1. Introduction
Sleep stages are the most-precise way to separate wakefulness from the sleep state. Physiologic and pathologic events can be identified and studied through examining the stages of sleep or sleep stages. Certain health insurances require that wakefulness is separated from the sleep state using an electroencephalogram (EEG) in order for a sleep study to be conducted.
An EEG uses electrodes placed on the head to detect electric potentials in the brain. The difference between the electric potentials of two electrode positions, called an EEG channel or channel, are recorded in regular intervals to produce brainwaves. One electrode is the active electrode, while the other is the reference electrode [
1]. The electrode positions are well-defined by the International 10/20 system [
1,
2,
3]. The EEG channels that are best to use were standardized originally by Rechtscheffen and Kales [
4], commonly known as the R&K standard. The American Academy of Sleep Medicine (AASM) maintains and updates the R&K standard today.
Sleep stages are typically identified with a combination of parameters known as a polysomnographic record (PSG). These parameters include, but are not limited to, electroencephalogram (EEG) derivations, electrooculogram (EOG) derivations, and a chin electromyogram (EMG) derivations [
1]. Elements from all three are used to identify sleep stages [
1]. An EEG monitors brainwaves. An EOG monitors eye movements. An EMG monitors muscle movements. EEGs, EOGs, and EMGs all can use electrodes placed on the head and face.
An alternative to a PSG is an at-home study. There can be many electrodes and channels used in a PSG. The AASM recommends that eight electrode positions creating six channels be used for an EEG alone [
1]. Using this many channels and the variety of parameters for the PSG require special training to use, special training to interpret, expensive equipment, and, likely, a lab. Some at-home studies use a single-channel EEG, requiring very little training to use, less-expensive equipment, and no lab. The at-home study still requires special training to interpret.
Automated sleep staging can be accomplished with a combination of parameters from a PSG [
5,
6,
7,
8,
9] or a single-channel EEG [
10,
11,
12,
13]. Hong et al. claims support vector machines (SVMs) and artificial neural networks (ANN) are the “tool of choice” for any data that are classified a priori [
14]. Ebrahimi et al. achieved 93% accuracy using the wavelet decomposition of a single-channel EEG and a neural network [
11]. Poudel et al. was able to compress, denoise, and classify electrocardiograms (ECGs) using discrete wavelet transforms (DWTs) and convolutional neural networks (CNNs) [
15]. Kurt et al. achieved 97–98% accuracy using the wavelet decomposition of the EEG, EOG, and chin-EMG [
8]. Li et al. enhanced sleep stage N1 classification from 41.5% to 55.65% using preprocessing signals with wavelet threshold denoising (WTD) and wavelet packet transform (WPT) [
16]. ElMoaqet et al. achieved an average per-class accuracy of 91.2%, a sensitivity of 77%, a specificity of 94.1%, and a precision of 75.9% preprocessing signals with a wavelet transform and a bidirectional long short-term memory (BiLSTM) [
17]. Fu et al. achieved an f1 score of 81.79 preprocessing data using the wavelet threshold method and a bidirectional recurrent neural network [
18].
In order to automate sleep staging with an at-home study, the wavelet decomposition of a single-channel EEG is used as a preprocessing step to a CNN to a bidirectional gated recurrent unit (BiGRU) model. Alvarez et al. [
13] listed the following algorithms, among others, in order of highest accuracy for sleep staging: ANN, support vector machine (SVM), hidden Markov model, and discriminant analysis. Lotte et al. [
19] scored many algorithms for classification in an EEG-based brain–computer interface including linear discriminant analysis, support vector machine (SVM), ANN multilayer perceptron, other ANNs, Bayes quadratic, the hidden Markov model, k-nearest neighbors, the Mahalanobis distance, and combinations. Even though Lotte et al. [
19] concluded that the SVM would be the best for the EEG-based brain–computer interface, they also stated that neural networks are the most-used category of classifiers. Seeing that both Alvarez et al. and Lotte et al. put significance on SVMs and hidden Markov models, these two algorithms may be tested in the future.
There are many time–frequency signal analysis representations that could be tested. The Gabor transform, short-time Fourier transform, Wigner distributions, and many others could be tested with future studies. This study used the multilevel discrete wavelet transform.
2. Methods
2.1. Data
This study used the “Sleep Recording and Hypnograms in European Data Format (EDF)” dataset or “The Sleep-EDF Database [Expanded]” from physionet.org [
20]. The portion of the database used was from a study on healthy patients from 1987–1991. There were 20 patients available. There were 10 males and 10 females ranging from 25–34 years old.
