1. Introduction
Glaucoma is an eye disease that can lead to blindness. Early diagnosis and treatment with ophthalmologists can prevent further deterioration [
1]. It is estimated that the number of glaucoma patients worldwide will increase from 76.5 million in 2020 to 111.8 million in 2040 [
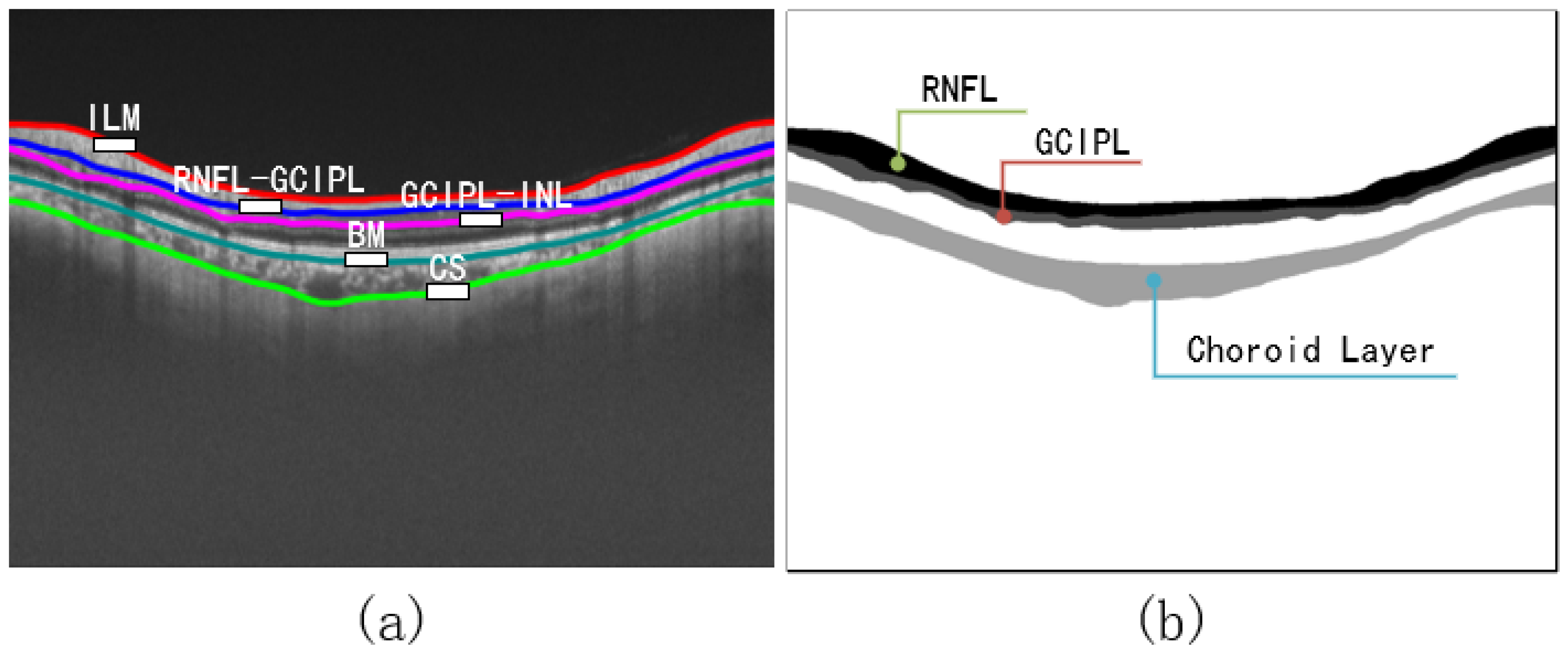
2]. Glaucoma is characterized by thinning of the retinal nerve fiber layer (RNFL) and optic disc depression. The main factors that form glaucoma are age, elevated intraocular pressure (IOP), and genetic background [
3]. The main parameter for early diagnosis of glaucoma is the thickness of the RNFL layer: the smaller the thickness, the more severe the symptoms [
4]. Thanks to the non-invasive, fast scanning speed, high resolution, and 3D imaging advantages of OCT technology [
5], it soon became a necessary technical means for diagnosing ophthalmic diseases [
6]. Ophthalmologists analyze OCT images to determine eye or body health conditions, such as glaucoma, multiple sclerosis [
7], and Alzheimer’s [
8]. Different tissue layers of the retina have strict topological edge order. OCT retinal layer image segmentation results are significant for thickness [
4,
9] and surface shape analysis [
10]. However, images collected by OCT technology are usually rough due to noise, and the layer boundary is unclear. Ophthalmologists must carefully analyze retinal OCT images to identify the retinal layer and its edge, which usually takes plenty of time. From the above, there is an urgent need for OCT automatic segmentation technology.
