1. Introduction
Margarine is a water-in-oil emulsion derived from vegetable and/or animal fats, with a fat content ranging from 80 to 90% (
w/
w) and a milk fat content of no more than 3% (
w/
w) [
1,
2]. This emulsion remains solid at 20 °C. It was discovered by Hippolyte Mège Mouriés, a French chemist, who patented his product in France and Britain in 1869. The product was described at that time as a blend of the glycerol esters of oleic and margaric acids and was therefore called oleo-margarine. Margaric acid was thought to be heptadecanoic acid (17:0), but currently, it is known that it was really a eutectic mixture of palmitic (16:0) and stearic (18:0) acids [
3]. “Fat-spread” is the generic name that is applied to any emulsion with a fat content ranging from 10 to 90%, whereas the term “vegetable shortening” or just “shortening” refers to all fat produced from vegetal oils that are hydrogenated, i.e., they stay semisolid at room temperature. According to this, the fat content of shortening is 100%.
The European legislation currently in force distinguishes the following types, regarding fat content [
4]: Margarine, three-quarter fat margarine, and half-fat margarine. The half-fat margarine is also named minarine or halvarine by Codex Alimentarius terminology [
2]. On the other hand, Moroccan legislation is less restrictive and does not consider different kinds of margarine concerning fat content. In fact, margarine is defined as “any food fat substance, which is not butter or lard, but resembles butter and it is produced for using as butter” [
5]. The milk fat content cannot exceed 10% (
w/
w). In order to simplify matters, and because it would not have major repercussions on the study, the term “margarine/spread” will be used in a broad sense in this paper, regardless of fat content.
For the manufacturing industrial process, the vegetal oils are heated at their melting temperature (approximately 40 °C) and mixed with the additives and emulsifiers to achieve a homogeneous mixture. In order to obtain a solid consistency of fat, the mixture is slowly cooled down and subjected to a hydrogenation process to produce fat saturation due to the unsaturated bonds of fatty acids of the vegetable oils breaking up [
6].
The properties of margarines/spreads mainly depend on the characteristics of the vegetable oils, which are the major ingredients of the product, and the additives. The fat source is usually either soybean oil or sunflower oil blended with a hydrogenated vegetable oil, typically in the ratio 3:1 [
7]. Other commodity vegetable oils include rape/canola, cottonseed, palm, palm kernel, and coconut, which may have been fractionated, blended, hydrogenated in varying degrees, and/or interesterified. Fish oil (hydrogenated or not) may also be included. Recent trends in the margarine market also consider mixtures with "healthy" vegetable oils with a low content of trans-saturated acid (e.g., high oleic sunflower or olive oils), as well as the addition of sterols. Regarding additives, these include surface-active agents, proteins, salt, and water, along with preservatives, flavours, and vitamins [
8].
From the chemical point of view, the fat fraction of margarines/spreads is mainly composed of triacylglycerols (TAGs) [
9]. Some data on the TAG composition of margarine/spread have been reported [
10], but, as far as the authors are concerned, only one paper has been published, devoted to this matter [
11]. The main compositional parameter being important for margarine/spread quality and healthy features is focused on the fatty acid (FA) profile [
12,
13,
14]. The FA profile is commonly analysed using gas chromatography after derivatisation of them in the corresponding methyl esters. This approach provides incomplete chemical information and does not allow the knowledge of the variability linked to the combination of three FAs in the TAGs.
Conventional chromatographic techniques have been used successfully for the qualitative and quantitative determination of TAGs [
15,
16], mainly high-performance liquid chromatography (HPLC) in both normal and reverse phase modes [
17,
18,
19]. The coupling of mass spectrometry to chromatographic instruments has drastically increased the analytical capabilities [
20,
21], and the regioisomeric and enantiomeric analysis of triacylglycerols is already affordable [
22], but the chromatographic signals obtained from TAG profiling methods are never specific enough due to the great variety of isomers present in low proportion. In addition, 1H NMR has also been proven to be very useful in determining the composition in acyl groups of margarine samples, in only a few minutes and with minimal or no sample pretreatment [
1,
23]. Some examples of TAG profiling in some closely related margarine/spread products as milk and dairy foods can be found in references [
24,
25].