Each patient had two relevant files: a polysomnogram (PSG) recording in EDF format and a hypnogram of annotations in EDF+. EDF is a standard format for exchanging EEG recordings [
21]. EDF+ has all the capabilities of EDF and the ability to contain annotations [
21]. The PSG recording included an EEG from the Fpz-Cz and Pz-Oz electrode locations, an EOG (horizontal), a submental chine EMG, an event marker, an oral–nasal respiration, and rectal body temperature. The hypnogram is an annotation of sleep patterns. The annotations included W for wakefulness, R for REM, 1 for Stage 1, 2 for Stage 2, 3 for Stage 3, 4 for Stage 4, M for movement time and ? for not scored. Once the first annotation was reached, the rest of the annotations were 30 s apart, creating the 30 s epochs.
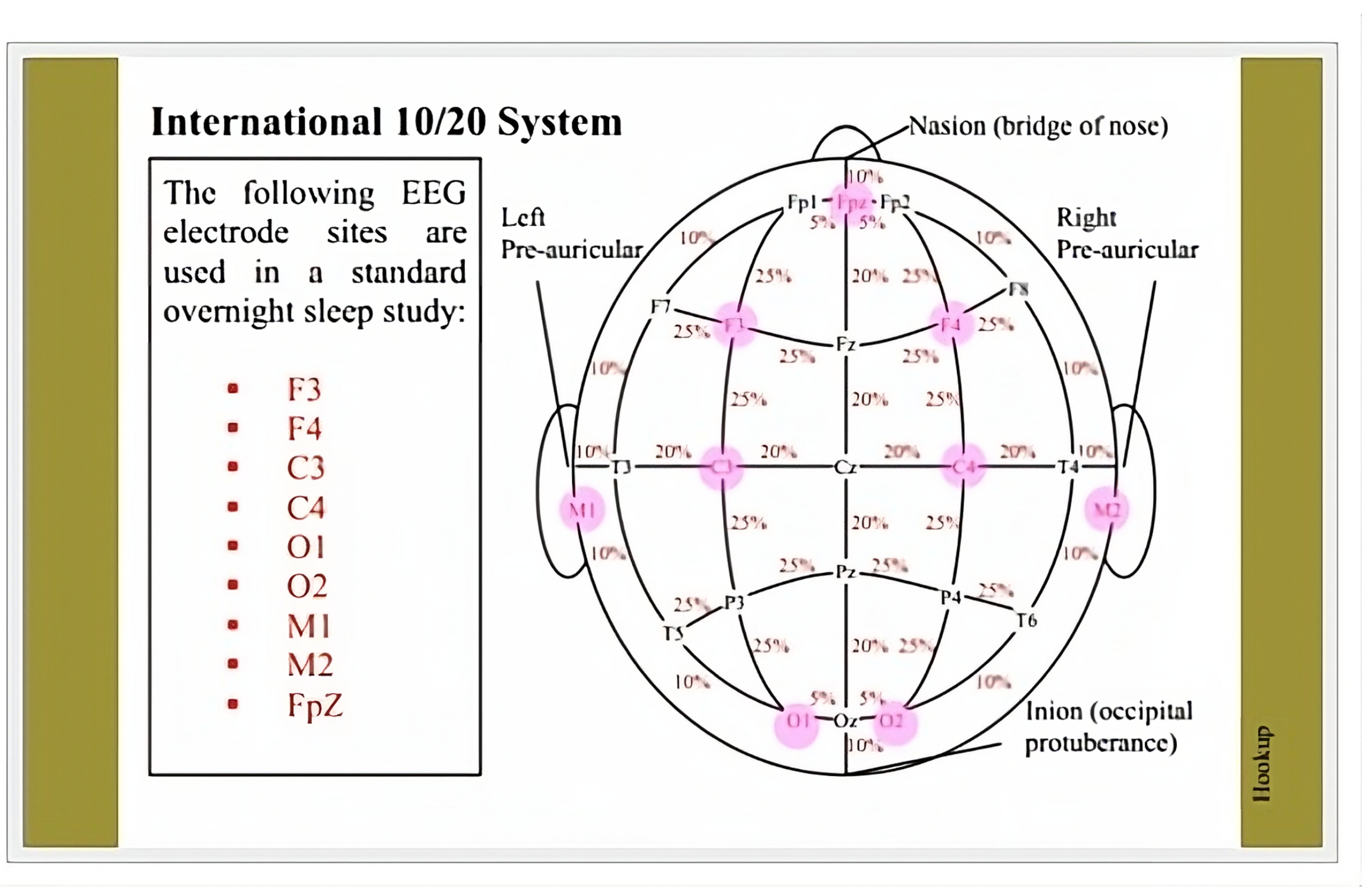
The international 10/20 system uses labels with letters and numbers to identify the different electrode positions on the head, as referenced in
Figure 1. The letters identify the brain lobe that the electrode is over, as identified in
Table 1. The numbers identify the position in the direction going from one ear to the other. To find each position, a technician begins at a starting position and moves around the head in percentages [
2,
3].