Many automatic retinal layer segmentation methods have been proposed to help doctors analyze OCT images. Their main goal is to obtain the correct and smooth retinal layer surface. Graph-based methods [
11,
12,
13], which only use hand-designed features, are vulnerable to the noise and distortion of OCT images. In recent years, deep learning has developed rapidly and is widely used in the medical field [
14]. The U-shaped [
15] neural network framework based on convolutional neural network (CNN) is the most widely used in ophthalmic retinal layer segmentation [
16], e.g., Ref. [
17] uses a fully convolutional neural network to predict each OCT image pixel and then extract the edge, Ref. [
18] divides the pixel into ten categories and applies the shortest path to obtain the edge of each layer, and Ref. [
19] uses ResUnet to directly predict the retinal layer category of each OCT image’s pixel and each layer’s edge position. Although the CNN-based model achieves good performance, it cannot learn the interaction of semantic information between global and long range due to the limitation of the convolution operation. On the contrary, the model constructed based on the Transformer has the ability of global modeling, and its performance surpasses the model based on CNN [
20]. Among them, the modified model based on Transformers such as Swin Transformer [
21] and CSWin Transformer [
22] have outstanding performance in terms of accuracy. The model based on the Transformer achieves satisfactory performance, but there are fewer applications in OCT images in retinal layer segmentation.
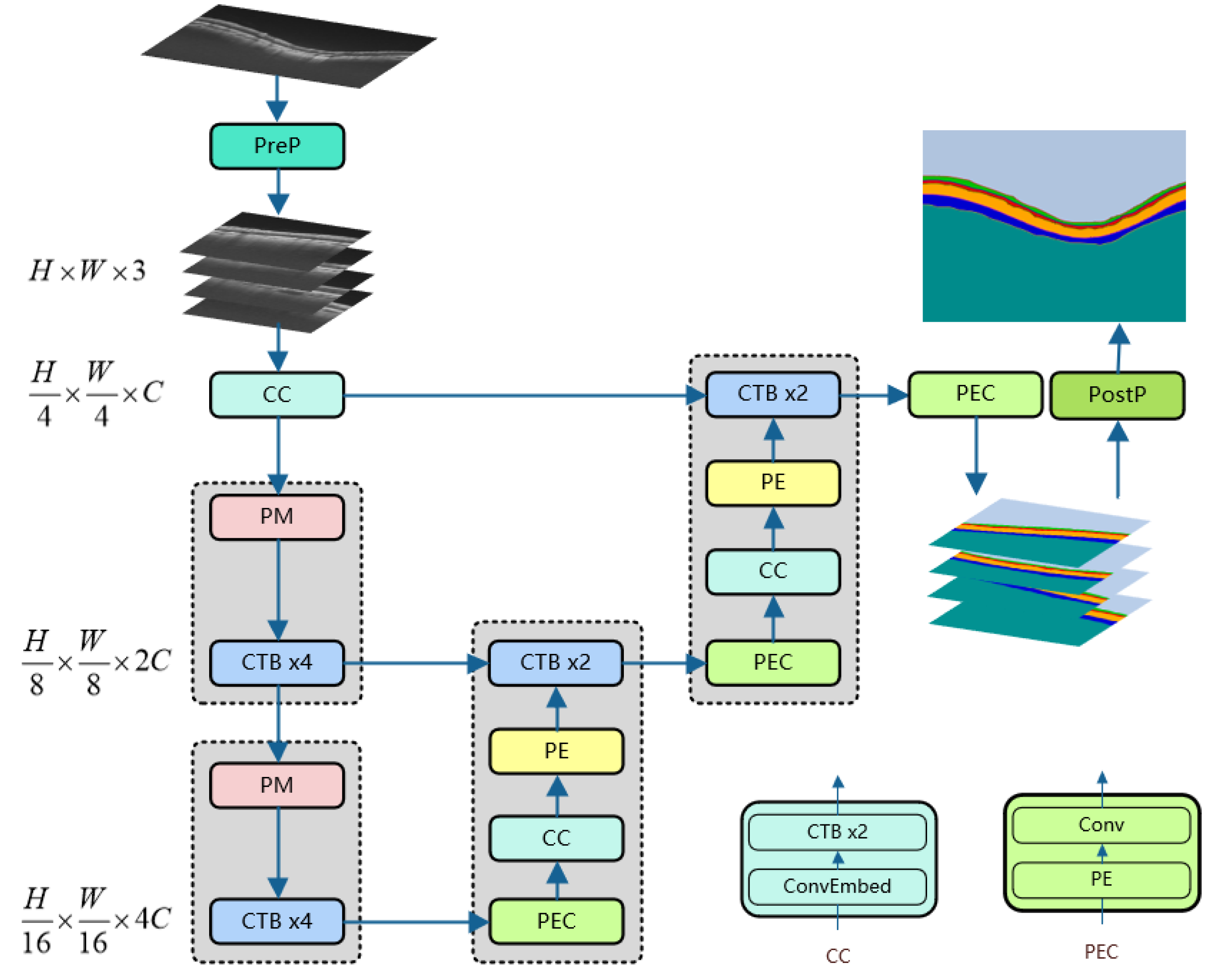
