Abstract
Nowadays, climate change and atmospheric pollution are two of humanity's most significant challenges. Greenhouse gases (GHGs) are responsible for climate change, and they create effects that are mostly irreversible. Therefore, monitoring and reducing such emissions are compulsory for the preservation of the environment for future generations. The European Union took action in this direction. The article presents the evolution of the total GHGs trend, from 1990 to 2021, in the EU countries and their associates. Trend analysis and grouping of the countries using different clustering techniques are performed. The analysis of the existence of greenhouse gases (GHGs) series’ trend, in 30 countries from Europe, showed that the GHG emissions decreased from 1990 to 2021 in only 17 countries. The annual series, built using the data reported by each country each year, does not present a specific trend. After grouping the countries in clusters by k-means and hierarchical clustering, the representative series for the annual recorded values in the 30 studied countries, called Regional series (RegS), is built using series selected from the cluster with the highest number of elements. The same algorithm provides the Representative Temporal series (TempS), which selects specific years after clustering the annual GHG series.
1. Introduction
The climate change impact on the environment, due to the continuous growth of greenhouse gas (GHG) emissions that produce global warming, has become one of the major concerns at the international level. With the increasing temperature trend, extreme weather events have become more frequent in many world regions [1].
GHGs are essential components for maintaining the conditions for survival, as well as producing an atmospheric layer that protects against the direct UV rays’ impact on the Earth [2]. At the same time, they are the highest contributors to global temperature augmentation. Since industrialization, an enormous quantity of GHGs have been produced by anthropogenic activities. For example, in 2018, GHG emissions were 41% higher than in 1990 [3].
The principal anthropic sources are transportation (especially from fossil fuels burning), electricity production, agriculture, land use, and forestry [4,5]. The U.S. Inventory [6] indicates that, in 2021, in the USA, the GHG volume exceeded 6340.2 mil mt of CO2 equivalents, which 6% higher than in 2020 but 17% lower than in 2005. The study by Hadipoor et al. [7] found that CO2 is one of the primary sources of pollution, indicating the correct trend to control the emissions to reduce the amount of gases released in the air.
According to the Intergovernmental Panel on Climate Change (IPCC) special report on climate change, the global temperature has been augmented by 0.8–1.2 °C with respect to the pre-industrial level. It is predicted to rise by 1.5 °C by 2030 and about 3 °C by 2100 if the emissions rate is the same [8].
Some GHG emissions are removed by natural sinks that are globally present. Still, the others (CO2, N2O, CFCs, HCFCs, PFCs, SF6) can last in the atmosphere for several hundred years, contributing to global temperature increase [9]. Therefore, the GHG emissions must be controlled, and conditions to stimulate their removal through natural sinks (or artificially designed sinks) must be created [3].
According to Naiyer and Abbas [2], although the effect of constant direct exposure of the human body to GHGs appears negligible, their increasing concentration over time is the main cause of different human illnesses. The most affected systems of the human organism are the respiratory system (provoking respiratory acidosis) [10,11], the cardiovascular system [12], the immune system [13,14], the digestive system, and CNS (affecting the brain cells, which may lead to memory loss) [14]. Measuring the impact of GHGs on human health and its quantification are aspects that must be clearly established at the global level [2].
In the context of climate change, the Paris Agreement in 2015 [15] set the goal of limiting the temperature increase, at the global scale, under 2 °C by 2050–2100. The European Union (EU) aims to achieve net-zero emissions by 2050. Therefore, many countries developed renewable energy sources for producing energy from non-pollutant sources. The United Kingdom is working to enhance the removal potential of natural sinks [16]. India (the world’s third largest contributor of GHGs) aims to reduce GHG emissions by 33–35% by 2030, compared to 2005. It also implements measures to generate 40% of electricity from renewable or nuclear sources by 2030 [17]. In the effort to reduce the effects of atmospheric pollution on the climate, in 2020, the European Union achieved a more than 30% emission decrease with respect to the levels from 1990 [18].
Controlling and monitoring the emission sources, understanding the processes produced in the atmosphere by gases’ reactions, and forecasting the effects are essential before taking measures for GHG reduction. Atmospheric conditions and hydro-meteorological variables [19,20,21] influence the gas dissipation and the apparition of secondary products.
Given the importance of the above topic and international concerns, different articles proposed models, especially for estimating GHG emissions from transportation [22,23,24,25]. Alhindawi et al. [23] considered the ratio of vehicle–kilometer, by mode, to the number of transportation vehicles for six transportation modes. They proposed multivariate regression and double exponential smoothing models to forecast GHG emissions. Güzel and Alp [24] utilized the Integrated MARKAL-EFOM System (TIMES) and an economic model for the same goal in three scenarios. The CRTEM/HBEFA-China can be employed to compute future emission scenarios; a software package integrated into CRTEM/HBEFA-China was also developed [25].
In the global context, there is interest in maintaining a decreasing GHG emission trend in Europe and determining the countries that should be sustained to reach the imposed levels. The present study analyzes the total GHGs trend in the UE_27 and some associated members (Switzerland, Norway, and Iceland) from 1990 to 2021. It also groups the series into different clusters using the k-means algorithm and hierarchical clustering. Additionally, two types of series that describe the evolution of GHGs in the EU are proposed. The first is the Regional series (RegS), which is computed using series from selected countries. The second one is the Representative Temporal series (TempS), which is built by selecting specific years after clustering the annual GHG series and applying an original algorithm [5,15].
2. Materials and Methods
2.1. Data Series
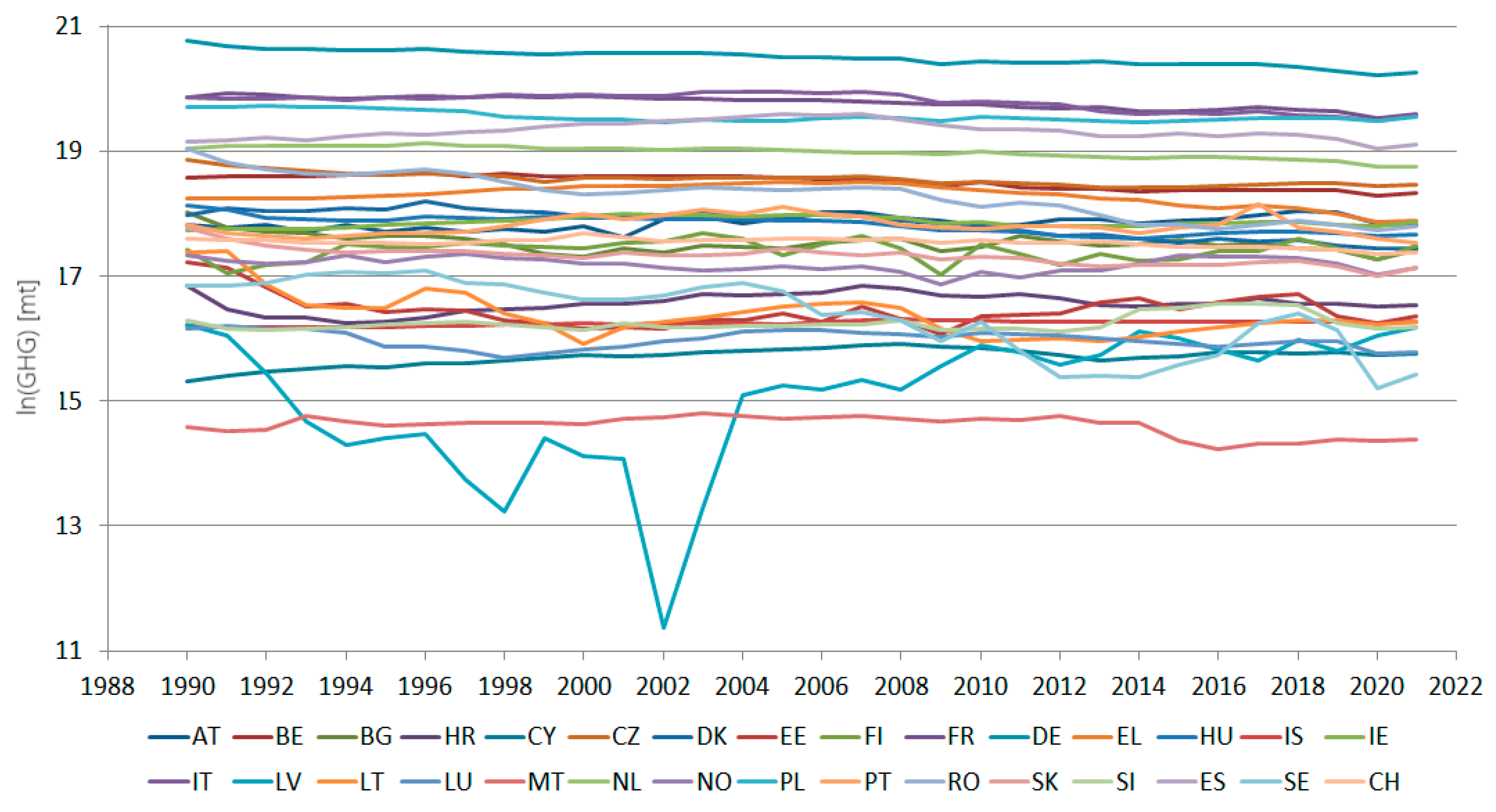
The studied data series consists of the total GHG net emissions (in mt CO2 equivalent), reported from 1990 to 2021, by the EU-27 countries and three associated members (Switzerland, Norway, and Iceland) to the United Nations Framework Convention on Climate Change. They are retrieved from [26]. Figure 1 presents the studied series, in logarithmic scale, for image clarity.