Nevertheless, the TAGs profile is characteristic of each vegetable oil, according to its botanical species, genus, or variety, which has a characteristic lipid profile. Consequently, TAGs profiling is both a useful and reliable tool in identifying vegetable oils and/or fraud detection [
16] in order to verify the stated composition of margarines/spreads and authenticate them. Moreover, to our knowledge, there are no antecedents describing the comparison and classification of different margarines/spreads according to their geographical origin.
Another relatively alternative way to identify each vegetable oil using TAG analytical information is applying the fingerprinting methodology. This applies nonspecific instrumental signals where all the implicit, but nonevident, information contained in the analytical signal acquired from the samples is used, not being necessary to profile each chemical species present in the working solution. In this sense, signals coming directly from the measurement device or detector coupled with the chromatographic instrument are treated as a whole, and by means of advanced chemometric tools, as multivariate data analysis to extract, it is possible to reduce and process the extensive datasets in order to build proper multivariate models for classification or quantification purposes [
26,
27]. This methodology has become one of the most efficient and comprehensive methods to verify food identity [
28].
This paper presents a multivariate qualitative analytical method for authenticating the geographical origin of margarines and fat-spread products. Several multivariate chemometrics tools were applied, such as principal components analysis (PCA), soft independent modelling by class analogy (SIMCA), and partial least squares-discriminant analysis (PLS-DA). As an analytical information source for building the multivariate models, both normal and reverse phase liquid chromatographic fingerprints were used. For this purpose, the analytical signals were acquired using a diode array detector (DAD) coupled with a high-performance liquid chromatographic (HPLC) system. Three strategies were tested to build the classification models: Two input-class, pseudo two input-class, and one input-class classification. The results from each classification method and strategy were compared and ranked on the basis of several classification performance metrics.
2. Materials and Methods
2.1. Chemicals and Samples
All solvents employed were HPLC-grade. Isopropanol and n-hexane were purchased from PANREAC Química (Barcelona, Spain), and acetonitrile was provided by VWR International Eurolab, S.L. (Barcelona, Spain).
A total of 35 margarine samples of different trade names or brands were analysed: 17 from Spain, 1 from France, 1 from Belgium, 1 from Germany, 1 from the Netherlands, 1 from the United Kingdom, and 13 from Morocco.
Table 1 shows a description of the kind of vegetable oil employed in the manufacture of the products.
2.2. Sample Preparation
10% (w/w) solutions of margarine in n-hexane were prepared. The solutions were stirred for 5 min, then they were decanted and the supernatant was passed through a polytetrafluoroethylene (PTFE) membrane syringe filter (0.22 µm), and the resultant solutions were stored at −20 °C until analysis. Before the chromatographic analysis, the solutions were again diluted with n-hexane at a 1:1 ratio.
2.3. Instrumentation/Chromatography Conditions
Analysis using normal and reverse liquid chromatography coupled with a diode-array detector, (NP)HPLC‑DAD and (RP)HPLC‑DAD, respectively, was carried out with an Agilent 1260 series liquid chromatograph (Santa Clara, CA, USA), equipped with a column thermostat (Eppendorf CH30), a quaternary pump, and degasser auto sampler. Agilent ChemStation OpenLab CDS software (rev. C.01.09) for LC systems was used to collect and record data.
(NP)HPLC‑DAD analysis was carried out using a column Lichrospher 100 CN (length 25 cm × i.d. 4 mm, particle size 4 µm) provided by Merck (Darmstadt, Germany). The column temperature was constant at 30 °C and the mobile phase was composed of n/hexane/isopropanol (96:4, v/v) at a flow rate of 1.2 mL min−1. The run time was 29 min.
(RP)HPLC-DAD analysis was performed using the column DevelosilTM C30-UG-5 (length 25 cm × i.d. 4.6 mm, particle size 5 µm) from Nomura Chemical Co. (San Diego, CA, USA). During the analysis, the column temperature was at 50 °C. A mixture of acetronitre/isopropanol (40:60, v/v) was used as mobile phase at a flow rate of 1.2 mL min−1. The chromatographic run time was 30 min.
The injection volume was 20 µL, and the DAD spectra were acquired at 210 and 254 nm.
