
Exploring Temporal Dynamics of River Discharge Using Univariate Long Short-Term Memory (LSTM) Recurrent Neural Network at East Branch of Delaware River




Abstract
:1. Introduction
2. Materials and Methods
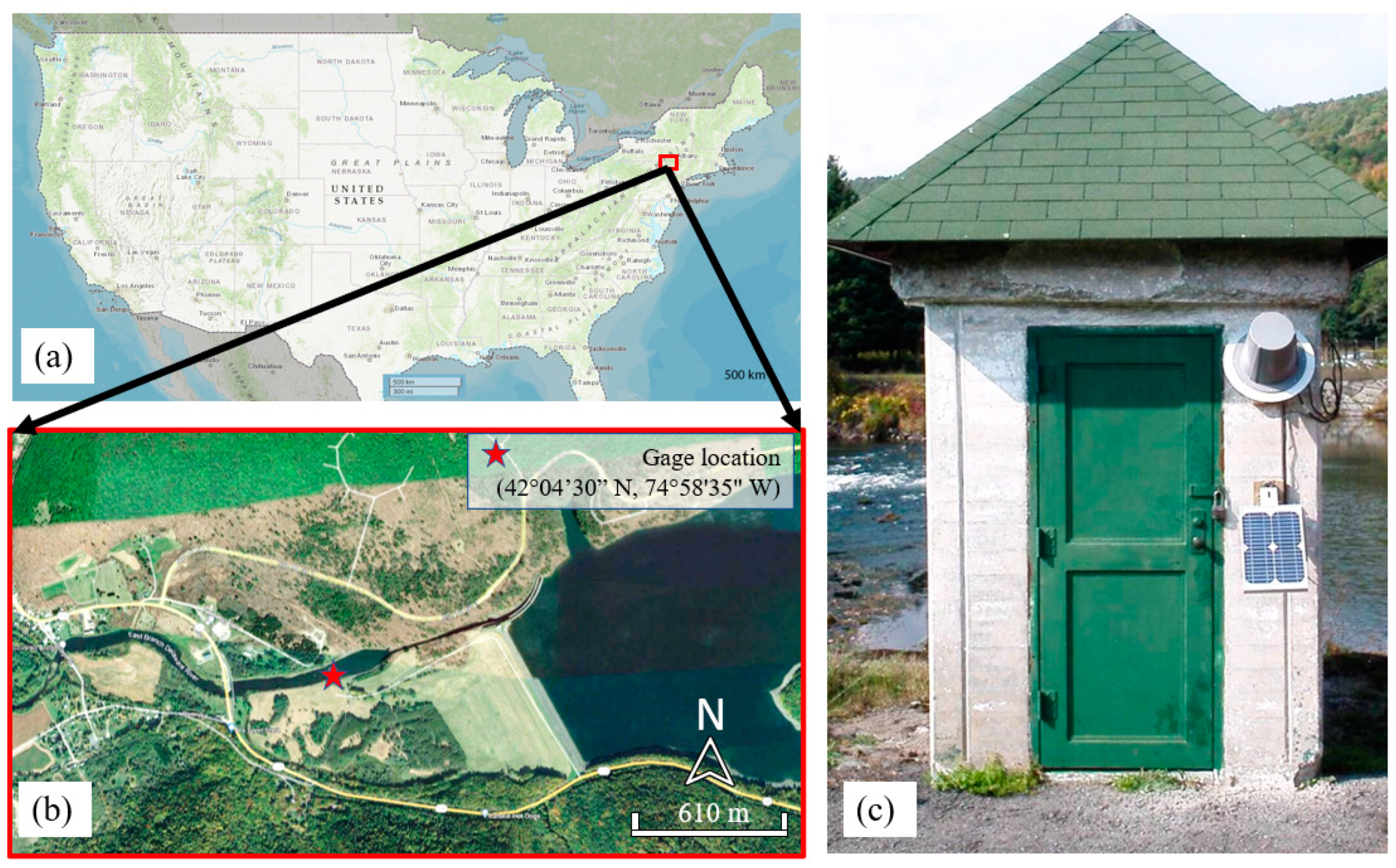
2.1. Study Location and Data Source
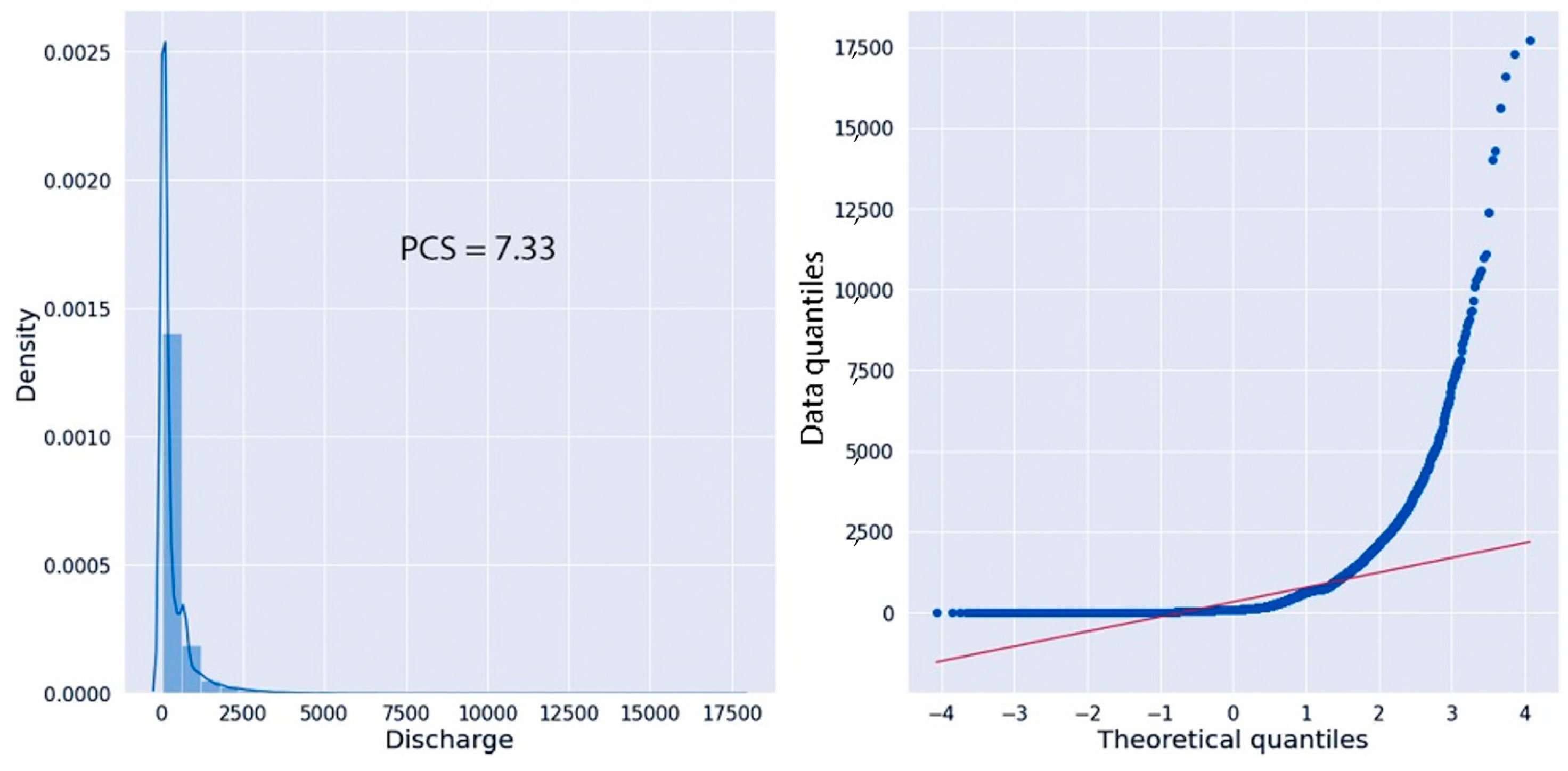
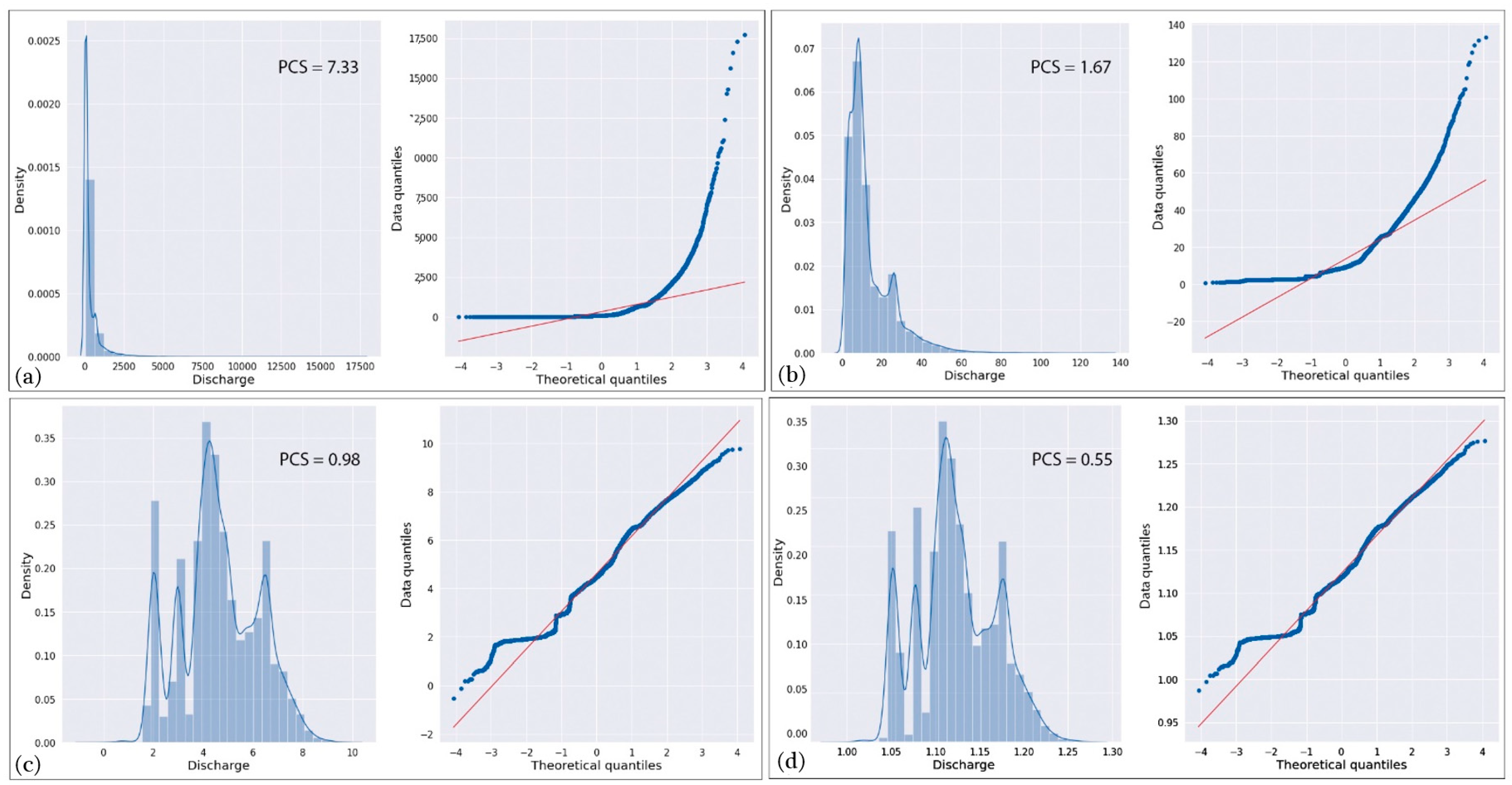
2.2. Univariate Exploratory Data Analysis and Feature Engineering
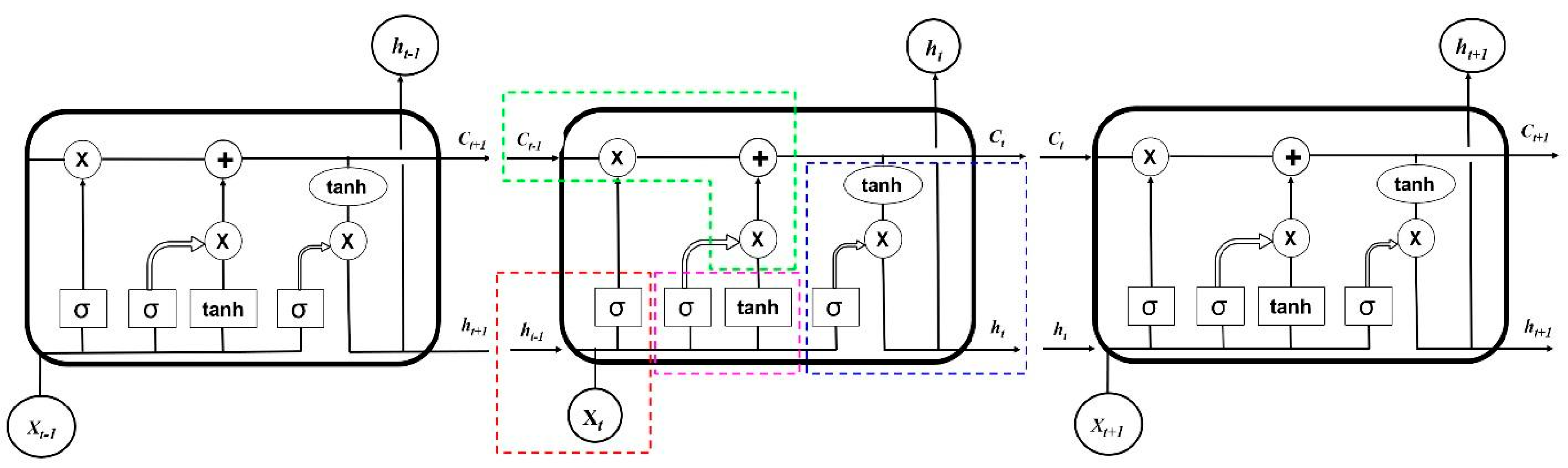
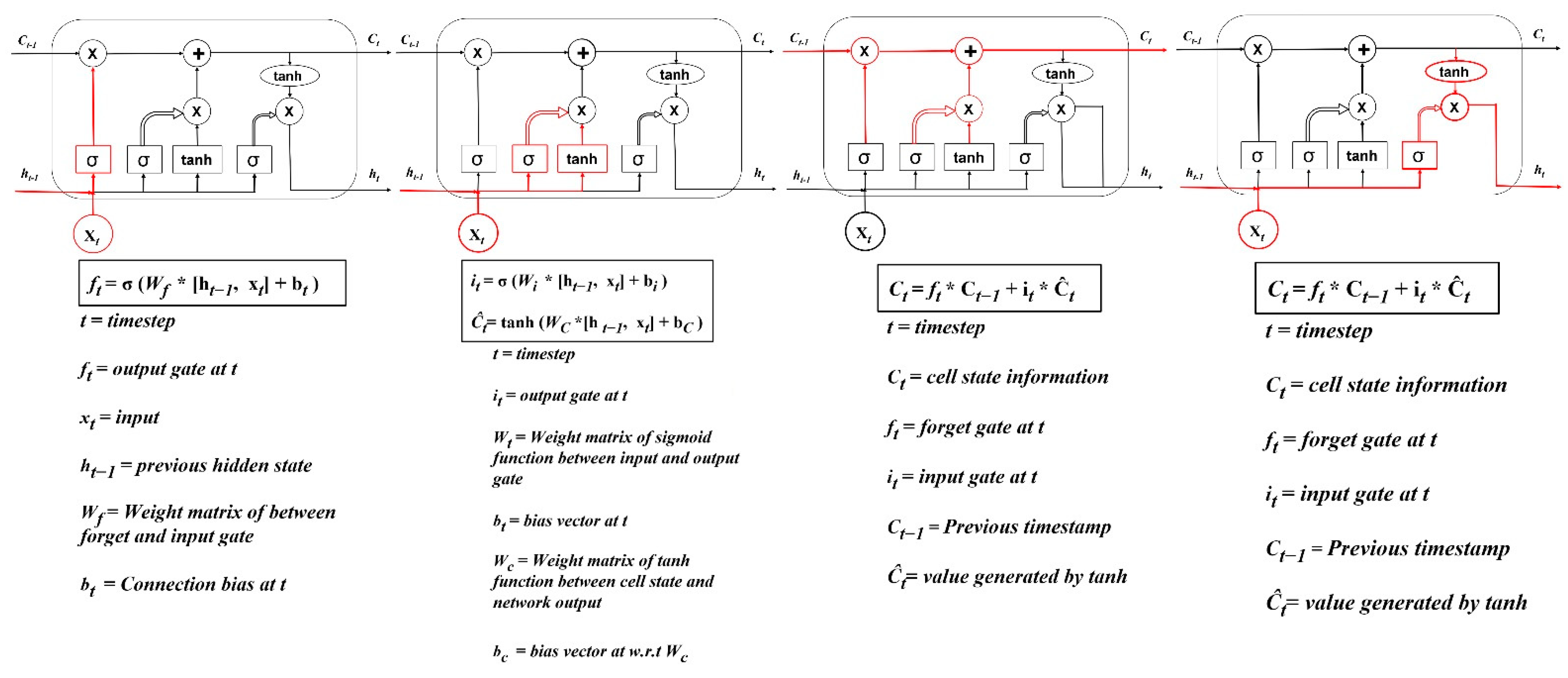
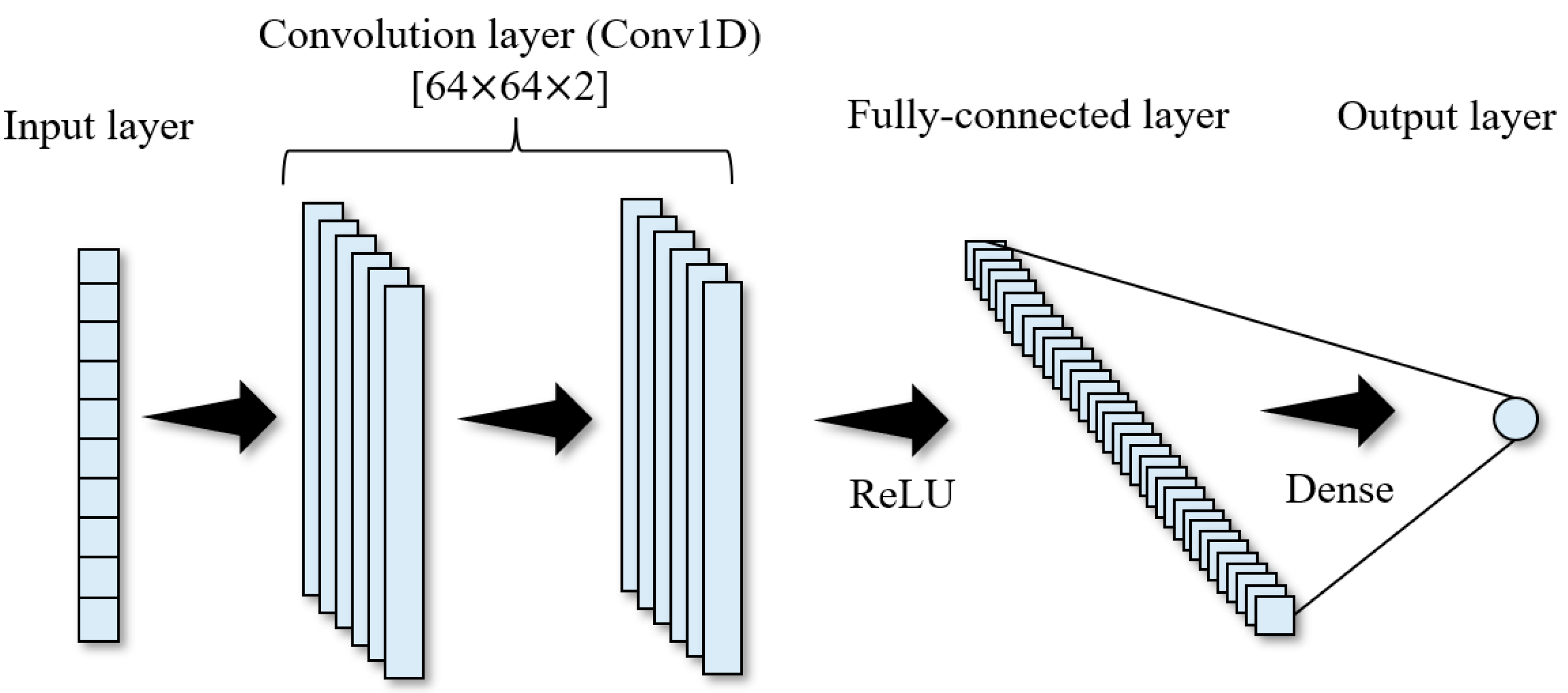
2.3. Long Short-Term Memory (LSTM) Recurrent Neural
2.4. Comparative Study
2.5. Error Analysis
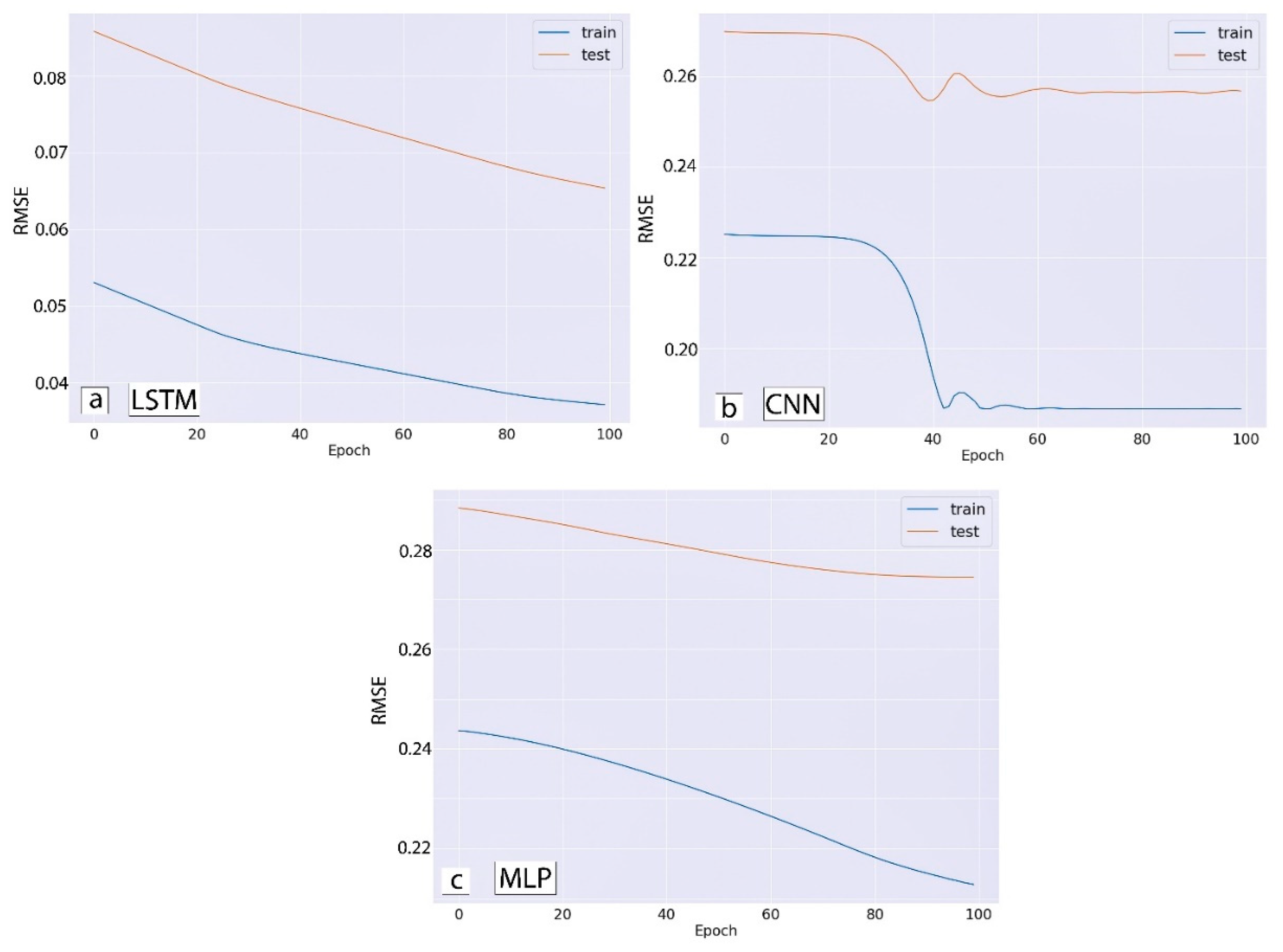
3. Results
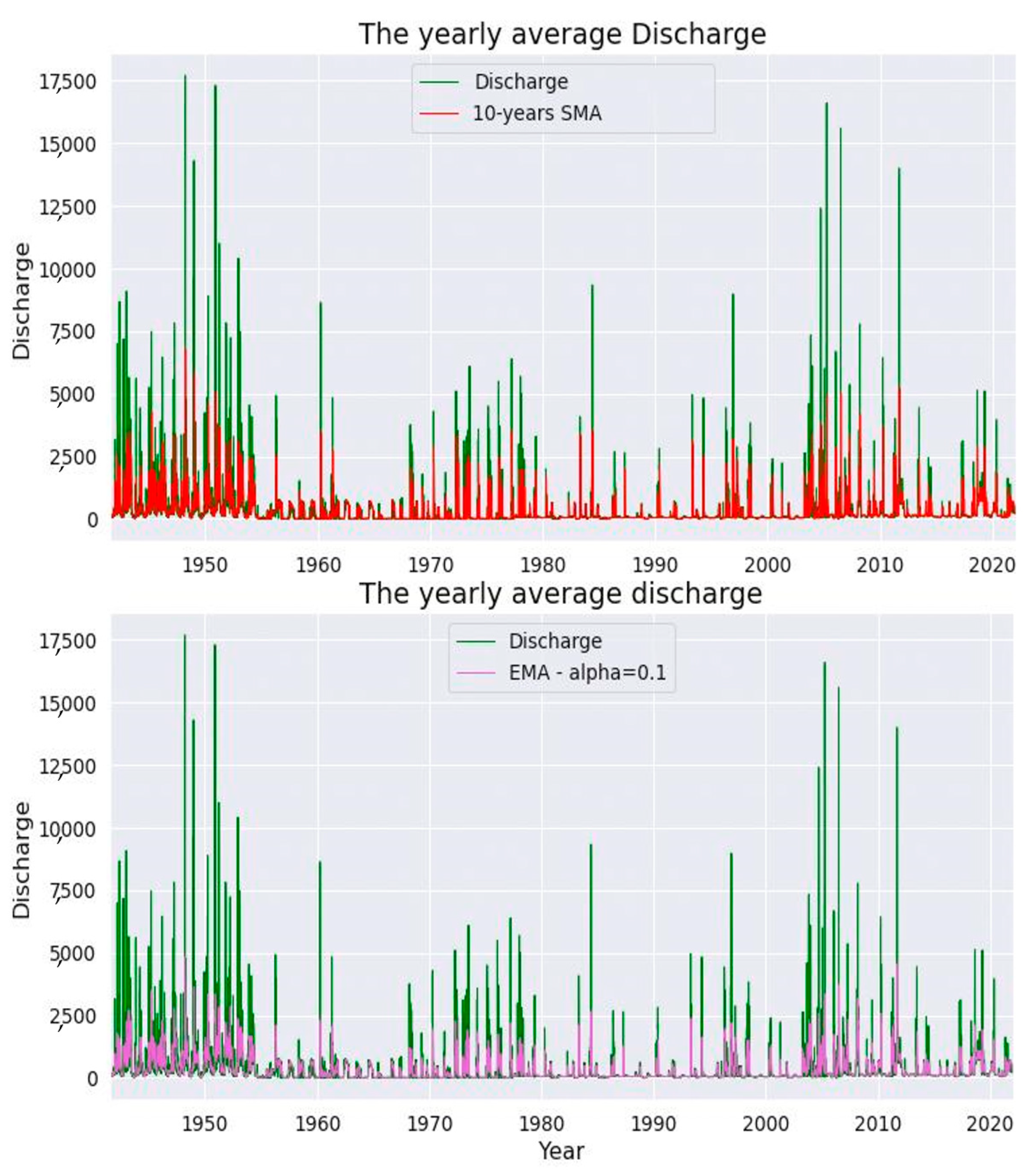
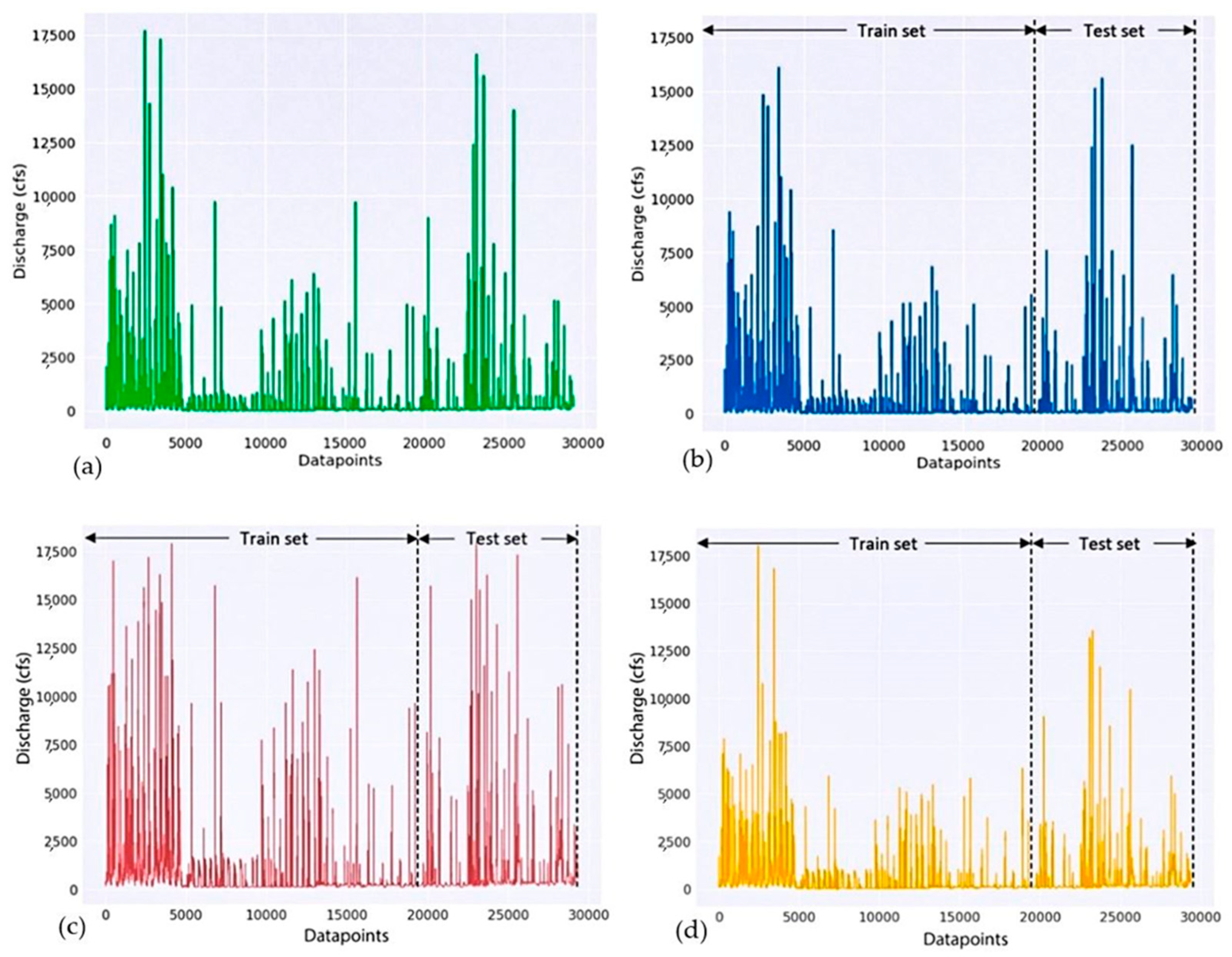
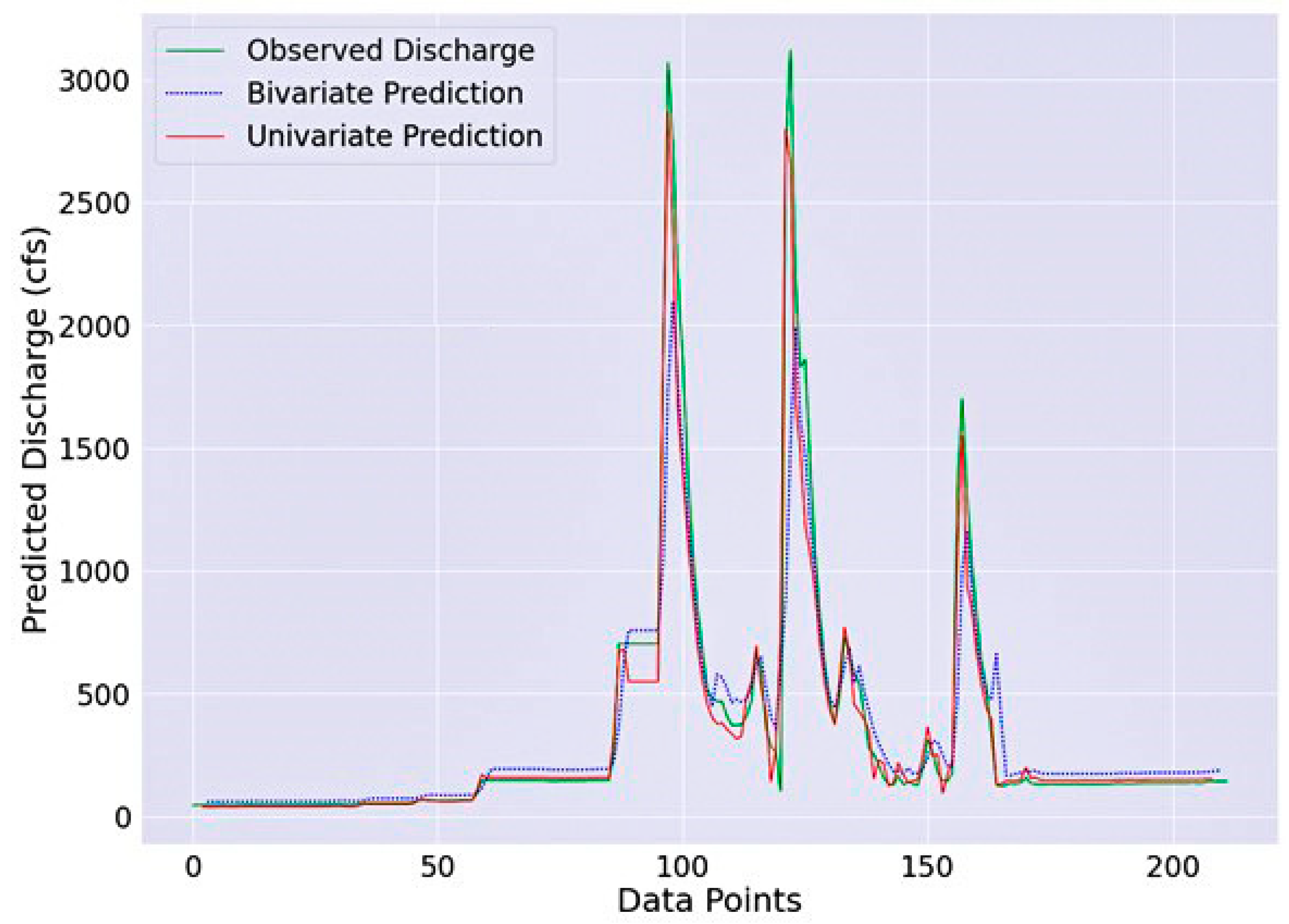
3.1. Predicted and Observed Discharge Series
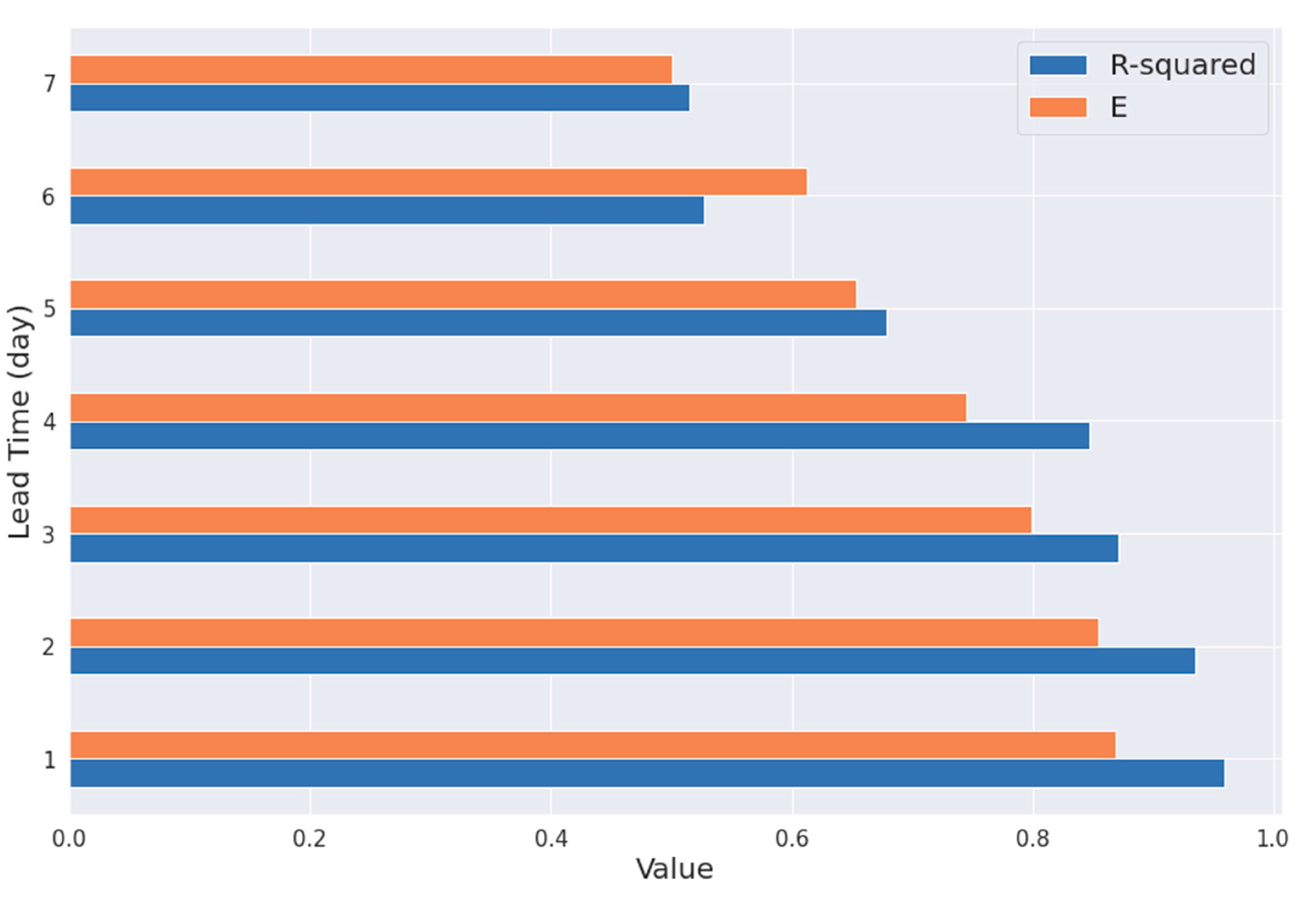
3.2. Model Evaluation Matrices and Improvement
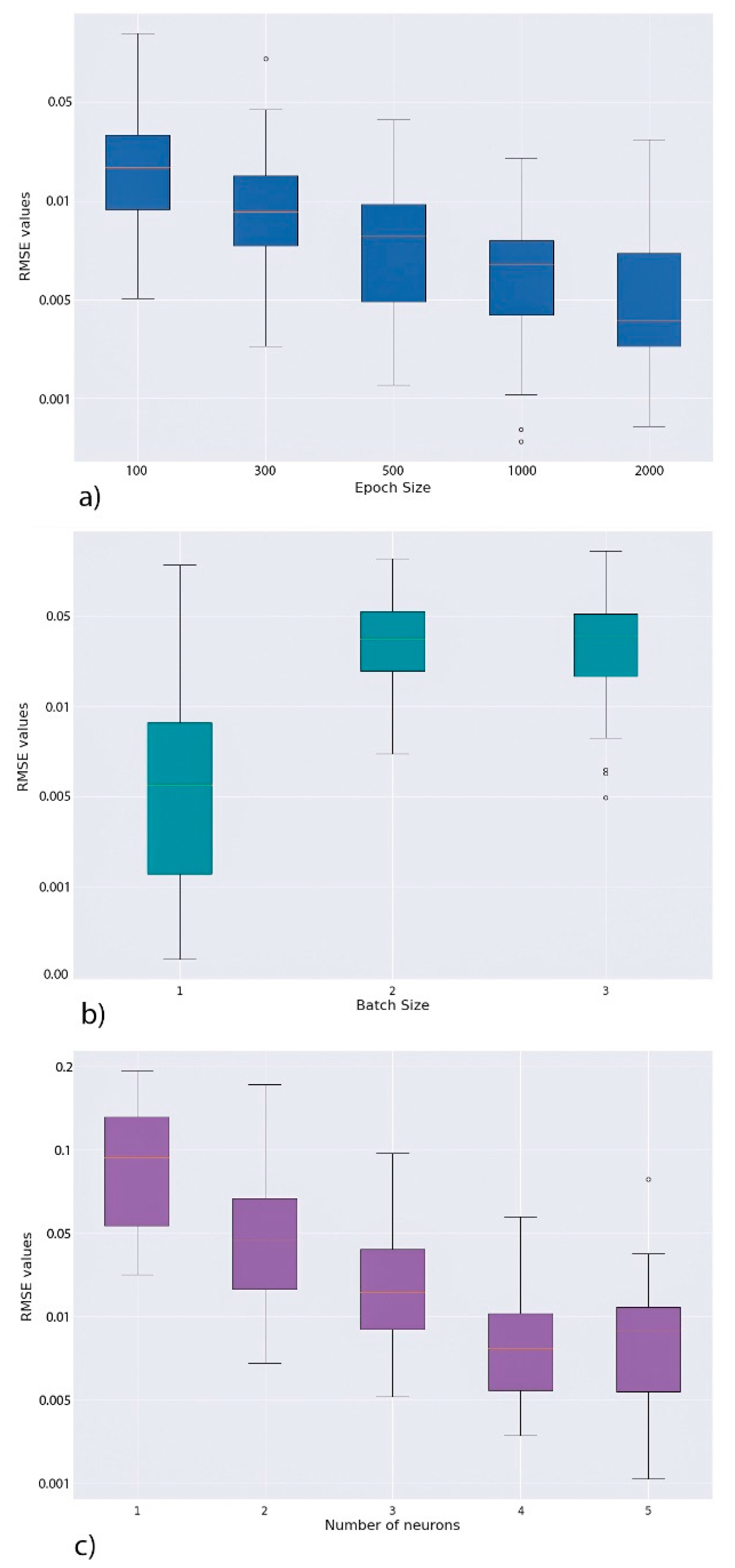
3.3. Hyperparameters
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Meis, M.; Benjamín, M.; Rodriguez, D. Forecasting the Daily Variability Discharge in the Fluvial System of the Paraná River: An ODPC Hydrology Application. Hydrol. Sci. J. 2022, 1–8. [Google Scholar] [CrossRef]
- Hossain, B.M.T.A.; Ahmed, T.; Aktar, N.; Khan, F.; Islam, A.; Yazdan, M.M.S.; Noor, F.; Rahaman, A. Climate Change Impacts on Water Availability in the Meghna Basin. In Proceedings of the 5th International Conference on Water and Flood Management (ICWFM-2015), Dhaka, Bangladesh, 6–8 March 2015. [Google Scholar]
- Kao, I.-F.; Zhou, Y.; Chang, L.-C.; Chang, F.-J. Exploring a Long Short-Term Memory Based Encoder-Decoder Framework for Multi-Step-Ahead Flood Forecasting. J. Hydrol. 2020, 583, 124631. [Google Scholar] [CrossRef]
- Song, X.; Liu, Y.; Xue, L.; Wang, J.; Zhang, J.; Wang, J.; Jiang, L.; Cheng, Z. Time-Series Well Performance Prediction Based on Long Short-Term Memory (LSTM) Neural Network Model. J. Pet. Sci. Eng. 2020, 186, 106682. [Google Scholar] [CrossRef]
- Le, X.-H.; Ho, H.V.; Lee, G.; Jung, S. Application of Long Short-Term Memory (LSTM) Neural Network for Flood Forecasting. Water 2019, 11, 1387. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Chen, Y.; Li, Z.; Fang, G.; Li, Y.; Wang, X.; Zhang, X.; Kayumba, P.M. Developing a Long Short-Term Memory (LSTM)-Based Model for Reconstructing Terrestrial Water Storage Variations from 1982 to 2016 in the Tarim River Basin, Northwest China. Remote Sens. 2021, 13, 889. [Google Scholar] [CrossRef]