Figure 1.
The total CHG series (mt equivalent CO2), on a logarithmic scale, in 30 European countries from 1990 to 2021.
2.2. Methodology
The first step was to test the null hypothesis that there is no monotonic trend against the hypothesis and that such a trend exists for all series. The Mann–Kendall test (MK) [27] was utilized, followed by Sen’s slope procedure [28] when the MK test rejected the null hypothesis. In such a case, a nonparametric linear slope is determined. The procedure is applied for the series registered in each country, the total series (computed by summing up the values recorded in all the countries), and each annual series formed by the values recorded in a specific year in all countries.
In the second stage, the series are grouped in clusters, based on the k-means algorithm [29] and hierarchical clustering [30], to determine the countries with similar pollution levels. The silhouette [31], the elbow–knee method [32,33], and the gap statistics [34,35] were utilized to select the optimal number of clusters, k. The ratio between clusters' sum of squares and the total sum of squares (BSS/TSS) is computed to determine the best clustering in the k-means algorithm. The higher the ratio, the better the clustering. Various methodologies are employed to choose k, so the results of the three algorithms are sometimes different. Therefore, in the present study, we explore the various situations.
Hierarchical clustering provides a dendrogram, showing the hierarchy of the series, which can be assessed and built using the matrix of the distances (Euclidean, Hamming, Manhattan, Cambera, Jaccard, etc.) between the elements (observations, series) that will be grouped. Based on the distance matrix, the similarities between the elements can be assessed by the “average”, “complete”, “median”, “ward.D”, and “ward.D2” methods. Here, we employed the first and last methods. In the average measure, the mean distance between the observations in each group is weighted by the number of observations in each cluster. In the “ward.D2”, the sum of squared errors is minimized, with the clusters being combined based on smaller distances between groups.
To choose between the “average” and “ward.D2”, the cophenetic correlation coefficient [36,37] was utilized. Values above 0.9 show a very good performance, the coefficients in the interval 0.8–0.9 indicate a good performance, and values under 0.8 prove a poor clustering quality. Bootstrapping (resampling from the data set and rerunning the algorithm) is done, and the average Jaccard measures are computed to check if the clustering algorithm provides a good representation of the groups in the studied data set. If they are greater than 0.85 (in the interval 0.6–0.85), the cluster is highly stable (stable). Values less than 0.6 indicate the cluster’s instability [38]. The advantages/disadvantages of k-means and hierarchical clustering are discussed in [39].
In the last stage, the RegS is built using the series recorded in each country (30 series) by the following procedure [15,40].
- Find the number of clusters for performing the clustering algorithms.
- Perform the k-means and hierarchical clustering for grouping the countries. Choose the best clustering using the criteria explained above.
- Select the cluster formed by the highest number of countries, as denoted by Clmax. If many clusters have the same largest number of elements, Clmax is that with the highest separation distance from the others and the lowest between the internal members [41].
- Build the Regional series by averaging the corresponding values of the series in Clmax. Thus, the value for the year j is the average of the values recorded in the year j in the countries from Clmax.
- Compute the modeling errors as differences between the recorded values and those of the Regional series.
- Determine the goodness-of-fit of the Regional series by computing the mean absolute percentage error (MAPE).
The same procedure is applied to the 32 annual series to determine the TempS, with each containing 30 values (reported by a different country during a specific year.
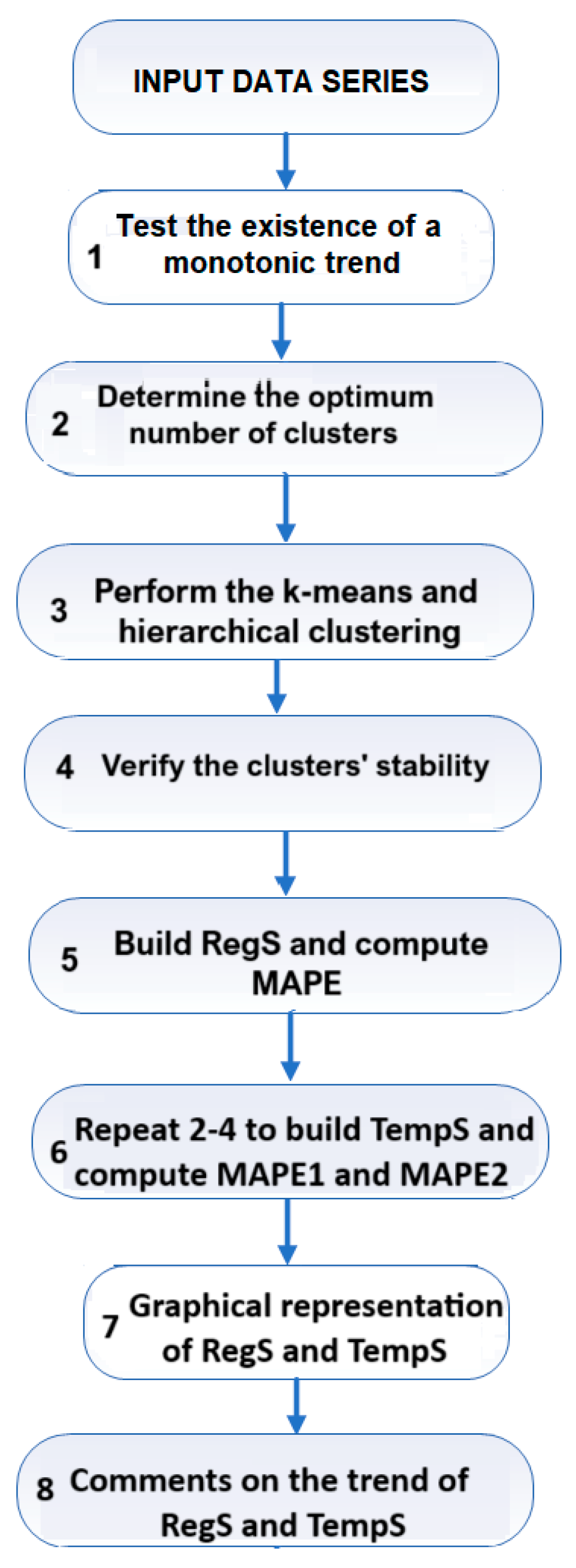
The flowchart of the work is presented in Figure 2.
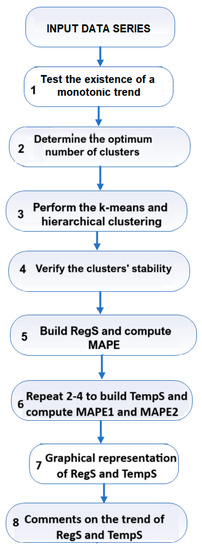
Figure 2.
