
1H NMR Spectroscopy Combined with Machine-Learning Algorithm for Origin Recognition of Chinese Famous Green Tea Longjing Tea


Abstract
1. Introduction
2. Materials and Methods
2.1. Longjing Tea Sample Preparation
2.2. NMR Spectroscopy Detection
2.3. Data Analysis
3. Results and Discussion
3.1. Metabolomic Analysis of Longjing Tea
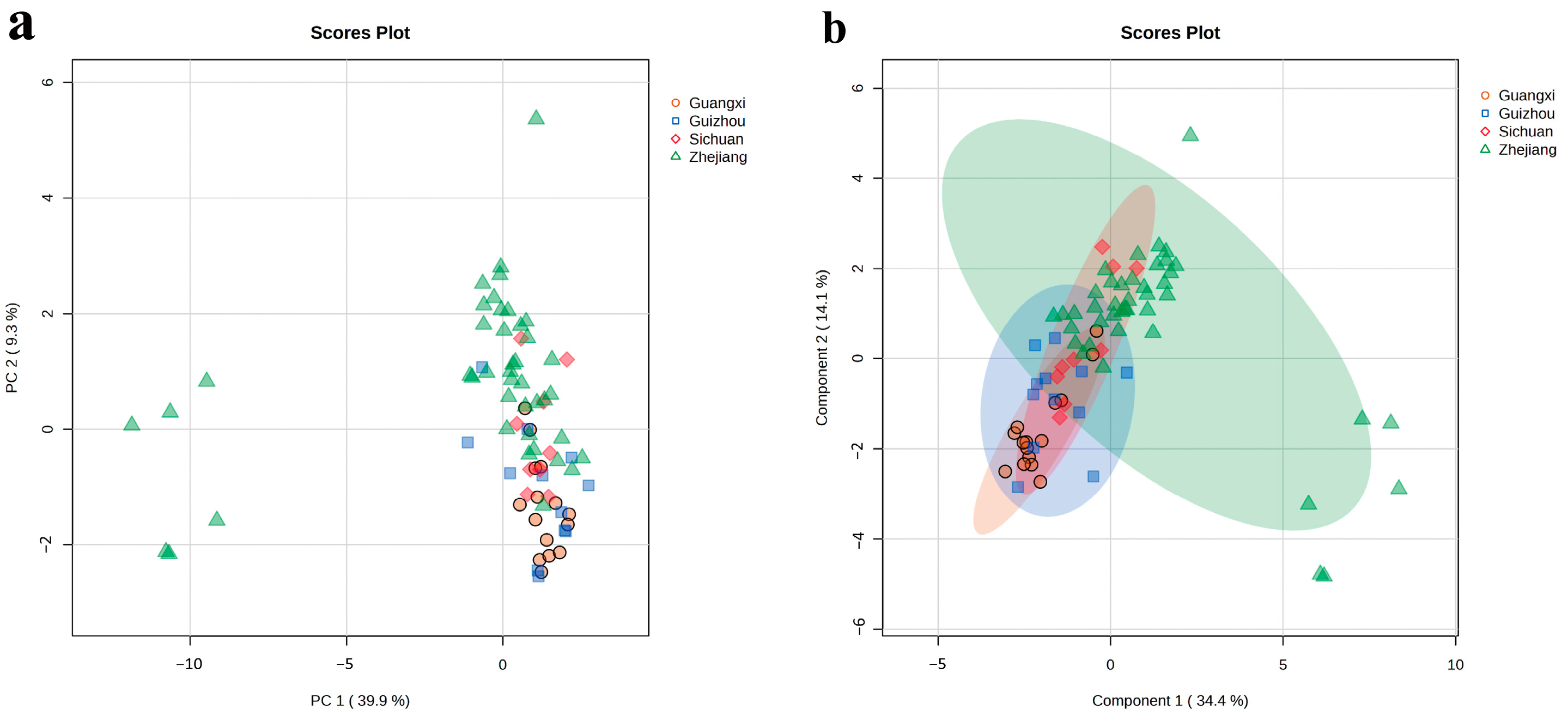
3.2. PCA and sPLS-DA Analysis of Longjing Tea Origin
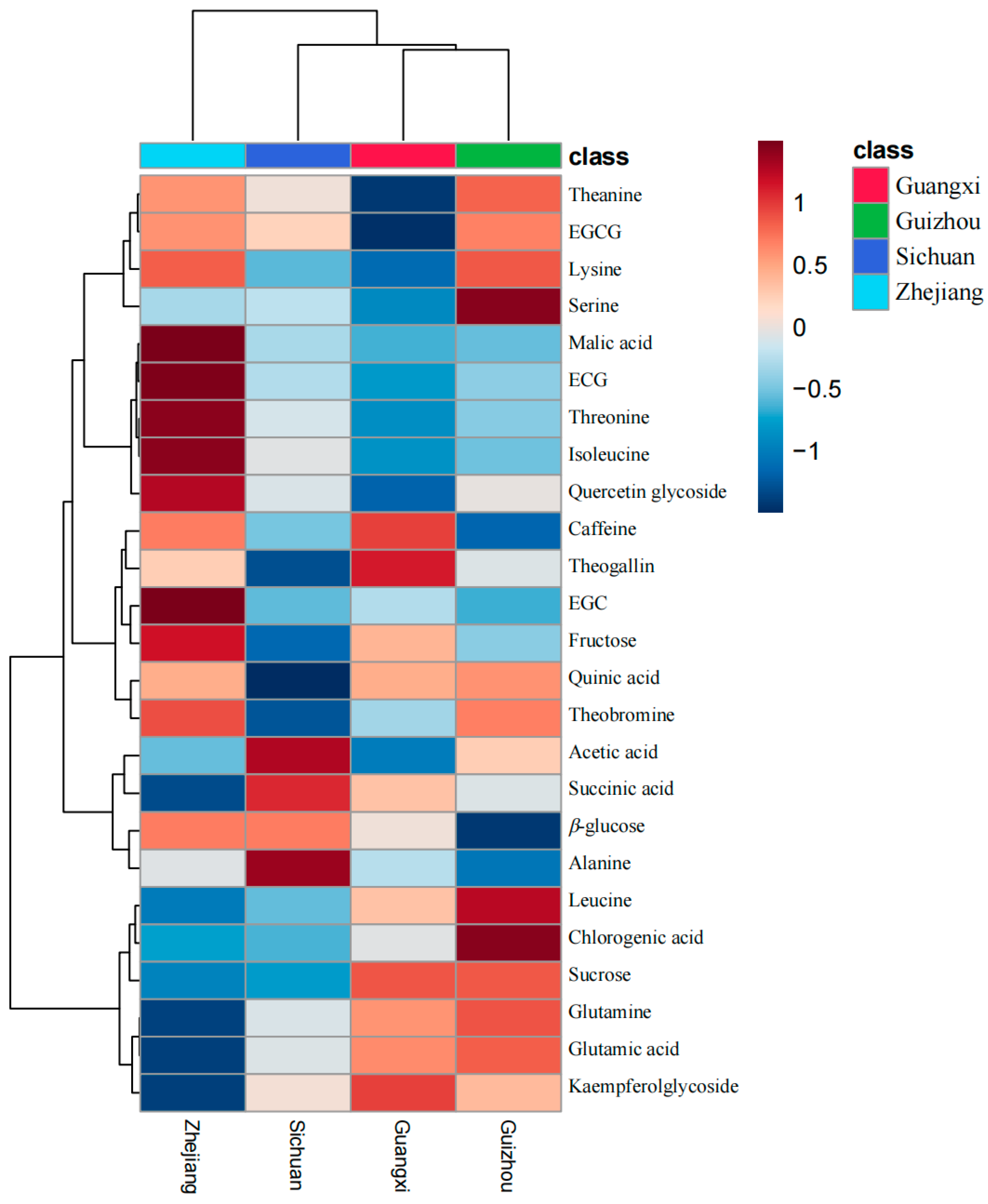
3.3. Hierarchical Clustering of Longjing Tea Origins
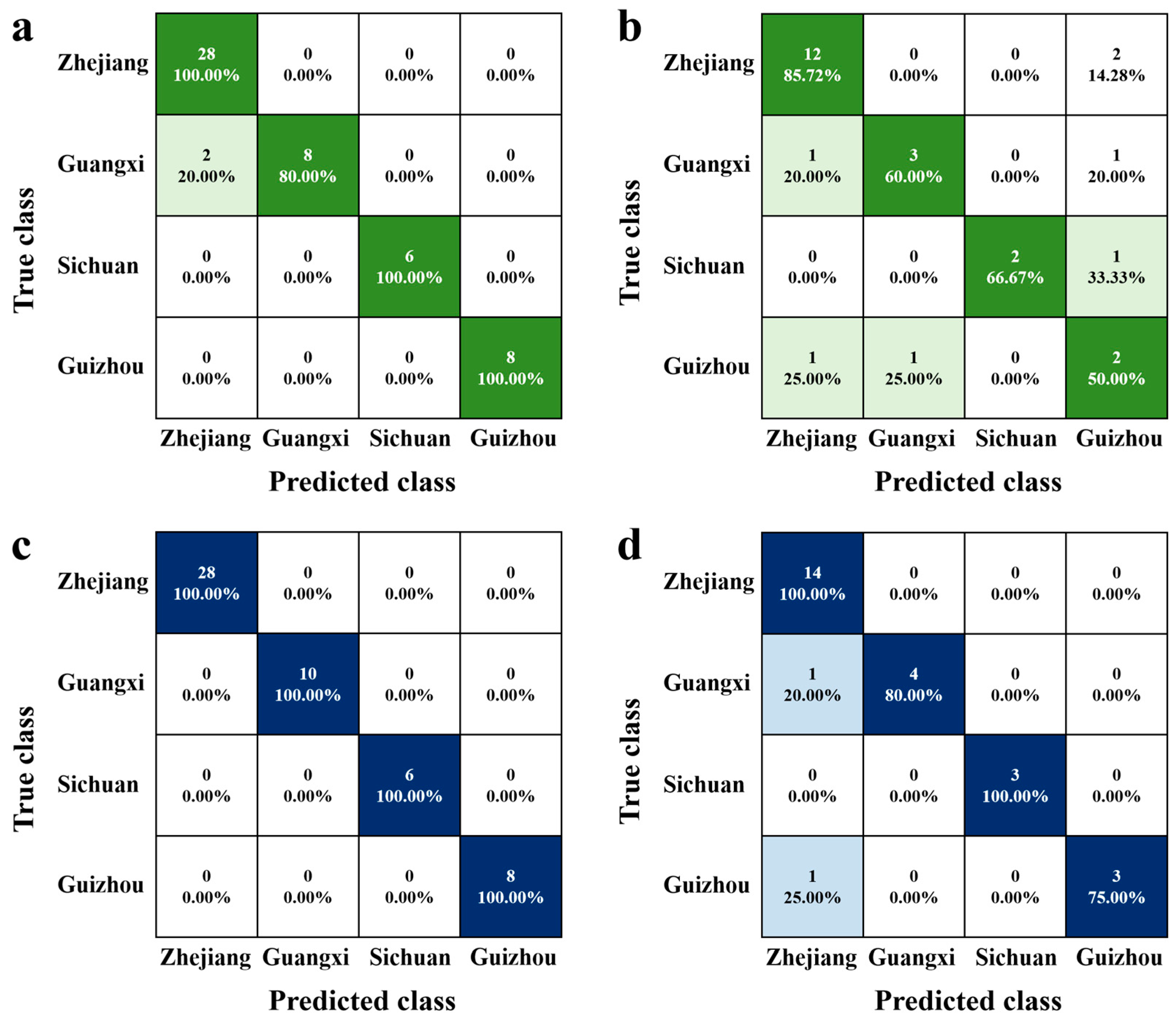
3.4. Machine-Learning Algorithm for Longjing Tea Origins
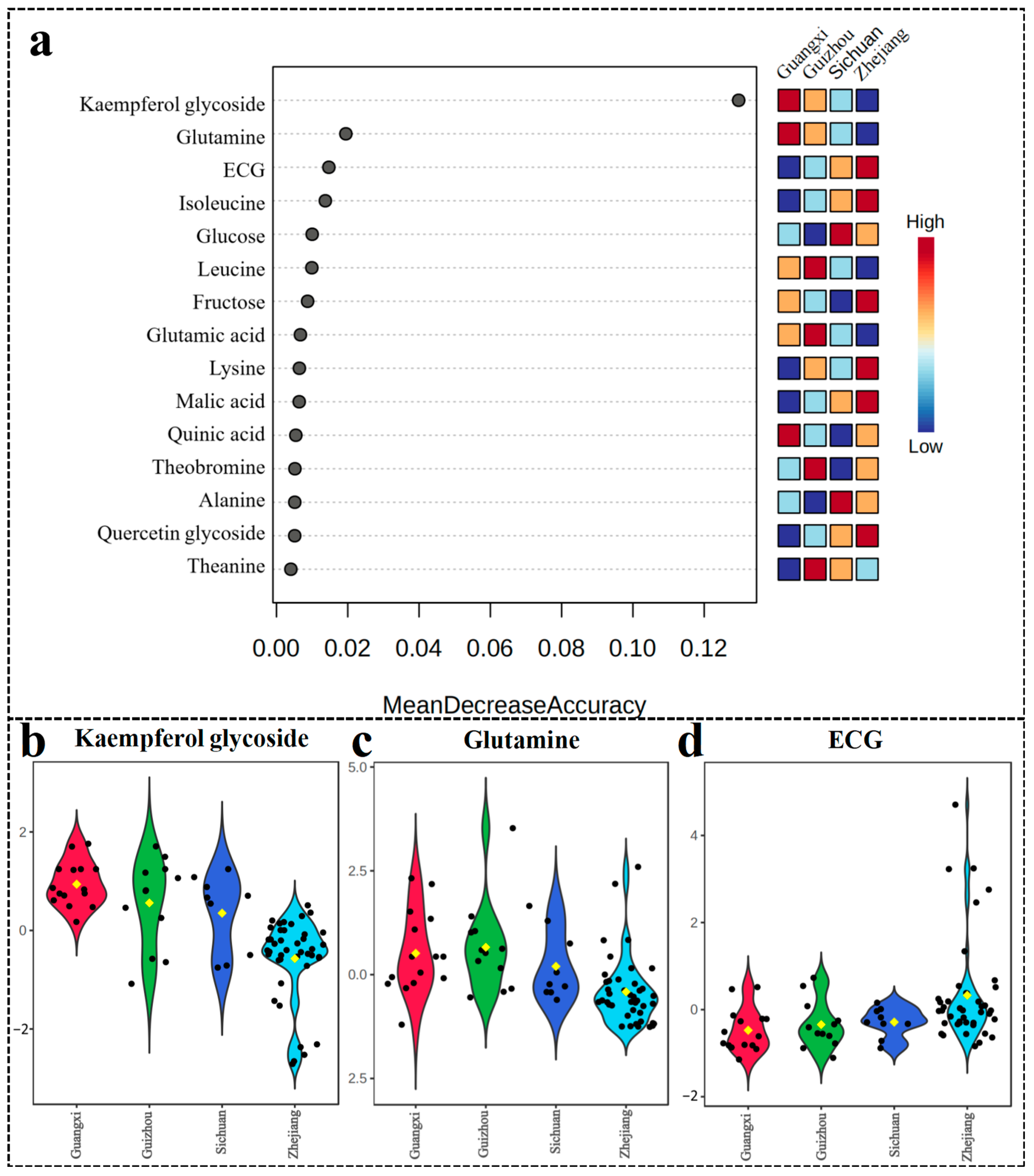
3.5. Metabolite Biomarkers Differentiating Longjing Tea Origins
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, H.Y.; Zhang, J.X.; Liu, S.T.; Li, T.H.; Wei, Y.M.; Gu, Z.; Su, Z.C.; Ning, J.M.; Wang, Y.J.; Hou, Z.W. Characterization of the key volatile compounds in longjing tea (Camellia sinensis) with different aroma types at different steeping temperatures by GC-MS and GC-IMS. LWT-Food Sci. Technol. 2024, 200, 116183. [Google Scholar] [CrossRef]
- GB/T 18650-2008; Product of Geographical Indication - Longjing Tea. National Standards of the People’s Republic of China: Beijing, China, 2008. (In Chinese)
- Ni, K.; Wang, J.; Zhang, Q.F.; Yi, X.Y.; Ma, L.F.; Shi, Y.Z.; Ruan, J.Y. Multi-element composition and isotopic signatures for the geographical origin discrimination of green tea in China: A case study of Xihu Longjing. J. Food Compos. Anal. 2018, 67, 104–109. [Google Scholar] [CrossRef]
- Lu, X.H.; Wang, J.; Lu, G.D.; Lin, B.; Chang, M.Z.; He, W. Quality level identification of West Lake Longjing green tea using electronic nose. Sens. Actuators B Chem. 2019, 301, 127056. [Google Scholar] [CrossRef]
