Abstract
The task of localizing distinct anatomical structures in medical image data is an essential prerequisite for several medical applications, such as treatment planning in orthodontics, bone-age estimation, or initialization of segmentation methods in automated image analysis tools. Currently, Anatomical Landmark Localization (ALL) is mainly solved by deep-learning methods, which cannot guarantee robust ALL predictions; there may always be outlier predictions that are far from their ground truth locations due to out-of-distribution inputs. However, these localization outliers are detrimental to the performance of subsequent medical applications that rely on ALL results. The current ALL literature relies heavily on implicit anatomical constraints built into the loss function and network architecture to reduce the risk of anatomically infeasible predictions. However, we argue that in medical imaging, where images are generally acquired in a controlled environment, we should use stronger explicit anatomical constraints to reduce the number of outliers as much as possible. Therefore, we propose the end-to-end trainable Global Anatomical Feasibility Filter and Analysis (GAFFA) method, which uses prior anatomical knowledge estimated from data to explicitly enforce anatomical constraints. GAFFA refines the initial localization results of a U-Net by approximately solving a Markov Random Field (MRF) with a single iteration of the sum-product algorithm in a differentiable manner. Our experiments demonstrate that GAFFA outperforms all other landmark refinement methods investigated in our framework. Moreover, we show that GAFFA is more robust to large outliers than state-of-the-art methods on the studied X-ray hand dataset. We further motivate this claim by visualizing the anatomical constraints used in GAFFA as spatial energy heatmaps, which allowed us to find an annotation error in the hand dataset not previously discussed in the literature.
1. Introduction
Anatomical Landmark Localization (ALL) involves the localization of distinctive points or structures in medical images, such as X-ray, MRI, or CT scans, and is a vital preprocessing step for many medical applications. For instance, locating these anatomical landmarks allows clinicians to accurately assess the severity of craniomaxillofacial malformations [1]. In addition, ALL plays an important role in treatment planning for orthodontics and orthognathic surgery using cephalometric images [2,3], assisting orthodontists in confirming diagnoses and determining retention stability and duration [4]. Automated image analysis tools also rely on anatomical landmark locations to initialize segmentation methods [5], which classify each pixel by task-specific semantic classes, e.g., finding all pixels belonging to tumors. Moreover, deformable registration methods may be built upon corresponding anatomical landmarks [6], e.g., to study lung perfusion. Other medical applications that benefit from accurate ALL prediction include the analysis of knee radiographs at different stages of osteoarthritis [7] and the guidance of visual navigation systems in orthopedic surgery [8]. However, manual ALL is error-prone, labor-intensive, time-consuming, and requires medical expertise [1]. In addition, the high variability within and between human anatomies further complicates the accuracy of manual ALL [3].
In recent years, machine-learning-based methods have been extensively explored to address ALL, as they provide the ability to approximate arbitrarily complex functions given sufficient learnable parameters and annotated training data [9,10,11,12,13]. In addition, the advent of deep learning has significantly transformed the fields of computer vision and ALL, allowing models, such as Convolutional Neural Networks (CNNs) [14], to learn task-specific features directly from data. Consequently, CNNs have been widely used to solve ALL [1,3,15,16,17]. However, even CNNs and their variants, such as the U-Net [18], struggle with the local similarity of anatomical structures and out-of-distribution inputs [15]. This limitation introduces the risk of predicting landmarks far from their true location (outlier prediction), which may hinder subsequent medical applications that rely on ALL estimates. For instance, Weng et al. [19] used anatomical landmarks to assess spinal flexibility, where an outlier could have a significant negative impact on the curvature estimate used by spine surgeons to evaluate spinal disorders. Therefore, ensuring robustness against outliers in ALL is critical to prevent potential negative medical consequences.
Several studies [1,3,15,17,20] have explored the integration of anatomical constraints into machine-learning-based approaches for ALL to enhance robustness against outliers. For instance, methods such as the SpatialConfiguration-Net (SCN) [15] and the CMF-Net [1] implicitly enforce anatomical feasibility by splitting their CNN into a localization component (providing coarse ALL estimates) and a spatial configuration component (providing anatomical refinement), assuming that the combined components are beneficial for both accuracy and robustness. Other techniques [3,17,20] integrate anatomical feasibility into the loss function, which evaluates the difference between the model output and the target. In addition, some methods [1,21,22] employ mechanisms such as attention [23] or use rich-representation learning [3,24] to help CNNs learn complex global relationships, thereby improving localization performance.
However, these methods cannot guarantee that the converged model adheres to the notion of anatomical feasibility seen during training; we argue that using the implicitly induced anatomical prior in these methods alone is not enough. The real-world clinical setting often includes out-of-distribution samples with occlusions (tags that contain medical information, field-of-view cutoffs, or missing body parts) or other variability not captured in the training dataset. Accurate ALL estimates of all visible landmarks are still required. To overcome this limitation, we propose our Global Anatomical Feasibility Filter and Analysis (GAFFA) method, which applies explicit anatomical constraints during training and inference. In addition, GAFFA allows us to visually analyze the learned anatomical constraints, as they can be represented as spatial energy heatmaps.
