



Performance Comparison of Object Detection Networks for Shrapnel Identification in Ultrasound Images

Abstract
:1. Introduction
1.1. Overview of Object Detection for Ultrasound Imaging
1.2. Object Detection Architectures
2. Materials and Methods
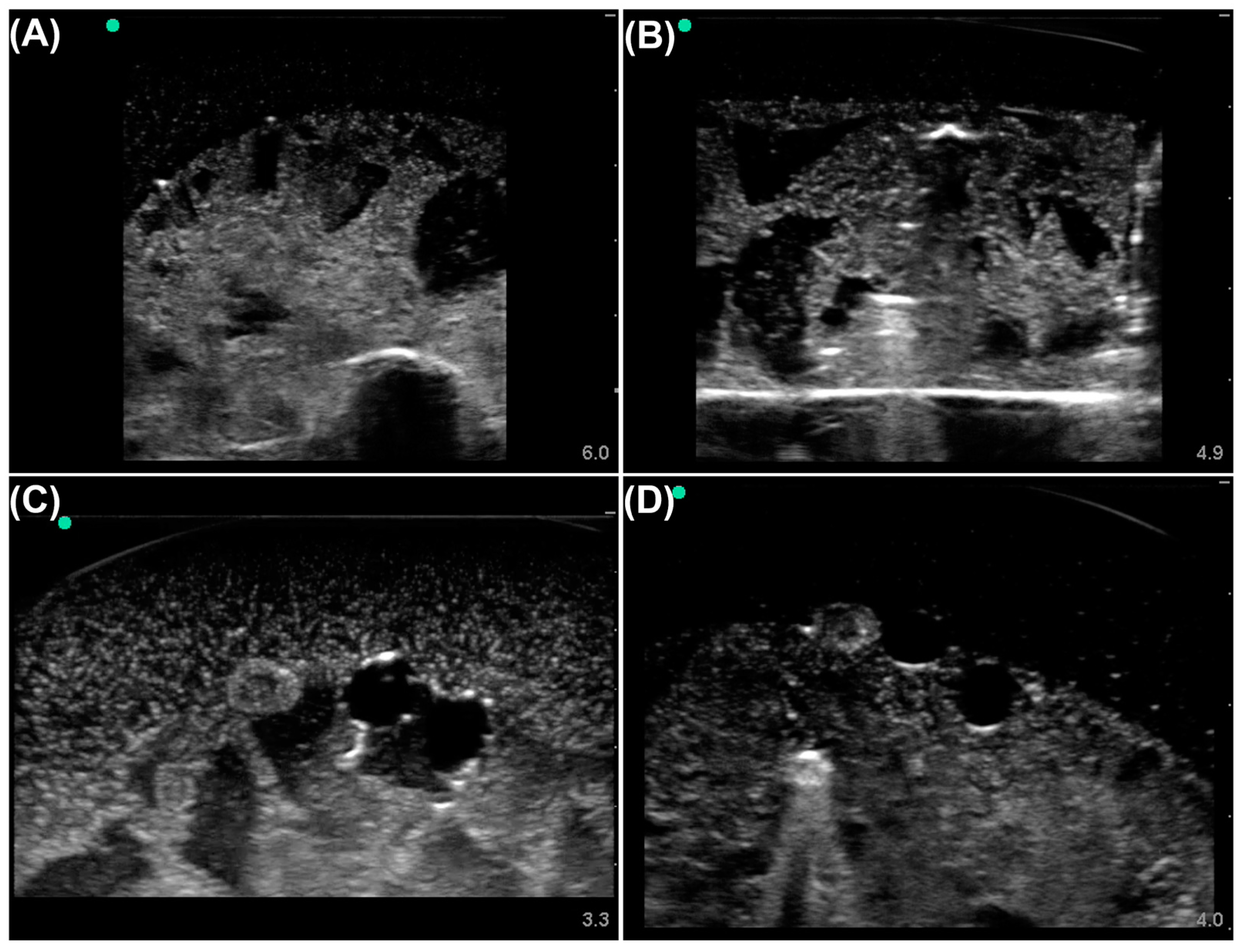
2.1. Dataset Prep
2.2. Object Detection Model Preparation and Training
2.3. Backend Performance Evaluation and Real-Time Testing
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
DoD Disclaimer
References
- Gil-Rodríguez, J.; Pérez de Rojas, J.; Aranda-Laserna, P.; Benavente-Fernández, A.; Martos-Ruiz, M.; Peregrina-Rivas, J.-A.; Guirao-Arrabal, E. Ultrasound Findings of Lung Ultrasonography in COVID-19: A Systematic Review. Eur. J. Radiol. 2022, 148, 110156. [Google Scholar] [CrossRef] [PubMed]
- European Society of Radiology (ESR). The Role of Lung Ultrasound in COVID-19 Disease. Insights Imaging 2021, 12, 81. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Yang, M. The Application of Ultrasound Image in Cancer Diagnosis. J. Healthc. Eng. 2021, 2021, 8619251. [Google Scholar] [CrossRef]
- Zhang, G.; Ye, H.-R.; Sun, Y.; Guo, Z.-Z. Ultrasound Molecular Imaging and Its Applications in Cancer Diagnosis and Therapy. ACS Sens. 2022, 7, 2857–2864. [Google Scholar] [CrossRef] [PubMed]
- Marin, J.; Abo, A.; Doniger, S.; Fischer, J.; Kessler, D.; Levy, J.; Noble, V.; Sivitz, A.; Tsung, J.; Vieira, R.; et al. Point-of-care ultrasonography by pediatric emergency physicians. Ann. Emerg. Med. 2015, 65, 472–478. [Google Scholar] [CrossRef] [Green Version]
- American College of Emergency Physicians Council Resolution on Ultrasound. ACEP News 1990, 9, 1–15.
- Townsend, S.; Lasher, W. The U.S. Army in Multi-Domain Operations 2028; U.S. Army: Fort Belvoir, VA, USA, 2018. [Google Scholar]
- Micucci, M.; Iula, A. Recent Advances in Machine Learning Applied to Ultrasound Imaging. Electronics 2022, 11, 1800. [Google Scholar] [CrossRef]
- Liu, S.; Wang, Y.; Yang, X.; Lei, B.; Liu, L.; Li, S.X.; Ni, D.; Wang, T. Deep Learning in Medical Ultrasound Analysis: A Review. Engineering 2019, 5, 261–275. [Google Scholar] [CrossRef]
- Diaz-Escobar, J.; Ordóñez-Guillén, N.E.; Villarreal-Reyes, S.; Galaviz-Mosqueda, A.; Kober, V.; Rivera-Rodriguez, R.; Rizk, J.E.L. Deep-Learning Based Detection of COVID-19 Using Lung Ultrasound Imagery. PLoS ONE 2021, 16, e0255886. [Google Scholar] [CrossRef]
- Lin, Z.; Li, Z.; Cao, P.; Lin, Y.; Liang, F.; He, J.; Huang, L. Deep Learning for Emergency Ascites Diagnosis Using Ultrasonography Images. J. Appl. Clin. Med. Phys. 2022, 23, e13695. [Google Scholar] [CrossRef]
