
Anomaly Detection in Optical Coherence Tomography Angiography (OCTA) with a Vector-Quantized Variational Auto-Encoder (VQ-VAE)


Abstract
1. Introduction
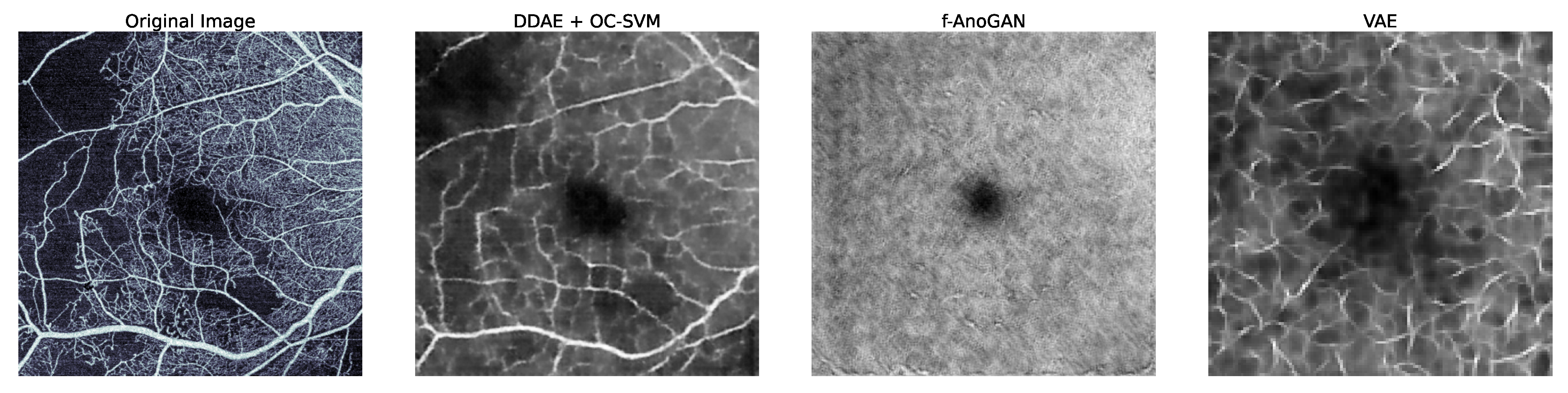
1.1. Related Work
1.2. Contribution
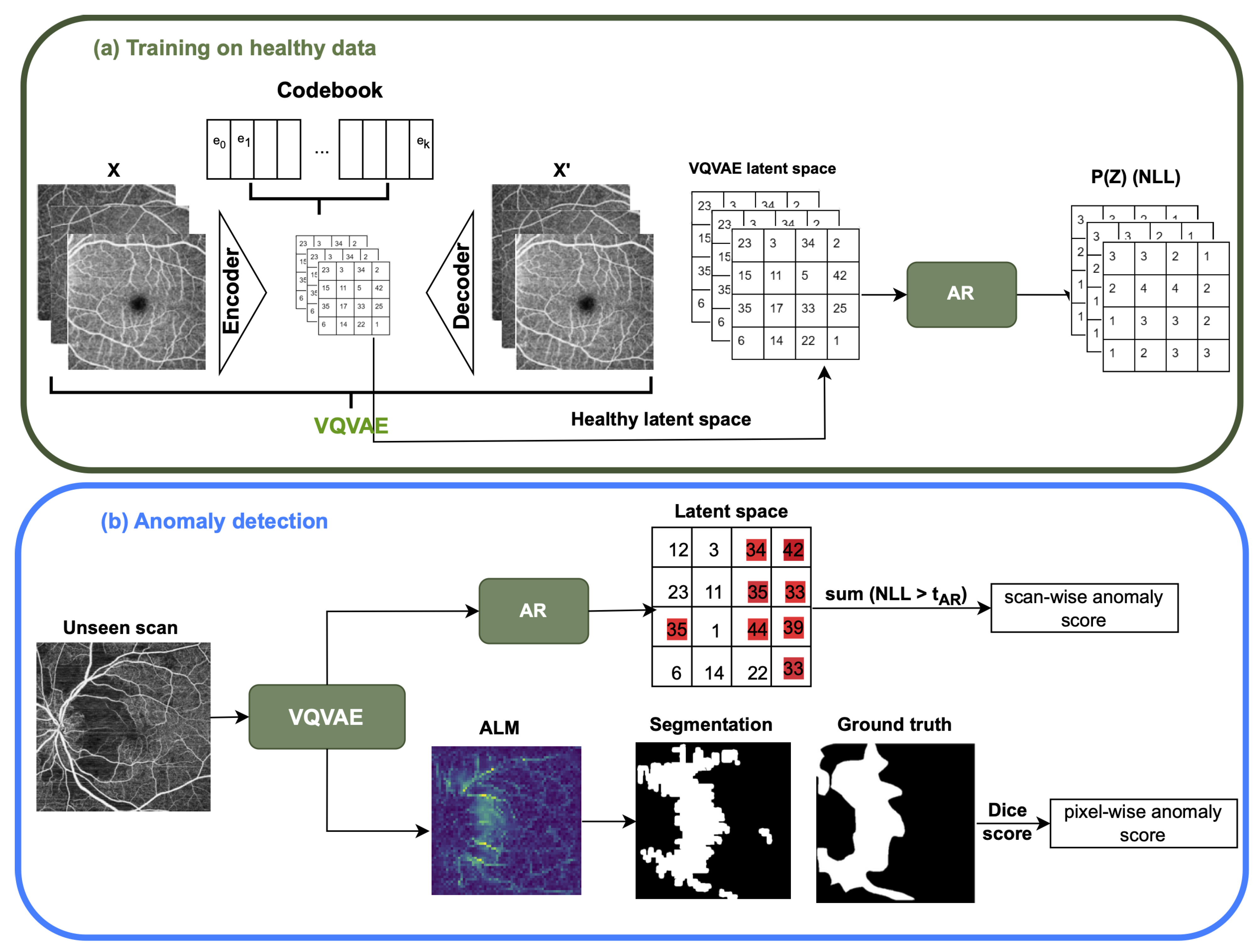
2. Methods
2.1. VQ-VAE and AR Model
2.1.1. The Vector Quantized Variational AutoEncoder (VQ-VAE)
2.1.2. The Auto-Regressive (AR) Model
2.1.3. Implementation Details
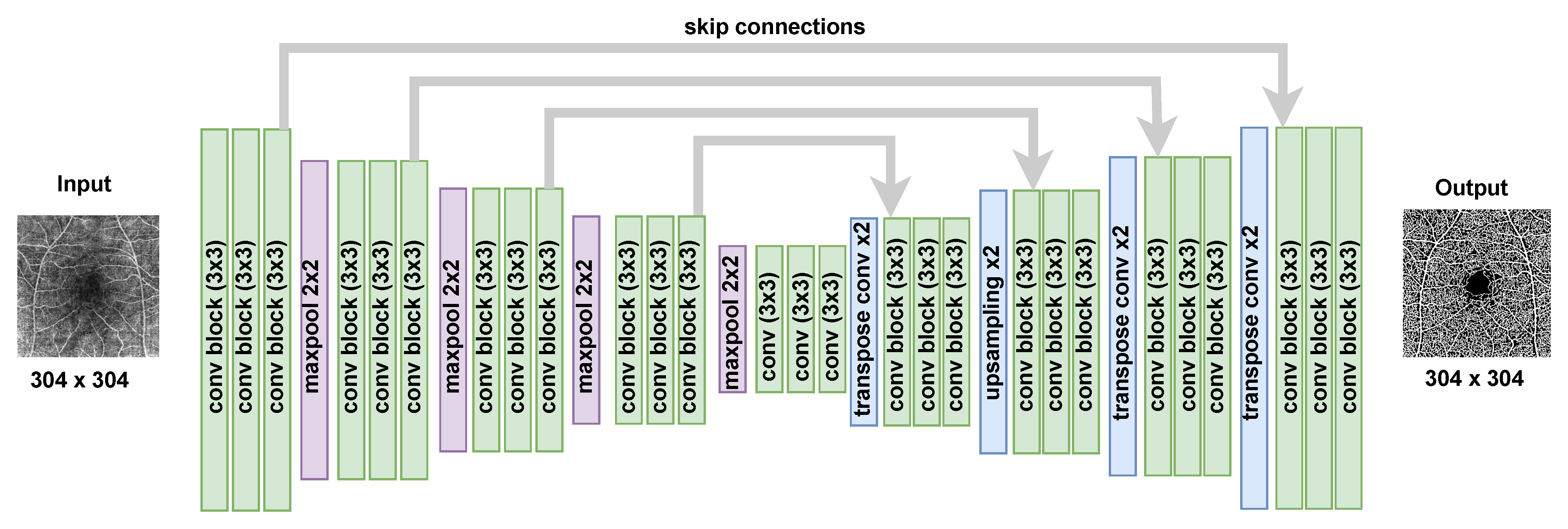
2.2. The Epistemic Uncertainty of Bayesian U-Net Model
2.2.1. Bayesian U-Net Training
2.2.2. Epistemic Uncertainty Map
