1. Introduction
Coffee (
Coffea sp.), one of the most important national plantation commodities, is critical to Indonesia because it boosts foreign exchange and social welfare. In 2019, coffee was grown on state plantations (14.5 thousand ha), private plantations (9.71 thousand ha), and smallholder plantations (1.215 million ha), with a total production of 741,657 tons. A total of 359,052 tons of coffee were exported abroad with foreign exchange earnings of USD 883 million [
1]. The five provinces of Sumatra Island, namely South Sumatra, Lampung, Aceh, North Sumatra, and Bengkulu, were the top national coffee producers, followed by East Java on Java Island, and South Sulawesi on Sulawesi Island. Two species of coffee are widely cultivated due to being geographically and climatologically well-suited for growing in Indonesia: Robusta (
Coffea canephora) and Arabica (
Coffea arabica).
Arabica coffee is the most cultivated coffee species, accounting for roughly 70% of the global coffee market’s availability. Arabica coffee is also one of the most popular coffee beverages. It has a rich flavor, is less bitter, and contains low caffeine. Arabica coffee trees grow well at an altitude of 1000–2100 m above sea level with an air temperature of 18–22 °C and an annual rainfall of at least 1500 mm [
2,
3]. Several locations became major Arabica coffee production zones in Indonesia, including Aceh, North Sumatra, Sulawesi, Flores, Bali, and East Java [
4]. The quality of Arabica coffee is affected by a variety of factors, including cultivar genetics, agro-climatic conditions, agricultural practice management, and postharvest processing. The growing locations of Arabica coffee determine its quality regarding physical aspects and chemical composition [
5]. Coffee quality is evaluated based on chemical, organoleptic, and physical attributes. Chemical assessments of coffee beans are complex, owing to the wide range of chemical compounds (nonvolatile and volatile) formed and contained [
6]. Organoleptic properties are related to the aroma, flavor, sweetness, acidity, or overall taste of coffee. Shape, thickness, weight, and color are examples of physical characteristics [
7].
Variability in coffee quality, taste, and body can be caused by the region where the coffee plants are grown. This variability aspect affects the commercial value of the product and has led to fraud such as mislabeling and adulteration. Mislabeling coffee means disguising the right geographical origin of coffee beans, while adulteration mixes and sells less-qualified coffee as pure-graded-expensive coffee [
8]. As a result, coffee producers and industries are concerned about preserving their market reputation to overcome these issues. The examination of coffee beans becomes important to affirm the authenticity of coffee and to declare whether the coffee is, in fact, what it is declared to be or belongs to the defined geographical origin. This outcome will also mean that the coffee quality meets technical/regularity documentation [
9]. In addition to the purposes of trading and purchasing, producers and industries need information that correlates to coffee quality from bean to cup (beverages) [
10].
Several analytical techniques have been used to examine the authenticity of coffee dependent on its chemical composition, such as gas and liquid chromatography, mass spectrometry, and nuclear magnetic resonance spectrometry [
8]. In recent studies, spectroscopic techniques have also been used to ensure accurate outcomes in evaluating the chemical composition and discrimination of agricultural products, including coffee. They are green, simple, rapid, robust, inexpensive, and nondestructive (do not need sample pretreatment) in the evaluation [
8,
11]. Regardless of these methods, several chemometric tools are usually needed to improve a series of classification models, such as principal component analysis (PCA) [
12], hierarchical cluster analysis (HCA) [
13], soft independent modeling by class analogy (SIMCA) [
14], linear discriminant analysis (LDA) [
15], and partial least square discriminant analysis (PLS-DA) [
16]. The effective models can generate classification accuracy close to 100% [
17]. The use of these methods for coffee authenticity in recent studies has gained the best accomplishment accuracy according to the geographical origins of Indonesian coffee in the form of green beans [
8,
18,
19], roasted beans [
20,
21], and powder [
22].
