A Candy Defect Detection Method Based on StyleGAN2 and Improved YOLOv7 for Imbalanced Data


Abstract
1. Introduction
- (1)
- To address the issue of irrelevant information occupying a significant portion of space during the GAN-based generation of synthetic defective candy samples, we employed the foreground–background separation algorithm to isolate the labeled defective candy samples from the captured images one by one.
- (2)
- To mitigate the impact of data imbalance between complete and defective candy samples on model accuracy, based on StyleGAN2, we employed the isolated defective candy samples to generate synthetic images.
- (3)
- To enhance the performance of the defect detection model, we improved the YOLOv7 object detection model and integrated the global attention mechanism, thereby enabling the precise identification of small defects in candy samples.
2. Materials and Methods
2.1. Data Acquisition
2.2. Manual Data Augmentation
2.2.1. Noise Injection
2.2.2. Histogram Equalization
2.3. Generative Adversarial Network Data Augmentation
2.3.1. Foreground–Background Separation
2.3.2. Defective Candy Data Augmentation
2.4. Defective Candy Detection and Recognition
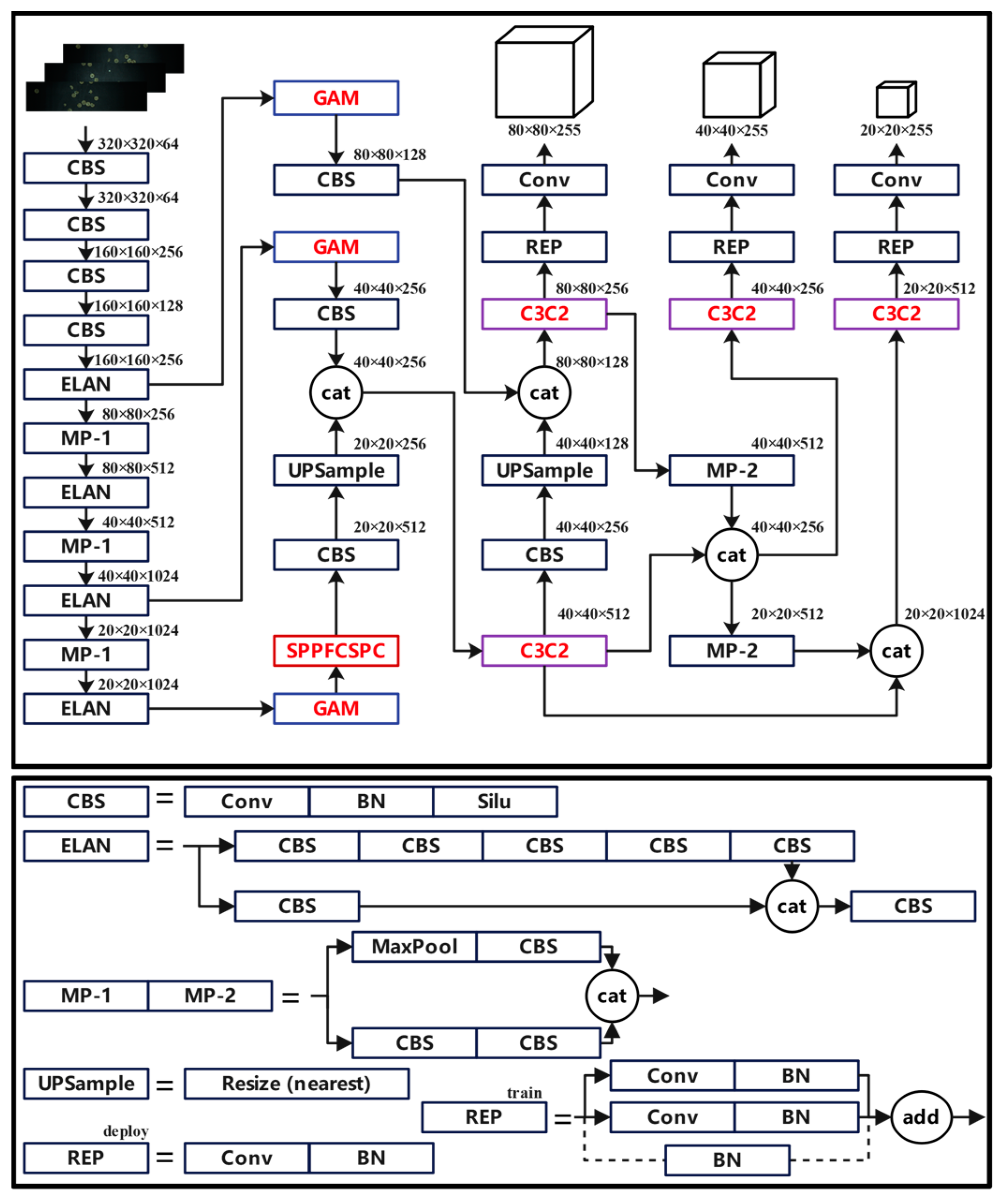
2.4.1. Improved YOLOv7 Detection Algorithm
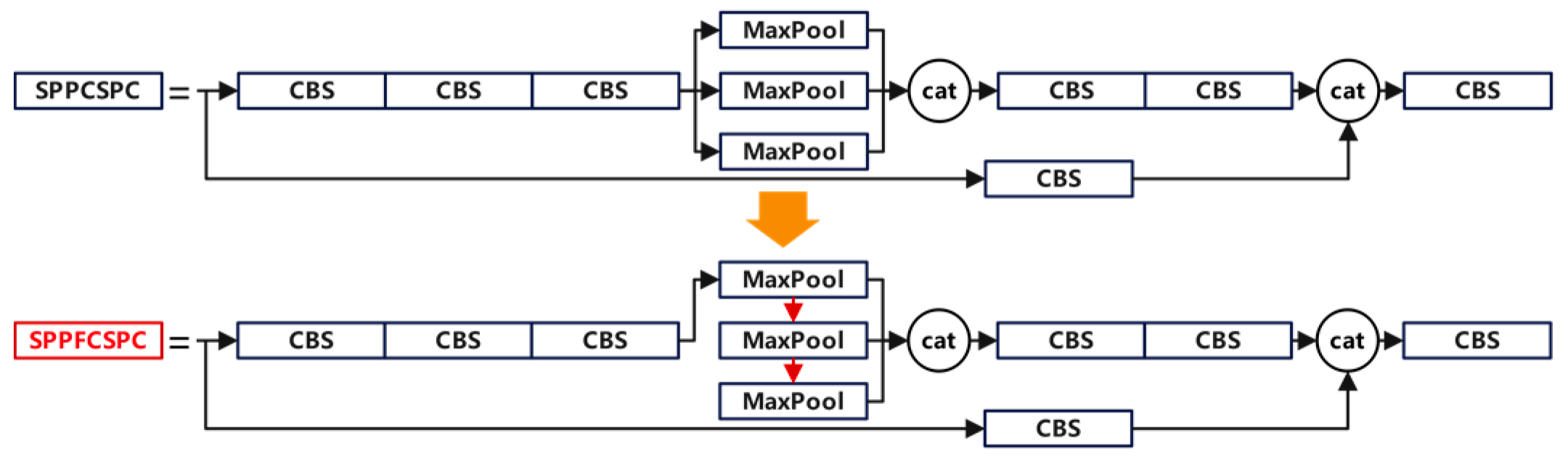
2.4.2. SPPFCSPC Module
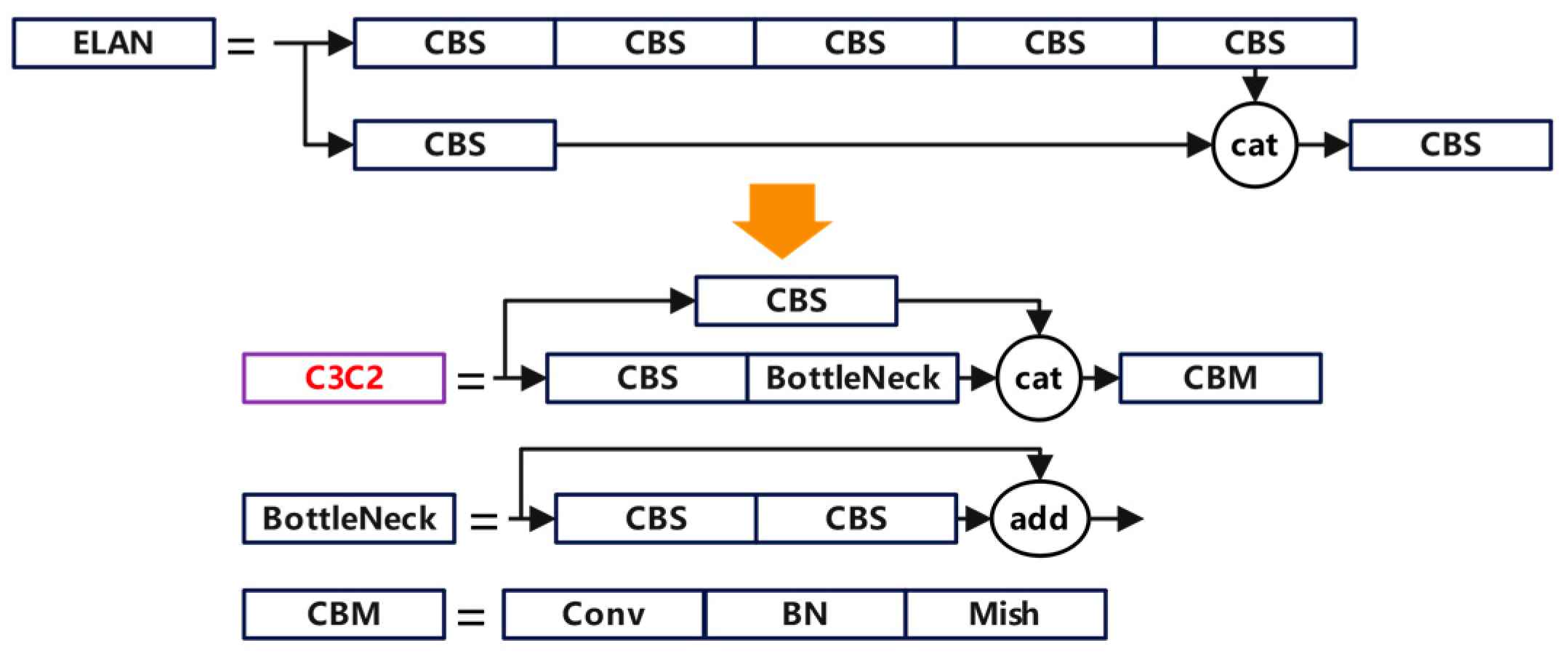
2.4.3. C3C2 Module
2.4.4. Global Attention Mechanism
2.5. Training Settings
2.6. Performance Evaluation
2.6.1. Fréchet Inception Distance
2.6.2. Learning Perceptual Image Patch Similarity
2.6.3. Multi-Scale Structural Similarity Index
2.6.4. Average Precision
2.7. Data Analysis and Application Deployment
2.7.1. Data Analysis
| Algorithm 1. StyleGAN2 latent vector and noise generation algorithm pseudocode. |
| StyleGAN2 latent vector noise |
| Input: Candy defective sample images and StyleGAN2 generator model Output: Latent vector and set of noise maps , 1: 2: 3: 4: 5: While not converge do 6: 7: 8: 9: While i in do 10: 11: 12: end while 13: 14: end while 15: return |
| Algorithm 2. StyleGAN2 generator generation algorithm pseudocode. |
