

Artificial Intelligence for Predicting the Aesthetic Component of the Index of Orthodontic Treatment Need

 , ,
, ,
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Collection
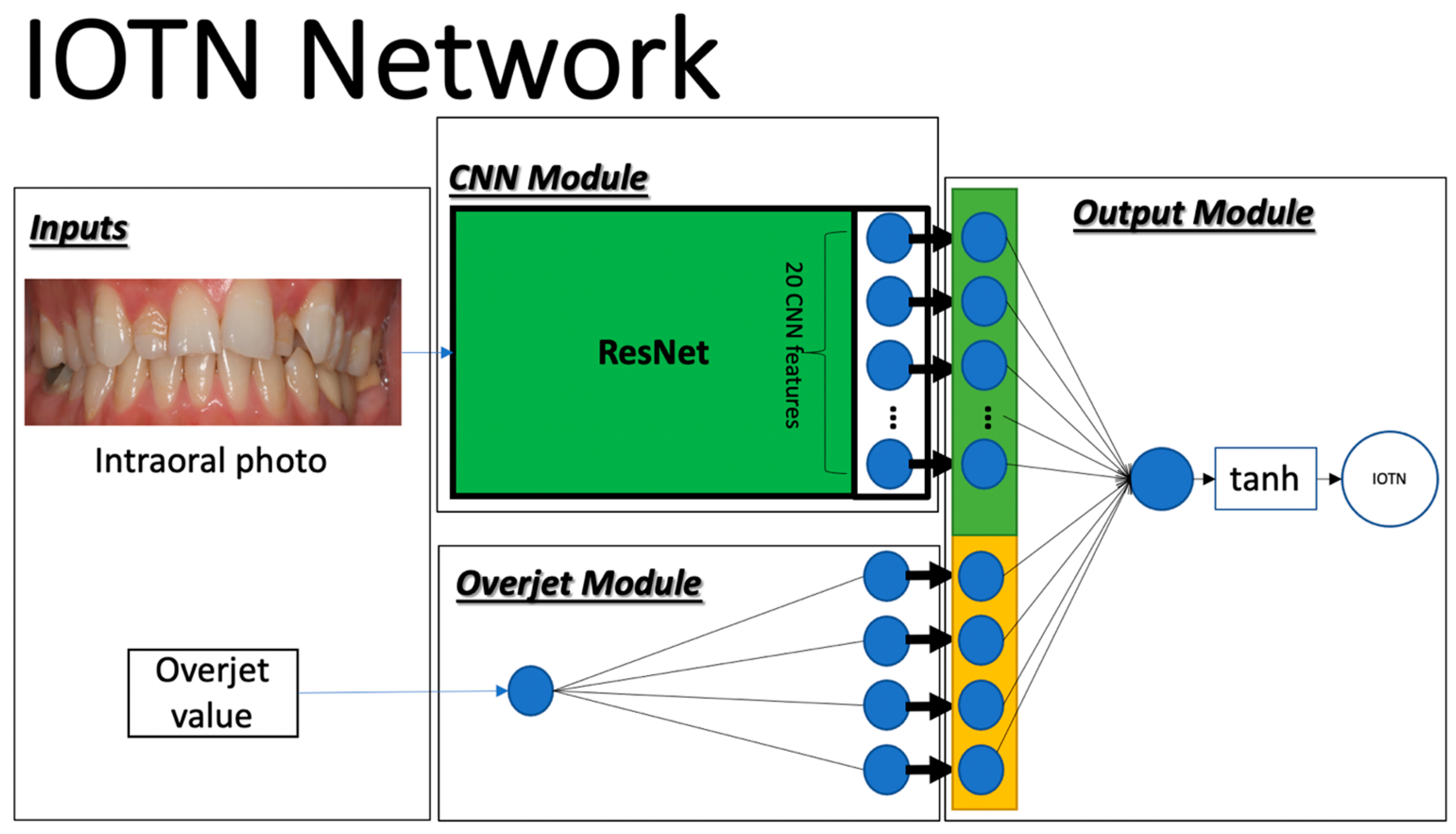
2.2. Deep Learning
2.3. Implementation
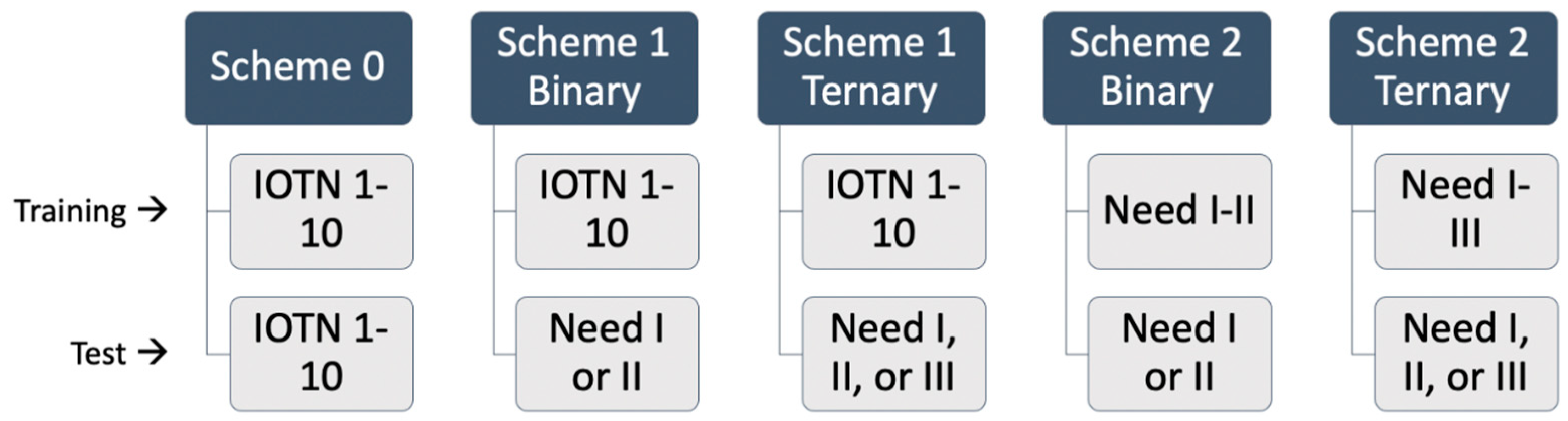
2.4. Data Augmentation and Transfer Learning
- Scheme 0
- 2.