2.2.3. Implementation Details
2.3. OCTA En Face Image Preprocessing
2.4. OCTA En Face Image Segmentation Post-Processing
3. Experimental Setup
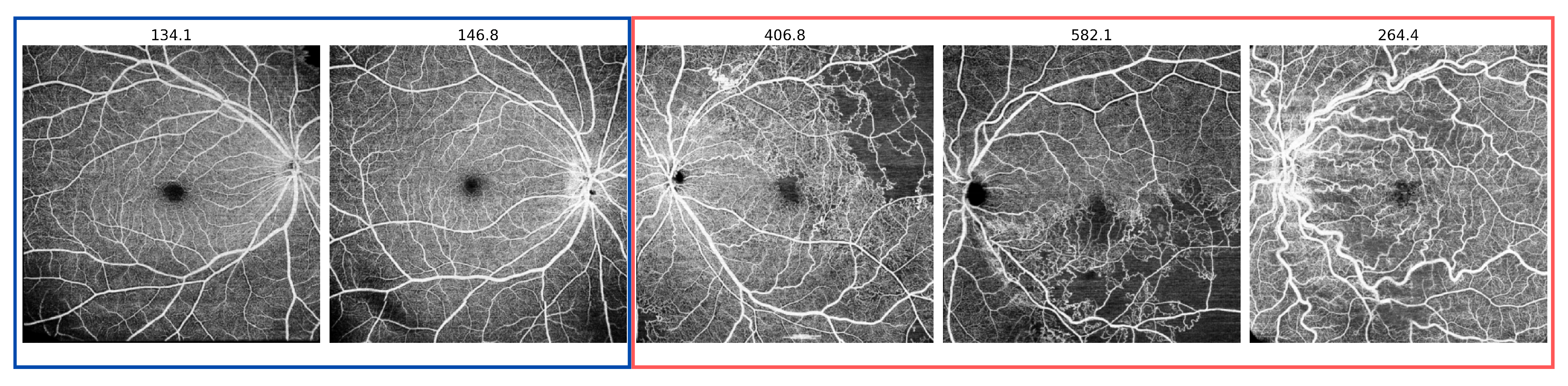
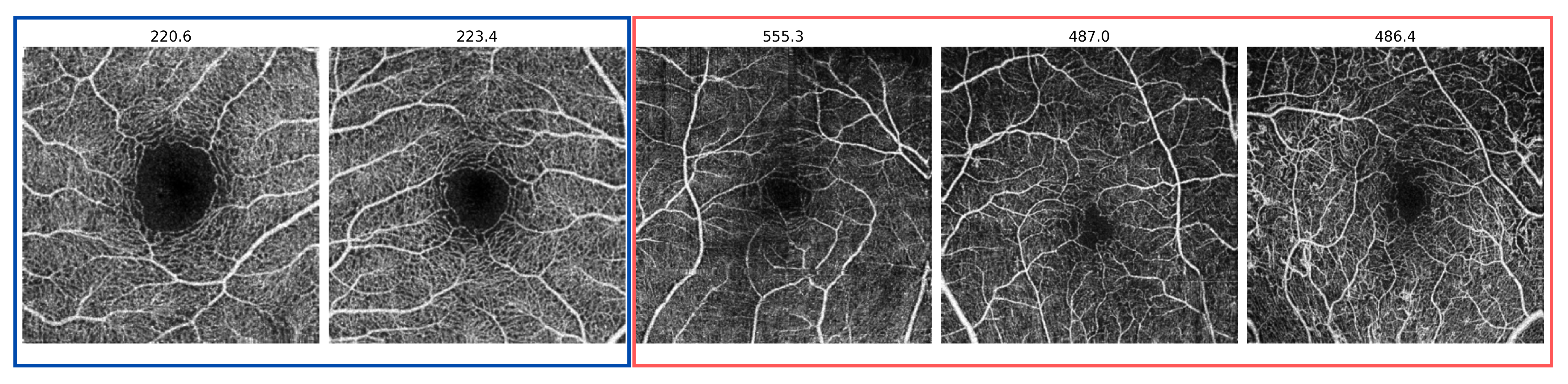
3.1. Datasets
3.2. The Anomaly Detection Evaluation Procedure
- Scan-wise anomaly score: This score is associated with the probability that a given scan contains an anomaly. During model testing, abnormal regions in the input scan correspond to latent space NLL probability values in the AR model or uncertainty values for the Bayesian U-Net. The scan-wise score is the sum of threshold