- Wang, L.Y.; Wei, K.; Cheng, H.; He, W.; Li, X.H.; Gong, W.Y. Geographical tracing of Xihu Longjing tea using high performance liquid chromatography. Food Chem. 2014, 146, 98–103. [Google Scholar] [CrossRef]
- He, W.; Hu, X.S.; Zhao, L.; Liao, X.J.; Zhang, Y.; Zhang, M.W.; Wu, J.H. Evaluation of Chinese tea by the electronic tongue: Correlation with sensory properties and classification according to geographical origin and grade level. Food Res. Int. 2009, 42, 1462–1467. [Google Scholar] [CrossRef]
- Fang, S.M.; Huang, W.J.; Wei, Y.M.; Tao, M.; Hu, X.; Li, T.H.; Kalkhajeh, Y.K.; Deng, W.W.; Ning, J.M. Geographical origin traceability of Keemun black tea based on its non-volatile composition combined with chemometrics. J. Sci. Food Agric. 2019, 99, 6937–6943. [Google Scholar] [CrossRef]
- Ma, G.C.; Zhang, Y.B.; Zhang, J.Y.; Wang, G.Q.; Chen, L.Y.; Zhang, M.L.; Liu, T.; Liu, X.; Lu, C.Y. Determining the geographical origin of Chinese green tea by linear discriminant analysis of trace metals and rare earth elements: Taking Dongting Biluochun as an example. Food Control 2016, 59, 714–720. [Google Scholar] [CrossRef]
- Yun, J.; Cui, C.J.; Zhang, S.H.; Zhu, J.J.; Peng, C.Y.; Cai, H.M.; Yang, X.G.; Hou, R.Y. Use of headspace GC/MS combined with chemometric analysis to identify the geographic origins of black tea. Food Chem. 2021, 360, 130033. [Google Scholar] [CrossRef]
- Gu, H.W.; Yin, X.L.; Peng, T.Q.; Pan, Y.; Cui, H.N.; Li, Z.Q.; Sun, W.Q.; Ding, B.M.; Hu, X.C.; Zhang, Z.H.; et al. Geographical origin identification and chemical markers screening of Chinese green tea using two-dimensional fingerprints technique coupled with multivariate chemometric methods. Food Control 2022, 135, 108795. [Google Scholar] [CrossRef]
