


Dual-Layer Index for Efficient Traceability Query of Food Supply Chain Based on Blockchain


Abstract
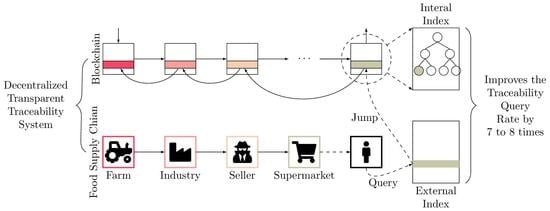
1. Introduction
2. Related Studies
2.1. Food Supply Chain Based on Blockchain
2.2. Other Supply Chain Based on Blockchain
2.3. Optimization Methods Based on External Database
2.4. Optimization Methods Based on Structure Alternation and Novel Data Forms
3. Methodology
3.1. Motivation
3.2. Chosen Approach
3.3. Idea Overview
3.4. Experimental Design
4. Dual-Layer Index Structure
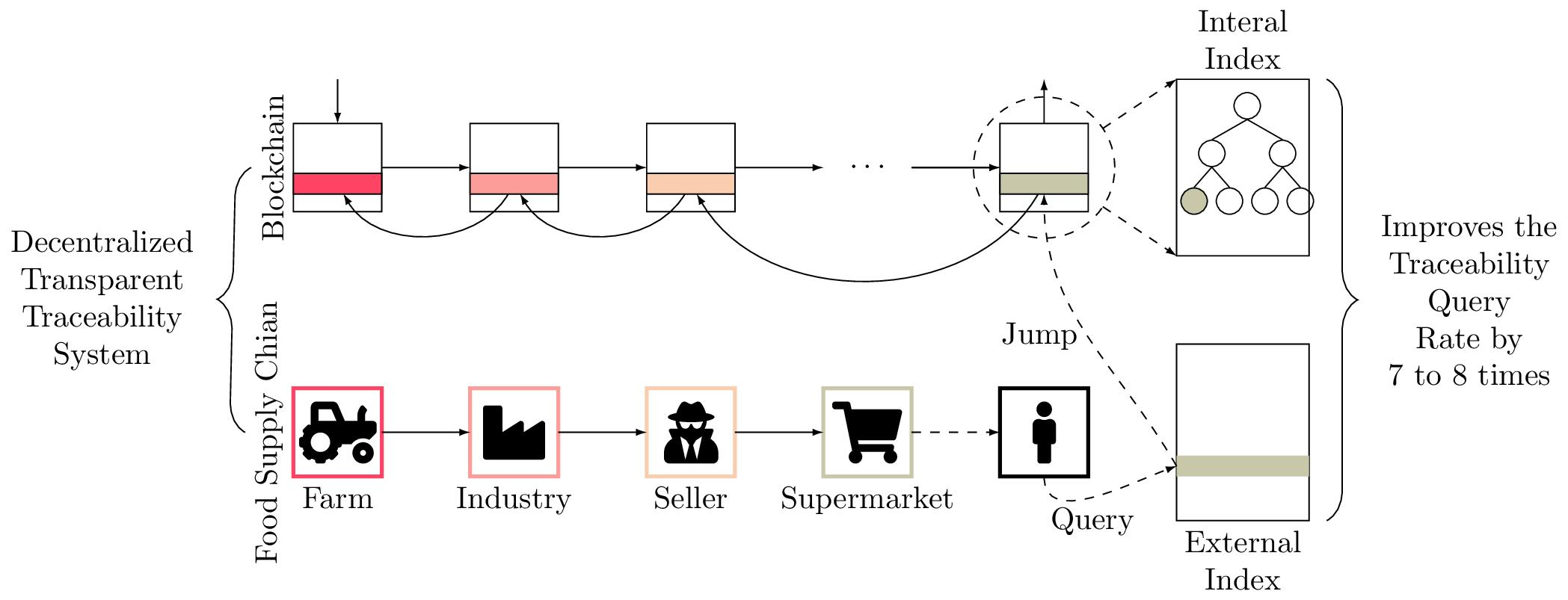
4.1. External Index Design
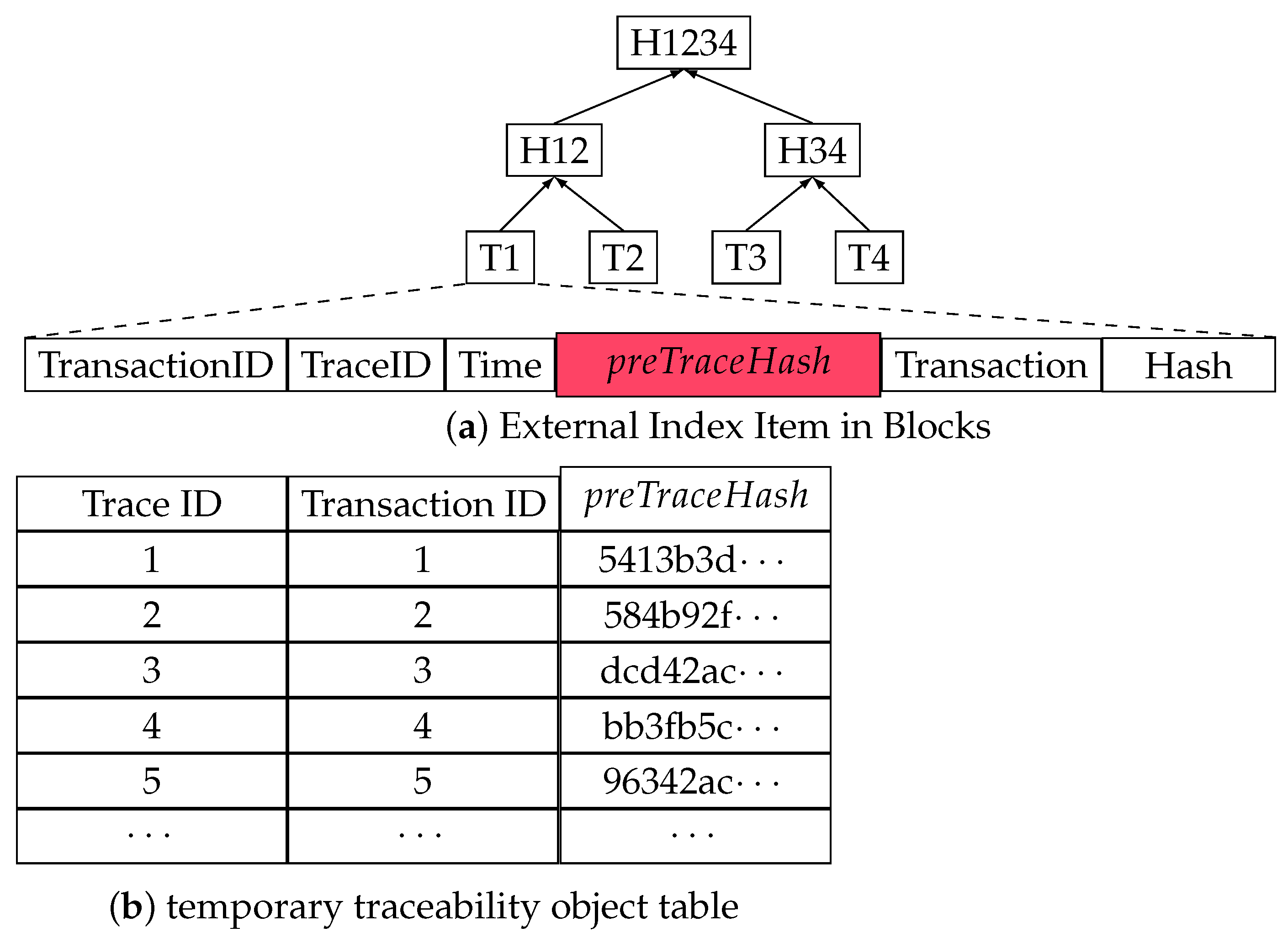
4.2. Internal Index Design
5. Dual-Layer Index Operation