Artificial neural networks (ANNs) are classified as supervised learning in which a certain number of groups are determined based on feature data and labeled datasets trained to produce correct results [
23,
24]. Inspired by the functional characteristics of human brains, ANNs are able to work such complex functions, including learning, recognition, classification, and decision-making [
25,
26]. ANNs are a simplified model of biological neural networks, where billions of neurons are interconnected, organized, and processed any information provided. The neurons in ANNs are organized in layers, namely (1) an input layer, where the data are fed, (2) one or more hidden layers, where the learning process takes place, and (3) an output layer, where the decision is generated [
25,
27]. The structure of this network is a variant of the original perceptron model proposed by Rosenblat in 1950 and is mentioned as multilayer perceptron [
28]. Multilayer perceptron (MLP) is a feed-forward neural network where the information is propagated through the network feed-forwardly from the input layer to the output layer [
27,
29]. Every neuron in a layer is connected to all neurons in the next layer (not inter-connected in the same layer). MLP also often uses a back-propagation algorithm to handle errors generated during the forward pass. The algorithm feeds the losses backwardly through the network by improving the weights and bias.
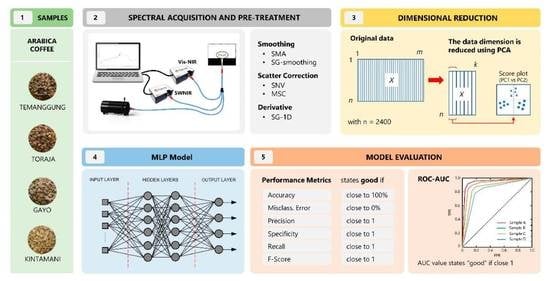
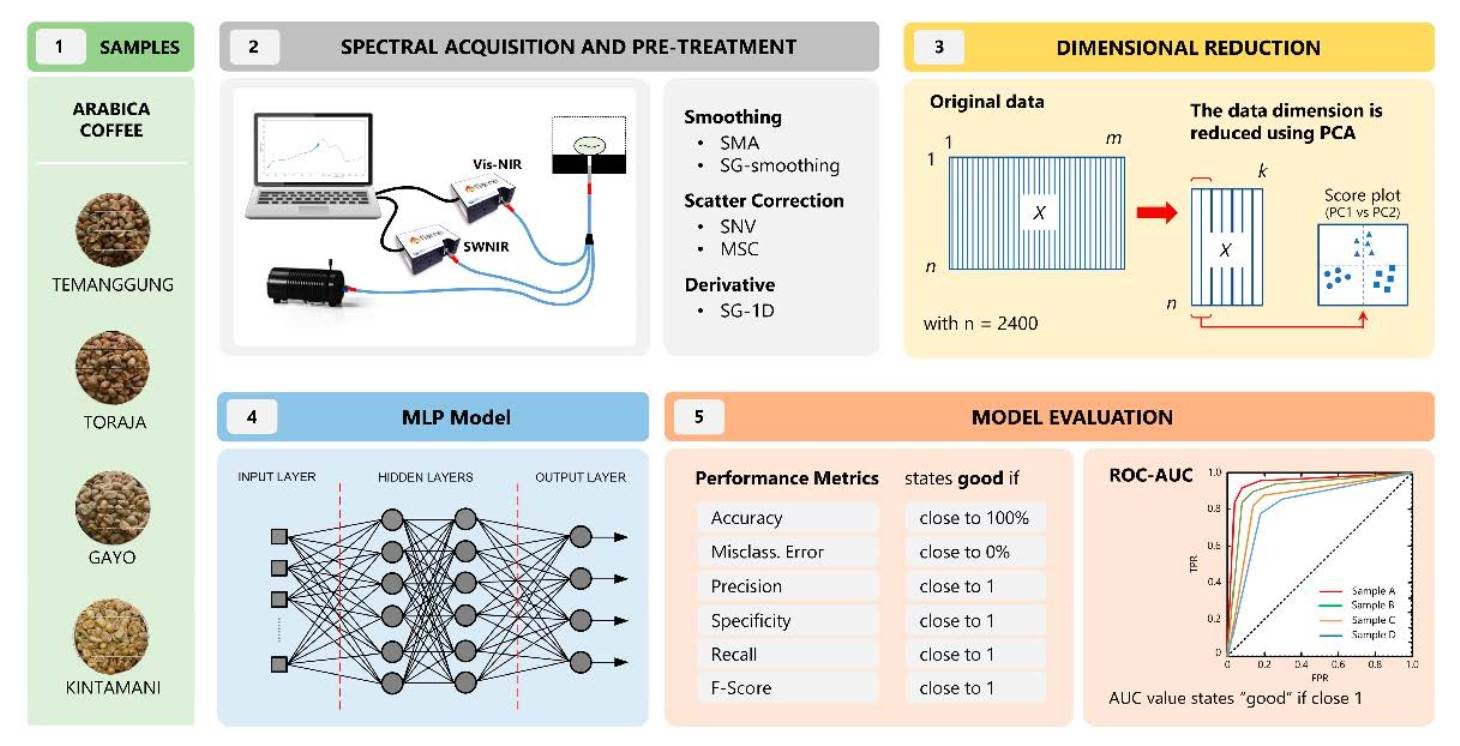
This study aimed to develop a classifier for authenticating coffee beans using a combination of a dimensional reduction technique, principal component analysis (PCA), and a nonlinear model, artificial neural network (ANN). The green coffee samples were from the same species, Arabica, and were grown in different regions of Indonesia, including Temanggung (East Java), Toraja (South Sulawesi), Gayo (Aceh), and Kintamani (Bali). Coffees from these origins were regarded as extensively cultivated in coffee plantations, top-graded, and widely exported abroad. PCA was employed to obtain the most important information, decrease the dimensionality of the spectroscopic data, and express that information as a dataset called principal components (PCs) [
30]. The PCs scores were used as input for the MLP model. An ANN based on multilayer perceptron (MLP) was used in this study, which was a powerful learning system with superior pattern recognition ability [
24,