pixel values above a threshold for the VQ-VAE with the AR model and above a threshold for the uncertainty map. Performance is evaluated using the area under the receiver operating characteristic curve (AUROC) score, along with the Average Precision (AP) score, which computes the average precision across all recall levels where both of these scores are computed a continuous values like our anomaly score. In addition, F1 score is computed based on selecting an operating point using the Youden Index to convert continuous score to a binary score.
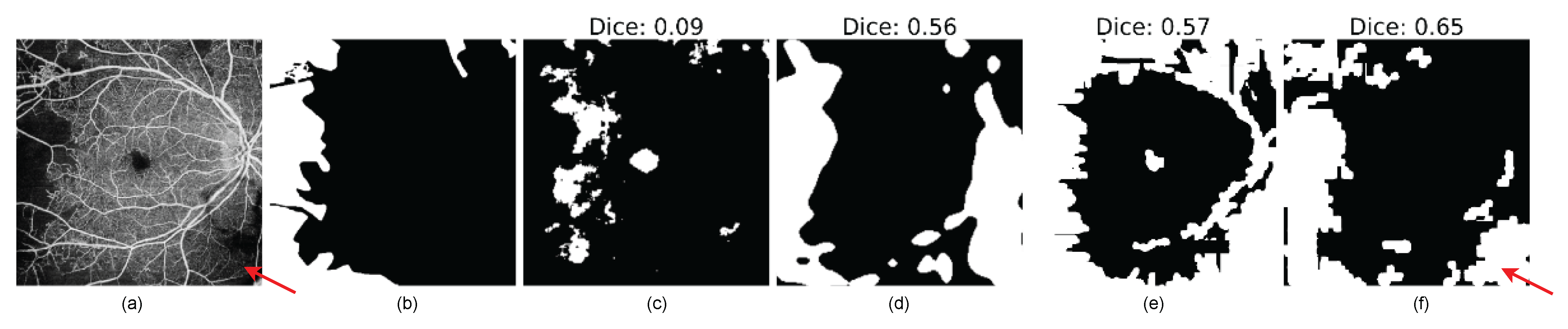
- Pixel-wise anomaly score: The pixel-wise score quantifies the probability that a given pixel belongs to an anomalous region. In both approaches, pixel values that are above the or threshold in VQ-VAE ALM and Uncertainty Map, respectively, will be highlighted as anomaly pixels in the segmentation results. Evaluation is performed using the Dice similarity metric, which calculates the size of the intersection of two areas divided by the average size of the individual areas. Additionally, Intersection over Union (IOU), sensitivity (True Positive Rate), and specificity (True Negative Rate) are used for the evaluation.
