

DTONet a Lightweight Model for Melanoma Segmentation


 ,
, 
Abstract
:1. Introduction
2. Background
3. Materials and Methods
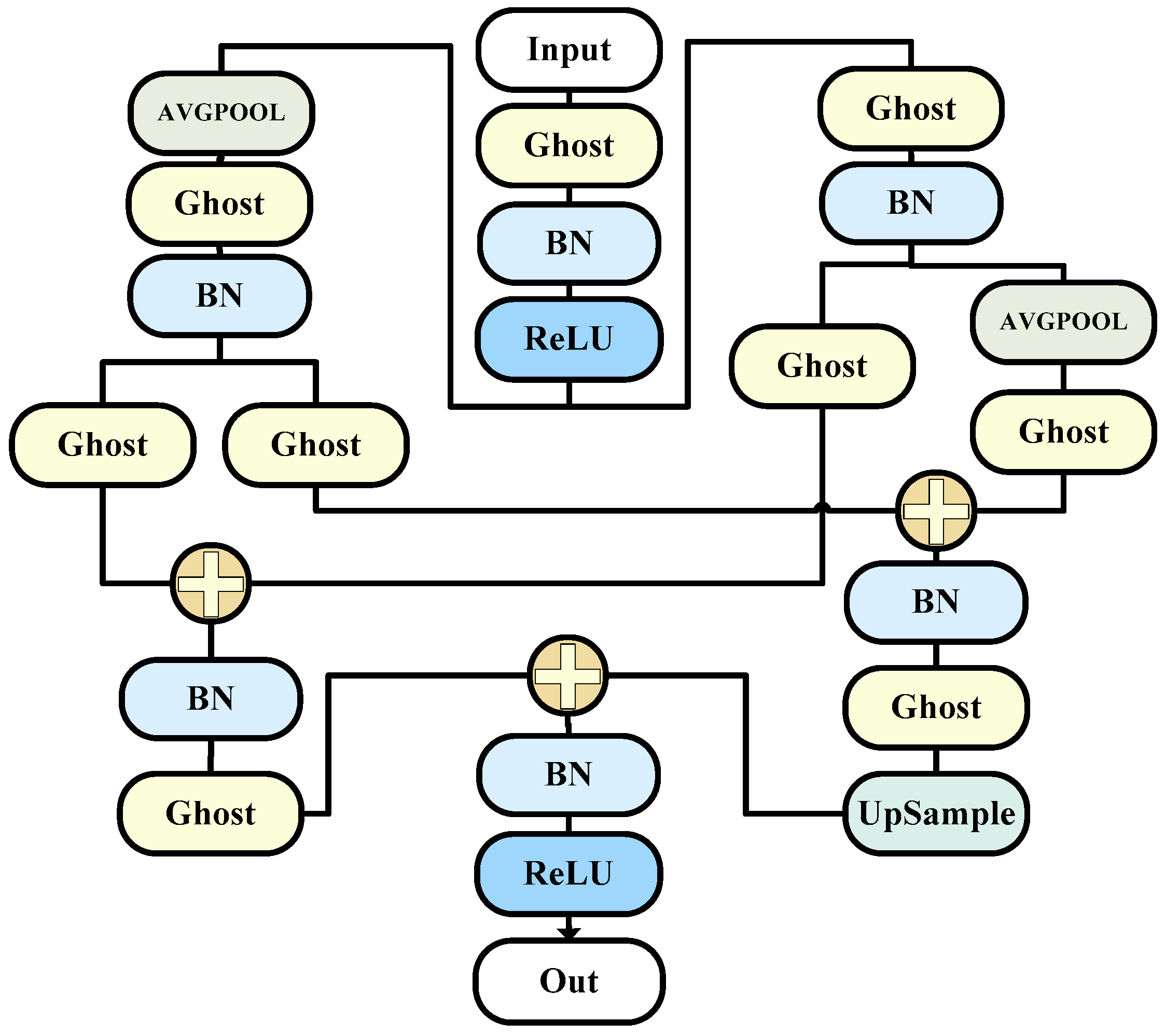
3.1. Overall Structure
3.2. G_O Block
- High-frequency convolution:
- Low-frequency convolution:
- Output feature map:
3.3. G_ECA Block
3.4. ORFB Block
4. Experiments and Results
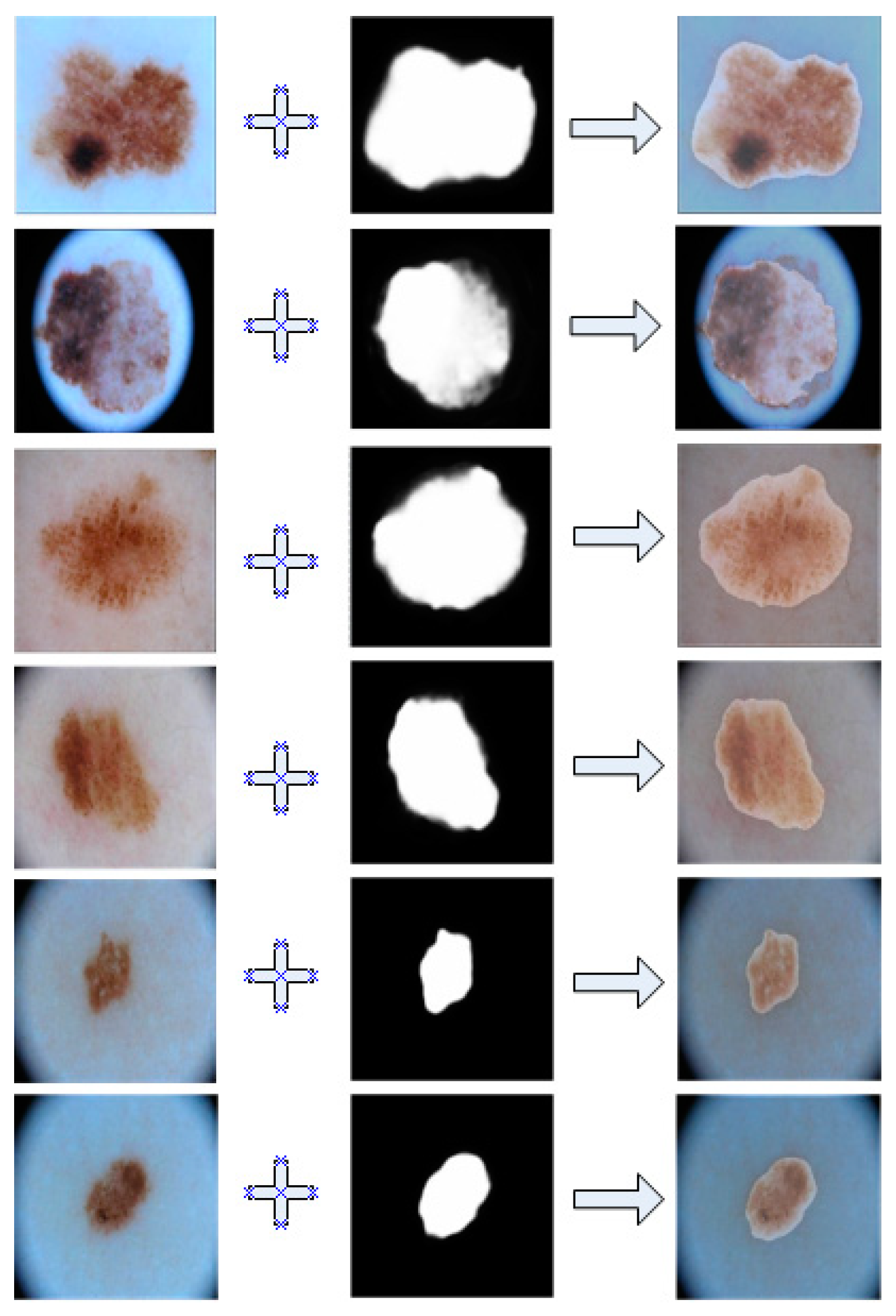
4.1. Dataset
4.2. Evaluation Metrics
4.3. Experimental Setup
4.4. Results and Analysis
4.4.1. Melanoma Segmentation Comparison with Advanced Models with ISIC2018
4.4.2. Melanoma Segmentation Comparison with Advanced Models with PH2
4.4.3. Cross-Domain Generalization Validation—Breast Ultrasound Dataset
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, X. Melanoma segmentation based on deep learning. Comput. Assist. Surg. 2017, 22 (Suppl. S1), 267–277. [Google Scholar] [CrossRef] [PubMed]
- Ming, G. Analysis and discussion of skin lesion image segmentation methods. J. Fujian Comput. 2024, 40, 24–29. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Proceedings 4. Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Wu, H.; Pan, J.; Li, Z.; Wen, Z.; Qin, J. Automated skin lesion segmentation via an adaptive dual attention module. IEEE Trans. Med. Imaging 2020, 40, 357–370. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Q.; He, T.; Zou, Y.J.D. Superpixel-oriented label distribution learning for skin lesion segmentation. Diagnostics 2022, 12, 938. [Google Scholar] [CrossRef]
- Song, Z.; Luo, W.; Shi, Q.J.E. Res-CDD-net: A network with multi-scale attention and optimized decoding path for skin lesion segmentation. Electronics 2022, 11, 2672. [Google Scholar] [CrossRef]
- Singh, V.K.; Abdel-Nasser, M.; Rashwan, H.A.; Akram, F.; Pandey, N.; Lalande, A.; Presles, B.; Romani, S.; Puig, D. FCA-Net: Adversarial learning for skin lesion segmentation based on multi-scale features and factorized channel attention. IEEE Access 2019, 7, 130552–130565. [Google Scholar] [CrossRef]