25]. The use of an MLP model to discriminate food and agricultural products dependent on spectroscopic techniques has been reported in several studies [
25,
26]. Two spectrometers will be used in this work, including a visible to near-infrared (Vis–NIR) spectrometer (400–1000 nm) and a shortwave near-infrared (SWNIR) spectrum (970–1630 nm). Several spectral pretreatment methods were employed to lessen noise and remove the light scattering effect in raw spectra [
31].
2. Materials and Methods
2.1. Material Preparation
Arabica green beans were purchased from trusted local markets in Indonesia and harvested in 2022. The samples were collected from various locations, including Temanggung (Middle Java), Toraja (South Sulawesi), Gayo (Aceh), and Kintamani (Bali). All beans were from full-washed coffee processing. The beans (100 g each) were cleaned manually to remove endocarp/parchment and dirt and separate them from uniform and damaged beans. Before the spectral acquisition, the samples were placed in plastic boxes at controlled temperature of 25–28 °C to maintain the coffee quality.
2.2. Spectral Acquisition and Pre-Processing
The reflectance spectra were obtained using a Vis–NIR spectrometer (Flame-T-VIS–NIR Ocean optics, Orlando, FL, USA, 400–1000 nm) and an NIR spectrometer (Flame-NIR Ocean optics, Orlando, FL, USA, 970–1630 nm). A tungsten halogen light (360–2400 nm, HL-2000-HP-FHSA Ocean Optics, Orlando, FL, USA, nominal bulb power 20 W, typical output power 8.4 mW) and a reflectance fiberoptic probe (QR400-7 VIS–NIR Ocean Optics, Orlando, FL, USA) were used in both spectrometers. A black box was used during spectral measurements to eliminate light interference from external sources. The distance between the samples and the sensor probe was 5 mm. Prior to spectral acquisition of each sample, white-dark reference spectra were measured, one from a white-background ceramic (WS-1, Ocean Optics, Orlando, FL, USA) and the dark reference came from the off-light source of the instrument system. Coffee spectra were collected using OceanView 1.6.7 software (Ocean Insight, Orlando, FL, USA) with an integration time of 1600 ms and a boxcar width of 1. In order to ensure the accuracy of spectral data acquisition, both spectrometers were preheated for 15 min before testing to maintain the instrument’s internal system stability, and a self-check was carried out to see if the instrument worked normally. A total of 2400 spectral data points of green coffee beans were collected from 4 origins × 600 beans. The raw spectral data were stored in CSV format.