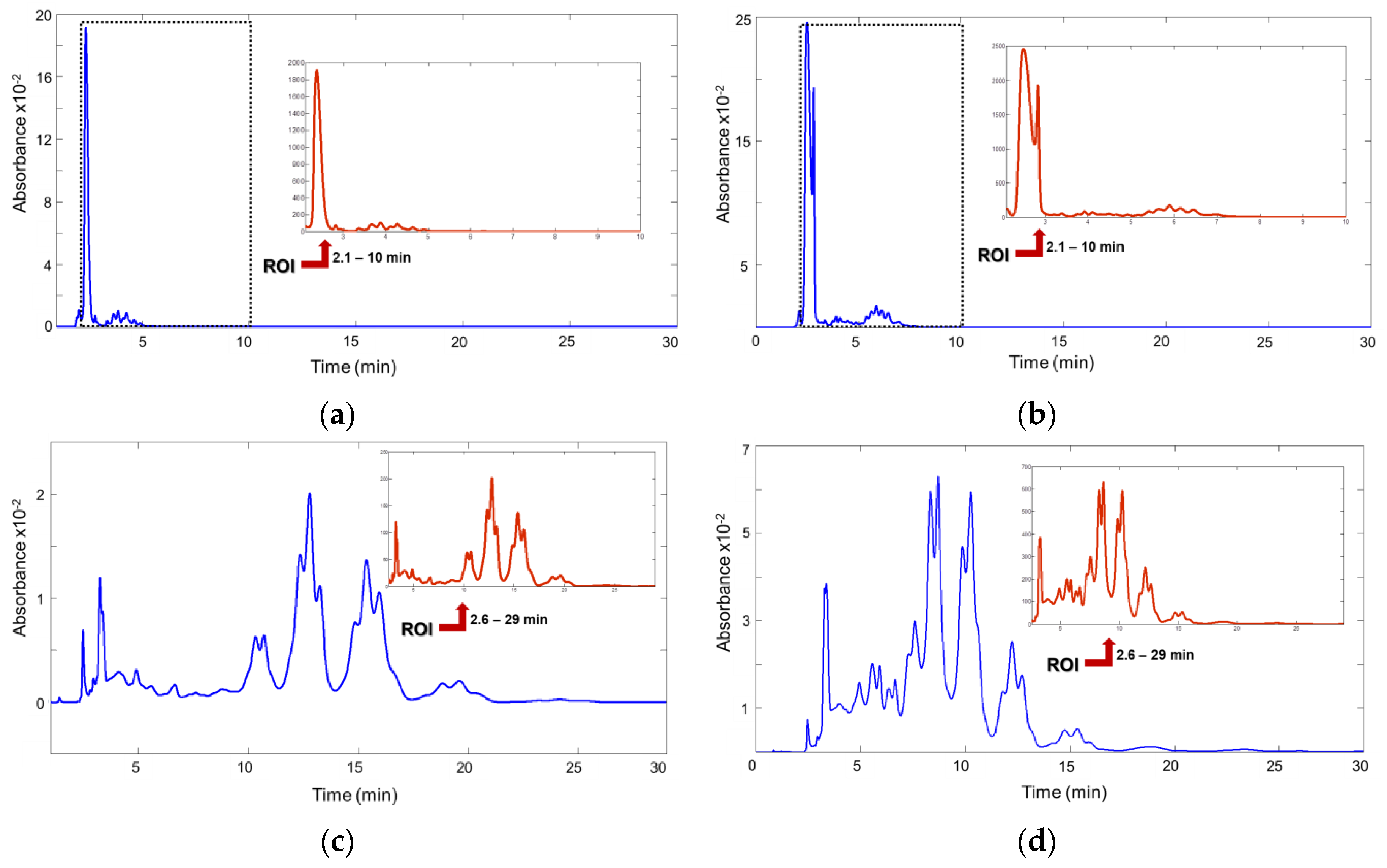
Figure 1a shows the fingerprint of a sample from Morocco recorded at 210 nm, and
Figure 1b shows a sample from Spain that recorded the same wavelength obtained using (NP)HPLC‑DAD. Likewise,
Figure 1c,d displays the fingerprints of the same samples recorded at 210 nm using (RP)HPLC‑DAD, respectively.