Flowchart of the work.
The R 4.3.2 software (https://www.r-project.org/, accessed on 21 July 2023) was utilized to conduct the study.
3. Results and Discussion
In the following, we shall use the abbreviations of the countries names, according to the international conventions, as follows: Austria (AT), Belgium (BE), Bulgaria (BG), Croatia (HR), Cyprus (CY), Czech Republic (CZ), Denmark (DK), Estonia (EE), Finland (FI), France (FR), Germany (DE), Greece (EL), Hungary (HU), Ireland (IE), Island (IS), Italy (IT), Latvia (LV), Lithuania (LT), Luxembourg (LU), Malta (MT), Netherland (NL), Norway (NO), Poland (PL), Portugal (PT), Romania (RO), Slovakia (SK), Slovenia (SI), Spain (ES), Sweden (SE), and Switzerland (CH).
Analyzing the total annual GHGs series recorded for the EU-27 (obtained by summing up the values recorded in all the EU countries during 1990–2021), two subperiods are determined—before 2002, with a logarithmic trend with the equation:
and after 2003, with a linear trend with the equation:
where t is the time, and is the value of the series at the moment t.
Overall, the trend of the total GHGs series during 1990–2021 is decreasing.
3.1. Building the Regional GHGs Series
Table 1 contains the p-values associated with the MK test for each country’s total GHGs series recorded from 1990 to 2021. When the p-value is less than 0.05 (the significance level), the p-value is followed (in the brackets) by the sign plus or minus if the slope determined by Sen's method is positive or negative, respectively. Out of 30 countries, the null hypothesis could not be rejected for 9. A negative trend has been determined for 17 series, whereas the estimated total GHGs series trend is positive for only 4 countries (AT, CY, IS, and LV).

Table 1.
The p-values in the MK test for the total GHGs per country.
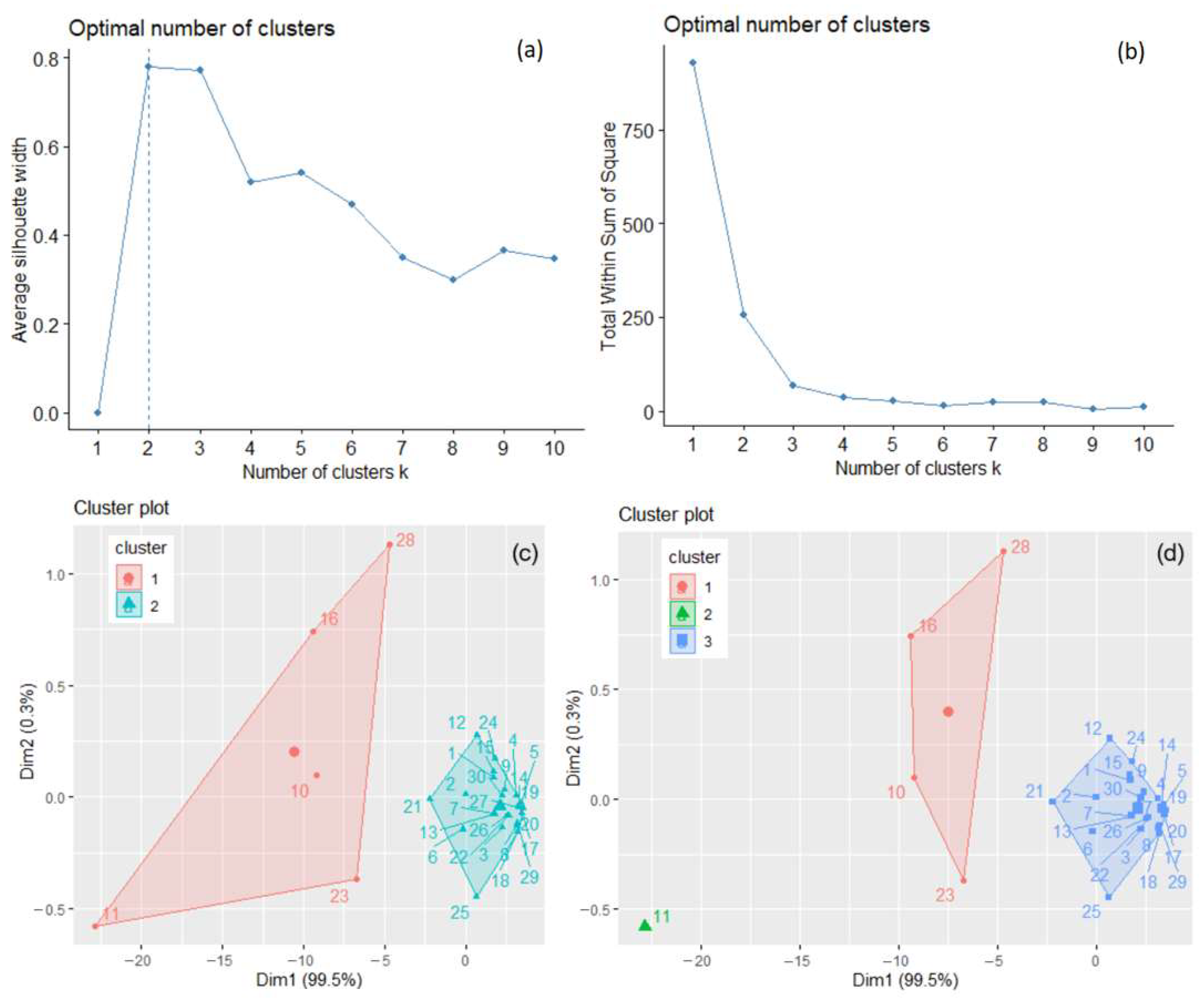
The optimal number of clusters used in the k-means algorithm was determined to be two by the silhouette method, three by the elbow–knee method (Figure 3a,b), and one by the gap statistics. It is known that, when some clusters are close to each other and another one is far from them, the gap statistics can underestimate the value of k [35]. Therefore, the option of a single cluster was removed, and the analysis was performed with two and three clusters. Finally, the best solution was chosen.
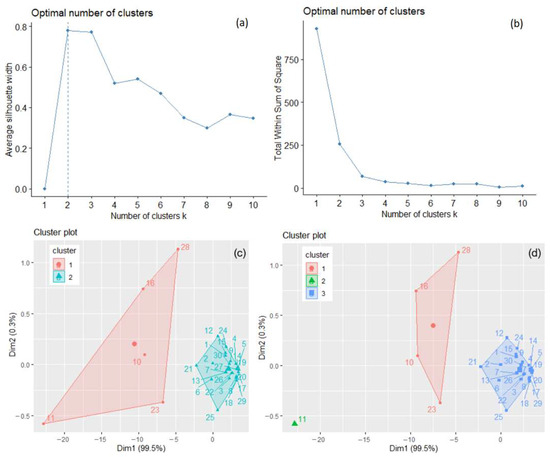
Figure 3.
The optimal number of clusters determined for the total GHG series, recorded in 30 countries by the silhouette method (a) and the elbow–knee method (b). The clusters of the countries are determined by k-means with k = 2 (c) and k = 3 (d).
The clusters that result when applying the k-means algorithm with k = 2 and k = 3 are presented in Figure 3c,d. When k = 2, the within-cluster sum of squares is 206.439 and 49.079, respectively, with the ratio BSS/TSS = 72.5 %. When k = 3, the within-cluster sum of squares, by cluster, is 13.321, 0.000, and 49.079, respectively, with the ratio BSS/TSS = 93.8 %. Figure 3d shows a better separation of the clusters (lower values of the within sum of squares, by cluster, and a significantly higher BSS/TSS ratio). To confirm the results, hierarchical clustering was applied for both values, with “ward.D2” and “average” methods. The highest cophenetic coefficient (0.956) was obtained for k = 3 clusters and the “average” method, indicating good clustering. After bootstrapping, the obtained average Jaccard values and corresponding instabilities were 0.632 (0.368), 0.742 (0.252), and 0.964 (0.000) for clusters 1, 2, and 3, respectively, indicating the clusters’ stability.