In order to apply the excellent performance of the Transformer to the segmentation of retinal layers, our network adopts a design combining convolution and the Transformer. Since the Transformer’s self-attention calculation consumes a lot of computing power [
23] and cannot directly process image data, it is necessary to use the convolutional layer to convert the image into sequence data containing multiple tokens. The backbone layer used by our network is the CSWin Transformer [
22], which enables powerful modeling capabilities while constraining computational cost; this is meaningful for improving the convergence speed of model training and small dataset training. Our network model follows the classic U-shaped structure design to enable the model to learn more features at multiple scales. We apply the proposed method to the retinal layer segmentation data, which is an essential reference for glaucoma, and compare it with the state-of-the-art method to verify the effectiveness of our method. Inspired by [
24], we propose a Dice loss function based on the edge area and use it for neural network training. The results show that this is effective for improving the characteristics of the edge area learned by the neural network and the segmentation accuracy.
Our contributions can be summarized as follows:
We design a CSWin-Transformer-based OCT image segmentation network for glaucoma retinal layers. After carefully analyzing the cross-attention mechanism of the CSWin Transformer, it is found that its self-attention in the horizontal and vertical directions matches the features of the retinal layer. Therefore, we developed the neural network and applied it to the segmentation task of glaucomatous retinal layers, which provides a new reference direction for using an attention mechanism for retinal layer segmentation.
