Authentication of the Origin, Variety and Roasting Degree of Coffee Samples by Non-Targeted HPLC-UV Fingerprinting and Chemometrics. Application to the Detection and Quantitation of Adulterated Coffee Samples




Abstract
1. Introduction
2. Materials and Methods
2.1. Chemicals and Standard Solutions
2.2. Instrumentation
2.3. Samples and Sample Treatment
2.4. Data Analysis
3. Results and Discussion
3.1. HPLC-UV Method
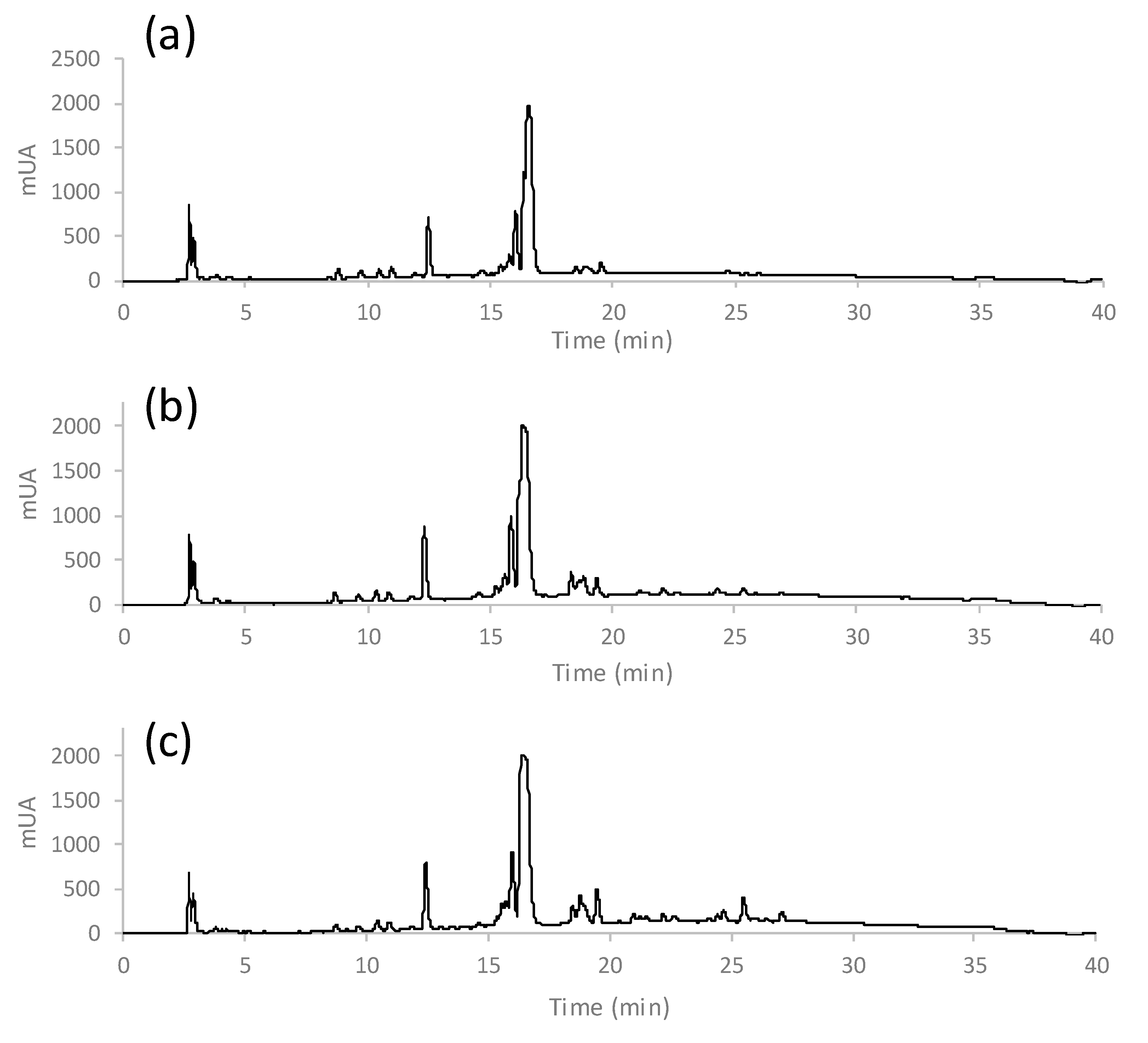
3.2. Non-Targeted HPLC-UV Fingerprints of Coffees
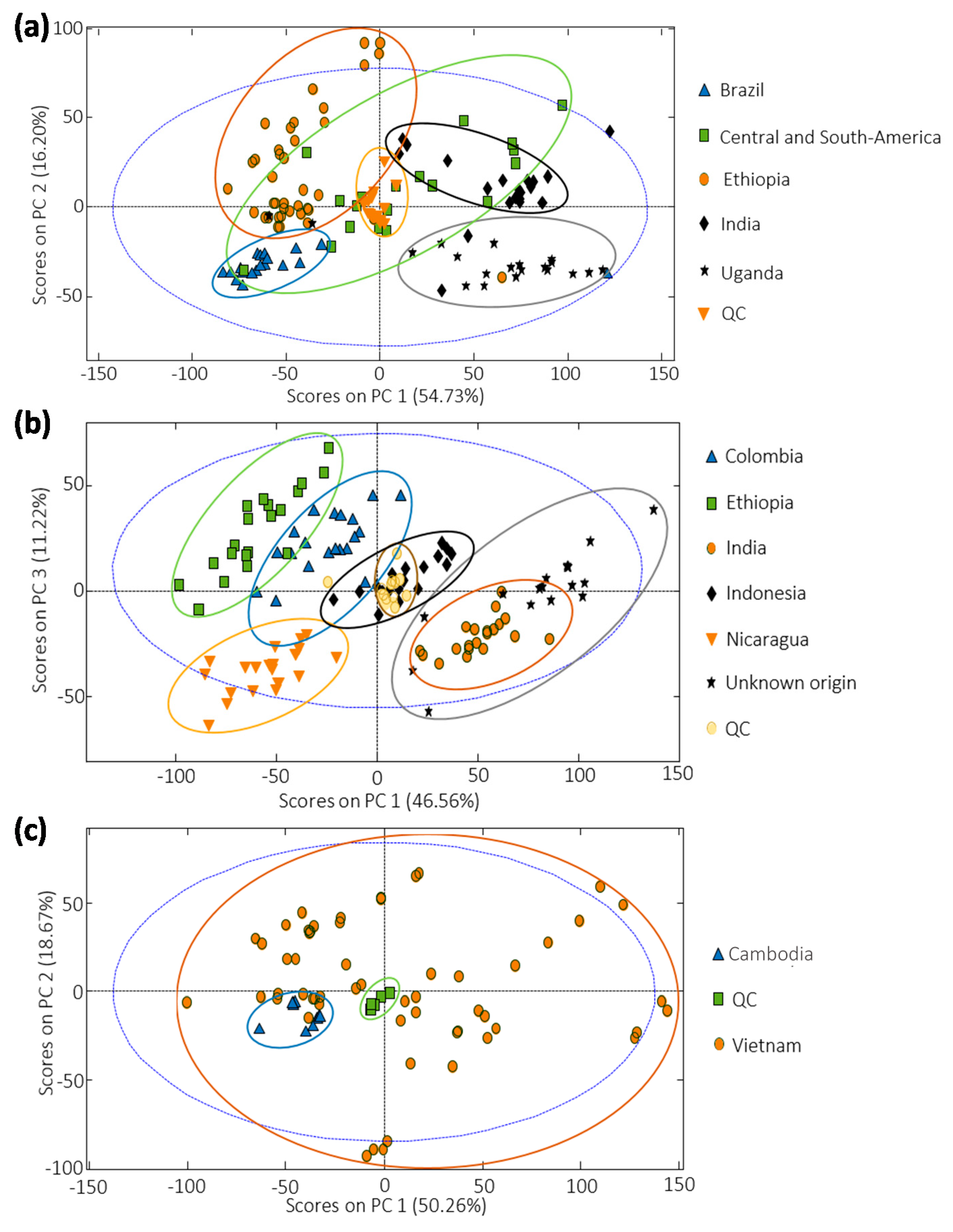
3.3. Sample Exploration by PCA
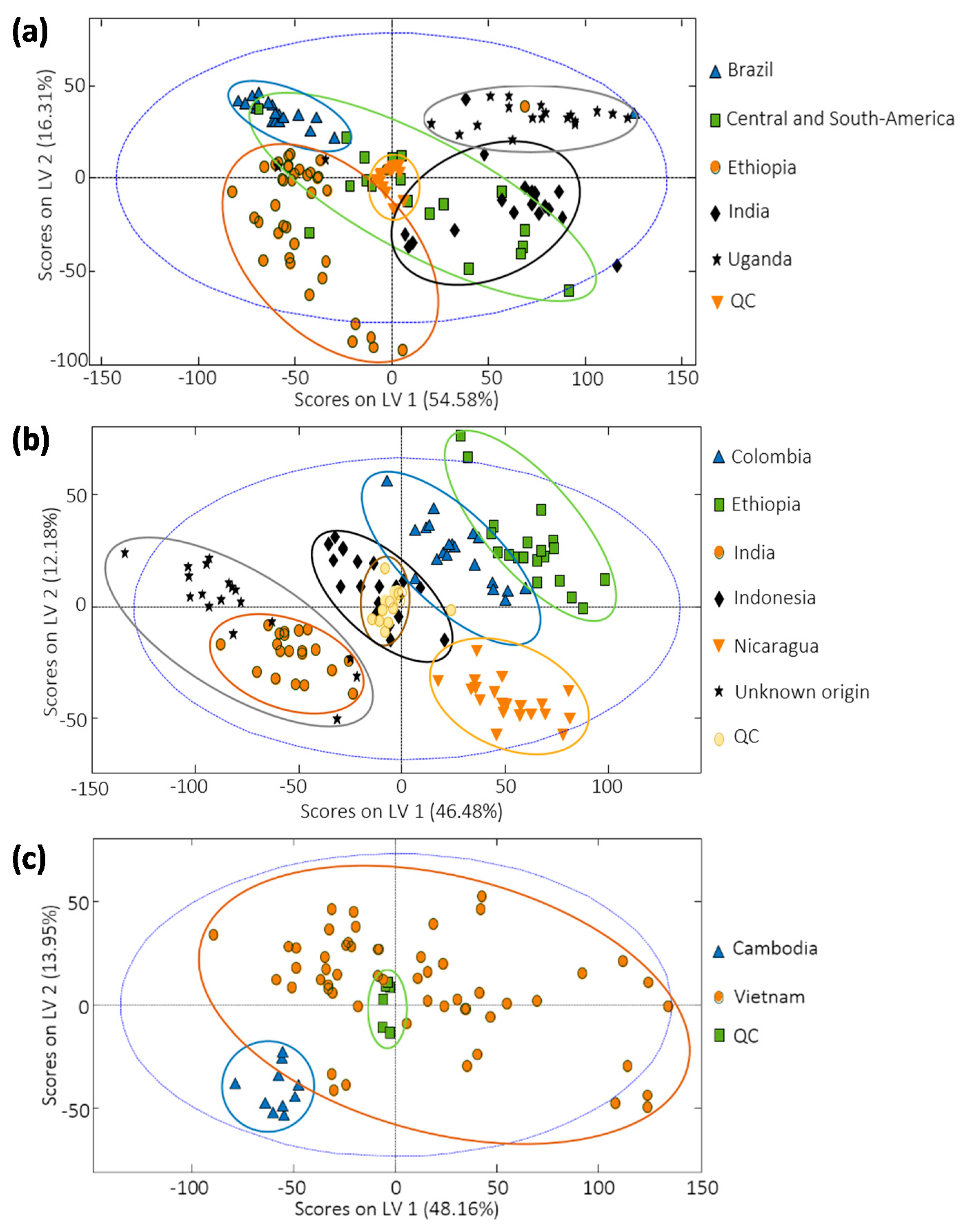
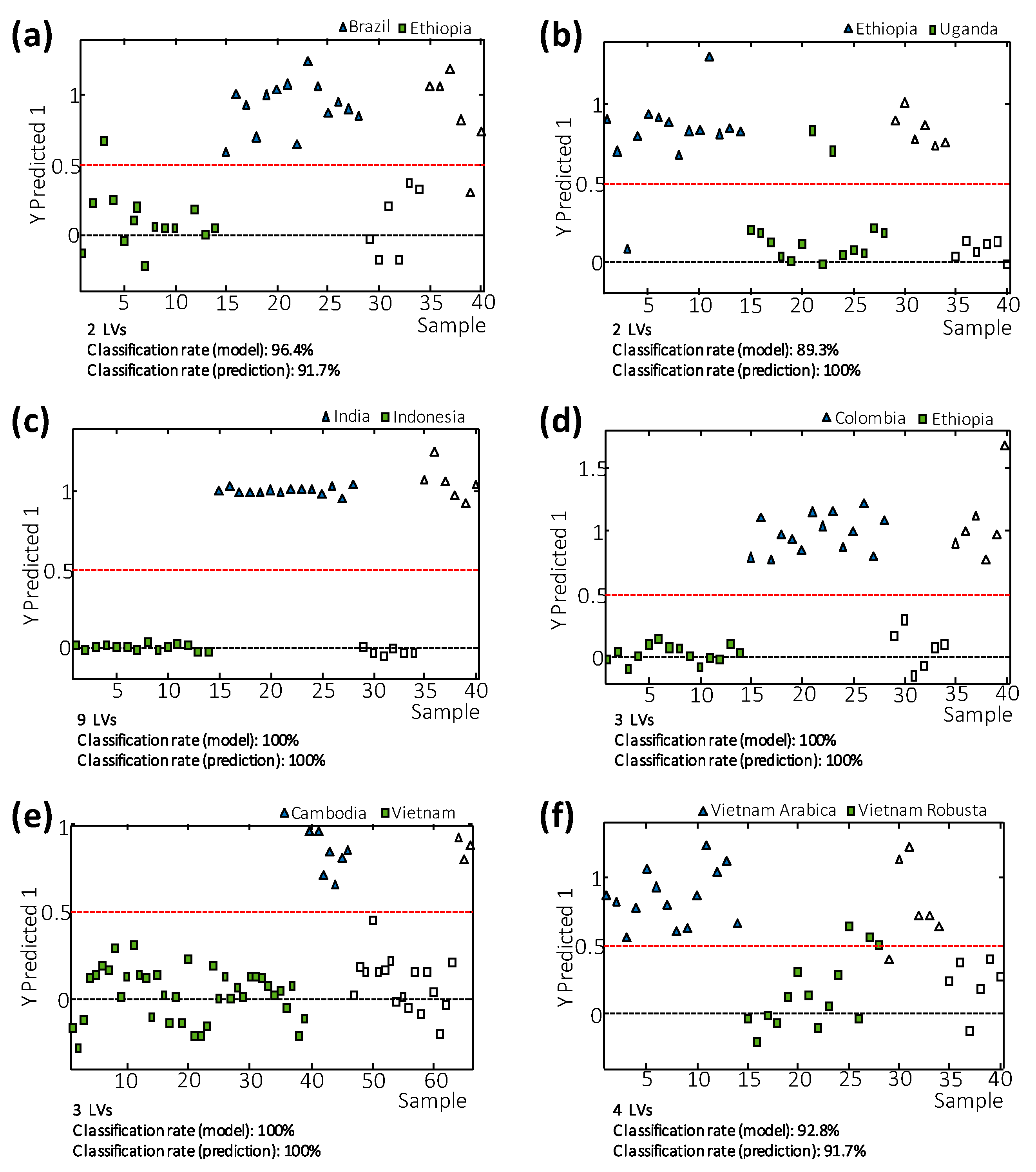
3.4. Sample Classification by PLS-DA
3.5. Supervised PLS-DA Method Validation
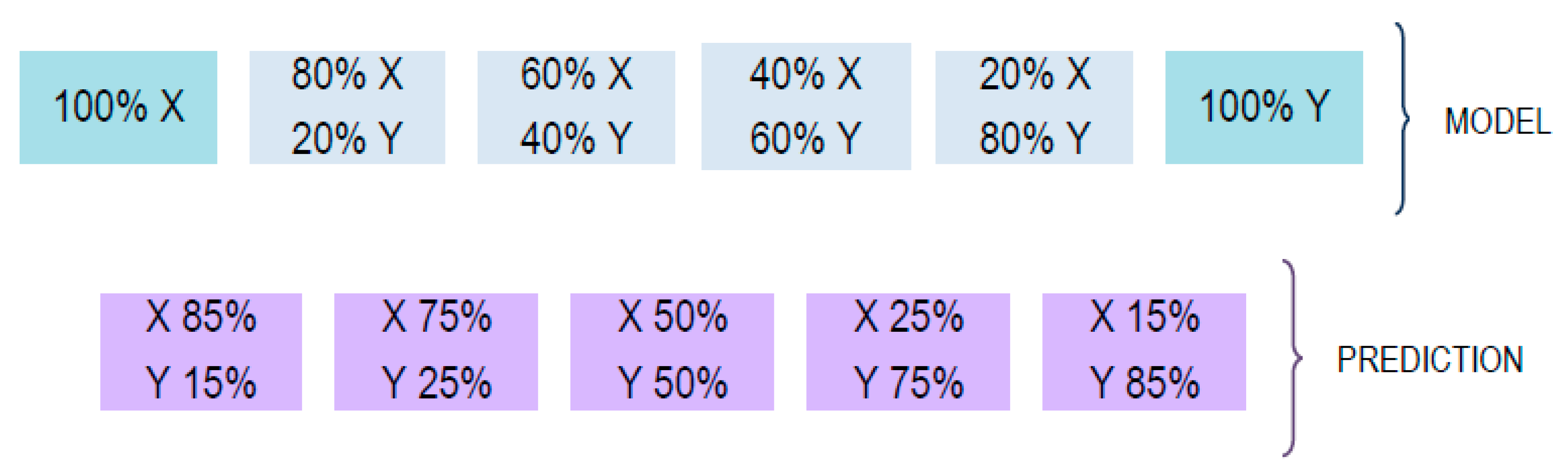
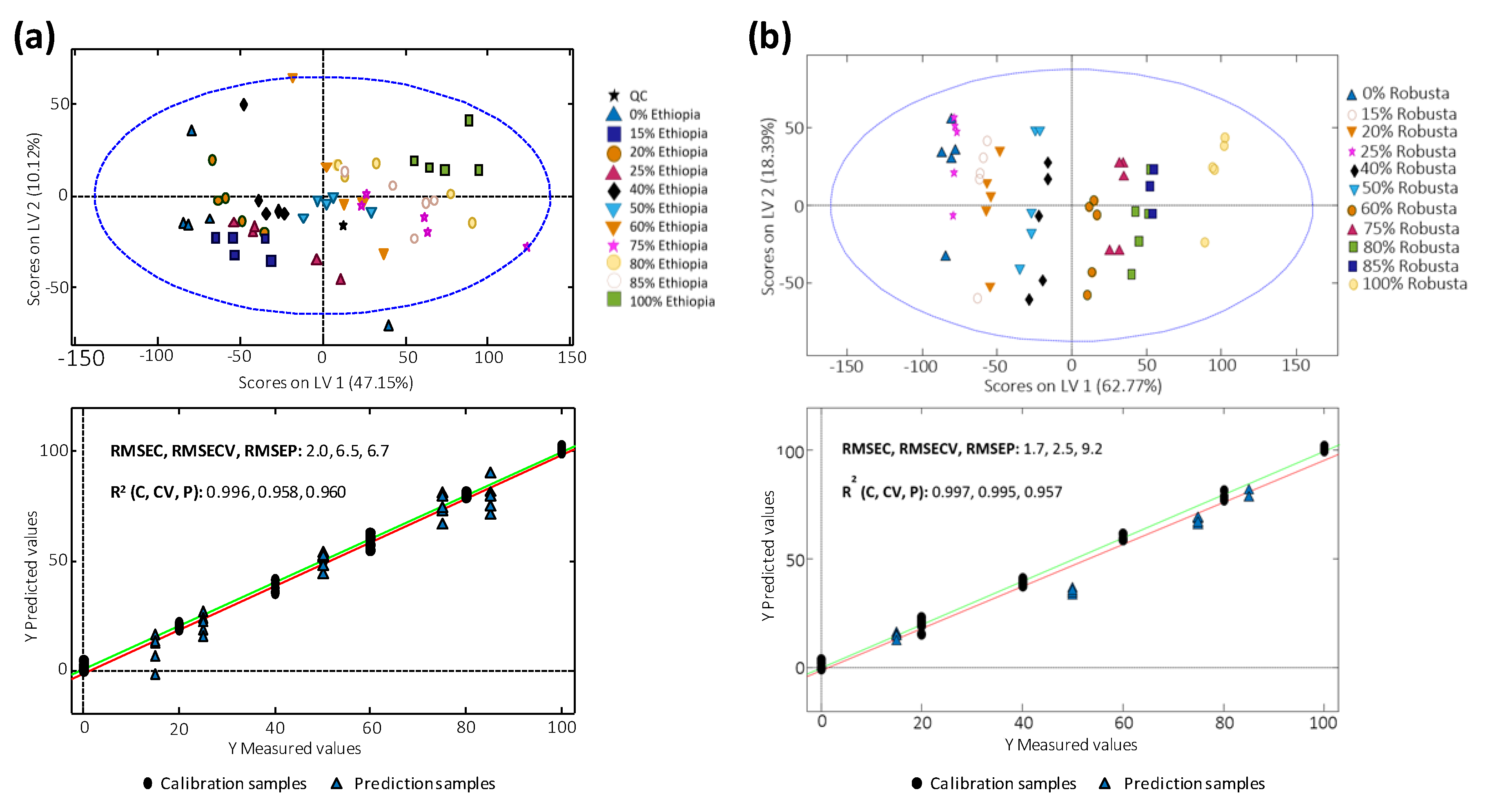
3.6. Quantitation of Coffee Adulterations by PLSR
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Campmajó, G.; Núñez, N.; Núñez, O. The Role of Liquid Chromatography-Mass Spectrometry in Food Integrity and Authenticity. In Mass Spectrometry—Future Perceptions and Applications; Kamble, G.S., Ed.; IntechOpen: London, UK, 2019; pp. 3–20. [Google Scholar]
