Abstract
Food recognition from images is crucial for dietary management, enabling applications like automated meal tracking and personalized nutrition planning. However, challenges such as background noise disrupting intra-class consistency, inter-class distinction, and domain shifts due to variations in capture angles, lighting, and image resolution persist. This study proposes a multi-stage convolutional neural network-based framework incorporating a boundary-aware module (BAM) for boundary region perception, deformable ROI pooling (DRP) for spatial feature refinement, a transformer encoder for capturing global contextual relationships, and a NetRVLAD module for robust feature aggregation. The framework achieved state-of-the-art performance on three benchmark datasets, with Top-1 accuracies of 99.80% on the Food-5k dataset, 99.17% on the Food-101 dataset, and 85.87% on the Food-2k dataset, significantly outperforming existing methods. This framework holds promise as a foundational tool for intelligent dietary management, offering robust and accurate solutions for real-world applications.
1. Introduction
Food recognition, typically referring to the classification of food types through image analysis, is a foundational task in food computing [1]. It plays a significant role in promoting healthy dietary management by helping individuals monitor their nutrient intake, avoid allergenic ingredients, and prevent diet-related health conditions such as hypertension, diabetes, heart disease, stroke, and cancer [2,3,4]. According to the World Health Organization (WHO), maintaining a healthy diet is fundamental to overall health, well-being, and optimal growth and development [5]. However, the significance of maintaining healthy diets is frequently underestimated, as most individuals lack proactive awareness and professional knowledge about nutrient intake and diet-related diseases [6]. Additionally, access to professional dietary guidance, such as from nutritionists, remains limited. This is particularly true in low- and middle-income countries, as well as in regions experiencing high levels of food insecurity [7].
With the rapid advancement of artificial intelligence, automatic food recognition leveraging deep learning (DL) techniques has achieved remarkable progress in various applications, such as dietary assessment, health monitoring, and mobile food-tracking applications [8,9,10]. Bossard et al. developed a large-scale image dataset comprising 101 food categories (named Food-101) for food recognition tasks and proposed an AlexNet [11]-based network, achieving a Top-1 accuracy of 56.4% [12]. The Food-101 dataset has been widely used and has become an important benchmark for evaluating food recognition tasks. VijayaKumari et al. proposed an Efficientnet-b0-based transfer learning framework, achieving a Top-1 accuracy of 80% [13]. Hamid et al. proposed a deep convolutional neural network with 54 layers to capture more complex feature representations, achieving a Top-1 accuracy of 88.28% [14]. Deng et al. proposed an attention-guided ConvNeXt-based framework [15] focusing on salient features specific to food items, achieving a Top-1 accuracy of 91.12% [16].
Despite the explorations and advancements achieved by these methods in food recognition, their performance remains limited, with challenges such as distinguishing subtle differences between food items and the insufficient scale and diversity of existing datasets, hindering further progress [17,18]. However, in our view, existing methods primarily focus on enhancing the backbone network by increasing its depth or introducing complex modules to improve feature representation capabilities. While these approaches have achieved certain performance gains, they fail to address the challenge of distinguishing subtle differences between food items.
We believe this issue is twofold: (1) The location information of food within an image is critical, as background elements can introduce noise. If a model places undue focus on background regions, it may struggle with intra-class consistency, leading to instability during learning, or confuse inter-class differences when items share similar backgrounds. (2) Existing food recognition datasets are usually collected from the internet and annotated manually. These datasets often exhibit significant variations in capture angles, lighting conditions, and devices, leading to notable differences in perspective, color distribution, and image resolution for the same food item. Such discrepancies amplify intra-class variability and domain-shift challenges.
To address these challenges, this paper presents a modular, multi-stage deep learning framework for food recognition named CBDTN. The proposed framework consists of three main components, i.e., the ConvNeXt-based backbone network, the boundary-aware module (BAM) and deformable ROI pooling (DRP), and the transformer encoder and the NetRVLAD module [19], with the following main contributions:
- A boundary-aware module is proposed to enhance edge perception and is paired with a spatial attention mechanism to refine global features. By employing deformable ROI pooling to extract multi-regional local features from the upsampled global features, it constructs a unified global-local feature space that effectively captures both fine-grained details and contextual information.
- A transformer encoder is employed to capture and integrate global and local features, followed by a NetRVLAD module for extracting relationships and aggregating features from them. This design ensures rotation-invariant features, reduces intra-class variations and domain shifts, and enhances the consistency and reliability of food recognition.
- The proposed CBDTN framework achieves excellent accuracy and generalization, achieving Top-1 accuracies of 99.80%, 99.17%, and 85.87% on three public food recognition benchmarks. The three datasets, which consist of 2, 101, and 2000 food categories with sizes of 5 K, 100 K, and 1 M images, respectively, highlight CBDTN’s superior cross-domain performance and its potential as a robust tool for food recognition in intelligent dietary management systems.
2. Related Works
2.1. Food Recognition
Food recognition has garnered significant attention in recent years due to its broad applications in dietary management, health monitoring, and personalized nutrition [20]. As a foundational task in computer vision, food recognition presents unique challenges related to intra-class variability (e.g., different food preparations) and inter-class similarity (e.g., visually similar dishes). These challenges have been extensively addressed using deep learning-based methods, many of which have been evaluated on public datasets containing a diverse range of food categories [21,22,23].
Several methods have leveraged deep learning to improve food recognition accuracy. Gao et al. incorporated data augmentation and feature enhancement into vision transformers [24] to enhance the model’s global feature representation capability, achieving a Top-1 accuracy of 95.17% on standard datasets [25]. Similarly, Sheng et al. focused on the trade-off between performance and efficiency, proposing a lightweight vision transformer-based hybrid network that achieved a Top-1 accuracy of 90.7% [26]. These approaches have made notable strides but often require either high computational resources or compromise efficiency for better performance.
Early approaches primarily focused on small-scale datasets, achieving limited generalization across different food categories. Recent advances have been fueled by the introduction of larger and more diverse datasets, such as Food-2K [18], which stands out as the largest food dataset to date and is often referred to as the “ImageNet” of food recognition. The availability of such large-scale datasets has opened up new opportunities but also introduced significant challenges. One of the main challenges is the computational complexity and memory requirements for training models on such extensive datasets. Moreover, the wide variety of food items and their presentation styles (e.g., different cooking methods and cultural variations) present difficulties in achieving robust and generalized recognition. In our study, we take advantage of the larger, more challenging datasets, including Food-2K, to explore the scalability and cross-domain generalization of food recognition models. The comprehensive evaluation of datasets of varying scales highlights the versatility and scalability of our method, providing a solid foundation for tackling the challenges posed by large-scale food recognition tasks.
2.2. Network Architecture
The development of convolutional neural networks (CNNs) has significantly advanced image analysis, driving major improvements across a wide range of tasks, particularly in computer vision. Early architectures like AlexNet [11] demonstrated the potential of deep learning for visual feature extraction, establishing a strong foundation for image classification. Building on this, more advanced CNNs such as ResNet [27] introduced deeper, more efficient designs that alleviated issues like vanishing gradients and enabled the extraction of more complex features. These improvements pushed the boundaries of performance in visual tasks, leading to substantial progress in object recognition and classification.
In the context of food recognition, CNN-based models have been widely adopted. However, as the need for handling more diverse, larger, and complex datasets arose, transformer-based architectures [28,29] began to gain popularity. By leveraging self-attention mechanisms, transformers excel in capturing long-range dependencies and contextual relationships, providing an advantage over CNNs in certain vision tasks. However, these architectures often come with higher computational costs and memory requirements, which limit their applicability in resource-constrained environments.