This study used raw and preprocessed spectra for the classification model. Several techniques were carried out to attain precise information from spectroscopic measurements [
32]. The simple moving average (SMA) and Savitzky–Golay (SG) filters were employed to denoise and smooth the spectral information. The number of points to be averaged in the spectrum at the SMA filter was 50 for Vis–NIR and 5 for SWNIR. The SG smoothing (SGS) and first derivatives (SG-1D), polyorder = 2, with a window size of 50 (Vis–NIR) and 5 (SWNIR), were also used. The multiplicative scatter correction (MSC) and standard normal variate (SNV) were used to deal with scattering disturbance by eliminating baseline effects caused by translation and offset in the spectrum.
2.3. Data Dimensional Reduction
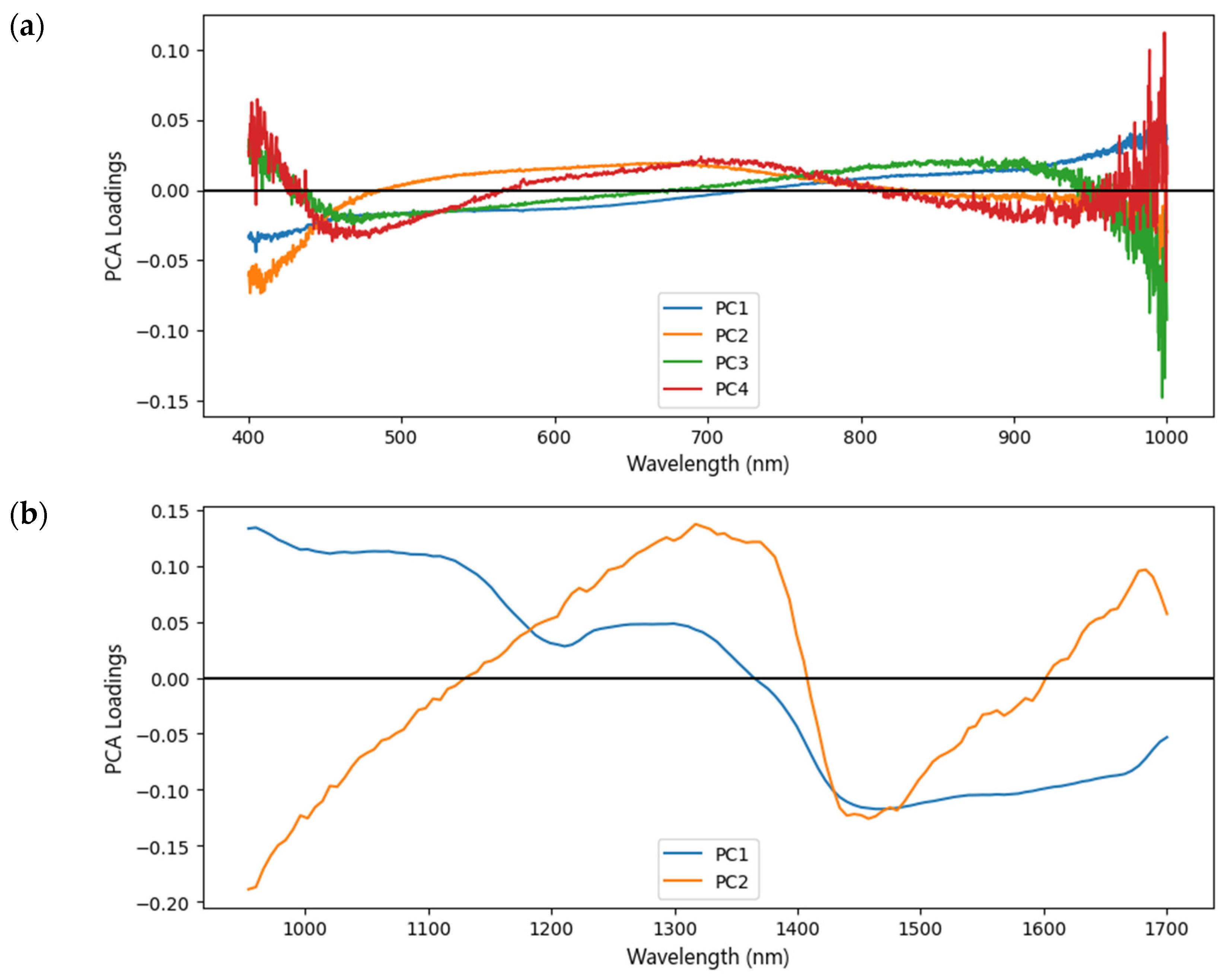
PCA was used to extract important information from spectroscopy data and express it as a set of new orthogonal variables known as principal components (PCs) [
30]. By plotting PCs based on the characteristic wavelengths from the original and preprocessed spectra, the clustering between the different groups of samples was evaluated [
33]. The evaluation of PCA was discovered through the interpretation of scree plots, scores plots, and loading plots. The scree plot interprets the variance values of individual PCs versus the PC number. In this study, it was performed on the explained variance ratio of PCs. The score plot interprets the sample coordinates projected onto the new successive axes (PCs). The PC scores with the explained variance ratio >0.5% will be used as input data for the classification model. The loading plot equates the contribution of variables in these same spaces [
34].
2.4. Structure of Classification Model
This study developed an artificial neural network (ANN) model based on a multilayer perceptron (MLP). This model uses a sequential model to arrange all layers in sequence, it specifies a neural network, to be precise, sequential: from input to output, passing through a series of hidden layers, one after the other. The MLP in this study consisted of an input layer, two hidden layers, and an output layer. The MLP architecture is shown in