The k-means and hierarchical clustering provided the same groups of countries based on the total emitted GHGs.
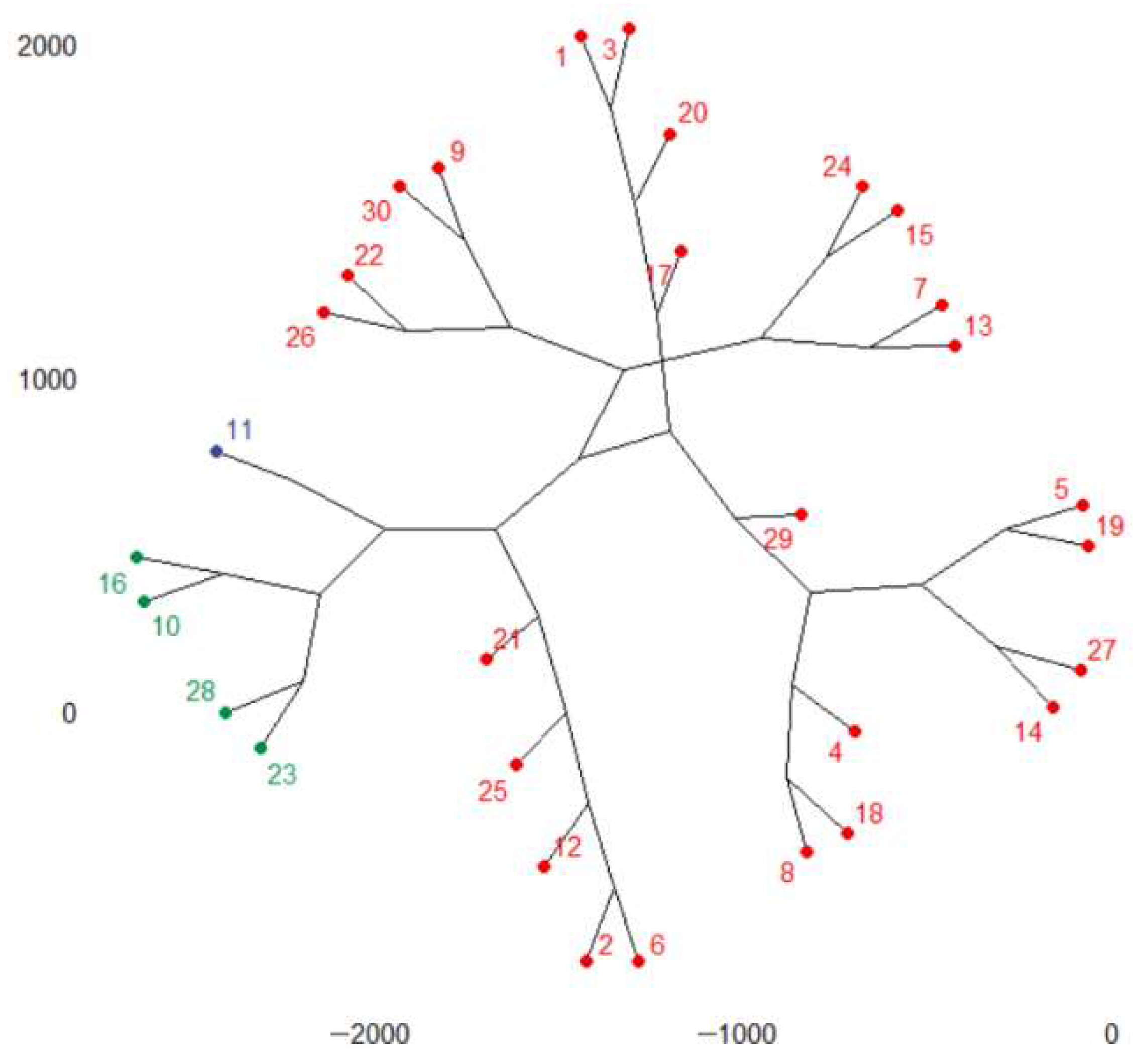
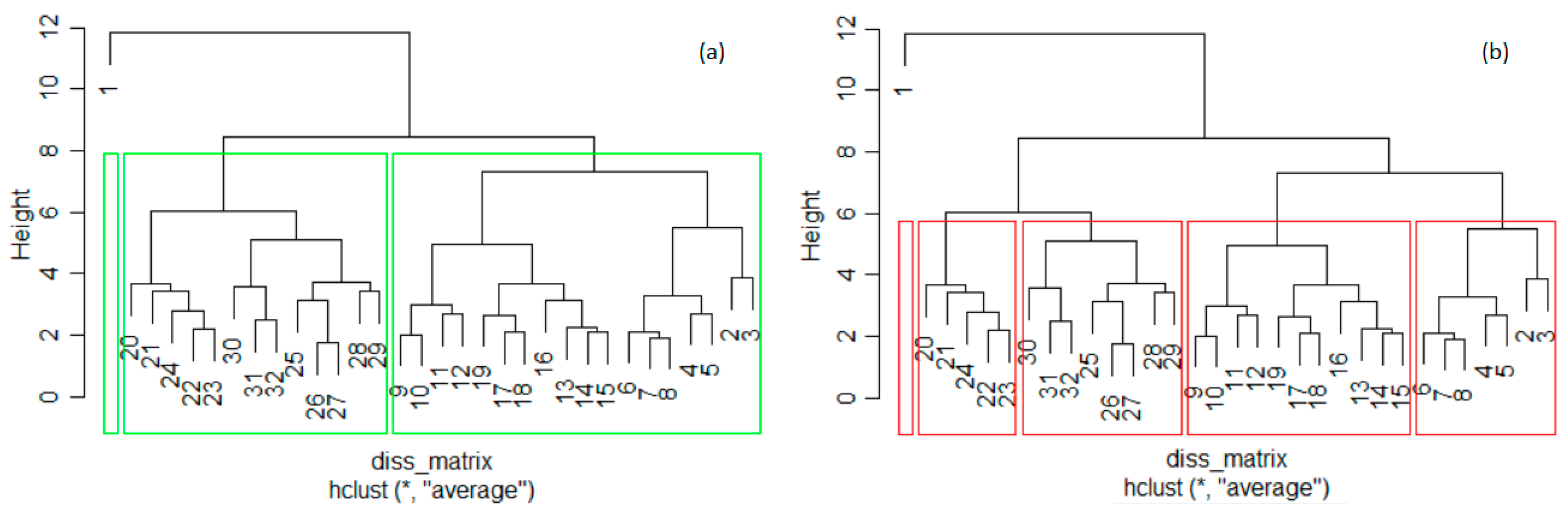
The phylogenic dendrogram for k = 3 is presented in Figure 4. According to Figure 4, France, Italy, Poland, and Spain belong to the first group, Germany belongs to the second group, and the rest of the countries are in the third cluster. Germany is the county with the highest emissions.
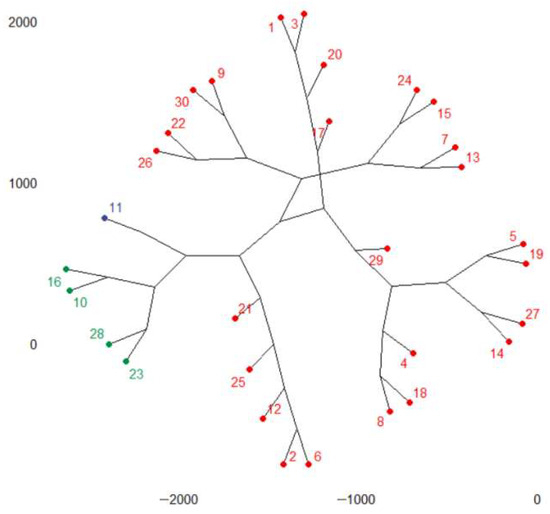
Figure 4.
The phylogenic dendrogram for the total GHGs series. Cluster 1: FR (10), IT(16), PL(23), ES(28); cluster 2: DE(11); cluster 3: the rest of the countries.