- Snider, E.J.; Hernandez-Torres, S.I.; Boice, E.N. An Image Classification Deep-Learning Algorithm for Shrapnel Detection from Ultrasound Images. Sci. Rep. 2022, 12, 8427. [Google Scholar] [CrossRef] [PubMed]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A Survey of Modern Deep Learning Based Object Detection Models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, X.; Sahoo, D.; Hoi, S.C. Recent Advances in Deep Learning for Object Detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef] [Green Version]
- Kaur, A.; Singh, Y.; Neeru, N.; Kaur, L.; Singh, A. A Survey on Deep Learning Approaches to Medical Images and a Systematic Look up into Real-Time Object Detection. Arch. Comput. Methods Eng. 2021, 29, 2071–2111. [Google Scholar] [CrossRef]
- Latif, J.; Xiao, C.; Imran, A.; Tu, S. Medical Imaging Using Machine Learning and Deep Learning Algorithms: A Review. In Proceedings of the 2019 2nd International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 30–31 January 2019; IEEE: Piscataway Township, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Cao, Z.; Duan, L.; Yang, G.; Yue, T.; Chen, Q.; Fu, H.; Xu, Y. Breast Tumor Detection in Ultrasound Images Using Deep Learning. In Patch-Based Techniques in Medical Imaging; Wu, G., Munsell, B.C., Zhan, Y., Bai, W., Sanroma, G., Coupé, P., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 121–128. [Google Scholar]
- Chiang, T.-C.; Huang, Y.-S.; Chen, R.-T.; Huang, C.-S.; Chang, R.-F. Tumor Detection in Automated Breast Ultrasound Using 3-D CNN and Prioritized Candidate Aggregation. IEEE Trans. Med. Imaging 2019, 38, 240–249. [Google Scholar] [CrossRef]
- Iriani Sapitri, A.; Nurmaini, S.; Naufal Rachmatullah, M.; Tutuko, B.; Darmawahyuni, A.; Firdaus, F.; Rini, D.P.; Islami, A. Deep Learning-Based Real Time Detection for Cardiac Objects with Fetal Ultrasound Video. Inform. Med. Unlocked 2023, 36, 101150. [Google Scholar] [CrossRef]
- Tang, Y.; Chen, H.; Qian, L.; Ge, S.; Zhang, M.; Zheng, R. Detection of Spine Curve and Vertebral Level on Ultrasound Images Using DETR. In Proceedings of the 2022 IEEE International Ultrasonics Symposium (IUS), Venice, Italy, 10–13 October 2022; pp. 1–4. [Google Scholar]
- Brattain, L.J.; Pierce, T.T.; Gjesteby, L.A.; Johnson, M.R.; DeLosa, N.D.; Werblin, J.S.; Gupta, J.F.; Ozturk, A.; Wang, X.; Li, Q.; et al. AI-Enabled, Ultrasound-Guided Handheld Robotic Device for Femoral Vascular Access. Biosensors 2021, 11, 522. [Google Scholar] [CrossRef]
- Smistad, E.; Løvstakken, L. Vessel Detection in Ultrasound Images Using Deep Convolutional Neural Networks. In Proceedings of the Deep Learning and Data Labeling for Medical Applications: First International Workshop, LABELS 2016, and Second International Workshop, DLMIA 2016, Held in Conjunction with MICCAI 2016, Athens, Greece, 21 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 30–38. [Google Scholar]