- Moore, J.C.; Spink, J.; Lipp, M. Development and Application of a Database of Food Ingredient Fraud and Economically Motivated Adulteration from 1980 to 2010. J. Food Sci. 2012, 77, R118–R126. [Google Scholar] [CrossRef] [PubMed]
- Gonzalvez, A.; Armenta, S.; Guardia, M. De Trace-element composition and stable-isotope ratio for discrimination of foods with Protected Designation of Origin. Trends Anal. Chem. 2009, 28, 1295–1311. [Google Scholar] [CrossRef]
- Kamiloglu, S. Authenticity and traceability in beverages. Food Chem. 2019, 277, 12–24. [Google Scholar] [CrossRef] [PubMed]
- Naranjo, M.; Vélez, L.T.; Rojano, B.A. Actividad antioxidante de café colombiano de diferentes calidades. Revista Cubana de Plantas Medicinales 2011, 16, 164–173. [Google Scholar]
- Esquivel, P.; Jiménez, V.M. Functional properties of coffee and coffee by-products. Food Res. Int. 2012, 46, 488–495. [Google Scholar] [CrossRef]
- Herawati, D.; Giriwono, P.E.; Nur, F.; Dewi, A.; Kashiwagi, T.; Andarwulan, N. Critical roasting level determines bioactive content and antioxidant activity of Robusta coffee beans. Food Sci. Biotechnol. 2019, 28, 7–14. [Google Scholar] [CrossRef]
- Monteiro, P.I.; Santos, J.S.; Rodionova, O.Y.; Pomerantsev, A.; Chaves, E.S.; Rosso, N.D.; Granato, D. Chemometric Authentication of Brazilian Coffees Based on Chemical Profiling. J. Food Sci. 2019, 84, 3099–3108. [Google Scholar] [CrossRef]