- Liu, Y.; Zhou, J.; Liu, L.; Zhan, Z.; Hu, Y.; Fu, Y.; Duan, H. FCP-net: A feature-compression-pyramid network guided by game-theoretic interactions for medical image segmentation. IEEE Trans. Med. Imaging 2022, 41, 1482–1496. [Google Scholar] [CrossRef] [PubMed]
- Ruan, J.; Xiang, S.; Xie, M.; Liu, T.; Fu, Y. (Eds.) MALUNet: A multi-attention and light-weight unet for skin lesion segmentation. In Proceedings of the 2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Las Vegas, NV, USA, 6–8 December 2022; pp. 1150–1156. [Google Scholar]
- Tang, Y.; Fang, Z.; Yuan, S.; Xing, Y.; Zhou, J.T.; Yang, F.J.I.A. imscgnet: Iterative multi-scale context-guided segmentation of skin lesion in dermoscopic images. IEEE Access 2020, 8, 39700–39712. [Google Scholar] [CrossRef]
- Azad, R.; Jia, Y.; Aghdam, E.K.; Cohen-Adad, J.; Merhof, D.J. Enhancing Medical Image Segmentation with TransCeption: A Multi-Scale Feature Fusion Approach. arXiv 2023, arXiv:2301.10847. [Google Scholar]
- Mu, J.; Lin, Y.; Meng, X.; Fan, J.; Ai, D.; Chen, D.; Qiu, H.; Yang, J.; Gu, Y. M-CSAFN: Multi-color Space Adaptive Fusion Network for Automated Port-wine Stains Segmentation. IEEE J. Biomed. Health Inform. 2023, 27, 3924–3935. [Google Scholar] [CrossRef] [PubMed]
- Dai, D.; Dong, C.; Xu, S.; Yan, Q.; Li, Z.; Zhang, C.; Luo, N. Ms RED: A novel multi-scale residual encoding and decoding network for skin lesion segmentation. Med. Image Anal. 2022, 75, 102293. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.; Wang, L.J.S. HMT-Net: Transformer and MLP Hybrid Encoder for Skin Disease Segmentation. Sensors 2023, 23, 3067. [Google Scholar] [CrossRef] [PubMed]
- Arshad, S.; Amjad, T.; Hussain, A.; Qureshi, I.; Abbas, Q.J.D. Dermo-Seg: ResNet-UNet Architecture and Hybrid Loss Function for Detection of Differential Patterns to Diagnose Pigmented Skin Lesions. Diagnostics 2023, 13, 2924. [Google Scholar] [CrossRef] [PubMed]