- Zeng, Y.; Wang, H.; Sha, M.; Lin, G.; Long, Y.; Liu, Y. Object Detection Algorithm of Vein Vessels in B-Mode Ultrasound Images. In Proceedings of the 2022 7th International Conference on Control and Robotics Engineering (ICCRE), Beijing, China, 15–17 April 2022; pp. 180–183. [Google Scholar]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo Algorithm Developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. Available online: https://arxiv.org/abs/1506.02640v5 (accessed on 20 March 2023).
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. Available online: https://arxiv.org/abs/2207.02696v1 (accessed on 20 March 2023).
- Sun, K.X.; Cong, C. Research On Chest Abnormality Detection Based On Improved YOLOv7 Algorithm. In Proceedings of the 2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Las Vegas, NV, USA, 6–8 December 2022; pp. 3884–3886. [Google Scholar]
- Bayram, A.F.; Gurkan, C.; Budak, A.; Karataş, H. A Detection and Prediction Model Based on Deep Learning Assisted by Explainable Artificial Intelligence for Kidney Diseases. EJOSAT 2022, 40, 67–74. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar] [CrossRef]
- Yang, B.; Wang, L.; Wong, D.F.; Shi, S.; Tu, Z. Context-Aware Self-Attention Networks for Natural Language Processing. Neurocomputing 2021, 458, 157–169. [Google Scholar] [CrossRef]
- Park, N.; Kim, S. How Do Vision Transformers Work? arXiv 2022, arXiv:2202.06709. [Google Scholar]
- Zhou, D.; Kang, B.; Jin, X.; Yang, L.; Lian, X.; Jiang, Z.; Hou, Q.; Feng, J. Deepvit: Towards Deeper Vision Transformer. arXiv 2021, arXiv:2103.11886. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing Convolutions to Vision Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 22–31. [Google Scholar]
- Yuan, K.; Guo, S.; Liu, Z.; Zhou, A.; Yu, F.; Wu, W. Incorporating Convolution Designs into Visual Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 579–588. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Hatamizadeh, A.; Tang, Y.; Nath, V.; Yang, D.; Myronenko, A.; Landman, B.; Roth, H.R.; Xu, D. Unetr: Transformers for 3d Medical Image Segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 574–584. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2020, arXiv:1905.11946. [Google Scholar]
- Du, R.; Chen, Y.; Li, T.; Shi, L.; Fei, Z.; Li, Y. Discrimination of Breast Cancer Based on Ultrasound Images and Convolutional Neural Network. J. Oncol. 2022, 2022, 7733583. [Google Scholar] [CrossRef]
- Hernandez-Torres, S.I.; Boice, E.N.; Snider, E.J. Using an Ultrasound Tissue Phantom Model for Hybrid Training of Deep Learning Models for Shrapnel Detection. J. Imaging 2022, 8, 270. [Google Scholar] [CrossRef]
