Abstract
This article investigates the effectiveness of feature extraction and selection techniques in enhancing the performance of classifier accuracy in Type II Diabetes Mellitus (DM) detection using microarray gene data. To address the inherent high dimensionality of the data, three feature extraction (FE) methods are used, namely Short-Time Fourier Transform (STFT), Ridge Regression (RR), and Pearson’s Correlation Coefficient (PCC). To further refine the data, meta-heuristic algorithms like Bald Eagle Search Optimization (BESO) and Red Deer Optimization (RDO) are utilized for feature selection. The performance of seven classification techniques, Non-Linear Regression—NLR, Linear Regression—LR, Gaussian Mixture Models—GMMs, Expectation Maximization—EM, Logistic Regression—LoR, Softmax Discriminant Classifier—SDC, and Support Vector Machine with Radial Basis Function kernel—SVM-RBF, are evaluated with and without feature selection. The analysis reveals that the combination of PCC with SVM-RBF achieved a promising accuracy of 92.85% even without feature selection. Notably, employing BESO with PCC and SVM-RBF maintained this high accuracy. However, the highest overall accuracy of 97.14% was achieved when RDO was used for feature selection alongside PCC and SVM-RBF. These findings highlight the potential of feature extraction and selection techniques, particularly RDO with PCC, in improving the accuracy of DM detection using microarray gene data.
1. Introduction
India faces a significant public health challenge with the escalating prevalence of diabetes. According to the International Diabetes Federation (IDF) Atlas data from 2021, a staggering 77 million adults in India already suffer from this chronic condition. Even more alarming are projections that this number will reach a critical mass of 134 million by 2045. This translates to approximately one in eight adults in India potentially having diabetes [1]. Particularly worrisome is the increasing number of young adults (below 40 years old) being diagnosed with type 2 diabetes.
Several factors contribute to this alarming rise. India’s rapid urbanization is linked to lifestyle changes that heighten diabetes risk. These changes include reduced physical activity levels, increased consumption of processed foods, and rising obesity rates. Additionally, genetic predisposition, stress, and environmental factors all play a role [2]. Unfortunately, many diabetes cases remain undiagnosed until complications arise, highlighting the need for increased awareness and early detection strategies.
The human cost of diabetes in India is immense, with this disease ranking as the seventh leading cause of death. The economic burden is equally concerning. It is estimated that diabetes drains the Indian economy of approximately USD 100 billion annually. Clearly, addressing this growing public health crisis requires a multipronged approach that focuses on preventive measures for type 2 diabetes, early diagnosis for all types, and proper management of the condition [3]. Considering these challenges, there is an urgent need for advanced diagnostic tools that can detect diabetes early and accurately. Traditional diagnostic methods, while useful, have limitations in terms of sensitivity and specificity. This has led researchers to explore innovative approaches, including the analysis of genetic data [4]. Microarray gene expression data have shown promise in identifying biomarkers associated with Type II Diabetes Mellitus (DM) [5]. However, the high-dimensional nature of microarray data presents its own set of challenges. The vast number of genes compared to the typically small sample sizes can lead to overfitting and reduced generalization in machine learning models [6]. This “curse of dimensionality” necessitates effective feature extraction and selection techniques to identify the most relevant genes for diabetes diagnosis.
In recent years, machine learning techniques have gained traction in medical diagnostics, offering the potential for more accurate and efficient disease detection. These methods, when combined with appropriate feature selection algorithms, can significantly enhance the accuracy of diabetes diagnosis. Meta-heuristic optimization algorithms have shown promise in feature selection tasks across various domains [7].
This study aims to address these challenges by investigating the effectiveness of feature extraction and selection techniques in improving the accuracy of Type II DM detection using microarray gene data. We explore three feature extraction methods: Short-Time Fourier Transform (STFT), Ridge Regression (RR), and Pearson’s Correlation Coefficient (PCC). Furthermore, we employ two meta-heuristic algorithms, Bald Eagle Search Optimization (BESO) and Red Deer Optimization (RDO), for feature selection. By combining these techniques with various classification methods, we seek to develop a robust framework for early and accurate diabetes detection.
Review of Related Works
Early and accurate diagnosis of diabetes is critical for effective management, but traditional methods like blood glucose tests have limitations. Microarray gene technology offers a promising alternative by analyzing gene expression patterns in the pancreas, potentially revealing early signs of the disease [8]. Recent advancements in machine learning algorithms have further enhanced their effectiveness for diabetes detection. A novel Convolutional Neural Network (CNN) architecture was specifically designed for diabetes classification using electronic health records (EHR) data [9]. The model achieved an impressive accuracy of 85.2%, demonstrating the potential of deep learning for diabetes diagnosis from readily available clinical data. Explainable Artificial Intelligence (XAI) techniques with machine learning models for diabetes prediction were used [10]. The XAI approach not only achieved high accuracy but also provided insights into the factors most influencing model predictions. This interpretability is crucial for clinicians to understand and trust the model’s recommendations [11]. Certain investigations were made into the use of machine learning models that combine various data sources, including gene expression data, clinical information, and lifestyle factors. The findings suggest that integrating multimodal datasets can lead to more accurate and comprehensive diabetes risk prediction models [12]. Ensemble learning approaches continue to show strong performance. Specific algorithms like Random Forest and Deep Neural Networks have proven effective in various studies [13]. Microarray gene data analysis remains a valuable avenue for exploration. While traditional datasets have dominated research in machine learning for diabetes detection, microarray gene data offer a relatively unexplored avenue [14]. This presents an opportunity to investigate the effectiveness of various performance metrics such as accuracy, F1 Score, Mathew Correlation Coefficient, Jaccard Metrics, Error Rate and Kappa.
Feature extraction and selection techniques play a crucial role in handling high-dimensional microarray data. Principal Component Analysis (PCA) was employed for dimensionality reduction in gene expression data, achieving improved classification accuracy for diabetes prediction [15]. Similarly, the utilization of Independent Component Analysis (ICA) for feature extraction demonstrated its effectiveness in identifying relevant gene signatures. Among feature selection methods, meta-heuristic algorithms have gained attention due to their ability to efficiently search large feature spaces. Particle Swarm Optimization (PSO) applied for feature selection in diabetes diagnosis showed improved accuracy and reduced Computational Complexity. Genetic Algorithms (GA) have also shown promise, as demonstrated by combining GA with Support Vector Machines for diabetes prediction using gene expression data [16]. Short-Time Fourier Transform (STFT) has been applied in various biomedical signal processing tasks, including ECG analysis for diabetes detection. However, its application to microarray data for diabetes diagnosis remains largely unexplored. Ridge Regression (RR) has been used for feature selection in high-dimensional biological data, but its potential in diabetes-specific gene expression analysis warrants further investigation.
PCC has been widely used for feature selection in bioinformatics, employed to identify diabetes-related genes from microarray data, achieving high classification accuracy. However, the combination of PCC with advanced meta-heuristic algorithms like Bald Eagle Search Optimization (BESO) and Red Deer Optimization (RDO) represents a novel approach in this field. Recent studies have highlighted the potential of BESO and RDO in various optimization problems. BESO applied to feature selection in cancer diagnosis demonstrated its effectiveness in handling high-dimensional data [17]. Similarly, RDO has shown promise in complex optimization tasks, as evidenced in protein structure prediction. However, the application of these algorithms to diabetes diagnosis using microarray data remains an open area of research. In terms of classification techniques, Support Vector Machines with Radial Basis Function kernel (SVM-RBF) have consistently shown strong performance in biomedical applications by achieving high accuracy using SVM-RBF for diabetes prediction from clinical data. The effectiveness of other classifiers such as Gaussian Mixture Models (GMMs), Expectation Maximization (EM), and Softmax Discriminant Classifier (SDC) in the context of diabetes diagnosis from gene expression data requires further exploration. While these studies have made significant contributions, there remains a need for comprehensive research that combines advanced feature extraction and selection techniques with state-of-the-art classification methods for diabetes diagnosis using microarray gene data. Table 1 represents the comparison of various machine learning approaches like various dimensionality reduction techniques and feature selection and classifiers of different datasets and accuracy.

Table 1.
Review of previous work.
2. Materials and Methods
As depicted in Figure 1, this research utilizes a multistage approach for accurate diabetes detection. The first stage focuses on extracting relevant features from the microarray gene data. Three techniques are utilized for this purpose—STFT, RR, and PCC. The second stage involves two roots—in one, extracted data are directly used by classifiers to measure the performance; in the second, data are used in the feature selection process. In this research, FS used two meta-heuristic algorithms, BESO and RDO. These algorithms can help identify the most informative features from the initial extraction stage, potentially leading to a more efficient classification process. Finally, the third stage utilizes various classification techniques to categorize the data into diabetic and non-diabetic classes by using seven methods—NLR, LR, GMMs, EM, LoR, SDC, and SVM-RBF.
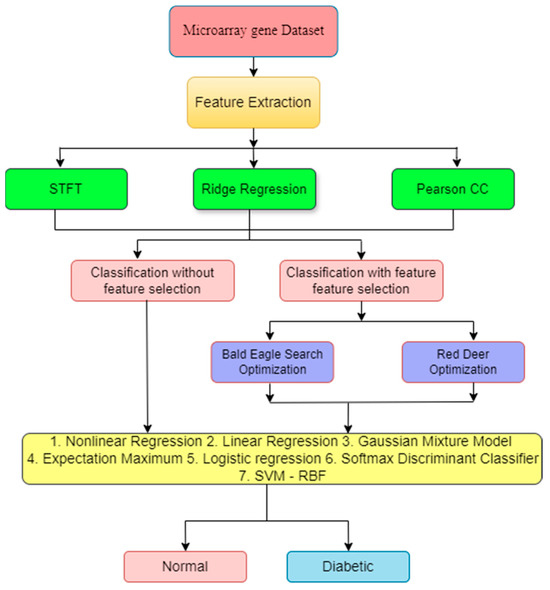
Figure 1.
Overall flow diagram.