- Belchior, V.; Botelho, B.G.; Casal, S.; Oliveira, L.S.; Franca, A.S. FTIR and Chemometrics as Effective Tools in Predicting the Quality of Specialty Coffees. Food Anal. Methods 2020, 13, 275–283. [Google Scholar] [CrossRef]
- Marquetti, I.; Link, J.V.; Lemes, A.L.G.; dos Santos Scholz, M.B.; Valderrama, P.; Bona, E. Partial least square with discriminant analysis and near infrared spectroscopy for evaluation of geographic and genotypic origin of arabica coffee. Comput. Electron. Agric. 2016, 121, 313–319. [Google Scholar] [CrossRef]
- Toci, A.T.; Farah, A. Volatile fingerprint of Brazilian defective coffee seeds: Corroboration of potential marker compounds and identification of new low quality indicators. Food Chem. 2014, 153, 298–314. [Google Scholar] [CrossRef]
- Smrke, S.; Kroslakova, I.; Gloess, A.N.; Yeretzian, C. Differentiation of degrees of ripeness of Catuai and Tipica green coffee by chromatographical and statistical techniques. Food Chem. 2015, 174, 637–642. [Google Scholar] [CrossRef] [PubMed]
- Blanc, M.B.; Davis, G.E.; Parchet, J.M.; Viani, R. Chromatographic Profile of Carbohydrates in Commercial Soluble Coffees. J. Agric. Food Chem. 1989, 37, 926–930. [Google Scholar] [CrossRef]