- Ma, B.; Pang, W.; Lou, Y.; Mei, X.; Wang, J.; Gu, J.; Dai, Z. Impacts of River Engineering on Multi-Decadal Water Discharge of the Mega-Changjiang River. Sustainability 2020, 12, 8060. [Google Scholar] [CrossRef]
- Bouwer, H. Integrated Water Management: Emerging Issues and Challenges. Agric. Water Manag. 2000, 45, 217–228. [Google Scholar] [CrossRef]
- Evans, R.G.; Sadler, E.J. Methods and Technologies to Improve Efficiency of Water Use. Water Resour. Res. 2008, 44. [Google Scholar] [CrossRef]
- Sophocleous, M. Groundwater Recharge and Sustainability in the High Plains Aquifer in Kansas, USA. Hydrogeol. J. 2005, 13, 351–365. [Google Scholar] [CrossRef]
- Zhang, X.; Meng, Y.; Xia, J.; Wu, B.; She, D. A combined model for river health evaluation based upon the physical, chemical, and biological elements. Ecol. Indic. 2018, 84, 416–424. [Google Scholar] [CrossRef]
- Kisi, O.; Cimen, M. A Wavelet-Support Vector Machine Conjunction Model for Monthly Streamflow Forecasting. J. Hydrol. 2011, 399, 132–140. [Google Scholar] [CrossRef]
- Liang, Z.; Xiao, Z.; Wang, J.; Sun, L.; Li, B.; Hu, Y.; Wu, Y. An Improved Chaos Similarity Model for Hydrological Forecasting. J. Hydrol. Amst. 2019, 577, 123953. [Google Scholar] [CrossRef]
- Kilsdonk, R.A.H.; Bomers, A.; Wijnberg, K.M. Predicting Urban Flooding Due to Extreme Precipitation Using a Long Short-Term Memory Neural Network. Hydrology 2022, 9, 105. [Google Scholar] [CrossRef]
- Ayzel, G.; Kurochkina, L.; Abramov, D.; Zhuravlev, S. Development of a Regional Gridded Runoff Dataset Using Long Short-Term Memory (LSTM) Networks. Hydrology 2021, 8, 6. [Google Scholar] [CrossRef]
- Bai, Y.; Bezak, N.; Sapač, K.; Klun, M.; Zhang, J. Short-Term Streamflow Forecasting Using the Feature-Enhanced Regression Model. Water Resour. Manag. Int. J. Publ. Eur. Water Resour. Assoc. EWRA 2019, 33, 4783–4797. [Google Scholar] [CrossRef]
- Xiao, Z.; Liang, Z.; Li, B.; Hou, B.; Hu, Y.; Wang, J. New Flood Early Warning and Forecasting Method Based on Similarity Theory. J. Hydrol. Eng. 2019, 24, 04019023. [Google Scholar] [CrossRef] [Green Version]
- Milly, P.C.D.; Dunne, K.A.; Vecchia, A.V. Global Pattern of Trends in Streamflow and Water Availability in a Changing Climate. Nature 2005, 438, 347–350. [Google Scholar] [CrossRef]
