
Next-Generation Sequencing: The Translational Medicine Approach from “Bench to Bedside to Population”


{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Cancer Genome Profiling and the 40 Year War
3. Upcoming Age of Personal Genome Sequencing
4. Epigenetic Biology and Its Implications on Human Health
5. The ENCODE Project: Debunking the Myth of ‘Junk’ DNA in the Genome(s)
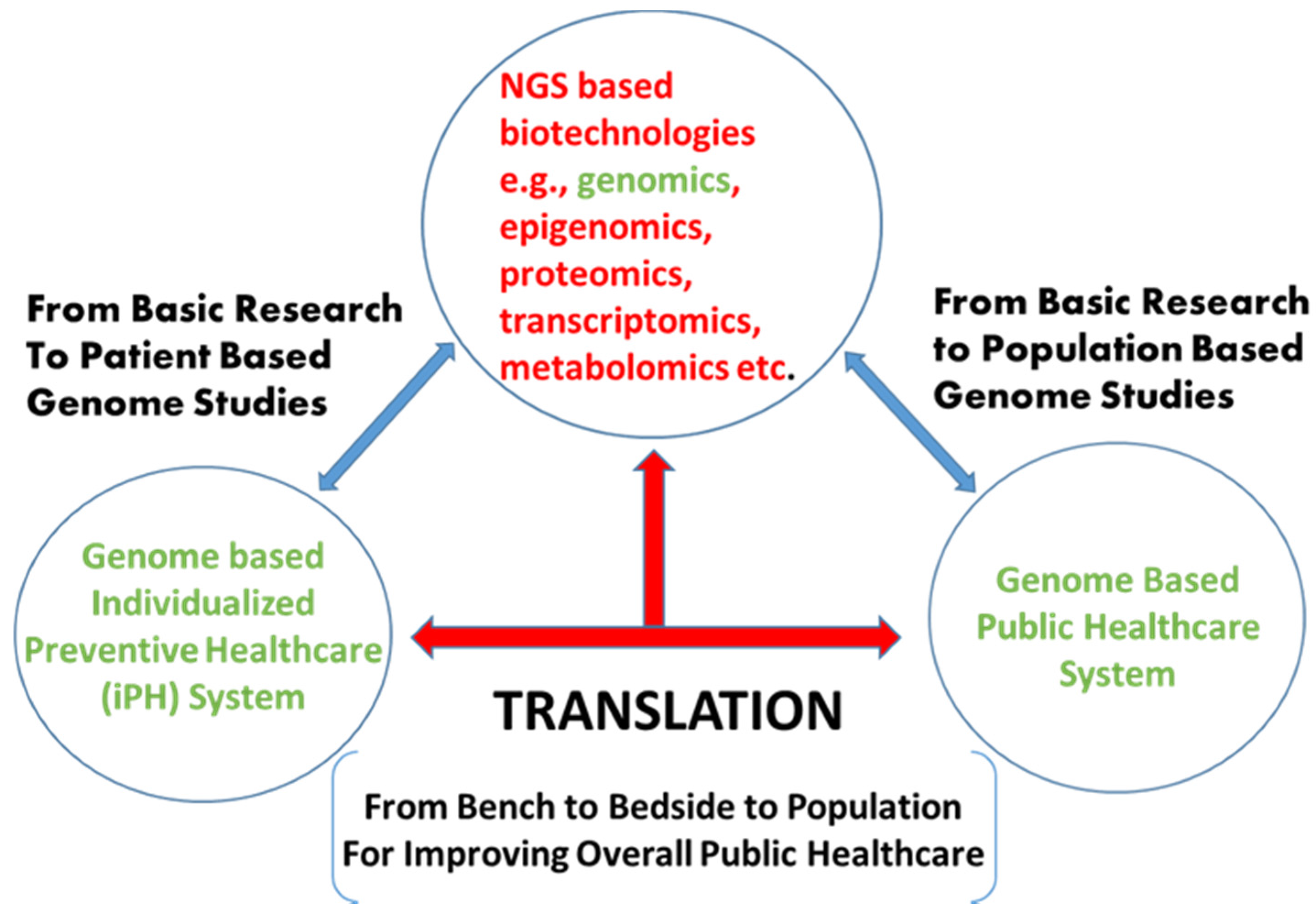
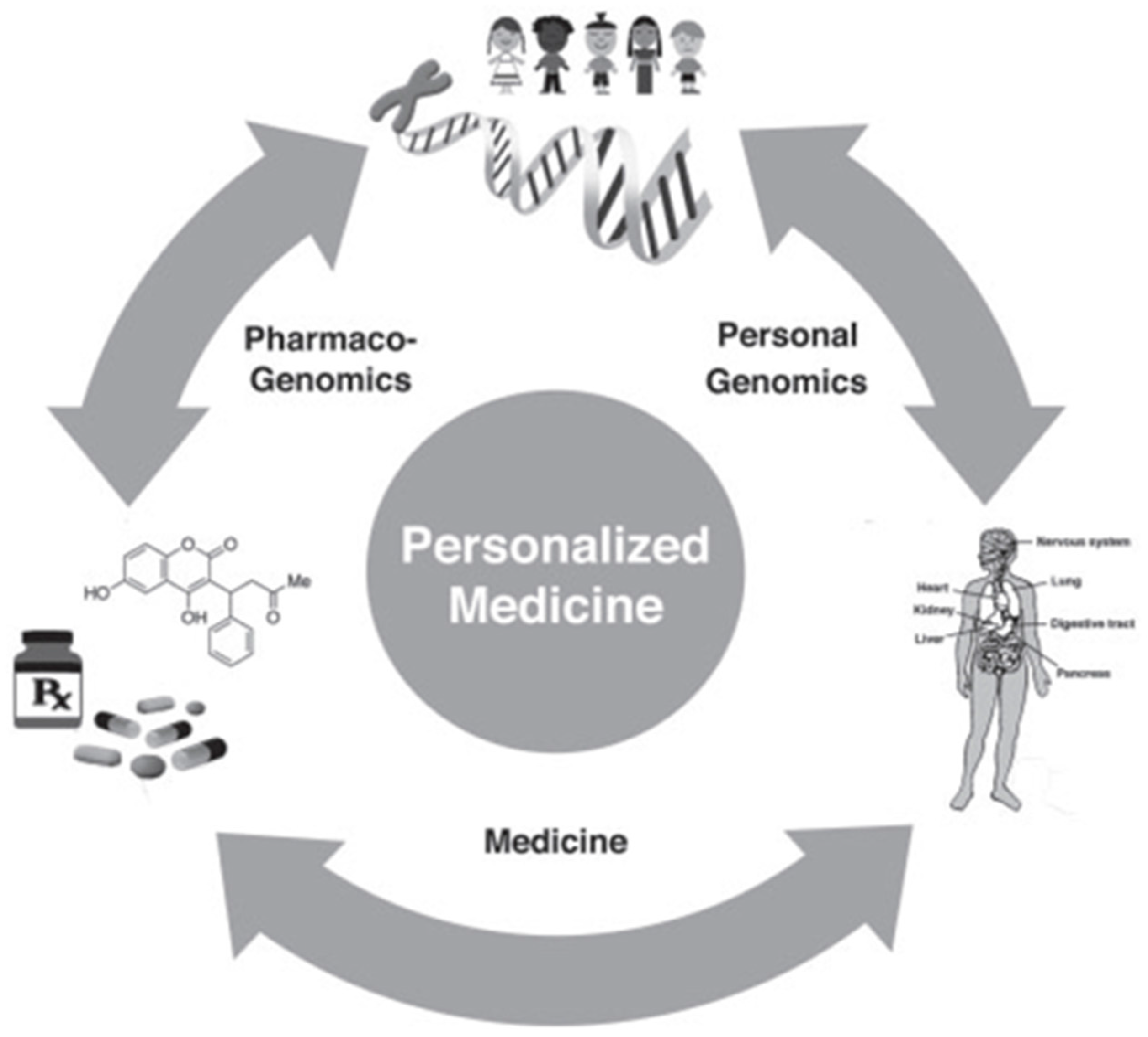
6. Precision Medicine and Public Healthcare
7. Conclusions and Future Challenges
Acknowledgments
Conflicts of Interest
Abbreviations
| NGS | Next Generation Sequencing |
| PGS | Personal Genome Sequencing |
| WG | Whole Genome |
| WE | Whole Exome |
| PGM | Personalized Genome Medicine |
| PGS | Personal Genome Sequencing |
References
- Bayer, R.; Galea, S. Public Health in Precision Medicine Era. N. Engl. J. Med. 2015, 373. [Google Scholar] [CrossRef] [PubMed]
- Genetics and Disease. Available online: http://www.hgu.mrc.ac.uk (accessed on 19 October 2015).