In response to these challenges, ConvNeXt [15] was introduced as an improved CNN framework inspired by transformer designs. ConvNeXt achieves superior performance over traditional CNNs and vision transformers while maintaining a more efficient computational profile. This makes it well suited for large-scale and real-time applications where both performance and efficiency are critical. Motivated by these advantages, our work adopts ConvNeXt as the backbone network, enabling high-quality feature extraction for food recognition tasks. This choice allows us to balance computational efficiency and performance, ensuring that the model can effectively handle the challenges posed by large-scale datasets while providing robust and accurate feature representations.
To further improve food recognition, we proposed and integrated several components into our framework, including the boundary-aware module (BAM), deformable ROI pooling (DRP), and a transformer encoder, followed by the NetRVLAD module. These components work synergistically to capture both global and local features, improving the model’s ability to address challenges such as intra-class variability, inter-class similarity, and domain shifts, which are commonly encountered in food recognition tasks. By combining a state-of-the-art backbone architecture with these specialized components, our approach pushes the boundaries of food recognition, achieving superior accuracy across multiple benchmark datasets of varying scales.
3. Materials and Methods
3.1. Overview of the Proposed Framework
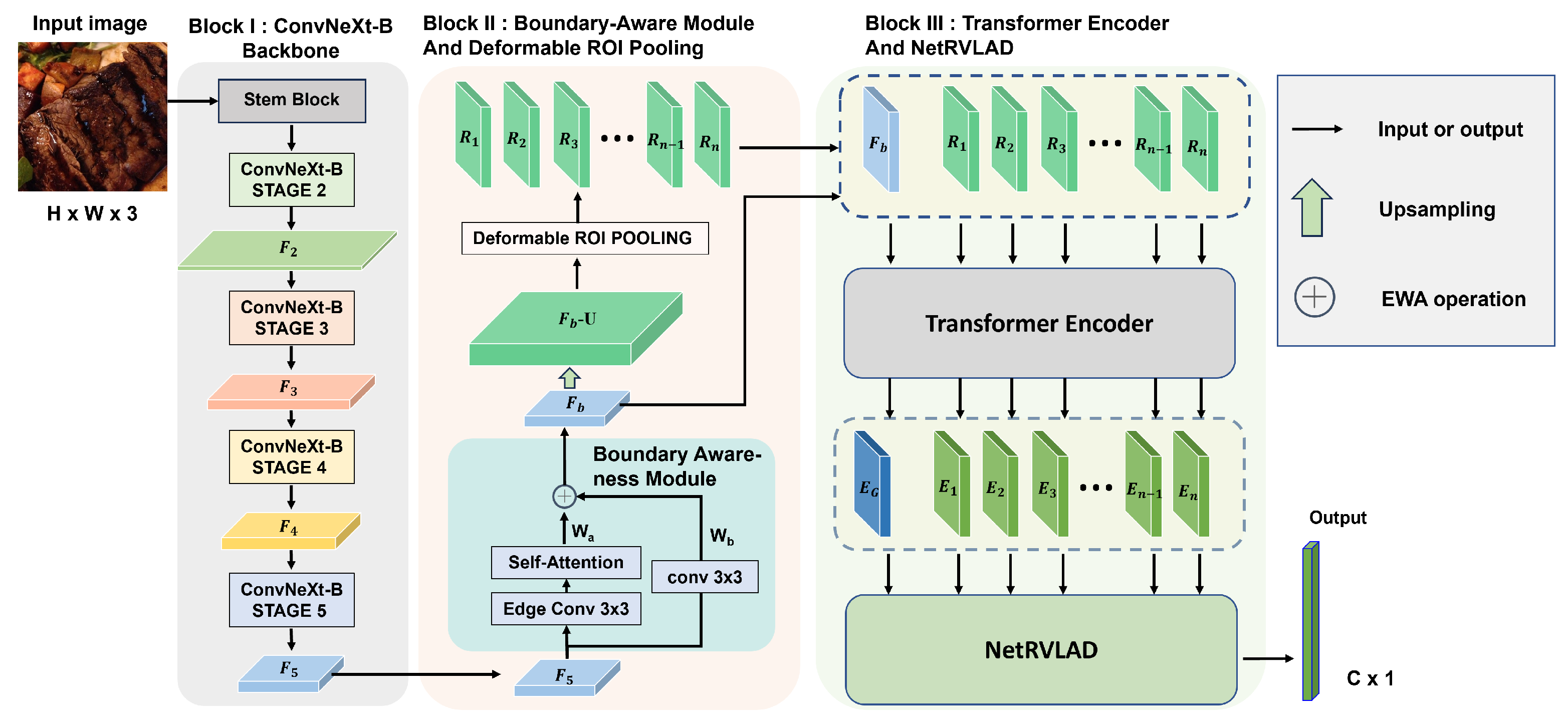
The proposed multi-stage DL framework, called CBDTN, is a CNN-based architecture consisting of three blocks: the ConvNeXt-based backbone for high-quality feature extraction, the BAM and DRP to refine the features and construct a global-local feature space, and the transformer encoder with the NetRVLAD module to model feature relationships and perform aggregation. As shown in Figure 1, Block I is the ConvNeXt-based backbone network, consisting of a stem block for processing input images and four stages that progressively extract hierarchical features, enabling robust and multi-scale feature representation. In Block II, the features extracted by the backbone network are first processed by the BAM to obtain boundary-sensitive global features. These features are then upsampled to generate feature maps with larger sizes. The upsampled feature maps are further processed using DRP to extract region-level local features with the same sizes as the boundary-sensitive global features. The global and local features are stacked to form a unified feature space, which serves as the input for Block III. In Block III, the input feature space is treated as a sequence and fed into a transformer encoder to model long-range relationships, producing encoded features. These encoded features are then passed to the NetRVLAD module, which performs clustering and soft assignment across different clusters to effectively aggregate diverse information within the feature space. This process enhances the utilization of convolutional features, improving the representational capacity of images within the same category while increasing the discriminative power of images across different categories. The final output, after passing through batch normalization (BN) and a softmax function, produces a feature vector of size , where C represents the number of categories. This vector is used to represent the discriminative probabilities for each class, facilitating the classification of input images into their respective categories. The framework employs the cross-entropy loss function to optimize the classification performance, which is defined as
where N is the number of samples in a batch, C is the number of classes, is the ground-truth label for sample i and class j, and is the predicted probability for the same.
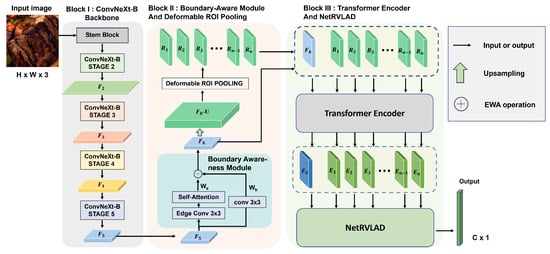
Figure 1.
The proposed framework. The framework consists of three blocks, including the ConvNeXt-based backbone, the BAM and DRP, and the transformer encoder with the NetRVLAD module, for food recognition.