- Shuai, M.Y.; Peng, C.Y.; Niu, H.L.; Shao, D.L.; Hou, R.Y.; Cai, H.M. Recent techniques for the authentication of the geographical origin of tea leaves from camellia sinensis: A review. Food Chem. 2022, 374, 131713. [Google Scholar] [CrossRef]
- Hatzakis, E. Nuclear magnetic resonance (NMR) spectroscopy in food science: A comprehensive review. Compr. Rev. Food Sci. Food Saf. 2019, 18, 189–220. [Google Scholar] [CrossRef]
- Cui, C.J.; Xia, M.Y.; Wei, Z.Q.; Chen, J.L.; Peng, C.Y.; Cai, H.M.; Jin, L.; Hou, R.Y. 1H NMR-based metabolomic approach combined with machine learning algorithm to distinguish the geographic origin of huajiao (Zanthoxylum bungeanum Maxim.). Food Control 2023, 145, 109476. [Google Scholar] [CrossRef]
- Cui, C.J.; Xu, Y.F.; Jin, G.; Zong, J.F.; Peng, C.Y.; Cai, H.M.; Hou, R.Y. Machine learning applications for identify the geographical origin, variety and processing of black tea using 1H NMR chemical fingerprinting. Food Control 2023, 148, 109686. [Google Scholar] [CrossRef]
- Worley, B.; Powers, R. PCA as a practical indicator of OPLS-DA model reliability. Curr. Metab. 2016, 4, 97–103. [Google Scholar] [CrossRef]
- Wu, X.H.; He, F.; Wu, B.; Zeng, S.P.; He, C.Y. Accurate classification of Chunmee tea grade using NIR spectroscopy and fuzzy maximum uncertainty linear discriminant analysis. Foods 2023, 12, 541. [Google Scholar] [CrossRef]
- Zhang, L.Z.; Dai, H.M.; Zhang, J.L.; Zheng, Z.Q.; Song, B.; Chen, J.Y.; Lin, G.; Chen, L.H.; Sun, W.J.; Huang, Y. A study on origin traceability of white tea (White Peony) based on near-infrared spectroscopy and machine learning algorithms. Foods 2023, 12, 499. [Google Scholar] [CrossRef] [PubMed]
