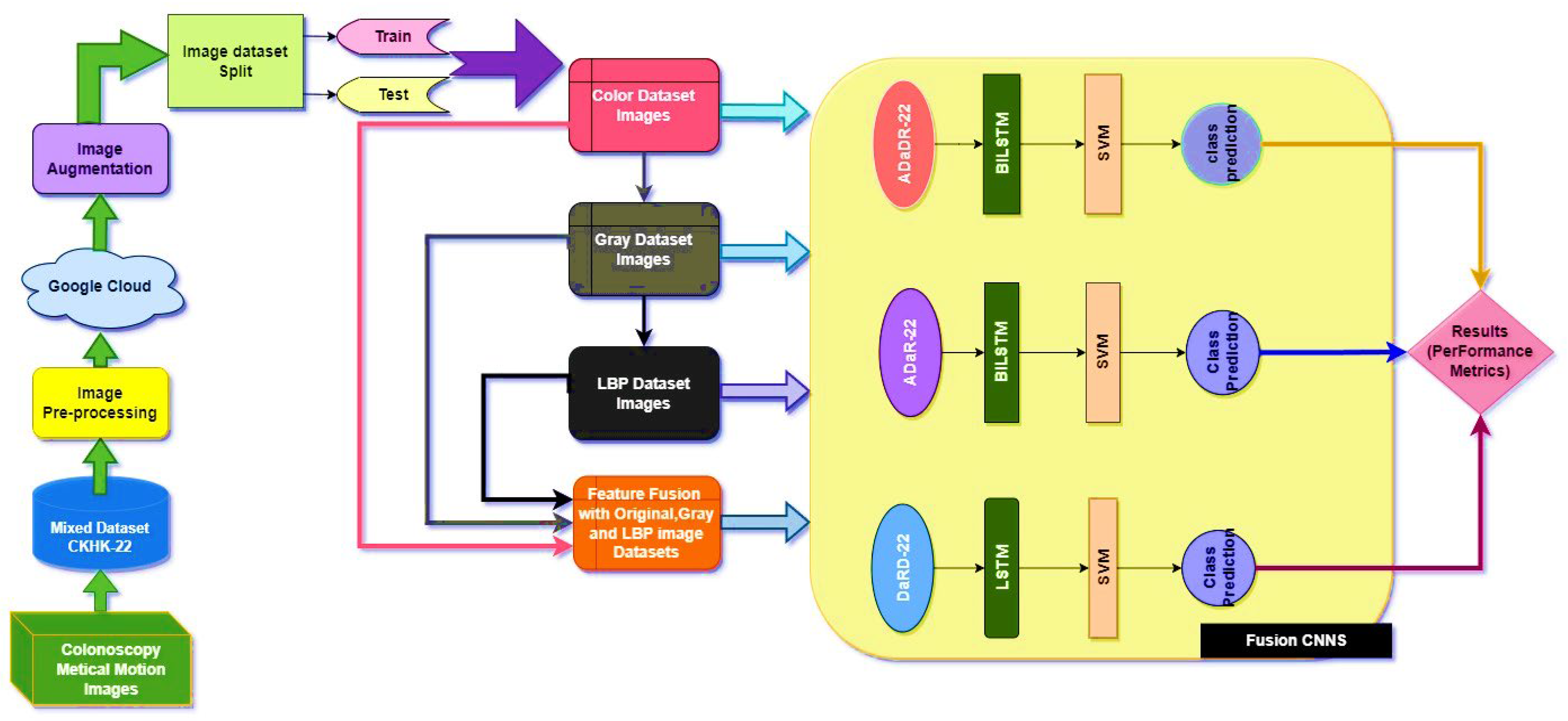
The EnsemDeepCADx system was created to detect colorectal cancer by fusing together several variables from the CKHK-22 mixed dataset. Using the original, greyscale, LBP, and feature fusion datasets, three ensemble CNNs were merged with BiLSTM and multi-class SVM to boost the system’s accuracy.
The main resulting experiments were divided into the last three stages of the CADx system, with the findings from each phase compared to find the optimal ensemble for CADx-based colorectal cancer recognition.