3.2. Block I: The ConvNeXt Architecture
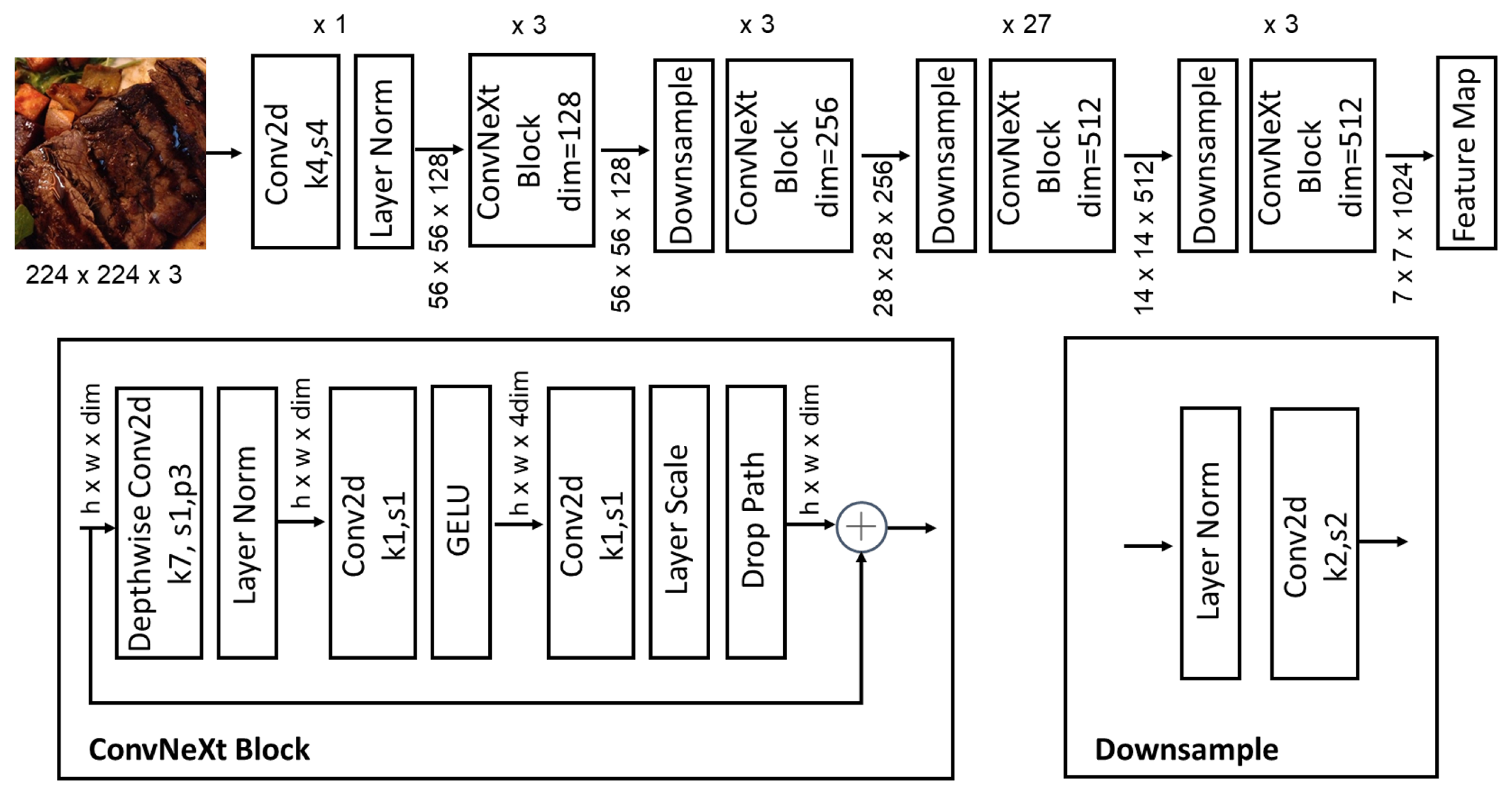
The proposed framework employs a ConvNeXt-based architecture [15] as its backbone, which is designed for efficient and hierarchical feature extraction, as depicted in Figure 1. The network begins with a stem block, which processes the input image to generate an initial feature map. The stem block utilizes a convolutional layer with a relatively large kernel size, followed by normalization (LayerNorm [30]) and a non-linear activation function (GELU [31]), capturing low-level spatial features while maintaining computational efficiency. Following the stem block, the backbone is divided into four hierarchical stages (Stage 2–Stage 5), each responsible for extracting increasingly abstract and semantically rich features. The transition between stages is facilitated by strided convolutions, which downsample the feature maps, effectively increasing the receptive field. The detailed structure of the ConvNeXt-based network is shown in Figure 2.
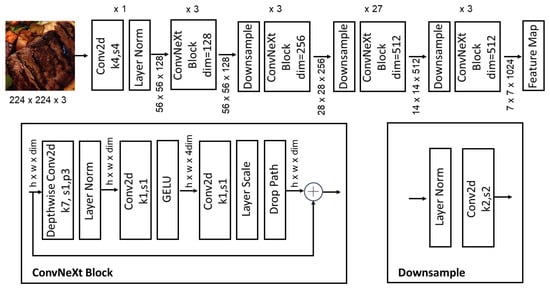
Figure 2.
The detailed structure of the ConvNeXt-based network.
In each stage, the ConvNeXt-based architecture employs depthwise separable convolutions to enhance computational efficiency. This operation decomposes standard convolutions into depthwise and pointwise convolutions, significantly reducing the parameter count while preserving expressive power. For a given input tensor , the depthwise convolution is expressed as
where is the depthwise convolutional kernel, and the pointwise convolution refines the output channels to through
where is the pointwise kernel. The network incorporates residual connections, denoted as
where represents the transformation function within each block. This design enhances gradient flow, mitigates vanishing gradients, and facilitates the training of deeper networks.
Feature maps are sequentially computed as and in Stages 2 through 5, respectively. Each stage increases the number of channels and computational depth, enabling the model to capture fine-grained and high-level semantic information. Specifically, the hierarchical structure ensures that lower stages extract local patterns, while higher stages focus on global context and object-level semantics. The final output, , serves as a compact yet information-rich representation for downstream tasks.
3.3. Block II: The Boundary-Aware Module and Deformable ROI Pooling
The boundary-aware module is designed to enhance feature representation by explicitly incorporating boundary information and combining it with semantic features through a self-attention mechanism and weighted feature fusion. The module first extracts edge information using a Sobel filter-based convolution operator, which applies edge detection in the horizontal and vertical directions to emphasize boundary details. The edge features are subsequently passed through a convolutional layer, followed by a self-attention mechanism. This mechanism takes the features as input and transforms them into query (Q), key (K), and value (V) matrices through learnable linear projections:
where F represents the input feature map and are the learnable weight matrices. The self-attention mechanism computes the attention weights by taking the scaled dot product of Q and K:
where is the dimensionality of the key vectors. The output of the self-attention mechanism is then obtained by weighting V with the computed attention map:
The self-attention output enhances the edge-aware feature representation by capturing long-range dependencies. This output is combined with semantic features extracted directly via a parallel convolutional operation. The two feature maps are fused through an element-wise addition weighted by the learnable parameters and :
where represents the boundary-aware feature map, denotes the enhanced features obtained via self-attention, and corresponds to the semantic features.