- Chang, L.-C.; Liou, J.-Y.; Chang, F.-J. Spatial-Temporal Flood Inundation Nowcasts by Fusing Machine Learning Methods and Principal Component Analysis. J. Hydrol. 2022, 612, 128086. [Google Scholar] [CrossRef]
- Devia, G.K.; Ganasri, B.P.; Dwarakish, G.S. A Review on Hydrological Models. Aquat. Procedia 2015, 4, 1001–1007. [Google Scholar] [CrossRef]
- Askarizadeh, A.; Rippy, M.A.; Fletcher, T.D.; Feldman, D.L.; Peng, J.; Bowler, P.; Mehring, A.S.; Winfrey, B.K.; Vrugt, J.A.; AghaKouchak, A.; et al. From Rain Tanks to Catchments: Use of Low-Impact Development To Address Hydrologic Symptoms of the Urban Stream Syndrome. Environ. Sci. Technol. 2015, 49, 11264–11280. [Google Scholar] [CrossRef]
- Zhao, J.; Xu, J.; Xie, X.; Lu, H. Drought Monitoring Based on TIGGE and Distributed Hydrological Model in Huaihe River Basin, China. Sci. Total Environ. 2016, 553, 358–365. [Google Scholar] [CrossRef] [PubMed]
- Humphrey, G.B.; Gibbs, M.S.; Dandy, G.C.; Maier, H.R. A Hybrid Approach to Monthly Streamflow Forecasting: Integrating Hydrological Model Outputs into a Bayesian Artificial Neural Network. J. Hydrol. 2016, 540, 623–640. [Google Scholar] [CrossRef]
- Mosavi, A.; Ozturk, P.; Chau, K. Flood Prediction Using Machine Learning Models: Literature Review. Water 2018, 10, 1536. [Google Scholar] [CrossRef] [Green Version]
- Costabile, P.; Macchione, F. Enhancing River Model Set-up for 2-D Dynamic Flood Modelling. Environ. Model. Softw. 2015, 67, 89–107. [Google Scholar] [CrossRef]
- Cheng, M.; Fang, F.; Kinouchi, T.; Navon, I.M.; Pain, C.C. Long Lead-Time Daily and Monthly Streamflow Forecasting Using Machine Learning Methods. J. Hydrol. 2020, 590, 125376. [Google Scholar] [CrossRef]
- Alvisi, S.; Franchini, M. Fuzzy Neural Networks for Water Level and Discharge Forecasting with Uncertainty. Environ. Model. Softw. 2011, 26, 523–537. [Google Scholar] [CrossRef]
- Prasad, R.; Deo, R.C.; Yan, L.; Maraseni, T. Input Selection and Performance Optimization of ANN-Based Streamflow Forecasts in the Drought-Prone Murray Darling Basin Region Using IIS and MODWT Algorithm. Atmos. Res. 2017, 197, 42–63. [Google Scholar] [CrossRef]
- Rathinasamy, M.; Adamowski, J.; Khosa, R. Multiscale Streamflow Forecasting Using a New Bayesian Model Average Based Ensemble Multi-Wavelet Volterra Nonlinear Method. J. Hydrol. 2013, 507, 186–200. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; El-shafie, A.; Jaafar, O.; Afan, H.A.; Sayl, K.N. Artificial Intelligence Based Models for Stream-Flow Forecasting: 2000–2015. J. Hydrol. 2015, 530, 829–844. [Google Scholar] [CrossRef]