With respect to the TAG composition of the blended fat, the obtained fingerprint depends on the proportion of unsaturated/saturated FAs. Note that only the unsaturated FAs generate a measurable signal as the saturated FAs are almost transparent to the UV-absorption detector at the working concentration. Consequently, fingerprints show specificity from the distribution of the unsaturated FAs into the different TAGs. This characteristic causes the UV-absorption fingerprints to be different to the fingerprint acquired from other more universal detectors used in edible fat analyses, such as refractive index (RID), evaporative light scattering (ELSD), and corona charged aerosol (CAD).
2.4. Chemometrics
The raw data files from each chromatogram were exported in “comma separated value” (CSV) format and then turned to “xls” format (Microsoft Excel). For (NP)HPLC-DAD and (RP)HPLC-DAD analysis, a data vector composed of 4500 and 4350 variables (each one a specific absorbance to a scanned wavelength) was collected for each sample, respectively. The chromatographic fingerprints were reproducible from sample to sample, and thus, no alignment process was applied. The only preprocessing data carried out was the mean centring of the dataset before the development of the models. PCA, SIMCA, and partial least squares-discriminant analysis (PLS-DA) methods were built using The Unscrambler software ver. 9.7 (CAMO, Oslo, Norway).
Three classification strategies were applied: one input-class (1iC), two input-class (2iC), and pseudo two input-class (
p2iC) to develop the different Spain/Morocco binary classification methods. Two input-class is the conventional binary classification methodology in which the model is trained using samples from target and nontarget class. One input-class strategy is used only in class modelling methods such as SIMCA. In these, the model is trained only with the target class. This methodology presents an advantage in food authentication as it is only necessary to analyse samples from target class (genuine class). Nevertheless, the modelling methods are less reliable than discriminant analysis methods; thus, the pseudo two input-class is applied in order to employ discriminant methods when it is only possible to have samples from the “genuine class”. A more detailed description about these strategies is shown in the paper published by Jiménez-Carvelo et al. [
29]. For each strategy, the original data set was randomly split into different sets: Training and validation set. For 2iC, the training set was made up of 20 margarine samples, and the external validation set was composed of the remaining margarine samples. For
p2iC, the training set was made up of 10 samples and 6 solvent analytical blank replicates, and the validation set was composed of 20 samples. For 1iC, the training set was composed of 10 samples, and the validation set included 20 samples.
Table 2 details the sample distribution regarding the geographical origin for each classification strategy.
Once all the classification models were validated, they were critiqued using the samples from the validation set, and new classification models were built. To follow, these final models were used to predict the continent origin of the margarine/spread samples from the European countries other than Spain (France, Belgium, Germany, the Netherlands, and the United Kingdom). These samples constitute the prediction set.
3. Results and Discussion
Firstly, four PCA models were built using the dataset composed of the whole fingerprint from each sample in both normal and reverse phase modes.
Table 3 shows the number of PCs chosen for each model.
Figure 2 shows the scores on the PC1–PC2 plane of the fingerprints acquired at 210 nm and 254 nm. The best groupings were found in the PCA models from data collected at 210 nm.
Once PCA models were evaluated, the three strategies (2iC, 1iC, and p2iC) were applied to develop the SIMCA and PLS-DA classification models. Nevertheless, the best results were found using the 2iC strategy from the 210-collecting dataset for both normal and reverse phases. Thus, the results shown in the following sections correspond with these datasets, considering the “Spanish class” as the target class in every case. It is important to emphasise that only the values of the performance metrics related to the target class provide useful information when the classification is used as a screening method, because the errors of the samples belonging to the nontarget class are not critical information as they all may be subjected to the confirmatory method.
3.1. SIMCA Methods
The application of SIMCA involves building a classification method in which each class of the training set is modelled independently (Spain model and Morocco model). Once the individual PC models were built, these were assembled to perform the classification of the samples. Two SIMCA models, for both the normal phase and reverse phase dataset, were then developed choosing four principal components (PCs).