| StyleGAN2 adapted generator |
| Input: Candy defective sample images , its corresponding closest latent vector , and StyleGAN2 generator Output: StyleGAN2 adapted generator 1: 2: 3: While not converging do 4: 5: 6: 7: 8: end while 9: return |
2.7.2. Application Deployment
3. Results
3.1. Generated Samples
3.2. Candy Defect Detection
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, K.; Zhao, M.; Li, Y.; He, Y.; Han, X.; Ma, X.; Ma, F. Spatiotemporal Trends of the Carbon Footprint of Sugar Production in China. Sustain. Prod. Consum. 2024, 46, 502–511. [Google Scholar] [CrossRef]
- Wang, J.; Li, Z.; Chen, Q.; Ding, K.; Zhu, T.; Ni, C. Detection and Classification of Defective Hard Candies Based on Image Processing and Convolutional Neural Networks. Electronics 2021, 10, 2017. [Google Scholar] [CrossRef]
- Kaushal, S.; Tammineni, D.K.; Rana, P.; Sharma, M.; Sridhar, K.; Chen, H.-H. Computer Vision and Deep Learning-Based Approaches for Detection of Food Nutrients/Nutrition: New Insights and Advances. Trends Food Sci. Technol. 2024, 146, 104408. [Google Scholar] [CrossRef]
- Zhu, L.; Spachos, P.; Pensini, E.; Plataniotis, K.N. Deep Learning and Machine Vision for Food Processing: A Survey. Curr. Res. Food Sci. 2021, 4, 233–249. [Google Scholar] [CrossRef]
- Teimouri, N.; Omid, M.; Mollazade, K.; Mousazadeh, H.; Alimardani, R.; Karstoft, H. On-Line Separation and Sorting of Chicken Portions Using a Robust Vision-Based Intelligent Modelling Approach. Biosyst. Eng. 2018, 167, 8–20. [Google Scholar] [CrossRef]
- Fan, S.; Li, J.; Zhang, Y.; Tian, X.; Wang, Q.; He, X.; Zhang, C.; Huang, W. On Line Detection of Defective Apples Using Computer Vision System Combined with Deep Learning Methods. J. Food Eng. 2020, 286, 110102. [Google Scholar] [CrossRef]
- Truong, V.D.; Xia, J.; Jeong, Y.; Yoon, J. An Automatic Machine Vision-Based Algorithm for Inspection of Hardwood Flooring Defects during Manufacturing. Eng. Appl. Artif. Intell. 2023, 123, 106268. [Google Scholar] [CrossRef]