4.2. Stage 2 Experimentation: Ensemble Fusion CNNs
In the second stage of the experiment, the EnsemDeepCADx system employs three ensemble CNN models: ADaDR-22, ADaR-22, and DaRD-22. Each of the four CKHK-22 datasets (original, greyscale, LBP, and feature fusion) is used to train and evaluate these models; they contain a total of 10,000 training and 4287 testing images in three datasets and 30,000 training and 12,861 testing images in the feature fusion dataset, with 10 classes in each dataset.
Each ensemble CNN collects and calculates a variety of performance metrics, including accuracy, precision, F1 score, and recall. The system also contrasts the efficacy of the models and graphically displays the results. This stage of the experiment is crucial because it contrasts the accuracy of each model with different input data by evaluating the performance of each CNN ensemble with a variety of datasets. The results can be used to determine which CNN ensemble performs the best on the CKHK-22 dataset for detecting colorectal cancer.
Table 3 presents the results of the Stage 2 experimental investigations of EnsemDeepCADx for ensemble CNNs using four datasets.
With a testing accuracy of 89%, DaRD-22 was the ensemble fusion CNN model with the maximum accuracy. This model’s precision was 90.78%, its recall was 89%, and its F1 score was 88.52%. This model’s training accuracy was 96.2%. The model with the lowest testing accuracy was ADaR-22, which had an accuracy of 86.33%. This model’s precision was 89.34%, its recall was 86.33%; and its F1 score was 85.66%. This model’s training accuracy was 94.22%.
The ADaR-22 model attained the highest accuracy for the Greyscale CKHK-22 dataset using ensemble fusion CNNs, with a precision of 85.47%, recall of 81.31%, F1 score of 82.07%, training accuracy of 91.33%, and testing accuracy of 82.07%, as shown in the table above. The DaRD-22 model obtained the lowest accuracy, with a precision of 81.95%, a recall of 80.66%, an F1 score of 79.57%, a training accuracy of 89.66%, and a testing accuracy of 81.60%.
Looking at the table, it appears that the DaRD-22 model in the LBP CKHK-22 dataset obtained the highest performance metrics. This model’s precision was 69.92%, its recall was 68.96%, and its F1 score was 67.56%. Training accuracy was 71.83%, while assessing accuracy was 68.96%. This indicates that the DaRD-22 model was able to effectively learn the LBP CKHK-22 dataset’s features and perform well when classifying the various classes. In contrast, the precision, recall, and F1 scores for the ADaDR-22 and ADaR-22 models were 64.4–68.74%, 65.31–66.03%, and 64.98–67.56%, respectively. The accuracy of training and testing was also inferior to the DaRD-22 model.
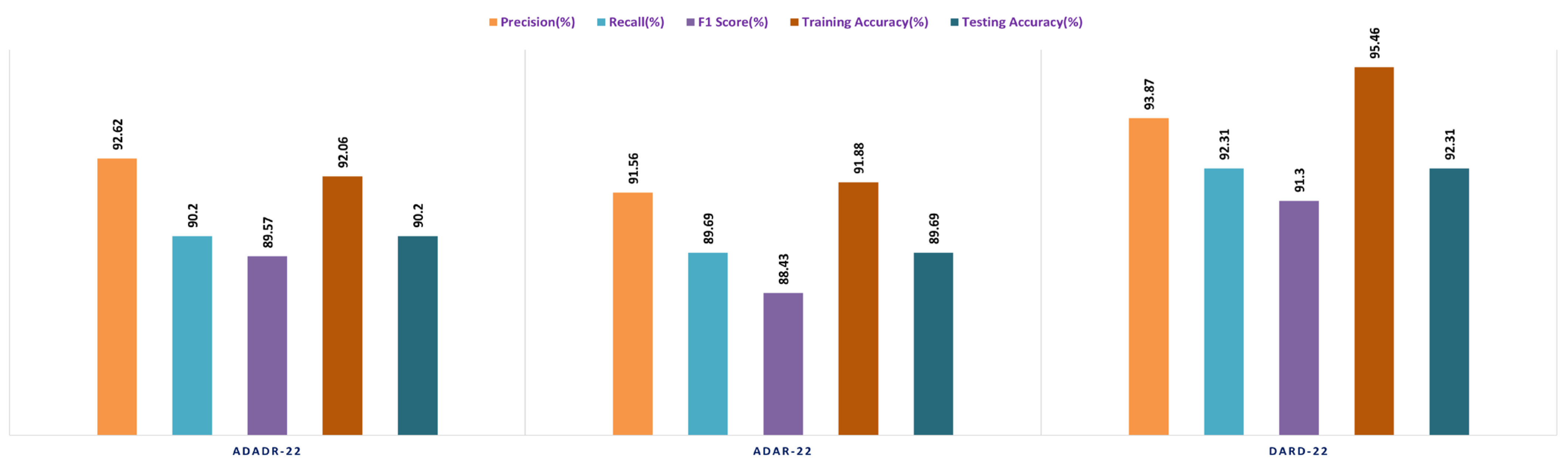
The ensemble fusion CNN model with the DaRD-22 architecture performed the best on the Feature Fusion CKHK-22 dataset, obtaining the highest precision (93.87%), recall (92.33%), and F1 score (91.3%). In addition, it had the maximum accuracy in training (95.46%) and testing (92.31%) compared to the other models. The ADaDR-22 model’s precision, recall, and F1 scores were 92.62%, 90.2%, and 89.5%, respectively. It had a lower training accuracy (92.06%) than the DaRD-22 model but a testing accuracy (90%) that was comparable. The ADaR-22 model performed the worst of the three, with precision, recall, and F1 scores of 91.56%, 89.69%, and 88.43%, respectively. In addition, it had the lowest accuracy during training (91.88%) and testing (89.69%) compared to the other models.