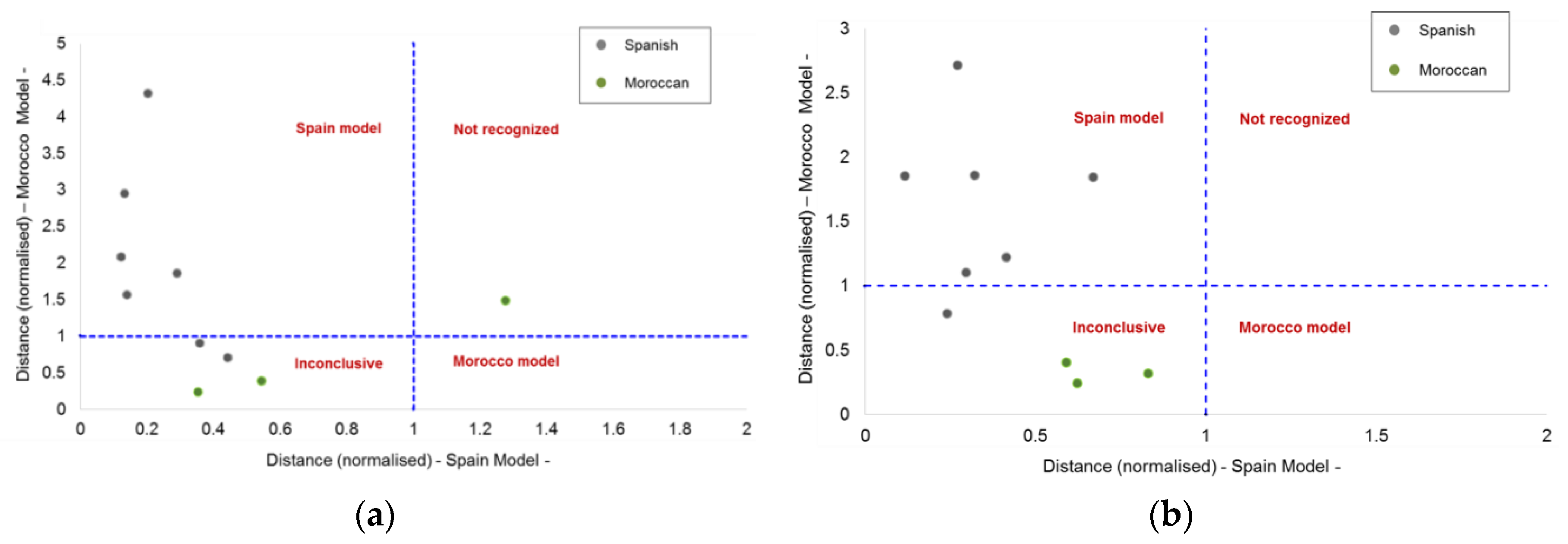
The classification results were evaluated, attending to Coomans’ plot.
Figure 3 displays the Coomans’ plot of the two SIMCA models. It can be observed that some samples are located in the bottom-left quadrant; thus, these samples were considered inconclusive and they were not taken into account for estimation of the quality metrics for each model.
Table 4 shows the results of the success/error contingencies, and
Table 5 collects the quality metrics calculated for each model.
Coomans’ plot is a tool to graphically visualize principal groupings results in pairwise plots easily, in which the two axes represent the normalised orthogonal distances of all the samples with respect to each individual model. Ideally, the validation samples should be classified in one class or another (target or nontarget class). In real conditions, some validation samples could be assigned to both classes simultaneously, as these samples are considered inconclusive ones, or to neither of them (the samples are not recognized as belonging to any class).
3.2. PLS-DA Methods
The discriminant methods are generated through establishing the boundaries for the different categories defined by the training objects. PLS-DA is a latent variable-based method whose development involves two stages: (I) Firstly, a PLS regression model is established from the latent variables (LV) to establish limits between the classes, and then, (ii) a discriminant analysis (DA) is performed to classify the samples into a specific class.