Different electrode positions and channels detect different brainwaves, activities, and events.
Table 2 lists some of the brainwaves, activities, and events and which lobe position or channel detects them. V-waves, K-complexes, spindles, sawtooth waves, and Alpha waves are all at least adequate in the frontal and central lobes of the brain. This is why we chose the Fpz-Cz channel.
Special software is required to read the EDF and EDF+ files. EDFbrowser is a free EDF and EDF+ reader, which can export the contents to a text file. All the contents of the PSG and hypnogram file were exported to a text file with the option to have time in seconds from the first recording.
The PSG and hypnogram text files were imported into a custom python 3 script. The python 3 script, epochs.py, uses the pywavelets package to complete a wavelet decomposition of any suggested level. The output file contains the annotation and decomposition of each epoch per line unless the annotation is for movement time or not scored. Movement time and not scored epochs are skipped. All the awake epochs except the last one are removed prior to the first epoch that is not a wake epoch. The count of each annotation per file is printed to standard out.
A focus of this study was meaningful interpretable information. We focused on 1 sleep stage at a time to minimize confusion in interpretability. We focused on REM sleep because of its relationship with degenerative brain disease [
22,
23]. All epochs were labeled either REM or non-REM.
2.2. Wavelet Decomposition
The EEG had a recording every 10 ms. There were 3000 recordings per epoch. This implies that the maximum decomposition level is 8. Each decomposition level produced a different number of coefficients, as listed in
Table 3.
During the decomposition process, the wavelet functions were convolved with the signal at different scales and positions, resulting in a set of coefficients that represent the contribution of each wavelet function to the signal at each scale and position. The coefficients at each scale represent a different frequency band of the signal. After each convolution, the resulting coefficients are downsampled, which means that the number of samples is reduced by a factor of two by discarding redundant samples. The sampling rate after each level of decomposition can be calculated using the following formula, where the original signal has a sample rate of
and
n is the level of decomposition.
The resulting sample rates are matched to the EEG frequencies in
Table 4.
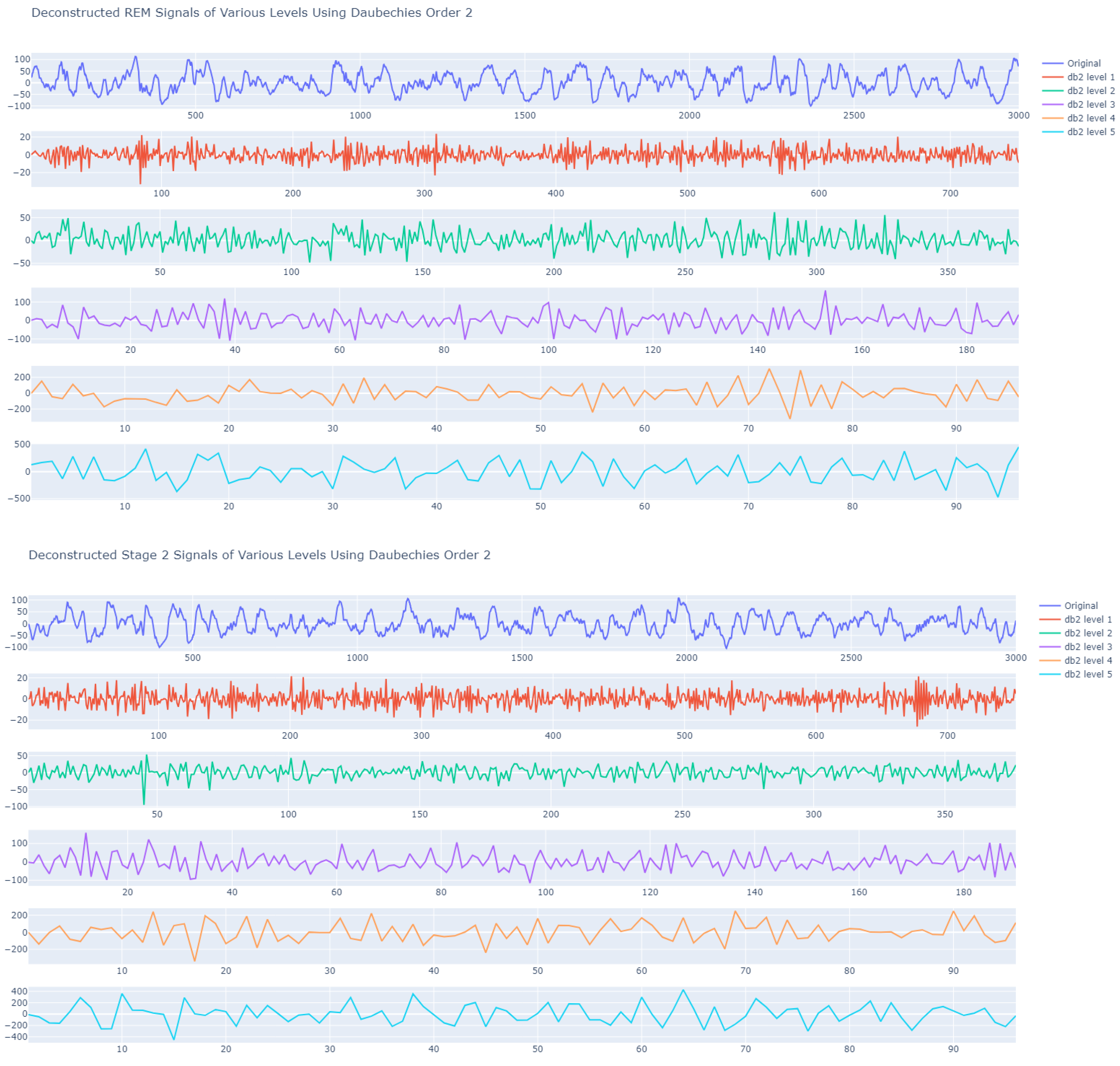
The reconstructed signal after each of the five DWT levels on a 30 s epoch sample is visualized in
Figure 2.