- Scheme 1
- 3.
- Scheme 2
- The IOTN Network Variant and Supplemented Dataset
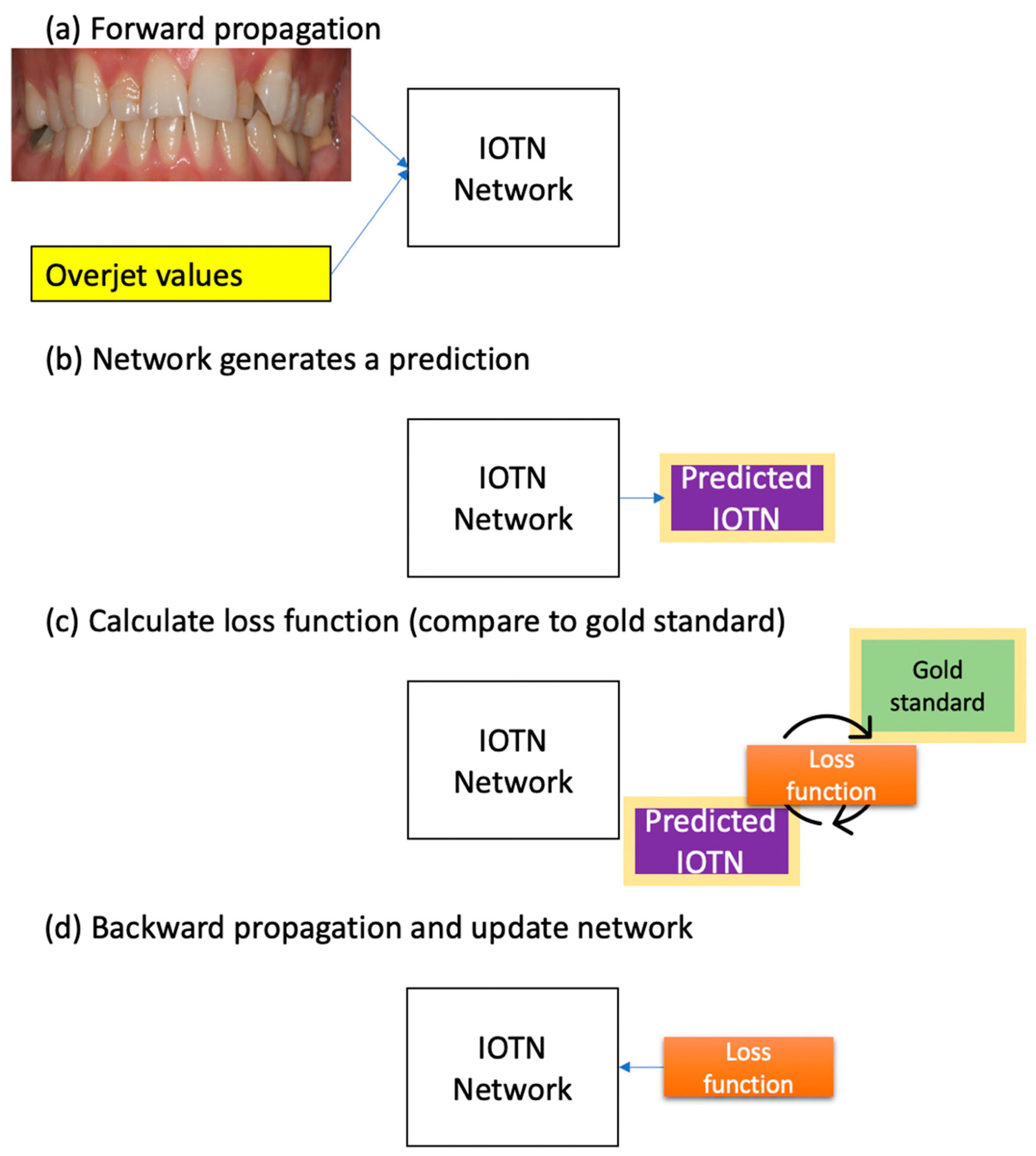
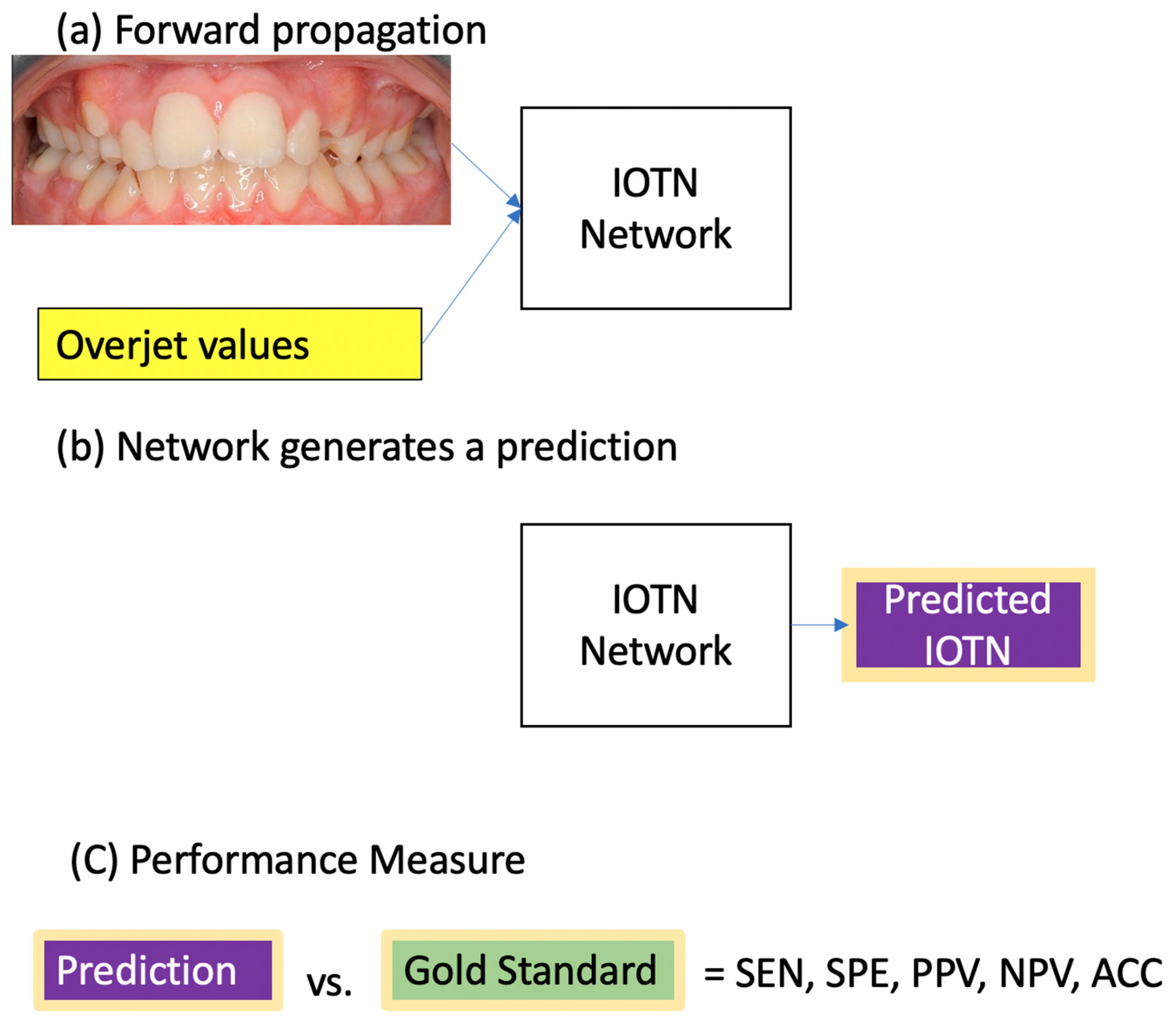
2.5. Statistical Analysis
3. Results