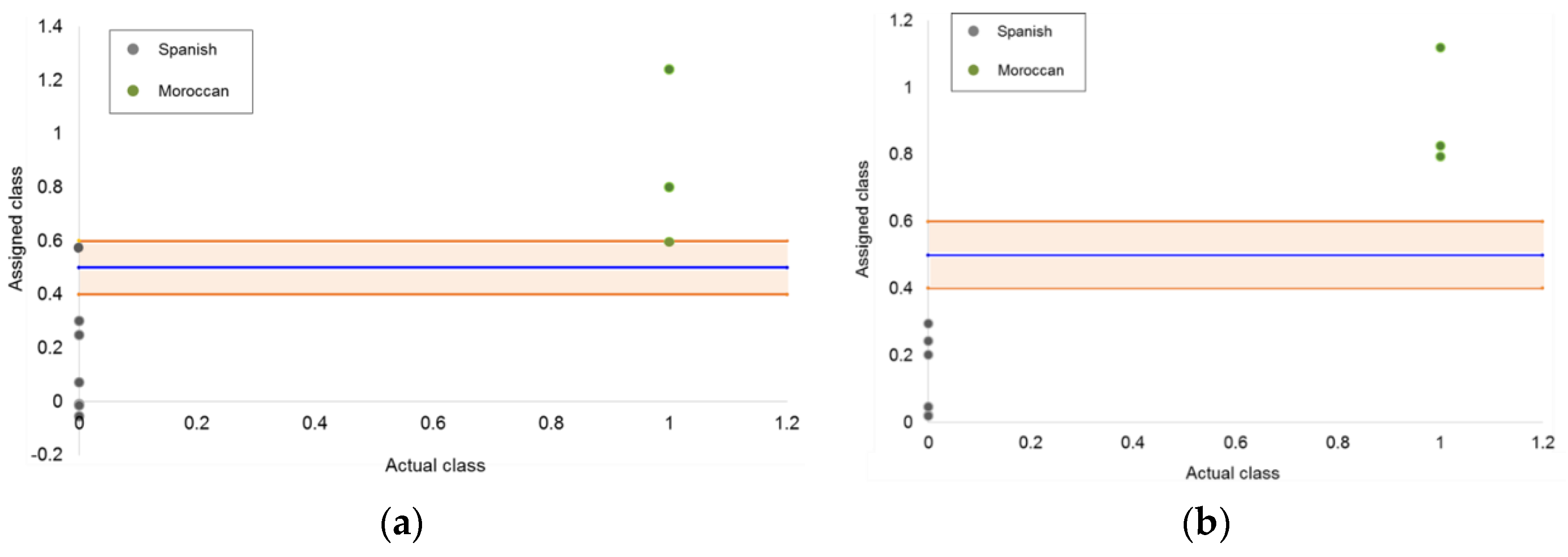
Two PLS-DA models were built using five LVs from both normal and reverse liquid chromatography datasets. The “Spanish class” was defined by values equal to 0, while the “Moroccan class” was defined by a value of 1. The decision criterion established for the classification of the samples was a threshold value of 0.5, i.e., all the margarine samples with scores greater than 0.5 were classified to the Moroccan class, and margarine samples with scores lower than 0.5 were assigned to the Spanish class. In addition, for the purpose of improving the reliability of the validation and prediction results, an uncertainty interval was established as plus/minus 0.1 the settled threshold value for the training samples.
Figure 4 shows the classification plots obtained from PLS-DA methods. The blue line displays the classification threshold, and the orange strip represents the uncertainty region, within which any sample is stated as inconclusive.
The PLS-DA classification performances were evaluated, calculating the same quality metrics as SIMCA. These were estimated using the success/error contingency for each class in which samples of the validation set were arranged. Both contingency tables and quality metrics for the two PLS-DA classifiers established are shown in
Table 6 and
Table 7, respectively.
As can be seen, PLS-DA models provided better classification results than SIMCA ones. In particular, the model developed using the (RP)HPLC-DAD dataset was the best, as all the quality metrics were equal to 1.00 and there were not any samples classified as inconclusive. All the margarine/spread samples from the target class were well classified (probability = 0), and the samples from the nontarget class were also classified correctly (probability = 1).
