

Effectiveness of Machine Learning in Predicting Orthodontic Tooth Extractions: A Multi-Institutional Study

 , , ,
, , ,
Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Machine Learning Algorithm—Random Forest
2.3. Metrics
3. Results
3.1. Demographic Distribution
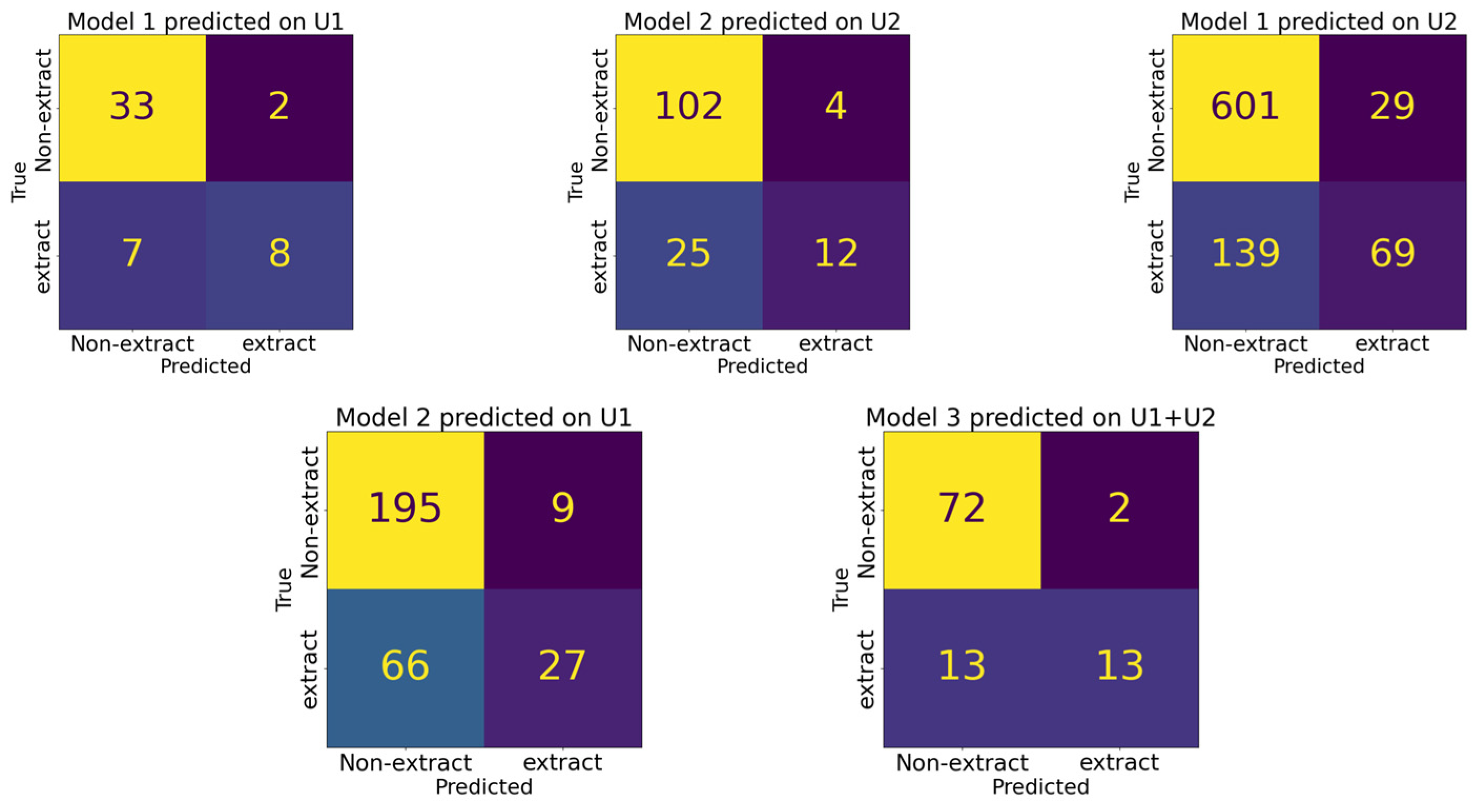
3.2. Performance Comparison among Different Models
3.3. Feature Rank
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Berne, M.L.Z.; Lin, F.-C.; Li, Y.; Wu, T.-H.; Chien, E.; Ko, C.-C. Machine Learning in Orthodontics: A New Approach to the Extraction Decision. In Machine Learning in Dentistry; Springer: Cham, Switzerland, 2021; pp. 79–90. [Google Scholar]
- Proffit, W.R. Forty-year review of extraction frequencies at a university orthodontic clinic. Angle Orthod. 1994, 64, 407–414. [Google Scholar] [PubMed]
- Jackson, T.H.; Guez, C.; Lin, F.-C.; Proffit, W.R.; Ko, C.-C. Extraction frequencies at a university orthodontic clinic in the 21st century: Demographic and diagnostic factors affecting the likelihood of extraction. Am. J. Orthod. Dentofac. Orthop. 2017, 151, 456–462. [Google Scholar] [CrossRef] [PubMed]
- Ackerman, J.L.; Proffit, W.R.; Sarver, D.M. The emerging soft tissue paradigm in orthodontic diagnosis and treatment planning. Clin. Orthod. Res. 1999, 2, 49–52. [Google Scholar] [CrossRef] [PubMed]
- Zaytoun, M.L. An Empirical Approach to the Extraction Versus Non-Extraction Decision in Orthodontics; University of North Carolina: Chapel Hill, NC, USA, 2019. [Google Scholar]
- Beattie, J.R.; Paquette, D.E.; Johnston, L.E., Jr. The functional impact of extraction and nonextraction treatments: A long-term comparison in patients with “borderline,” equally susceptible Class II malocclusions. Am. J. Orthod. Dentofac. Orthop. 1994, 105, 444–449. [Google Scholar] [CrossRef] [PubMed]
- Evrard, A.; Tepedino, M.; Cattaneo, P.M.; Cornelis, M.A. Which factors influence orthodontists in their decision to extract? A questionnaire survey. J. Clin. Exp. Dent. 2019, 11, e432–e438. [Google Scholar] [CrossRef] [PubMed]
- Fleming, P.S.; Cunningham, S.J.; Benson, P.E.; Jauhar, P.; Millett, D. Extraction of premolars for orthodontic reasons on the decline? A cross-sectional survey of BOS members. J. Orthod. 2018, 45, 283–288. [Google Scholar] [CrossRef] [PubMed]
- Weintraub, J.A.; Vig, P.S.; Brown, C.; Kowalski, C.J. The prevalence of orthodontic extractions. Am. J. Orthod. Dentofac. Orthop. 1989, 96, 462–466. [Google Scholar] [CrossRef] [PubMed]
