1. Introduction
In obstetric imaging, the position of the fetus in relation to maternal anatomical structures, such as the bladder and intestines, otherwise known as fetal presentation/orientation, must be determined [
1]. The American Institute of Ultrasound in Medicine outlines fetal imaging protocols, stating that fetal presentation must be identified in all second and third-trimester fetal imaging examinations [
2]. Four of the main fetal orientations are vertex (head down), breech (head up), oblique (diagonal), and transverse (sideways) [
1,
3,
4]. Diagnosing fetal orientation is important for the choice of delivery [
5,
6,
7].
Ultrasound (US) is the imaging method of choice to screen for fetal abnormalities. US uses sound waves to produce images [
8]. However, recent advances in Magnetic Resonance Imaging (MRI) have demonstrated improved soft-tissue contrast and radiation-free properties and improved sensitivity over US imaging in some cases [
9,
10,
11,
12,
13,
14]. MRI uses strong magnetic fields, magnetic field gradients, and radio waves to form images [
15,
16]. As a result, fetal MRI is emerging as an essential imaging modality in evaluating complex fetal abnormalities and is even outperforming US in detecting many fetal pathologies [
17,
18,
19,
20]. The more accurate diagnoses from MRI, in turn, allow for better planning during the pregnancy for the postnatal and neonatal periods and even allow for possible fetal surgery where necessary [
14,
21]. MRI can also be used shortly before delivery for pelvimetric measurements to assess whether an attempt at vaginal delivery is feasible. While MRI is not the method of choice to determine fetal presentation, it is crucial to correctly assess fetal presentation when acquiring a fetal MRI to enable sequence planning. This can form the basis for more automated fetal MRI acquisition. In addition, fetal presentation needs to be correctly mentioned in the radiological report of the fetal MRI.
Machine learning is the application of computer algorithms that can self-learn through experience and data inputs [
22]. Deep learning is a subfield within machine learning, which mimics human brain processes and uses large amounts of data and neural networks to learn patterns for recognition [
22,
23]. Deep learning, specifically convolutional neural networks (CNNs), have been previously applied to various fetal imaging applications, such as fetal head and abdomen measurement, artifact detection in 3D fetal MRI, and anomaly identification in a fetal brain, spine or heart [
24,
25,
26].
For predicting the mode of delivery for a pregnancy, Kowsher et al. [
27] applied 32 supervised machine and deep learning algorithms to a dataset consisting of 21 different metrics from 13,527 women [
27]. The data metrics included age, blood circulation, and parity, among others [
27]. Of all models tested, the Quadratic Discriminant Analysis algorithm yielded the best accuracy result at 97.9% [
27]. In the case of deep learning algorithms, only a standard neural network has been tested to date, producing an accuracy of 95.4% [
27]. Xu et al. [
28] used CNNs to create heatmaps that can then estimate the fetal pose of a 3D fetal MRI volume with a Markov Random Field model. Xu’s work provides an estimation of fetal pose in space, which is important for monitoring fetal movement. Nevertheless, this approach does not provide a classification of the fetal presentation with respect to the maternal anatomy using internationally acceptable classes (vertex, breech, oblique, and transverse) [
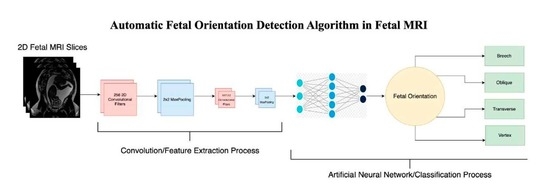
29]. To the best of our knowledge, such an approach of applying CNNs to automatically detect fetal orientation, with the motivation of facilitating delivery planning and fetal MRI acquisition, has not been performed, which is the goal of our study. We will then compare the performance of our novel CNN algorithm with those of other state-of-the-art CNN architectures, including VGG, ResNet, Xception and Inception.