Figure 13,
Figure 14,
Figure 15 and
Figure 16 depict the comprehensive graphical analysis of the results of the second stage. Using ensemble fusion CNNs, the analysis revealed that DaRD-22 provided the highest level of accuracy in the Stage 2 experiment.
4.3. Stage 3 Experimentation: Ensemble Fusion CNNs + Multi-Class SVM
In the third stage of the investigation, the EnsemDeepCADx system integrates the three ensemble CNN models (ADaDR-22, ADaR-22, and DaRD-22) with a multi-class SVM to improve the colorectal cancer detection accuracy of the CKHK-22 dataset. Input for this stage is the feature fusion dataset, which has demonstrated superior performance in Stage 2.
The SVM functions as the final classifier in the EnsemDeepCADx system, receiving as input the fused features from the ensemble CNN models and producing the output. In Stage 2, the accuracy, precision, F1 score, recall, are computed for the combined ensemble CNN-SVM model, and the results are compared with the individual ensemble CNN models. This crucial stage of the experiment seeks to improve the accuracy of the EnsemDeepCADx system by integrating the strengths of ensemble CNNs and SVM for detecting colorectal cancer in the CKHK-22 dataset.
Table 4 presents the results of the Stage 3 experimental investigations of EnsemDeepCADx for ensemble CNNs with multi-class SVM using four datasets.
Employing the original CKHK-22 datasets, the Stage 2 experiment compared the performance of the ensemble fusion CNNs when combined with a multi-class SVM using the original CKHK-22 datasets. Each model’s precision, recall, and F1 scores are displayed in the table above. The analysis revealed that the ADaR-22 model had the greatest precision value of 86.62% whereas the DaRD-22 model had the highest recall and F1 scores of 85.55% and 84.5%, respectively. The DaRD-22 model had the greatest training accuracy, at 88.67%, while the ADaDR-22 model had the highest testing accuracy, at 86.44%.
The ensemble fusion CNNs were combined with multi-class SVM and deployed to the greyscale CKHK-22 datasets in the Stage 2 experiment. The analysis results are presented in the table. DaRD-22 obtained the highest precision score with a value of 82.32%, followed by ADaDR-22 with 81.32% and ADaR-22 with 80.29%. DaRD-22 obtained the maximum recall score with a value of 80.62%, followed by ADaDR-22 with 79.91% and ADaR-22 with 77.79%. DaRD-22 obtained the highest F1 score with a value of 79.57%, followed by ADaDR-22 with 78.83% and ADaR-22% with 76.10%. DaRD-22 achieved the maximum training accuracy with 89.69%, followed by ADaDR-22 with 87.84% and ADaR-22 with 82.30%. DaRD-22 achieved the maximum testing accuracy with a value of 80.62%, followed by ADaDR-22 with 79.91% and ADaR-22 with 77.1%. Overall, DaRD-22 achieved the highest scores for most metrics, indicating that it performed the best among the three models on the greyscale CKHK-22 datasets.