- Yoon, H.; Kim, S.; Lee, J.; Yoo, S.J.D. Deep-Learning-Based Morphological Feature Segmentation for Facial Skin Image Analysis. Diagnostics 2023, 13, 1894. [Google Scholar] [CrossRef] [PubMed]
- Gulzar, Y.; Khan, S.A.J.A.S. Skin lesion segmentation based on vision transformers and convolutional neural networks—A comparative study. Appl. Sci. 2022, 12, 5990. [Google Scholar] [CrossRef]
- Tang, Y.; Yang, F.; Yuan, S. A multi-stage framework with context information fusion structure for skin lesion segmentation. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 1407–1410. [Google Scholar]
- Wu, J.; Chen, E.Z.; Rong, R.; Li, X.; Xu, D.; Jiang, H. (Eds.) Skin lesion segmentation with C-UNet. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 2785–2788. [Google Scholar]
- Ali, R.; Hardie, R.C.; Narayanan, B.N.; De Silva, S. (Eds.) Deep learning ensemble methods for skin lesion analysis towards melanoma detection. In Proceedings of the 2019 IEEE National Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 15–19 July 2019; pp. 311–316. [Google Scholar]
- Izadi, S.; Mirikharaji, Z.; Kawahara, J.; Hamarneh, G. (Eds.) Generative adversarial networks to segment skin lesions. In Proceedings of the 2018 IEEE 15Th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 881–884. [Google Scholar]
- Shao, D.; Ren, L.; Ma, L.J.B. MSF-Net: A Lightweight Multi-Scale Feature Fusion Network for Skin Lesion Segmentation. Biomedicines 2023, 11, 1733. [Google Scholar] [CrossRef]
- Yuan, C.; Zhao, D.; Agaian, S.S.J. UCM-Net: A Lightweight and Efficient Solution for Skin Lesion Segmentation using MLP and CNN. arXiv 2023, arXiv:2310.09457. [Google Scholar]
- Ijaz, H.; Sultan, H.; Altaf, M.; Waris, A. (Eds.) Embedded Skin Lesion Segmentation using Lightweight Encoder-Decoder Architectures. In Proceedings of the 2023 3rd International Conference on Artificial Intelligence (ICAI), Wuhan, China, 17–19 November 2023; pp. 176–181. [Google Scholar]