2.1. Dataset Details
Our research focused on utilizing microarray gene data from human pancreatic islets to detect diabetes and explore potential features associated with the disease. The data originated from the Nordic islet transplantation program (https://www.ncbi.nlm.nih.gov/bioproject/PRJNA178122). The data has accessed on 20 August 2021 and included gene expression profiles from 57 healthy individuals and 20 diabetic patients. To ensure data quality and facilitate analysis, preprocessing steps were implemented. First, genes with the highest peak intensity per patient were selected, resulting in a dataset of 22,960 genes. Next, a logarithmic transformation (base 10) was applied to standardize the data across samples, ensuring a mean of 0 and a variance of 1. This step helps to normalize gene expression values and account for potential variations between samples. Table 2 shows the details about the datasets used in this article. A key challenge in microarray data analysis is dealing with high dimensionality, referring to the large number of genes present. To address this, we employed feature extraction techniques. These techniques aim to reduce the number of features while retaining the most informative content relevant to diabetes detection [30]. Following feature extraction, feature selection techniques were applied to further refine the dataset and potentially improve classification accuracy. Specifically, two optimization algorithms were utilized, BESO [31] and RDO [32]. These algorithms helped identify the most relevant features for diabetes detection, further reducing the dimensionality of the data. Finally, to evaluate the performance and accuracy of diabetes classification, seven different classification algorithms were used. These algorithms will be discussed in detail later in this article.
Table 2.
Details of the dataset before and after feature extraction and feature selection.
2.2. Need for Feature Extraction (FE)
Microarray data analysis presents a challenge due to its high dimensionality. This means the data include a vast number of genes, which can be overwhelming for classification algorithms. A high number of features can lead to a phenomenon called the “curse of dimensionality”. This occurs when the number of features [33] grows exponentially, making it difficult for classification algorithms to learn effective decision boundaries and potentially leading to overfitting. Feature extraction techniques help address this challenge by reducing the number of features while retaining the most informative ones for diabetes detection. This process essentially focuses the analysis on the most relevant aspects of the gene expression data that contribute to differentiating between diabetic and non-diabetic samples. FE acts as a filter, selecting the most informative features from the vast amount of gene expression data. This allows the classification algorithms to work with a more manageable dataset and ultimately leads to more accurate diabetes detection.
2.2.1. Short-Time Fourier Transform (STFT)
STFT offers a valuable technique for analyzing microarray gene expression data. It excels at capturing frequency domain information within specific time windows. This allows researchers to condense the dataset by extracting key features that represent how gene expression levels change over time and across various frequencies. Like its application in QRS complex detection by [34], STFT provides a time–frequency representation of gene expression data. This visualization facilitates exploration of how gene expression levels fluctuate across time and different frequency components. A key strength of STFT lies in its ability to pinpoint specific time intervals where frequencies are dominant. This allows researchers to identify genes with temporal patterns that activate during distinct time periods within the data. Additionally, STFT contributes to dimensionality reduction by extracting significant genes or groups of genes associated with specific frequency components [35]. This targeted approach streamlines the exploration of gene expression dynamics, ultimately aiding in the discovery of biologically relevant patterns within the data.
where is the input data, and length n is 0, 1, 2, …, n − 1; is the representation for the STFT window and is 0, 1, 2, …, m − 1. Moreover, is the complex variable.
2.2.2. Ridge Regression (RR)
The analysis begins by focusing on smaller groups of samples. For each group, a feature matrix () is created. This matrix includes information about each sample as data point in a row, along with its corresponding outcome in an outcome vector () [36]. Ridge Regression is then applied to this local data to identify patterns. The estimates obtained by applying Ridge Regression to these local groups are referred to as local Ridge Regression estimates.
Analyzing the estimation error in distributed Ridge Regression benefits from studying it within the framework of finite sample analysis for linear models. In this context, we consider the standard linear model, where Y represents the outcome variable, X is the feature matrix, b is the coefficient vector, and ε represents the error term. The outcome for each of the ‘n’ independent samples is represented by a continuous vector with ‘n’ dimensions. This study utilizes a data matrix, X, to represent the features of the samples. This matrix has dimensions n × p, where ‘n’ represents the number of samples and ‘p’ represents the number of features measured for each sample. We are also interested in a vector of coefficients, denoted by beta (β). This vector has ‘p’ dimensions and contains unknown values, which aim to estimate through analysis. These coefficients will ultimately reveal how much each feature contributes to the outcome variable we are trying to predict. This technique is employed for two main purposes: predicting the outcome variable for new samples and accurately estimating the influence of each feature (coefficient) on that outcome. However, it is important to consider that random errors or noise can significantly impact the outcome vector, , which represents the actual values that are trying to predict [37].
In linear models, we often assume that the errors in the outcome variable (represented by the vector ε) are independent of each other, have an average value of zero, and a constant variance . Ridge Regression is a popular technique for estimating the coefficients (β). Here, the equation for the same is:
The Ridge Regression technique incorporates a parameter known as lambda (λ), which plays a crucial role in tuning the model. This parameter offers several advantages when it comes to estimating the coefficients (β). One key benefit is that it helps to ‘shrink’ the coefficients obtained from Ordinary Least Squares regression, often leading to improved estimation accuracy. Now, let us consider a scenario where our data samples are spread across multiple locations or machines, represented by ‘q’ in total. In this case, we can partition the data for analysis as:
In distributed computing environments, where data are spread across multiple machines, approximate solutions for Ridge Regression are often preferred. This approach involves performing Ridge Regression locally on smaller subsets of the data ( at each machine [38]. To achieve this, local Ridge Regression with a regularization parameter is performed on each data subset (. The formula for these local ridge estimators is as follows:
Here,
- represents the locally estimated coefficient vector for a specific data subset.
- denotes the design matrix for the i-th data subset.
- represents the outcome vector for the i-th data subset.
- is the regularization parameter for the local Ridge Regression on the i-th subset.
- I is the identity matrix with the same dimension as .
By using a weighted one-shot distributed estimation summation, the local ridge estimators from each data subset are combined as:
where
- represents the final combined coefficient vector obtained from all data subsets.
- represents the weight assigned to the local estimator from the i-th data subset.
- represents the locally estimated coefficient vector for the i-th data subset (as defined earlier).
Unlike Ordinary Least Squares (OLS), the local Ridge Regression estimators we defined previously have some inherent bias. Due to this bias, there is no effect of imposing constraints on the weights used to combine them. This approach is particularly well suited for data matrices (X) with any covariance structure (). Assuming we have ‘n’ samples that are equally distributed across different machines, we can compute a local ridge estimator () for each data subset [39]. Additionally, we can estimate local values for the signal-to-noise ratio (SNR, represented by and the noise level for each subset). To find the optimal weights for combining these local estimators, we consider three key factors: m, m0, and λ.
2.2.3. Pearson’s Correlation Coefficient (PCC)
PCC [40] serves as a powerful statistical tool for analyzing microarray gene expression data in diabetes detection. It measures the strength and direction of the linear relationship between gene expression levels. High PCC values, positive or negative, indicate that gene expression levels tend to fluctuate together. This co-fluctuation can reveal underlying biological processes. Genes with strong positive PCC may be regulated by similar mechanisms, potentially impacting diabetes development. Conversely, genes with strong negative PCC might play opposing roles in cellular processes, with one potentially protective against diabetes while the other linked to disease progression.
By analyzing PCC values between gene pairs, we can identify potentially valuable genes for diabetes detection. Genes with strong positive correlations may act together to influence the diabetic state. Conversely, genes with strong negative correlations might represent opposing pathways with implications for disease development [41].
PCC analysis helps us understand how gene expression levels co-vary, ultimately aiding in the selection of informative gene sets that can be used to build robust models for accurate diabetes classification.
indicates the covariances between x and y.
indicated the Standard Deviation of x and y.
From Table 3, analyzing various features extracted from the data, STFT and RR show minimal class differences with a mean of 40.7 and a variance of approximately 11,700 between diabetic and non-diabetic groups, suggesting they might not be strong discriminators for diabetes. Slight variations in Skewness and Kurtosis for most features hint at some distributional differences between the classes. Sample and Shannon Entropy values are identical within each class but differ between them, potentially indicating distinct underlying data patterns. Higuchi’s Fractal Dimension [42], however, stands out with a clear distinction (approximately 1.1 for STFT and 2.0 for diabetic class data) between classes for all features, suggesting its potential value in diabetes detection. Finally, Canonical Correlation Analysis (CCA) reveals a significant difference between diabetic and non-diabetic classes for the diabetic class data (0.4031 vs. 0.0675). This highlights CCA’s potential to identify features within the diabetic class data that are relevant for diabetes classification [43]. Overall, the table emphasizes the importance of analyzing various statistical parameters to understand the characteristics of different features and their potential role in differentiating diabetic and non-diabetic samples. The observed variations in Skewness and Kurtosis suggest that the data may not follow a typical Gaussian (normal) distribution and might exhibit non-linear relationships. This can be further confirmed by visualizing the data using techniques like histograms, Normal Probability plots, and scatter plots of the feature extraction outputs.
Table 3.
Statistical analysis for different feature extraction techniques.
Figure 2 shows the Normal Probability plot of STFT for both diabetic and non-diabetic class, from the data points 1 to 4 as reference points, from 5 to 8 as upper bounds and from 9 to 12 as clustered variable points.
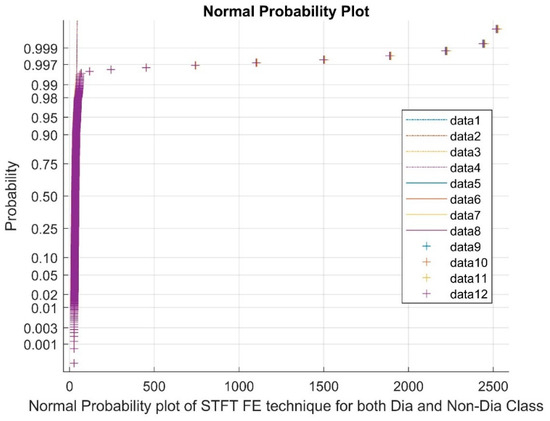
Figure 2.
Normal plot of STFT FE techniques for both diabetic and non-diabetic class.
Figure 3 shows the histograms of the RR FE technique applied to both diabetic and non-diabetic classes. While the distributions appear somewhat bell shaped, suggesting a possible tendency towards normality, a closer look reveals some deviations. Notably, there is an overlap between the distributions of the diabetic and non-diabetic classes. This overlap, along with potential deviations within each class distribution, suggests a more complex, non-linear relationship between the classes.