- Katsanis, S.H.; Katsanis, N. Molecular genetic testing and the future of clinical genomics. Nat. Rev. Genet. 2013, 14, 415–426. [Google Scholar] [CrossRef] [PubMed]
- Transformational Health. Available online: http://www.frost.com (accessed on 11 November 2015).
- Khoury, M.J.; Gwinn, M.; Bowen, M.S.; Dotson, W.D. Beyond Base-Pairs to Bedside: A Population Perspective on How Genomics Can Improve Health. Am. J. Public Health 2012, 102. [Google Scholar] [CrossRef] [PubMed]
- Revolutionizing Genetic Screening and Education. Available online: http://www.genesinlife.org (accessed on 7 September2015).
- Ning, W.; Li, C.J.; Kaminski, N.; Feghali-Bostwick, C.A.; Alber, S.M.; Di, Y.P.; Otterbein, S.L.; Song, R.; Hayashi, S.; Zhou, Z.; et al. Comprehensive gene expression profiles reveal pathways related to the pathogenesis of chronic obstructive pulmonary disease. Proc. Natl. Acad. Sci. USA 2004, 101, 14895–14900. [Google Scholar] [CrossRef] [PubMed]
- Bai, J.P.; Alekseyenko, A.V.; Statnikov, A.; Wang, I.M.; Wong, P.H. Strategic Applications of Gene Expression: From Drug Discovery/Development to Bedside. AAPS J. 2013, 15, 427–437. [Google Scholar] [CrossRef] [PubMed]
- Mefford, C.H.; Batshaw, M.L.; Hoffman, P.E. Genomics, Intellectual Disability and Autism. N. Engl. J. Med. 2012, 366, 733–743. [Google Scholar] [PubMed]
- American Society of Human Genetics Board of Directors and American College of Medical Genetics Board of Directors. Points to Consider: Ethical, Legal, and Psychosocial Implications of Genetic Testing in Children and Adolescents. Am. J. Hum. Genet. 1995, 57, 1233–1241. [Google Scholar]
- Pociot, F.; Akolkar, B.; Concannon, P.; Erlich, H.A.; Julier, C.; Morahan, G.; Nierras, C.R.; Todd, J.A.; Rich, S.S.; Nerup, J. Genetics of type 1 diabetes: What’s next? Diabetes 2010, 59, 1561–1571. [Google Scholar] [CrossRef] [PubMed]
- Newborn Screening. Available online: http://www.genome.gov (accessed on 27 September2015).
- End of Cancer-Genome Project Prompts Rethink of Research Strategy. Available online: http://www.scientificamerica.com (accessed on 23 October 2015).