- Milani, M.I.; Rossini, E.L.; Catelani, T.A.; Pezza, L.; Toci, A.T.; Pezza, H.R. Authentication of roasted and ground coffee samples containing multiple adulterants using NMR and a chemometric approach. Food Control 2020, 112, 107104. [Google Scholar] [CrossRef]
- de Morais, T.C.B.; Rodrigues, D.R.; de Carvalho Polari Souto, U.T.; Lemos, S.G. A simple voltammetric electronic tongue for the analysis of coffee adulterations. Food Chem. 2019, 273, 31–38. [Google Scholar] [CrossRef] [PubMed]
- Daniel, D.; Lopes, F.S.; dos Santos, V.B.; do Lago, C.L. Detection of coffee adulteration with soybean and corn by capillary electrophoresis-tandem mass spectrometry. Food Chem. 2018, 243, 305–310. [Google Scholar] [CrossRef]
- Domingues, D.S.; Pauli, E.D.; De Abreu, J.E.M.; Massura, F.W.; Cristiano, V.; Santos, M.J.; Nixdorf, S.L. Detection of roasted and ground coffee adulteration by HPLC by amperometric and by post-column derivatization UV-Vis detection. Food Chem. 2014, 146, 353–362. [Google Scholar] [CrossRef]
- Toci, A.T.; Farah, A.; Pezza, H.R.; Pezza, L. Coffee Adulteration: More than Two Decades of Research. Crit. Rev. Anal. Chem. 2016, 46, 83–92. [Google Scholar] [CrossRef]
- Spaniolas, S.; Tsachaki, M.; Bennett, M.J.; Tucker, G.A. Evaluation of DNA extraction methods from green and roasted coffee beans. Food Control 2008, 19, 257–262. [Google Scholar] [CrossRef]
