, 21291–21309. [Google Scholar] [CrossRef]
- Licen, S.; Muzic, E.; Briguglio, S.; Tolloi, A.; Barbieri, P.; Giungato, P. Derivatized volatile organic compound characterization of Friulano wine from Collio (Italy–Slovenia) by HS-SPME-GC-MS and discrimination from other varieties by chemometrics. Br. Food J. 2021, 123, 2844–2855. [Google Scholar] [CrossRef]
- Tavares, A.; Mafra, G.; Carasek, E.; Micke, G.A.; Vitali, L. Determination of five 3-alkyl-2-methoxypyrazines employing HS-SPME-GC-NPD: Application in evaluation of off-flavor of South American wines. J. Food Compos. Anal. 2022, 105, 104237. [Google Scholar] [CrossRef]
- Bordiga, M.; Coisson, J.D.; Travaglia, E.; Piana, G.; Arlorio, M. HS-SPME/GCxGC/TOF-MS: A powerful tool for off-flavors identification in Italian muscat-based wines. Spec. Issue Czech J. Food Sci. 2009, 27, S227. [Google Scholar]
- Briones-Labarca, V.; Perez-Wom, M.; Habib, G.; Giovagnoli-Vicuña, C.; Cañas-Sarazua, R.; Tabilo-Munizaga, G.; Salazar, F.N. Oenological and quality characteristic on young white wines (sauvignon blanc): Effects of high hydrostatic pressure processing. J. Food Qual. 2017, 2017, 8524073. [Google Scholar] [CrossRef]
- Qian, X.; Jia, F.; Cai, J.; Shi, Y.; Duan, C.; Lan, Y. Characterization and Evolution of Volatile Compounds of Cabernet Sauvignon Wines from Two Different Clones during Oak Barrel Aging. Foods 2022, 11, 74. [Google Scholar] [CrossRef] [PubMed]
- Issa-Issa, H.; Lipan, L.; Cano-Lamadrid, M.; Nemś, A.; Corell, M.; Calatayud-García, P.; Carbonell-Barrachina, A.A.; López-Lluch, D. Effect of Aging Vessel (Clay-Tinaja versus Oak Barrel) on the Volatile Composition, Descriptive Sensory Profile, and Consumer Acceptance of Red Wine. Beverages 2021, 7, 35. [Google Scholar] [CrossRef]
- Revi, M.; Badeka, A.; Kontakos, S.; Kontominas, M.G. Effect of packaging material on enological parameters and volatile compounds of dry white wine. Food Chem. 2014, 152, 331–339. [Google Scholar] [CrossRef]
- Verzera, A.; Merlino, M.; Cincotta, F.; Prestia, O.; Sparacio, A.; Sparla, S.; Condurso, C. Varietal Aromas of Fortified Wines from Different Moscato Var.(Vitis vinifera L.) under the Same Pedoclimatic Conditions. Foods 2021, 10, 2549. [Google Scholar] [CrossRef] [PubMed]
- Castro, R.; Natera, R.; Durán, E.; García-Barroso, C. Application of solid phase extraction techniques to analyse volatile compounds in wines and other enological products. Eur. Food Res. Technol. 2008, 228, 1–18. [Google Scholar] [CrossRef]
- Spietelun, A.; Pilarczyk, M.; Kloskowski, A.; Namieśnik, J. Current trends in solid-phase microextraction (SPME) fibre coatings. Chem. Soc. 2010, 39, 4524–4537. [Google Scholar] [CrossRef]
- Andujar-Ortiz, I.; Moreno-Arribas, M.V.; Martín-Álvarez, P.J.; Pozo-Bayón, M.A. Analytical performance of three commonly used extraction methods for the gas chromatography–mass spectrometry analysis of wine volatile compounds. J. Chromatogr. A 2009, 1216, 7351–7357. [Google Scholar] [CrossRef]
- Munck, L.; Norgaard, L.; Engelsen, S.B.; Bro, R.; Andersson, C.A. Chemometrics in food science: A demonstration of the feasibility of a highly exploratory, inductive evaluation strategy of fundamental scientific significance. Chemom. Intell. Lab. Syst. 1998, 44, 31–60. [Google Scholar] [CrossRef]
- Francis, I.L.; Høj, P.B.; Dambergs, R.G.; Janik, L.; Cynkar, W.U.; Gishen, M. Analysis of Grapes and Wine by Near Infrared Spectroscopy. J. Near Infrared Spectrosc. 2006, 14, 279–289. [Google Scholar] [CrossRef]