3.1. Prediction of IOTN-AC 1–10
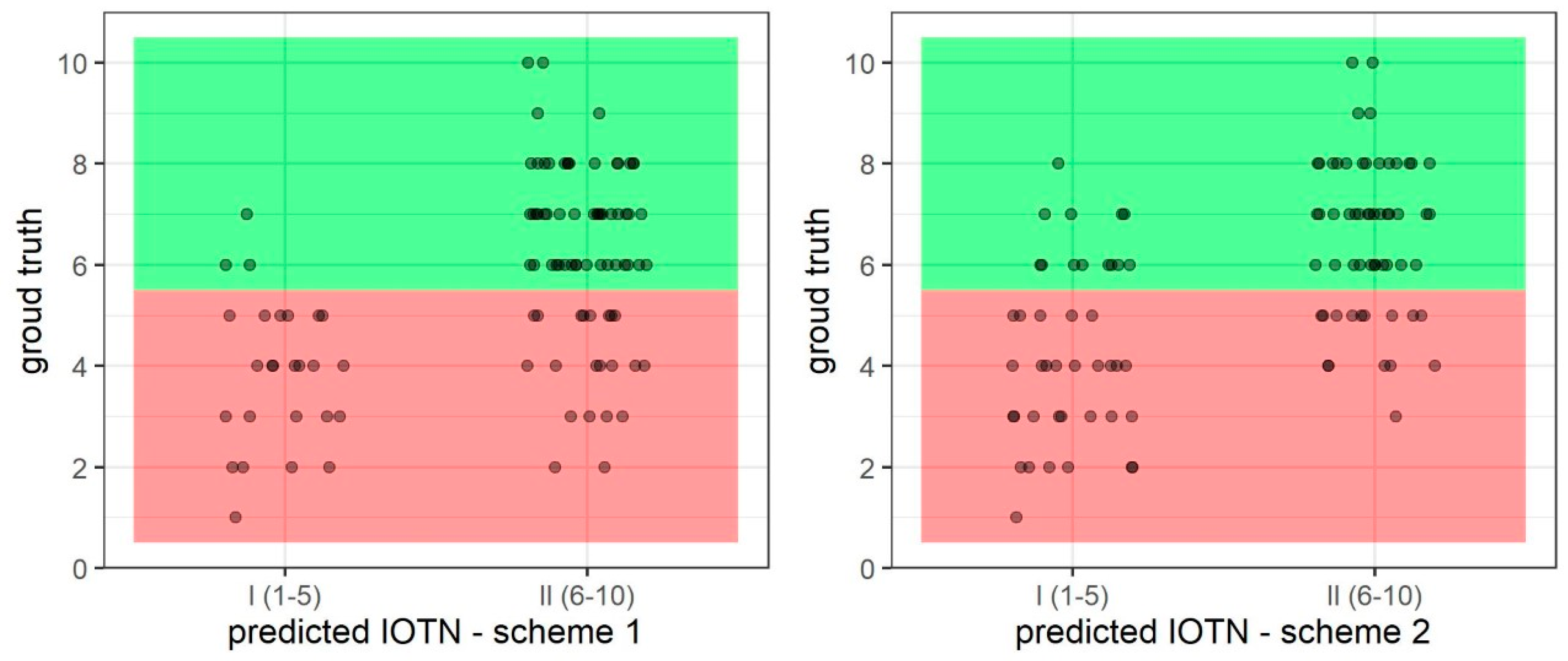
3.2. Prediction of IOTN-AC 1–5 (I) and 6–10 (II)—Binary
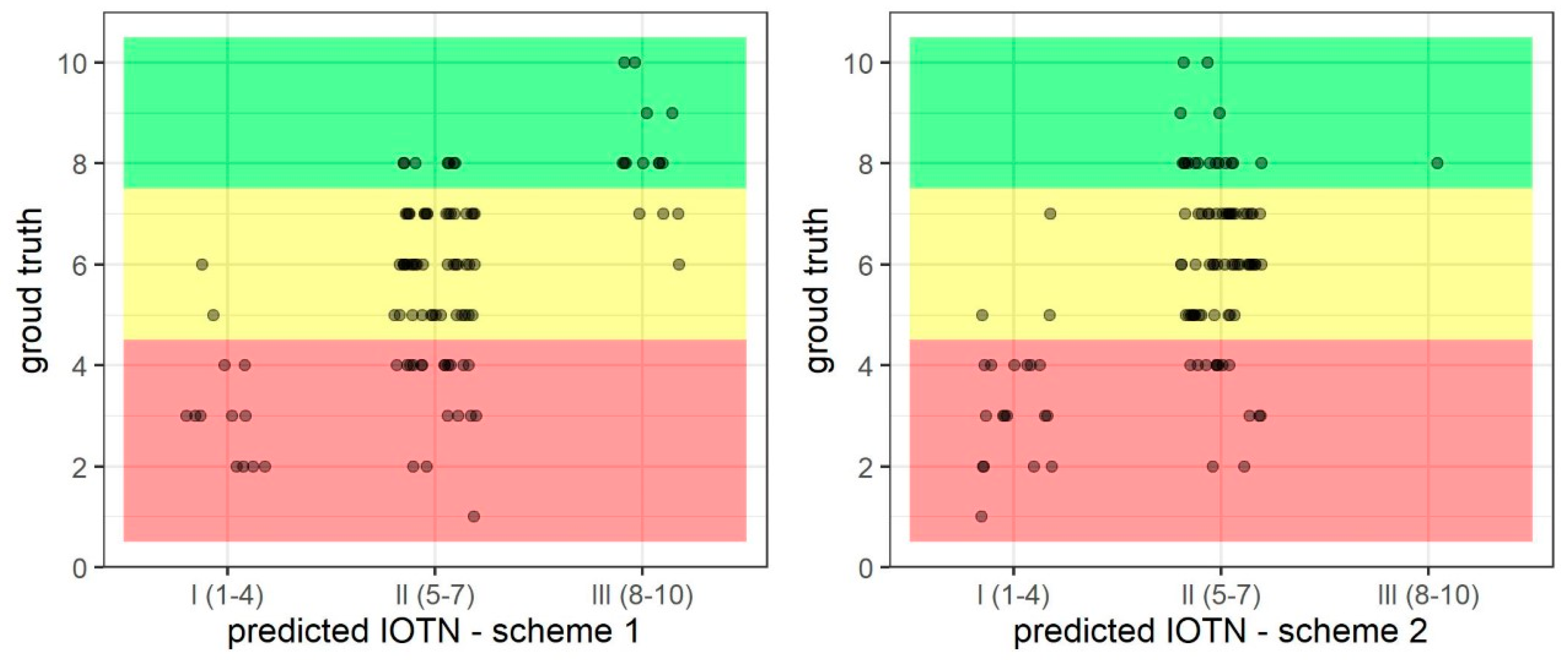
3.3. Prediction of IOTN-AC 1–4 (I), 5–7 (II), and 8–10 (II)—Ternary