- Spaniolas, S.; May, S.T.; Bennett, M.J.; Tucker, G.A. Authentication of coffee by means of PCR-RFLP analysis and lab-on-a-chip capillary electrophoresis. J. Agric. Food Chem. 2006, 54, 7466–7470. [Google Scholar] [CrossRef]
- Pizarro, C.; Esteban-Díez, I.; González-Sáiz, J.M. Mixture resolution according to the percentage of robusta variety in order to detect adulteration in roasted coffee by near infrared spectroscopy. Anal. Chim. Acta 2007, 585, 266–276. [Google Scholar] [CrossRef]
- Ciampa, A.; Renzi, G.; Taglienti, A.; Sequi, P.; Valentini, M. Studies on coffee roasting process by means of nuclear magnetic resonance spectroscopy. J. Food Qual. 2010, 33, 199–211. [Google Scholar] [CrossRef]
- Reis, N.; Franca, A.S.; Oliveira, L.S. Discrimination between roasted coffee, roasted corn and coffee husks by Diffuse Reflectance Infrared Fourier Transform Spectroscopy. LWT Food Sci. Technol. 2013, 50, 715–722. [Google Scholar] [CrossRef]
- Garrett, R.; Vaz, B.G.; Hovell, A.M.C.; Eberlin, M.N.; Rezende, C.M. Arabica and Robusta coffees: Identification of major polar compounds and quantification of blends by direct-infusion electrospray ionization-mass spectrometry. J. Agric. Food Chem. 2012, 60, 4253–4258. [Google Scholar] [CrossRef] [PubMed]