- Jin, G.; Zhu, Y.Y.; Cui, C.J.; Yang, C.; Hu, S.D.; Cai, H.M.; Ning, J.M.; Wei, C.L.; Li, A.X.; Hou, R.Y. Tracing the origin of Taiping Houkui green tea using 1H NMR and HS-SPME-GC-MS chemical fingerprints, data fusion and chemometrics. Food Chem. 2023, 425, 136538. [Google Scholar] [CrossRef]
- Tarachiwin, L.; Ute, K.; Kobayashi, A.; Fukusaki, E. 1H NMR based metabolic profiling in the evaluation of Japanese green tea quality. J. Agric. Food Chem. 2007, 55, 9330–9336. [Google Scholar] [CrossRef]
- Lee, J.E.; Lee, B.J.; Chung, J.O.; Hwang, J.A.; Lee, S.J.; Lee, C.H.; Hong, Y.S. Geographical and climatic dependencies of green tea (Camellia sinensis) metabolites: A 1H NMR-based metabolomics study. J. Agric. Food Chem. 2010, 58, 10582–10589. [Google Scholar] [CrossRef]
- Boffo, E.F.; Tavares, L.A.; Ferreira, M.M.; Ferreira, A.G. Classification of Brazilian vinegars according to their 1H NMR spectra by pattern recognition analysis. LWT-Food Sci. Technol. 2009, 42, 1455–1460. [Google Scholar] [CrossRef]
- Le Gall, G.; Colquhoun, I.J.; Defernez, M. Metabolite profiling using 1H NMR spectroscopy for quality assessment of green tea, Camellia sinensis (L.). J. Agric. Food Chem. 2004, 52, 692–700. [Google Scholar] [CrossRef] [PubMed]
- Shevchuk, A.; Jayasinghe, L.; Kuhnert, N. Differentiation of black tea infusions according to origin, processing and botanical varieties using multivariate statistical analysis of LC-MS data. Food Res. Int. 2018, 109, 387–402. [Google Scholar] [CrossRef] [PubMed]