- Geladi, P. Chemometrics in spectroscopy. Part I. Classical chemometrics. Spectrochim. Acta Part B 2003, 58, 767–782. [Google Scholar] [CrossRef]
- Wise, B.M.; Gallagher, N.B. The process chemometrics approach to process monitoring and fault detection. J. Process Control 1996, 6, 329–348. [Google Scholar] [CrossRef]
- Rapp, A. Volatile flavour of wine: Correlation between instrumental analysis and sensory perception. Nahrung 1998, 42, 351–363. [Google Scholar] [CrossRef]
- Spranger, M.I.; Clımaco, M.C.; Sun, B.; Eiriz, N.; Fortunato, C.; Nunes, A.M.; Conceição Leandro, M.; Avelar, M.L.; Belchior, A.P. Differentiation of red winemaking technologies by phenolic and volatile composition. Anal. Chim. Acta 2004, 513, 151–161. [Google Scholar] [CrossRef]
- Santos, J.P.; Arroyo, T.; Aleixandre, M.; Lozano, J.; Sayago, I.; García, M.; Fernández, M.J.; Arés, L.; Gutiérrez, J.; Cabellos, J.M.; et al. A comparative study of sensor array and GC–MS: Application to Madrid wines characterization. Sens. Actuators B Chem. 2004, 102, 299–307. [Google Scholar] [CrossRef]
- Falqué, E.; Fernández, E.; Dubourdieu, D. Volatile components of Loureira, Dona Branca, and Treixadura wines. J. Agric. Food Chem. 2002, 50, 538–543. [Google Scholar] [CrossRef]
- Weldegergis, B.T.; Crouch, A.M. Analysis of volatiles in Pinotage wines by stir bar sorptive extraction and chemometric profiling. J. Agric. Food Chem. 2008, 56, 10225–10236. [Google Scholar] [CrossRef]
- Herraiz, T.; Reglero, G.; Herraiz, M.; Martin-Alvarez, P.J.; Cabezudo, M.D. The influence of the yeast and type of culture on the volatile composition of wines fermented without sulfur dioxide. Am. J. Enol. Vitic. 1990, 41, 313–318. [Google Scholar]
- Mateo, J.J.; Jiménez, M.; Pastor, A.; Huerta, T. Yeast starter cultures affecting wine fermentation and volatiles. Food Res. J. 2001, 34, 307–314. [Google Scholar] [CrossRef]
- Tredoux, A.; de Villiers, A.; Majek, P.; Lynen, F.; Crouch, A.; Sandra, P. Stir bar sorptive extraction combined with GC-MS analysis and chemometric methods for the classification of South African wines according to the volatile composition. J. Agric. Food Chem. 2008, 56, 4286–4296. [Google Scholar] [CrossRef]
- Lubes, G.; Goodarzi, M. Analysis of Volatile Compounds by Advanced Analytical Techniques and Multivariate Chemometrics. Chem. Rev. 2017, 117, 6399–6422. [Google Scholar] [CrossRef]
- Noble, A.C.; Ebeler, S.E. Use of multivariate statistics in understanding wine flavour. Food Rev. Int. 2002, 18, 1–20. [Google Scholar] [CrossRef]
- Marengo, E.; Aceto, M.; Maurino, V. Classification of Nebbiolo-based wines from Piedmont (Italy) by means of solid-phase microextraction–gas chromatography–mass spectrometry of volatile compounds. J. Chromatogr. A 2001, 943, 123–137. [Google Scholar] [CrossRef]
- Moret, I.; Scarponi, G.; Cescon, P. Chemometric characterization and classification of five Venetian white wines. J. Agric. Food Chem. 1994, 42, 1143–1153. [Google Scholar] [CrossRef]
- Kaufmann, A. Multivariate statistics as a classification tool in the food laboratory. J. AOAC Int. 1997, 80, 665–675. [Google Scholar] [CrossRef]
- Aires De Sousa, J. Verifying wine origin: A neural network approach. Am. J. Enol. Vitic. 1996, 47, 410–414. [Google Scholar]
- Pati, S.; Tufariello, M.; Crupi, P.; Coletta, A.; Grieco, F.; Losito, I. Quantification of volatile compounds in wines by HS-SPME-GC/MS: Critical issues and use of multivariate statistics in method optimization. Processes 2021, 9, 662. [Google Scholar] [CrossRef]