In the Stage 2 experiment with the LBP CKHK-22 dataset, DaRD-22 attained the highest Precision, Recall, F1 Score, Training Accuracy, and Testing Accuracy among the three models, as shown in the table. DaRD-22 achieved a Precision of 69.46%, a Recall of 68.10%, an F1 Score of 67.50%, a Training Accuracy of 70.11%, and a Testing Accuracy of 68.10%. ADaR-22 achieved the lowest Precision, Recall, and F1 Score values, whereas ADaDR-22 achieved the lowest Training and Testing Accuracy values.
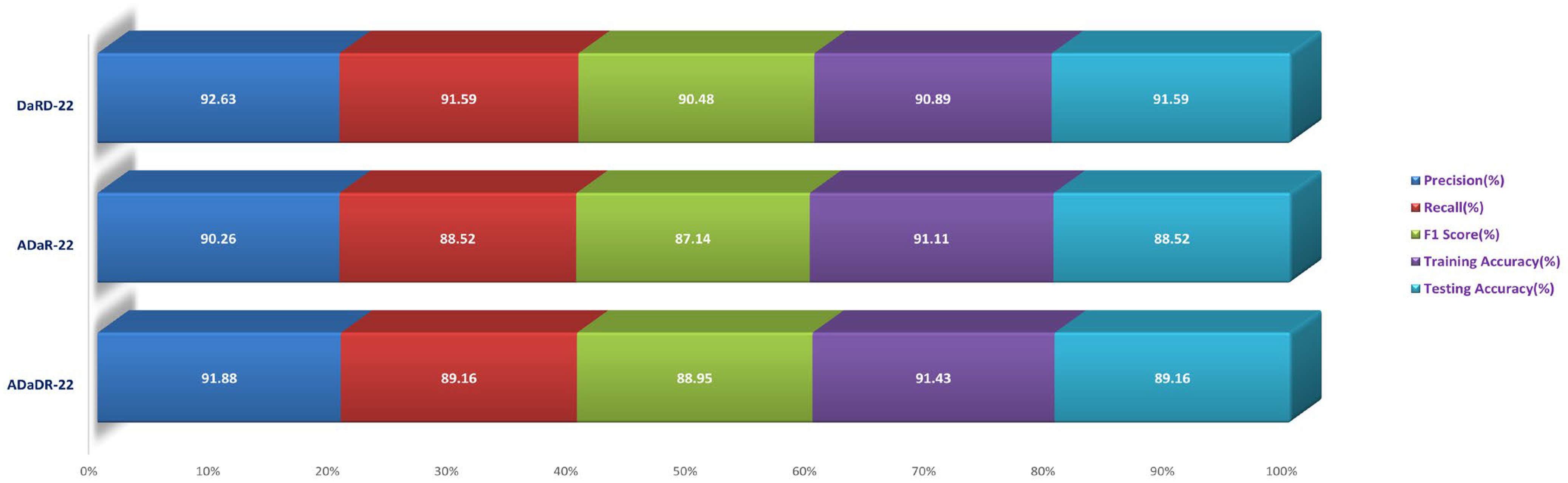
During the Stage 2 section of the experiment, the feature fusion CKHK-22 dataset was used to evaluate and contrast the capabilities of ensemble fusion CNNs in conjunction with multi-class SVM. The percentage of 91.59% was reached by DaRD-22, making it the system with the greatest recall, while the value of 92.63% was attained by DaRD-22, making it the system with the best accuracy. Additionally, DaRD-22 earned the highest F1 score, which was 90.48%. DaRD-22 attained the greatest training accuracy with a value of 90.89%, and it gained the best testing accuracy with a value of 91.59%. Both results were accomplished by DaRD-22.
The results indicate that DaRD-22 ensemble fusion CNNs combined with a multi-class SVM can enhance the performance of the models on the CKHK-22 datasets. Depending on the performance metric of concern, the best-performing model differs.
