Effect of Product Involvement on Panels’ Vocabulary Generation, Attribute Identification, and Sample Configurations in Beer





Abstract
:1. Introduction
2. Materials and Methods
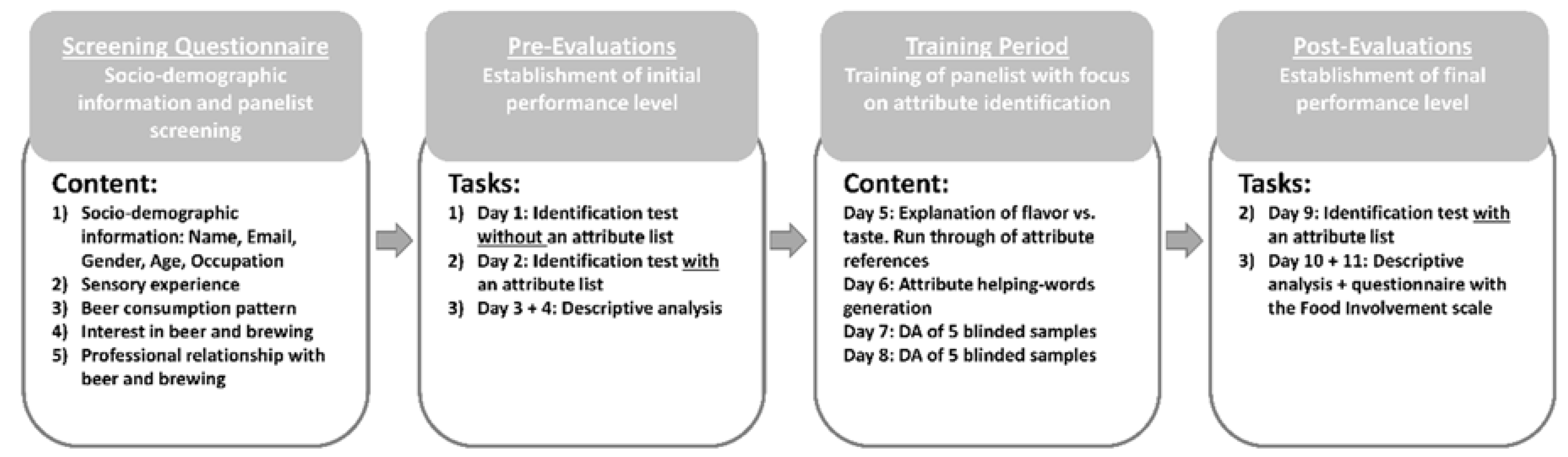
2.1. Experimental Overview
2.2. Screening Questionnaire
2.3. Samples
2.4. Panels
2.5. Pre-Evaluations
2.5.1. Identification Test without an Attribute List (Task 1)
2.5.2. Identification Test with an Attribute List (Task 2)
2.5.3. Descriptive Analysis (Task 3)
2.6. Training Period
2.7. Post-Evaluations
2.8. Statistical Analysis
2.8.1. Comparison of the Panels’ Vocabulary Generation—Identification Test without a List
2.8.2. Comparison of the Panels’ Identifications of Attributes and Attribute Understanding—Identification Test with a List
2.8.3. Comparison of the Panels’ Positioning of the Samples in the Sensory Space—Sensory Profiling Data
2.8.4. Comparison of the Panels’ Individual and Average FIS Scores
3. Results
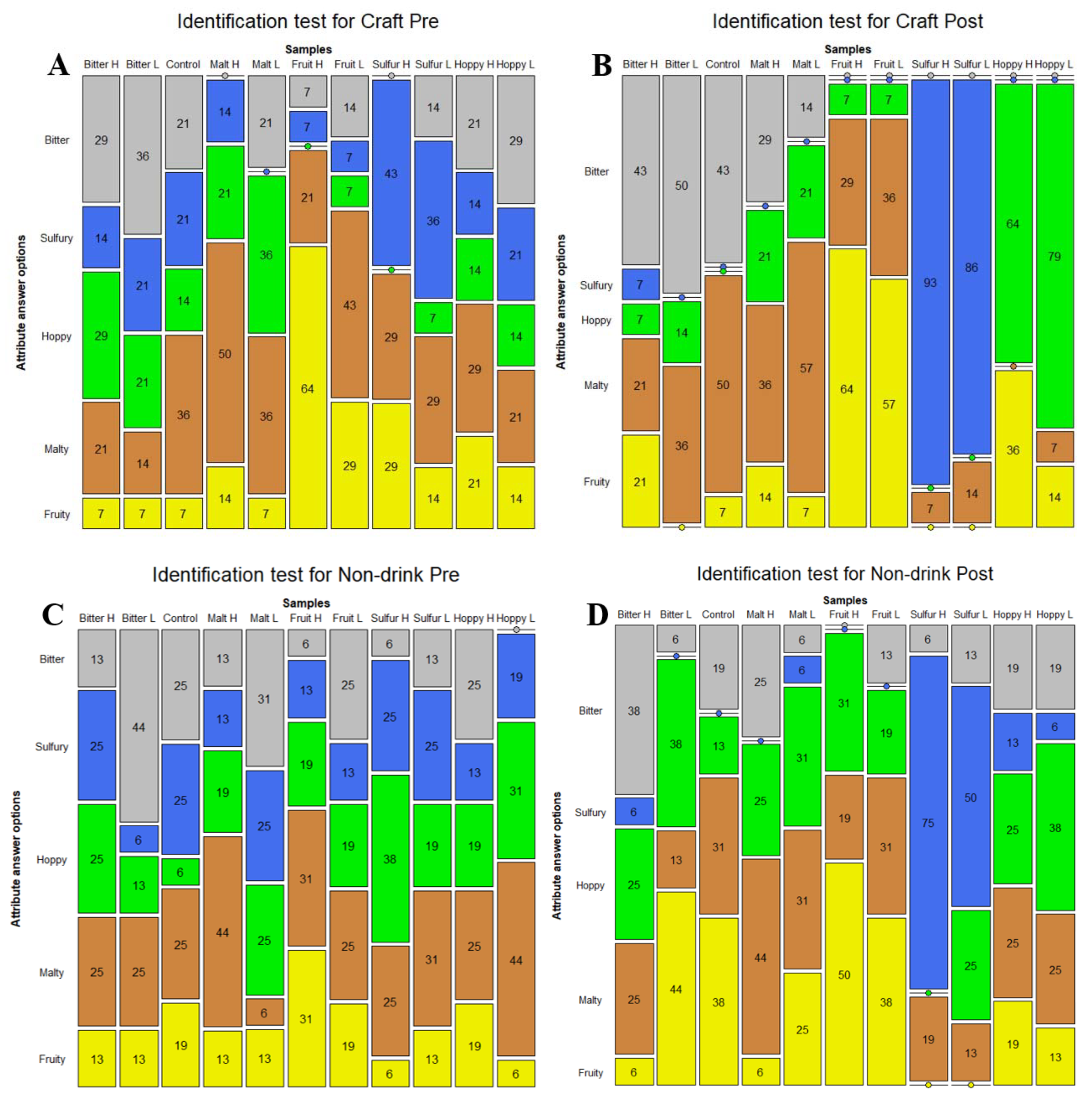
3.1. Comparison of the Panels’ Vocabulary Generation—Identification Test Without a List
3.2. Comparison of the Panels’ Identifications of Attributes and Attribute Understanding—Identification Test with a List
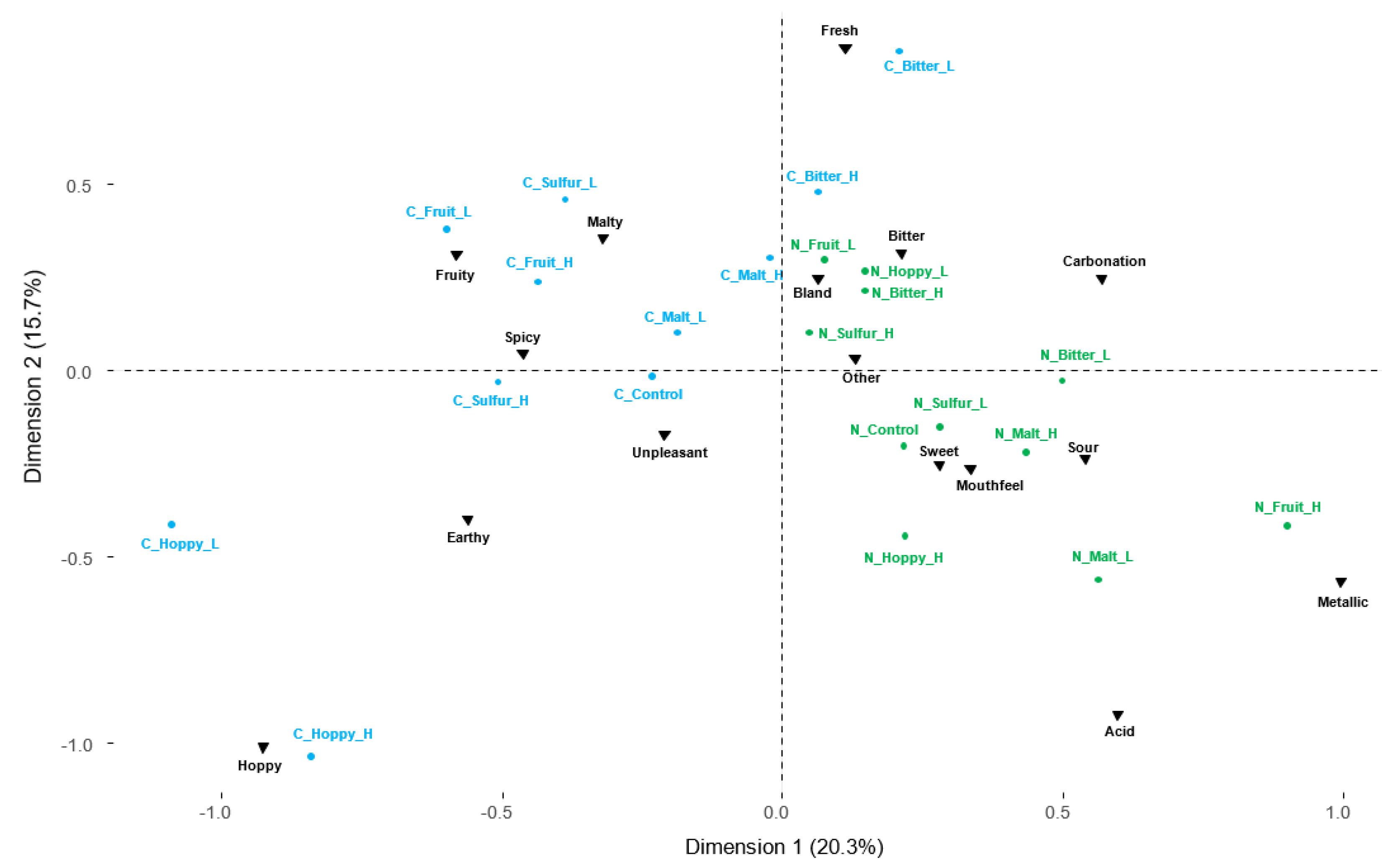
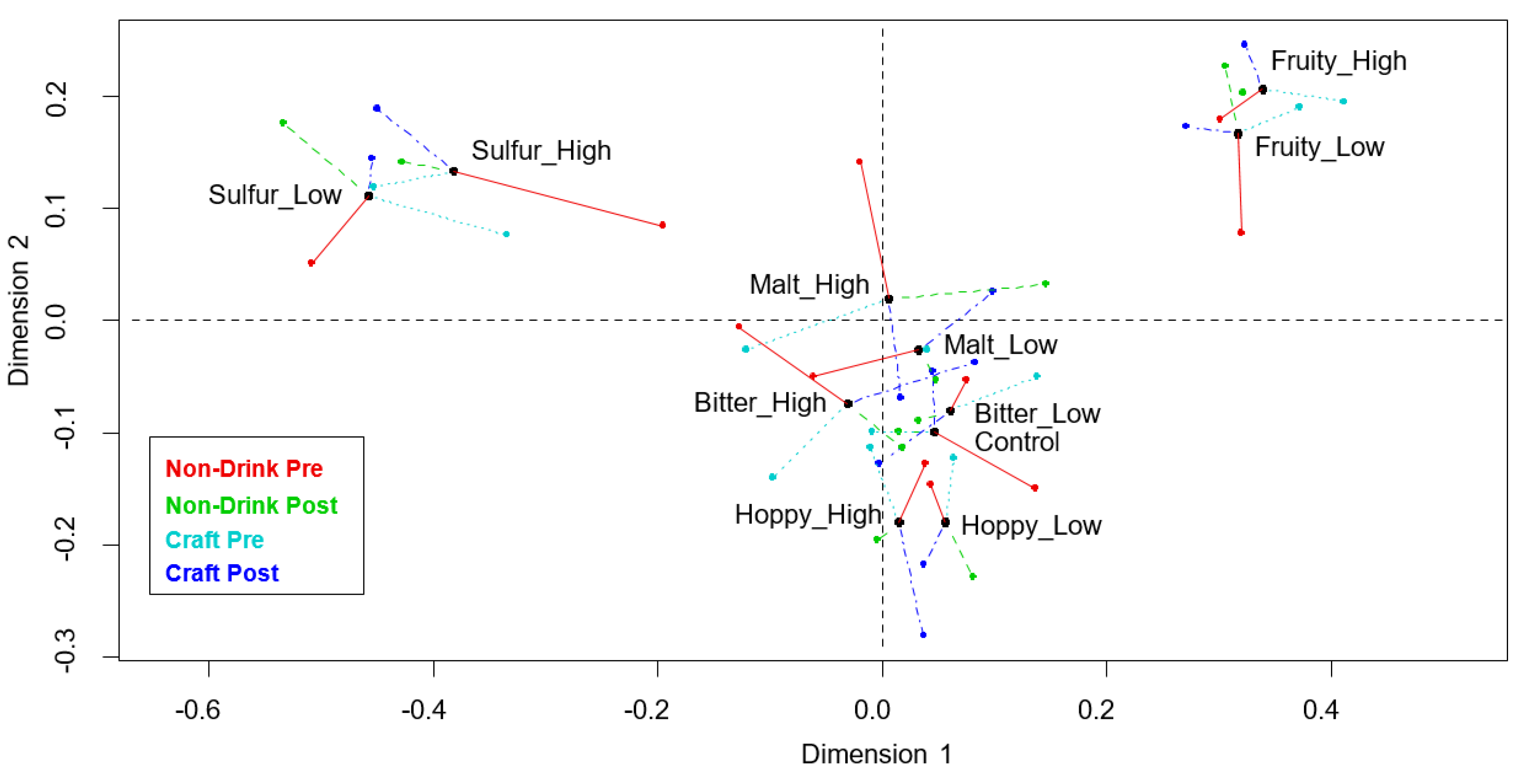
3.3. Comparison of the Panels’ Positioning of the Samples in the Sensory Space—Sensory Profiling Data
3.4. Comparison of the Panels’ Individual and Average FIS Scores
4. Discussion
4.1. Comparison of the Panels’ Descriptive Similarity—Vocabulary Generation
4.2. Comparison of the Panels’ Attribute Knowledge Similarity—Identification of Attributes
4.3. Comparison of the Panels’ Perceptual Similarity—Sample Positioning in the Sensory Space
4.4. Comparison of the Panels’ Individual and Average FIS Scores
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Overview of the Screening Questionnaire