4. Discussion
Fet-Net, the seven-layer convolutional neural network, demonstrated an average accuracy and F1-score of 97.68% and a loss of 0.06828 in classifying the fetal orientation of 6120 2D MRI slices during a 5-fold cross-validaton experiment. Fet-Net accurately classified the 2D MRI slices as one of vertex, breech, oblique or transverse with precision and recall scores above 95.23% for all four individual labels.
It is interesting to note that Fet-Net has only 10,556,420 parameters in its architecture, whereas out of the prominent networks, the next closest in terms of number of parameters is VGG16 with 14,847,04. The architecture with the highest number of parameters is ResNet152, with 58,896,516. During transfer learning, the transferred layers were frozen, which yielded better results than when the layers were not frozen. Therefore, the comparison between Fet-Net and the transfer learning models is when the layers were not trainable for the prominent CNNs. The number of parameters needed for a classification task depends on the dataset being used. Certain datasets may require a denser network to be able to classify correctly. Nevertheless, if a network is too complex for a more straightforward classification task, then trends such as overfitting will be illustrated. This was apparent in looking at the curves of
Figure 3B–D, as the validation curves begin to diverge from the training curves rather than converge. Therefore, despite the fewer parameters, Fet-Net’s architecture performed better than the more complex architectures with far more parameters. Data normalization was an essential operation in the algorithm, since it markedly improved the loss of the model and increased the speed of convergence during the model’s training. Without normalization, the average accuracy decreased to 59.53%, while the average loss increased to 0.81983. This is evidence of a model that is unable to learn with each successive epoch when normalization is not performed.
VGG16 performed the best after Fet-Net, with an accuracy of 96.72% and a loss of 0.12316. This accuracy was lower than Fet-Net by 0.96%, and the loss was greater by 0.05488. The most drastic difference in performance was demonstrated by ResNet101, in which the accuracy was lower by 15.56%, and the loss was greater by 0.40258. One-sided ANOVA testing was used to determine the statistical difference between Fet-Net’s results and those of the prominent CNN architectures. Based on the ANOVA test, the difference in results of VGG16 from Fet-Net was statistically significant (p < 0.05). Therefore, Fet-Net outperformed all 11 prominent architectures in a significant manner. Fet-Net’s precision and recall of all four individual labels outperformed all other architectures, apart from VGG16’s precision for the transverse label by 0.3742% and VGG16’s recall for the oblique label by 0.3936%. Fet-Net’s lower loss than all other architectures demonstrates its ability to predict the correct fetal orientation with higher confidence. In other words, on average, the neuron of the correct label in the last layer of the artificial neural network has a higher probability associated with its classification than when the other prominent CNN architectures are tested.
Accuracy and loss curves are very telling regarding how well a model has learned. The curves illustrate whether overfitting or underfitting have occurred depending on the resemblance of the validation curve to the training curve. It is essential to have the training and validation accuracy curves gradually increase together to a consistent plateau and loss curves that slowly decline together to a consistent minimum.
Figure 3 demonstrated that only Fet-Net (
Figure 3A) follows the desired trend, whereas all other architectures demonstrated overfitting, as the plateau of the validation accuracy curves were below the training accuracy curves, and the validation loss curves were above the training loss curves.
Despite the decreased accuracy and increased loss for Fet-Net in
Table 3, the results of the validation experiment were still encouraging. It was expected that Fet-Net would not perform as well with the 605 unseen 2D MRI slices, as none of the slices from these 3D MRI datasets were used in training. During this test, five-fold cross-validation was not performed; thus, three different random seeds were set to ensure that the results for Fet-Net were not obtained by chance. Fet-Net’s average F1-scores across the three seeds for all four labels were above 80%. Fet-Net outperformed all other architectures by at least 5.34%, and its loss was lower by at least 0.5694.