Figure 17,
Figure 18,
Figure 19 and
Figure 20 depict the comprehensive graphical analysis of the results of the third stage. Using ensemble fusion CNNs with multi-class SVM, the analysis revealed that DaRD-22 provided the highest level of accuracy in the Stage 3 experiment.
4.4. Stage 4 Experimentation: Ensemble Fusion CNNs + BiLSTM + Multi-Class SVM
In the final stage of the experiment, BiLSTM and multi-class SVM were merged with all three ensemble CNNs (ADaDR-22, ADaR-22, and DaRD-22). All four of the CKHK-22 featured datasets (original, greyscale, LBP, and feature fusion) were used in the model’s training and testing, with metrics including accuracy, precision, F1 score, and recall serving as measures of performance. The success of the EnsemDeepCADx system in identifying colorectal cancer utilising ensemble CNNs, BiLSTM, and multi-class SVM was determined by the outcomes of this stage. The results of this stage provided insight into the optimal mix of these models for boosting the system’s precision.
Table 5 presents the results of the Stage 4 experimental investigations of EnsemDeepCADx for ensemble CNNs with BiLSTM and multi-class SVM using four datasets.
In the final phase of the experiment with the original CKHK-22 image datasets, DaRD-22 ensemble fusion CNNs achieved the highest values for precision, recall, F1 score, training accuracy, and testing accuracy, with a precision of 95.31%, a recall of 94.9%, an F1 score of 93.4%, a training accuracy of 98.64%, and a testing accuracy of 95.96%. ADaDR-22 ensemble fusion CNNs attained the lowest values, with a precision of 89.92%, a recall of 93.47%, an F1 score of 86.76%, a training accuracy of 97.74%, and a testing accuracy of 93.47%. ADaR-22 ensemble fusion CNNs achieved 92.12% precision, 91.58% recall, an F1 score of 85.61%, a training accuracy of 96.95%, and a testing accuracy of 91.58%.
The DaRD-22 model achieved the highest precision, recall, and F1 score for the ensemble fusion CNNS + BLSTM + multi-class SVM applied to the greyscale CKHK-22 dataset, with values of 90.46, 88.79, and 87.62, respectively. On the other hand, the ADaR-22 model obtained the lowest values for these metrics, with precision, recall, and F1 score values of 84.92%, 83.09%, and 82.57%, respectively. The DaRD-22 model also obtained the highest training and testing accuracy with values of 95.56% and 88.79%, respectively.
DaRD-22 had the highest ensemble fusion CNNs + BLSTM + multi-class SVM values for the LBP CKHK-22 datasets, with a precision of 75.11%, recall of 73.5%, F1 score of 72.67%, training accuracy of 75.89%, and testing accuracy of 73.5%. ADaDR-22 had the lowest values, with a precision of 70.67%, recall of 69.92%, F1 score of 67.41%, training accuracy of 72.56%, and testing accuracy of 69.92%.
The following is an analysis of the highest and lowest ensemble fusion CNNs + BLSTM + multi-class SVM values for the feature fusion CKHK-22 datasets. DaRD-22 obtained the highest accuracy with a value of 96.98%. This indicates that 96.98% of all predicted positive cases were in fact positive. DaRD-22 obtained the highest recall with a score of 97.12%. This indicates that 97.12% of all actual positive cases were accurately identified as positive. DaRD-22 obtained the greatest F1 score, with a value of 95.98%. This is the harmonic mean of precision and recall, balancing the two metrics. DaRD-22 obtained the maximum training accuracy with a value of 98.72%. This indicates that the model correctly categorised 98.72% of the training dataset. DaRD-22 obtained the greatest testing accuracy with a value of 97.89%. This indicates that the model accurately classified 97.89% of the test dataset. On the other hand, ADaR-22 obtained the lowest values for all metrics. Nonetheless, even the lowest values are comparatively high, indicating that the model performs well in general.
Figure 21,
Figure 22,
Figure 23 and
Figure 24 depict the comprehensive graphical analysis of the results of the third stage. Using ensemble fusion CNNs with BiLSTM and multi-class SVM, the analysis revealed that DaRD-22 provided the highest level of accuracy in the Stage 4 experiment.