- Belguidoum, K.; Amira-Guebailia, H.; Boulmokh, Y.; Houache, O. HPLC coupled to UV-vis detection for quantitative determination of phenolic compounds and caffeine in different brands of coffee in the Algerian market. J. Taiwan Inst. Chem. Eng. 2014, 45, 1314–1320. [Google Scholar] [CrossRef]
- Craig, A.P.; Fields, C.; Liang, N.; Kitts, D.; Erickson, A. Performance review of a fast HPLC-UV method for the quantification of chlorogenic acids in green coffee bean extracts. Talanta 2016, 154, 481–485. [Google Scholar] [CrossRef]
- De Luca, S.; Ciotoli, E.; Biancolillo, A.; Bucci, R.; Magrì, A.D.; Marini, F. Simultaneous quantification of caffeine and chlorogenic acid in coffee green beans and varietal classification of the samples by HPLC-DAD coupled with chemometrics. Environ. Sci. Pollut. Res. 2018, 25, 28748–28759. [Google Scholar] [CrossRef]
- Mnatsakanyan, M.; Stevenson, P.G.; Conlan, X.A.; Francis, P.S.; Goodie, T.A.; McDermott, G.P.; Barnett, N.W.; Shalliker, R.A. The analysis of café espresso using two-dimensional reversed phase-reversed phase high performance liquid chromatography with UV-absorbance and chemiluminescence detection. Talanta 2010, 82, 1358–1363. [Google Scholar] [CrossRef]