- Wang, G.; Chen, S.; Hu, G.; Pang, D.; Wang, Z. Detection Algorithm of Abnormal Flow State Fluid on Closed Vibrating Screen Based on Improved YOLOv5. Eng. Appl. Artif. Intell. 2023, 123, 106272. [Google Scholar] [CrossRef]
- Xiao, Z.; Wang, J.; Han, L.; Guo, S.; Cui, Q. Application of Machine Vision System in Food Detection. Front. Nutr. 2022, 9, 888245. [Google Scholar] [CrossRef]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-Shot Refinement Neural Network for Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Salt Lake City, UT, USA, 2018; pp. 4203–4212. [Google Scholar]
- Chou, Y.-C.; Kuo, C.-J.; Chen, T.-T.; Horng, G.-J.; Pai, M.-Y.; Wu, M.-E.; Lin, Y.-C.; Hung, M.-H.; Su, W.-T.; Chen, Y.-C.; et al. Deep-Learning-Based Defective Bean Inspection with GAN-Structured Automated Labeled Data Augmentation in Coffee Industry. Appl. Sci. 2019, 9, 4166. [Google Scholar] [CrossRef]
- Guo, Z.; Zheng, H.; Xu, X.; Ju, J.; Zheng, Z.; You, C.; Gu, Y. Quality Grading of Jujubes Using Composite Convolutional Neural Networks in Combination with RGB Color Space Segmentation and Deep Convolutional Generative Adversarial Networks. J. Food Process Eng. 2021, 44, e13620. [Google Scholar] [CrossRef]
- Abdullah-Al-Wadud, M.; Kabir, M.; Akber Dewan, M.; Chae, O. A Dynamic Histogram Equalization for Image Contrast Enhancement. IEEE Trans. Consum. Electron. 2007, 53, 593–600. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A Survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Subur, J.; Sardjono, T.A.; Mardiyanto, R. Braille Character Recognition Using Find Contour Method. In Proceedings of the 2015 International Conference on Electrical Engineering and Informatics (ICEEI), Bali, Indonesia, 10–11 August 2015; pp. 699–703. [Google Scholar]
- Huang, N.; Huang, Z.; Fu, C.; Zhou, H.; Xia, Y.; Li, W.; Xiong, X.; Cai, S. A Multiview Stereo Algorithm Based on Image Segmentation Guided Generation of Planar Prior for Textureless Regions of Artificial Scenes. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 3676–3696. [Google Scholar] [CrossRef]