- Nakagawa, H.; Wardell, C.P.; Furuta, M.; Taniguchi, H.; Fujimoto, A. Cancer whole-genome sequencing: Present and future. Oncogene 2015, 34, 5943–5950. [Google Scholar] [CrossRef] [PubMed]
- Ledford, H. End of cancer-genome project prompts rethink. Nature 2015, 517, 128–129. [Google Scholar] [CrossRef] [PubMed]
- Tomczak, K.; Czerwinska, P.; Wiznerowicz, M. The Cancer Genome Atlas (TCGA); an immeasurable source of knowledge. Contemp. Oncol. (Pozn.) 2015, 19, A68–A77. [Google Scholar] [CrossRef] [PubMed]
- Shyr, D.; Liu, Q. Next generation sequencing in cancer research and clinical application. Biol. Proced. Online 2013, 15. [Google Scholar] [CrossRef] [PubMed]
- Harismendy, O.; Ng, P.C.; Strausberg, R.L.; Wang, X.; Stockwell, T.B.; Beeson, K.Y.; Schork, N.J.; Murray, S.S.; Topol, E.J.; Levy, S.; et al. Evaluation of next generation sequencing platforms for population targeted sequencing studies. Genome Biol. 2009, 10. [Google Scholar] [CrossRef] [PubMed]
- Constantin, N.; Wahli, W. Nutrigenomic foods: What will we be eating tomorrow? Nutrafoods 2013, 12, 3–12. [Google Scholar] [CrossRef]
- Mardis, E.R.; Wilson, R.K. Cancer genome sequencing: A review. Hum. Mol. Genet. 2009, 18, R163–R168. [Google Scholar] [CrossRef] [PubMed]
- Handy, D.E.; Castro, R.; Loscalzo, J. Epigenetic modifications: Basic Mechanisms and Role in Cardiovascular Disease. Circulation 2011, 123, 2145–2156. [Google Scholar] [CrossRef] [PubMed]
- Morozova, O.; Marra, M.A. Applications of next-generation sequencing technologies in functional genomics. Genomics 2008, 92, 255–264. [Google Scholar] [CrossRef] [PubMed]
- Shen, T.; Hans, S.; Nai, C.Y. Clinical applications of next generation sequencing in cancer: From panels, to exomes, to genomes. Front. Genet. 2015, 6. [Google Scholar] [CrossRef]
- Gilissen, C.; Hoischen, A.; Brunner, H.G.; Veltman, J.A. Disease gene identification strategies for exome sequencing. Eur. J. Hum. Genet. 2012, 20, 490–497. [Google Scholar] [CrossRef] [PubMed]
- Margolis, R.; Smith, P. Commentary: Parallel evolution of Molecular Endocrinology as a journal and a discipline: Convergence of interests with the National Institute of Diabetes and Digestive and Kidney Diseases (NIDDK/NIH). Mol. Endocrinol. 2010, 24, 1697–1702. [Google Scholar] [CrossRef] [PubMed]
- Guerrero-Bosagna, C.; Jensen, P. Globalization, climate change, and transgenerational epigenetic inheritance: Will our descendants be at risk? Clin. Epigenet. 2015, 7. [Google Scholar] [CrossRef] [PubMed]
- Luthra, R.; Chen, H.; Chowdhuri, S.R.; Singh, R.R. Next-Generation Sequencing in Clinical Molecular of Cancer: Advantages and Challenges. Cancers 2015, 7, 2023–2036. [Google Scholar] [CrossRef] [PubMed]
- Genomic Medicine Initiative. Available online: http://www.salk.edu (accessed on 22 April 2016).