- Zeng, L.; Fu, Y.Q.; Gao, Y.; Wang, F.; Liang, S.; Yin, J.F.; Fauconnier, M.L.; Ke, L.; Xu, Y.Q. Dynamic changes of key metabolites in Longjing green tea during processing revealed by widely targeted metabolomic profiling and sensory experiments. Food Chem. 2024, 450, 139373. [Google Scholar] [CrossRef]
- Estoup, A.; Lombaert, E.; MARIN, J.M.; Guillemaud, T.; Pudlo, P.; Robert, C.P.; Cornuet, J.M. Estimation of demo-genetic model probabilities with Approximate Bayesian Computation using linear discriminant analysis on summary statistics. Mol. Ecol. Resour. 2012, 12, 846–855. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.D.; Ma, J.; Wang, Q.J.; Sun, D.W. Applications of machine learning techniques for enhancing nondestructive food quality and safety detection. Crit. Rev. Food Sci. Nutr. 2023, 63, 1649–1669. [Google Scholar] [CrossRef] [PubMed]
- Fraser, K.; Lane, G.A.; Otter, D.E.; Hemar, Y.; Quek, S.Y.; Harrison, S.J.; Rasmussen, S. Analysis of metabolic markers of tea origin by UHPLC and high resolution mass spectrometry. Food Res. Int. 2013, 53, 827–835. [Google Scholar] [CrossRef]
- Xu, M.; Wang, J.; Zhu, L.Y. The qualitative and quantitative assessment of tea quality based on E-nose, E-tongue and E-eye combined with chemometrics. Food Chem. 2019, 289, 482–489. [Google Scholar] [CrossRef]
- Yu, X.-L.; Li, J.; Yang, Y.Q.; Zhu, J.Y.; Yuan, H.B.; Jiang, Y.W. Comprehensive investigation on flavonoids metabolites of Longjing tea in different cultivars, geographical origins, and storage time. Heliyon 2023, 9, e17305. [Google Scholar] [CrossRef]
- Ye, J.H.; Ye, Y.; Yin, J.F.; Jin, J.; Liang, Y.R.; Liu, R.Y.; Tang, P.; Xu, Y.Q. Bitterness and astringency of tea leaves and products: Formation mechanism and reducing strategies. Trends Food Sci. Technol. 2022, 123, 130–143. [Google Scholar] [CrossRef]