In the countries from the second group, the recorded emissions are above 228 mil mt and below 565.4 mil mt CO2 equivalent. In the countries from the third group, the maximum recorded value of GHGs was 228,533,250 mt CO2 equivalent.
Given the above results, the regional series was built using the series from the third cluster. The MAPE (Table 2) goodness-of-fit indicator is a non-dimensional indicator that gives a better image of the fitting quality than the dimensional indicators and permit comparisons between different data series. The lower the MAPE is, the better the fitting is. The fitting results are good for most countries. The series in the first and second clusters are well estimated. Very high values of MAPE are recorded for some countries belonging to the last group, which have very low emissions.
Table 2.
MAPE (%) in modeling the Regional Series GHGs series.
3.2. Building the Representative Temporal Series
According to Table 3, which contains the p-values in the MK test for the annual total GHG series, the null hypothesis could not be rejected for all these series, so one cannot assume the existence of a monotonic trend of annual series.
Table 3.
The p-values in the MK test for the annual total GHGs series.
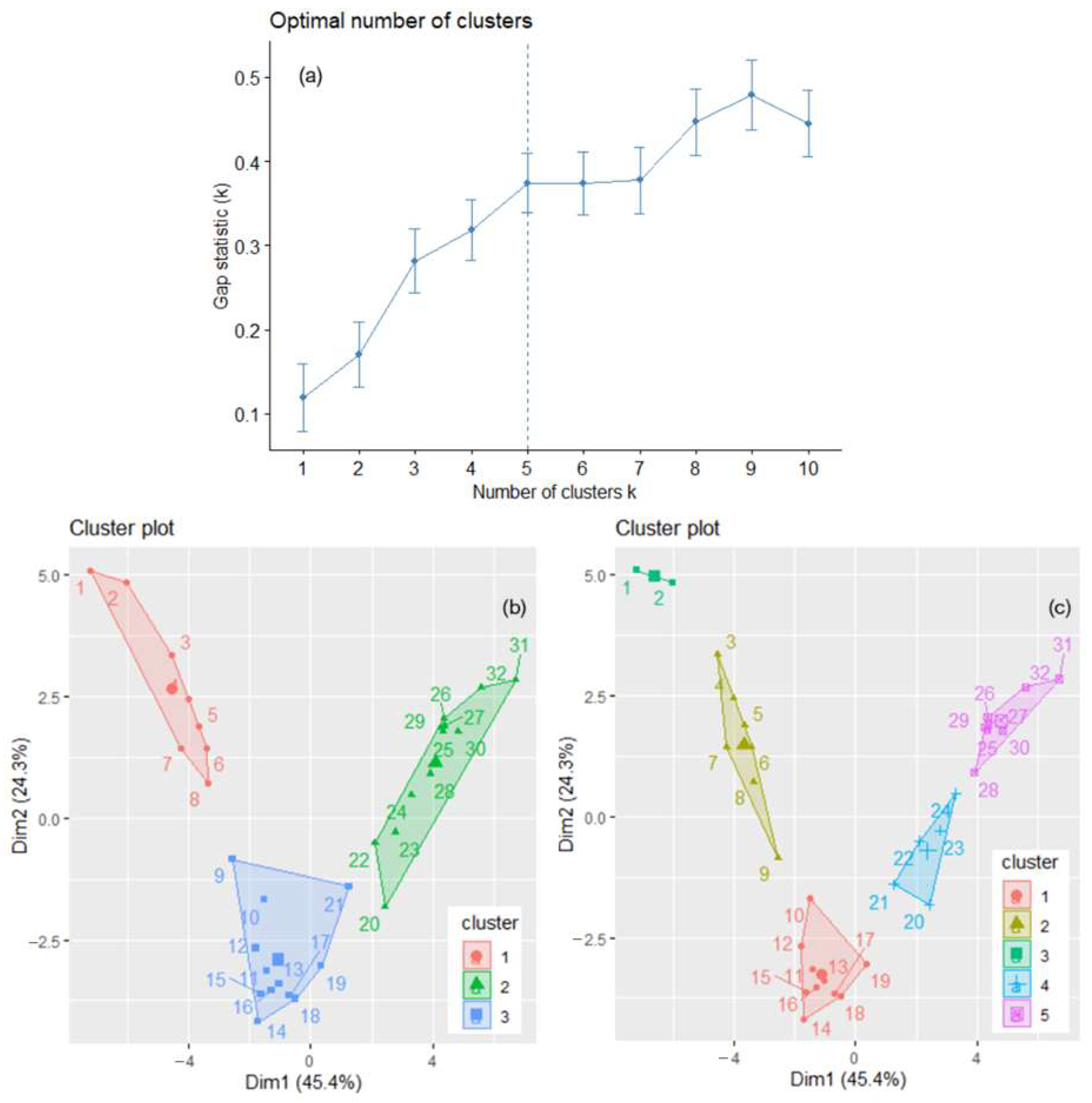
The optimal number of clusters for the annual total GHGs series is either three—determined by the silhouette and elbow–knee methods—or five—detected by the gap statistics (Figure 5a). Therefore, the analysis was done for k = 3 and k = 5. The clusters obtained by the k-means algorithm for the annual GHGs series are presented in Figure 5b,c. The years are from 1 (1990) to 32 (2021). BSS/TSS is 59.9% when k = 3 and 76.3% when k = 5. When k = 3, 1990–1997 (1–8 in Figure 5b) belong to the first cluster, 1998–2008 and 2010 are in the second, and 2009 and 2011–2021 belong to the third.
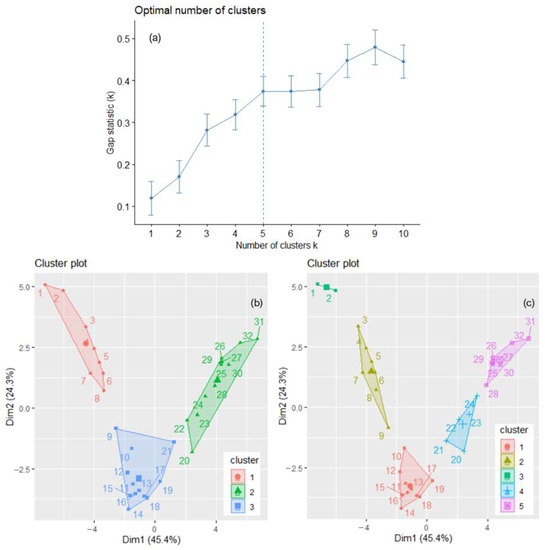
Figure 5.
(a) k = 5, indicated by the dotted vertical line, is the optimum number of clusters found by the gap statistics. The clusters of the annual GHGs series are determined by k-means with (b) k = 3 and (c) k = 5. The years are numbered from 1 to 32, corresponding to the years from 1990 to 2021.
The within-cluster sum of squares by cluster is, respectively, 119.414, 106.360, and 147.550 (and the BSS/TSS = 59.9%). When k = 5 (Figure 5c), the clusters are formed by the years 1990 and 1991 (cluster 3), 1992–1998 (cluster 2), 1999–2008 (cluster 3), 2009–2013 (cluster 4), 2014–2021 (cluster 5). The cophenetic coefficient was 0.8119 (0.7163) when using the “average” (“ward.D2”) method in the hierarchical clustering. Therefore, the first one was employed to build the clusters.
The dendrograms (Figure 6) do not confirm the clustering by the k-means. In both dendrograms, the first years form a separate cluster. Still, for k = 3, the second cluster in the dendrogram includes the years from the second cluster in the k-means and 2010. The first cluster, except 1990, and the third one in the k-means are merged to obtain the third cluster in Figure 6a.
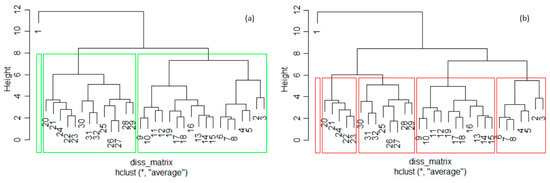
Figure 6.