2.3. Model
Each of these reconstructed signals was used as the input to a CNN. The hyperparameters of the neural network were tested using a custom hyperparameter random search. The random search was divided into 4 steps: preprocessing/training parameters, the candidate builder, the model builder, and the model trainer/tester. These were managed with the random search python script.
2.3.1. Preprocessing/Training Parameters
The random search starts building a model by defining a few parameters based on the preprocessing of the data and the training of the model. The preprocessing parameters included the number and set of input files, the normalization standard deviation and mean, the mother wavelet, the decomposition level, and the expected frequency band. The training parameters included the number of cross-validation folds, the validation split percentage, the max number of training epochs, and the batch size. The following is a sample of the preprocessing and training parameters.
| dataFiles: | input152.csv,input042.csv |
| cvFolds: | 10 |
| validation_split: | 0.1 |
| epoch: | 100 |
| batchSize: | 381 |
| normSTD: | 19.476044983423417 |
| normMean: | 0.017218097667286797 |
| mother wavelet: | db2 |
| decomp level: | 5 |
| frequency band: | Delta |
The data files were preprocessed into 30 s epochs with labels. All the movement time was removed. All wake stages except the last one before the first stage that was not wake were removed. The files use the following naming format with the patient number in 2 digits (PP) and the night number in 1 digit (n).
The other preprocessing arguments were the normalization standard deviation (normSTD), the normalization mean (normMean), the mother wavelet used in the multilevel discrete wavelet transform (mother wavelet), the decomposition level used in the multilevel discrete wavelet transform (decomp level), and the frequency band being represented by this CNN. The normalization process was calculated across the entire dataset in the dataFiles parameter. The mother wavelet was manually chosen.
The training arguments included the batch size of each epoch (batchSize), the maximum number of epochs for training (epoch), the number of cross-validation folds (cvFolds), and the validation split percentage in decimals (validation_split). The batch size was calculated to be the entire training dataset given the record count in the dataFiles (R), the number of cross-validation folds (C), and the validation split (V) with the following formula. The best epoch size was found through testing. The validation split and cross-validation folds were chosen as a baseline for to show the generalization.
2.3.2. The Candidate Builder
The candidate builder creates a json structure Listing 1 with all the necessary information to build a model. Each CNN candidate is expected to have a CNN layer followed by a collection of dense layers. Hyperparameters specific to the CNN include the number of filters (defaulted to 5 or 10) and the kernel size (defaulted to 3, 5, 10, 20, or 66). The number of dense layers and the number of nodes in each layer is a hyperparameter. The activation function, kernel initializers, bias initializers, and optimizers are also all hyperparameters. The following is an example candidate in JSON structure.
| Listing 1. A sample JSON structure created by the candidate builder and read by the model builder. |
![Bioengineering 10 01074 i001]() |
2.3.3. The Model Builder
The model builder reads the json structure Listing 1 and creates a Tensorflow Keras model. A sample CNN model is shown in
Figure 3.