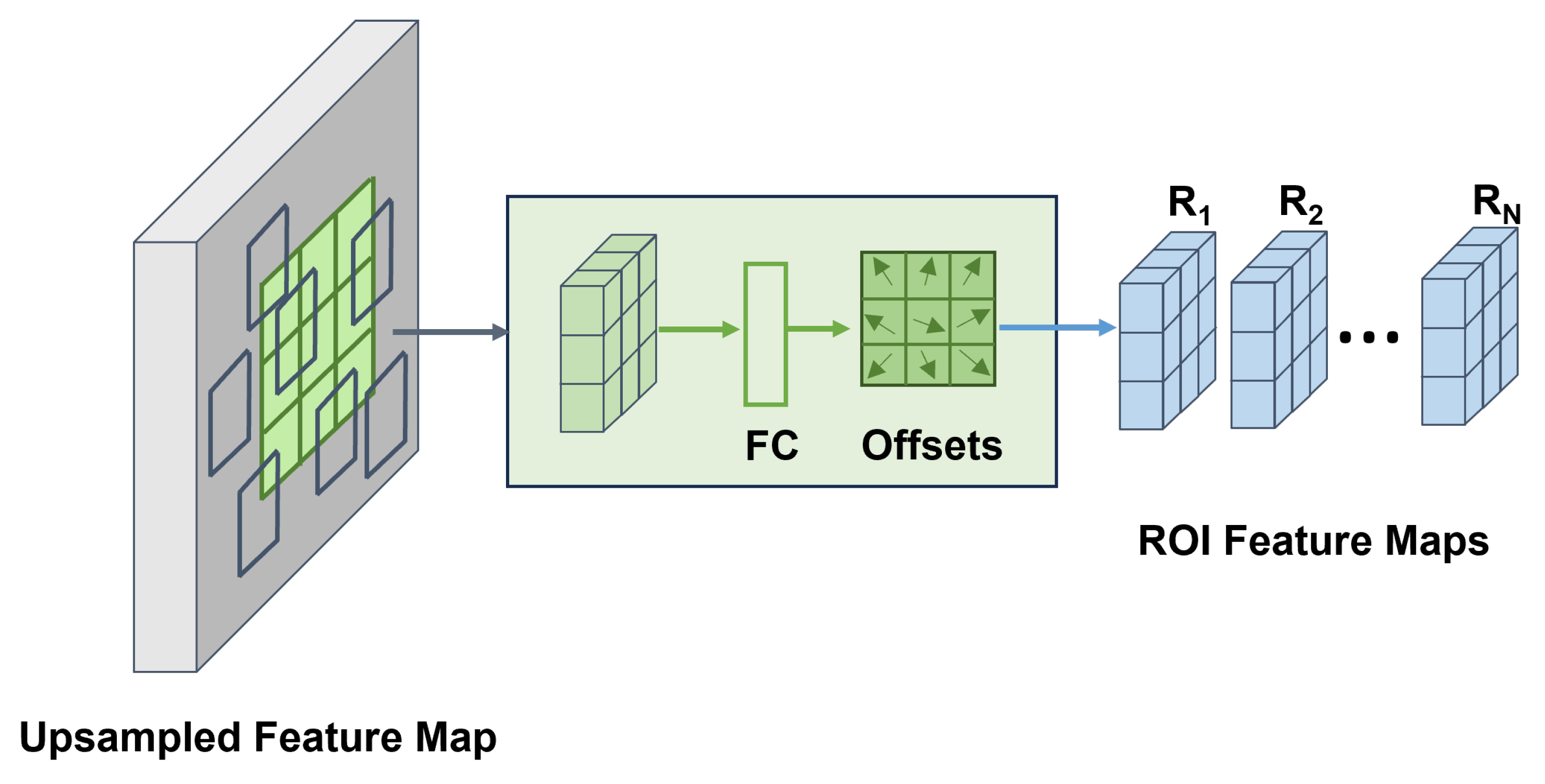
The boundary-aware feature map is then upsampled to a resolution of , where N is a tunable hyperparameter. In our model, N is set to 42, ensuring that the upsampled feature map preserves both spatial resolution and boundary sensitivity. As shown in Figure 3, the upsampled feature map undergoes deformable ROI pooling, a process designed to adaptively aggregate features from regions of interest (ROIs) while accommodating geometric variations. Unlike standard ROI pooling, which applies fixed spatial bins, deformable ROI pooling predicts offsets for each bin based on the input feature map, thereby enhancing its ability to capture fine-grained and spatially misaligned features. For a given set of n ROIs, deformable ROI pooling produces feature maps, denoted as , all with consistent dimensions.
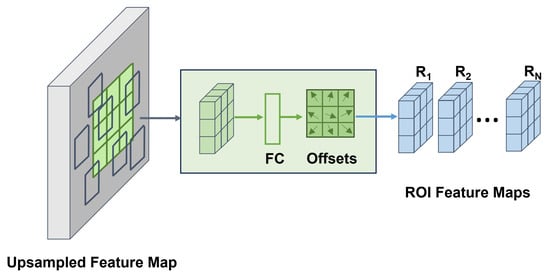
Figure 3.
The structure of deformable ROI pooling module.
The resulting ROI-specific features are combined with to form a unified global-local feature space, effectively integrating boundary-aware global features and region-specific local features. This composite feature space serves as the input to Block III, enabling robust downstream processing. The boundary-aware module thus provides a mechanism for capturing both contextual and boundary-sensitive details, crucial for tasks requiring precise spatial understanding.
3.4. Block III: The Transformer Encoder and the NetRVLAD Module
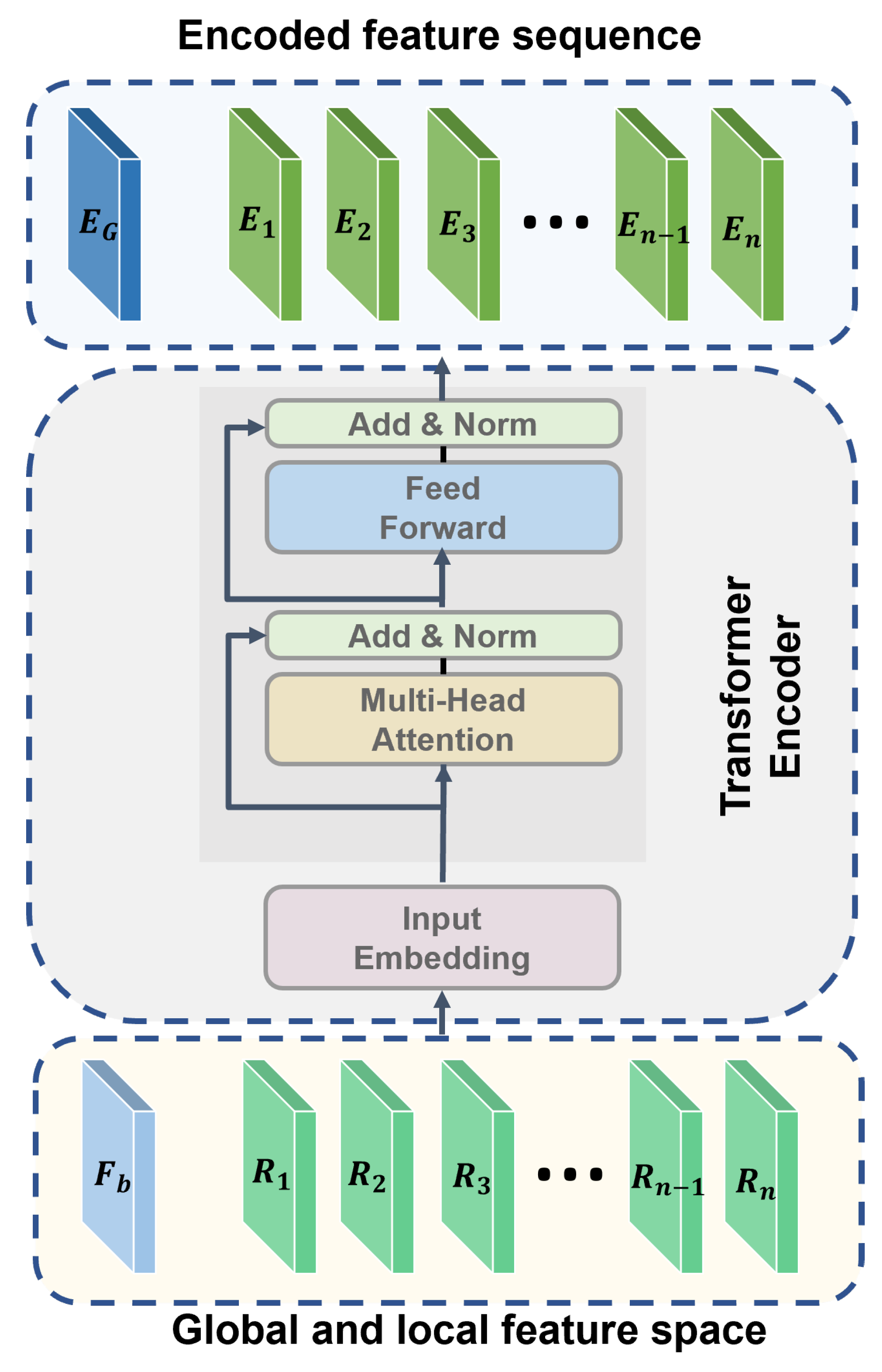
The transformer encoder module is designed to encode both global and local features into a unified sequence representation, which is subsequently processed for classification. As shown in Figure 4, the input to this module consists of global features and region-specific local features . These inputs are first projected onto a fixed-dimensional embedding space using a learnable linear projection layer:
where is the learnable weight matrix and represents the projected input embeddings. The sequence of embeddings is then passed through a transformer encoder block. Each encoder block consists of a multi-head self-attention mechanism, followed by layer normalization and a position-wise feed-forward network.