Dendrogram of the annual total GHGs series and clusters determined by hierarchical clustering with (a) k = 3 and (b) k = 5. The years are numbered from 1 (1990) to 32 (2021).
For k = 5, 1991 (year 2 from cluster 3 in Figure 5c) forms a single cluster in the hierarchical clustering (Figure 6b, the left-hand-side cluster), and 1991 was included in the cluster containing 1992–1997 (the right-hand cluster in Figure 6b). The year 1998 (year 9 from cluster 2 in Figure 5c) was moved to the fourth cluster (from left to right in Figure 6b) together with 1999–2008.
The fourth (and fifth) cluster in k-means coincides with the third (and second) in Figure 6b. Thus, there are only a few differences between the clusters provided by the k-means and hierarchical clustering when k = 5. After bootstrapping, the average Jaccard values and corresponding instabilities in the k-means clustering with k = 3 are 0.824 (0.070), 0.847 (0.166), and 0.988 (0.020), respectively, indicating high stability. For k = 5, lower stabilities were obtained. Therefore, the best clustering of the annual total of GHG series was obtained with k = 3 (Figure 6a). Therefore, the series that will participate in building TempS belongs to the cluster with the highest ratio of BSS/TSS in the k-means algorithm: the third cluster.
Table 4 provides the MAPE in this case (MAPE 1) and compares them with those obtained when the representative temporal series would be computed using the elements from the second cluster (MAPE2). The values of MAPE1 vary between 4.134 and 40.619 for all years but 2012. MAPE2’s variation interval is 5.310–60.698, except for 2012 when it is 312.412 because of the very low value recorded in Latvia (109.406 mt CO2 equivalent). The average MAPE is significantly lower (21.129 compared to 30.661) when building the TempS with the elements in the third cluster.
Table 4.
MAPE (%) in building TempS for the total GHGs series.
3.3. General Comments
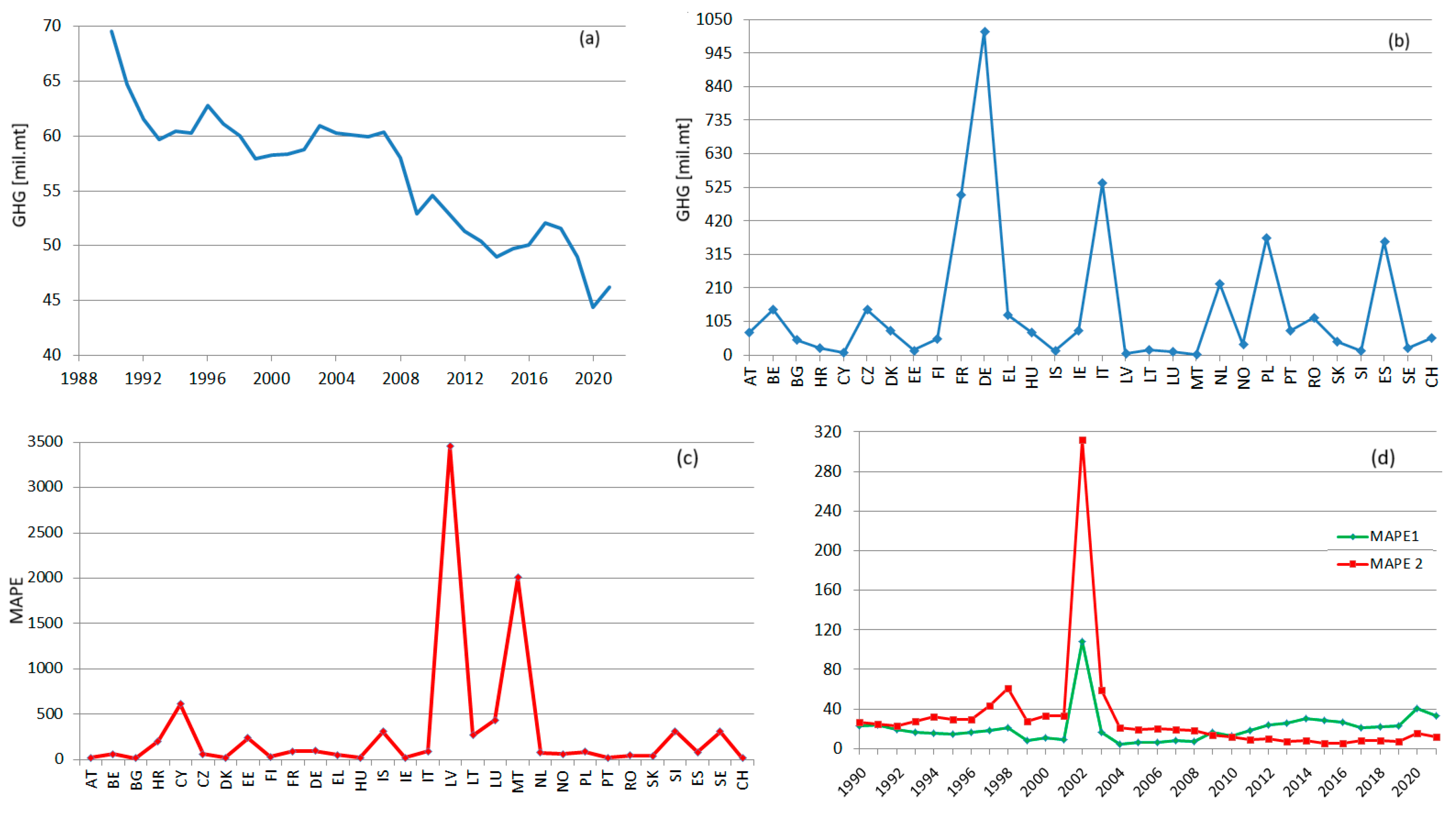
The charts of RegS and TempS are shown in Figure 7, together, with the corresponding MAPEs. None of RegS and TempS are linear. An overall decreasing trend can be emphasized for RegS (Figure 7a), with slight subperiods of augmentation followed by periods of abrupt decrease. The presence of decrement periods is due to the existence of series with an increasing tendency or periods of variation around a particular value, followed by decay periods. Still, the decrease in RegS from 1990 to 2021 is significant.
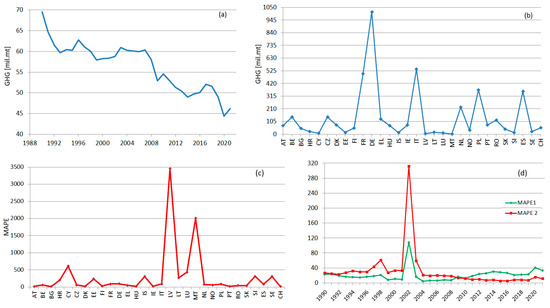
Figure 7.
(a) RegS and (b) TempS; (c) MAPE for RegS; (d) MAPE 1 and MAPE 2 for TempS.
In the case of RegS, the inhomogeneities in the GHG emissions are reflected in high MAPE for the lowest producer countries, which might be considered outliers (the picks in Figure 7c).
The TempS emphasizes the existence of high emissions producers, which are constantly the same during the study period (DE, FR, IT, SE, PT). When analyzing the MAPE1, remark that, during 1990–1998 and 2009–2011, the values are in the same range, whereas for 1999, 2001, and 2004–2008, the values are much lower; the highest values correspond to 2012–2021. These ranges of values are related to the slight variations of the annual series.
The values of MAPE 2 are significantly higher than those of MAPE 1 between 1990 and 2009, reflecting a worse fitting of TempS. After 2012, MAPE 2 becomes lower than MAPE 1. Given the high variations in the previous period, the average MAPE1 is about 1.5 lower than the average MAPE 2. These values are influenced by the values of the series that participate in building TempS. An idea that will be explored in the future is fitting TempS using subseries that better fit the set of studied series on different subperiods.