- Schwendicke, F.; Samek, W.; Krois, J. Artificial Intelligence in Dentistry: Chances and Challenges. J. Dent. Res. 2020, 99, 769–774. [Google Scholar] [CrossRef] [PubMed]
- Arsiwala-Scheppach, L.T.; Chaurasia, A.; Müller, A.; Krois, J.; Schwendicke, F. Machine Learning in Dentistry: A Scoping Review. J. Clin. Med. 2023, 12, 937. [Google Scholar] [CrossRef] [PubMed]
- Ko, C.-C.; Tanikawa, C.; Wu, T.-H.; Pastwait, M.; Jackson, C.B.; Kwon, J.J.; Lee, Y.-T.; Lian, C.; Wang, L.; Shen, D. Machine Learning in Orthodontics: Application Review. Embrac. Nov. Technol. Dent. Orthod. 2019, 1001, 117. [Google Scholar]
- Xie, X.; Wang, L.; Wang, A. Artificial Neural Network Modeling for Deciding if Extractions Are Necessary Prior to Orthodontic Treatment. Angle Orthod. 2010, 80, 262–266. [Google Scholar] [CrossRef] [PubMed]
- Jung, S.-K.; Kim, T.-W. New approach for the diagnosis of extractions with neural network machine learning. Am. J. Orthod. Dentofac. Orthop. 2016, 149, 127–133. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Kong, D.; Tang, T.; Su, D.; Yang, P.; Wang, H.; Zhao, Z.; Liu, Y. Orthodontic treatment planning based on artificial neural networks. Sci. Rep. 2019, 9, 2037. [Google Scholar] [CrossRef] [PubMed]
- Suhail, Y.; Upadhyay, M.; Chhibber, A.; Kshitiz. Machine Learning for the Diagnosis of Orthodontic Extractions: A Computational Analysis Using Ensemble Learning. Bioengineering 2020, 7, 55. [Google Scholar] [CrossRef] [PubMed]
- Etemad, L.; Wu, T.-H.; Heiner, P.; Liu, J.; Lee, S.; Chao, W.-L.; Zaytoun, M.L.; Guez, C.; Lin, F.; Jackson, C.B.; et al. Machine learning from clinical data sets of a contemporary decision for orthodontic tooth extraction. Orthod. Craniofac. Res. 2021, 24, 193–200. [Google Scholar] [CrossRef] [PubMed]
- Fields, H.; Kim, D.-G.; Jeon, M.; Firestone, A.; Zongyang, S.; Shanker, S.; Mercado, A.M.; Deguchi, T.; Vig, K.W. Evaluation of objective structured clinical examination for advanced orthodontic education 12 years after introduction. Am. J. Orthod. Dentofac. Orthop. 2017, 151, 840–850. [Google Scholar] [CrossRef] [PubMed]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Grinsztajn, L.; Oyallon, E.; Varoquaux, G. Why Do Tree-Based Models Still Outperform Deep Learning on Tabular Data? arXiv 2022, arXiv:2207.08815. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn Res. 2011, 12, 2825–2830. [Google Scholar]
- Wojtas, M.; Chen, K. Feature importance ranking for deep learning. Adv. Neural Inf. Process. Syst. 2020, 33, 5105–5114. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Description of Feature |
|---|---|