3.4. Predictions without Overjet and with Supplemented Data
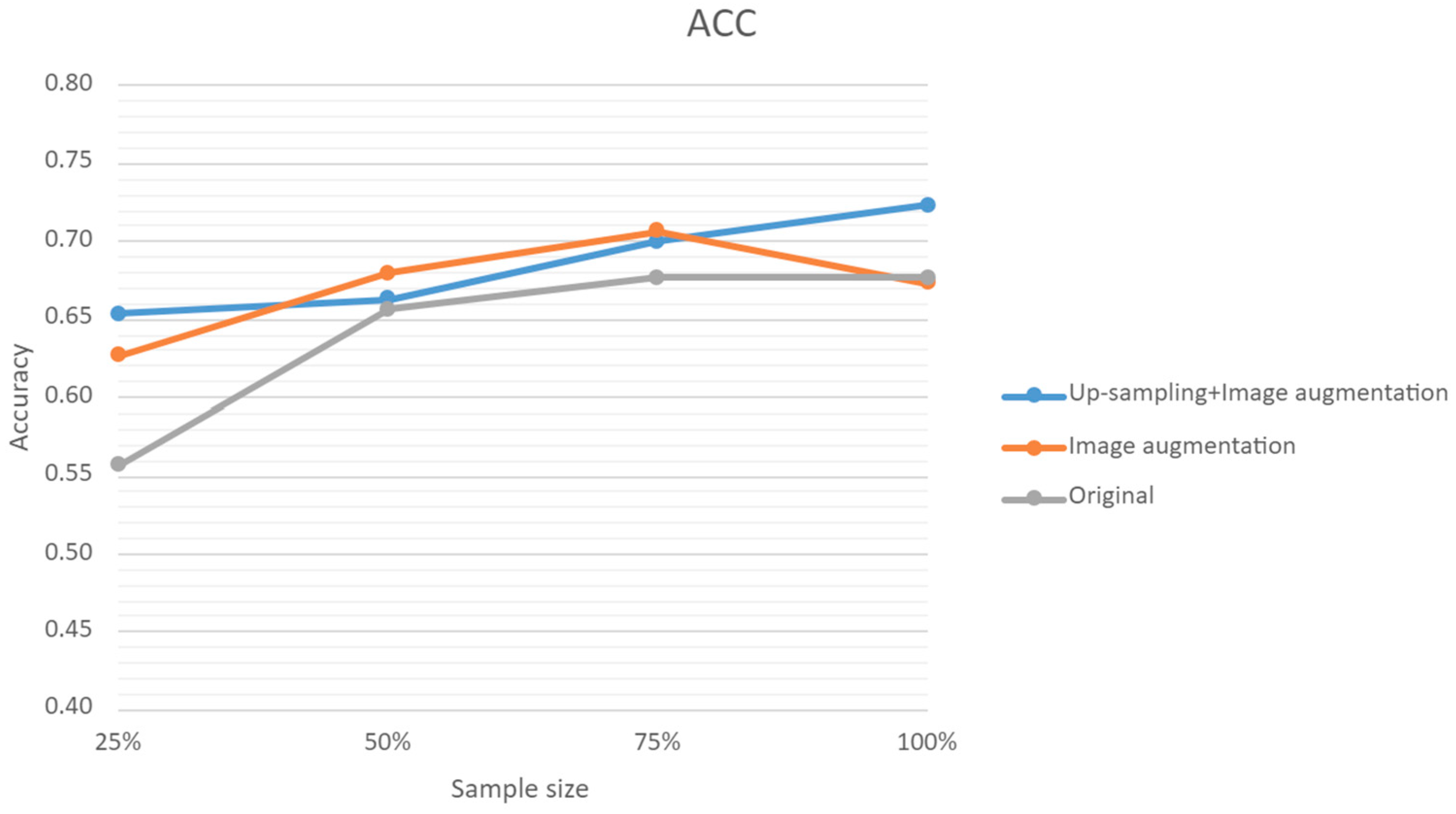
3.5. Predictions with Sample Size and Augmented Data
3.6. Summary
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- An NHS under Pressure. BMA, 2022. Available online: https://www.bma.org.uk/advice-and-support/nhs-delivery-and-workforce/pressures/an-nhs-under-pressure (accessed on 15 February 2023).