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Question Formulation | Answer Options |
|---|---|---|
| 1 | Please provide your first and last name: | written answer |
| 2 | Please provide your email address: | written answer |
| 3 | Please indicate your gender: | Male/Female |
| 4 | Please provide your age: | Numerical value |
| 5 | What is your current occupation? | A. Employed full time B. Employed part time C. Unemployed looking for work D. Unemployed not looking for work E. Retired F. Student G. Disabled |
| 6 | Approximately, How many sensory studies have you participated in? | Numerical value |
| 7 | Do you drink beer regularly? | Yes/No |
| 8 | Please state why you do not drink beer? | Written answer |
| 9 | Would you be willing to taste? | Yes/No |
| 10 | Please choose the beer(s) you usually drink. Choose as many as you like. If the beer you usually drink is not present, please choose a similar style of beer. | Pictures and names of the following beers were presented: A. Budweiser Light B. Budweiser C. Lagunitas IPA D. Coors Light E. Stone IPA F. Miller Light G. Pabst Blue Ribbon H. Pliny the Elder I. Sierra Nevada Pale Ale |
| 11 | How interesting do you find brewing and beer production? | A. Extremely interesting B. Very interesting C. Moderately interesting D. Slightly interesting E. Not interesting at all |
| 12 | Do you or any of your close relatives work with beer professionally? | Yes/No |
Appendix B. The Food Involvement Scale
| # | Reversed | Food Involvement Scale Item |
|---|---|---|
| 1 | x | I don’t think much about food each day |
| 2 | x | Cooking or barbequing is not much fun |
| 3 | Talking about what I ate or am going to eat is something I like to do | |
| 4 | x | Compared with other daily decisions, my food choices are not very important |