5.1. Dual-Layer Index Creation
5.1.1. Internal Index Creation
5.1.2. External Index Creation
5.2. Dual-Layer Index Query
6. Experiments
6.1. Environment Setup
6.2. Dataset Setup
6.3. Experiment Setup
- (1)
- Block Construction Cost Experiment
- (2)
- Data Amount Influence Experiment
- (3)
- Block Depth Influence Experiment
- (4)
- Block Size Influence Experiment
- (5)
- Extreme Case Experiment
- (6)
- Complex Scenario Experiment
6.4. Experimental Results and Analysis
- : block construction time on dataset with index type . While importing the dataset into the simulation system, we calculated the block generation time by obtaining the operation system’s timestamp.
- : storage of the simulation system on dataset with index type . Once the data set was imported into the simulation system, we calculated the block storage occupancy by obtaining the storage size of the block files in the simulation system.
- : execution time of traceability queries on dataset with index type . After importing the dataset into the simulation system, we conducted traceability queries on the simulation system and calculated the time required for traceability queries by obtaining the operation system’s timestamp.
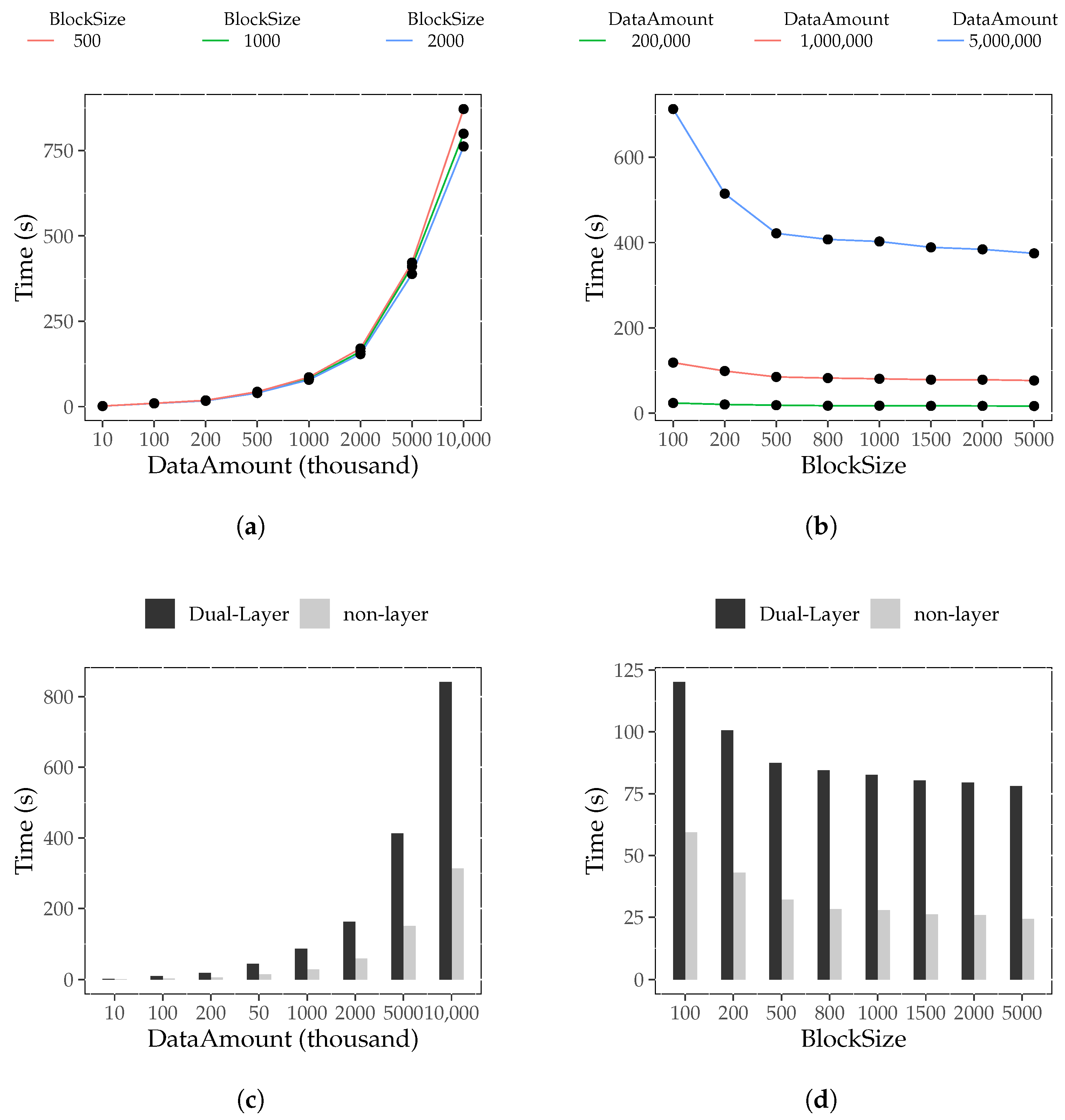
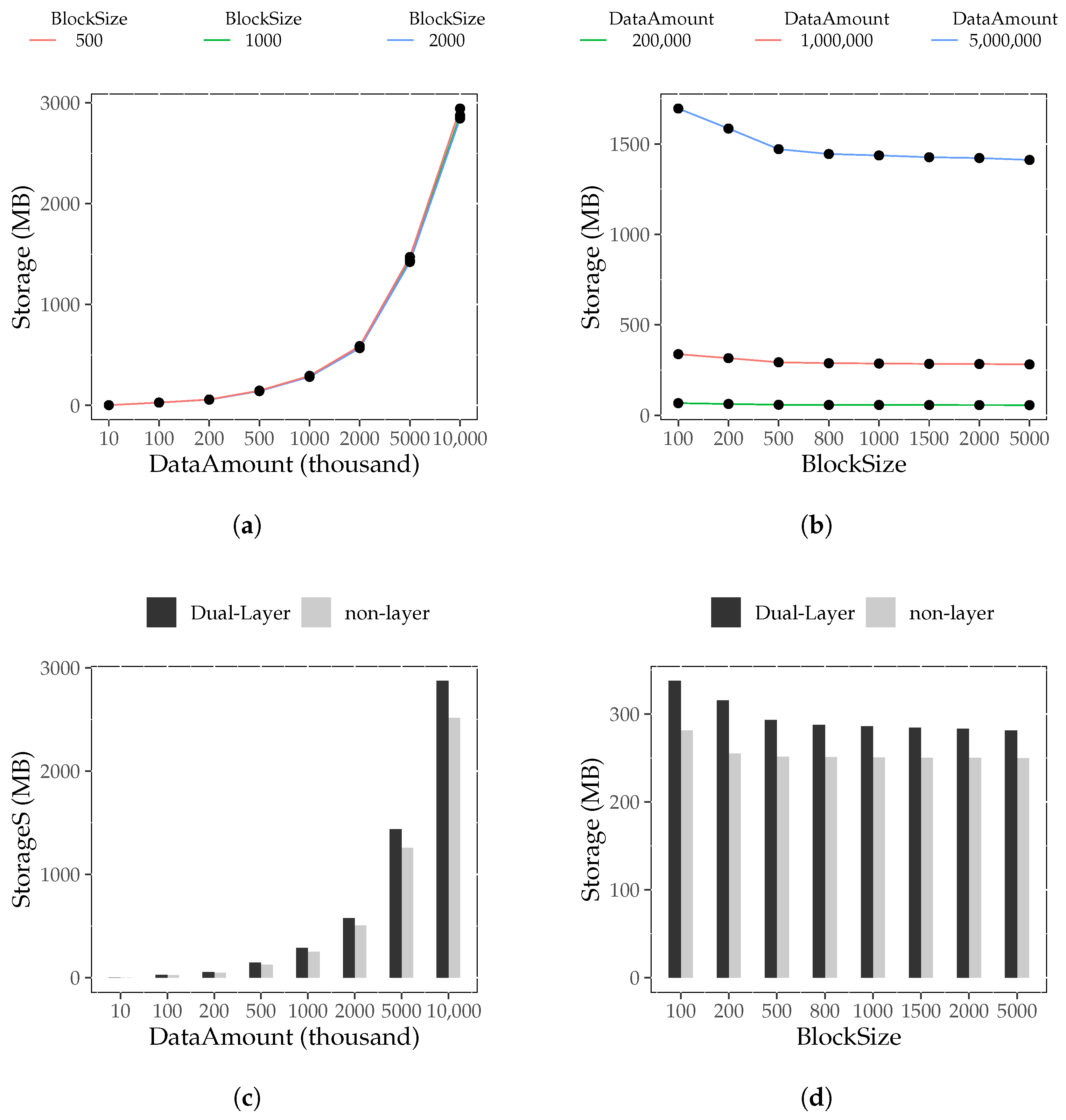
6.4.1. Index Construction Cost Experiment
- (1)