- The ‘Zoom Boom’: BOS Stats Reveal a Surge in Demand for Orthodontics during the Pandemic. British Orthodontic Society, 2021. Available online: https://www.dentalreview.news/dentistry/21-orthodontic/7269-bos-reports-zoom-boom-surge-in-orthodontics (accessed on 15 February 2023).
- Price, J.; Whittaker, W.; Birch, S.; Brocklehurst, P.; Tickle, M. Socioeconomic disparities in orthodontic treatment outcomes and expenditure on orthodontics in England’s state-funded National Health Service: A retrospective observational study. BMC Oral Health. 2017, 17, 123. [Google Scholar] [CrossRef] [PubMed]
- Shaw, W.C. The influence of children’s dentofacial appearance on their social attractiveness as judged by peers and lay adults. Am. J. Orthod. 1981, 79, 399–415. [Google Scholar] [CrossRef] [PubMed]
- Papio, M.A.; Fields, H.W.; Beck, F.M.; Firestone, A.R.; Rosenstiel, S.F. The effect of dental and background facial attractiveness on facial attractiveness and perceived integrity and social and intellectual qualities. Am. J. Orthod. Dentofac. Orthop. 2019, 156, 464–474.e1. [Google Scholar] [CrossRef]
- Olsen, J.A.; Inglehart, M.R. Malocclusions and perceptions of attractiveness, intelligence, and personality, and behavioral intentions. Am. J. Orthod. Dentofac. Orthop. 2011, 140, 669–679. [Google Scholar] [CrossRef]
- Trivedi, K.; Shyagali, T.R.; Doshi, J.; Rajpara, Y. Reliability of Aesthetic component of IOTN in the assessment of subjective orthodontic treatment need. J. Adv. Oral. Res. 2011, 2, 59–66. [Google Scholar] [CrossRef]
- Richmond, S.; Shaw, W.C.; O’Brien, K.D.; Buchanan, I.B.; Stephens, C.D.; Andrews, M.; Roberts, C.T. The relationship between the index of orthodontic treatment need and consensus opinion of a panel of 74 dentists. Br. Dent. J. 1995, 178, 370–374. [Google Scholar] [CrossRef] [PubMed]
- Younis, J.; Vig, K.; DJ, R.; RJ, W. A validation study of three indexes of orthodontic treatment need in the United States. Community Dent. Oral. Epidemiol. 1997, 25, 358–362. [Google Scholar] [CrossRef] [PubMed]
- Borzabadi-Farahani, A. An Overview of Selected Orthodontic Treatment Need Indices. In Principles in Contemporary Orthodontics; Naretto, S., Ed.; InTech: Rijeka, Croatia, 2011; Available online: http://www.intechopen.com/books/principles-in-contemporary-orthodontics/an-overview-of-selected-orthodontic-treatment-need-indices (accessed on 21 August 2024).
- Stenvik, A.; Espeland, L.; Linge, B.O.; Linge, L. Lay attitudes to dental appearance and need for orthodontic treatment. Eur. J. Orthod. 1997, 19, 271–277. [Google Scholar] [CrossRef] [PubMed]
- Üçüncü, N.; Ertugay, E. The use of the index of orthodontic treatment need (IOTN) in a school population and referred population. J. Orthod. 2001, 28, 45–52. [Google Scholar] [CrossRef]
- Livas, C.; Delli, K. Subjective and objective perception of orthodontic treatment need: A systematic review. Eur. J. Orthod. 2013, 35, 347–353. [Google Scholar] [CrossRef]
- Holmes, A. The subjective need and demand for orthodontic treatment. Br. J. Orthod. 1992, 19, 287–297. [Google Scholar] [CrossRef] [PubMed]
- Needs Assessment for Orthodontic Services in London Needs Assessment for Orthodontic Services in London; Public Health England: London, UK, 2015. Available online: https://www.gov.uk/government/publications/orthodontic-services-in-london-needs-assessment (accessed on 21 August 2024).