4. Results
4.1. Scan-Wise Anomaly Detection Results
4.2. Pixel-Level Anomaly Segmentation Results
5. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Khatib, M.N. Articles Trends in prevalence of blindness and distance and near vision impairment over 30 years: An analysis for the Global Burden of Disease Study. Lancet Glob. Health 2021, 9, 130–143. [Google Scholar]
- James, S.L.; Abate, D.; Abate, K.H.; Abay, S.M.; Abbafati, C.; Abbasi, N.; Abbastabar, H.; Abd-Allah, F.; Abdela, J.; Abdelalim, A.; et al. Global, regional, and national incidence, prevalence, and years lived with disability for 354 Diseases and Injuries for 195 countries and territories, 1990–2017: A systematic analysis for the Global Burden of Disease Study 2017. Lancet 2018, 392, 1789–1858. [Google Scholar] [CrossRef] [PubMed]
- Burton, M.J.; Ramke, J.; Marques, A.P.; Bourne, R.R.; Congdon, N.; Jones, I.; Tong, B.A.A.; Arunga, S.; Bachani, D.; Bascaran, C.; et al. The lancet global health commission on global eye health: Vision beyond 2020. Lancet Glob. Health 2021, 9, e489–e551. [Google Scholar] [CrossRef] [PubMed]
- Kim, D.; Fingler, J.; Werner, J.; Schwartz, D.; Fraser, S.; Zawadzki, R. In vivo volumetric imaging of human retinal circulation with phase-variance optical coherence tomography. Biomed. Opt. Express 2011, 2, 1504–1513. [Google Scholar] [CrossRef] [PubMed]
- Musa, F.U.; Muen, W.J.; Hancock, R.; Clark, D. Adverse effects of fluorescein angiography in hypertensive and elderly patients. Acta Ophthalmol. Scand. 2006, 84 6, 740–742. [Google Scholar] [CrossRef]
- Drexler, W.; Fujimoto, J.G. State-of-the-art retinal optical coherence tomography. Prog. Retin. Eye Res. 2008, 27, 45–88. [Google Scholar] [CrossRef] [PubMed]
- Spaide, R.F.; Fujimoto, J.G.; Waheed, N.K.; Sadda, S.R.; Staurenghi, G. Optical coherence tomography angiography. Prog. Retin. Eye Res. 2018, 64, 1–55. [Google Scholar] [CrossRef] [PubMed]
- Rocholz, R.; Corvi, F.; Weichsel, J.; Schmidt, S.; Staurenghi, G. OCT Angiography (OCTA) in Retinal Diagnostics. In High Resolution Imaging in Microscopy and Ophthalmology: New Frontiers in Biomedical Optics; Springer: Berlin/Heidelberg, Germany, 2019; pp. 135–160. [Google Scholar] [CrossRef]
- Chung, C.Y.; Tang, H.; Li, S.; Li, K.K. Differential microvascular assessment of retinal vein occlusion with coherence tomography angiography and fluorescein angiography: A blinded comparative study. Int. Ophthalmol. 2018, 38, 1119–1128. [Google Scholar] [CrossRef]
- Danuta, B.S.; Dubis, A.; Chen, F.; Zawadzki, R.; Sampson, D. Towards standardizing retinal optical coherence tomography angiography: A review. Light Sci. Appl. 2022, 11, 63. [Google Scholar] [CrossRef]
- Wagner, S.; Fu, D.; Faes, L.; Liu, X.; Huemer, J.; Khalid, H.; Ferraz, D.; Korot, E.; Kelly, C.; Balaskas, K.; et al. Insights into Systemic Disease through Retinal Imaging-Based Oculomics. Transl. Vis. Sci. Technol. 2020, 9, 6. [Google Scholar] [CrossRef] [PubMed]
- Hormel, T.T.; Hwang, T.S.; Bailey, S.T.; Wilson, D.J.; Huang, D.; Jia, Y. Artificial intelligence in OCT angiography. Prog. Retin. Eye Res. 2021, 85, 100965. [Google Scholar] [CrossRef] [PubMed]
- Anvari, P.; Ashraf Khorasani, M.; Habibi, A.; Falavarjani, K. Artifacts in Optical Coherence Tomography Angiography. J. Ophthalmic Vis. Res. 2021, 16, 271. [Google Scholar] [CrossRef] [PubMed]