| Gender | Patient biological sex, 0 = female, 1 = male |
| Age | Patient age at the time of treatment |
| Overjet (mm) Value | Distance from tip of lower incisor to tip of upper incisor along occlusal plane |
| Overbite (mm) Value | Distance from the tip of the upper and lower incisor perpendicular to the occlusal plane |
| Maxillary Crowding (mm) | Amount of maxillary arch crowding |
| Mandibular Crowding (mm) | Amount of mandibular arch crowding |
| Molar Classification | Angle classification using two binary variables, class I (0 or 1) and class II (0 or 1); for example, a class III patient would be class I = 0, class II = 0, while a class I patient would be class I = 1, class II = 0 |
| Curve of Spee | The perpendicular distance between the deepest mandibular cusp tip and a flat plane laid on the occlusal surface |
| SNA (°) Value | Angle created by sella, nasion, and A point |
| SNB (°) Value | Angle created by sella, nasion, and B point |
| ANB (°) Value | Angle created by A point, nasion, and B point |
| U1-NA (°) Value | Angle formed by the long axis of the upper incisor to a line from nasion to A point |
| U1-NA (mm) Value | Distance between the tip of the upper incisor and a line from nasion to A point |
| L1-NB (°) Value | Angle formed by the long axis of the lower incisor to a line from nasion to B point |
| L1-NB (mm) Value | Distance between the tip of the lower incisor and a line from nasion to B point |
| FMIA (L1-FH) (°) Value | Angle formed by the long axis of the lower central incisor and Frankfort horizontal plane |
| PFH/AFH (%) Value | The ratio of posterior face height (measured by sella to gonion) to anterior face height (measured by nasion to menton) |
| FMA (MP-FH) (°) Value | Angle formed by the mandibular plane and Frankfort horizontal plane |
| Upper Lip to E-Plane (mm) Value | The measurement from the upper lip to the esthetic plane, or a line drawn from the tip of the nose to the tip of the chin |
| Metric | Definition |
|---|---|
| Sensitivity (TP/TP + FN) | The proportion of clinical extraction cases that were identified by the model correctly |
| Specificity (TN/TN + FP) | The proportion of clinical non-extraction cases that were identified by the model correctly |
| PPV (TP/TP + FP) | The proportion of true extraction cases among all the model-predicted extraction cases |
| NPV (TN/TN + FN) | The proportion of true non-extraction cases among all the model prediction non-extraction cases |
| ACC (TN + TP/TN + TP + FN + FP) | The proportion of model correctly predicted cases among all the cases |