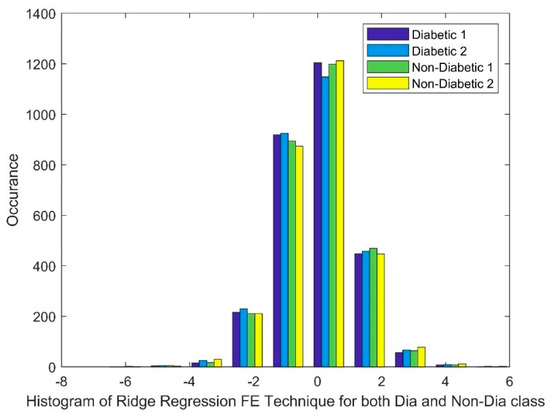
Figure 3.
Histogram of RR FE techniques for both diabetic and non-diabetic class.
Figure 4 displays histogram of the PCC FE technique applied to both diabetic and non-diabetic classes. The markers on the x-axis represent patients, with x(:,1) indicating patient 1 and x(:,10) indicating patient 10. The histograms reveal a skewed distribution of values, suggesting a non-normal data pattern. Additionally, a gap and potential non-linearity are observed in the data distribution for this method.
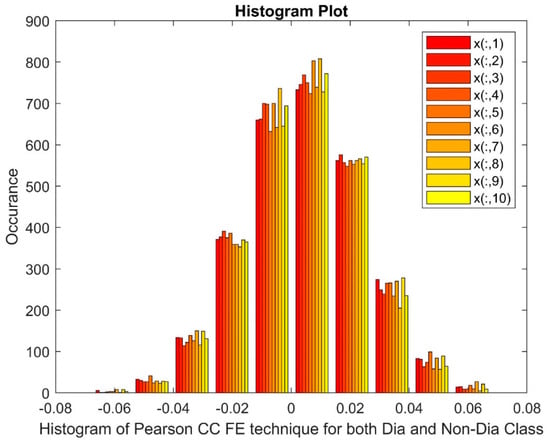
Figure 4.
Histogram of PCC FE techniques for both diabetic and non-diabetic class.
Fron all the techniques of FE, it is revealed that non-gaussian, non-linearity and techniques highlight the complexity of the data observed across the classes and the potential for further feature selection is essential.
3. Feature Selection Method
As mentioned in Section 1, there are two meta-heuristic algorithms, namely BESO and RDO, used as feature selection techniques that should be compared with and without the FS method from FE techniques to classifiers to enhance classifier performance.
3.1. Bald Eagle Search Optimization (BESO)
Bald Eagle Search Optimization (BESO) is a recent addition to the field of meta-heuristic algorithms. It draws inspiration from the hunting behavior of bald eagles, specifically their adeptness in locating and capturing prey. During the optimization process, BESO utilizes various search strategies modeled on these predatory behaviors. These strategies allow the search agents to explore the search space effectively, ultimately leading to the identification of optimal solutions for complex real-world problems.
- Step 1: Simulating Exploration: Selecting the Search Area
The BESO algorithm mimics the exploration phase of a bald eagle’s hunt through its first stage. In this stage, the algorithm determines a suitable search area for potential solutions, like how a bald eagle might scout a vast region for prey, which is mathematically stated as
A control parameter set between 1.5 and 2 guides the search area’s size, while a random number () between 0 and 1 introduces an element of chance, preventing stagnation in local optima. This exploration is further influenced by two key factors. The algorithm considers the best solution found so far to guide its search towards promising regions. Additionally, the average position of the current eagle population is factored in to ensure exploration extends beyond the immediate vicinity of the best solution and delves into new areas.
- Step 2: Intensifying the Search
The second stage of BESO intensifies the search for optimal solutions within the exploration area identified in phase one. This mimics the behavior of a bald eagle that has located a promising hunting ground. Here, the search agents meticulously scan the defined region. They follow a spiral-like pattern, like how a bald eagle might meticulously search a lake for fish. This focused search pattern allows the algorithm to efficiently explore the selected area and identify potential solutions with greater precision. The mathematically expression as:
where
The two random parameters, denoted as ‘a’ and ‘R’, control the search pattern within the chosen exploration area. These parameters influence the number of spirals undertaken by the search agents and the variation in their coiling shape. This element of randomness helps prevent the algorithm from becoming stuck in suboptimal solutions. By introducing variation in the search pattern, BESO encourages exploration of diverse positions within the search area, ultimately leading to the identification of more accurate solutions.
- Step 3: Convergence
The final stage of BESO, represents the convergence towards the optimal solution [44]. In this stage, the search agents gravitate towards the most promising position identified so far. This convergence process can be mathematically written as:
where
Two random parameters () play a crucial role in this stage. These parameters, ranging between 1 and 2, control the intensity of the search agents’ movement towards the best solution.
3.2. Red Deer Optimization (RDO)
Red Deer Optimization (RDO) is a recent metaheuristic algorithm inspired by the fascinating mating behavior of red deer during the rut, or breeding season. Introduced in 2016 [45], RDO mimics this natural process to find optimal solutions to complex problems. The algorithm starts with a random population of individuals, representing potential solutions to the diabetes detection problem. These individuals are analogous to red deer. The strongest individuals, like dominant males, are identified. These “stags” compete for influence over the remaining population, like how stags fight for harems of females during the rut. The outcome of this competition determines how solutions are combined to create new offspring, representing the next generation of potential solutions. Stronger “stags” have a greater chance of mating with more “hinds”, leading to a wider exploration of the solution space. Weaker individuals may still contribute, but to a lower extent. This process balances exploration and exploitation [46]—key aspects of optimization. Through this iterative process of selection, competition, and reproduction, RDO progressively refines the population towards improved solutions for diabetes detection. The final population contains the most promising solutions identified by the algorithm [47].
4. The RDO Algorithm
- (a)
- Initialization: Each RD is described by a set of variables, analogous to its genes. The number of variables (XNvar) corresponds to the number of genes. The values of these variables represent the potential contribution of each gene to diabetes detection, for instance, the set XNvar to 50, which means to account for investigations.
Initializing Individual Positions:
The position of each RD (Xi) is defined by this set of variables. Here, Xi would be a vector containing the values for each of the 50 genes (e.g., [θ1, θ2, …, θ50]). These initial values are assigned randomly.
- (b)
- Roaring: In the “roar stage”, each RD representing a potential gene selection for diabetes detection can explore its surrounding solution space based on the microarray gene data. Imagine each RD has neighboring solutions in this multidimensional space. Here, a RD can adjust its position, which means gene selection within this local area. The algorithm evaluates the fitness of both the original and the adjusted positions using a fitness function reflecting how well the gene selection differentiates between diabetic and non-diabetic cases.
An equation is used to update the RD positions,
Here, a1, a2, and a3 are the random factors between 0 and 1. and are the old and new positions of RDs. This process is akin to the RD exploring its surroundings and “roaring” if it finds a better location with a higher fitness value (B*) [48]. Such successful adjustments elevate the RD to commander status, signifying a promising solution for diabetes detection. Conversely, if the exploration yields a position (A*) with a lower fitness value compared to the original, the Red Deer remains a “stag”. These stags still have the chance to contribute in later stages of the algorithm. This roar stage essentially refines the initial population by focusing on the RD gene selections that demonstrate better potential for differentiating diabetic and non-diabetic cases based on the gene data.
- (c)
- Roar:
Following the roar stage, commanders engage in a unique form of competition with the remaining stags. This competition does not involve literal combat, but rather an exchange of information about their gene selections.
Each commander interacts with a set of randomly chosen stags. The fight’s outcome determines how much information, or details about their gene selections, the commander shares with the stags. Commanders with demonstrably better gene selections will share more information with the stags they compete with. Imagine commanders with promising solutions guiding the stags towards improvement. Here, commanders with demonstrably superior gene selections retain their position as leaders and share more knowledge with the stags. Conversely, if a stag’s gene selection shows potential during the competition, it might surpass the commander’s current selection. In such cases, the stag’s improved solution becomes the new leader, and the information flow is reversed.
- (d)
- Creation phase of harems:
Following the roar and fight stages, commanders are rewarded based on their performance. This reward system is reflected in the formation of harems. A harem consists of a commander and a group of hinds as female deer. The number of hinds a commander attracts is directly proportional to his success in the previous stages. Commanders with demonstrably superior gene selections will attract larger harems. Imagine a commander’s “power” being determined by how well its gene selection differentiates between diabetic and non-diabetic cases.
Commanders with greater power will attract more hinds to their harems. Stags, on the other hand, are not included in harems. This reward system incentivizes the continued exploration and refinement of promising gene selections for diabetes detection.
- (e)
- The mating phase in RDO occurs in three key scenarios: 1. Commander Mating Within Harems—Each commander has the opportunity to mate with a specific proportion (α) of the hinds within its harem. This mating metaphorically represents the creation of new gene selections based on combinations of the commander’s strong selection and those of the hinds. 2. Commander Expansion Beyond Harems—Commanders can potentially mate with hinds from other harems. A random harem is chosen, and its commander has the chance to “mate” with a certain percentage (β) (which lies between 0 and 1) of the hinds in other harems. 3. Stag Mating—Stags also have a chance to contribute. They can mate with the closest hind, regardless of harem boundaries. This allows even less successful gene selections to potentially contribute to the next generation, introducing some level of diversity. By incorporating these three mating scenarios, RDO explores a combination of promising gene selections, ventures beyond established solutions, and maintains some level of diversity through stag mating.
- (f)
- Mating phase—New solutions are created. This process combines the strengths of existing gene selections from commanders, hinds, and even stags, promoting a balance between inheritance and exploration. This approach helps refine the population towards more effective gene selections for diabetes detection using your microarray gene data.
- (g)
- Building the next generation—RDO employs a two-pronged approach to select individuals for the next generation. A portion of the strongest RD is automatically selected for the next generation. These individuals represent the most promising gene selections identified so far. Additional members for the next generation are chosen from the remaining hinds and the newly generated offspring. This selection process often utilizes techniques like fitness tournaments or roulette wheels, which favor individuals with better fitness values.
- (h)
- RDO’s stopping criterion to determine the number of Iterations—a set number of iterations can be predetermined as the stopping point. The algorithm might stop if it identifies a solution that surpasses a certain threshold of quality for differentiating diabetic and non-diabetic segregation. A time limit might also be set as the stopping criterion. The parameters of each value involved in this algorithm are described in Table 4.
Table 4. Parameters of RDO.
Based on the p-value selection criteria employed in Table 5, features extracted using STFT, RR, and PCC might not be the most informative for diabetes detection. This conclusion is drawn from analyzing p-values obtained through t-tests for various FE methods for two FS techniques as BESO and RDO were revealed that p-values can serve as initial indicators to quantify the potential presence of outliers, non-linearity, and non-Gaussian data distributions within the classes. Further analysis may be necessary to identify the most statistically significant features for accurate diabetes classification.