- Construction Time Result
- (2)
- Block Storage Result
6.4.2. Data Amount Influence Experiment
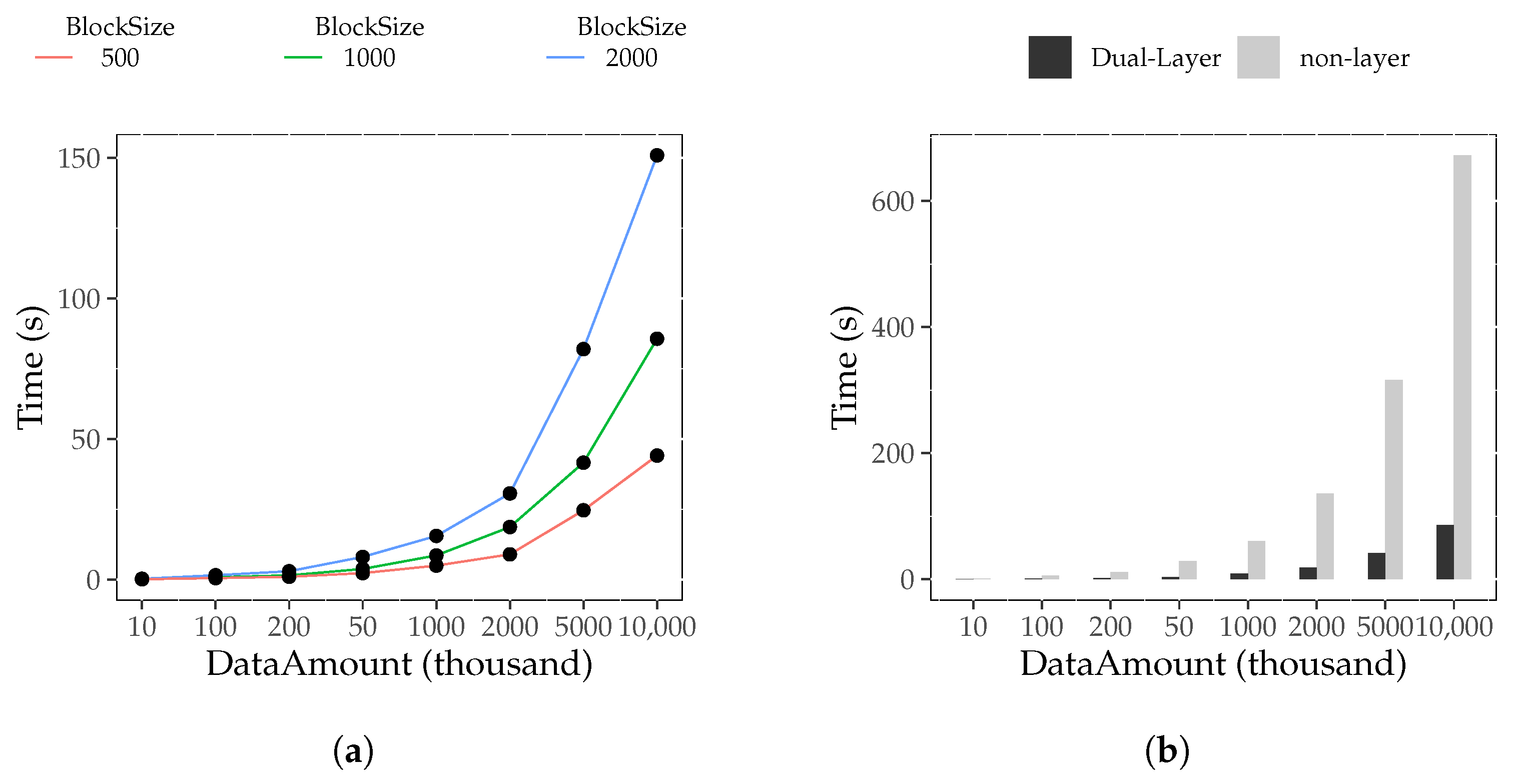
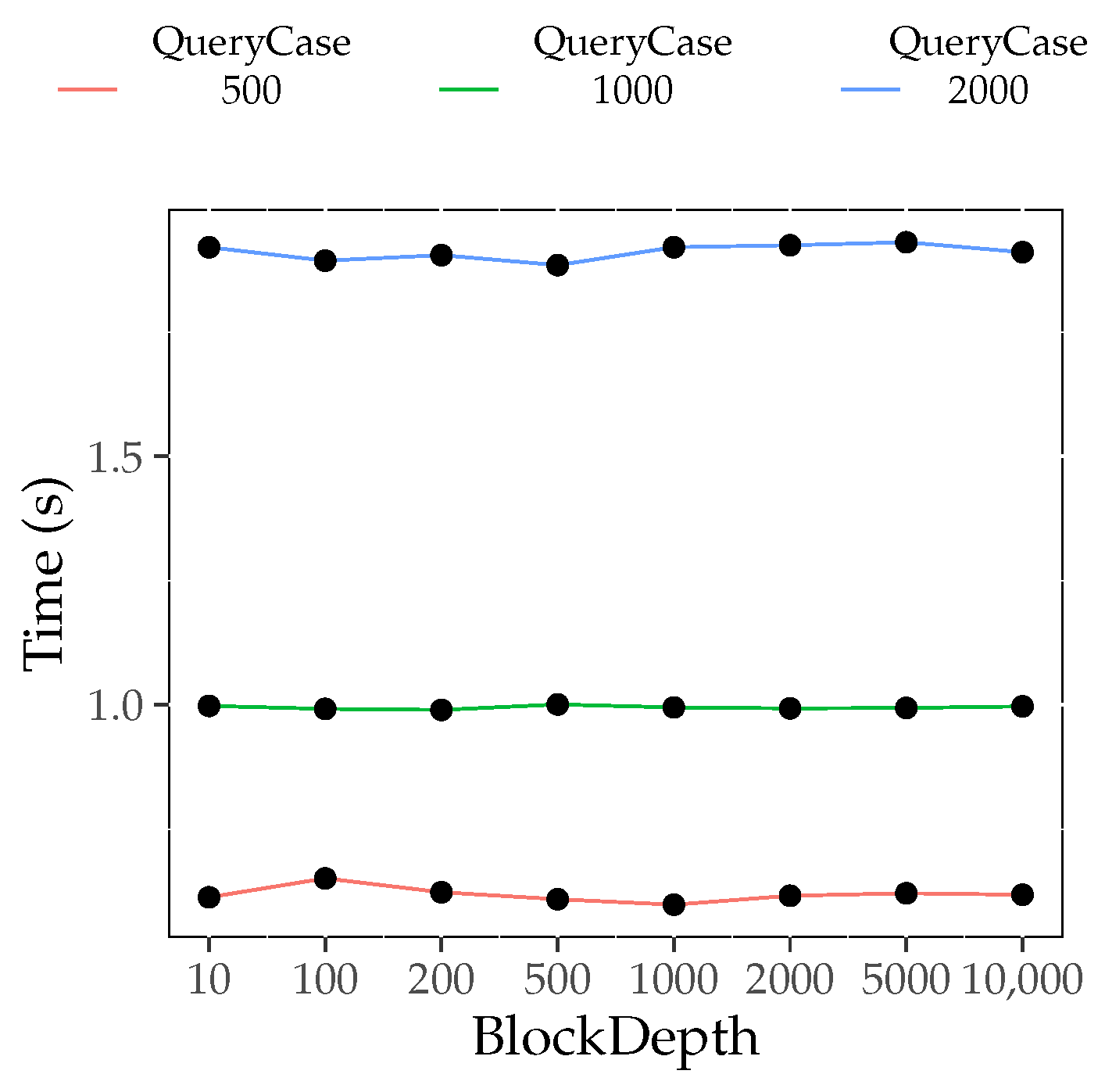
6.4.3. Block Depth Influence Experiment
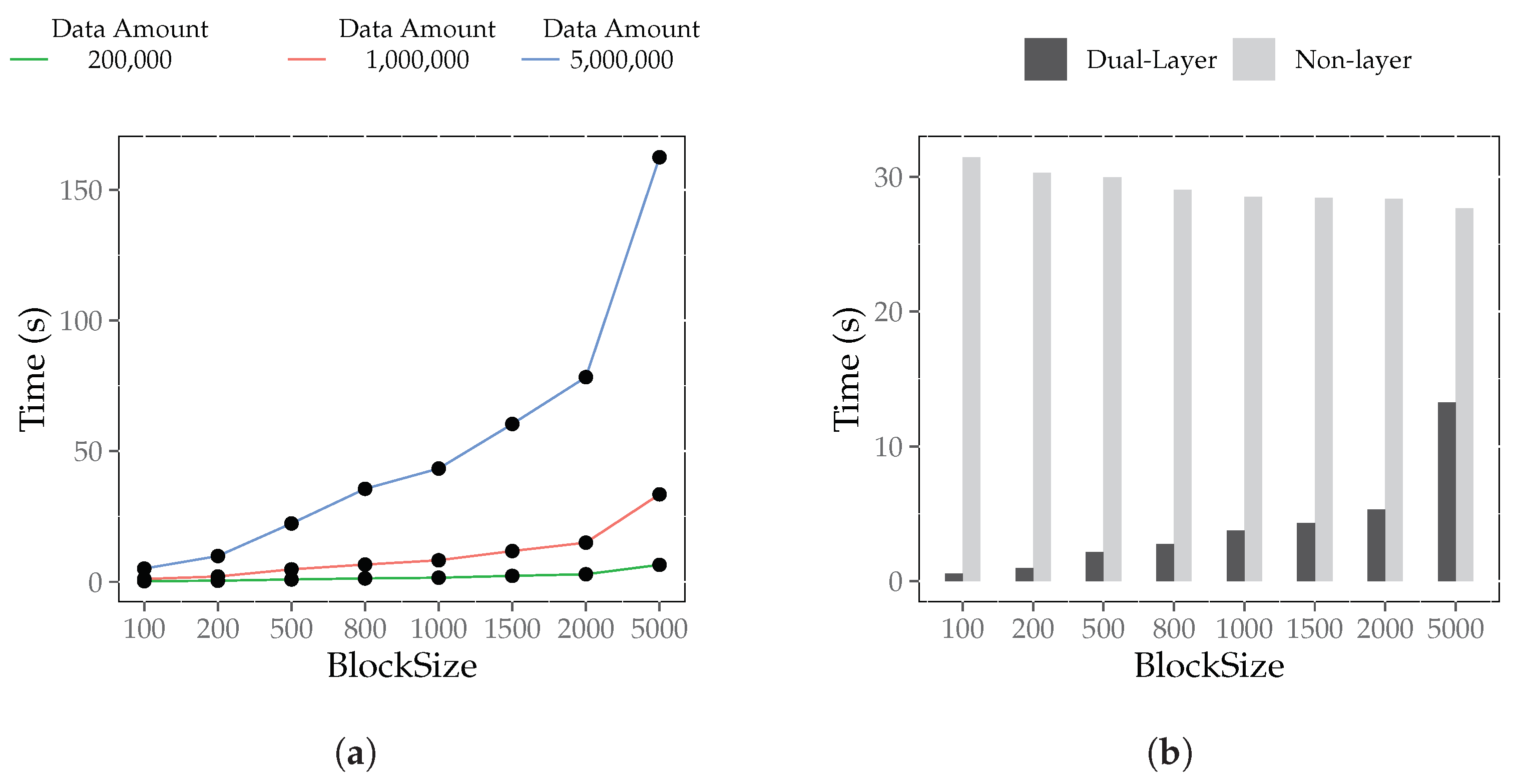
6.4.4. Block Size Influence Experiment
6.4.5. Extreme Case Experiment
6.4.6. Complex Scenario Experiment
7. Discussion
7.1. Discussion of Experimental Results
7.2. Implementation Discussion
- For a novel food supply chain, the initial step is to modify the MB+ tree block structure. This alteration is imperative for storing the internal index and a part of the external index. Following this, the location for storing the external index must be determined. Three main options exist: (1) If a blockchain system supports a state database, such as Fabric, Ethereum, or Partiy, the external index can be stored within this database. (2) Another option is to make use of a special block that is designated for external index storage, but this may lead to query time overhead. (3) Alternatively, an external database can be introduced to store the external index, though this approach may introduce security and tampering problems. In the end, to ensure the maintenance of the system, an intelligent contract must be created that writes the traceability data and effectively maintains the dual-layer index structure.