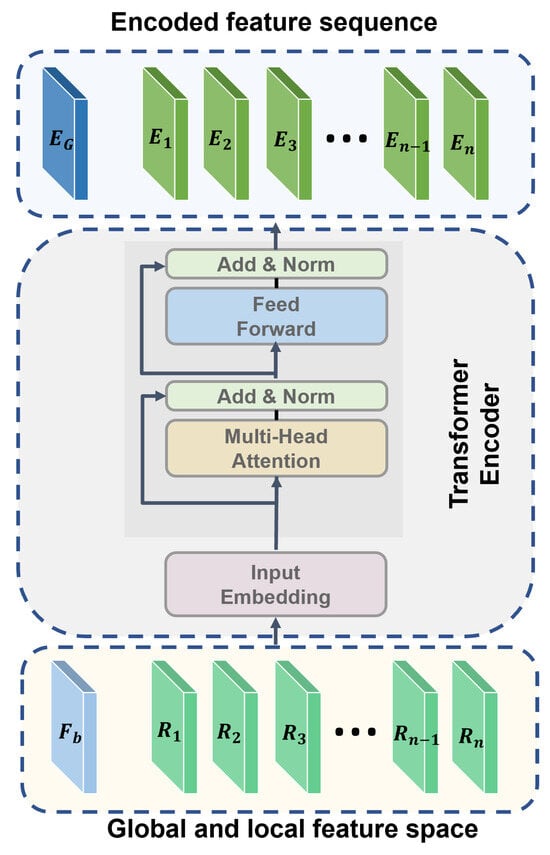
Figure 4.
The structure of the deformable ROI pooling module.
The multi-head self-attention mechanism calculates the attention weights by projecting the input embeddings onto query (Q), key (K), and value (V) matrices:
where are the learnable projection matrices. The attention output is computed as
where is the dimensionality of the key vectors. The attention output is subjected to dropout and added back to the input via a residual connection, followed by layer normalization:
Next, the normalized attention output is passed through a feed-forward neural network (FFNN) consisting of two dense layers with ReLU activation:
where and are learnable parameters. A second residual connection and layer normalization are applied to produce the final encoded features:
The output of the encoder is a sequence of encoded features , where represents the global feature embedding and corresponds to the region-specific features.
The NetRVLAD module processes a sequence of encoded features , where represents the globally encoded feature vector and corresponds to locally encoded features derived from individual ROIs. The module aggregates these feature descriptors into a compact and discriminative global representation suitable for classification tasks.
Each feature vector (where ) is first projected onto a cluster-assignment space using a trainable weight matrix and a bias vector . For a given feature vector , the cluster activation scores are computed as
where represents the soft assignment of to the predefined clusters. The softmax function ensures that each feature is probabilistically distributed across all clusters.
Next, all input feature vectors are aggregated by weighting them according to their cluster assignments. For the entire sequence of encoded features, the cluster-wise aggregated features are computed as
where is the c-th cluster assignment score for the i-th feature vector and represents the aggregated feature descriptor for the c-th cluster. This process results in a VLAD representation , where each row corresponds to the aggregated descriptor of a cluster.
The VLAD representation V is normalized along the feature dimension using L2 normalization to ensure robustness to scale variations:
Finally, the normalized VLAD representation is flattened into a vector of dimension and projected onto the output space of dimension output_dim using a trainable matrix :
where is the final compact feature representation.
In this framework, the global feature and local features are effectively aggregated into a unified global-local feature space. The resulting representation captures both global context and local discriminative details, enabling accurate classification when passed through subsequent normalization (BatchNorm) and classification layers (softmax).
This combination of a transformer encoder and NetRVLAD module enables effective modeling of both global and local contexts while ensuring robust feature clustering and aggregation, which are critical for high-performance classification tasks.
4. Results
4.1. Datasets and Training Settings
To evaluate the performance of the proposed model, we conducted experiments on three widely used public datasets for food recognition: EPFL Food-5k [32], ETHZ Food-101 [12], and Food-2k [18]. EPFL Food-5k comprises 5000 images, evenly divided into 2500 food-related and 2500 non-food images. The images were sourced from wearable cameras and mobile phones, providing a high degree of variability in content and quality. The dataset is split into 3000 images for training, 1000 for validation, and 1000 for testing. ETHZ Food-101 is the first large-scale dataset for Western cuisine recognition, containing a total of 101,000 images across 101 food categories. The dataset is officially divided into 75,750 images for training and validation, and 25,250 images for testing, ensuring a standardized benchmark for evaluation. Food-2k, released in 2023, is the largest food recognition dataset, consisting of 1,036,564 images spanning 2000 food categories. The dataset is partitioned into training (60%), validation (10%), and testing (30%) subsets, offering extensive coverage of diverse food types and enabling robust model training and evaluation. The distributions and details of the three datasets are summarized in Table 1.

Table 1.
The distributions and details of the EPFL Food-5k, ETHZ Food-101, and Food-2k datasets.
We trained our framework with an input image size of 224 × 224, a batch size of 8, and the SGD [33] optimizer on eight NVIDIA RTX A6000 GPUs using the Keras framework for 200 epochs. The initial learning rate was set to 0.0001 and was adjusted dynamically during training to optimize convergence. Specifically, the learning rate was reduced by a factor of 10 every 50 epochs. During training, images were resized to 256 × 256 and then augmented with random rotations (), scaling (), horizontal flipping (50% probability), and random cropping to match the target input size, which enhances robustness by simulating real-world variations. The FLOPs for the proposed CBDTN model were measured at 1.22 G, and the number of trainable parameters was 591.19 M.
4.2. Evaluation Metrics
To achieve a comprehensive assessment, multiple and contrasting evaluation metrics were employed. These metrics included sensitivity (Sen), precision (Pre), and specificity (Spe), accuracy (Acc) and are defined below.
Sensitivity measures the proportion of true positives correctly identified by the model:
where is the number of true positives and is the number of false negatives.
Precision indicates the proportion of predicted positives that are true positives:
where is the number of false positives.
Specificity measures the proportion of true negatives correctly identified:
where is the number of true negatives.