- Myronidis, D.; Ioannou, K.; Fotakis, D.; Dörflinger, G. Streamflow and Hydrological Drought Trend Analysis and Forecasting in Cyprus. Water Resour. Manag. Int. J. Publ. Eur. Water Resour. Assoc. EWRA 2018, 32, 1759–1776. [Google Scholar] [CrossRef]
- Wang, W.; Chau, K.; Xu, D.; Chen, X.-Y. Improving Forecasting Accuracy of Annual Runoff Time Series Using ARIMA Based on EEMD Decomposition. Water Resour. Manag. 2015, 29, 2655–2675. [Google Scholar] [CrossRef]
- Long, J.; Sun, Z.; Pardalos, P.M.; Hong, Y.; Zhang, S.; Li, C. A Hybrid Multi-Objective Genetic Local Search Algorithm for the Prize-Collecting Vehicle Routing Problem. Inf. Sci. 2019, 478, 40–61. [Google Scholar] [CrossRef]
- Abdollahzadeh, M.; Khosravi, M.; Hajipour Khire Masjidi, B.; Samimi Behbahan, A.; Bagherzadeh, A.; Shahkar, A.; Tat Shahdost, F. Estimating the Density of Deep Eutectic Solvents Applying Supervised Machine Learning Techniques. Sci. Rep. 2022, 12, 4954. [Google Scholar] [CrossRef]
- Chang Fi [Chang, F.J.; LiChiu, C.; ChienWei, H.; IFeng, K. Prediction of Monthly Regional Groundwater Levels through Hybrid Soft-Computing Techniques. J. Hydrol. Amst. 2016, 541, 965–976. [Google Scholar] [CrossRef]
- Daliakopoulos, I.N.; Coulibaly, P.; Tsanis, I.K. Groundwater Level Forecasting Using Artificial Neural Networks. J. Hydrol. 2005, 309, 229–240. [Google Scholar] [CrossRef]
- Parchami-Araghi, F.; Mirlatifi, S.M.; Dashtaki, S.G.; Mahdian, M.H. Point Estimation of Soil Water Infiltration Process Using Artificial Neural Networks for Some Calcareous Soils. J. Hydrol. Amst. 2013, 481, 35–47. [Google Scholar] [CrossRef]
- Zhu, X.; Khosravi, M.; Vaferi, B.; Nait Amar, M.; Ghriga, M.A.; Mohammed, A.H. Application of Machine Learning Methods for Estimating and Comparing the Sulfur Dioxide Absorption Capacity of a Variety of Deep Eutectic Solvents. J. Clean. Prod. 2022, 363, 132465. [Google Scholar] [CrossRef]
- Rozos, E.; Dimitriadis, P.; Mazi, K.; Koussis, A.D. A Multilayer Perceptron Model for Stochastic Synthesis. Hydrology 2021, 8, 67. [Google Scholar] [CrossRef]
- Elbeltagi, A.; Di Nunno, F.; Kushwaha, N.L.; de Marinis, G.; Granata, F. River Flow Rate Prediction in the Des Moines Watershed (Iowa, USA): A Machine Learning Approach. Stoch. Environ. Res. Risk Assess. 2022, 36, 3835–3855. [Google Scholar] [CrossRef]