2.3.4. The Model Trainer/Tester
The model trainer/tester trains the model, tests the model, and saves all relevant data. The stopping condition is always based on the validation loss. There is an option to explore the models with a tensor board. Each cross-validation training and test set was created using a the Scikit-Learn StratifiedKFold function. Each training set was trained using the batch size, validation percentage, and maximum number of epochs parameters. This training was allowed to save a large collection of metrics including all the fit history, a plot of the loss versus validation loss, and a plot of the area under the ROC curve versus the validation area under the ROC curve. The fit history can include the accuracy, precision, recall, f1 score, and area under the ROC curve. Each test set was then used to obtain a collection of metrics, which was always saved. The test set collection of metrics included true positives, false negatives, false positives, true negatives, true positives, the accuracy, the sensitivity, the specificity, the recall, the precision, the f1 score, and the last loss calculated in the fit history.
2.4. Filter Comparisons: The Frequency Band Wavelet Model
Once all the models were trained, the CNN filters were extracted and examined for interpretability. Each frequency band representative model trained on the data decomposed by each mother wavelet (the frequency band wavelet model) produced a different set of filters in each cross-validation step. The filters extracted were the filters from the first cross-validation step with the highest f1 score for each frequency band wavelet model. Two methods of comparison were used: visual comparison and Spearman rank correlation.
The visual comparison was intended to see if there was any relationship with known clinical markers provided by the AASM. The clinical markers included, but were not limited to k-complexes, sleep spindles, and slow wave activity. K-complexes are sharp negative EEG waves that occur during N2 sleep in response to external stimuli. The presence of K-complexes can be used as a marker of sleep depth and stability. Sleep spindles are brief bursts of EEG activity in the frequency range of 11–16 Hz that occur during N2 sleep. The presence and density of sleep spindles can be used as a marker of sleep quality. Slow wave activity (SWA) is EEG activity in the frequency range of 0.5–4 Hz that occurs during N3 sleep. The amount of SWA is an important marker of sleep quality, with higher levels of SWA indicating deeper and more-restorative sleep.
The Spearman rank correlation is used as a first step numerical analysis of filters. The assumption is that a filter can be found by every wavelet model. Spearman’s rank correlation is calculated for the filters from each extracted frequency band wavelet model against each of the other extracted filters for each wavelet model associated with the same frequency band. For example, the Theta coiflet 4 model filters were compared against all the other models representing the Theta frequency band. There are 5 or 10 filters for each model. An example single comparison would be the 1st filter of the Theta coiflet 4 model against the 10th filter of the Theta Haar model.
Spearman’s rank coefficient was then used to find filters that were found by other training. A formula was used to find the filters with the most and highest correlations. The formula uses the 95th percentile of all the Spearman’s rank coefficients as a threshold, the filter threshold. The top 5 filters with the most Spearman’s rank coefficients greater than the filter threshold were found to be the most-relevant filters.