- Zhang, J.; Li, L.; Gao, N.; Wang, D.; Gao, Q.; Jiang, S. Feature extraction and selection from volatile compounds for analytical classification of Chinese red wines from different varieties. Anal. Chim. Acta 2010, 662, 137–142. [Google Scholar] [CrossRef]
- Pérez-Prieto, L.J.; López-Roca, J.M.; Martínez-Cutillas, A.; Pardo Mínguez, F.; Gómez-Plaza, E. Maturing wines in oak barrels. Effects of origin, volume, and age of the barrel on the wine volatile composition. J. Agric. Food Chem. 2002, 50, 3272–3276. [Google Scholar] [CrossRef]
- Moreno-Olivares, J.D.; Giménez-Bañón, M.J.; Paladines-Quezada, D.F.; Gómez-Martínez, J.C.; Cebrián-Pérez, A.; Fernández-Fernández, J.I.; Bleda-Sámchez, J.A.; Gil-Muñoz, R. Aromatic Characterization of New White Wine Varieties Made from Monastrell Grapes Grown in South-Eastern Spain. Molecules 2020, 25, 3917. [Google Scholar] [CrossRef] [PubMed]
- Aragoni, P.; Atienza, J.; Climent, M.D. Influence of Clarification, Yeast Type, and Fermentation Temperature on the Organic Acid and Higher Alcohols of Malvasia and Muscatel Wines. Am. J. Enol. Vitic. 1998, 49, 211–219. [Google Scholar]
- Naes, T.; Isaksson, T.; Fearn, T.; Davies, T. A User-friendly Guide to Multivariate Calibration and Classification; NIR Publications: Chichester, UK, 2002. [Google Scholar]
- Călugăr, A.; Corbean, D.; Pop, N.; Bunea, C.I.; Babeș, A.C.; Iliescu, M.; Bora, F.D.; Muresan, I.C. The Economic Impact of Paraffin Type and Substrate Mixture on the Production of Grafted Vines—Case Study Muscat Ottonel. Agronomy 2020, 10, 1584. [Google Scholar] [CrossRef]
- Canuti, V.; Cantu, A.; Picchi, M.; Lerno, L.A.; Tanabe, C.K.; Zanoni, B.; Heymann, H.; Ebeler, S.E. Evaluation of the Intrinsic and Perceived Quality of Sangiovese Wines from California and Italy. Foods 2020, 9, 1088. [Google Scholar] [CrossRef] [PubMed]
- Arvanitoyannis, I.S.; Katsota, M.N.; Psarra, E.P.; Soufleros, E.H.; Kallithraka, S. Application of quality control methods for assessing wine authenticity: Use of multivariate analysis (chemometrics). Trends Food Sci. Technol. 1999, 10, 321–336. [Google Scholar] [CrossRef]
- Villano, C.; Lisanti, M.T.; Gambuti, A.; Vecchio, R.; Moio, L.; Frusciante, L.; Aversano, R.; Carputo, D. Wine varietal authentication based on phenolics, volatiles and DNA markers: State of the art, perspectives and drawbacks. Food Control 2017, 80, 1–10. [Google Scholar] [CrossRef]
- Sivertsen, H.K.; Holen, B.; Nicolaysen, F.; Risvik, E. Classification of French red wines according to their geographical origin by the use of multivariate analyses. J. Sci. Food Agric. 1999, 79, 107–115. [Google Scholar] [CrossRef]
- Sudol, P.E.; Galletta, M.; Tranchida, P.Q.; Zoccali, M.; Mondello, L.; Synovec, R.E. Untargeted profiling and differentiation of geographical variants of wine samples using headspace solid-phase microextraction flow-modulated comprehensive two-dimensional gas chromatography with the support of tile-based Fisher ratio analysis. J. Chromatogr. A 2022, 1662, 462735. [Google Scholar] [CrossRef]
- Vilanova, M.; Genisheva, Z.; Masa, A.; Oliveira, J.M. Correlation between volatile composition and sensory properties in Spanish Albariño wines. Microchem. J. 2010, 95, 240–246. [Google Scholar] [CrossRef]
- Poggesi, S.; Dupas de Matos, A.; Longo, E.; Chiotti, D.; Pedri, U.; Eisenstecken, D.; Boselli, E. Chemosensory Profile of South Tyrolean Pinot Blanc Wines: A Multivariate Regression Approach. Molecules 2021, 26, 6245. [Google Scholar] [CrossRef]