- For an existing food supply chain, the first step is to create a novel blockchain environment that supports the dual-layer index feature. Subsequently, the traceability data should be exported from the original supply chain system and imported into the novel blockchain system. However, this process may entail a cross-chain operation. If the underlying blockchain systems are identical, a data transformation intelligent contract would be necessary. Otherwise, the traceability data have to be exported to local storage and imported to the novel blockchain system later. However, the use of local storage for data exporting poses potential issues. The absence of adequate data protection mechanisms may result in tampering problems.
7.3. Comparison with Related Methods
7.4. Assumptions and Limitations
- (1)
- Assumptions
- (2)
- Limitations
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, P.; Zhang, Z.; Li, Y. Investment Decision of Blockchain-Based Traceability Service Input for a Competitive Agri-Food Supply Chain. Foods 2022, 11, 2981. [Google Scholar] [CrossRef]
- Latino, M.E.; Corallo, A.; Menegoli, M.; Nuzzo, B. An integrative conceptual framework of food certifications: Systematic review, research agenda, and macromarketing implications. J. Macromark. 2022, 42, 71–99. [Google Scholar] [CrossRef]
- Khanna, A.; Jain, S.; Burgio, A.; Bolshev, V.; Panchenko, V. Blockchain-Enabled Supply Chain platform for Indian Dairy Industry: Safety and Traceability. Foods 2022, 11, 2716. [Google Scholar] [CrossRef] [PubMed]
- Kechagias, E.P.; Gayialis, S.P.; Papadopoulos, G.A.; Papoutsis, G. An Ethereum-Based Distributed Application for Enhancing Food Supply Chain Traceability. Foods 2023, 12, 1220. [Google Scholar] [CrossRef]
- Islam, S.; Cullen, J.M. Food traceability: A generic theoretical framework. Food Control 2021, 123, 107848. [Google Scholar] [CrossRef]
- Wang, L.; Xu, L.; Zheng, Z.; Liu, S.; Li, X.; Cao, L.; Li, J.; Sun, C. Smart Contract-Based Agricultural Food Supply Chain Traceability. IEEE Access 2021, 9, 9296–9307. [Google Scholar] [CrossRef]
- Tian, F. An agri-food supply chain traceability system for China based on RFID & blockchain technology. In Proceedings of the International Conference on Service Systems and Service Management, Kunming, China, 24–26 June 2016; IEEE: Kunming, China, 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Yiu, N.C.-K. Toward Blockchain-Enabled Supply Chain Anti-Counterfeiting and Traceability. Future Internet 2021, 13, 86. [Google Scholar] [CrossRef]
- Zheng, Z.; Xie, S.; Dai, H.; Chen, X.; Wang, H. An Overview of Blockchain Technology: Architecture, Consensus, and Future Trends. In Proceedings of the 2017 IEEE International Congress on Big Data (BigData Congress), Honolulu, HI, USA, 25–30 June 2017; IEEE: Honolulu, HI, USA, 2017; pp. 557–564. [Google Scholar] [CrossRef]
- Gupta, H.; Hans, S.; Aggarwal, K.; Mehta, S.; Chatterjee, B.; Jayachandran, P. Efficiently processing temporal queries on hyperledger fabric. In Proceedings of the International Conference on Data Engineering, Paris, France, 16–19 April 2018; IEEE: Paris, France, 2018; pp. 1489–1494. [Google Scholar] [CrossRef]
- Sunny, J.; Undralla, N.; Madhusudanan Pillai, V. Supply Chain Transparency through Blockchain-Based Traceability: An Overview with Demonstration. Comput. Ind. Eng. 2020, 150, 106895. [Google Scholar] [CrossRef]
- Kim, H.M.; Laskowski, M. Toward an ontology-driven blockchain design for supply-chain provenance. Intell. Syst. Account. Financ. Manag. 2018, 25, 18–27. [Google Scholar] [CrossRef]
- Xie, J.; Zhu, S.; Li, B. Research on data storage model of household electrical appliances supply chain traceability system based on blockchain. In Proceedings of the International Conference on Advanced Computational Intelligence, Wanzhou, China, 14–16 May 2021; IEEE: Wanzhou, China, 2021; pp. 179–185. [Google Scholar] [CrossRef]
- Peng, Z.; Wu, H.; Xiao, B.; Guo, S. VQL: Providing Query Efficiency and Data Authenticity in Blockchain Systems. In Proceedings of the IEEE International Conference on Data Engineering Workshops, Macao, China, 8–11 April 2019; IEEE: Macao, China, 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Prashar, D.; Jha, N.; Jha, S.; Lee, Y.; Joshi, G.P. Blockchain-Based Traceability and Visibility for Agricultural Products: A Decentralized Way of Ensuring Food Safety in India. Sustainability 2020, 12, 3497. [Google Scholar] [CrossRef]
- Damoska Sekuloska, J.; Erceg, A. Blockchain Technology toward Creating a Smart Local Food Supply Chain. Computers 2022, 11, 95. [Google Scholar] [CrossRef]
- Zhang, X.; Li, Y.; Peng, X.; Zhao, Z.; Han, J.; Xu, J. Information Traceability Model for the Grain and Oil Food Supply Chain Based on Trusted Identification and Trusted Blockchain. Int. J. Environ. Res. Public Health 2022, 19, 6594. [Google Scholar] [CrossRef] [PubMed]
- Kong, L.; Chen, W.; Lv, H.; Chen, Q.; Lin, G.; Huang, S.; Deng, W. BCSChain: Blockchain-based ceramic supply chain. In Proceedings of the International Conference on Blockchain and Transtworthy System, Chengdu, China, 4–5 August 2022; Svetinovic, D., Zhang, Y., Luo, X., Huang, X., Chen, X., Eds.; Springer: Chengdu, China, 2022; Volume 1679, pp. 91–104. [Google Scholar] [CrossRef]
- Hader, M.; Tchoffa, D.; Mhamedi, A.E.; Ghodous, P.; Dolgui, A.; Abouabdellah, A. Applying integrated Blockchain and Big Data technologies to improve supply chain traceability and information sharing in the textile sector. J. Ind. Inf. Integr. 2022, 28, 100345. [Google Scholar] [CrossRef]
- Abdallah, S.; Nizamuddin, N. Blockchain-based solution for pharma supply chain industry. Comput. Ind. Eng. 2023, 177, 108997. [Google Scholar] [CrossRef]
- Liu, H.; Yang, B.; Xiong, X.; Zhu, S.; Chen, B.; Tolba, A.; Zhang, X. A financial management platform based on the integration of blockchain and supply chain. Sensors 2023, 23, 1497. [Google Scholar] [CrossRef]
- Helmer, S.; Roggia, M.; Ioini, N.E.; Pahl, C. EthernityDB—Integrating Database Functionality into a Blockchain. In Proceedings of the New Trends in Databases and Information Systems, Budapest, Hungary, 2–5 September 2018; Benczúr, A., Thalheim, B., Horváth, T., Chiusano, S., Cerquitelli, T., Sidló, C., Revesz, P.Z., Eds.; Springer: Budapest, Hungary, 2018; Volume 909, pp. 37–44. [Google Scholar] [CrossRef]
- McConaghy, T.; Marques, R.; Muller, A.; De Jonghe, D.; McConaghy, T.; McMullen, G.; Henderson, R.; Bellemare, S.; Granzotto, A. Bigchaindb: A scalable blockchain database. White Paper. 2016. Available online: https://gamma.bigchaindb.com/whitepaper/bigchaindb-whitepaper.pdf (accessed on 16 April 2023).