| 5 | When I travel, one of the things I anticipate most is eating the food there | |
| 6 | I do most or all of the clean up after eating | |
| 7 | I enjoy cooking for others and myself | |
| 8 | x | When I eat out, I don’t think or talk much about how the food tastes |
| 9 | x | I do not like to mix or chop food |
| 10 | I do most or all of my own food shopping | |
| 11 | x | I do not wash dishes or clean the table |
| 12 | I care whether or not a table is nicely set |
References
- Dijksterhuis, G.B.; Byrne, D.V. Does the mind reflect the mouth? Sensory profiling and the future. Crit. Rev. Food Sci. Nutr. 2005, 45, 527–534. [Google Scholar] [CrossRef]
- Lawless, H.T.; Heymann, H. Sensory Evaluation of Food: Principles and Practices, 2nd ed.; Springer Science & Business Media: New York, NY, USA, 2010; ISBN 978-1-4419-6487-8. [Google Scholar]
- Meilgaard, M.C.; Civille, G.V.; Carr, B.T. Sensory Evaluation Techniques; CRC Press Taylor & Francis Group: Boca Raton, FL, USA, 1999. [Google Scholar]
- Murray, J.M.; Delahunty, C.M.; Baxter, I.A. Descriptive sensory analysis: Past, present and future. Food Res. Int. 2001, 34, 461–471. [Google Scholar] [CrossRef]
- Delarue, J. The use of rapid sensory methods in R&D and research: An introduction. In Rapid Sensory Profiling Techniques and Related Methods: Applications in New Product Development and Consumer Research; Delarue, J., Lawlor, J.B., Rogeaux, M., Eds.; Woodhead Publishing: Oxford, UK, 2015; pp. 3–25. [Google Scholar]
- Valentin, D.; Chollet, S.; Lelièvre, M.; Abdi, H. Quick and dirty but still pretty good: A review of new descriptive methods in food science. Int. J. Food Sci. Technol. 2012, 47, 1563–1578. [Google Scholar] [CrossRef]