- Tufariello, M.; Chiriatti, M.A.; Grieco, F.; Perrotta, C.; Capone, S.; Rampino, P.; Tristezza, M.; Mita, G.; Grieco, F. Influence of autochthonous Saccharomyces cerevisiae strains on volatile profile of Negroamaro wines. LWT Food Sci. Technol. 2014, 58, 35–48. [Google Scholar] [CrossRef]
- Tufariello, M.; Rizzuti, A.; Palombi, L.; Ragone, R.; Capozzi, G.; Gallo, V.; Mastrorilli, P.; Grieco, F. Non-targeted metabolomic approach as a tool to evaluate the chemical profile of sparkling wines fermented with autochthonous yeast strains. Food Control 2021, 126, 108099. [Google Scholar] [CrossRef]
- Petrozziello, M.; Bonello, F.; Asproudi, A.; Nardi, T.; Tsolakis, C.; Bosso, A.; Di Martino, V.; Fugaro, M.; Mazzei, R.A. Xylovolatile Fingerprint of Wines Aged in Barrels or with Oak Chips. In Proceedings of the 11th OenoIVAS International Symposium, Bordeaux, France, 25–28 June 2019; Volume 54, pp. 513–522. [Google Scholar] [CrossRef]
- Casassa, L.F.; Ceja, G.M.; Vega-Osorno, A.; du Fresne, F.; Llodrá, D. Detailed chemical composition of Cabernet Sauvignon wines aged in French oak barrels coopered with three different stave bending techniques. Food Chem. 2021, 340, 127573. [Google Scholar] [CrossRef]
- De Maceo Morais, S.; De sousa Galvao, M.; Souza Olegarlo, L.; Moreira de Carvalho, L.; Elias Pereira, G.; Leite de Andrade Lima, L.; Honorato da Silva, F.L.; Suely Madruga, M. Identification of Chemical Markers of Commercial Tropical Red Wine Candidates for the São Francisco Valley Geographical Indication. Food Anal. Methods 2022, 1–19. [Google Scholar] [CrossRef]
- Maioli, F.; Picchi, M.; Guerrini, L.; Parenti, A.; Domizio, P.; Andrenelli, L.; Zanoni, B.; Canuti, V. Monitoring of Sangiovese Red Wine Chemical and Sensory Parameters along One-Year Aging in Different Tank Materials and Glass Bottle. ACS Food Sci. Technol. 2022, 2, 221–239. [Google Scholar] [CrossRef]
- Sanchez, R.; Rodriguez-Nogales, J.M.; Fernandez-Fernandez, E.; Gonzalez, M.R.; Medina-Trujillo, L.; Martin, P. Volatile composition and sensory properties of wines from vineyards affected by iron chlorosis. Food Chem. 2022, 369, 130850. [Google Scholar] [CrossRef] [PubMed]
- Dall’Asta, C.; Cirlini, M.; Morini, E.; Galaverna, G. Brand-dependent volatile fingerprinting of Italian wines from Valpolicella. J. Chromatogr. A 2011, 1218, 7557–7565. [Google Scholar] [CrossRef]
- Wu, Y.; Duan, S.; Zhao, L.; Gao, Z.; Luo, M.; Song, S.; Xu, W.; Zhang, C.; Ma, C.; Wang, S. Aroma characterization based on aromatic series analysis in table grapes. Sci. Rep. 2016, 6, 31116. [Google Scholar] [CrossRef]
- Stój, A.; Czernecki, T.; Domagala, D.; Targoński, Z. Application of volatile compound analysis for distinguishing between red wines from Poland and from other European countries. S. Afr. J. Enol. Vitic. 2017, 38, 245–263. [Google Scholar] [CrossRef][Green Version]
- Valentin, L.; Barroso, L.P.; Barbosa, R.M.; de Paulo, G.A.; Castro, I.A. Chemical typicality of South American red wines classified according to their volatile and phenolic compounds using multivariate analysis. Food Chem. 2020, 302, 125340. [Google Scholar] [CrossRef]
- Costa, G.P.; Nicolli, K.P.; Welke, J.E.; Manfroi, V.; Zini, C.A. Volatile Profile of Sparkling Wines Produced with the Addition of Mannoproteins or Lees before Second Fermentation Performed with Free and Immobilized Yeasts. J. Braz. Chem. Soc. 2018, 29, 1866–1875. [Google Scholar] [CrossRef]
- Berna, A.Z.; Trowell, S.; Clifford, D.; Cynkar, W.; Cozzolino, D. Geographical origin of Sauvignon Blanc wines predicted by mass spectrometry and metal oxide based electronic nose. Anal. Chim. Acta 2009, 648, 146–152. [Google Scholar] [CrossRef]