Accuracy represents the overall correctness of the model’s predictions:
where , , , and are defined as above.
4.3. Experimental Results
To comprehensively evaluate the effectiveness of the proposed method, we conducted comparative experiments on the three datasets against several state-of-the-art approaches across multiple evaluation metrics, including Acc, Sen, Pre, and Spe. The results demonstrate the superiority of our method, achieving consistent improvements across these metrics. Additionally, to further validate the contribution of each component in the proposed framework, we performed ablation studies. These ablation experiments systematically examined the impact of each module, providing insights into their specific roles in enhancing overall model performance.
4.3.1. Comparative Results on the EPFL Food-5k Dataset
The EPFL Food-5k dataset comprises only two categories: food and non-food. To comprehensively evaluate model performance, we calculated the true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN) based on the predictions made on the test set. We conducted comparative experiments on the EPFL Food-5k dataset, benchmarking our approach against several state-of-the-art methods, including GoogLeNet [32], ResNet-152+SVM [34], KenyanFC [35], and VGG16 [36]. The results summarized in Table 1 highlight the significant advantages of our method across all evaluation metrics: sensitivity (Sen), precision (Pre), specificity (Spe), and accuracy (Acc), providing a detailed assessment of the model’s capability.
As shown in Table 2, among the compared methods, ResNet-152+SVM exhibited the best performance, achieving a high accuracy of , along with sensitivity and specificity scores of and , respectively. KenyanFC and GoogLeNet also performed well, both with accuracies of , but they showed slightly lower precision and specificity compared to ResNet-152+SVM. VGG16 delivered the lowest overall performance among the baselines, with an accuracy of .
Table 2.
Comparative results on the EPFL Food-5k dataset.
The proposed method outperformed all compared approaches, achieving the highest accuracy (), along with significant improvements in precision () and specificity (). Furthermore, our model maintained a perfect sensitivity score (), highlighting its exceptional ability to identify positive instances. These results indicate that the proposed method not only achieves superior classification accuracy but also balances the trade-offs between identifying positive and negative samples, as reflected in the metrics. The results emphasize the robustness of our method and its ability to address challenges in food image classification, surpassing existing state-of-the-art approaches on the EPFL Food-5k dataset.
4.3.2. Comparative Results on the ETHZ Food-101 Dataset
To further demonstrate the effectiveness of our proposed method, we conducted experiments on the ETHZ Food-101 dataset, a widely used benchmark in the food recognition domain. As is standard in this field, the Top-1 accuracy (Acc) was employed as the primary evaluation metric to ensure a fair and direct comparison with existing methods. Additionally, some studies in the domain also report the Top-5 accuracy () as a complementary, more lenient metric to provide further insights into model performance.
Reporting both the Top-1 accuracy and Top-5 accuracy provides a more holistic evaluation of model performance. While the Top-1 accuracy reflects the strict classification capability of the model, the Top-5 accuracy offers insight into the model’s ability to identify the correct class among the top candidates, which is especially useful in scenarios with high intra-class variability or subtle inter-class differences. The comparative results are presented in Table 3.
Table 3.
Comparative results on the ETHZ Food-101 dataset.
The proposed method achieved a Top-1 accuracy of , significantly outperforming all competing methods. Among the existing approaches, ViT [25] demonstrated strong performance, achieving an accuracy of , followed by ConvNeXt-AG [16] with and LP-ViT [26] with . CNN54 [14], a deeper convolutional neural network, attained , while EfficientNet-b0 [13] and AlexNet [12] showed relatively lower accuracies of and , respectively.
The remarkable improvement in accuracy by our method highlights its superior capability in addressing the challenges of food recognition, such as high intra-class variance and inter-class similarity. By using the standard Top-1 accuracy metric, this evaluation ensures comparability with prior methods and underscores the robustness and generalizability of the proposed framework in the context of large-scale food recognition tasks.
4.3.3. Comparative Results on the Food-2k Dataset
We conducted comparative experiments on the Food-2k dataset, the largest and most challenging benchmark in the food recognition domain. Both the Top-1 accuracy () and Top-5 accuracy () were used as evaluation metrics to ensure a comprehensive assessment of the model’s classification performance. The results summarized in Table 4 highlight the advantages of our approach compared to several state-of-the-art methods.
The proposed method achieved the highest performance in both the Top-1 accuracy () and Top-5 accuracy (), outperforming all competing methods. Among the baseline methods, PRENet(ResNet101) [18] delivered the best performance after ours, with a Top-1 accuracy of and a Top-5 accuracy of , closely followed by SENet154 [37], with a Top-1 accuracy of and a Top-5 accuracy of . MSPTN [38] also showed competitive results, achieving a Top-1 accuracy of and a Top-5 accuracy of . In contrast, methods such as PMG [39], MOMN [40], and ViT-CNN [41] demonstrated relatively lower performance, with Top-1 accuracies ranging from to and Top-5 accuracies ranging from to .
The notable increase in the Top-5 accuracy () also highlights the model’s capability to rank the true class consistently among the top predictions, an important characteristic for applications requiring flexible decision making. These results affirm the superiority of the proposed framework over state-of-the-art methods on the Food-2k dataset.
Table 4.
Comparative results on the Food-2k dataset.
Table 4.
Comparative results on the Food-2k dataset.
| Method | Top-1 Acc | Top-5 Acc |
|---|---|---|
| PMG [39] | 0.8129 | 0.9612 |
| MOMN [40] | 0.8084 | 0.9602 |
| SENet154 [37] | 0.8362 | 0.9722 |
| ViT-CNN [41] | 0.8079 | 0.9574 |
| MSPTN [38] | 0.8288 | 0.9712 |
| PRENet(ResNet101) [18] | 0.8375 | 0.9733 |
| CBDTN (Ours) | 0.8587 | 0.9828 |
4.3.4. Ablation Study
To analyze the contribution of each module in the proposed framework, we conducted an ablation study on the three datasets: Food-5k, Food-101, and Food-2k. The results are summarized in Table 5, demonstrating the impact of removing specific components on overall performance.
Table 5.
Ablation study results.
Effect of BAM (Boundary-Aware Module): Removing the BAM (denoted as w/o BAM) resulted in a significant drop in accuracy across all datasets, with reductions of on Food-5k, on Food-101, and on Food-2k. This highlights the importance of boundary-sensitive features in capturing fine-grained details for improved classification accuracy.
Effect of DRP (Deformable ROI Pooling): When replacing DRP with a simpler approach of directly repeating and stacking boundary-sensitive features (w/o DRP), the performance further decreased, with accuracy on Food-5k dropping to , accuracy on Food-101 dropping to , and accuracy on Food-2k dropping to . These results underscore the ability of DRP to enhance feature localization and capture regional variations effectively.
Effect of Transformer Encoder: Substituting the transformer encoder with a fully connected (FC) layer for feature dimension processing (w/o transformer encoder) also led to a considerable performance reduction. The accuracy dropped by on Food-5k, on Food-101, and on Food-2k, emphasizing the importance of the transformer encoder in capturing global and local dependencies in the feature space.
Effect of NetRVLAD Module: Replacing the NetRVLAD module with a simpler FC layer to directly output class probabilities (w/o NetRVLAD) reduced the accuracy to , , and on Food-5k, Food-101, and Food-2k, respectively. These results demonstrate the effectiveness of the NetRVLAD module in clustering and aggregating discriminative features for robust classification.
Overall Impact: The complete framework (CBDTN) consistently achieved the best performance across all datasets, with accuracies of , , and on Food-5k, Food-101, and Food-2k, respectively. The ablation results confirm the critical contributions of the BAM, DRP, transformer encoder, and NetRVLAD module to the proposed framework, each playing a distinct and complementary role in enhancing classification accuracy.