- Ma, Y.; Wu, L.; Gao, Y.; Gao, F.; Zhang, J.; Luo, Z. ULFAC-Net: Ultra-Lightweight Fully Asymmetric Convolutional Network for Skin Lesion Segmentation. IEEE J. Biomed. Health Inform. 2023, 27, 2886–2897. [Google Scholar] [CrossRef]
- Lu, C.; Xu, H.; Wu, M.; Huang, Y. (Eds.) IESBU-Net: A Lightweight Skin Lesion Segmentation UNet with Inner-Module Extension and Skip-Connection Bridge. In Proceedings of the International Conference on Artificial Neural Networks, Crete, Greece, 26–29 September 2023; pp. 115–126. [Google Scholar]
- Wei, S.; Chen, H.; Zhao, J.; Zhou, Y.; Yang, Y. SRP&PASMLP-Net: Lightweight skin lesion segmentation network based on structural re-parameterization and parallel axial shift multilayer perceptron. Int. J. Imaging Syst. Technol. 2023, 34, 22985. [Google Scholar]
- Wang, Y.; Wang, J.; Zhou, W.; Liu, Z.; Yang, C.J.P.i.M.; Biology. MAUNext: A lightweight segmentation network for medical images. Phys. Med. Biol. 2023, 68, ad0a1f. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Fan, H.; Xu, B.; Yan, Z.; Kalantidis, Y.; Rohrbach, M.; Yan, S.; Feng, J. (Eds.) Drop an octave: Reducing spatial redundancy in convolutional neural networks with octave convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 3435–3444. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. (Eds.) ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Ali, R.; Hardie, R.C.; De Silva, M.S.; Kebede, T.M.J. Skin lesion segmentation and classification for ISIC 2018 by combining deep CNN and handcrafted features. arXiv 2019, arXiv:1908.05730. [Google Scholar]
- Valanarasu, J.M.J.; Patel, V.M. (Eds.) Unext: Mlp-based rapid medical image segmentation network. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; pp. 23–33. [Google Scholar]
- Kou, R.; Wang, C.; Yu, Y.; Peng, Z.; Yang, M.; Huang, F.; Fu, Q. LW-IRSTNet: Lightweight infrared small target segmentation network and application deployment. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 1–13. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Parameters | GFLOPS | IoU | Acc | Dice |
|---|---|---|---|---|---|