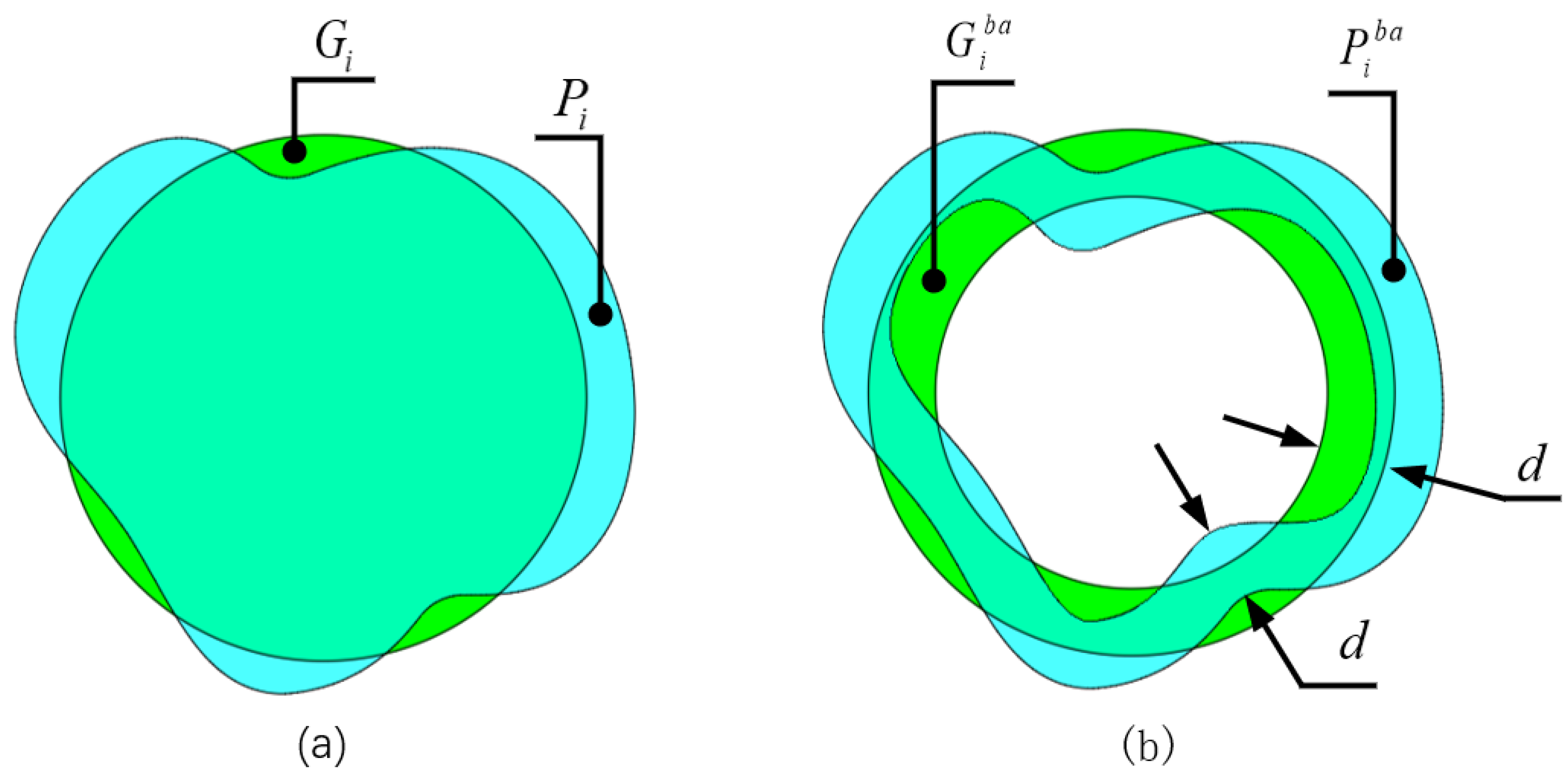
We present a Dice loss function based on edge regions. In retinal layer segmentation tasks, features are often condensed in edge regions. Based on the Dice loss function, we developed a loss function that only calculates the overlapping loss of the edge region, which can guide the depth learning model to learn more edge features to improve the accuracy of edge segmentation.