- Recamales, A.F.; Gallo, V.; Hernanz, D.; González-Miret, M.L.; Heredia, F.J. Effect of time and storage conditions on major volatile compounds of Zalema white wine. J. Food Qual. 2011, 34, 100–110. [Google Scholar] [CrossRef]
- Ubeda, C.; Callejón, R.M.; Troncoso, A.M.; Peña-Neira, A.; Morales, M.L. Volatile profile characterisation of Chilean sparkling wines produced by traditional and Charmat methods via sequential stir bar sorptive extraction. Food Chem. 2016, 207, 261–271. [Google Scholar] [CrossRef] [PubMed]
- Jurado, J.M.; Ballesteros, O.; Alcázar, A.; Pablos, F.; Martin, M.J.; Vilchez, J.L.; Navalon, A. Differentiation of certified brands of origins of Spanish white wines by HS-SPME-GC and chemometrics. Anal. Bioanal. Chem. 2008, 390, 961–970. [Google Scholar] [CrossRef]
- Guillén, D.A.; Palma, M.; Natera, R.; Romero, R.; Barroso, C.G. Determination of the age of sherry wines by regression techniques using routine parameters and phenolic and volatile compounds. J. Agric. Food Chem. 2005, 53, 2412–2417. [Google Scholar] [CrossRef]
- Bertuccioli, M.; Rosi, I.; Picchi, M.; Viviani, C. Prediction of Wine Sensory Aroma Attributes by Wine Headspace Volatile Compounds. In Proceedings of the Fourth International Symposium on Cool Climate Viticulture and Enology, Rochester, NY, USA, 16–20 July 1996; pp. 333–337. [Google Scholar]
- Campo, E.; Ferreira, V.; Escudero, A.; Cacho, J. Prediction of the wine properties related to grape variety from dynamic-headspace gas chromatography–olfactometry data. J. Agric. Food Chem. 2005, 53, 5682–5690. [Google Scholar] [CrossRef]
- Aznar, M.; Lopez, R.; Cacho, J.F.; Ferreira, V. Prediction of aged red wine aroma properties from aroma chemical composition. Partial least squares regression models. J. Agric. Food Chem. 2003, 51, 2700–2707. [Google Scholar] [CrossRef]
- Perestrelo, R.; Silva, C.; Câmara, J.S. A useful approach for the differentiation of wines according to geographical origin based on global volatile patterns. J. Sep. Sci. 2014, 37, 1974–1981. [Google Scholar] [CrossRef]
- Hu, B.; Cao, Y.; Zhu, J.; Xu, W.; Wu, W. Analysis of metabolites in chardonnay dry white wine with various inactive yeasts by 1 H NMR spectroscopy combined with pattern recognition analysis. AMB Express 2019, 9, 1–14. [Google Scholar] [CrossRef]
- Oliveira, A.S.; Furtado, I.; Bastos, M.d.L.; de Pinho, P.G. The influence of different closures on volatile composition of a white wine. Food Packag. Shelf Life 2020, 23, 100465. [Google Scholar] [CrossRef]
- Karabagias, I.K.; Karabagias, V.K.; Badeka, A.V. Volatilome of white wines as an indicator of authenticity and adulteration control using statistical analysis. Aust. J. Grape Wine Res. 2021, 27, 269–279. [Google Scholar] [CrossRef]
- Khalafyan, A.A.; Temerdashev, Z.A.; Yakuba, Y.F.; Guguchkina, T.I. Computer analysis of the sensory qualities of red wines as a method to optimize their blend formulation. Heliyon 2019, 5, e01602. [Google Scholar] [CrossRef] [PubMed]
- Masoum, S.; Bouveresse, D.J.R.; Vercauteren, J.; Jalali-Heravi, M.; Rutledge, D.N. Discrimination of wines based on 2D NMR spectra using learning vector quantization neural networks and partial least squares discriminant analysis. Anal. Chim. Acta 2006, 558, 144–149. [Google Scholar] [CrossRef]
- Cabrita, M.J.; Aires-De-Sousa, J.; Gomes Da Silva, M.D.R.; Rei, F.; Costa Freitas, A.M. Multivariate statistical approaches for wine classification based on low molecular weight phenolic compounds. Aust. J. Grape Wine Res. 2012, 18, 138–146. [Google Scholar] [CrossRef]