The DaRD-22 classifier, an ensemble fusion CNN model with BiLSTM and multi-class SVM classifiers, scored the greatest accuracy across all metrics, with a testing accuracy of 97.89%, according to the findings of experimental investigations conducted on the feature fusion CKHK-22 dataset. The model also performed well in terms of accuracy in identifying positive instances and maintaining a low false positive rate (measured by precision, recall, and F1 score). The excellent 98.72% training accuracy also shows that the model is appropriate for the training data and can generalise to novel, unknown test data with ease. The DaRD-22 model outperformed BiLSTM and multi-class SVM classifiers on the feature fusion CKHK-22 dataset, making it the best model for reliably detecting colorectal cancer in this EnsemDeepCADx system.
Presented in
Table 6 are the performance metrics for ensemble fusion CNN-DarD-22 with BiLSTM and multi-class SVM, utilising the feature fusion CKHK-22 mixed dataset. Each row in the table corresponds to a specific class of polyps or non-polyp regions in the colon, and each column provides a different performance metric for that class.
Precision is the proportion of true positive predictions for a given class out of all positive predictions for that class. In other words, precision measures the proportion of correctly identified instances of a given class out of all instances predicted as that class. The classes with precision above 0.9 are bbps-0-1, bbps-2-3, non-polyps, pylorus, retroflex-stomach, and z-line.
Recall assesses the percentage of true positive predictions for a given class out of all actual instances of that class in the test dataset. In other words, recall measures the proportion of correctly identified instances of a given class out of all actual instances of that class. The classes with recall above 0.9 are bbps-0-1, bbps-2-3, cecum, non-polyps, pylorus, retroflex-stomach, and z-line.
The F1 score is the harmonic mean of precision and recall. It is a single metric that combines precision and recall into one number. The classes with an F1 score above 0.9 are bbps-0-1, bbps-2-3, non-polyps, pylorus, retroflex-stomach, and z-line.
Support refers to the number of test images that belong to a particular class. The classes with the highest support in this dataset are polyps and dyed-lifted-polyps with 2604 and 1803 images, respectively. However, the highest-performing classes based on precision, recall, and F1 score are bbps-0-1, bbps-2-3, non-polyps, pylorus, retroflex-stomach, and z-line.
Overall, the results suggest that the ensemble fusion CNN-DarD-22 using the feature fusion CKHK-22 mixed dataset can accurately identify polyps and non-polyp regions in the colon, with several classes exhibiting high precision, recall, and F1 score. The analysed performance metrics are shown in
Figure 25.
From the foregoing, we may deduce that this classifier’s confusion matrix will contain many true positives and true negatives for the classes with high recall values, and many false negatives for the classes with low recall values.
Figure 25 illustrates the confusion matrix for the DaRD-22 with BiLSTM and multi-class SVM performance of the ensemble fusion CNN on the CKHK-22 dataset. More insight into the classifier’s performance might be gained with the use of a thorough confusion matrix, which would show the real number of true positives, false positives, true negatives, and false negatives for each class. The performance metric recall indicates how many true positive instances were accurately labelled as such by the classifier. The following may be inferred from the table of recall values: it turns out that “bbps-0-1” (0.98), “bbps-2-3” (0.99), “cecum” (0.99), “polyps” (0.82), “pylorus” (1.00), “retroflex-stomach” (0.99), and “z-line” (0.99) had the greatest recall values. These are the categories for which a large percentage of true positives were properly identified by the classifier. Recall values for “dyed-lifted-polyps” (92.2%) and “dyed-resection-margins” (43.3%) were the lowest. These are the categories where the classifier produced a larger number of false negatives because it incorrectly classified a large percentage of true positives.