3. Results
There are tens of gigabytes of results that are available for review in a result set. Things such as the exact model definition, the training parameters, and the results of each training can be found in the result set. The following is a collection of sample and high-priority results. The wavelet model with the highest f1 score is coiflet 4. The examples are primarily based on that. The results described below include: the training parameters, the fit history with the validation of a single training, the cross-validation results of a single training, the average cross-validation results for all wavelet models, a plot of filters from the coiflet 4 model and none model, the plot of of the top five correlated filters from each frequency band, and a description of those comparisons.
3.1. The Model
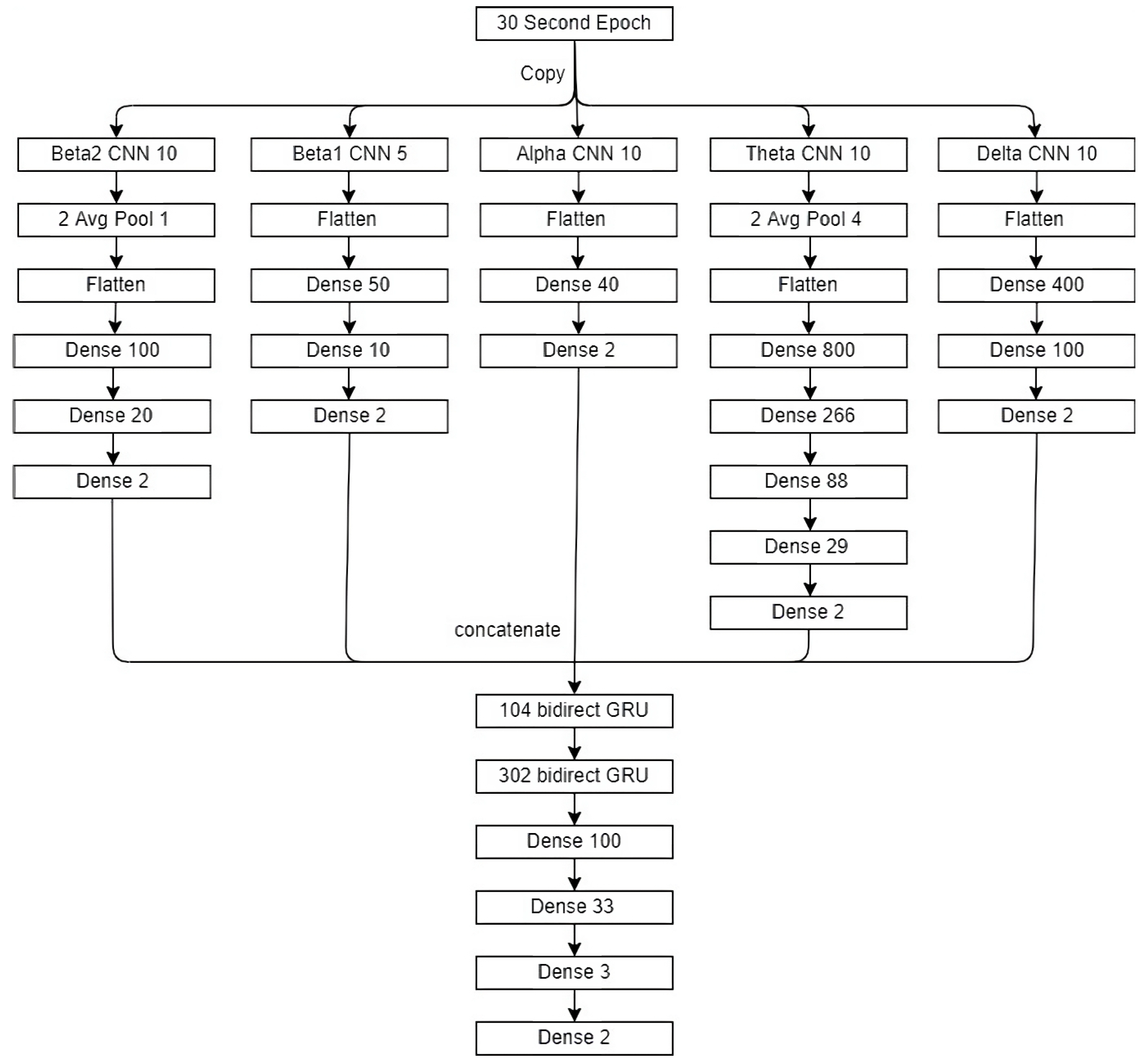
The model used is a variation on the most-common models, the CNN to the RNN models [
24,
25,
26,
27,
28]. The model in
Figure 4 consists of a convolution part and a recurrent or a memory part. The input data are three epochs: a pretarget epoch, a target epoch, and a post-target epoch. Each of the three epochs is fed through wavelet decomposition based on the five frequency bands. The decomposed signal based on each frequency band from each epoch is input for the CNN model. The output from all frequency bands and epochs is concatenated. There are outputs from 15 datasets fed through the CNN model (five frequency bands for each of the three models). The concatenated output is input to the BiGRU model. The resulting model is represented in
Figure 4.
The convolutional part consisted of five CNNs. The GACNN model [
29] found that the most information can be extracted from an EEG signal using four different filter sizes for each CNN. This model adds an additional CNN with a different filter size. There is 1 CNN for each of the Delta, Theta, and Alpha EEG bands and 2 CNNs for the beta EEG band for a total of 5 CNNs. Each CNN has a filter size that allows the frequency of the filter to fit within the specified frequency band, as described in
Table 5. The beta EEG band spans the largest frequency and is at the boundary of the sampling rate, which can lead to noise in the signal. Splitting the beta EEG into 2 CNN filter sizes is an attempt to separate out the noise and extract more-interpretable information.
Each CNN was trained independently on the 30 s epochs to score REM and not REM. Each CNN was associated with a different frequency range in an EEG described in
Table 5. Each CNN had either 5 or 10 filters. The pooling layers pool size is on the left and the factor by which to downscale for strides is on the right in
Figure 4. In each CNN, the same activation, weight initializer, and bias initializer are used on each layer except the final layer, which always uses softmax. The activation function is always tanh. The weight initializer and bias initializer is described in
Table 5.
The output of the five CNNs are concatenated without any adjustment. A new CNN dataset is created with each record consisting of three epochs of the concatenated output of the CNNs. Each record is labeled with the middle or current epoch. This duplicates the pre- and post-epochs used to score the current epoch by technicians.
The RNN has 2 layers of bidirectional gated recurrent unit (GRU) cells, 3 fully connected layers, and the final softmax layer. The input to the first GRU is the new CNN dataset. As can be seen in
Figure 4, the first GRU layer outputs 104 dimensions and the second 302 dimensions. All the other parameters were set to the default Keras parameters. No optimization was required.