- Agatonovic-Kustrin, S.; Morton, D.W.; Yusof, A.P.M. The use of Fourier transform infrared (FTIR) spectroscopy and artificial neural networks (ANNs) to assess wine quality. Mod. Chem. Appl. 2013, 1, 1–8. [Google Scholar] [CrossRef]
- Kruzlicova, D.; Mocak, J.; Balla, B.; Petka, J.; Farkova, M.; Havel, J. Classification of Slovak white wines using artificial neural networks and discriminant techniques. Food Chem. 2009, 112, 1046–1052. [Google Scholar] [CrossRef]
- Fuentes, S.; Tongson, E.; Torrico, D.D.; Gonzalez Viejo, C. Modeling pinot noir aroma profiles based on weather and water management information using machine learning algorithms: A vertical vintage analysis using artificial intelligence. Foods 2020, 9, 33. [Google Scholar] [CrossRef] [PubMed]
- Baykal, H.; Yildirim, H.K. Application of artificial neural networks (ANNs) in wine technology. Crit. Rev. Food Sci. Nutr. 2013, 53, 415–421. [Google Scholar] [CrossRef] [PubMed]
- Moldes, O.A.; Mejuto, J.C.; Rial-Otero, R.; Simal-Gandara, J. A critical review on the applications of artificial neural networks in winemaking technology. Crit. Rev. Food Sci. Nutr. 2017, 57, 2896–2908. [Google Scholar] [CrossRef]
- Gunning, D.; Aha, D. DARPA’s Explainable Artificial Intelligence (XAI) Program. AI Mag. 2019, 40, 44–58. [Google Scholar] [CrossRef]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A Review of Machine Learning Interpretability Methods. Entropy 2021, 23, 18. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
| Name | Scope | Pros | Cons | Applications |
|---|---|---|---|---|
| M-ANOVA | Hypothesis testing | M-ANOVA allows a deeper analysis than ANOVA in determining changes introduced by a given factor. | It requires a larger number of samples than the number of variables. The extension of the analysis to N factors is more complex. Results can be misleading if the working assumptions are not respected. | Determination of significant differences between wine varieties [40]; characterization of the volatile profile [42]; effects of oak origin, barrel volume, and barrel age [41]; effects of variety, clarification, temperature, and yeast type [43]; descriptive sensory analysis [46]. |
| PCA | Hypothesis testing; Exploratory analysis; Unsupervised classification | Explain multivariate variance by a limited number of factors. It does not suffer the possible multi-collinearity between variables; on the contrary it exploits it. It allows to visualize both the similarity and dissimilarity between samples and the correlation and influence of variables. | Highly dependent on the pre-treatment of the data, e.g., standardization. Sensitive to outliers. The detection of orthogonal (uncorrelated) factors can lead to a misinterpretation of the true cause-effect relationship. Only Euclidean metrics can be considered. | Assessment of the authenticity of wines [47,48]; distinguishing different wines [49]; correlation between volatile composition and sensory properties [51,52]; discrimination of wines produced by selected yeast strains [53]; identification of key-role molecules in aging process [55]; identification of peculiar features in the VOC profile [57]. |
| PLS | Linear regression | It can be used in cases where the number of variables is greater than the number of samples. Handles well any multi-collinearity between variables. | The interpretation of the results is more complex than that of the results of a simple multilinear regression. Results can be poor in the case of non-linear relationships between variables. | Correlation between VOCs and wine ageing [69]; correlations between volatile compounds and sensory descriptors [51]; correlations between chemical data and sensory descriptors [70,71,72]. |