- Zar, Y.; Aimmanee, P. A Complete Review of Automatic Detection, Segmentation, and Quantification of Neovascularization in Optical Coherence Tomography Angiography Images. Diagnostics 2023, 13, 3407. [Google Scholar] [CrossRef] [PubMed]
- Meiburger, K.M.; Salvi, M.; Rotunno, G.; Drexler, W.; Liu, M. Automatic Segmentation and Classification Methods Using Optical Coherence Tomography Angiography (OCTA): A Review and Handbook. Appl. Sci. 2021, 11, 9734. [Google Scholar] [CrossRef]
- Sandhu, H.S.; Eladawi, N.; Elmogy, M.; Keynton, R.; Helmy, O.; Schaal, S.; El-Baz, A. Automated diabetic retinopathy detection using optical coherence tomography angiography: A pilot study. Br. J. Ophthalmol. 2018, 102, 1564–1569. [Google Scholar] [CrossRef] [PubMed]
- Zang, P.; Hormel, T.T.; Wang, X.; Tsuboi, K.; Huang, D.; Hwang, T.S.; Jia, Y. A diabetic retinopathy classification framework based on deep-learning analysis of OCT angiography. Transl. Vis. Sci. Technol. 2022, 11, 10. [Google Scholar] [CrossRef]
- Ryu, G.; Lee, K.; Park, D.; Park, S.H.; Sagong, M. A deep learning model for identifying diabetic retinopathy using optical coherence tomography angiography. Sci. Rep. 2021, 11, 23024. [Google Scholar] [CrossRef] [PubMed]
- Heisler, M.; Karst, S.; Lo, J.; Mammo, Z.; Yu, T.; Warner, S.; Maberley, D.; Beg, M.F.; Navajas, E.V.; Sarunic, M.V. Ensemble Deep Learning for Diabetic Retinopathy Detection Using Optical Coherence Tomography Angiography. Transl. Vis. Sci. Technol. 2020, 9, 20. [Google Scholar] [CrossRef] [PubMed]
- Thakoor, K.; Bordbar, D.; Yao, J.; Moussa, O.; Chen, R.; Sajda, P. Hybrid 3d-2d Deep Learning for Detection of Neovascularage-Related Macular Degeneration Using Optical Coherence Tomography B-Scans And Angiography Volumes. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; pp. 1600–1604. [Google Scholar] [CrossRef]
- Giarratano, Y.; Bianchi, E.; Gray, C.; Morris, A.; MacGillivray, T.; Dhillon, B.; Bernabeu, M.O. Automated Segmentation of Optical Coherence Tomography Angiography Images: Benchmark Data and Clinically Relevant Metrics. arXiv 2020, arXiv:1912.09978. [Google Scholar] [PubMed]
- Ma, Y.; Hao, H.; Xie, J.; Fu, H.; Zhang, J.; Yang, J.; Wang, Z.; Liu, J.; Zheng, Y.; Zhao, Y. ROSE: A Retinal OCT-Angiography Vessel Segmentation Dataset and New Model. IEEE Trans. Med. Imaging 2021, 40, 928–939. [Google Scholar] [CrossRef]
- Sultana, F.; Sufian, A.; Dutta, P. Automatic Diabetic Retinopathy Lesion Segmentation in UW-OCTA Images Using Transfer Learning. In MICCAI Challenge on Mitosis Domain Generalization; Springer: Cham, Switzerland, 2023; pp. 186–194. [Google Scholar] [CrossRef]
- Hou, J.; Xiao, F.; Xu, J.; Zhang, Y.; Zou, H.; Feng, R. Deep-OCTA: Ensemble Deep Learning Approaches for Diabetic Retinopathy Analysis on OCTA Images. arXiv 2022, arXiv:2210.00515. [Google Scholar]
- Tang, J.; Wang, X.N.; Yang, X.; Wen, Y.; Qian, B.; Chen, T.; Sheng, B. TSNet: Task-specific network for joint diabetic retinopathy grading and lesion segmentation of ultra-wide optical coherence tomography angiography images. Vis. Comput. 2023, 1–12. [Google Scholar] [CrossRef]
- McClintic, B.R.; McClintic, J.I.; Bisognano, J.D.; Block, R.C. The Relationship between Retinal Microvascular Abnormalities and Coronary Heart Disease: A Review. Am. J. Med. 2010, 123, 374.e1–374.e7. [Google Scholar] [CrossRef] [PubMed]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly Detection: A Survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Tschuchnig, M.E.; Gadermayr, M. Anomaly Detection in Medical Imaging—A Mini Review. In Data Science—Analytics and Applications; Springer Fachmedien Wiesbaden: Wiesbaden, Germany, 2022; pp. 33–38. [Google Scholar] [CrossRef]