Figure 1.
This study used p features in the input layer (X); the number of p was obtained from PCs scores generated. In order to achieve the best classification results, the structure of the hidden layers in the MLP model was determined as i neurons in hidden layer 1 (h) and j neurons in hidden layer 2 (H). The number of i and j was determined as equal. The output layer had multiple nodes as it would classify four origins of coffee beans. With the one-hot encoding technique, each categorical value in the output layer was converted into a new categorical column and assigned a binary value of 1 or 0 to the column, 4-class classification problem: class 0 (temanggung) → [1, 0, 0, 0], class 1 (toraja) → [0, 1, 0, 0], class 2 (gayo) → [0, 0, 1, 0], class 3 (kintamani) → [0, 0, 0, 1].
Several parameters must also be considered during building this model, including activation function, method of weight initialization, loss function, validation method, batch size, the number of epochs, etc. All these values and parameters were defined experimentally to generate the best outcomes for the model which will also be elaborated on in the experimental results and discussion sessions.
2.5. K-Fold Cross-Validation
In this study, the dataset was split into two parts—a training set and a testing set. About 2/3 of random samples were put in the training set, and the remaining 1/3 was assigned to the testing set. K-fold cross-validation evaluates the model’s ability in certain data to classify new data and flag problems such as overfitting [
35,
36]. The training data were divided into
k subsets (folds).
k refers to the number of folds that a given dataset that will split into. This study determined
k = 10. Since we had about 1600 training data and
k = 10, each fold contains around 160 data. In these partitioned folds, training and testing subsets were performed in
k iterations such that in each iteration, we put one fold for validation and left the remaining
k − 1 folds to train the model [
37,
38]. The total effectiveness of the model was ascertained by calculating the average of each iteration and the estimation error generated. An illustration of this validation method is given in
Figure 2.