- Belayneh, A.; Adamowski, J.; Khalil, B.; Ozga-Zielinski, B. Long-Term SPI Drought Forecasting in the Awash River Basin in Ethiopia Using Wavelet Neural Network and Wavelet Support Vector Regression Models. J. Hydrol. 2014, 508, 418–429. [Google Scholar] [CrossRef]
- Mirzavand, M.; Ghazavi, R. A Stochastic Modelling Technique for Groundwater Level Forecasting in an Arid Environment Using Time Series Methods. Water Resour. Manag. 2015, 29, 1315–1328. [Google Scholar] [CrossRef]
- Yoon, H.; Jun, S.-C.; Hyun, Y.; Bae, G.-O.; Lee, K.-K. A Comparative Study of Artificial Neural Networks and Support Vector Machines for Predicting Groundwater Levels in a Coastal Aquifer. J. Hydrol. 2011, 396, 128–138. [Google Scholar] [CrossRef]
- Khosravi, M.; Tabasi, S.; Hossam Eldien, H.; Motahari, M.R.; Alizadeh, S.M. Evaluation and Prediction of the Rock Static and Dynamic Parameters. J. Appl. Geophys. 2022, 199, 104581. [Google Scholar] [CrossRef]
- Karimi, M.; Khosravi, M.; Fathollahi, R.; Khandakar, A.; Vaferi, B. Determination of the Heat Capacity of Cellulosic Biosamples Employing Diverse Machine Learning Approaches. Energy Sci. Eng. 2022, 10, 1925–1939. [Google Scholar] [CrossRef]
- Jothiprakash, V.; Kote, A.S. Effect of Pruning and Smoothing While Using M5 Model Tree Technique for Reservoir Inflow Prediction. J. Hydrol. Eng. 2011, 16, 563–574. [Google Scholar] [CrossRef]
- Khosravi, M.; Arif, S.B.; Ghaseminejad, A.; Tohidi, H.; Shabanian, H. Performance Evaluation of Machine Learning Regressors for Estimating Real Estate House Prices. Preprints 2022, 2022090341. [Google Scholar] [CrossRef]
- Allawi, M.F.; Jaafar, O.; Mohamad Hamzah, F.; Mohd, N.S.; Deo, R.C.; El-Shafie, A. Reservoir Inflow Forecasting with a Modified Coactive Neuro-Fuzzy Inference System: A Case Study for a Semi-Arid Region. Theor. Appl. Climatol. 2018, 134, 545–563. [Google Scholar] [CrossRef]
- Xu, X.; Zhang, X.; Fang, H.; Lai, R.; Zhang, Y.; Huang, L.; Liu, X. A Real-Time Probabilistic Channel Flood-Forecasting Model Based on the Bayesian Particle Filter Approach. Environ. Model. Softw. 2017, 88, 151–167. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Zhu, Y.; Zhang, X.; Ye, M.; Yang, J. Developing a Long Short-Term Memory (LSTM) Based Model for Predicting Water Table Depth in Agricultural Areas. J. Hydrol. 2018, 561, 918–929. [Google Scholar] [CrossRef]
- Bai, Y.; Xie, J.; Wang, X.; Li, C. Model Fusion Approach for Monthly Reservoir Inflow Forecasting. J. Hydroinform. 2016, 18, 634–650. [Google Scholar] [CrossRef]