- Yu, Z.M.; Yang, Z.Y. Understanding different regulatory mechanisms of proteinaceous and non-proteinaceous amino acid formation in tea (Camellia sinensis) provides new insights into the safe and effective alteration of tea flavor and function. Crit. Rev. Food Sci. Nutr. 2020, 60, 844–858. [Google Scholar] [CrossRef]
- Jiang, H.; Yu, F.; Qin, L.; Zhang, N.; Cao, Q.; Schwab, W.; Li, D.X.; Song, C.K. Dynamic change in amino acids, catechins, alkaloids, and gallic acid in six types of tea processed from the same batch of fresh tea (Camellia sinensis L.) leaves. J. Food Compos. Anal. 2019, 77, 28–38. [Google Scholar] [CrossRef]
- Farag, M.A.; Elmetwally, F.; Elghanam, R.; Kamal, N.; Hellal, K.; Hamezah, H.S.; Zhao, C.; Mediani, A. Metabolomics in tea products; a compile of applications for enhancing agricultural traits and quality control analysis of Camellia sinensis. Food Chem. 2023, 404, 134628. [Google Scholar] [CrossRef] [PubMed]
- Chen, Q.C.; Shi, J.; Mu, B.; Chen, Z.; Dai, W.D.; Lin, Z. Metabolomics combined with proteomics provides a novel interpretation of the changes in nonvolatile compounds during white tea processing. Food Chem. 2020, 332, 127412. [Google Scholar] [CrossRef]
- Yang, C.; Cui, C.J.; Zhu, Y.Y.; Xia, X.Y.; Jin, G.; Liu, C.J.; Li, Y.Y.; Xue, X.H.; Hou, R.Y. Effect of brewing conditions on the chemical and sensory profiles of milk tea. Food Chem. X 2022, 16, 100453. [Google Scholar] [CrossRef] [PubMed]
- Yue, C.; Cao, H.L.; Wang, L.; Zhou, Y.H.; Huang, Y.T.; Hao, X.Y.; Wang, Y.C.; Wang, B.; Yang, Y.J.; Wang, X.C. Effects of cold acclimation on sugar metabolism and sugar-related gene expression in tea plant during the winter season. Plant Mol. Biol. 2015, 88, 591–608. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.W.; Li, T.Y.; Wang, Q.S.; LeCompte, J.; Harkess, R.L.; Bi, G.H. Screening tea cultivars for novel climates: Plant growth and leaf quality of Camellia sinensis cultivars grown in Mississippi, United States. Front. Plant Sci. 2020, 11, 280. [Google Scholar] [CrossRef]
- Lee, J.E.; Lee, B.J.; Chung, J.O.; Kim, H.N.; Kim, E.H.; Jung, S.; Lee, H.; Lee, S.J.; Hong, Y.S. Metabolomic unveiling of a diverse range of green tea (Camellia sinensis) metabolites dependent on geography. Food Chem. 2015, 174, 452–459. [Google Scholar] [CrossRef]
- Lai, G.P.; Cui, Y.Q.; Granato, D.; Wen, M.C.; Han, Z.S.; Zhang, L. Free, soluble conjugated and insoluble bonded phenolic acids in Keemun black tea: From UPLC-QQQ-MS/MS method development to chemical shifts monitoring during processing. Food Res. Int. 2022, 155, 111041. [Google Scholar] [CrossRef]
- Hou, Z.W.; Wang, Y.J.; Xu, S.S.; Wei, Y.M.; Bao, G.H.; Dai, Q.Y.; Deng, W.W.; Ning, J.M. Effects of dynamic and static withering technology on volatile and nonvolatile components of Keemun black tea using GC-MS and HPLC combined with chemometrics. LWT 2020, 130, 109547. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Metabolite | Chemical Shift, in ppm (Multiplicity) |
|---|---|---|
| 1 | Leucine | 0.97(d) |
| 2 | Isoleucine | 1.03, 1.98 |
| 3 | Theanine | 1.10, 2.13, 2.37, 3.19, 3.72 |
| 4 | Threonine | 1.36, 4.23 |
| 5 | Alanine | 1.46 (d), 3.84 |
| 6 | Arginine | 1.68 (m), 1.90 (m) |
| 7 | Lysine | 1.71 (m), 1.87 (m) |
| 8 | Glutamine | 2.01 |
| 9 | Quinic acid | 2.05 (m), 3.54 (dd), 4.04 (dd) |
| 10 | Acetic acid | 2.07 |
| 11 | Glutamic acid | 2.12 (m) |
| 12 | Chlorogenic acid | 2.17 (m), 5.33 (m) |
| 13 | Malic acid | 2.37 (dd), 2.63 (dd) |