5. Discussion
In this study, we addressed key challenges in food recognition, including variability in food presentation, intra-class diversity, and inter-class similarity. These challenges arise due to the diverse nature of food items, such as varying preparation styles, overlapping appearances, and the differing contexts in which food is photographed. To overcome these issues, we proposed a novel framework that integrates a boundary-aware module (BAM), deformable ROI pooling (DRP), a transformer encoder, and a NetRVLAD module. These components were designed to jointly enhance the model’s capability for robust feature extraction, fine-grained discrimination, and effective aggregation of global and local features.
The proposed BAM effectively captures boundary-sensitive features, aiding in the differentiation of highly similar food items. DRP further refines these features by localizing critical regions, enabling adaptive representation of subtle intra-class differences. The transformer encoder integrates global dependencies and contextual relationships, which are crucial for distinguishing visually similar classes. The NetRVLAD module provides robust feature clustering and aggregation, ensuring the extraction of discriminative embeddings for final classification.
Quantitative results across three diverse datasets, Food-5k, Food-101, and Food-2k, demonstrate the superiority of the proposed method. The framework consistently achieved state-of-the-art performance across multiple evaluation metrics, with significant improvements in accuracy compared to existing methods. For instance, on the challenging Food-101 dataset, our framework outperformed the previously best method by a notable margin, achieving a Top-1 accuracy of 99.17%. Ablation studies further validated the contributions of each module, showing complementary and synergistic effects when integrated into the complete framework.
The proposed method holds significant promise for advancing intelligent dietary management systems. Its superior performance in food recognition could be instrumental in applications such as automated meal tracking, calorie estimation, and personalized nutrition planning. By accurately identifying and classifying food items in diverse scenarios, our framework can provide reliable and efficient solutions to support healthy eating habits and dietary interventions.
Despite its outstanding performance, the current model also has limitations. Specifically, the framework’s reliance on high-capacity components, such as transformer encoders, requires substantial computational resources and memory, posing challenges for deployment on resource-constrained devices. To address this, future work will focus on making the model more lightweight to enhance its applicability in mobile and embedded systems. Techniques such as knowledge distillation, model pruning, and quantization will be explored to achieve a balance between performance and computational efficiency.
Current methods mainly focus on food recognition and analysis using single images. However, exploring dynamic food recognition based on video data and incorporating multi-modal data (e.g., nutritional information) for comprehensive nutritional analysis remain open challenges. Addressing these aspects will further enhance the framework’s practical applicability in real-world scenarios, enabling more robust and versatile solutions for real-time meal tracking and personalized nutrition.
Overall, the proposed framework’s potential extends beyond its current application in food recognition. It may serve as a foundational tool for broader dietary management systems, paving the way for accessible and efficient solutions to support global health initiatives. By continuing to refine and adapt the model, we aim to advance its utility in real-world scenarios, further contributing to the development of smart dietary management tools.
6. Conclusions
In conclusion, this study proposed a multi-stage DL framework for food recognition, addressing critical challenges such as high intra-class diversity and inter-class similarity in food datasets. The framework integrates a boundary-aware module (BAM) for boundary-sensitive feature extraction, deformable ROI pooling (DRP) for localized feature refinement, a transformer encoder for capturing global contextual relationships, and a NetRVLAD module for robust feature aggregation. These components work synergistically to enhance the model’s ability to handle complex visual variations in food items.
The framework was evaluated comprehensively on three benchmark datasets: Food-5k, Food-101, and Food-2k, consistently outperforming state-of-the-art methods across multiple evaluation metrics. On the Food-101 dataset, the proposed model achieved a Top-1 accuracy of 99.17%, surpassing the previously best existing method by a notable margin. Similarly, on the Food-2k dataset, the model achieved a Top-1 accuracy of 85.87% and a Top-5 accuracy of 98.28%, demonstrating its robustness and generalizability. Ablation studies further validated the contributions of individual modules, showcasing the complementary effects of the proposed architectural innovations.
The outstanding performance highlights the framework’s potential as a foundational tool for intelligent dietary management systems, enabling applications such as automated meal tracking, calorie estimation, and personalized nutrition planning. By delivering high accuracy and robustness, the proposed method addresses real-world challenges in food recognition, paving the way for smarter and more efficient solutions in dietary management.
Author Contributions
Conceptualization, S.L. and Y.G.; methodology, S.L.; software, S.L.; validation, S.L.; formal analysis, S.L.; investigation, S.L.; resources, Y.G.; writing—original draft preparation, S.L.; writing—review and editing, S.L.; visualization, S.L.; supervision, Y.G.; project administration, Y.G.; funding acquisition, S.L. and Y.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research received funding from the following sources: the National Natural Science Foundation of China, grant numbers 62401378 and 62276174; the Beijing Municipal Natural Science Foundation, grant number Z220015; the National Key Research and Development Program of China, grant number 2023YFC3604200; the Natural Science Foundation of Guangdong Province, grant number 2021A1515011970; the R&D Program of Beijing Municipal Education Commission, grant number KM202410025021; and Capital Medical University, grant numbers PYZ23030 and 2023KF02.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data supporting the findings of this study are publicly available [Food-5k, Food-101, Food-2k]. The datasets can be accessed at the following links: https://www.kaggle.com/datasets/trolukovich/food5k-image-dataset (accessed on on 22 January 2025), https://data.vision.ee.ethz.ch/cvl/datasets_extra/food-101/ (accessed on 22 January 2025), http://123.57.42.89/FoodProject.html (accessed on on 22 January 2025). Access to these datasets requires registration and approval from the dataset provider.
Acknowledgments
This research received funding from the following sources: the National Natural Science Foundation of China, grant numbers 62401378 and 62276174; the Beijing Municipal Natural Science Foundation, grant number Z220015; the National Key Research and Development Program of China, grant number 2023YFC3604200; the Natural Science Foundation of Guangdong Province, grant number 2021A1515011970; the R&D Program of Beijing Municipal Education Commission, grant number KM202410025021; and Capital Medical University, grant numbers PYZ23030, 2023KF02.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Konstantakopoulos, F.S.; Georga, E.I.; Fotiadis, D.I. A review of image-based food recognition and volume estimation artificial intelligence systems. IEEE Rev. Biomed. Eng. 2023, 17, 136–152. [Google Scholar] [CrossRef] [PubMed]
- Shao, W.; Min, W.; Hou, S.; Luo, M.; Li, T.; Zheng, Y.; Jiang, S. Vision-based food nutrition estimation via RGB-D fusion network. Food Chem. 2023, 424, 136309. [Google Scholar] [CrossRef] [PubMed]
- Adedeji, A.A.; Priyesh, P.V.; Odugbemi, A.A. The Magnitude and Impact of Food Allergens and the Potential of AI-Based Non-Destructive Testing Methods in Their Detection and Quantification. Foods 2024, 13, 994. [Google Scholar] [CrossRef] [PubMed]
- Joshua, S.R.; Shin, S.; Lee, J.H.; Kim, S.K. Health to eat: A smart plate with food recognition, classification, and weight measurement for type-2 diabetic mellitus patients’ nutrition control. Sensors 2023, 23, 1656. [Google Scholar] [CrossRef]
- WHO. Healthydiet. 2024. Available online: https://www.who.int/news-room/fact-sheets/detail/healthy-diet (accessed on 22 January 2025).