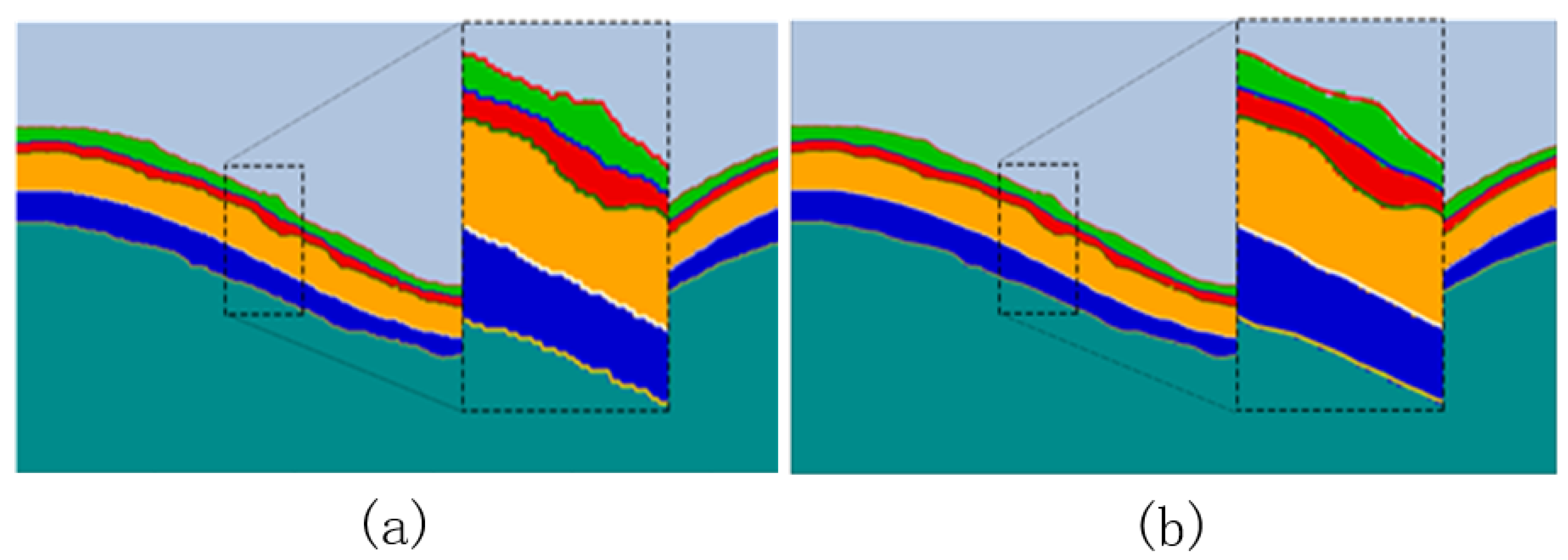
5. Discussion
Retinal layer segmentation for glaucoma is challenging due to the high resolution of the images involved and the high requirement for retinal layer edge segmentation. We designed CTS-Net based on the analysis of the cross-attention mechanism of the CSWin Transformer and the hierarchical characteristics of OCT retinal layer images. The proposed method is superior to the comparison model in MAD and RMSE metrics and inferior to the comparison model in Std, which shows that the test results of the model are relatively stable. Although the results of the BADL+DL loss function are similar to those of the Dice loss function (
Table 4), when BADL is added, the MAD and RMSE metrics of the test results of the RelayNet, Swin-Net, and CTS-Net models are reduced, which indicates that BADL can guide the model to improve the performance of edge segmentation. It also shows that BADL can be used as a general loss function for image segmentation.
Our work also has some limitations. The proposed method must pre-process the rectangular image into a square before it can be used. However, Refs. [
19,
35,
36] can directly input the rectangular image into the neural network. This problem can be solved by fine-tuning the CSWin Transformer structure to make it available for rectangular images. Our method is limited to 2D images and cannot process 3D data with rich information, which may be our future research work.