- Akkus, Z.; Galimzianova, A.; Hoogi, A.; Rubin, D.; Erickson, B. Deep Learning for Brain MRI Segmentation: State of the Art and Future Directions. J. Digit. Imaging 2017, 30, 449–459. [Google Scholar] [CrossRef] [PubMed]
- van Hespen, K.; Zwanenburg, J.; Dankbaar, J.; Geerlings, M.; Hendrikse, J.; Kuijf, H. An anomaly detection approach to identify chronic brain infarcts on MRI. Sci. Rep. 2021, 11, 7714. [Google Scholar] [CrossRef] [PubMed]
- Rajpurkar, P.; Irvin, J.; Zhu, K.; Yang, B.; Mehta, H.; Duan, T.; Ding, D.; Bagul, A.; Langlotz, C.; Shpanskaya, K.; et al. CheXNet: Radiologist-Level Pneumonia Detection on Chest X-rays with Deep Learning. arXiv 2017, arXiv:1711.05225. [Google Scholar]
- Tlusty, T.; Amit, G.; Ben-Ari, R. Unsupervised clustering of mammograms for outlier detection and breast density estimation. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 3808–3813. [Google Scholar] [CrossRef]
- Seeböck, P.; Waldstein, S.; Riedl, S.; Bogunović, H.; Schlegl, T.; Gerendas, B.; Donner, R.; Schmidt-Erfurth, U.; Langs, G. Unsupervised Identification of Disease Marker Candidates in Retinal OCT Imaging Data. IEEE Trans. Med. Imaging 2018, 38, 1037–1047. [Google Scholar] [CrossRef] [PubMed]
- Schlegl, T.; Seeböck, P.; Waldstein, S.; Langs, G.; Schmidt-Erfurth, U. f-AnoGAN: Fast Unsupervised Anomaly Detection with Generative Adversarial Networks. Med. Image Anal. 2019, 54, 30–44. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Li, Y.; He, N.; Ma, K.; Fang, L.; Li, H.; Zheng, Y. Anomaly Detection for Medical Images Using Self-Supervised and Translation-Consistent Features. IEEE Trans. Med. Imaging 2021, 40, 3641–3651. [Google Scholar] [CrossRef] [PubMed]
- Zhou, K.; Gao, S.; Cheng, J.; Gu, Z.; Fu, H.; Tu, Z.; Yang, J.; Zhao, Y.; Liu, J. Sparse-GAN: Sparsity-constrained Generative Adversarial Network for Anomaly Detection in Retinal OCT Image. arXiv 2020, arXiv:1911.12527. [Google Scholar]
- Seebock, P.; Orlando, J.I.; Schlegl, T.; Waldstein, S.M.; Bogunovic, H.; Klimscha, S.; Langs, G.; Schmidt-Erfurth, U. Exploiting Epistemic Uncertainty of Anatomy Segmentation for Anomaly Detection in Retinal OCT. IEEE Trans. Med. Imaging 2020, 39, 87–98. [Google Scholar] [CrossRef] [PubMed]
- Sidibé, D.; Sankar, S.; Lemaître, G.; Rastgoo, M.; Massich, J.; Cheung, C.; Tan, G.; Milea, D.; Lamoureux, E.; Wong, T.Y.; et al. An anomaly detection approach for the identification of DME patients using spectral domain optical coherence tomography images. Comput. Methods Programs Biomed. 2016, 139, 109–117. [Google Scholar] [CrossRef] [PubMed]
- Zavrtanik, V.; Kristan, M.; Skočaj, D. DRAEM—A discriminatively trained reconstruction embedding for surface anomaly detection. arXiv 2021, arXiv:2108.07610. [Google Scholar]
- Lee, S.; Lee, S.; Song, B.C. CFA: Coupled-hypersphere-based Feature Adaptation for Target-Oriented Anomaly Localization. arXiv 2022, arXiv:2206.04325. [Google Scholar]
- Razavi, A.; van den Oord, A.; Vinyals, O. Generating Diverse High-Fidelity Images with VQ-VAE-2. arXiv 2019, arXiv:1906.00446. [Google Scholar]
- Chen, X.; Mishra, N.; Rohaninejad, M.; Abbeel, P. PixelSNAIL: An Improved Autoregressive Generative Model. arXiv 2017, arXiv:1712.09763. [Google Scholar]