- Jham, G.N.; Winkler, J.K.; Berhow, M.A.; Vaughn, S.F. γ-tocopherol as a marker of Brazilian coffee (Coffea arabica L.) adulteration by corn. J. Agric. Food Chem. 2007, 55, 5995–5999. [Google Scholar] [CrossRef]
- Pérez-Míguez, R.; Sánchez-López, E.; Plaza, M.; Marina, M.L.; Castro-Puyana, M. Capillary electrophoresis-mass spectrometry metabolic fingerprinting of green and roasted coffee. J. Chromatogr. A 2019, 1605. [Google Scholar] [CrossRef]
- Barbosa, S.; Pardo-Mates, N.; Hidalgo-Serrano, M.; Saurina, J.; Puignou, L.; Núñez, O. UHPLC-HRMS (orbitrap) fingerprinting in the classification and authentication of cranberry-based natural products and pharmaceuticals using multivariate calibration methods. Anal. Methods 2019, 11, 3341–3349. [Google Scholar] [CrossRef]
- Barbosa, S.; Pardo-Mates, N.; Hidalgo-Serrano, M.; Saurina, J.; Puignou, L.; Núñez, O. Detection and Quantitation of Frauds in the Authentication of Cranberry-Based Extracts by UHPLC-HRMS (Orbitrap) Polyphenolic Profiling and Multivariate Calibration Methods. J. Agric. Food Chem. 2018, 66, 9353–9365. [Google Scholar] [CrossRef] [PubMed]
- Eigenvector Research Incorporated. Powerful Resources for Intelligent Data Analysis. Available online: http://www.eigenvector.com/software/solo.htm (accessed on 15 January 2019).