- Shan, T.; Tay, F.R.; Gu, L. Application of Artificial Intelligence in Dentistry. J. Dent. Res. 2021, 100, 232–244. [Google Scholar] [CrossRef]
- Mohammad-Rahimi, H.; Nadimi, M.; Rohban, M.H.; Shamsoddin, E.; Lee, V.Y.; Motamedian, S.R. Machine learning and orthodontics, current trends and the future opportunities: A scoping review. Am. J. Orthod. Dentofac. Orthop. 2021, 160, 170–192.e4. [Google Scholar] [CrossRef] [PubMed]
- Mohammad-Rahimi, H.; Motamedian, S.R.; Rohbanm, M.H.; Krois, J.; Uribe, S.E.; Mahmoudinia, E.; Rokhshad, R.; Nadimi, M.; Schwendicke, F. Deep learning for caries detection: A systematic review. J. Dent. 2022, 122, 104115. [Google Scholar] [CrossRef]
- Aggarwal, R.; Sounderajah, V.; Martin, G.; Ting, D.S.W.; Karthikesalingam, A.; King, D.; Ashrafian, H.; Darzi, A. Diagnostic accuracy of deep learning in medical imaging: A systematic review and meta-analysis. NPJ Digit. Med. 2021, 4, 65. [Google Scholar] [CrossRef]
- Ko, C.-C.; Tanikawa, C.; Wu, T.-H.; Pastewait, M.; Bonebreak Jackson, C.; Kwon, J.J.; Lee, Y.-T.; Lian, C.; Wang, L.; Shen, D. Embracing Novel Technologies in Dentistry and Orthodontics. In Craniofacial Growth Series; University of Michigan: Ann Arbor, MI, USA, 2020; pp. 117–135. [Google Scholar]
- Schwendicke, F.; Chaurasia, A.; Arsiwala, L.; Lee, J.H.; Elhennawy, K.; Jost-Brinkmann, P.G.; Demarco, F.; Krois, J. Deep learning for cephalometric landmark detection: Systematic review and meta-analysis. Clin. Oral Investig. 2021, 25, 4299–4309. [Google Scholar] [CrossRef]
- Hwang, H.W.; Park, J.H.; Moon, J.H.; Yu, Y.; Kim, H.; Her, S.B.; Srinivasan, G.; Aljanabi, M.N.A.; Donatelli, R.E.; Lee, S.-J. Automated identification of cephalometric landmarks: Part 2-Might it be better than human? Angle Orthod. 2020, 90, 69–76. [Google Scholar] [CrossRef]
- Muraev, A.A.; Tsai, P.; Kibardin, I.; Oborotistov, N.; Shirayeva, T.; Ivanov, S.; Guseynov, N.; Aleshina, O.; Bosykh, Y.; Safyanova, E.; et al. Frontal cephalometric landmarking: Humans vs artificial neural networks. Int. J. Comput. Dent. 2020, 23, 139–148. [Google Scholar] [PubMed]
- Murata, S.; Ishigaki, K.; Lee, C.; Tanikawa, C.; Date, S.; Yoshikawa, T. Towards a Smart Dental Healthcare: An Automated Assessment of Orthodontic Treatment Need. Healthinfo 2017, 2017, 35–39. [Google Scholar]
- Jones, N.; Marks, R.; Ramirez, R.; Ríos-Vargas, M. 2020 Census Illuminates Racial Ethnic Composition of the Country, U.S. Census Bureau. 2020. Available online: https://biz.libretexts.org/Courses/Folsom_Lake_College/BUS_330%3A_Managing_Diversity_in_the_Workplace_(Buch)/Unit_3%3A_Diversity_Groups_and_Categories%3A_Part_B/Chapter_6%3A_European_Americans_Native_Americans_and_Multi-racial_Americans/6.3%3A_Multi-racial_Americans/6.3.1%3A_2020_Census_Illuminates_Racial_and_Ethnic_Composition_of_the_Country (accessed on 18 December 2020).
- Proffit, W.R.; Fields, H.W.; Moray, L.J. Prevalence of malocclusion and orthodontic treatment need in the United States: Estimates from the NHANES III survey. Int. J. Adult Orthodon. Orthognath. Surg. 1998, 13, 97–106. [Google Scholar] [PubMed]
- Alhammadi, M.S.; Halboub, E.; Fayed, M.S.; Labib, A.; El-Saaidi, C. Global distribution of malocclusion traits: A systematic review. Dental. Press J. Orthod. 2018, 23, 40.e1. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Myrianthous, G. Training vs. Testing vs. Validation Sets. Towards Data Science, 2021. Available online: https://towardsdatascience.com/training-vs-testing-vs-validation-sets-a44bed52a0e1 (accessed on 15 December 2022).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2019; Available online: https://proceedings.neurips.cc/paper/2019/file/bdbca288fee7f92f2bfa9f7012727740-Paper.pdf (accessed on 21 August 2024).