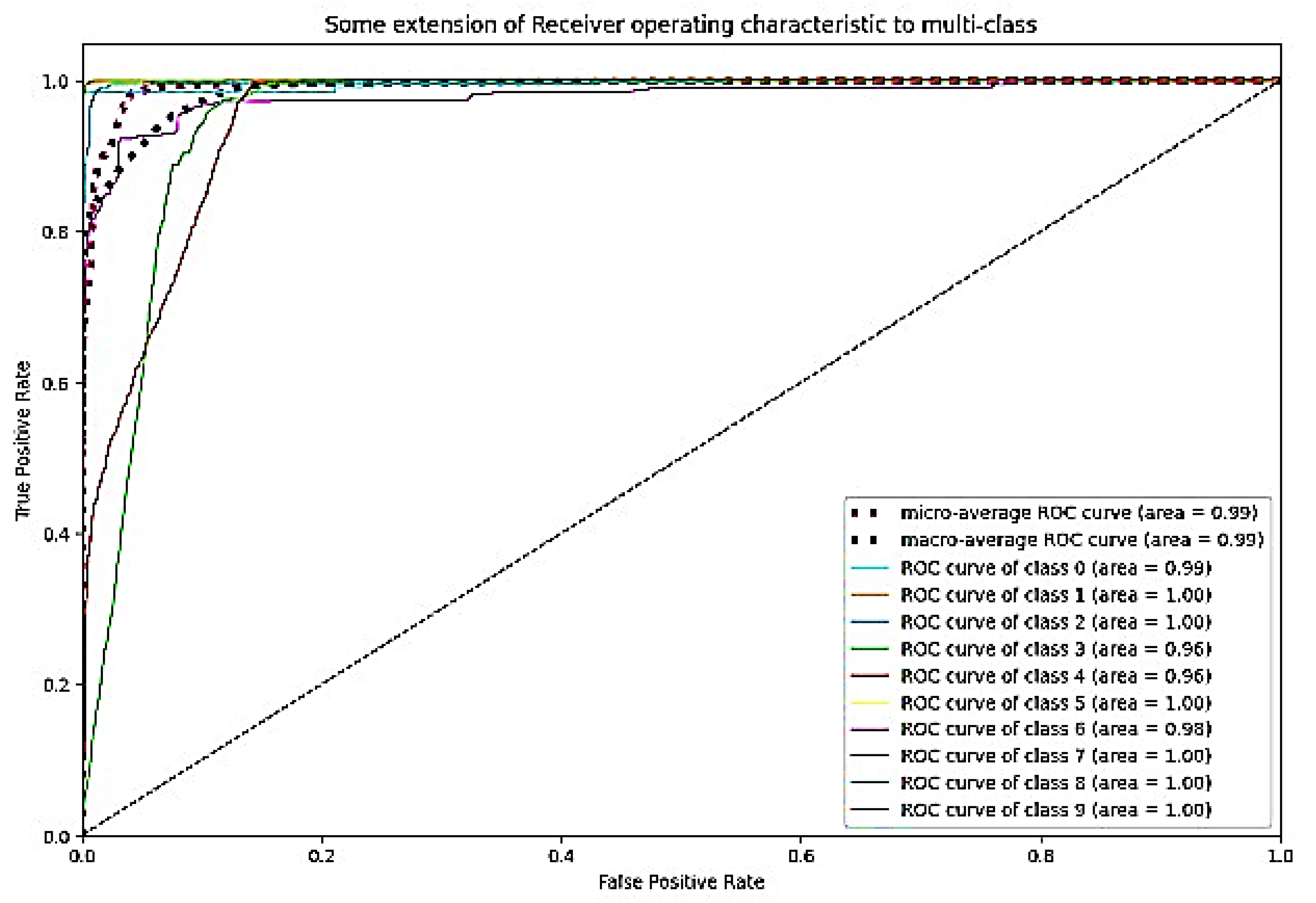
The ROC curve is a graphical representation of a binary classifier system’s performance as its discrimination threshold is altered.
Figure 26 depicts the confusion matrix and
Figure 27 depicts the ROC curve for DaRD-22 using the CKHK-22 feature fusion dataset. The True Positive Rate (TPR) is plotted on the
y-axis and the False Positive Rate (FPR) is plotted on the
x-axis. AUC (Area Under the Curve) is a metric that assesses the classification system’s overall performance. In this instance, the AUC value is 0.9882, indicating that the efficacy of the classifier system is very high. It indicates that the system can effectively differentiate between positive and negative samples. Since the AUC value is close to 1, it can be inferred that there is no misclassification in any class and that the accuracy of all classes is greater than 0.96. The EnsemDeepCADx system is a powerful instrument for detecting and diagnosing colorectal cancer, as evidenced by its AUC of 0.9882 and outstanding accuracy values in all 10 classes.































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}