Table 5.
Utilizing p-values for feature selection in diabetes detection: A comparison of various FE techniques.
Analyzing the Impact of Feature Extraction Methods Using Statistical Measures
The PCM analyses of gene expression in diabetic and non-diabetic patients reveal crucial insights into the relationships between different genes. Diabetic patients show a broader range of strong positive and negative correlations, indicating clusters of co-expressed genes and genes with opposing expression patterns. In contrast, non-diabetic patients exhibit weaker correlations and a more diverse expression pattern. Identifying these patterns is essential for understanding the underlying mechanisms of diabetes and for discovering potential biomarkers for diagnosis and treatment. The analysis of the Pearson Correlation Matrix (PCM) [49] in both diabetic and non-diabetic patients reveals significant insights into gene expression patterns. In diabetic patients, the STFT BESO values range from −0.69 to 0.98, with strong positive correlations such as 0.98 between var1 and var2, and negative correlations like −0.69 between var3 and var6, indicating clusters of co-expressed genes and opposing expression patterns. For non-diabetic patients, the RR BESO values range from −0.94 to 0.78, showing weaker correlations overall, with notable positive correlations such as 0.68 between var1 and var5, and negative correlations like −0.64 between var1 and var3, suggesting a more diverse gene expression pattern (Figure 5). Another PCM analysis for non-diabetic patients shows values ranging from −0.54 to 0.86, with significant correlations including a strong 0.83 between var2 and var5, and a negative −0.34 between var2 and var3, providing a baseline for comparison. An additional PCM for diabetic patients indicates values from 0.11 to 0.68, with a notable positive 0.92 between var4 and var6, and a negative −0.47 between var5 and var6, reinforcing the presence of significant gene clusters (Figure 6).
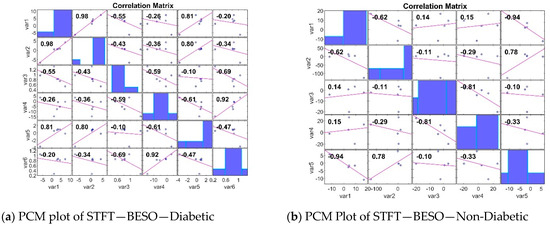
Figure 5.
PCM plots for the STFT FE method.
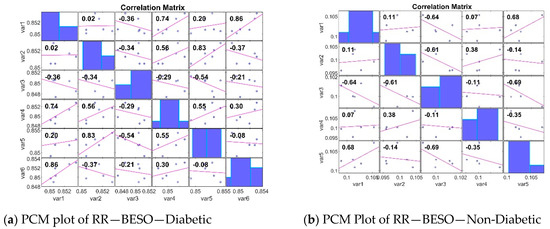
Figure 6.
PCM Plots for the RR FE method.
5. Classifiers
FE acts like a filter, selecting the most informative data tidbits from the massive count of gene expressions. However, these informative features alone are not enough to diagnose diabetes. Here is where classifiers come in as powerful tools. They analyze the selected features, learning the subtle patterns that differentiate diabetic from non-diabetic samples. These patterns can be complex and non-linear, making them difficult to identify by hand. Classifiers ultimately leverage this knowledge to make automated and accurate classifications of new, unseen diabetic cases.
5.1. Non-Linear Regression
While standard Linear Regression assumes a straightforward, linear relationship between variables, Non-Linear Regression emerges as a powerful tool for diabetes detection. It tackles the challenge of complex relationships that might exist between features extracted from gene expression data and the presence of diabetes. The core principle involves modeling the relationship between extracted features and the diabetic state using a specific mathematical function that captures the non-linearity [50]. The model strives to minimize the sum of squared errors between the predicted diabetic state and the actual diabetic state for each data point. Imagine finding the best-fitting non-linear curve that represents the data.
Least squares estimation then comes into play to determine the unknown parameters within the chosen non-linear function. These parameters define the shape and characteristics of this non-linear relationship. After training the model with known diabetic and non-diabetic data points, the estimated non-linear function can predict the diabetic state for new, unseen cases based on their extracted features. A threshold probability or value can be established to classify the predicted state as diabetic or non-diabetic. This approach offers a valuable technique for leveraging the complexities within gene expression data for improved diabetes detection.
Non-Linear Regression centers on the concept of an expectation function, typically denoted by . This function represents the predicted value of the dependent variable (often signifying the diabetic state) based on the independent variables (also known as features extracted from gene expression data) for each data point. Here is the key difference between non-linear and linear models: in Non-Linear Regression, at least one parameter () for each data point () must influence one or more derivatives of the expectation function.
5.2. Linear Regression
Linear Regression [51], a basis of statistical analysis, excels at modeling linear relationships between variables. However, in the realm of diabetes detection, it falls short as a primary classification tool, Linear Regression assumes a straight-line connection between the features extracted from gene expression data (independent variables) and the diabetic state (dependent variable). This linearity might not reflect the true complexities of the underlying biology. Diabetic development can involve intricate, non-linear relationships that Linear Regression might miss, leading to inaccurate classifications. Next, diabetes detection is inherently a binary classification problem. While applying a threshold might seem straightforward, it can be suboptimal for capturing the nuances of the data and the disease itself.
5.3. Gaussian Mixture Models
Gaussian Mixture Models (GMMs) [52] shine as powerful tools for unsupervised machine learning. Unlike techniques requiring labeled data, GMMs excel at uncovering hidden structures within complex datasets like gene expression profiles. GMMs act like detectives, searching for hidden patterns in the data. They can automatically group similar gene expression profiles into clusters, potentially revealing subgroups within the diabetic or non-diabetic population. Unlike rigid clustering methods, GMMs employ a softer approach. They assign probabilities to each cluster for a given data point, allowing for potential overlap between clusters. This flexibility reflects the inherent complexities of diseases like diabetes, where gene expression patterns might not be perfectly distinct.
GMMs assume that the data are from a blend of multiple, simpler Gaussian distributions [53].
Within the Gaussian distribution formula, the symbol denotes the mean vector, representing the average position of the data points in the n-dimensional space. represents the covariance matrix, which captures the relationships between the different features (dimensions) within the data. The determinant of the covariance matrix, denoted by ||, plays a role in calculating the overall spread of the data around the mean. Finally, the function is used to calculate the probability density of a particular data point within the Gaussian distribution.
By uncovering hidden structures and capturing the complexities of gene expression data, GMMs provide valuable insights for researchers exploring novel approaches to diabetes detection.
5.4. Expectation Maximum
The EM algorithm emerges as a powerful tool for addressing missing information or hidden factors [54,55]. The EM algorithm acts like a skilled detective in diabetes detection. Two-step process such as:
- Expectation Step: In this initial step, the EM algorithm estimates the missing information, or hidden factors based on the currently available data and the current model parameters.
- Maximization Step: With the estimated missing values in place, the EM algorithm then refines the model parameters by considering the newly completed data.
Figure 7 represents the flow diagram of EM algorithm. Through this iterative process of estimating missing information and then improving the model based on those estimates, the EM algorithm gradually uncovers the underlying structure and parameters governing the distribution of gene expression data. This ultimately leads to a more accurate classification of diabetic and non-diabetic cases.
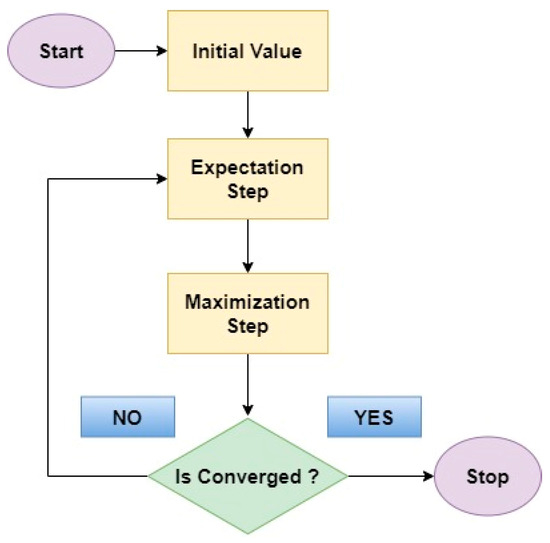
Figure 7.
Flow diagram of EM algorithm.
5.5. Logistic Regression
LR establishes itself as a powerful tool for binary classification tasks, proving its worth in decoding the complexities of diabetes detection. Like its role in identifying alcoholic tendencies, Logistic Regression [56] estimates the probability of an individual developing diabetes based on a collection of factors. The initial phase involves meticulously gathering relevant data on potential risk factors from a sample population. The collected data are then strategically divided into two distinct sets. The training set serves as the foundation for building the Logistic Regression model, while the testing set acts as an impartial evaluator, assessing the model’s accuracy in predicting new diabetic cases. The LR model [57] meticulously analyzes the training data. Once the model is fully trained and refined, it can be leveraged to predict the probability of diabetes in new individuals based solely on their specific risk factors.
The objective is to optimize both the fitness and log-likelihood, which can be achieved by attaining the subsequent function:
5.6. Softmax Discriminant Classifier
SDC is an ingenious approach that leverages the power of an individual’s genetic makeup to predict their potential diabetes risk. SDC [58] is meticulously analyzing a person’s genes. It employs a specialized tool—a discriminant function—that acts like a comparison chart. This function compares the genetic profile against those of individuals confirmed to have or not have diabetes. The key strength of SDC lies in its ability to learn and adapt. The goal is to establish clear boundaries between these two groups, enabling accurate classification of new cases. When presented with a new genetic profile, SDC compares it to the learned patterns. By analyzing the closest match, SDC can estimate the likelihood of an individual developing diabetes.
The process of transforming class samples and test samples in SDC incorporates non-linear enhancement values, which are calculated utilizing the subsequent equations:
In these formulas, represents the distinction of the i-th class, and as converges to zero, is maximized. This characteristic ensures that the test sample is most likely to belong to a particular class.