- Sahoo, S.; Jha, M.K. Groundwater-Level Prediction Using Multiple Linear Regression and Artificial Neural Network Techniques: A Comparative Assessment. Hydrogeol. J. 2013, 21, 1865–1887. [Google Scholar] [CrossRef]
- Mehedi, M.A.A.; Reichert, N.; Molkenthin, F. Sensitivity Analysis of Hyporheic Exchange to Small Scale Changes in Gravel-Sand Flumebed Using a Coupled Groundwater-Surface Water Model. In Proceedings of the EGU General Assembly 2020, Online, 4–8 May 2020. EGU2020-20319. [Google Scholar] [CrossRef]
- Kişi, Ö. Streamflow Forecasting Using Different Artificial Neural Network Algorithms. J. Hydrol. Eng. 2007, 12, 532–539. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Hu, R.; Fang, F.; Pain, C.C.; Navon, I.M. Rapid Spatio-Temporal Flood Prediction and Uncertainty Quantification Using a Deep Learning Method. J. Hydrol. 2019, 575, 911–920. [Google Scholar] [CrossRef]
- Shin, M.-J.; Moon, S.-H.; Kang, K.G.; Moon, D.-C.; Koh, H.-J. Analysis of Groundwater Level Variations Caused by the Changes in Groundwater Withdrawals Using Long Short-Term Memory Network. Hydrology 2020, 7, 64. [Google Scholar] [CrossRef]
- Granata, F.; Di Nunno, F.; de Marinis, G. Stacked Machine Learning Algorithms and Bidirectional Long Short-Term Memory Networks for Multi-Step Ahead Streamflow Forecasting: A Comparative Study. J. Hydrol. 2022, 613, 128431. [Google Scholar] [CrossRef]
- Kao, I.-F.; Liou, J.-Y.; Lee, M.-H.; Chang, F.-J. Fusing Stacked Autoencoder and Long Short-Term Memory for Regional Multistep-Ahead Flood Inundation Forecasts. J. Hydrol. 2021, 598, 126371. [Google Scholar] [CrossRef]
- Yazdan, M.M.S.; Khosravi, M.; Saki, S.; Mehedi, M.A.A. Forecasting Energy Consumption Time Series Using Recurrent Neural Network in Tensorflow. Preprints 2022, 2022090404. [Google Scholar] [CrossRef]
- Younger, A.S.; Hochreiter, S.; Conwell, P.R. Meta-Learning with Backpropagation. In Proceedings of the IJCNN’01. International Joint Conference on Neural Networks. Proceedings (Cat. No.01CH37222), Washington, DC, USA, 15–19 July 2001; Volume 3, pp. 2001–2006. [Google Scholar]
- Mouatadid, S.; Adamowski, J.F.; Tiwari, M.K.; Quilty, J.M. Coupling the Maximum Overlap Discrete Wavelet Transform and Long Short-Term Memory Networks for Irrigation Flow Forecasting. Agric. Water Manag. 2019, 219, 72–85. [Google Scholar] [CrossRef]
- Kratzert, F.; Klotz, D.; Brenner, C.; Schulz, K.; Herrnegger, M. Rainfall–Runoff Modelling Using Long Short-Term Memory (LSTM) Networks. Hydrol. Earth Syst. Sci. 2018, 22, 6005–6022. [Google Scholar] [CrossRef] [Green Version]