- Vincenza, P.; Valentina, D.M.; Maria, V.E.; Fatima, D.E.D.P.; Anna, R.; Francesco, S.; Valeria, D. Cracking the Code of Human Diseases Using Next-Generation Sequencing: Applications, Challenges, and Perspectives. BioMed Res. Int. 2015, 2015. [Google Scholar] [CrossRef]
- Rehm, H.L. Disease-targeted sequencing: A cornerstone in the clinic. Nat. Rev. Genet. 2013, 14, 295–300. [Google Scholar] [CrossRef] [PubMed]
- Black, J.S.; Salto-Tellez, M.; Mills, K.I.; Catherwooda, M.A. The impact of next-generation sequencing technologies on hematological research—A review. Pathogenesis 2015, 2, 9–16. [Google Scholar] [CrossRef]
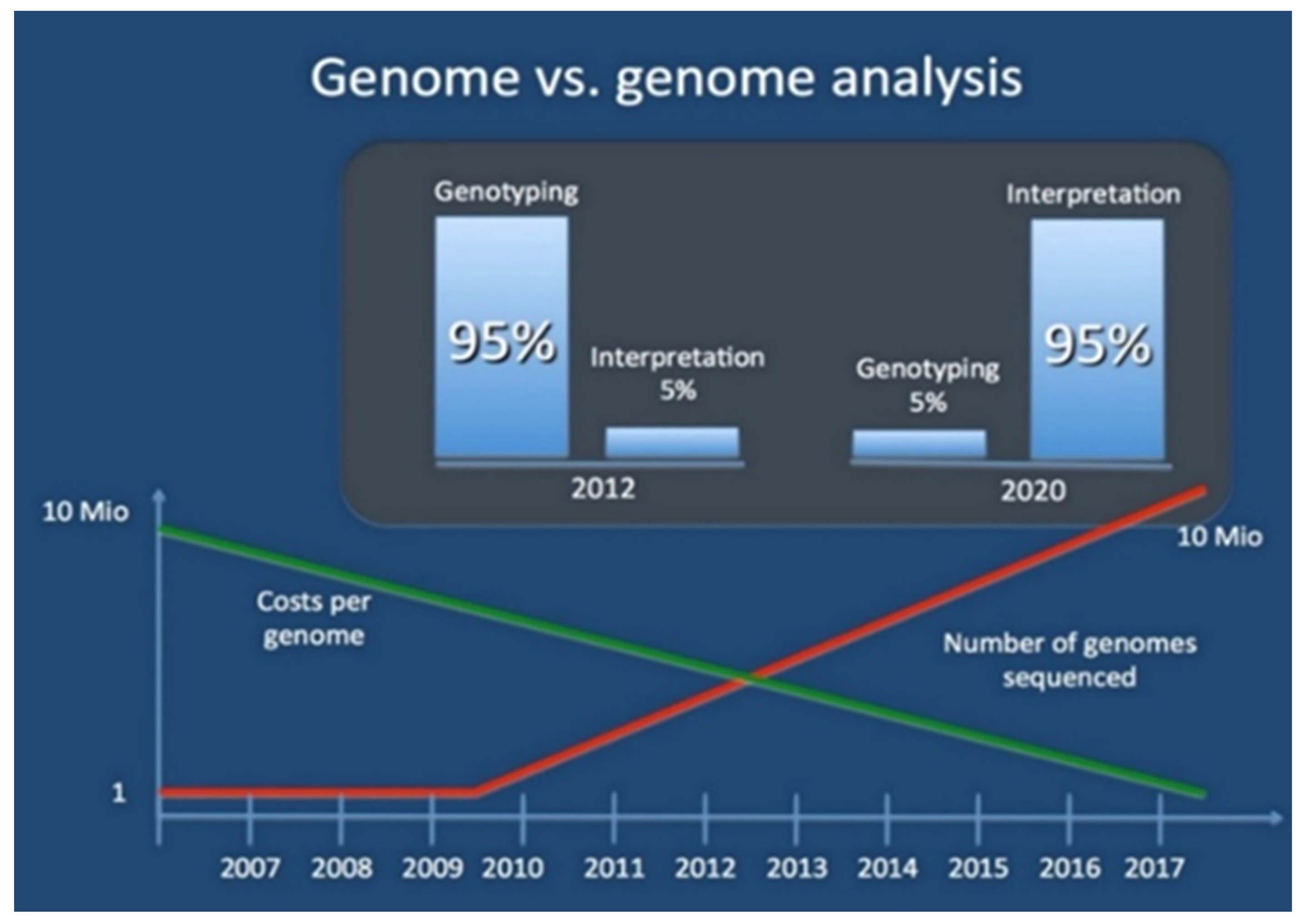
- Genome vs Genome Analysis. Available online: www.epilepsydenetics.net (accessed on 23 October 2015).
- An Introduction to Next-Generation Sequencing. Available online: http://www.illumina.com (accessed on 2 October 2015).
- Drmanac, R. The Advent of Personal Genome Sequencing. Genet. Med. 2011, 13, 188–190. [Google Scholar] [CrossRef] [PubMed]
- Methods for Investigating the Genomic Basis of Complex Diseases. Available online: http://www.Illumina.com (accessed on 2 September2015).