| UNet | 7.770 | 13.780 | 0.8169 | 0.9576 | 0.8838 |
| U-Net++ | 9.160 | 34.900 | 0.8203 | 0.9587 | 0.8881 |
| Attention-UNet | 8.730 | 16.740 | 0.8217 | 0.9588 | 0.8863 |
| UNeXt_s [34] | 0.300 | 0.100 | 0.8057 | 0.9557 | 0.8895 |
| MALUNet [11] | 0.175 | 0.083 | 0.8120 | 0.9532 | 0.8924 |
| LW-IRSTNet [35] | 0.161 | 0.301 | 0.8216 | 0.9588 | 0.8854 |
| Ours | 0.030 | 0.126 | 0.8284 | 0.9607 | 0.8845 |
| Models | Parameters | GFLOPS | IoU | Acc | Dice |
|---|---|---|---|---|---|
| UNet | 7.770 | 13.780 | 0.8062 | 0.9276 | 0.8916 |
| U-Net++ | 9.160 | 34.900 | 0.7929 | 0.9238 | 0.8831 |
| Attention-UNet | 8.730 | 16.740 | 0.8102 | 0.9303 | 0.8716 |
| UNeXt_s | 0.300 | 0.100 | 0.8077 | 0.9277 | 0.8900 |
| MALUNet | 0.175 | 0.083 | 0.8278 | 0.9351 | 0.9048 |
| LW-IRSTNet | 0.161 | 0.301 | 0.8327 | 0.9386 | 0.8944 |
| Ours | 0.030 | 0.126 | 0.8347 | 0.9388 | 0.8914 |
| Models | IoU | Acc | Dice |
|---|---|---|---|
| UNet | 0.6859 | 0.9642 | 0.7913 |
| U-Net++ | 0.6861 | 0.9625 | 0.7900 |
| Attention-UNet | 0.6875 | 0.9636 | 0.7948 |
| Ours | 0.6901 | 0.9633 | 0.7910 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hao, S.; Wang, H.; Chen, R.; Liao, Q.; Ji, Z.; Lyu, T.; Zhao, L. DTONet a Lightweight Model for Melanoma Segmentation. Bioengineering 2024, 11, 390. https://doi.org/10.3390/bioengineering11040390
Hao S, Wang H, Chen R, Liao Q, Ji Z, Lyu T, Zhao L. DTONet a Lightweight Model for Melanoma Segmentation. Bioengineering. 2024; 11(4):390. https://doi.org/10.3390/bioengineering11040390
Chicago/Turabian StyleHao, Shengnan, Hongzan Wang, Rui Chen, Qinping Liao, Zhanlin Ji, Tao Lyu, and Li Zhao. 2024. "DTONet a Lightweight Model for Melanoma Segmentation" Bioengineering 11, no. 4: 390. https://doi.org/10.3390/bioengineering11040390
APA StyleHao, S., Wang, H., Chen, R., Liao, Q., Ji, Z., Lyu, T., & Zhao, L. (2024). DTONet a Lightweight Model for Melanoma Segmentation. Bioengineering, 11(4), 390. https://doi.org/10.3390/bioengineering11040390