- Varela, P.; Ares, G. Novel Techniques in Sensory Characterization and Consumer Profiling, 1st ed.; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Lestringant, P.; Delarue, J.; Heymann, H. 2010–2015: How have conventional descriptive analysis methods really been used? A systematic review of publications. Food Qual. Prefer. 2019, 71, 1–7. [Google Scholar] [CrossRef]
- Barcenas, P.; Pérez Elortondo, F.J.; Albisu, M. Projective mapping in sensory analysis of ewes milk cheeses: A study on consumers and trained panel performance. Food Res. Int. 2004, 37, 723–729. [Google Scholar] [CrossRef]
- Liu, J.; Grønbeck, M.S.; Di Monaco, R.; Giacalone, D.; Bredie, W.L.P. Performance of Flash Profile and Napping with and without training for describing small sensory differences in a model wine. Food Qual. Prefer. 2016, 48, 41–49. [Google Scholar] [CrossRef]
- Guerrero, L.; Gou, P.; Arnau, J. Descriptive analysis of toasted almonds: A comparison between expert and semi-trained assessors. J. Sens. Stud. 1997, 12, 39–54. [Google Scholar] [CrossRef]
- Lawless, H.T. Flavor description of white wine by “expert” and nonexpert wine consumers. J. Food Sci. 1984, 49, 120–123. [Google Scholar] [CrossRef]
- Giacalone, D.; Ribeiro, L.; Frøst, M. Perception and Description of Premium Beers by Panels with Different Degrees of Product Expertise. Beverages 2016, 2, 5. [Google Scholar] [CrossRef]
- Oliver, P.; Cicerale, S.; Pang, E.; Keast, R. Comparison of Quantitative Descriptive Analysis to the Napping methodology with and without product training. J. Sens. Stud. 2018, 33, e12331. [Google Scholar] [CrossRef]
- Zamora, M.C.; Guirao, M. Performance comparison between trained assessors and wine experts using specific sensory attributes. J. Sens. Stud. 2004, 19, 530–545. [Google Scholar] [CrossRef]
- Chollet, S.; Valentin, D. Impact of training on beer flavor perception and description: Are trained and untrained subjects really different? J. Sens. Stud. 2001, 16, 601–618. [Google Scholar] [CrossRef]