| ANN | Non-linear regression; Supervised classification; Unsupervised classification | Capable to handle strong non-linearity in the underlying model. They are robust to the presence of noise and outliers. They are unaffected by, and indeed exploit, multi-collinearity between variables. | A large number of samples is required. Interpretability of results is more difficult. Validation of results is necessary to exclude overfitting. | Authenticity and traceability assessment [38,77,78]; discrimination between treatments [79] and wines [80]; clustering of wines by varietal origin and vintage; high accuracy in the prediction of aroma profiles from weather and water management information [82]; prediction of wine process parameters [83,84]. |
| LDA | Supervised classification | Interpretability of results is straightforward. | It cannot be used if the number of variables exceeds the number of samples. Conditioned by multi-collinearity. Results can be poor in the case groups are non-linearly separable. | Varietal differentiation from volatile profiles [28]; classification of wines with different aroma profiles [65]; distinguishing among wines with different conditions and times of storage [66]. |
| PLS-DA | Supervised classification | It can be used in cases where the number of variables is greater than the number of samples. Handles well any multi-collinearity between variables | The interpretation of the results is more complex than that of the results of a simple LDA. | Discrimination of selected wines with different geographical origin and type [73]; identification of key volatile metabolites able to discriminate different wines by origin, fermentation, type [74,75,76]. |
| HCA | Unsupervised classification | Straightforward interpretation. It allows different levels of clustering to be evaluated. It allows the use of metrics other than Euclidean to assess similarity and dissimilarity between samples. | The results are highly dependent on the pre-treatment of the data, e.g., whether or not standardization is applied. | Classification of high-quality wines according to their brand based on their volatile fingerprint [60]; fraud prevention by verification of authenticity of wines [62,63,64]. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tufariello, M.; Pati, S.; Palombi, L.; Grieco, F.; Losito, I. Use of Multivariate Statistics in the Processing of Data on Wine Volatile Compounds Obtained by HS-SPME-GC-MS. Foods 2022, 11, 910. https://doi.org/10.3390/foods11070910
Tufariello M, Pati S, Palombi L, Grieco F, Losito I. Use of Multivariate Statistics in the Processing of Data on Wine Volatile Compounds Obtained by HS-SPME-GC-MS. Foods. 2022; 11(7):910. https://doi.org/10.3390/foods11070910
Chicago/Turabian StyleTufariello, Maria, Sandra Pati, Lorenzo Palombi, Francesco Grieco, and Ilario Losito. 2022. "Use of Multivariate Statistics in the Processing of Data on Wine Volatile Compounds Obtained by HS-SPME-GC-MS" Foods 11, no. 7: 910. https://doi.org/10.3390/foods11070910
APA StyleTufariello, M., Pati, S., Palombi, L., Grieco, F., & Losito, I. (2022). Use of Multivariate Statistics in the Processing of Data on Wine Volatile Compounds Obtained by HS-SPME-GC-MS. Foods, 11(7), 910. https://doi.org/10.3390/foods11070910