3.1.1. Training Parameters
The first part of the model completed through the random search is the model for the Delta frequency band. The preprocessing and training arguments are as follows:
| dataFiles: | input152.csv,input042.csv,input171.csv,input161.csv, |
| input091.csv,input002.csv,input142.csv,input031.csv, |
| input082.csv,input151.csv,input101.csv,input032.csv |
| cvFolds: | 10 |
| validation_split: | 0.1 |
| epoch: | 100 |
| batchSize: | 2054 |
| normSTD: | 20.366845241085922 |
| normMean: | −0.4573919127663568 |
| mother wavelet: | coif4 |
| decomp level: | 5 |
| frequency band: | Delta |
3.1.2. Fit History Data
The training then creates the following “fit history”
Table 6 and
Table 7.
The fit history for the training data showed that the model prediction was 100% on all metrics while the loss started low and steadily decreased. The fit history for the validation started with all metrics in the 96% range and moving up, while the loss started low and steadily decreased. This suggested that the model was accurate with the ability to generalize.
3.1.3. Fit History Plots
This fit history was then plotted in two different plots: loss vs. validation loss and auc_roc vs. validation auc_roc. See
Figure 5.
This visualization of the fit history is a simpler way to confirm that this model was a good fit for these data.
3.1.4. Cross-Validation
After the training, the cross-validation test data were used to create a different set of metrics. These cross-validation data are aggregated across all cross-validation folds in
Table 8.
Table 8 identifies the true positives, false positives, false negatives, and true negatives. Through 6 of the 10 cross-validation fold, there were 0 false positives and false negatives.
Table 8 identifies that these six folds were 100% accurate and the average accuracy was 97%, despite that the f1 score became as low as 11% and the average f1 score was 85%. This was not as good as the other models, and the other parts of this complete model need to be added to improve the model.
3.1.5. Average Cross-Validation
The same model was tested with wavelet decomposition using 28 different mother wavelets and 1 without any wavelet decomposition. All the results produced 98% accuracy or higher accuracy with an f1 score between 93% and 94%.
Table 9 and
Table 10 show the average cross-validation results from all 22 mother wavelets. The coif4 mother wavelet had the highest f1 score of 0.9456. The db5 mother wavelet had the lowest f1 score of 0.9374. The model without any wavelet decomposition was closer to the lowest f1 score of 0.9392, but notably not the lowest.
Table 11 shows the comparison to the other models. The models used for comparison used the same dataset. These models attempted to score all stages of sleep, and while this could be the end goal, focusing on one stage of sleep can help the model be more explainable. In addition, other stages of sleep can have very specific clinical markers, which can be easily identified with simpler methods.
3.1.6. CNN Filters
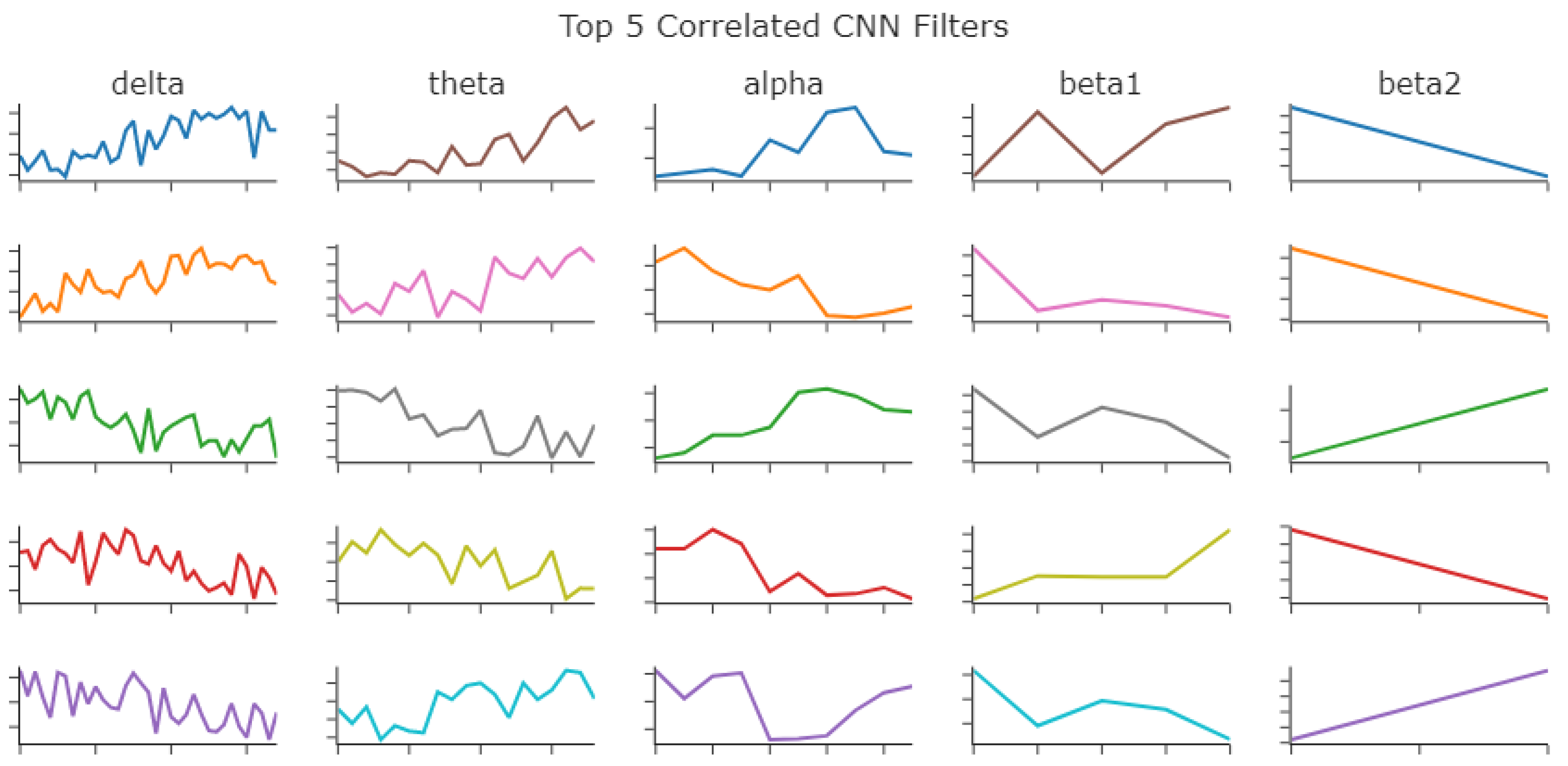
The filters from each frequency band wavelet model were extracted and plotted for visual inspection. The clinical markers such as k-complexes, v-waves, and spindles can be seen in the filters. Slow waves cannot be seen as easily.
Figure 6 has the filters from the coiflet 4 model and the none model (the model trained on data without preprocessing). The CNN filter size for each band was Delta (35), Theta (19), Alpha (10), Beta1 (5), and Beta2 (2). The CNN filter size,