- Gawel, R. The use of language by trained and untrained experienced wine tasters. J. Sens. Stud. 1997, 12, 267–284. [Google Scholar] [CrossRef]
- Hersleth, M.; Berggren, R.; Westad, F.; Martens, M. Perception of bread: A comparison of consumers and trained assessors. J. Food Sci. 2005, 70, 95–101. [Google Scholar] [CrossRef]
- Baker, K.A.; Didcock, E.A.; Kemm, J.R.; Patrick, J.M. Effect of age, sex and illness on salt taste detection thresholds. Age Ageing 1983, 12, 159–165. [Google Scholar] [CrossRef]
- Doty, R.L.; Shaman, P.; Applebaum, S.L.; Giberson, R.; Siksorski, L.; Rosenberg, L. Smell identification ability: Changes with age. Science 1984, 226, 1441–1443. [Google Scholar] [CrossRef]
- Henderson, D.; Vaisey, M. Some personality traits related to performance in a repeated sensory task. J. Food Sci. 1970, 35, 407–411. [Google Scholar] [CrossRef]
- Jacob, N.; Golmard, J.L.; Berlin, I. Differential perception of caffeine bitter taste depending on smoking status. Chemosens. Percept. 2014, 7, 47–55. [Google Scholar] [CrossRef]
- Krut, L.H.; Perrin, M.J.; Bronte-Stewart, B. Taste perception in smokers and non-smokers. Br. Med. J. 1961, 384–387. [Google Scholar] [CrossRef]
- Mata, M.; Gonzalez, O.; Pedrero, D.; Monroy, A.; Angulo, O. Correlation Between Personality Traits and Discriminative Ability of a Sensory Panel. CYTA J. Food 2007, 5, 252–258. [Google Scholar]
- Mojet, J.; Christ-Hazelhof, E.; Heidema, J. Taste perception with age: Generic or specific losses in threshold sensitivity to the five basic tastes? Chem. Senses 2001, 26, 845–860. [Google Scholar] [CrossRef]
- Pangborn, R.M. Relationship of personal traits and attitudes to acceptance of food attributes. In Food Acceptance and Nutrition; Solms, J., Booth, D.A., Pangborn, R.M., Raunhardt, O., Eds.; Academic Press: San Diego, CA, USA, 1987; pp. 353–370. [Google Scholar]