- Song, D.; Xu, X.; Cui, X.; Ou, Y.; Chen, W. Bolt Looseness Detection Based on Canny Edge Detection Algorithm. Concurr. Comput. 2023, 35, e7713. [Google Scholar] [CrossRef]
- Zhao, Y.; Kang, Z.; Chen, L.; Guo, Y.; Mu, Q.; Wang, S.; Zhao, B.; Feng, C. Quality Classification of Kiwifruit under Different Storage Conditions Based on Deep Learning and Hyperspectral Imaging Technology. Food Meas. 2023, 17, 289–305. [Google Scholar] [CrossRef]
- He, X.; Chang, Z.; Zhang, L.; Xu, H.; Chen, H.; Luo, Z. A Survey of Defect Detection Applications Based on Generative Adversarial Networks. IEEE Access 2022, 10, 113493–113512. [Google Scholar] [CrossRef]
- Yang, G.; Song, C.; Yang, Z.; Cui, S. Bubble Detection in Photoresist with Small Samples Based on GAN Augmentations and Modified YOLO. Eng. Appl. Artif. Intell. 2023, 123, 106224. [Google Scholar] [CrossRef]
- Bai, Z.; Pei, X.; Qiao, Z.; Wu, G.; Bai, Y. Improved YOLOv7 Target Detection Algorithm Based on UAV Aerial Photography. Drones 2024, 8, 104. [Google Scholar] [CrossRef]
- Chang, R.; Zhou, S.; Zhang, Y.; Zhang, N.; Zhou, C.; Li, M. Research on Insulator Defect Detection Based on Improved YOLOv7 and Multi-UAV Cooperative System. Coatings 2023, 13, 880. [Google Scholar] [CrossRef]
- Cheng, C.; Wang, C.; Yang, D.; Wen, X.; Liu, W.; Zhang, F. Underwater Small Target Detection Based on Dynamic Convolution and Attention Mechanism. Front. Mar. Sci. 2024, 11, 1348883. [Google Scholar] [CrossRef]
- Paolini, M.; Tonidandel, L.; Larcher, R. Development, Validation and Application of a Fast GC-FID Method for the Analysis of Volatile Compounds in Spirit Drinks and Wine. Food Control 2022, 136, 108873. [Google Scholar] [CrossRef]
- Sun, H.; Wu, S.; Ma, L. Adversarial Attacks on GAN-Based Image Fusion. Inf. Fusion 2024, 108, 102389. [Google Scholar] [CrossRef]
- Bamoriya, P.; Siddhad, G.; Kaur, H.; Khanna, P.; Ojha, A. DSB-GAN: Generation of Deep Learning Based Synthetic Biometric Data. Displays 2022, 74, 102267. [Google Scholar] [CrossRef]
- Kang, L.; Lu, Z.; Meng, L.; Gao, Z. YOLO-FA: Type-1 Fuzzy Attention Based YOLO Detector for Vehicle Detection. Expert Syst. Appl. 2024, 237, 121209. [Google Scholar] [CrossRef]