- Muzammal, M.; Qu, Q.; Nasrulin, B. Renovating blockchain with distributed databases: An open source system. Future Gener. Comput. Syst. 2019, 90, 105–117. [Google Scholar] [CrossRef]
- Zhou, E.; Sun, H.; Pi, B.; Sun, J.; Yamashita, K.; Nomura, Y. Ledgerdata Refiner: A Powerful Ledger Data Query Platform for Hyperledger Fabric. In Proceedings of the International Conference on Internet of Things: Systems, Management and Security, Granada, Spain, 22–25 October 2019; IEEE: Granada, Spain, 2019; pp. 433–440. [Google Scholar] [CrossRef]
- Li, Y.; Zheng, K.; Yan, Y.; Liu, Q.; Zhou, X. EtherQL: A Query Layer for Blockchain System. In Proceedings of the International Conference on Database Systems for Advanced Applications, Suzhou, China, 27–30 March 2017; Candan, S., Chen, L., Pedersen, T.B., Chang, L., Hua, W., Eds.; Springer: Suzhou, China, 2017; Volume 10178, pp. 556–567. [Google Scholar] [CrossRef]
- Pratama, F.A.; Mutijarsa, K. Query Support for Data Processing and Analysis on Ethereum Blockchain. In Proceedings of the International Symposium on Electronics and Smart Devices, Bandung, Indonesia, 23–24 October 2018; IEEE: Bandung, India, 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Ma, S.; Cao, Y.; Xiong, L. Efficient logging and querying for blockchain-based cross-site genomic dataset access audit. BMC Med. Genom. 2020, 13, 91. [Google Scholar] [CrossRef]
- Ren, Y.; Zhu, F.; Sharma, P.K.; Wang, T.; Wang, J.; Alfarraj, O.; Tolba, A. Data Query Mechanism Based on Hash Computing Power of Blockchain in Internet of Things. Sensors 2019, 20, 207. [Google Scholar] [CrossRef]
- Pei, Q.; Zhou, E.; Xiao, Y.; Zhang, D.; Zhao, D. An Efficient Query Scheme for Hybrid Storage Blockchains Based on Merkle Semantic Trie. In Proceedings of the International Symposium on Reliable Distributed Systems, Shanghai, China, 21–24 September 2020; IEEE: Shanghai, China, 2020; pp. 51–60. [Google Scholar] [CrossRef]
- Niu, Y.; Zhang, C.; Wei, L.; Xie, Y.; Zhang, X.; Fang, Y. An Efficient Query Scheme for Privacy-Preserving Lightweight Bitcoin Client with Intel SGX. In Proceedings of the IEEE Global Communications Conference, Waikoloa, HI, USA, 9–13 December 2019; IEEE: Waikoloa, HI, USA, 2019; pp. 1–6. [Google Scholar] [CrossRef]
- He, K.; Shi, J.; Huang, C.; Hu, X. Blockchain Based Data Integrity Verification for Cloud Storage with T-Merkle Tree. In Proceedings of the International Conference on Algorithms and Architectures for Parallel Processing, New York City, NY, USA, 2–4 October 2020; Qiu, M., Ed.; Springer: New York, NY, USA, 2020; Volume 12454, pp. 65–80. [Google Scholar] [CrossRef]
- Xu, Y.; Zhao, S.; Kong, L.; Zheng, Y.; Zhang, S.; Li, Q. ECBC: A High Performance Educational Certificate Blockchain with Efficient Query. In Proceedings of the International Colloquium on Theoretical Aspects of Computing, Hanoi, Vietnam, 23–27 October 2017; Hung, D.V., Kapur, D., Eds.; Springer: Hanoi, Vietnam, 2017; Volume 10580, pp. 288–304. [Google Scholar] [CrossRef]
- Radanliev, P.; De Roure, D. New and Emerging Forms of Data and Technologies: Literature and Bibliometric Review. Multimed. Tools Appl. 2023, 82, 2887–2911. [Google Scholar] [CrossRef]
- Kamilaris, A.; Fonts, A.; Prenafeta-Boldv, F.X. The rise of blockchain technology in agriculture and food supply chains. Trends Food Sci. Technol. 2019, 91, 640–652. [Google Scholar] [CrossRef]
- Ray, P.P.; Kumar, N.; Dash, D. BLWN: Blockchain-Based Lightweight Simplified Payment Verification in IoT-Assisted e-Healthcare. IEEE Syst. J. 2021, 15, 134–145. [Google Scholar] [CrossRef]
- Huang, X.; Gong, X.; Huang, X.; Zhao, L.; Gao, K. EBTree: A B-plus Tree Based Index for Ethereum Blockchain Data. In Proceedings of the Asia Service Sciences and Software Engineering Conference, Nagoya, Japan, 13–15 May 2020; ACM: New York, NY, USA, 2020; pp. 83–90. [Google Scholar] [CrossRef]
- Schmidt, B.V.; Moreno, M.S. Traceability Optimization in the Meat Supply Chain with Economic and Environmental Considerations. Comput. Ind. Eng. 2022, 169, 108271. [Google Scholar] [CrossRef]
- Saranya, P.; Maheswari, R. Proof of Transaction (PoTx) Based Traceability System for an Agriculture Supply Chain. IEEE Access 2023, 11, 10623–10638. [Google Scholar] [CrossRef]