- Marimont, S.N.; Tarroni, G. Anomaly detection through latent space restoration using vector quantized variational autoencoders. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1764–1767. [Google Scholar]
- Li, M.; Zhang, Y.; Ji, Z.; Xie, K.; Yuan, S.; Liu, Q.; Chen, Q. Ipn-v2 and octa-500: Methodology and dataset for retinal image segmentation. arXiv 2020, arXiv:2012.07261. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Reddy, P. Blood vessel extraction in fundus images using hessian eigenvalues and adaptive thresholding. Evol. Intell. 2021, 14, 577–582. [Google Scholar] [CrossRef]
- Qian, B.; Chen, H.; Wang, X.; Guan, Z.; Li, T.; Jin, Y.; Wu, Y.; Wen, Y.; Che, H.; Kwon, G.; et al. DRAC 2022: A public benchmark for diabetic retinopathy analysis on ultra-wide optical coherence tomography angiography images. Patterns 2024, 5, 100929. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Huang, K.; Xu, Q.; Yang, J.; Zhang, Y.; Ji, Z.; Xie, K.; Yuan, S.; Liu, Q.; Chen, Q. OCTA-500: A retinal dataset for optical coherence tomography angiography study. Med. Image Anal. 2024, 93, 103092. [Google Scholar] [CrossRef] [PubMed]
- Zimmerer, D.; Isensee, F.; Petersen, J.; Kohl, S.; Maier-Hein, K. Unsupervised Anomaly Localization using Variational Auto-Encoders. arXiv 2019, arXiv:1907.02796. [Google Scholar]
- Kreitner, L.; Paetzold, J.C.; Rauch, N.; Chen, C.; Hagag, A.M.; Fayed, A.E.; Sivaprasad, S.; Rausch, S.; Weichsel, J.; Menze, B.H.; et al. Synthetic optical coherence tomography angiographs for detailed retinal vessel segmentation without human annotations. IEEE Trans. Med. Imaging 2024, 43, 2061–2073. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DRAC | OCTA-500 | |||||
|---|---|---|---|---|---|---|
| Method | AUROC | F1 | AP | AUROC | F1 | AP |
| CFA [40] | 0.81 | 0.79 | 0.95 | 0.59 | 0.59 | 0.69 |
| DRAEM [39] | 0.76 | 0.77 | 0.93 | 0.49 | 0.26 | 0.55 |
| Bayesian U-Net | 0.67 | 0.75 | 0.90 | 0.53 | 0.6 | 0.58 |
| VQ-VAE + AR | 0.92 | 0.92 | 0.98 | 0.75 | 0.71 | 0.77 |
| Method | Dice | IoU | Sensitivity | Specificity |
|---|---|---|---|---|
| CFA [40] | ||||
| DRAEM [39] | ||||
| Bayesian U-Net | 0.61 ± 0.16 | 0.46 ± 0.17 | 0.80 ± 0.13 | 0.80 ± 0.08 |
| VQ-VAE ALM | 0.60 ± 0.17 | 0.45 ± 0.17 | 0.57 ± 0.19 | 0.91 ± 0.06 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jebril, H.; Esengönül, M.; Bogunović, H. Anomaly Detection in Optical Coherence Tomography Angiography (OCTA) with a Vector-Quantized Variational Auto-Encoder (VQ-VAE). Bioengineering 2024, 11, 682. https://doi.org/10.3390/bioengineering11070682
Jebril H, Esengönül M, Bogunović H. Anomaly Detection in Optical Coherence Tomography Angiography (OCTA) with a Vector-Quantized Variational Auto-Encoder (VQ-VAE). Bioengineering. 2024; 11(7):682. https://doi.org/10.3390/bioengineering11070682
Chicago/Turabian StyleJebril, Hana, Meltem Esengönül, and Hrvoje Bogunović. 2024. "Anomaly Detection in Optical Coherence Tomography Angiography (OCTA) with a Vector-Quantized Variational Auto-Encoder (VQ-VAE)" Bioengineering 11, no. 7: 682. https://doi.org/10.3390/bioengineering11070682
APA StyleJebril, H., Esengönül, M., & Bogunović, H. (2024). Anomaly Detection in Optical Coherence Tomography Angiography (OCTA) with a Vector-Quantized Variational Auto-Encoder (VQ-VAE). Bioengineering, 11(7), 682. https://doi.org/10.3390/bioengineering11070682