5.7. Support Vector Machine (Radial Basis Function)
Support Vector Machines (SVMs) are a powerful machine learning technique well suited for classification tasks like diabetes detection. Unlike Linear Regression, SVMs can handle non-linear relationships between features extracted from gene expression data and the diabetic state. SVMs [59] can map the extracted features of initially existing in a lower-dimensional space into a higher-dimensional space. This transformation allows the data points to be separated more effectively using a hyperplane, even if the original relationship between features and the diabetic state was non-linear. RBF kernel is a popular choice for SVM classification. It acts like a bridge, calculating the similarity between data points in the higher-dimensional space. This similarity measure is then used by the SVM algorithm to identify the optimal hyperplane that best separates diabetic from non-diabetic data points in this transformed space. Once the optimal hyperplane is established, new, unseen data points can be mapped into the same higher-dimensional space using the RBF kernel. Their position relative to the hyperplane allows the SVM to classify them as diabetic or non-diabetic.
By effectively handling non-linearities and leveraging the RBF kernel for similarity calculations, SVMs offer a robust approach to classifying diabetic cases based on gene expression data.
5.8. Selection of Classifiers Parameters through Training and Testing
To ensure the model’s generalizability despite limited data, a robust technique called 10-fold cross-validation is employed. This method splits the data into 10 equal folds, trains the model on 9 folds, and tests it on the remaining fold. This process is repeated for all folds, providing a more reliable estimate of the model’s performance on unseen data compared to a single test/train split. Additionally, the model was trained on a dataset containing 2870 features per patient for 20 diabetic and 50 non-diabetic individuals. This comprehensive training process, combined with k-fold cross-validation, strengthens the reliability of the findings. The training process is measured in the MSE as:
is the actual value observed at a specific time, and is the target value the model predicts for that time.
6. Classifiers Training and Testing
Table 6 represents the confusion matrix for diabetes detection and the parameters are defined as follows:
Table 6.
Confusion matrix of diabetic and non-diabetic classification.
- TP (True Positive): Catches diabetic patients.
- TN (True Negative): Identifies healthy people.
- FP (False Positive): Mistakes a healthy person for diabetic.
- FN (False Negative): Misses a diabetic person.
Table 7 directly compares the Mean Squared Error (MSE) on both the training data it learns from (Train MSE) and unseen test data (Test MSE), with lower MSE indicating better performance. The highest values achieved as Support Vector Machine (SVM) with an RBF kernel, achieving exceptionally low MSE on both training and test data (Train MSE: 1.88 × 10−6, Test MSE: 1 × 10−6). Statistical models, like Ridge Regression (Train MSE: 7.29 × 10−6, Test MSE: 3.25 × 10−5), Linear Regression (Train MSE: 1.16 × 10−5, Test MSE: 1.94 × 10−5), and Logistic Regression with L1 penalty (LoR) (Train MSE: 2.7 × 10−5, Test MSE: 3.02 × 10−5) also show promise with consistently low MSE values. Mixture models, Gaussian Mixture Models (GMMs) (Train MSE: 1.02 × 10−5, Test MSE: 1.48 × 10−5) and Expectation Maximization (EM) (Train MSE: 5.29 × 10−6, Test MSE: 1.37 × 10−5), demonstrate competitive results. Notably, STFT and PCC have higher MSE values across both Train and Test data, suggesting they may not be as effective for this specific diabetes detection task. Note that all models exhibit lower MSE on the training data compared to test data, indicating some degree of overfitting. This underscores the importance of evaluating models using unseen test data to ensure they generalize well to new cases.
Table 7.
Mean Squared Error analysis for different FE techniques without feature selection.
In Table 8, SVM with an RBF kernel maintains its dominant position (Train MSE: 2.18 × 10−6, Test MSE: 1.44 × 10−6). It achieves exceptionally low MSE on both the training data it learns from and unseen test data. Statistical models show mixed results. Ridge Regression (Train MSE: 1.44 × 10−5, Test MSE: 2.21 × 10−5) performs consistently, while LR (Train MSE: 3.76 × 10−5, Test MSE: 2.3 × 10−5) delivers slightly higher training MSE but achieves a lower test MSE. Logistic Regression with L1 penalty (Train MSE: 9.97 × 10−6, Test MSE: 1.76 × 10−5) demonstrates the most significant improvement in test MSE compared to training MSE. Mixture models present a similar picture. The GMM exhibits a significant jump in Test MSE (3.97 × 10−4) compared to Train MSE (4.51 × 10−5), suggesting potential overfitting. EM shows more balanced performance (Train MSE: 3.14 × 10−4, Test MSE: 1.37 × 10−5). Like the previous table, STFT and PCC remain less competitive in this task, evident from their higher MSE values across both Train and Test data (above 5.00×10−5 for most cases). An interesting observation is the significant reduction in Test MSE for SDC (Softmax Discriminant Classifier) compared to the previous table (Train MSE: 2.21 × 10−5, Test MSE: 1.6 × 10−5 to Train MSE: 2.81 × 10−6, Test MSE: 2.81 × 10−4). This suggests potential improvements in model generalizability. Overall, SVM with RBF kernel remains the leader, while statistical and mixture models show varying effectiveness depending on the specific model and its ability to generalize to unseen data. The significant reduction in SDC’s Test MSE warrants further investigation into its potential for diabetes detection.
Table 8.
Mean Squared Error analysis for different feature extraction techniques with Bald Eagle Search Optimization (BESO) feature selection.
In Table 9, SVM with an RBF kernel maintains its exceptional performance (Train MSE: 4.25 × 10−7, Test MSE: 3.6 × 10−7). It achieves remarkably low MSE on both the training and unseen test data, solidifying its position as the leading contender. Statistical models show further improvement. LoR (Train MSE: 4.85 × 10−5, Test MSE: 1.96 × 10−6) demonstrates a significant decrease in Test MSE compared to the previous table. Logistic Regression with L1 penalty (LoR) (Train MSE: 1.39 × 10−5, Test MSE: 2.25 × 10−6) also exhibits a positive trend with lower Test MSE. However, RR (Train MSE: 6.08 × 10−5, Test MSE: 9 × 10−6) shows a slight increase in Test MSE. Mixture models present a more promising picture in this table. The GMM achieves a significant reduction in both Train MSE (9.01 × 10−6) and Test MSE (4.41 × 10−6), suggesting potential improvements in addressing overfitting. EM maintains consistent performance (Train MSE: 3.51 × 10−5, Test MSE: 7.29 × 10−6). Like previous observations, STFT and PCC remain less competitive (Train and Test MSE values above 5.00 × 10−6). The most significant improvement is seen with SDC. It achieves exceptionally low Test MSE (1.96 × 10−6) compared to both previous tables (Train MSE: 1.35 × 10−5, Test MSE: 2.89 × 10−6). This dramatic reduction in Test MSE warrants further investigation into the potential of SDC for diabetes detection, especially considering its consistent Train MSE across all three tables.
Table 9.
Mean Squared Error analysis for different feature extraction techniques with Red Deer Optimization (RDO) feature selection.
Overall, SVM with RBF kernel remains the frontrunner. Statistical and mixture models demonstrate ongoing optimization, with Logistic Regression and GMMs showing the most notable improvements. The remarkable performance boost of SDC in this table highlights its potential as a viable approach for diabetes detection.
Selection of Targets
The target value for the non-diabetic class () ranges from 0 to 1, with emphasis on the lower end of the scale. This range is determined by a specific constraint [60].
Here, denotes the mean value of the input feature vectors considered for classification across N non-diabetic features. Similarly, in the case of the diabetic class (), the target value is aligned with the upper range of the 0 to 1 scale. This alignment is determined by the following principle as:
In this context, represents the average value of input feature vectors for the M diabetic cases considered in classification. It is crucial to note that the target value ) is deliberately set higher than the average values of both and . This choice of target values mandates a minimum discrepancy between them of 0.5, as stated below,
The target values for non-diabetic () and diabetic () cases are set at 0.1 and 0.85, respectively. After setting the targets, MSE is employed to assess classifier performance. Table 10 illustrates the optimal parameter selection for the classifiers following the training and testing phases.
Table 10.
Classifiers optimal parameters.
7. Outcomes and Findings
The evaluation approach ensures robust assessment of the models’ effectiveness in classifying diabetic patients. Researchers employ a widely used technique called “tenfold cross-validation”. Here, the data are meticulously divided into 10 equal sets. Nine of these sets (representing 90% of the data) are used to train the models. The remaining set (10%) serves a crucial purpose—testing the model’s performance on unseen data. This approach helps mitigate overfitting and provides a more reliable picture of how the models would perform in real-world scenarios. To go beyond simple accuracy, we leverage a valuable tool called a confusion matrix. This matrix allows us to calculate a comprehensive set of performance metrics. These metrics include accuracy (overall percentage of correct predictions), F1 score (balances precision and recall), MCC (considers true positives/negatives for a more robust evaluation), Jaccard Metric (measures the shared proportion of positive predictions between the model and the ground truth), Error Rate (percentage of incorrect predictions), and Kappa statistic [61] (measures agreement beyond chance). By analyzing these metrics derived from the confusion matrix, we gain a deeper understanding of the models’ strengths and weaknesses in distinguishing between diabetic and non-diabetic cases. Table 11 shows which methods are employed to calculate the performance metrics mentioned. This table provides a transparent view of the evaluation process and allows for further analysis of the models’ configuration.
Table 11.
Performance metrics.
The result of the above metrics for evaluation of the performance in each classifier is given in Table 12.
Table 12.
Analysis of different parameters with different classifiers through various FE techniques without feature selection techniques.
From Table 12, SVM with an RBF kernel solidified its dominance. It achieved the highest overall accuracy (92.8571%), F1 score (85.71%), Matthews Correlation Coefficient (MCC) (0.7979), and Jaccard similarity (75%), demonstrating its exceptional ability to distinguish between diabetic and non-diabetic cases With PCC as FE. Conversely, RR exhibited the lowest performance across most metrics, suggesting that it may not be suitable for this task. While the choice of feature extraction technique appears less impactful than the model itself (except for PCC), some interesting observations emerged. The combination of STFT and RR yielded the lowest overall performance (average accuracy of 80%), indicating RR might be less effective here. Excluding these outliers (SVM and Pearson CC), the average accuracy for other models ranged from 81% to 84%, with F1 scores between 72% and 74% and MCC values between 0.60 and 0.65. Overall, SVM with an RBF kernel emerged as the strongest contender for diabetes detection due to its consistent performance across various feature extraction techniques. While other models like NLR and SDC showed promise, further investigation might be necessary to evaluate their generalizability and confirm their effectiveness.