- Liu, Y.; Fan, H.; Yuan, X.; Xiang, J. GL-GAN: Adaptive Global and Local Bilevel Optimization for Generative Adversarial Network. Pattern Recognit. 2022, 123, 108375. [Google Scholar] [CrossRef]
- Viola, J.; Chen, Y.; Wang, J. FaultFace: Deep Convolutional Generative Adversarial Network (DCGAN) Based Ball-Bearing Failure Detection Method. Inf. Sci. 2021, 542, 195–211. [Google Scholar] [CrossRef]
- Le, X.; Mei, J.; Zhang, H.; Zhou, B.; Xi, J. A Learning-Based Approach for Surface Defect Detection Using Small Image Datasets. Neurocomputing 2020, 408, 112–120. [Google Scholar] [CrossRef]
- Rayhana, R.; Jiao, Y.; Bahrami, Z.; Liu, Z.; Wu, A.; Kong, X. Valve Detection for Autonomous Water Pipeline Inspection Platform. IEEE/ASME Trans. Mechatron. 2022, 27, 1070–1080. [Google Scholar] [CrossRef]
- Kim, Y.; Lee, T.; Hyun, Y.; Coatanea, E.; Mika, S.; Mo, J.; Yoo, Y. Self-Supervised Representation Learning Anomaly Detection Methodology Based on Boosting Algorithms Enhanced by Data Augmentation Using StyleGAN for Manufacturing Imbalanced Data. Comput. Ind. 2023, 153, 104024. [Google Scholar] [CrossRef]
- Soeb, M.J.A.; Jubayer, M.F.; Tarin, T.A.; Al Mamun, M.R.; Ruhad, F.M.; Parven, A.; Mubarak, N.M.; Karri, S.L.; Meftaul, I.M. Tea Leaf Disease Detection and Identification Based on YOLOv7 (YOLO-T). Sci Rep 2023, 13, 6078. [Google Scholar] [CrossRef] [PubMed]
- Zhao, C.; Shu, X.; Yan, X.; Zuo, X.; Zhu, F. RDD-YOLO: A Modified YOLO for Detection of Steel Surface Defects. Measurement 2023, 214, 112776. [Google Scholar] [CrossRef]
- Yu, L.; Qian, M.; Chen, Q.; Sun, F.; Pan, J. An Improved YOLOv5 Model: Application to Mixed Impurities Detection for Walnut Kernels. Foods 2023, 12, 624. [Google Scholar] [CrossRef] [PubMed]
- Feng, J.; Wang, Z.; Wang, S.; Tian, S.; Xu, H. MSDD-YOLOX: An Enhanced YOLOX for Real-Time Surface Defect Detection of Oranges by Type. Eur. J. Agron. 2023, 149, 126918. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | FID ↓ | LPIPS ↓ | MS-SSIM ↑ |
|---|---|---|---|
| DCGAN | 33.9 | 0.178 | 0.724 |
| WGAN | 37.7 | 0.186 | 0.776 |