- Ni, L.; Wang, D.; Singh, V.P.; Wu, J.; Wang, Y.; Tao, Y.; Zhang, J. Streamflow and Rainfall Forecasting by Two Long Short-Term Memory-Based Models. J. Hydrol. 2020, 583, 124296. [Google Scholar] [CrossRef]
- Hu, C.; Wu, Q.; Li, H.; Jian, S.; Li, N.; Lou, Z. Deep Learning with a Long Short-Term Memory Networks Approach for Rainfall-Runoff Simulation. Water 2018, 10, 1543. [Google Scholar] [CrossRef] [Green Version]
- Poole, G.C.; Fogg, S.K.; O’Daniel, S.J.; Amerson, B.E.; Reinhold, A.M.; Carlson, S.P.; Mohr, E.J.; Oakland, H.C. Hyporheic Hydraulic Geometry: Conceptualizing Relationships among Hyporheic Exchange, Storage, and Water Age. PLoS ONE 2022, 17, e0262080. [Google Scholar] [CrossRef] [PubMed]
- Mehedi, M.A.A.; Amur, A.; McGauley, M.; Metcalf, J.; Wadzuk, B.; Smith, V. Quantifying the Benefits of AI vs. Numerical Modeling for Urban Green Stormwater Infrastructure. In Proceedings of the AGU Fall Meeting 2021, New Orleans, LA, USA, 13–17 December 2021; Volume 2021, p. H45N-1330. [Google Scholar]
- Kilinc, H.C.; Haznedar, B. A Hybrid Model for Streamflow Forecasting in the Basin of Euphrates. Water 2022, 14, 80. [Google Scholar] [CrossRef]
- Xayasouk, T.; Lee, H.; Lee, G. Air Pollution Prediction Using Long Short-Term Memory (LSTM) and Deep Autoencoder (DAE) Models. Sustainability 2020, 12, 2570. [Google Scholar] [CrossRef] [Green Version]
- Rozos, E.; Dimitriadis, P.; Bellos, V. Machine Learning in Assessing the Performance of Hydrological Models. Hydrology 2022, 9, 5. [Google Scholar] [CrossRef]
- Staudemeyer, R.C.; Morris, E.R. Understanding LSTM—A Tutorial into Long Short-Term Memory Recurrent Neural Networks. arXiv 2019, arXiv:1909.09586. [Google Scholar]
- Tsang, G.; Deng, J.; Xie, X. Recurrent Neural Networks for Financial Time-Series Modelling. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 892–897. [Google Scholar]
- Maulik, R.; Egele, R.; Lusch, B.; Balaprakash, P. Recurrent Neural Network Architecture Search for Geophysical Emulation. In Proceedings of the Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Atlanta, GA, USA, 9–19 November 2020; pp. 1–14. [Google Scholar]
- Gupta, H.V.; Kling, H. On Typical Range, Sensitivity, and Normalization of Mean Squared Error and Nash-Sutcliffe Efficiency Type Metrics. Water Resour. Res. 2011, 47. [Google Scholar] [CrossRef]
- Willmott, C.J.; Robeson, S.M.; Matsuura, K. A Refined Index of Model Performance. Int. J. Climatol. 2012, 32, 2088–2094. [Google Scholar] [CrossRef]