- Dietrich, F.; Louw, L.; Palm, D. Blockchain-Based Traceability Architecture for Mapping Object-Related Supply Chain Events. Sensors 2023, 23, 1410. [Google Scholar] [CrossRef] [PubMed]
- Baralla, G.; Pinna, A.; Corrias, G. Ensure Traceability in European Food Supply Chain by Using a Blockchain System. In Proceedings of the 2019 IEEE/ACM 2nd International Workshop on Emerging Trends in Software Engineering for Blockchain (WETSEB), Montreal, QC, Canada, 27–27 May 2019; IEEE: Montreal, QC, Canada, 2019; pp. 40–47. [Google Scholar] [CrossRef]
- Lai, C.; Wang, Y. Achieving efficient and secure query in blockchain-based traceability systems. In Proceedings of the International Conference on Privacy, Security & Trust, Fredericton, NB, Canada, 22–24 August 2022; IEEE: Fredericton, NB, Canada, 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Qin, H.; Si, Y.; Xue, C.; Li, X.; Jiang, Z. A query optimization method for blockchain-based traceability system. In Proceedings of the Information Technology, Networking, Electronic and Automation Control Conference, Chongqing, China, 24–26 February 2023; IEEE: Chongqing, China, 2023; Volume 6, pp. 236–242. [Google Scholar] [CrossRef]
- Martintoni, D.; Senni, V.; Marin, E.G.; Gutierrez, A.J.C. Sensitive Information Protection in Blockchain-Based Supply-Chain Management for Aerospace. In Proceedings of the 2022 IEEE International Conference on Omni-layer Intelligent Systems (COINS), Barcelona, Spain, 1–3 August 2022; IEEE: Barcelona, Spain, 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Cha, S.; Baek, S.; Kim, S. Blockchain based sensitive data management by using key escrow encryption system from the perspective of supply chain. IEEE Access 2020, 8, 154269–154280. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1 | 2 | 3 | 4 |
| Block Depth | 10 | 100 | 200 | 500 | 1000 | 2000 | 5000 | 10,000 |
|---|---|---|---|---|---|---|---|---|
| non-layer Index (s) | 0.686 | 6.04 | 11.975 | 30.003 | 58.634 | 115.321 | 284.665 | 658.633 |
| Dual-Layer Index (s) | 0.998 | 0.992 | 0.99 | 1.001 | 0.995 | 0.993 | 0.994 | 0.997 |
| Data Amount | ||||
|---|---|---|---|---|
| Query Time (s) | 165.816 | 423.128 | 816.563 | 1655.432 |
| Construction Time (s) | 1579.213 | 3910.875 | 7936.125 | 17,136.263 |
| Construct Storage (GB) | 6.58 | 14.13 | 29.16 | 61.59 |
| Bifurcation Factor | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| One-To-Many | 0.124 | 0.118 | 0.102 | 0.136 | 0.122 |
| Many-To-One | 0.135 | 1.545 | 42.598 | 469.312 | 3289.885 |
| Ref | Research Object | Method Type | Security | Sensitive Data Protection | Storage Overhead | Traceability Query Influencing Factors |
|---|---|---|---|---|---|---|
| Ours | Blockchain Traceability Query | Index | Blockchain | No | Low | Traceability Length |
| [42] | Blockchain Traceability Query | Index | Blockchain | No | Low | Data Amount |
| [43] | Blockchain Traceability Query | Index | Blockchain | No | Low | Data Amount |
| [26] | Blockchain Query | External Database | External Database | No | High | Data Amount |
| [14] | Blockchain Query | External Database | External Database | No | High | Data Amount |
| [44] | Application of Supply Chain | Application | Blockchain | Yes | Low | - |
| [45] | Application of Supply Chain | Application | Blockchain | Yes | Low | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, C.; Liu, Y.; Na, M.; Song, J. Dual-Layer Index for Efficient Traceability Query of Food Supply Chain Based on Blockchain. Foods 2023, 12, 2267. https://doi.org/10.3390/foods12112267
Guo C, Liu Y, Na M, Song J. Dual-Layer Index for Efficient Traceability Query of Food Supply Chain Based on Blockchain. Foods. 2023; 12(11):2267. https://doi.org/10.3390/foods12112267
Chicago/Turabian StyleGuo, Chaopeng, Yiming Liu, Meiyu Na, and Jie Song. 2023. "Dual-Layer Index for Efficient Traceability Query of Food Supply Chain Based on Blockchain" Foods 12, no. 11: 2267. https://doi.org/10.3390/foods12112267
APA StyleGuo, C., Liu, Y., Na, M., & Song, J. (2023). Dual-Layer Index for Efficient Traceability Query of Food Supply Chain Based on Blockchain. Foods, 12(11), 2267. https://doi.org/10.3390/foods12112267