, was calculated based on a representative frequency within each frequency band
and the sample rate,
, for this dataset before preprocessing (100 Hz).
Spearman’s rank coefficient was then calculated for all wavelet models in the same frequency band. This coefficient has more implications for the Delta, Theta, and Alpha frequency bands because of their filter size. The 95th percentile for the Spearman’s rank coefficient was 0.34145658263305323. The percent of coefficients for the top five of each frequency band that were higher than the 95th percentile are in
Table 12.
Each of the top five models were then plotted in
Figure 7 to be visually inspected. The clinical markers such as k-complexes, v-waves, and spindles can be seen in the filters. Slow waves cannot be seen as easily.
4. Discussion
Preprocessing with wavelet decomposition provided marginal improvement in the f1 score in most cases. From the visual inspection, clinical markers can be seen in the CNN filters. Preprocessing with wavelet decomposition does not definitively improve the ability to see those clinical markers. Similarity comparisons between the filters found that bigger filters tended to be less similar.
Table 13 compares the top 5 f1 scores with the top 1 Pearson’s coefficient in each frequency band.
In future studies, every aspect of this study could be changed to improve the necessary results: the choice of EEG channel; the choice of sleep channel; the choice of sleep stage; the choice of epoch size. Of the time–frequency techniques, the wavelet transform is the best choice, but the modification of the wavelet transform should be changed to possibly a continuous wavelet transform or a new modification of the discrete wavelet transform. The support vector machine, multilayer perceptron, convolution neural networks, deep feed-forward neural networks, and the hidden Markov model should all be tested for classification.
This study was limited to the choice between two sleep channels. For at-home studies, there are different devices that use different channels. One device uses two electrodes around the Fpz electrode position. This position is basically on the forehead of a person and would be one of the easiest positions to locate for an untrained person.
The goal of this paper was to support an at-home sleep study. A sleep study needs to be able to detect all stages, but it is very important for a sleep study to identify sleep from wakefulness. If REM cannot be identified, all stages cannot be identified with a single-channel EEG.
The epoch was originally defined based on the ease of use. The complications of the paper size and time required for an analysis can be eliminated by the choice of epoch size. A training dataset may be difficult to find for a small epoch size, but each individual wave can be classified based on the definitions provided by the AASM. This could result in epochs being scored literally by which waves make up the majority of the epoch.
Time–frequency analysis has many new modifications for discrete wavelet transforms. These modifications should be tested for improvements to the current discrete wavelet transforms. Furthermore, the continuous wavelet transform (CWT) can contain more detail than the discrete wavelet transform (DWT). The CWT should be tested against the new modifications of the DWT.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}