- Hossain, M.D.; Ochiai, H.; Fall, D.; Kadobayashi, Y. LSTM-Based Network Attack Detection: Performance Comparison by Hyper-Parameter Values Tuning. In Proceedings of the 2020 7th IEEE International Conference on Cyber Security and Cloud Computing (CSCloud)/2020 6th IEEE International Conference on Edge Computing and Scalable Cloud (EdgeCom), New York, NY, USA, 1–3 August 2020; pp. 62–69. [Google Scholar] [CrossRef]
- Gorgolis, N.; Hatzilygeroudis, I.; Istenes, Z.; Gyenne, L.-G. Hyperparameter Optimization of LSTM Network Models through Genetic Algorithm. In Proceedings of the 2019 10th International Conference on Information, Intelligence, Systems and Applications (IISA), Patras, Greece, 15–17 July 2019; pp. 1–4. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Count | 29,393 |
| Mean | 323.73 |
| Standard Deviation | 681.61 |
| Minimum | 0.6 |
| 25th percentile | 42 |
| 50th percentile | 88.4 |
| 75th percentile | 332 |
| Maximum | 17,700 |
| Inter Quantile Range (IQR) | 290.00 |
| LSTM Component | Equations |
|---|---|
| Forget gate | |
| Input gate | |
| Output gate | |
| Cell state | |
| Candidate for cell state | |
| Hidden state |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mehedi, M.A.A.; Khosravi, M.; Yazdan, M.M.S.; Shabanian, H. Exploring Temporal Dynamics of River Discharge Using Univariate Long Short-Term Memory (LSTM) Recurrent Neural Network at East Branch of Delaware River. Hydrology 2022, 9, 202. https://doi.org/10.3390/hydrology9110202
Mehedi MAA, Khosravi M, Yazdan MMS, Shabanian H. Exploring Temporal Dynamics of River Discharge Using Univariate Long Short-Term Memory (LSTM) Recurrent Neural Network at East Branch of Delaware River. Hydrology. 2022; 9(11):202. https://doi.org/10.3390/hydrology9110202
Chicago/Turabian StyleMehedi, Md Abdullah Al, Marzieh Khosravi, Munshi Md Shafwat Yazdan, and Hanieh Shabanian. 2022. "Exploring Temporal Dynamics of River Discharge Using Univariate Long Short-Term Memory (LSTM) Recurrent Neural Network at East Branch of Delaware River" Hydrology 9, no. 11: 202. https://doi.org/10.3390/hydrology9110202
APA StyleMehedi, M. A. A., Khosravi, M., Yazdan, M. M. S., & Shabanian, H. (2022). Exploring Temporal Dynamics of River Discharge Using Univariate Long Short-Term Memory (LSTM) Recurrent Neural Network at East Branch of Delaware River. Hydrology, 9(11), 202. https://doi.org/10.3390/hydrology9110202