6. Conclusions
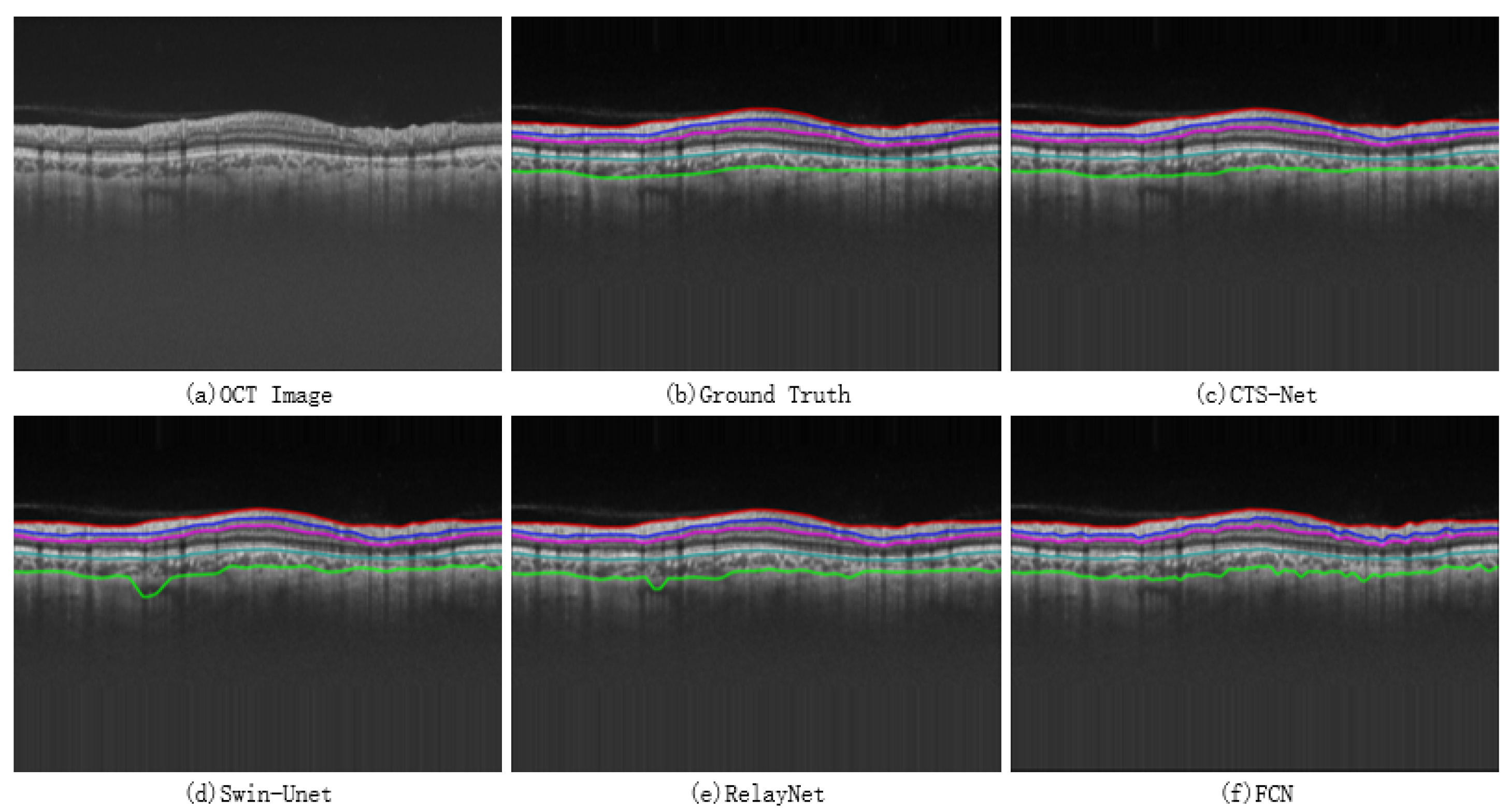
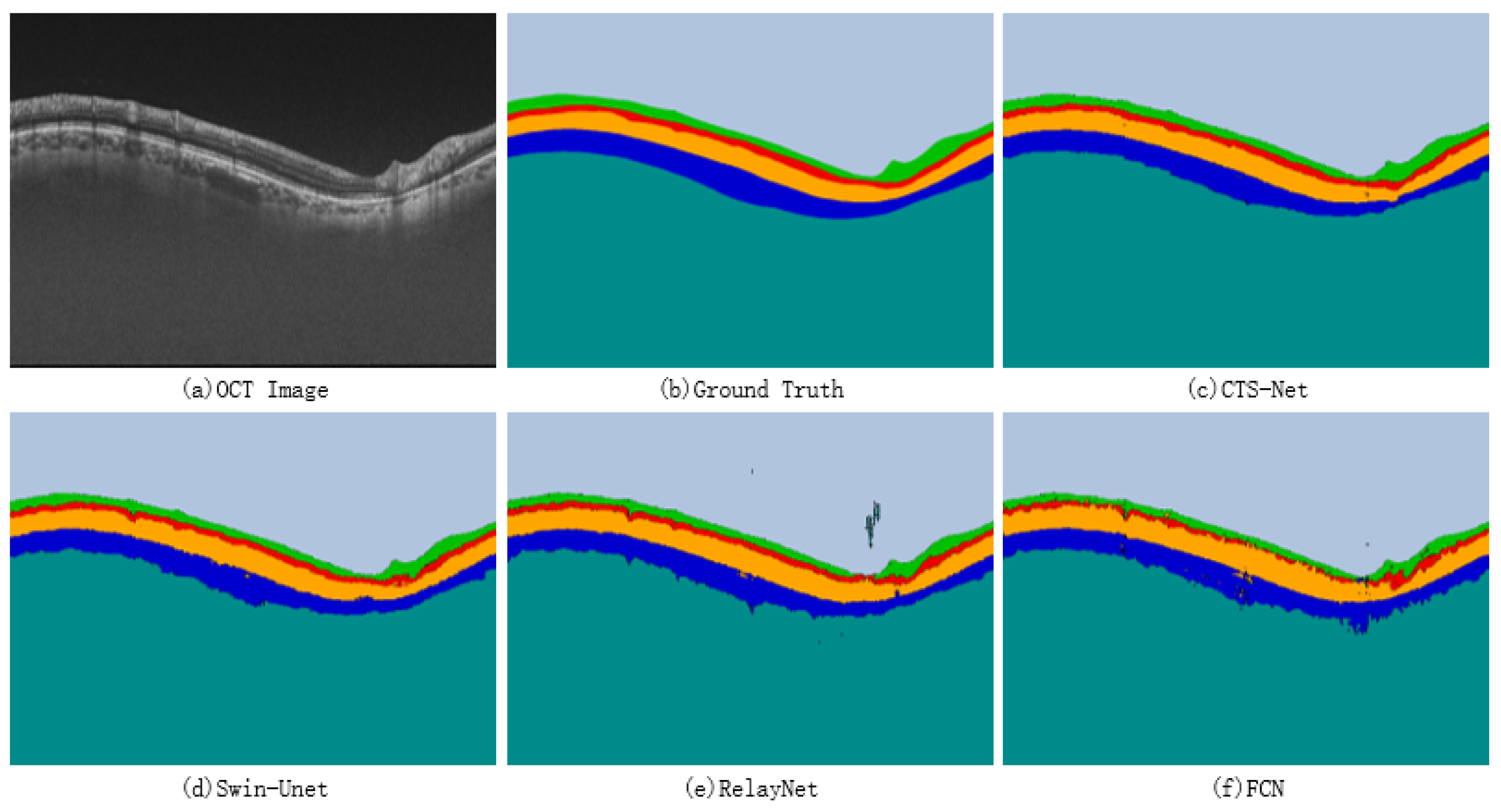
The neural network model based on CSWin Transformer has excellent potential in image segmentation but it is rarely used in OCT retinal layer image segmentation. The cross attention of CSWin Transformer can achieve a wide range of self-attention calculations, giving the model excellent remote modeling capability. In this paper, we built CTS-Net based on the basic skeleton of CSWin Transformer to realize pixel-level segmentation of OCT images of the glaucoma retinal layer and to obtain smooth and continuous retinal layer boundaries. We proposed a Dice loss function based on the boundary area to guide the model to discover more features around the edge region. The experimental results show that the evaluation indexes of MAD, RMSE, and DSC are 1.79 pixels, 2.15 pixels, and 92.79%, respectively, which are better than the contrast model. Further cross-validation experiments show the robustness of the CTS-Net method. The proposed method can effectively promote depth learning technology’s performance in retinal layer OCT image segmentation.



 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}