| BA (SEN + SPE/2) | The proportion of model correctly predicted cases among all cases adjusted for imbalances in dataset |
| University 1 | University 2 | |
|---|---|---|
| Gender | ||
| Male | 131 (44.11%) | 341 (40.69%) |
| Female | 166 (55.89%) | 497 (59.31%) |
| Age (Mean ± SD) | 17.15 ± 8.67 | 18.37 ± 10.69 |
| Race | ||
| Caucasian | 180 (60.61%) | 517 (61.70%) |
| African American | 52 (17.51%) | 130 (15.51%) |
| Hispanic | 44 (14.81%) | 129 (15.39%) |
| Other | 21 (7.07%) | 62 (7.40%) |
| Extraction Type | ||
| Extraction | 93 (31.31%) | 208 (24.82%) |
| No-extraction | 204 (68.69%) | 630 (75.18%) |
| Total (samples) | 297 (247 training, 50 tests) | 838 (695 training, 141 tests) |
| Accuracy (ACC) | Balanced Accuracy (BA) | Sensitivity (SEN) | Specificity (SPE) | PPV | NPV | |
|---|---|---|---|---|---|---|
| Model 1 predicted on University 1 dataset | 0.82 | 0.74 | 0.53 | 0.94 | 0.80 | 0.83 |
| Model 2 predicted on University 2 dataset | 0.80 | 0.64 | 0.32 | 0.96 | 0.75 | 0.80 |
| Model 1 predicted on University 2 dataset | 0.80 | 0.64 | 0.33 | 0.95 | 0.70 | 0.81 |
| Model 2 predicted on University 1 dataset | 0.75 | 0.62 | 0.29 | 0.96 | 0.75 | 0.75 |
| Model 3 predicted on University 1 and 2 dataset | 0.85 | 0.74 | 0.50 | 0.97 | 0.87 | 0.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Etemad, L.E.; Heiner, J.P.; Amin, A.A.; Wu, T.-H.; Chao, W.-L.; Hsieh, S.-J.; Sun, Z.; Guez, C.; Ko, C.-C. Effectiveness of Machine Learning in Predicting Orthodontic Tooth Extractions: A Multi-Institutional Study. Bioengineering 2024, 11, 888. https://doi.org/10.3390/bioengineering11090888
Etemad LE, Heiner JP, Amin AA, Wu T-H, Chao W-L, Hsieh S-J, Sun Z, Guez C, Ko C-C. Effectiveness of Machine Learning in Predicting Orthodontic Tooth Extractions: A Multi-Institutional Study. Bioengineering. 2024; 11(9):888. https://doi.org/10.3390/bioengineering11090888
Chicago/Turabian StyleEtemad, Lily E., J. Parker Heiner, A. A. Amin, Tai-Hsien Wu, Wei-Lun Chao, Shin-Jung Hsieh, Zongyang Sun, Camille Guez, and Ching-Chang Ko. 2024. "Effectiveness of Machine Learning in Predicting Orthodontic Tooth Extractions: A Multi-Institutional Study" Bioengineering 11, no. 9: 888. https://doi.org/10.3390/bioengineering11090888
APA StyleEtemad, L. E., Heiner, J. P., Amin, A. A., Wu, T.-H., Chao, W.-L., Hsieh, S.-J., Sun, Z., Guez, C., & Ko, C.-C. (2024). Effectiveness of Machine Learning in Predicting Orthodontic Tooth Extractions: A Multi-Institutional Study. Bioengineering, 11(9), 888. https://doi.org/10.3390/bioengineering11090888