From Figure 8, SVM with an RBF kernel consistently achieved the highest values across all performance metrics, demonstrating its exceptional ability to distinguish diabetic from non-diabetic cases. For instance, we observed exceptional accuracy (approximately 85%) and F1 score (approximately 80%) for SVM with RBF compared to other models. While the choice of FE technique seems to have a lower impact on overall performance compared to the model itself (except for RR), one noteworthy observation emerged. RR, when combined with any feature extraction technique, yielded the lowest performance. Excluding RR and the outliers (SVM and Pearson CC), other models exhibited average accuracy ranging from 80% to 85%, with F1 scores between 70% and 75%. Overall, SVM with RBF kernel stands out as the most promising approach for diabetes detection based on its consistently high performance across various feature extraction techniques. While other models like NLR, SDC, and some with other feature extraction techniques show promise, further investigation might be necessary to evaluate their generalizability and confirm their effectiveness.
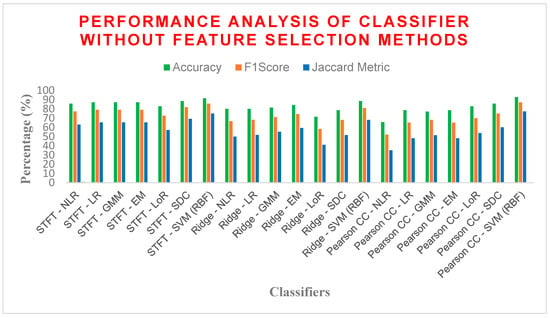
Figure 8.
Performance analysis of different classifiers without the FS method.
From Table 13, SVM with RBF kernel solidified its dominance. It achieved the highest overall accuracy (92.86%), F1 score (87.80%), Matthews Correlation Coefficient (MCC) (0.8280), and Jaccard similarity (78.26%), demonstrating its exceptional ability to distinguish between diabetic and non-diabetic cases with PCC as FE for BESO FS. Conversely, PCC with NLR exhibited the lowest performance across most metrics, with accuracy as low as 57.14%, a F1 score of 44.44%, and a MCC of 0.1446. Examining the impact of FE techniques revealed some interesting insights. The pairing of STFT with RR yielded a moderate average accuracy of 78%, indicating RR might be less effective here. However, excluding RR techniques, with STFT in NLR, LoR, GMMs, EM achieved similar average accuracy (ranging from 80% to 84%) when combined with SVM (RBF), as high as 91.42%. This highlights the consistent performance of SVM (RBF) across various FE methods. In conclusion, SVM with an RBF kernel emerged as the strongest contender for diabetes detection based on its consistently high performance across different FE techniques.
Table 13.
Analysis of different parameters with different classifiers through various FE techniques with Bald Eagle Search Optimization feature selection techniques.
Figure 9 revealed SVM with RBF kernel as the strongest classifier for diabetes detection, achieving exceptional performance (accuracy > 92%, F1 score > 87%, MCC > 0.82, Jaccard > 78%). Interestingly, the choice of feature extraction technique had less impact, except for Ridge Regression, which yielded the lowest performance across all techniques. While other models like NLR, LR, GMMs, EM, and SDC showed promise, SVM with RBF kernel emerged as the leader due to its consistent effectiveness.
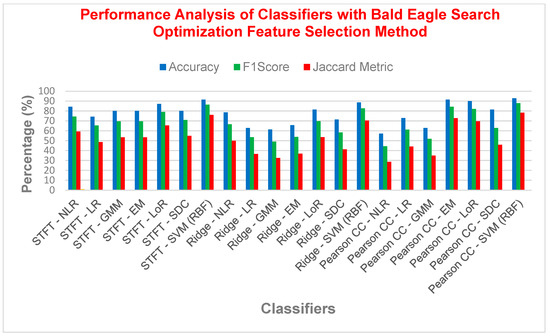
Figure 9.
Performance analysis of different classifier with the Bald Eagle Search Optimization FS method.
From Table 14, it is observed that the diabetes detection models revealed SVM with RBF kernel as the champion, achieving exceptional results (accuracy reached the highest ever as 97.14%, F1 score reaches 95%, MCC exceeds 0.93, Jaccard exceeds 90%). This dominance is evident compared to the lowest performing model, Pearson CC with NLR, which obtained an accuracy as low as 62%, a F1 score of 48%, and a MCC of 0.22. Excluding these outliers, the average performance across models ranged from 80% to 85% accuracy, 70% to 78% F1 score, and 0.55 to 0.65 MCC. Interestingly, the choice of feature extraction technique seems to have a lower impact on performance, except for Ridge Regression. It consistently yielded the lowest values (accuracy approximately 65%, F1 score approximately 55%, MCC approximately 0.30) regardless of the technique used. Techniques like NLR, LR, GMMs, EM, LoR, and SDC performed similarly well with SVM (RBF), all achieving average accuracy above 80%. This highlights the robustness of SVM with RBF across various feature extraction approaches.
Table 14.
Analysis of different parameters with different classifiers through various FE techniques with Red Deer Optimization feature selection techniques.
From Figure 10, it is observed that from the analysis of diabetes detection models, SVM with RBF kernel emerged as the clear leader, achieving over 97% accuracy, with F1 score exceeding 95% and MCC surpassing 0.93. Interestingly, the choice of feature extraction method had minimal impact on performance, as models like NLR, LR, GMMs, EM, LoR, and SDC performed similarly well with SVM (RBF), all achieving an average accuracy of over 80%. However, Ridge Regression consistently underperformed across all metrics, suggesting that it may not be the best choice for this task. Overall, SVM with RBF kernel demonstrated exceptional and consistent performance, making it the top contender for diabetes detection.
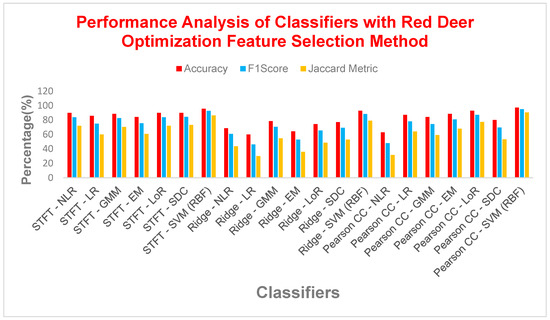
Figure 10.
Performance analysis of various classifiers with the Red Deer Optimization FS method.
Figure 11 illustrates the performance of the Jaccard Metric and Error Rate (%) parameters through histograms. It is observed that the maximum Error Rate stabilizes at 50%, while the maximum Jaccard Metric reaches 90%. The histogram representing the Error Rate is skewed towards the right side of the graph, indicating that regardless of the feature extraction method or feature selection method employed, the classifier’s Error Rate remains below 50%. On the other hand, the histogram of the Jaccard Metric displays sparsity towards the edges and covers a greater number of points in the central area across the classifier.
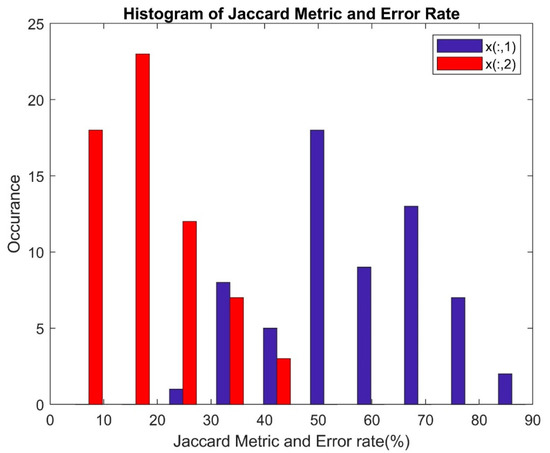
Figure 11.
Performance of Jaccard Metric and Error Rate.
7.1. Computational Complexity
This study evaluates classifiers based on their Computational Complexity (CC), specifically focusing on how it scales with the size of the input data (denoted as O(n)). Ideally, a classifier should have a low CC, represented as O(1). This indicates that the algorithm’s complexity remains constant regardless of how much data it needs to process. This is a desirable characteristic because it ensures efficient performance even with large datasets. Interestingly, the analysis highlights that the CC in these models is independent of the input size, further emphasizing their efficiency. However, the text also mentions that some models exhibit a logarithmic complexity (O(log n)) as the data size increases. Additionally, the study explores hybrid models that incorporate DR techniques and feature selection methods within their classification process. These techniques can potentially influence the CC of the overall model.
Table 15 reveals a range of complexities across the classifiers. NLR, LR, LoR, and SDC show a complexity of O(n2 logn) during training and then increase to O(2n2 log2n) or O(2n2 logn) for prediction. GMMs and EM are slightly more complex, reaching O(n2 log2n) in training and O(2n3 log2n) for prediction. However, SVM (RBF) stands out as the most computationally demanding, reaching O(2n4 log2n) during training and a slightly lower O(2n2 log4n) for prediction. In conclusion, the chosen classifier and FE technique significantly impact the computational cost of your analysis. While all classifiers show increased complexity due to the FE techniques, SVM (RBF) is the most demanding. For large datasets and a balance between efficiency and potentially good performance, consider classifiers like NLR, LR, or LoR with these FE techniques.
Table 15.
Computational Complexity of different classifiers without feature selection.
Table 16 reveals a range of complexities. NLR, LR, and LoR show a complexity of O(n4 logn) during training and then increase to O(2n4 log2n) for prediction. GMMs and EM are slightly more complex, reaching O(n4 log2n) in training and O(2n5 log2n) for prediction. However, SVM (RBF) stands out as the most demanding, reaching a staggering O(2n6 log2n) during training and a slightly lower O(2n4 log4n) for prediction. In conclusion, both the chosen classifier and FE technique significantly impact the computational cost of your analysis. While all classifiers show increased complexity due to the FE techniques, SVM (RBF) is the most challenging.
Table 16.
Computational Complexity of different classifiers with BESO features selection.
Table 17 reveals the impact of FE techniques, such as STFT, Ridge Regression, and Pearson CC, on overall complexity with RDO FS techniques. These techniques introduce additional computations, leading to a notable increase in CC across all classifiers. The table provided illustrates a spectrum of complexities for classifiers employed with these FE techniques. NLR, LR, and LoR exhibit a complexity of O(n5 logn), while GMMs and EM are slightly more complex, reaching O(n5 log2n). SDC demonstrates a complexity of O(n6 logn). However, SVM (RBF) stands out as the most demanding, with a staggering complexity of O(2n7 log2n). Regarding feature selection, it is crucial to note that this analysis solely focuses on CC based on the chosen FE techniques. Techniques like RDO for feature selection have the potential to reduce the number of features utilized in the classification process, significantly lowering the overall complexity of the model compared to using all features.