- Shepherd, R.; Farleigh, C.A. Attitudes and personality related to salt intake. Appetite 1986, 7, 343–354. [Google Scholar] [CrossRef]
- Bell, R.; Marshall, D.W. The construct of food involvement in behavioral research: Scale development and validation. Appetite 2003, 40, 235–244. [Google Scholar] [CrossRef]
- Gains, N.; Thomson, D.M.H. Sensory profiling of canned lager beers using consumers in their own homes. Food Qual. Prefer. 1990, 2, 39–47. [Google Scholar] [CrossRef]
- Vidal, L.; Giménez, A.; Medina, K.; Boido, E.; Ares, G. How do consumers describe wine astringency? Food Res. Int. 2015, 78, 321–326. [Google Scholar] [CrossRef]
- Byrnes, N.K.; Loss, C.R.; Hayes, J.E. Perception of chemesthetic stimuli in groups who differ by food involvement and culinary experience. Food Qual. Prefer. 2015, 46, 142–150. [Google Scholar] [CrossRef] [Green Version]
- Elgaard, L.; Mielby, L.A.; Hopfer, H.; Byrne, D.V. A comparison of two sensory panels trained with different feedback calibration range specifications via sensory description of five beers. Foods 2019. submitted for publication. [Google Scholar]
- Beaton, D.; Chin Fatt, C.R.; Abdi, H. An ExPosition of multivariate analysis with the singular value decomposition in R. Comput. Stat. Data Anal. 2014, 72, 176–189. [Google Scholar] [CrossRef]
- Kassambara, A.; Mundt, F. Factoextra: Extract and Visualize the Results of Multivariate Data Analyses. Available online: https://CRAN.R-project.org/package=factoextra (accessed on 12 October 2019).
- Meyer, D.; Zeileis, A.; Hornik, K. The strucplot framework: Visualizing multi-way contingency tables with vcd. J. Stat. Softw. 2006, 17, 1–48. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 12 October 2019).