- Trevethqn, R. Sensitivity, Specificity, and Predictive Values: Foundations, Pliabilities, and Pitfalls in Research and Practice. Front. Public Health 2017, 5, 307. [Google Scholar]
- Kelleher, J.; Namee, B.; D’Arcy, A. Fundamentals of Machine Learning for Predictive Data Analytics; The MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- McHugh, M.L. Lessons in biostatistics interrater reliability: The kappa statistic. Biochem. Medica. 2012, 22, 276–282. [Google Scholar] [CrossRef]
- Del Moral, P.; Nowaczyk, S.; Pashami, S. Why Is Multiclass Classification Hard? IEEE Access 2022, 10, 80448–80462. [Google Scholar] [CrossRef]
- The NHS Constitution. Available online: https://www.gov.uk/government/publications/the-nhs-constitution-for-england/the-nhs-constitution-for-england (accessed on 18 February 2023).
- Lee, J.-H.; Kim, D.H.; Jeong, S.N.; Choi, S.H. Detection and diagnosis of dental caries using a deep learning-based convolutional neural network algorithm. J. Dent. 2018, 77, 106–111. [Google Scholar] [CrossRef]
- Chen, H.; Zhang, K.; Lyu, P.; Li, H.; Zhang, L.; Wu, J.; Lee, C.H. A deep learning approach to automatic teeth detection and numbering based on object detection in dental periapical films. Sci. Rep. 2019, 9, 3840. [Google Scholar] [CrossRef]
- Yu, H.J.; Cho, S.; Kim, M.; Kim, W.; Kim, J.; Choi, J. Automated Skeletal Classification with Lateral Cephalometry Based on Artificial Intelligence. J. Dent. Res. 2020, 99, 249–256. [Google Scholar] [CrossRef]
- Koppolu, P.; Almutairi, H.; al Yousef, S.; Ansary, N.; Noushad, M.; Vishal, M.B.; Swapna, L.A.; Alsuwayyigh, N.; Albalawi, M.; Shrivastava, D.; et al. Relationship of skin complexion with gingival tissue color and hyperpigmentation. A multi-ethnic comparative study. BMC Oral Health 2024, 24, 451. [Google Scholar] [CrossRef]
- Ramirez, A.H.; Sulieman, L.; Schlueter, D.J.; Halvorson, A.; Qian, J.; Ratsimbazafy, F.; Loperena, H.R.; Mayo, K.; Basford, M.; Deflaux, N.; et al. The All of Us Research Program: Data quality, utility, and diversity. Patterns 2022, 3, 100570. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IOTN | Count | Percentage |
|---|---|---|
| 1 | 7 | 1% |
| 2 | 49 | 5% |
| 3 | 97 | 10% |
| 4 | 134 | 13% |
| 5 | 149 | 15% |
| 6 | 203 | 20% |
| 7 | 182 | 18% |
| 8 | 125 | 12% |
| 9 | 31 | 3% |
| 10 | 32 | 3% |
| Scheme | Sens | Spec | PPV | NPV | Acc |
|---|---|---|---|---|---|
| Scheme 0 | 0.27 | 0.92 | 0.50 | 0.92 | 0.34 |
| Scheme 1 Binary | 0.77 | 0.88 | 0.89 | 0.75 | 0.82 |
| Scheme 2 Binary | 0.76 | 0.87 | 0.88 | 0.74 | 0.81 |
| Scheme 1 Ternary | 0.65 | 0.83 | 0.77 | 0.85 | 0.72 |
| Scheme 2 Ternary | 0.63 | 0.81 | 0.67 | 0.82 | 0.67 |
| Scheme 1 w/out OJ Binary | 0.80 | 0.87 | 0.89 | 0.77 | 0.83 |
| Scheme 1 w/out OJ Ternary | 0.58 | 0.79 | 0.69 | 0.81 | 0.66 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stetzel, L.; Foucher, F.; Jang, S.J.; Wu, T.-H.; Fields, H.; Schumacher, F.; Richmond, S.; Ko, C.-C. Artificial Intelligence for Predicting the Aesthetic Component of the Index of Orthodontic Treatment Need. Bioengineering 2024, 11, 861. https://doi.org/10.3390/bioengineering11090861
Stetzel L, Foucher F, Jang SJ, Wu T-H, Fields H, Schumacher F, Richmond S, Ko C-C. Artificial Intelligence for Predicting the Aesthetic Component of the Index of Orthodontic Treatment Need. Bioengineering. 2024; 11(9):861. https://doi.org/10.3390/bioengineering11090861
Chicago/Turabian StyleStetzel, Leah, Florence Foucher, Seung Jin Jang, Tai-Hsien Wu, Henry Fields, Fernanda Schumacher, Stephen Richmond, and Ching-Chang Ko. 2024. "Artificial Intelligence for Predicting the Aesthetic Component of the Index of Orthodontic Treatment Need" Bioengineering 11, no. 9: 861. https://doi.org/10.3390/bioengineering11090861
APA StyleStetzel, L., Foucher, F., Jang, S. J., Wu, T.-H., Fields, H., Schumacher, F., Richmond, S., & Ko, C.-C. (2024). Artificial Intelligence for Predicting the Aesthetic Component of the Index of Orthodontic Treatment Need. Bioengineering, 11(9), 861. https://doi.org/10.3390/bioengineering11090861