- Padilla, R.; Netto, S.L.; da Silva, E.A.B. A Survey on Performance Metrics for Object-Detection Algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Rio de Janeiro, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar]
- Medak, D.; Posilović, L.; Subašić, M.; Budimir, M.; Lončarić, S. Automated Defect Detection From Ultrasonic Images Using Deep Learning. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 2021, 68, 3126–3134. [Google Scholar] [CrossRef]
- Snider, E.J.; Hernandez-Torres, S.I.; Hennessey, R. Using Ultrasound Image Augmentation and Ensemble Predictions to Prevent Machine-Learning Model Overfitting. Diagnostics 2023, 13, 417. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Model | Backbone Architecture | Parameters | COCO mAP@50 |
|---|---|---|---|
| YOLOv3 | Darknet-53 | 65.2 M | 57.9 |
| YOLOv7 | E-ELAN (Extended Efficient Layer Aggregation Network) computational blocks | 36.9 M | 69.7 |
| YOLOv7tiny | E-ELAN computational blocks | 6.2 M | 56.7 |
| DETR-R50 | ResNet-50 | 41 M | 42.04 |
| EfficientDet-D2 | EfficientNet-B2 | 8.1 M | 62.7 |
| Model | [email protected] | [email protected] | [email protected]:0.95 | Inference Time (ms/Image) |
|---|---|---|---|---|
| YOLOv3 | 0.889 | 0.00013 | 0.490 | 9.72 |
| YOLOv7 | 0.921 | 0.00189 | 0.567 | 8.22 |
| YOLOv7tiny | 0.957 | 0.00211 | 0.615 | 5.68 |
| DETR | 0.643 | 0.003 | 0.423 | 34.13 |
| EfficientDet-D2 | 0.909 | 0.003 | 0.562 | 22.74 |
| Model | [email protected] | [email protected]:0.95 | ||
|---|---|---|---|---|
| Training Result | Testing to Training Ratio | Training Result | Testing to Training Ratio | |
| YOLOv3 | 0.978 | 0.909 | 0.581 | 0.843 |
| YOLOv7 | 0.994 | 0.927 | 0.733 | 0.774 |
| YOLOv7tiny | 0.990 | 0.967 | 0.721 | 0.853 |
| DETR | 0.742 | 0.867 | 0.627 | 0.675 |
| EfficientDet-D2 | 0.988 | 0.920 | 0.725 | 0.775 |
| Category | Count | Recall | Precision | AP:0.50 |
|---|---|---|---|---|
| Vein | 1080 | 0.955 | 0.963 | 0.981 |
| Artery | 1115 | 0.981 | 0.985 | 0.993 |
| Nerve | 1113 | 0.954 | 0.949 | 0.937 |
| Shrapnel | 1378 | 0.819 | 0.819 | 0.858 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hernandez-Torres, S.I.; Hennessey, R.P.; Snider, E.J. Performance Comparison of Object Detection Networks for Shrapnel Identification in Ultrasound Images. Bioengineering 2023, 10, 807. https://doi.org/10.3390/bioengineering10070807
Hernandez-Torres SI, Hennessey RP, Snider EJ. Performance Comparison of Object Detection Networks for Shrapnel Identification in Ultrasound Images. Bioengineering. 2023; 10(7):807. https://doi.org/10.3390/bioengineering10070807
Chicago/Turabian StyleHernandez-Torres, Sofia I., Ryan P. Hennessey, and Eric J. Snider. 2023. "Performance Comparison of Object Detection Networks for Shrapnel Identification in Ultrasound Images" Bioengineering 10, no. 7: 807. https://doi.org/10.3390/bioengineering10070807