The results of the ablation study were also encouraging, as they demonstrated the role each component of the Fet-Net architecture plays in achieving the obtained performance. First, as a test, L1 and L2 regularization were separately added to the architecture to see if it improved performance; yet, it significantly increased the loss and was therefore left out of the architecture. The Adam optimizer has advantages over the SGD optimizer due to its adaptive learning rate. However, Zhang argues that predictive models with the SGD optimizer can generalize more effectively than those with the Adam optimizer, which is an essential property of an image classifier [
35]. Both optimizers were tested during the testing phase of the experiment, and it was apparent that the SGD optimizer failed to converge, as the accuracy and loss values did not improve during the training process, which ultimately led to poor generalization. Therefore, the Adam optimizer was used. Typically, dropouts are only used in the neural network component of the architecture; however, as shown in
Table 4, the results were enhanced by adding the dropout components into the feature extraction portion of the architecture. The dropout rate was set to 0.5 across the entire architecture, which is typically the limit for dropout rates. The accuracy and loss metrics were negatively impacted by dropout rates below 0.5. The 0.5 dropout rate prevented overfitting, which became apparent even when a 0.4 dropout rate was used. From
Table 4, it is clear how the accuracy of Fet-Net was reduced with each successive ablation. From the complete architecture to its most ablated version, the accuracy was reduced by 18.84%, and the loss increased by 1.0489. The ANOVA test demonstrates the statistical significance of the difference in accuracy and loss between the complete architecture and the fully ablated architecture with
p-values of 8.8310 × 10
and 2.2410 × 10
for the accuracy and the loss, respectively. Statistical testing was conducted for the accuracies between every successive row of
Table 4, and it was found that the differences in accuracies were all significant (
p-values < 0.05) except for the removal of the hidden layer of 256 neurons after removing the dropouts from the entire architecture. However, the hidden layer was still incorporated into the architecture, as the difference in loss between the complete architecture and an ablated version with just the hidden layer removed is statistically significant (
p-value = 0.004).
Figure 4 illustrates a more pronounced overfitting trend as more components are removed from the architecture.
Fet-Net again outperformed all other prominent architectures, with the exception of the ResNet152 architecture for loss. As the magnetic field strength of an MRI increases, so too does the signal-to-noise ratio [
37]. The signal-to-noise ratio also increases with the repetition time of an MRI, which is the amount of elapsed time between two pulse sequences on one slice [
37]. If a model with fewer parameters performs better on images of reduced SNR, then the amount of time for MRI acquisition does not need to be as long. The differences in accuracy between
Table 2 and
Table 5 demonstrate how most of the prominent architectures are much more affected by noisier images. For example, the VGG16 architecture only trailed Fet-Net by 0.96% for accuracy on undistorted images. However, when tested with noisy images, the VGG16 architecture trailed Fet-Net by 7.08%. The current accuracy of 74.58% for Fet-Net is not satisfactory; however, these results illustrate that a model with fewer parameters is not as affected by lower SNR MRIs. With this information, it may be possible to conduct MRIs faster and build an optimized predictive model with fewer parameters than the current prominent architectures, which could ultimately help in alleviating the healthcare systems pertaining to the backlog in MRI appointments.
There are some limitations associated with the experimental process. Despite treating the 2D image slices as independent after performing data augmentation, there is an inherent correlation between the images of one fetus. In addition, the 2D image slices of one 3D fetal MRI have subtle differences; yet, they still resemble one another. While there were no direct duplicates of 2D image slices between the training and validation/testing sets, the randomized split of 2D slices across training/validation/testing sets during the 5-fold cross-validation experiment may give rise to images in the validation/testing sets resembling an image in the training set. We, therefore, performed a validation experiment to provide a more informative representation of Fet-Net’s capabilities. Additionally, this study uses one dataset of 6120 2D MRI slices split into five separate training validation and testing folds; however, further comparisons of deep learning algorithms using different MRI datasets should be conducted to confirm these promising results.

 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}