2.6. Model Evaluation
The confusion matrix was used for model performance evaluation [
39]. First, we must compute a set of predicted targets and compare them with actual targets [
29]. The predicted targets represent the values of the class as a result of the model, while the actual class represents the original values of the initial class [
40]. The general idea is to count the correct/incorrect classifications of positive samples and the correct/incorrect classification of negative samples [
41]. A schematic representation of multi-class confusion matrix of coffee origin is shown in
Table 1. The determination of
TP,
TN,
FP, and
FN are calculated using formulas given in
Table 2. The
TP (True Positive) values represent the number of correctly classified positive examples; the
TN (True Negative) values estimate the number of correctly classified negative examples; the
FP (False Positive) values represent the number of correctly classified negative examples; and the
FN (False Negative) is the number of actual positive examples grouped as negative [
35].
The performance of the MLP model was determined by calculating performance metrics. The most commonly employed indicators are accuracy, specificity, precision, recall or sensitivity, and F-score; the formulas are given in
Table 3. Accuracy (
AC) estimates the proportion of correctly classified samples, whereas Misclassification error (
E) estimates the proportion of incorrectly classified samples. Specificity (
SP) counts the ratio of incorrectly classified samples to all negative samples. Recall (R) or sensitivity calculates the ratio of correctly classified samples to all positive samples. Precision (P) measures the ratio of correctly classified samples as positive to all the positively classified samples. F-score (FS) combines the precision and recall scores of a model. While ‘accuracy’ remains valid for balanced data, F-score works well on imbalanced data. The
AC evaluates the correct classified samples, and the values shall be close to 100%. The
SP,
R,
P, and
FS are declared as ‘good’ when they are close to 1. The
E evaluates wrongly classified samples, which shall be as low as possible, ideally close to 0% [
36].
The area under the curve (AUC) and receiver operating characteristic (ROC) curve were also determined to check or visualize the performance of this classification model. The ROC curve for the multi-class problems contains a graph that represents TPR (true positive rate) on the
y-axis against FPR (false positive rate) on the
x-axis [
42,
43]. The proportion of true positive comes from the value of sensitivity, while the proportion of false negative comes from 1-specificity [
44]. A ROC curve starts at point (0,0) and ends at point (1,1). The point at coordinate (0,0) (TPR = 0, FPR = 0) represents that the classifier never predicts a positive class. Point (1,1) (TPR = 1, FPR = 1) represents the opposite situation, the classifier classifies all samples as positive and produces a possibly high number of false positives. The perfect coordinate is at (0,1) while TPR = 1 and FPR = 0.
Figure 3 shows an example of an ROC graph with three ROC curves. Classifier A performs far better than the other two (B and C). Classifier C is useless as its performance is no better than chance [
37].
The area under the curve (AUC) summarizes each ROC curve in the form of numerical information. The AUC is calculated by summing the area under the ROC curve; the larger the area, the more accurate the model is [
44]. The AUC value lies on the interval 0 to 1. The greater the AUC value, the better the classification model. Since a better classification model should lie above the ascending diagonal of an ROC graph (curve C in
Figure 3), the AUC must exceed the value of 0.5 [
37].
All data analyses in this work—from spectral preprocessing to PCA analysis to the development and evaluation of the MLP model—were conducted by PyCharm 2022.3 (Professional Edition for educational use) as an IDE platform for Python code (v3.10). In addition, a number of libraries were used, such as Pandas (v2.0.0), NumPy (v1.24.2), Matplotlib (v3.7.1), SciPy (v1.10.1), Scikit-Learn (v1.2.2), and Keras (v2.11.0).
4. Discussion
Spectroscopic data contain multiple variables that may have large amounts of information and multicollinearity [
63]. Reduction of dimensionality is required to map those variables which are a high dimensionality to a lesser dimensionality [
64]. In many spectroscopic studies, an unsupervised learning algorithm which is also one of the prominent dimensionality reduction techniques in chemometrics analysis, is principal component analysis (PCA). PCA converts and summarizes spectroscopic data (a group of correlated variables) by forming new (uncorrelated) variables called principles components (PCs), which are linear combinations of the original variables [
52,
64].