- Massart, D.L.; Vandeginste, B.G.M.; Buydens, L.M.C.; de Jong, S.; Lewi, P.J.; Smeyers-Verbeke, J. Handbook of Chemometrics and Qualimetrics; Elsevier: Amsterdam, The Netherlands, 1997. [Google Scholar]
- Lucci, P.; Saurina, J.; Núñez, O. Trends in LC-MS and LC-HRMS analysis and characterization of polyphenols in food. TrAC Trends Anal. Chem. 2017, 88, 1–24. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Commercial Name | Number of Samples | Coffee Variety | Origin Region | Roasting Degree |
|---|---|---|---|---|
| - | - | Set of sample 1 | - | - |
| Arabica Ethiopia Harrar | 20 | Arabica | Ethiopia | 1/5 |
| Bukeela | 20 | Arabica-Arabica Mixture | Ethiopia | 1/5 |
| Dulsao | 20 | Arabica | Brazil | 2/5 |
| Arpeggio | 20 | Arabica | Central and South-America | 4/5 |
| Indriya | 20 | Arabica-Robusta Mixture | India | 4/5 |
| Robusta Uganda | 20 | Robusta | Uganda | 4/5 |
| - | - | Set of sample 2 | - | - |
| Master Origin Colombia | 20 | Arabica | Colombia | 3/5 |
| Master Origin Ethiopia | 20 | Arabica | Ethiopia | 2/5 |
| Master Origin India | 20 | Arabica-Robusta Mixture | India | 5/5 |
| Master Origin Nicaragua | 20 | Arabica | Nicaragua | 2/5 |
| Master Origin Indonesia | 20 | Arabica | Indonesia | 4/5 |
| Paris Black | 20 | Arabica-Robusta Mixture | Unknown origin | 4/5 |
| - | - | Set of sample 3 | - | - |
| - | 20 | Arabica | Vietnam | Unknown |
| - | 20 | Robusta | Vietnam | Unknown |
| - | 10 | Mixture | Vietnam | Unknown |
| - | 6 | Unknown | Vietnam | Unknown |
| - | 10 | Unknown | Cambodia | Unknown |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Núñez, N.; Collado, X.; Martínez, C.; Saurina, J.; Núñez, O. Authentication of the Origin, Variety and Roasting Degree of Coffee Samples by Non-Targeted HPLC-UV Fingerprinting and Chemometrics. Application to the Detection and Quantitation of Adulterated Coffee Samples. Foods 2020, 9, 378. https://doi.org/10.3390/foods9030378
Núñez N, Collado X, Martínez C, Saurina J, Núñez O. Authentication of the Origin, Variety and Roasting Degree of Coffee Samples by Non-Targeted HPLC-UV Fingerprinting and Chemometrics. Application to the Detection and Quantitation of Adulterated Coffee Samples. Foods. 2020; 9(3):378. https://doi.org/10.3390/foods9030378
Chicago/Turabian StyleNúñez, Nerea, Xavi Collado, Clara Martínez, Javier Saurina, and Oscar Núñez. 2020. "Authentication of the Origin, Variety and Roasting Degree of Coffee Samples by Non-Targeted HPLC-UV Fingerprinting and Chemometrics. Application to the Detection and Quantitation of Adulterated Coffee Samples" Foods 9, no. 3: 378. https://doi.org/10.3390/foods9030378
APA StyleNúñez, N., Collado, X., Martínez, C., Saurina, J., & Núñez, O. (2020). Authentication of the Origin, Variety and Roasting Degree of Coffee Samples by Non-Targeted HPLC-UV Fingerprinting and Chemometrics. Application to the Detection and Quantitation of Adulterated Coffee Samples. Foods, 9(3), 378. https://doi.org/10.3390/foods9030378