- Wang, P.; Song, M.; Eliassen, A.H.; Wang, M.; Fung, T.T.; Clinton, S.K.; Rimm, E.B.; Hu, F.B.; Willett, W.C.; Tabung, F.K.; et al. Optimal dietary patterns for prevention of chronic disease. Nat. Med. 2023, 29, 719–728. [Google Scholar] [CrossRef]
- Fong, J.H. Risk Factors for Food Insecurity among Older Adults in India: Study Based on LASI, 2017–2018. Nutrients 2023, 15, 3794. [Google Scholar] [CrossRef]
- Salinari, A.; Machì, M.; Armas Diaz, Y.; Cianciosi, D.; Qi, Z.; Yang, B.; Ferreiro Cotorruelo, M.S.; Villar, S.G.; Dzul Lopez, L.A.; Battino, M.; et al. The Application of Digital Technologies and Artificial Intelligence in Healthcare: An Overview on Nutrition Assessment. Diseases 2023, 11, 97. [Google Scholar] [CrossRef]
- Zhang, Y.; Deng, L.; Zhu, H.; Wang, W.; Ren, Z.; Zhou, Q.; Lu, S.; Sun, S.; Zhu, Z.; Gorriz, J.M.; et al. Deep learning in food category recognition. Inf. Fusion 2023, 98, 101859. [Google Scholar] [CrossRef]
- Menichetti, G.; Ravandi, B.; Mozaffarian, D.; Barabási, A.L. Machine learning prediction of the degree of food processing. Nat. Commun. 2023, 14, 2312. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2012; Volume 25. [Google Scholar]
- Bossard, L.; Guillaumin, M.; Van Gool, L. Food-101–mining discriminative components with random forests. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Part VI 13. Springer: Cham, Switzerland, 2014; pp. 446–461. [Google Scholar]
- VijayaKumari, G.; Vutkur, P.; Vishwanath, P. Food classification using transfer learning technique. Glob. Transit. Proc. 2022, 3, 225–229. [Google Scholar]
- Hassannejad, H.; Matrella, G.; Ciampolini, P.; De Munari, I.; Mordonini, M.; Cagnoni, S. Food image recognition using very deep convolutional networks. In Proceedings of the 2nd International Workshop on Multimedia Assisted Dietary Management, Amsterdam, The Netherlands, 16 October 2016; pp. 41–49. [Google Scholar]
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I.S.; Xie, S. Convnext v2: Co-designing and scaling convnets with masked autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16133–16142. [Google Scholar]
- Deng, G.; Wu, D.; Chen, W. Attention Guided Food Recognition via Multi-Stage Local Feature Fusion. Comput. Mater. Contin. 2024, 80, 1985. [Google Scholar] [CrossRef]
- Behera, A.; Wharton, Z.; Hewage, P.R.; Bera, A. Context-aware attentional pooling (cap) for fine-grained visual classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 929–937. [Google Scholar]
- Min, W.; Wang, Z.; Liu, Y.; Luo, M.; Kang, L.; Wei, X.; Wei, X.; Jiang, S. Large scale visual food recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9932–9949. [Google Scholar] [CrossRef] [PubMed]
- Guo, W.; Li, S.; Chen, F.; Sun, Y.; Gu, Y. Satellite Video Multi-Label Scene Classification with Spatial and Temporal Feature Cooperative Encoding: A Benchmark Dataset and Method. IEEE Trans. Image Process. 2024, 33, 2238–2251. [Google Scholar] [CrossRef] [PubMed]
- Ma, T.; Wang, H.; Wei, M.; Lan, T.; Wang, J.; Bao, S.; Ge, Q.; Fang, Y.; Sun, X. Application of smart-phone use in rapid food detection, food traceability systems, and personalized diet guidance, making our diet more health. Food Res. Int. 2022, 152, 110918. [Google Scholar] [CrossRef]
- Ma, P.; Zhang, Z.; Jia, X.; Peng, X.; Zhang, Z.; Tarwa, K.; Wei, C.I.; Liu, F.; Wang, Q. Neural network in food analytics. Crit. Rev. Food Sci. Nutr. 2024, 64, 4059–4077. [Google Scholar] [CrossRef]
- Louro, J.; Fidalgo, F.; Oliveira, Â. Recognition of Food Ingredients—Dataset Analysis. Appl. Sci. 2024, 14, 5448. [Google Scholar] [CrossRef]
- Bera, A.; Krejcar, O.; Bhattacharjee, D. Rafa-net: Region attention network for food items and agricultural stress recognition. IEEE Trans. Agrifood Electron. 2024, 1–13. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef]
- Gao, X.; Xiao, Z.; Deng, Z. High accuracy food image classification via vision transformer with data augmentation and feature augmentation. J. Food Eng. 2024, 365, 111833. [Google Scholar] [CrossRef]
- Sheng, G.; Min, W.; Zhu, X.; Xu, L.; Sun, Q.; Yang, Y.; Wang, L.; Jiang, S. A lightweight hybrid model with location-preserving vit for efficient food recognition. Nutrients 2024, 16, 200. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Khan, A.; Rauf, Z.; Sohail, A.; Khan, A.R.; Asif, H.; Asif, A.; Farooq, U. A survey of the vision transformers and their CNN-transformer based variants. Artif. Intell. Rev. 2023, 56, 2917–2970. [Google Scholar] [CrossRef]
- Xu, J.; Sun, X.; Zhang, Z.; Zhao, G.; Lin, J. Understanding and improving layer normalization. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2019; Volume 32. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Singla, A.; Yuan, L.; Ebrahimi, T. Food/non-food image classification and food categorization using pre-trained googlenet model. In Proceedings of the 2nd International Workshop on Multimedia Assisted Dietary Management, Amsterdam, The Netherlands, 16 October 2016; pp. 3–11. [Google Scholar]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- McAllister, P.; Zheng, H.; Bond, R.; Moorhead, A. Combining deep residual neural network features with supervised machine learning algorithms to classify diverse food image datasets. Comput. Biol. Med. 2018, 95, 217–233. [Google Scholar] [CrossRef]
- Jalal, M.; Wang, K.; Jefferson, S.; Zheng, Y.; Nsoesie, E.O.; Betke, M. Scraping social media photos posted in Kenya and elsewhere to detect and analyze food types. In Proceedings of the 5th International Workshop on Multimedia Assisted Dietary Management, Nice, France, 21 October 2019; pp. 50–59. [Google Scholar]
- Şengür, A.; Akbulut, Y.; Budak, Ü. Food image classification with deep features. In Proceedings of the 2019 International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 21–22 September 2019; pp. 1–6. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Li, W.; Li, J.; Ma, M.; Hong, X.; Fan, X. Multi-Scale Spiking Pyramid Wireless Communication Framework for Food Recognition. IEEE Trans. Multimed. 2024, 1–13. [Google Scholar] [CrossRef]
- Du, R.; Chang, D.; Bhunia, A.K.; Xie, J.; Ma, Z.; Song, Y.Z.; Guo, J. Fine-grained visual classification via progressive multi-granularity training of jigsaw patches. In Proceedings of the European Conference on Computer Vision, Virtual, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 153–168. [Google Scholar]
- Min, S.; Yao, H.; Xie, H.; Zha, Z.J.; Zhang, Y. Multi-objective matrix normalization for fine-grained visual recognition. IEEE Trans. Image Process. 2020, 29, 4996–5009. [Google Scholar] [CrossRef]
- Bianco, S.; Buzzelli, M.; Chiriaco, G.; Napoletano, P.; Piccoli, F. Food Recognition with Visual Transformers. In Proceedings of the 2023 IEEE 13th International Conference on Consumer Electronics-Berlin (ICCE-Berlin), Berlin, Germany, 3–5 September 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 82–87. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).