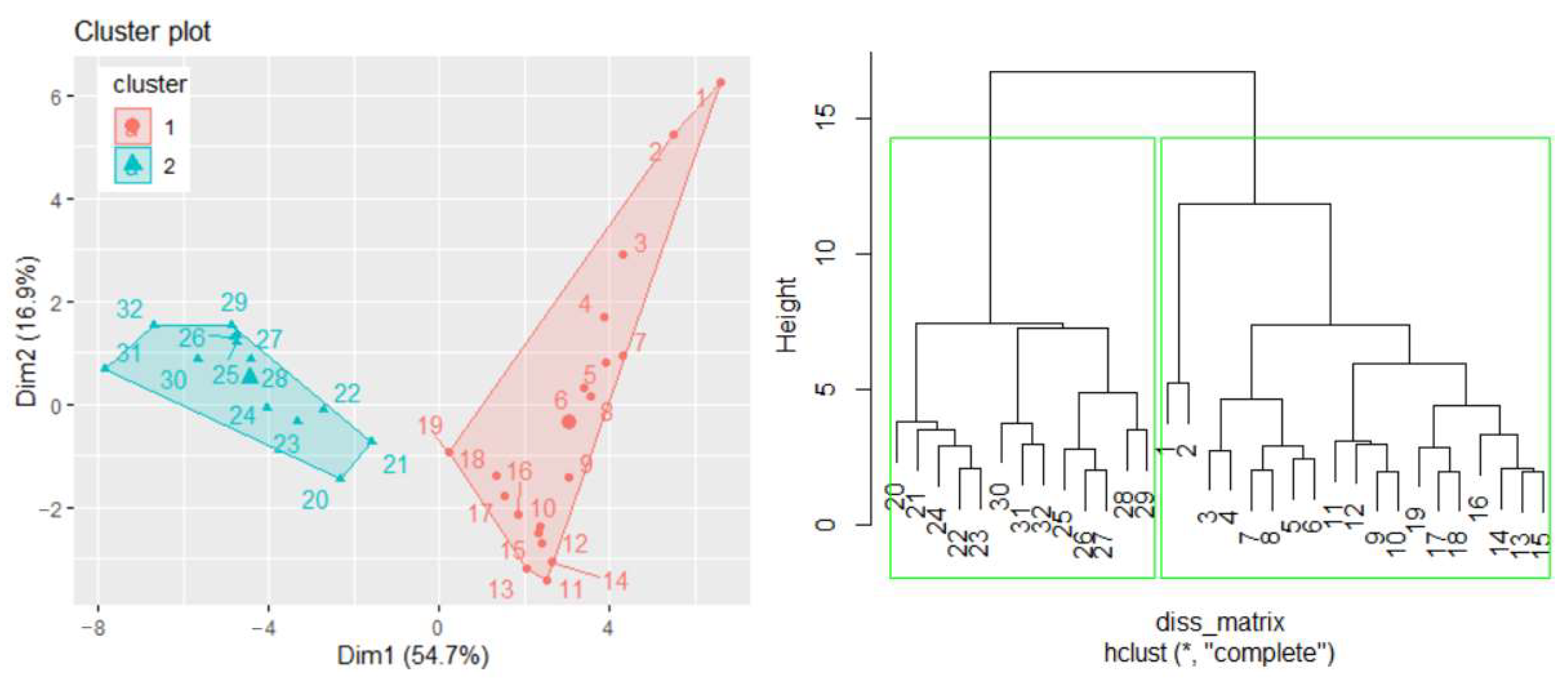
A similar study can be performed considering other variables, such as population or GDP, when the studied series will be formed by the annual GHG emissions in mt CO2 equivalent/per capita and GHG emissions in mt CO2 equivalent/per GDP, respectively. In the first case, when determining the TempS, the best number of clusters is two, and the hierarchical clustering confirms the results of the k-means algorithm (Figure 8). The cluster that participates in building TempS contains the series recorded in the first 19 years (the first cluster in Figure 8(left)). A detailed study will be presented in another article.
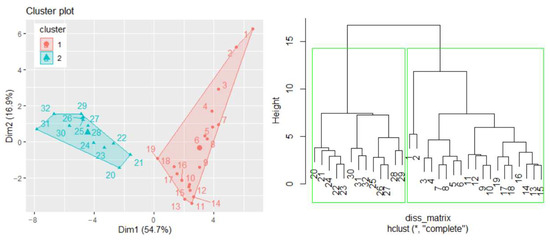
Figure 8.
(left) Clusters of the GHG per capita series for building TempS and (right) the dendrogram.
4. Conclusions
This work analyzed the total GHG series recorded in 30 European countries to emphasize the series trend. The RegS and TempS were also built by an original algorithm. The series that participated in creating these representative series were selected after determining the cluster with the highest number of elements. When using the optimal value provided for k (for running the k-means algorithm) by different criteria differs, the separation and stability criteria are crucial for choosing the correct number of clusters to cluster the series. Selecting the optimum number of groups (k) is essential for fitting RegS and TempS since the estimation accuracy is influenced by the series values participating in the process.
There are notable differences between the GHG emissions in different countries. Germany is the highest pollutant producer, and small countries, such as Malta, are the lowest. This situation and the increasing tendencies of GHG series in some countries contribute to the low fitting quality of the recorded series in the mentioned countries.
The data series used are trustworthy. Even if some reporting errors are possible, when one is interested in the regional or temporal evolution of GHG emissions in Europe, the trend shown by the presented models is the same (only the accuracy is lower). The main advantage of the proposed models is that they give an image of GHG's spatial and temporal evolution over a region. They can be built without restrictions related to the territory or specific requirements on the series distributions.
In a future study, we intend to extend the analysis to the specific GHGs (CO2, CH4, N2O, fluorinated gases, etc.) and incorporate other variables, such as GDP and population.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data will be available on request from the author.
Conflicts of Interest
The present research work carries no conflict of interest.
References
- Maji, S.; Ahmed, A.; Ghosh, S. Source Apportionment of Greenhouse Gases in the Atmosphere. In Greenhouse Gases: Sources, Sinks and Mitigation; Sonwani, S., Saxena, P., Eds.; Springer: Singapore, 2022; pp. 9–37. [Google Scholar] [CrossRef]
- Naiyer, S.; Abbas, S.S. Effect of Greenhouse Gases on Human Health. In Greenhouse Gases: Sources, Sinks and Mitigation; Sonwani, S., Saxena, P., Eds.; Springer: Singapore, 2022; pp. 85–106. [Google Scholar] [CrossRef]
- Saini, M.; Saini, S.K. Identification of Major Sinks of Greenhouse Gases. In Greenhouse Gases: Sources, Sinks and Mitigation; Sonwani, S., Saxena, P., Eds.; Springer: Singapore, 2022; pp. 39–62. [Google Scholar] [CrossRef]
- Greenhouse Gas Emissions. Sources of Greenhouse Gas Emissions. Available online: https://www.epa.gov/ghgemissions/sources-greenhouse-gas-emissions (accessed on 7 July 2023).
- Bărbulescu, A.; Postolache, F. New approaches for modeling the regional pollution in Europe. Sci. Total Environ. 2021, 753, 141993. [Google Scholar] [CrossRef] [PubMed]
- Greenhouse Gas Emissions. Inventory of U.S. Greenhouse Gas Emissions and Sinks. Available online: https://www.epa.gov/ghgemissions/inventory-us-greenhouse-gas-emissions-and-sinks (accessed on 7 July 2023).
- Hadipoor, M.; Keivanimehr, F.; Baghban, A.; Reza Ganjali, M.; Habibzadeh, S. Chapter 24—Carbon dioxide as a main source of air pollution: Prospective and current trends to control. In Sorbents Materials for Controlling Environmental Pollution; Núñez-Delgado, A., Ed.; Elsevier: Amsterdam, The Netherlands, 2021; pp. 623–688. [Google Scholar] [CrossRef]
- Allen, M.; Babiker, M.; Chen, Y.; de Coninck, H.; Connors, S.; van Diemen, R.; Zickfeld, K. IPCC, 2018: Summary for Policymakers. In Global Warming of 1.5 °C: An IPCC Special Report on the Impacts of Global Warming of 1.5 °C above Pre-Industrial Levels and Related Global Greenhouse Gas Emission Pathways, in the Context of Strengthening the Global Response to the Threat of Climate Change, Sustainable Development, and Efforts to Eradicate Poverty; IPCC: Geneva, Switzerland, 2018; Available online: https://www.ipcc.ch/sr15/chapter/spm/ (accessed on 23 July 2023).