- Collins, F.S.; Varmus, H. A New Initiative on Precision Medicine. N. Engl. J. Med. 2015, 327. [Google Scholar] [CrossRef] [PubMed]
- MIT Technology Review. Available online: http://www.technologyreview.com (accessed on 21 April 2016).
- Cancer. Available online: http://www.who.int (accessed on 1 November2015).
- Map of Genetic Variations Published. Available online: http://www.paneuropeannetworks.com (accessed on 22 May 2016).
- Murgatroyd, C.; Patchev, A.V.; Wu, Y.; Micale, V.; Bockmühl, Y.; Fischer, D.; Holsboer, F.; Wotjak, C.T.; Almeida, O.F.X.; Spengler, D. Dynamic DNA methylation programs persistent adverse effects of early-life stress. Nat. Neurosci. 2009, 12, 1559–1566. [Google Scholar] [CrossRef] [PubMed]
- Exom Health. Available online: http://www.exomhealth.com (accessed on 16 March 2016).
- Sekar, D.; Thirugnanasambantham, K.; Islam Hairul, V.I.; Saravanan, S. Sequencing approach in cancer treatment. Cell Prolif. 2014, 47, 391–395. [Google Scholar] [CrossRef] [PubMed]
- Willard, H.F.; Angrist, M.; Ginsburg, G.S. Genomic medicine: Genetic variations and its impact on the future of health care. Phil. Trans. R. Soc. B 2005, 360, 1543–1550. [Google Scholar] [CrossRef] [PubMed]
- Perry, A.S.; Baird, A.M.; Gray, S.G. Epigenetic Methodologies for the study of Celiac Disease. Methods Mol. Biol. 2015, 1326, 131–158. [Google Scholar] [PubMed]
- McManus, B. Trends in genomic biomarkers. Heart Metab. 2009, 43, 19–21. [Google Scholar]
- Skinner, M.K.; Manikkam, M.; Tracey, R.; Guerrero-Bosagna, C.; Haque, M.; Nilsson, E.E. Ancestral dicholorodiphenyltricholoroethane (DDT) exposure promotes epigenetic transgenerational inheritance of obesity. BMC Med. 2013, 11. [Google Scholar] [CrossRef] [PubMed]
- Epigenome Roadmap. 2015. Available online: http://www.nature.com (accessed on 25 November 2015).
- Sloan, C.A.; Chan, E.T.; Davidson, J.M.; Malladi, V.S.; Strattan, J.S.; Hitz, B.C.; Gabdank, I.; Narayanan, A.K.; Ho, M.; Lee, B.T.; et al. ENCODE data at the ENCODE portal. Nucleic Acids Res. 2016, 44, D726–D932. [Google Scholar] [CrossRef] [PubMed]
- Consortium, R.E.; Kundaje, A.; Meuleman, W.; Ernst, J.; Bilenky, M.; Yen, A.; Heravi-Moussavi, A.; Kheradpour, P.; Zhang, Z.; Wang, J.; et al. Integrative analysis of 111 reference human epigenomes. Nature 2015, 518, 317–330. [Google Scholar]
- ENCODE: Encyclopedia of DNA Elements. Available online: http://www.encodeproject.org (accessed on 21 April 2016).
- Wheeler, D.A.; Wang, L. From human genome to cancer genome: The first decade. Genome Res. 2013, 23, 1054–1062. [Google Scholar] [CrossRef] [PubMed]
- Qu, H.; Fang, X. A Brief Review on the Human Encyclopedia of DNA Elements (ENCODE) Project. Genom. Proteom. Bioinform. 2013, 11, 135–141. [Google Scholar] [CrossRef] [PubMed]
- Tekola-Ayele, F.; Rotimi, C.N. Translational Genomics in Low and Middle-Income Countries: Opportunities and Challenges. Public Health Genom. 2015, 18, 242–247. [Google Scholar] [CrossRef] [PubMed]
- EXPOSOME and EXPOSOMICS. Available online: http://www.cdc.gov (accessed on 27 April 2016).