| 14 | Succinic acid | 2.52 (s) |
| 15 | EGC | 2.62, 4.27, 6.06, 6.55, 6.80 |
| 16 | EGCG | 2.72, 3.08, 5.56, 6.59, 6.92 |
| 17 | ECG | 3.08, 4.81, 6.50, 6.95 |
| 18 | Caffeine | 3.22 (s), 3.38 (s), 3.77 (s) |
| 19 | Sucrose | 3.43, 3.65, 3.70, 4.08, 4.23 |
| 20 | α-glucose | 3.50, 5.16 (d) |
| 21 | Theogallin | 2.20, 3.84, 4.20 |
| 22 | Serine | 3.83, 3.97 (m) |
| 23 | Fructose | 3.56, 4.13 |
| 24 | β-glucose | 3.58, 4.58 |
| 25 | Rutin | 4.52 (d), 5.11 (d), 6.39 (d) |
| 26 | EC | 6.04, 6.11, 6.50, 6.87, 6.99 |
| 27 | Quercetin glycoside | 6.88, 7.63 |
| 28 | Kaempferol glycoside | 6.96 |
| 29 | Gallic acid | 7.07 (s) |
| 30 | Theobromine | 7.81 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, Z.; Jin, Y.; Gu, Z.; Zhang, R.; Su, Z.; Liu, S. 1H NMR Spectroscopy Combined with Machine-Learning Algorithm for Origin Recognition of Chinese Famous Green Tea Longjing Tea. Foods 2024, 13, 2702. https://doi.org/10.3390/foods13172702
Hou Z, Jin Y, Gu Z, Zhang R, Su Z, Liu S. 1H NMR Spectroscopy Combined with Machine-Learning Algorithm for Origin Recognition of Chinese Famous Green Tea Longjing Tea. Foods. 2024; 13(17):2702. https://doi.org/10.3390/foods13172702
Chicago/Turabian StyleHou, Zhiwei, Yugu Jin, Zhe Gu, Ran Zhang, Zhucheng Su, and Sitong Liu. 2024. "1H NMR Spectroscopy Combined with Machine-Learning Algorithm for Origin Recognition of Chinese Famous Green Tea Longjing Tea" Foods 13, no. 17: 2702. https://doi.org/10.3390/foods13172702
APA StyleHou, Z., Jin, Y., Gu, Z., Zhang, R., Su, Z., & Liu, S. (2024). 1H NMR Spectroscopy Combined with Machine-Learning Algorithm for Origin Recognition of Chinese Famous Green Tea Longjing Tea. Foods, 13(17), 2702. https://doi.org/10.3390/foods13172702