- Hothorn, T.; Hornik, K.; van de Wiel, M.A.; Zeileis, A. Implementing a class of permutation tests: The coin Package. J. Stat. Softw. 2008, 28, 1–23. [Google Scholar] [CrossRef]
- Gower, J.C. Generalized procrustes analysis. Psychometrika 1975, 40, 33–51. [Google Scholar] [CrossRef]
- Le, S.; Josse, J.; Husson, F. FactoMineR: An R package for multivariate analysis. J. Stat. Softw. 2008, 25, 1–18. [Google Scholar] [CrossRef]
- Xiong, R.; Blot, K.; Meullenet, J.F.; Dessirier, J.M. Permutation tests for generalized procrustes analysis. Food Qual. Prefer. 2008, 19, 146–155. [Google Scholar] [CrossRef]
- Dijksterhuis, G. Assessing Panel Consonance. Food Qual. Prefer. 1995, 6, 7–14. [Google Scholar] [CrossRef]
- Hervé, M. RVAideMemoire: Testing and Plotting Procedures for Biostatistics. Available online: https://CRAN.R-project.org/package=RVAideMemoire (accessed on 12 October 2019).
| # | Sample Name | Sample Modification | Sensory Profile Alterations |
|---|---|---|---|
| 1 | Control | Carlsberg pilsner with no modification | Unaltered |
| 2 | Bitter Low | Carlsberg pilsner + Isohop® (0.012 µL/mL) | Slight increased bitter taste |
| 3 | Bitter High | Carlsberg pilsner + Isohop® (0.024 µL/mL) | Intense increased bitter taste |
| 4 | Malt Low | Carlsberg pilsner + isobutyraldehyde (1 capsule 1/1500 mL) | Slight increased malty flavor |
| 5 | Malt High | Carlsberg pilsner + isobutyraldehyde (1 capsule 1/1000 mL) | Intense increased malty flavor |
| 6 | Fruity Low | Carlsberg pilsner + iso-amyl acetate (1 capsule 2/1300 mL) | Slight increased fruity flavor |
| 7 | Fruity High | Carlsberg pilsner + iso-amyl acetate (1 capsule 2/800 mL) | Intense increased fruity flavor |
| 8 | Sulfur Low | Carlsberg pilsner + hydrogen sulfphide (1 capsul e3/1300 mL) | Slight increased sulfury flavor |
| 9 | Sulfur High | Carlsberg pilsner + hydrogen sulphide (1 capsule 3/800 mL) | Intense increased sulfury flavor |
| 10 | Hoppy Low | Carlsberg pilsner + hop oil extract (1 capsule 4/1500 mL) | Slight increased hoppy flavor |
| 11 | Hoppy High | Carlsberg pilsner + hop oil extract (1 capsule 4/1000 mL) | Intense increased hoppy flavor |
| Product | Craft Vs. Non | |||
|---|---|---|---|---|
| Pre | Post | |||
| χ2 | p Value | χ2 | p Value | |
| Bitter Low | 0.01 | 0.941 | 5.24 | 0.022 |
| Bitter High | 0.41 | 0.522 | 0.00 | 1.000 |
| Malt Low | 2.42 | 0.120 | 1.12 | 0.290 |
| Malt High | 0.00 | 1.000 | 0.01 | 0.941 |
| Fruit Low | 0.04 | 0.840 | 0.50 | 0.478 |
| Fruit High | 2.08 | 0.149 | 0.18 | 0.676 |
| Sulfur Low | 0.06 | 0.811 | 2.83 | 0.092 |
| Sulfur High | 0.42 | 0.518 | 0.67 | 0.413 |
| Hoppy Low | 0.44 | 0.507 | 3.59 | (0.058) |
| Hoppy High | 0.00 | 1.000 | 3.23 | 0.072 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elgaard, L.; Mielby, L.A.; Heymann, H.; Byrne, D.V. Effect of Product Involvement on Panels’ Vocabulary Generation, Attribute Identification, and Sample Configurations in Beer. Foods 2019, 8, 488. https://doi.org/10.3390/foods8100488
Elgaard L, Mielby LA, Heymann H, Byrne DV. Effect of Product Involvement on Panels’ Vocabulary Generation, Attribute Identification, and Sample Configurations in Beer. Foods. 2019; 8(10):488. https://doi.org/10.3390/foods8100488
Chicago/Turabian StyleElgaard, Line, Line A. Mielby, Hildegarde Heymann, and Derek V. Byrne. 2019. "Effect of Product Involvement on Panels’ Vocabulary Generation, Attribute Identification, and Sample Configurations in Beer" Foods 8, no. 10: 488. https://doi.org/10.3390/foods8100488