As stated in
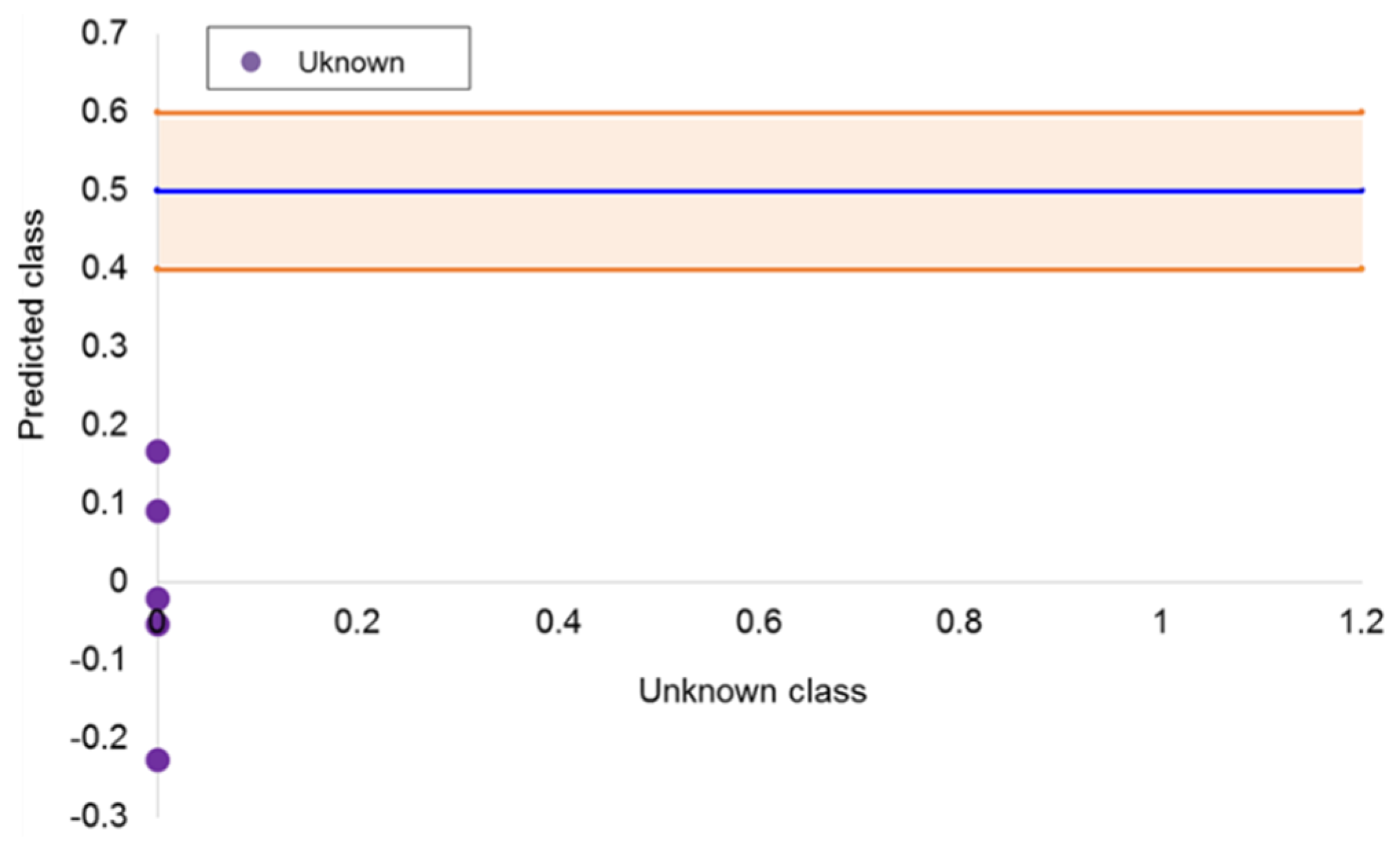
Section 2.4, once SIMCA and PLS-DA models were correctly validated, the best model was applied to predict the class similarity of the margarine/spread samples from Belgium, France, Germany, the Netherlands, and the United Kingdom. For this purpose, the PLS-DA model built from the (RP)HPLC-DAD dataset was employed. The main goal of performing this classification was to test: (i) If the model was able to classify these samples as inconclusive as they belonged to neither Spanish nor Moroccan classes, and (ii) if the model was able to find similarities with any of the modelling classes (originating from Spain or Morocco). As can be seen in
Figure 5, the model classified the five samples in the Spanish class. Probably, the overriding reason is related to the manufacturing process, because in Europe, there is an extensive and descriptive legislation that the margarine/spread products should be similar enough and all alternative to those manufactured in Morocco.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}