Chemometric methods became routinely applied tools to handle problems related to spectroscopic data, including (a) determination of the concentration of a compound in a sample, (b) classification of the origins of samples, and (c) recognition of the presence/absence of substructures in the chemical structure of an unknown organic compound in samples. Currently, the chemometric approach is not only based on methods to solve chemical problems but also is data-driven, which can be applied to solve problems for other disciplines such as econometrics, sociology, psychometrics, medicine, biology, image analysis, and pattern recognition. This method uses multivariate statistical data analysis to analyze and restructure datasets, as well as to make empirical mathematical models that can predict the values of important properties that are not directly measurable [
65]. Principal component regression (PCR) and partial least-square regression (PLSR) are methods to deal with calibration problems, while the classifications are discriminant analysis (DA), SIMCA, classification tree (CT), support vector machine (SVM), and machine learning algorithm including artificial neural networks (ANN).
The use of an ANN model in spectroscopic research has been found, including in identifying functional groups and qualitative analysis [
66]. The backpropagation (BP) algorithm is commonly used to train feedforward neural networks that have only inter-layer connections and are fully connected from the input layer to the hidden layers and to the output layers. Here, the spectral information is used as input variables, and the analyte concentration, physical-chemical characteristic, or desired group of samples is used as output. However, the disadvantage of the ANN model is related to the complex infrastructure. To get robust learning results, it must use a large number of training samples. The input variables must also be higher than the number of outputs estimated. In spectroscopic data, the large number of spectral variables often renders the predicted outputs, but methods of reducing the variable dimensionality are often required so the model can work easier and take a few times to train the model [
67].
The combination of PCA and ANN in the classification problems was demonstrated by He et al. [
52] to discriminate the five typical varieties of yoghurt by Visible/NIR-spectroscopy (325 to 1075 nm). The first seven principal components (PC1 to PC7) from original spectra gained 99.97% of explained variance and are applied as input variables for BP-ANN. The distinguishment of five yoghurt types was performed satisfactorily. Briandet et al. [
68] used ANN to detect adulteration in instant coffee using infrared spectroscopy. Five types of samples were determined, including pure coffee, coffee + glucose, coffee + starch, and coffee + chicory. The ANN model output was an improvement over the classification results obtained by LDA.
A spectrum with a large number of variables is not recommended to be used directly as an input variable for an ANN and should be compressed first [
66]. PCA can be applied to compress a large number of spectral data into a small number of variables defined as PCs. These small variables represent the most common data variations that can be attributed to the first, one, two, or three components and soon. These components can replace the original spectroscopic variables without much loss of information [
69]. To obtain new data, generally, many scientists determine the number of PCs that explain more than 85% of the cumulative variance ratio [
21,
52,
65]. Practically, a value greater than 85% is not always necessary to be achieved. The number of PCs obtained can also be changed to any extent according to the circumstance [
52]. There is no definitive answer to the question of how many the number of components to retain. It depends on the amount of total cumulative variance explained, the relative size of the eigenvalues (the variances of the sample components), and the subject-matter interpretation of the components [
69]. Referring to [
68], we can consider the number of components by excluding eigenvalues near zero because they are deemed unimportant and may indicate an unsuspected linear dependency in the data. Therefore, in this study, we use PCs with an explained variance ratio greater than 0.5% to overcome this issue. According to
Table 4, the number of components to be included in the model varies.
In special cases for calibration problems, applying PCA in data compression may run the risk of ignoring some useful information correlated to the analytes, a relatively large number of PCs should be used. Approaches for future studies in the classification problems can be carried out by employing ANN not only combined with PCA but also with LDA and PLS regression. LDA compresses spectroscopic data and produces less-dimensional variables called linear discriminants (LDs). Spectral information also can be compressed through a PLS regression, and the PLS factors were used as input for the ANN model [
65,
70].















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}