- Meyer, L.; Brinkman, S.; van Kesteren, L.; Leprince-Ringuet, N.; van Boxmeer, F. IPCC, 2014: Climate Change 2014: Synthesis Report. Contribution of Working Groups I, II and III to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change; IPCC: Geneva, Switzerland, 2014. [Google Scholar]
- Guais, A.; Brand, G.; Jacquot, L.; Karrer, M.; Dukan, S.; Grevillot, G.; Molina, T.J.; Bonte, J.; Regnier, M.; Schwartz, L. Toxicity of carbon dioxide: A review. Chem. Res. Toxicol. 2011, 24, 2061–2070. [Google Scholar] [CrossRef] [PubMed]
- Azuma, K.; Hag, N.; Yanagi, U.; Osawa, H. Effects of low-level inhalation exposure to carbon dioxide in indoor environments: A short review on human health and psychomotor performance. Environ. Int. 2018, 121, 51–56. [Google Scholar] [CrossRef] [PubMed]
- Badner, N.H.; Scott Beattie, W.; Freeman, D.; Spence, J.D. Nitrous oxide induced increased homocysteine concentrations are associated with increased postoperative myocardial ischemia in patients undergoing carotid endarterectomy. Anesth. Analg. 2000, 9, 1073–1079. [Google Scholar] [CrossRef]
- Moudgil, G.C.; Gordon, J.; Forrest, J.B. Comparative effects of volatile anaesthetic agents and nitrous oxide on human leucocyte chemotaxis in vitro. Can. Anaest. Soc. J. 1984, 31, 631–637. [Google Scholar] [CrossRef] [PubMed]
- Murray, C.J.L.; Lopez, A.D. (Eds.) The global burden of disease: A comprehensive assessment of mortality and disability from diseases, injuries, and risk factors in 1990 and projected to 2020: Summary. In Global Burden of Disease and Injury Series; The Harvard School of Public Health: Boston, MA, USA, 1990; Volume 1. [Google Scholar]
- The Paris Agreement. United Nations. Framework Convention on Climate Change (UNFCCC). 2015. Available online: https://unfccc.int/sites/default/files/resource/parisagreement_publication.pdf (accessed on 15 August 2023).
- Committee on Climate Change. Net Zero—The UK’s Contribution to Stopping Global Warming, Ch 1, 38–53. 2019. Available online: https://www.theccc.org.uk/wp-content/uploads/2019/05/Net-Zero-The-UKs-contribution-to-stopping-global-warming.pdf (accessed on 18 August 2023).
- Timperley, J. Carbon Brief. The Carbon Brief Profile: India. 2019. Available online: https://www.carbonbrief.org/the-carbon-brief-profile-india (accessed on 18 August 2023).
- European Environment Agency. Climate Change Mitigation: Reducing Emissions. Available online: https://www.eea.europa.eu/en/topics/in-depth/climate-change-mitigation-reducing-emissions (accessed on 15 June 2023).
- Pan, L.; Yao, E.; Yang, Y. Impact analysis of traffic-related air pollution based on real-time traffic and basic meteorological information. J. Environ. Manag. 2016, 183, 510–520. [Google Scholar] [CrossRef] [PubMed]
- Bărbulescu, A.; Barbeş, L. Modeling the carbon monoxide dissipation in Timisoara, Romania. J. Environ. Manag. 2017, 204, 831–838. [Google Scholar] [CrossRef] [PubMed]
- Bărbulescu, A.; Nazzal, Y.; Howari, F. Statistical analysis and estimation of the regional trend of aerosol size over the Arabian Gulf Region during 2002–2016. Sci. Rep. 2018, 8, 9571. [Google Scholar] [CrossRef] [PubMed]
- Trofimenko, Y.V.; Komkov, V.I.; Donchenko, V.V.; Potapchenko, T.D. Model for the assessment greenhouse gas emissions from road transport. Period. Eng. Nat. Sci. 2019, 7, 465–473. Available online: http://pen.ius.edu.ba (accessed on 20 August 2023). [CrossRef]
- Alhindawi, R.; Abu Nahleh, Y.; Kumar, A.; Shiwakoti, N. Projection of Greenhouse Gas Emissions for the Road Transport Sector Based on Multivariate Regression and the Double Exponential Smoothing Model. Sustainability 2020, 12, 9152. [Google Scholar] [CrossRef]
- Güzel, T.D.; Alp, K. Modeling of greenhouse gas emissions from the transportation sector in Istanbul by 2050. Atmos. Pollut. Res. 2022, 11, 2190–2201. [Google Scholar] [CrossRef]
- TRASfer. Modelling GHG Emissions of Road Transport in China—New Technical Paper Published. Available online: http://www.transferproject.org/modelling-ghg-emissions-of-road-transport-in-china/ (accessed on 17 August 2023).
- EEA Greenhouse Gases—Data Viewer. Available online: https://www.eea.europa.eu/data-and-maps/data/data-viewers/greenhouse-gases-viewer (accessed on 15 June 2023).
- Kendall, M.G. Rank Correlation Methods, 4th ed.; Charles Griffin: London, UK, 1975. [Google Scholar]
- Sen, P.K. Estimates of the regression coefficient based on Kendall’s tau. J. Am. Stat. Assoc. 1968, 63, 1379–1389. [Google Scholar] [CrossRef]
- Daburra, I. K-means Clustering: Algorithm, Applications, Evaluation Methods, and Drawbacks. Available online: https://towardsdatascience.com/k-means-clustering-algorithm-applications-evaluation-methods-and-drawbacks-aa03e644b48a (accessed on 18 June 2023).
- Hierarchical Clustering in R. Available online: https://www.datacamp.com/tutorial/hierarchical-clustering-R (accessed on 18 June 2023).
- Rousseeuw, P. Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- K-Mean: Getting the Optimal Number of Clusters. Available online: https://www.analyticsvidhya.com/blog/2021/05/k-mean-getting-the-optimal-number-of-clusters/ (accessed on 16 June 2023).
- Madsen, B.E.; Browning, S.R. A Groupwise Association Test for Rare Mutations Using a Weighted Sum Statistic. PLoS Genet. 2009, 5, e1000384. [Google Scholar] [CrossRef] [PubMed]
- Tibshirani, R.; Walther, G.; Hastie, T. Estimating the number of clusters in a data set via the gap statistic. J. Royal Stat. Soc. B 2001, 63, 411–423. [Google Scholar] [CrossRef]
- Löhr, T. K-Means Clustering and the Gap-Statistics. Available online: https://towardsdatascience.com/k-means-clustering-and-the-gap-statistics-4c5d414acd29 (accessed on 16 June 2023).
- Sokal, R.R.; Rohlf, F.J. The comparison of dendrograms by objective methods. Taxon 1962, 11, 33–40. [Google Scholar] [CrossRef]
- Farris, J.S. On the cophenetic correlation coefficient. System. Zool. 1969, 18, 279–285. [Google Scholar] [CrossRef]
- Myrphy, P. Clustering Data in R. Available online: https://rstudio-pubs-static.s3.amazonaws.com/599072_93cf94954aa64fc7a4b99ca524e5371c.html (accessed on 30 June 2023).
- Bărbulescu, A. On the Regional Temperature Series Evolution in the South-Eastern Part of Romania. Appl. Sci. 2023, 13, 3904. [Google Scholar] [CrossRef]
- Bărbulescu, A.; Postolache, F.; Dumitriu, C.Ș. Estimating the precipitation amount at regional scale using a new tool, Climate Analyzer. Hidrology 2021, 8, 125. [Google Scholar] [CrossRef]
- Soetewey, A. Stats and R. The Complete Guide to Clustering Analysis: K-Means and Hierarchical Clustering by Hand and in R. Available online: https://statsandr.com/blog/clustering-analysis-k-means-and-hierarchical-clustering-by-hand-and-in-r/ (accessed on 20 June 2022).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).