Table 17.
Computational Complexity of different classifiers with RDO features selection.
7.2. Limitations
Table 18 compares the results are various machine learning methods in terms of accuracy prediction. Investigated the potential of using microarray gene data to identify type 2 diabetes early and potentially predict associated diseases. The analysis revealed promising classification techniques that could be valuable for screening and identifying diabetes markers, along with potentially linked diseases like strokes and kidney problems. While the findings may be specific to this patient group and require further validation, they pave the way for future research. The methods used, such as microarrays, might not be readily available in all settings due to cost and complexity. However, this study lays the groundwork for developing more accessible and efficient approaches for early diabetes detection and disease management. Overall, this research highlights the potential for early detection of type 2 diabetes and associated diseases, emphasizing the importance of further research to validate these findings and develop more accessible screening methods for improved patient outcomes.
Table 18.
Comparison with previous work.
7.3. Conclusions and Future Work
This analysis explored various FE techniques (STFT, Ridge Regression, and PCC) and feature selection methods (BESO and RDO) for their impact on classifier performance in detecting Type II DM using microarray gene data. While RR with RDO FS yielded lower accuracy, STFT and PCC showcased improved performance metrics, particularly for the SVM (RBF) classifier. Notably, the combination of SVM (RBF) and RDO achieved the highest accuracy (92.85%) even without feature selection. However, employing RDO alongside SVM (RBF) still resulted in the highest accuracy across all FE techniques (95%, 92%, and 97.14% for STFT, RR, and PCC, respectively). BESO also yielded promising results, achieving high accuracy values (approximately 90%) with all three FE techniques. Interestingly, Computational Complexity remained similar across classifiers with different dimensionality reduction methods, highlighting the crucial role of feature selection in boosting accuracy. In conclusion, this study presents a novel approach for Type II DM detection using microarrays. Future research will explore the application of Convolutional Neural Networks (CNNs), Deep Learning Networks (DNNs), and Long Short-Term Memory (LSTM) networks, along with hyperparameter tuning for further performance optimization.
Author Contributions
Conceptualization, D.C and H.R.; methodology, D.C. and H.R.; software, D.C.; validation, H.R.; formal analysis, D.C. and H.R.; investigation, D.C. and H.R.; resources, D.C. and H.R.; data curation, H.R.; writing—original draft, D.C.; writing—review and editing, H.R.; visualization, D.C.; supervision, H.R. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Saeedi, P.; Petersohn, I.; Salpea, P.; Malanda, B.; Karuranga, S.; Unwin, N.; Colagiuri, S.; Guariguata, L.; Motala, A.A.; Ogurtsova, K.; et al. Global and regional diabetes prevalence estimates for 2019 and projections for 2030 and 2045: Results from the International Diabetes Federation Diabetes Atlas. Diabetes Res. Clin. Pract. 2019, 157, 107843. [Google Scholar] [CrossRef] [PubMed]
- Mohan, V.; Sudha, V.; Shobana, S.; Gayathri, R.; Krishnaswamy, K. Are unhealthy diets contributing to the rapid rise of type 2 diabetes in India? J. Nutr. 2023, 153, 940–948. [Google Scholar] [CrossRef]
- Oberoi, S.; Kansra, P. Economic menace of diabetes in India: A systematic review. Int. J. Diabetes Dev. Ctries. 2020, 40, 464–475. [Google Scholar] [CrossRef] [PubMed]
- American Diabetes Association Professional Practice Committee. 2. Classification and diagnosis of diabetes: Standards of Medical Care in Diabetes—2022. Diabetes Care 2022, 45 (Suppl. 1), S17–S38. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Ding, J.; Zhi, D.U.; Gu, K.; Wang, H. Identification of type 2 diabetes based on a ten-gene biomarker prediction model constructed using a support vector machine algorithm. BioMed Res. Int. 2022, 2022, 1230761. [Google Scholar] [CrossRef] [PubMed]
- Mahendran, N.; Durai Raj Vincent, P.M.; Srinivasan, K.; Chang, C.-Y. Machine learning based computational gene selection models: A survey, performance evaluation, open issues, and future research directions. Front. Genet. 2020, 11, 603808. [Google Scholar] [CrossRef] [PubMed]
- Shivahare, B.D.; Singh, J.; Ravi, V.; Chandan, R.R.; Alahmadi, T.J.; Singh, P.; Diwakar, M. Delving into Machine Learning’s Influence on Disease Diagnosis and Prediction. Open Public Health J. 2024, 17, e18749445297804. [Google Scholar] [CrossRef]
- Chellappan, D.; Rajaguru, H. Detection of Diabetes through Microarray Genes with Enhancement of Classifiers Performance. Diagnostics 2023, 13, 2654. [Google Scholar] [CrossRef]
- Gowthami, S.; Reddy, R.V.S.; Ahmed, M.R. Exploring the effectiveness of machine learning algorithms for early detection of Type-2 Diabetes Mellitus. Meas. Sens. 2024, 31, 100983.c. [Google Scholar]
- Tasin, I.; Nabil, T.U.; Islam, S.; Khan, R. Diabetes prediction using machine learning and explainable AI techniques. Healthc. Technol. Lett. 2023, 10, 1–10. [Google Scholar] [CrossRef]
- Frasca, M.; La Torre, D.; Pravettoni, G.; Cutica, I. Explainable and interpretable artificial intelligence in medicine: A systematic bibliometric review. Discov. Artif. Intell. 2024, 4, 15. [Google Scholar] [CrossRef]
- Chaddad, A.; Peng, J.; Xu, J.; Bouridane, A. Survey of explainable AI techniques in healthcare. Sensors 2023, 23, 634. [Google Scholar] [CrossRef] [PubMed]
- Hussain, F.; Hussain, R.; Hossain, E. Explainable artificial intelligence (XAI): An engineering perspective. arXiv 2021, arXiv:2101.03613. [Google Scholar]
- Markus, A.F.; Kors, J.A.; Rijnbeek, P.R. The role of explainability in creating trustworthy artificial intelligence for health care: A comprehensive survey of the terminology, design choices, and evaluation strategies. J. Biomed. Inform. 2021, 113, 103655. [Google Scholar] [CrossRef] [PubMed]
- Hira, Z.M.; Gillies, D.F. A review of feature selection and feature extraction methods applied on microarray data. Adv. Bioinform. 2015, 2015, 198363. [Google Scholar] [CrossRef] [PubMed]
- Daliri, M.R. Feature selection using binary particle swarm optimization and support vector machines for medical diagnosis. Biomed. Tech./Biomed. Eng. 2012, 57, 395–402. [Google Scholar] [CrossRef] [PubMed]
- Alhussan, A.A.; Abdelhamid, A.A.; Towfek, S.K.; Ibrahim, A.; Eid, M.M.; Khafaga, D.S.; Saraya, M.S. Classification of diabetes using feature selection and hybrid Al-Biruni earth radius and dipper throated optimization. Diagnostics 2023, 13, 2038. [Google Scholar] [CrossRef] [PubMed]
- Kumar, D.A.; Govindasamy, R. Performance and evaluation of classification data mining techniques in diabetes. Int. J. Comput. Sci. Inf. Technol. 2015, 6, 1312–1319. [Google Scholar]
- Lawi, A.; Syarif, S. Performance evaluation of naive Bayes and support vector machine in type 2 diabetes Mellitus gene expression microarray data. J. Phys. Conf. Ser. 2019, 1341, 042018. [Google Scholar]
- Jakka, A.; Jakka, V.R. Performance evaluation of machine learning models for diabetes prediction. Int. J. Innov. Technol. Explor. Eng. Regul. Issue 2019, 8, 1976–1980. [Google Scholar]
- Yang, T.; Zhang, L.; Yi, L.; Feng, H.; Li, S.; Chen, H.; Zhu, J.; Zhao, J.; Zeng, Y.; Liu, H. Ensemble learning models based on noninvasive features for type 2 diabetes screening: Model development and validation. JMIR Med. Inform. 2020, 8, e15431. [Google Scholar] [CrossRef] [PubMed]
- Marateb, H.R.; Mansourian, M.; Faghihimani, E.; Amini, M.; Farina, D. A hybrid intelligent system for diagnosing microalbuminuria in type 2 diabetes patients without having to measure urinary albumin. Comput. Biol. Med. 2014, 45, 34–42. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.-M.; Huang, K.-Y.; Lee, T.-Y.; Weng, J. An interpretable rule-based diagnostic classification of diabetic nephropathy among type 2 diabetes patients. BMC Bioinform. 2015, 16 (Suppl. 1), S5. [Google Scholar] [CrossRef]
- Chikh, M.A.; Saidi, M.; Settouti, N. Diagnosis of diabetes diseases using an Artificial Immune Recognition System2 (AIRS2) with fuzzy K-nearest neighbor. J. Med. Syst. 2012, 36, 2721–2729. [Google Scholar] [CrossRef] [PubMed]
- Luo, G. Automatically explaining machine learning prediction results: A demonstration on type 2 diabetes risk prediction. Health Inf. Sci. Syst. 2016, 4, 2. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.; Lim, D.H.; Kim, Y. Classification and prediction on the effects of nutritional intake on overweight/obesity, dyslipidemia, hypertension and type 2 diabetes mellitus using deep learning model: 4–7th Korea national health and nutrition examination survey. Int. J. Environ. Res. Public Health 2021, 18, 5597. [Google Scholar] [CrossRef] [PubMed]
- Kalagotla, S.K.; Gangashetty, S.V.; Giridhar, K. A novel stacking technique for prediction of diabetes. Comput. Biol. Med. 2021, 135, 104554. [Google Scholar] [CrossRef] [PubMed]