| BigGAN | 7.8 | 0.172 | 0.804 |
| StyleGAN | 4.1 | 0.147 | 0.731 |
| StyleGAN2 | 2.6 | 0.113 | 0.893 |
| Batch Size | Epochs | LWeight_Decay | Learning_Rate |
|---|---|---|---|
| 16 | 600 | 0.0005 | 0.01 |
| Model | Precision | Recall | ||
|---|---|---|---|---|
| Faster R-CNN | 0.833 | 0.791 | 0.853 | 0.603 |
| YOLOv5 | 0.929 | 0.878 | 0.935 | 0.757 |
| YOLOX | 0.942 | 0.892 | 0.946 | 0.778 |
| YOLOv7 | 0.951 | 0.926 | 0.955 | 0.769 |
| Improved YOLOv7 | 0.981 | 0.962 | 0.977 | 0.806 |
| Model | Precision | Recall | Speed (ms) | Size (Mb) | |
|---|---|---|---|---|---|
| YOLOv7 | 0.951 | 0.925 | 0.769 | 10.9 | 73.1 |
| YOLOv7-SPPFCSPC | 0.950 | 0.928 | 0.771 | 7.6 | 48.8 |
| YOLOv7-SPPFCSPC-C3C2 | 0.977 | 0.949 | 0.799 | 7.2 | 43.7 |
| YOLOv7-SPPFCSPC-GAM | 0.948 | 0.965 | 0.783 | 7.9 | 50.3 |
| YOLOv7-SPPFCSPC-C3C2-GAM | 0.981 | 0.962 | 0.806 | 7.3 | 43.1 |
| Methods | Precision | Recall | ||
|---|---|---|---|---|
| Original | 0.923 | 0.916 | 0.945 | 0.748 |
| Original + Manual data augmentation | 0.927 | 0.915 | 0.939 | 0.752 |
| Original + StyleGAN2 | 0.977 | 0.955 | 0.977 | 0.794 |
| Original + Manual data augmentation + StyleGAN2 | 0.981 | 0.962 | 0.971 | 0.806 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Xue, S.; Li, Z.; Fang, X.; Zhu, T.; Ni, C. A Candy Defect Detection Method Based on StyleGAN2 and Improved YOLOv7 for Imbalanced Data. Foods 2024, 13, 3343. https://doi.org/10.3390/foods13203343
Li X, Xue S, Li Z, Fang X, Zhu T, Ni C. A Candy Defect Detection Method Based on StyleGAN2 and Improved YOLOv7 for Imbalanced Data. Foods. 2024; 13(20):3343. https://doi.org/10.3390/foods13203343
Chicago/Turabian StyleLi, Xingyou, Sheng Xue, Zhenye Li, Xiaodong Fang, Tingting Zhu, and Chao Ni. 2024. "A Candy Defect Detection Method Based on StyleGAN2 and Improved YOLOv7 for Imbalanced Data" Foods 13, no. 20: 3343. https://doi.org/10.3390/foods13203343
APA StyleLi, X., Xue, S., Li, Z., Fang, X., Zhu, T., & Ni, C. (2024). A Candy Defect Detection Method Based on StyleGAN2 and Improved YOLOv7 for Imbalanced Data. Foods, 13(20), 3343. https://doi.org/10.3390/foods13203343