- Potamias, G.; Lakiotaki, K.; Katsila, T.; Lee, M.T.; Topouzis, S.; Cooper, D.N.; Patrinos, G.P. Deciphering next-generation pharmacogenomics: An information technology perspective. Open Biol. 2014, 4. [Google Scholar] [CrossRef] [PubMed]
- Lau, C.K.; Kuo, J.K. Genomics and President Obama’s Precision Medicine Initiative. 2015. Available online: http://www.pathway.com (accessed on 22 October 2015).
- Roden, D.N.; George, A.L. The genetic basis of variability in drug responses. Nat. Rev. Drug Discov. 2002, 1, 37–44. [Google Scholar] [CrossRef] [PubMed]
- Schadt, E.E.; Liderman, M.D.; Sorenson, J.; Lee, L.; Nolan, G.P. Computational solutions to large-scale data management and analysis. Nat. Rev. Genet. 2010, 11, 647–657. [Google Scholar] [CrossRef] [PubMed]
- Wright, G.E.B.; Koornhof, G.J.P.; Adeyemo, A.A.; Tifin, N. Ethical and legal implications of whole genome and whole exome sequencing in African populations. BMC Med. Ethics 2013, 14. [Google Scholar] [CrossRef] [PubMed]
- Sivitz, W.I.; Yrek, M.A. Mitochondrial Dysfunction in Diabetes: From Molecular Mechanisms to Functional Significance and Therapeutic Opportunities. Antioxd. Redox Signal. 2010, 12, 537–577. [Google Scholar] [CrossRef] [PubMed]
- The ENCODE Project Consortium. An integrated encyclopedia of DNA elements in the human genome. Nature 2012, 489, 57–74. [Google Scholar]
- Feldman, B. Genomics and the Role of Big Data in Personalizing the Healthcare Experience. Available online: http://www.oreilly.com (accessed on 5 July 2015).
- Genetics in the Workplace. Available online: www.cdc.gov (accessed on 22 May 2016).
- Ginsburg, G.S.; Willard, H.F. (Eds.) Genomic and Personalized Medicine, 2nd ed.; Academic Press: Burlington, MA, USA, 2012; Volumes 1 and 2.
- Human Gene Set Shrinks Again. Available online: http://www.the-scientist.com (accessed on 22 May 2016).
- Bredenoord, A.L.; Vries, M.C.D.; van Delden, J.J.M. Next-generation sequencing: Does the next generation still have a right to an open future? Nat. Rev. Genet. 2013, 306. [Google Scholar] [CrossRef]
- Jacob, H.J.; Abrams, K.; Bick, D.P.; Brodie, K.; Dimmock, D.P.; Farrell, M.; Geurts, J.; Harris, J.; Helbling, D.; Joers, B.J.; et al. Genomics in Clinical Practice: Lessons from the Front Lines. Sci. Transl. Med. 2013, 5. [Google Scholar] [CrossRef] [PubMed]
- Rare Variant Studies of Common Disease. Available online: http://www.massgenomics.org (accessed on 23 November 2015).



© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Beigh, M.M. Next-Generation Sequencing: The Translational Medicine Approach from “Bench to Bedside to Population”. Medicines 2016, 3, 14. https://doi.org/10.3390/medicines3020014
Beigh MM. Next-Generation Sequencing: The Translational Medicine Approach from “Bench to Bedside to Population”. Medicines. 2016; 3(2):14. https://doi.org/10.3390/medicines3020014
Chicago/Turabian StyleBeigh, Mohammad Muzafar. 2016. "Next-Generation Sequencing: The Translational Medicine Approach from “Bench to Bedside to Population”" Medicines 3, no. 2: 14. https://doi.org/10.3390/medicines3020014
APA StyleBeigh, M. M. (2016). Next-Generation Sequencing: The Translational Medicine Approach from “Bench to Bedside to Population”. Medicines, 3(2), 14. https://doi.org/10.3390/medicines3020014