- Sarwar, M.A.; Kamal, N.; Hamid, W.; Shah, M.A. Prediction of diabetes using machine learning algorithms in healthcare. In Proceedings of the 2018 24th International Conference on Automation and Computing (ICAC), Newcastle Upon Tyne, UK, 6–7 September 2018. [Google Scholar] [CrossRef]
- Li, J.; Chen, Q.; Hu, X.; Yuan, P.; Cui, L.; Tu, L.; Cui, J.; Huang, J.; Jiang, T.; Ma, X.; et al. Establishment of noninvasive diabetes risk prediction model based on tongue features and machine learning techniques. Int. J. Med. Inform. 2021, 149, 104429. [Google Scholar] [CrossRef] [PubMed]
- Prajapati, S.; Das, H.; Gourisaria, M.K. Feature selection using differential evolution for microarray data classification. Discov. Internet Things 2023, 3, 12. [Google Scholar] [CrossRef]
- Alsattar, H.A.; Zaidan, A.A.; Zaidan, B.B. Novel meta-heuristic bald eagle search optimisation algorithm. Artif. Intell. Rev. 2020, 53, 2237–2264. [Google Scholar] [CrossRef]
- Hilal, A.M.; Alrowais, F.; Al-Wesabi, F.N.; Marzouk, R. Red Deer Optimization with Artificial Intelligence Enabled Image Captioning System for Visually Impaired People. Comput. Syst. Sci. Eng. 2023, 46, 1929–1945. [Google Scholar] [CrossRef]
- Horng, J.-T.; Wu, L.-C.; Liu, B.-J.; Kuo, J.-L.; Kuo, W.-H.; Zhang, J.J. An expert system to classify microarray gene expression data using gene selection by decision tree. Expert Syst. Appl. 2009, 36, 9072–9081. [Google Scholar] [CrossRef]
- Shaik, B.S.; Naganjaneyulu, G.V.S.S.K.R.; Chandrasheker, T.; Narasimhadhan, A. A method for QRS delineation based on STFT using adaptive threshold. Procedia Comput. Sci. 2015, 54, 646–653. [Google Scholar] [CrossRef]
- Bar, N.; Nikparvar, B.; Jayavelu, N.D.; Roessler, F.K. Constrained Fourier estimation of short-term time-series gene expression data reduces noise and improves clustering and gene regulatory network predictions. BMC Bioinform. 2022, 23, 330. [Google Scholar] [CrossRef] [PubMed]
- Imani, M.; Ghassemian, H. Ridge regression-based feature extraction for hyperspectral data. Int. J. Remote Sens. 2015, 36, 1728–1742. [Google Scholar] [CrossRef]
- Paul, S.; Drineas, P. Feature selection for ridge regression with provable guarantees. Neural Comput. 2016, 28, 716–742. [Google Scholar] [CrossRef]
- Prabhakar, S.K.; Rajaguru, H.; Ryu, S.; Jeong, I.C.; Won, D.O. A holistic strategy for classification of sleep stages with EEG. Sensors 2022, 22, 3557. [Google Scholar] [CrossRef] [PubMed]
- Mehta, P.; Bukov, M.; Wang, C.-H.; Day, A.G.; Richardson, C.; Fisher, C.K.; Schwab, D.J. A high-bias, low-variance introduction to machine learning for physicists. Phys. Rep. 2019, 810, 1–124. [Google Scholar] [CrossRef]
- Li, G.; Zhang, A.; Zhang, Q.; Wu, D.; Zhan, C. Pearson correlation coefficient-based performance enhancement of broad learning system for stock price prediction. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 2413–2417. [Google Scholar] [CrossRef]
- Mu, Y.; Liu, X.; Wang, L. A Pearson’s correlation coefficient based decision tree and its parallel implementation. Inf. Sci. 2018, 435, 40–58. [Google Scholar] [CrossRef]
- Grace Elizabeth Rani, T.G.; Jayalalitha, G. Complex patterns in financial time series through Higuchi’s fractal dimension. Fractals 2016, 24, 1650048. [Google Scholar] [CrossRef]
- Rehan, I.; Rehan, K.; Sultana, S.; Rehman, M.U. Fingernail Diagnostics: Advancing type II diabetes detection using machine learning algorithms and laser spectroscopy. Microchem. J. 2024, 201, 110762. [Google Scholar] [CrossRef]
- Wang, J.; Ouyang, H.; Zhang, C.; Li, S.; Xiang, J. A novel intelligent global harmony search algorithm based on improved search stability strategy. Sci. Rep. 2023, 13, 7705. [Google Scholar] [CrossRef]
- Fard, A.F.; Hajiaghaei-Keshteli, M. Red Deer Algorithm (RDA); a new optimization algorithm inspired by Red Deers’ mating. Int. Conf. Ind. Eng. 2016, 12, 331–342. [Google Scholar]
- Fathollahi-Fard, A.M.; Hajiaghaei-Keshteli, M.; Tavakkoli-Moghaddam, R. Red deer algorithm (RDA): A new nature-inspired meta-heuristic. Soft Comput. 2020, 24, 14637–14665. [Google Scholar] [CrossRef]
- Bektaş, Y.; Karaca, H. Red deer algorithm based selective harmonic elimination for renewable energy application with unequal DC sources. Energy Rep. 2022, 8, 588–596. [Google Scholar] [CrossRef]
- Kumar, A.P.; Valsala, P. Feature Selection for high Dimensional DNA Microarray data using hybrid approaches. Bioinformation 2013, 9, 824. [Google Scholar] [CrossRef]
- Zhang, G.; Allaire, D.; Cagan, J. Reducing the Search Space for Global Minimum: A Focused Regions Identification Method for Least Squares Parameter Estimation in Nonlinear Models. J. Comput. Inf. Sci. Eng. 2023, 23, 021006. [Google Scholar] [CrossRef]
- Draper, N.R.; Smith, H. Applied Regression Analysis; John Wiley & Sons: Hoboken, NJ, USA, 1998; Volume 326. [Google Scholar]
- Prabhakar, S.K.; Rajaguru, H.; Lee, S.-W. A comprehensive analysis of alcoholic EEG signals with detrend fluctuation analysis and post classifiers. In Proceedings of the 2019 7th International Winter Conference on Brain-Computer Interface (BCI), Gangwon, Republic of Korea, 18–20 February 2019. [Google Scholar]
- Llaha, O.; Rista, A. Prediction and Detection of Diabetes using Machine Learning. In Proceedings of the 20th International Conference on Real-Time Applications in Computer Science and Information Technology (RTA-CSIT), Tirana, Albania, 21–22 May 2021; pp. 94–102. [Google Scholar]
- Hamid, I.Y. Prediction of Type 2 Diabetes through Risk Factors using Binary Logistic Regression. J. Al-Qadisiyah Comput. Sci. Math. 2020, 12, 1. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, X.; Xu, L.; Ding, F. Expectation–maximization algorithm for bilinear systems by using the Rauch–Tung–Striebel smoother. Automatica 2022, 142, 110365. [Google Scholar] [CrossRef]
- Moon, T.K. The expectation-maximization algorithm. IEEE Signal Process. Mag. 1996, 13, 47–60. [Google Scholar] [CrossRef]
- Adiwijaya; Wisesty, U.N.; Lisnawati, E.; Aditsania, A.; Kusumo, D.S. Dimensionality reduction using principal component analysis for cancer detection based on microarray data classification. J. Comput. Sci. 2018, 14, 1521–1530. [Google Scholar] [CrossRef]
- Peng, C.-Y.J.; Lee, K.L.; Ingersoll, G.M. An introduction to logistic regression analysis and reporting. J. Educ. Res. 2002, 96, 3–14. [Google Scholar] [CrossRef]
- Zang, F.; Zhang, J.S. Softmax Discriminant Classifier. In Proceedings of the 3rd International Conference on Multimedia Information Networking and Security, Shanghai, China, 4–6 November 2011; pp. 16–20. [Google Scholar]
- Yao, X.; Panaye, A.; Doucet, J.; Chen, H.; Zhang, R.; Fan, B.; Liu, M.; Hu, Z. Comparative classification study of toxicity mechanisms using support vector machines and radial basis function neural networks. Anal. Chim. Acta 2005, 535, 259–273. [Google Scholar] [CrossRef]
- Ortiz-Martínez, M.; González-González, M.; Martagón, A.J.; Hlavinka, V.; Willson, R.C.; Rito-Palomares, M. Recent developments in biomarkers for diagnosis and screening of type 2 diabetes mellitus. Curr. Diabetes Rep. 2022, 22, 95–115. [Google Scholar] [CrossRef] [PubMed]
- Maxwell, A.E.; Warner, T.A.; Guillén, L.A. Accuracy assessment in convolutional neural network-based deep learning remote sensing studies—Part 1: Literature review. Remote Sens. 2021, 13, 2450. [Google Scholar] [CrossRef]
- Maniruzzaman, M.; Kumar, N.; Abedin, M.M.; Islam, M.S.; Suri, H.S.; El-Baz, A.S.; Suri, J.S. Comparative approaches for classifi-cation of diabetes mellitus data: Machine learning paradigm. Comput. Methods Programs Biomed. 2017, 152, 23–34. [Google Scholar] [CrossRef] [PubMed]
- Hertroijs, D.F.L.; Elissen, A.M.J.; Brouwers, M.C.G.J.; Schaper, N.C.; Köhler, S.; Popa, M.C.; Asteriadis, S.; Hendriks, S.H.; Bilo, H.J.; Ruwaard, D.; et al. A risk score including body mass index, glycated hemoglobin and triglycerides predicts future glycemic control in people with type 2 diabetes. Diabetes Obes. Metab. 2017, 20, 681–688. [Google Scholar] [CrossRef] [PubMed]
- Deo, R.; Panigrahi, S. Performance assessment of machine learning based models for diabetes prediction. In Proceedings of the 2019 IEEE Healthcare Innovations and Point of Care Technologies, (HI-POCT), Bethesda, MD, USA, 20–22 November 2019. [Google Scholar]
- Akula, R.; Nguyen, N.; Garibay, I. Supervised machine learning based ensemble model for accurate prediction of type 2 diabetes. In Proceedings of the 2019 Southeast Con, Huntsville, AL, USA, 11–14 April 2019. [Google Scholar]
- Xie, Z.; Nikolayeva, O.; Luo, J.; Li, D. Building risk prediction models for type 2 diabetes using machine learning techniques. Prev. Chronic Dis. 2019, 16, E130. [Google Scholar] [CrossRef]
- Bernardini, M.; Morettini, M.; Romeo, L.; Frontoni, E.; Burattini, L. Early temporal prediction of type 2 diabetes risk condition from a general practitioner electronic health record: A multiple instance boosting approach. Artif. Intell. Med. 2020, 105, 101847. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, Y.; Niu, M.; Wang, C.; Wang, Z. Nonlaboratory based risk assessment model for type 2 diabetes mellitus screening in Chinese rural population: A joint bagging boosting model. IEEE J. Biomed. Health Inform. 2021, 25, 4005–4016. [Google Scholar] [CrossRef] [PubMed]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).