Contribution
Based on the work of [15], we use a refined U-Net model for initial landmark localization, but we do not use the implicit spatial configuration component for landmark refinement in our proposed method. Instead, inspired by the works of [25,26] in the area of facial landmark localization and human pose estimation, respectively, we propose our end-to-end trainable GAFFA method that approximately solves a Markov Random Field (MRF) [27] in a fully differentiable manner. GAFFA filters out outlier predictions that are inconsistent with human anatomy, exemplified on X-ray images of hand bones. To the best of our knowledge, this has not been investigated in the ALL or medical image analysis literature. The explicit prior anatomical knowledge is provided by the topology of the MRF, which largely follows the natural bone connectivity of a human hand, and conditional distribution heatmaps, which describe the probability that landmark is in a specific location, given the location of landmark . These conditional distribution heatmaps are estimated with the Gaussian Mixture Model (GMM) [28] framework, using ground-truth distances between landmarks computed with the annotated training data prior to model training. For comparison, we implemented both an SCN and an external Graphical Model (GM) [10], which also implements an MRF. However, for the GM, the separate MRF is approximately solved with Loopy Belief Propagation (LBP) [29] in a non-differentiable way. Overall, we evaluate three different landmark refinement paradigms: explicit anatomical prior (GM), implicit anatomical prior (SCN), and our proposed explicit end-to-end trainable anatomical prior (GAFFA). Our experimental results show an improvement in robustness to large outliers using GAFFA over state-of-the-art methods.
Our main contributions of GAFFA that extend [25,26] are as follows:
- We use Differentiable Spatial to Numerical Transform (DSNT) [30] coordinate regression. DSNT has no disconnect between loss computation and desired metrics and retains the spatial generalization property of heatmap regression.
- The computational costs are reduced by combining the optimization strategies of [25,26] and designing an efficient pipeline of upscaling and downscaling operations within GAFFA. This is necessary to make our method computationally feasible, as we use higher resolution inputs and a larger number of landmarks than [25,26].
- We refine the marginal energy equation used in GAFFA, e.g., returning back from logarithmic space is not necessary for finding the location of the highest pixel intensity.
- The data augmentation scheme is extended with occlusion perturbations [24], which increases the overall ALL performance and robustness against occlusions.
2. Methods
We follow the methodology of Payer et al. [15] to divide the task of ALL into the two subtasks of initial landmark localization and landmark refinement. Our initial landmark localization method is based on the U-Net [18], which is also used in the local appearance component of [15]. The rough localization results of the U-Net are then filtered with one of the three investigated landmark refinement methods. We implemented a SpatialConfiguration-Net (SCN), as proposed by Payer et al. [15], that exploits implicit anatomical constraints within the network architecture. Furthermore, based on the notion of Markov Random Fields (MRFs) [31], we use an external Graphical Model (GM) [10] and lastly propose the end-to-end trainable Global Anatomical Feasibility Filter and Analysis (GAFFA) method based on [25,26] to explicitly find a consensus between anatomical constraints and initial localization results. Our code and experimental setup can be found at https://github.com/imigraz/GAFFA.
2.1. Dataset
We used the Digital Hand Atlas dataset (https://ipilab.usc.edu/research/baaweb/dbdform/ last accessed 19 July 2024) with annotations provided at (https://github.com/christianpayer/MedicalDataAugmentationTool-HeatmapRegression/tree/master/hand_xray/hand_xray_dataset/setup last accessed 19 July 2024), which has been extensively studied in the ALL literature [15,17,20,24], where hand bone landmarks can be used as an initial stage, e.g., for bone-age estimation [32,33,34]. It contains 895 2D X-ray images of hands, each having 37 landmark annotations. There is no information about the physical resolution for this dataset, which is very important for medical applications. Hence, there is a normalization procedure found in the literature [15] that defines an image-specific normalization constant, , which is defined as
where and denote the corresponding coordinates of Landmark 2 and Landmark 6 in the image j. Moreover, describes the Euclidean distance between any two landmarks. This procedure normalizes each wrist (described by and ) to be 50 mm wide. We can then use to measure how many millimeters a pixel distance represents in image j.
2.2. Initial Landmark Localization with Heatmap Regression
The initial landmark prediction is based on the U-Net [18] heatmap regression framework of [15], which is openly available on GitHub (https://github.com/christianpayer/MedicalDataAugmentationTool-HeatmapRegression last accessed on 19 July 2024). However, we rewrote all the TensorFlow code in this framework with PyTorch Lightning, as this allowed us to use other PyTorch-based libraries. The used U-Net, shown in Figure 1, outputs a heatmap for each unique landmark in the dataset (37 output heatmaps in total). The regression target is a Gaussian-distributed blob placed so that the blob peak coincides with the annotated target landmark location. The final coordinate prediction of a landmark can be derived by finding the location of the pixel with the highest intensity in its corresponding heatmap prediction via the non-differentiable argmax function.
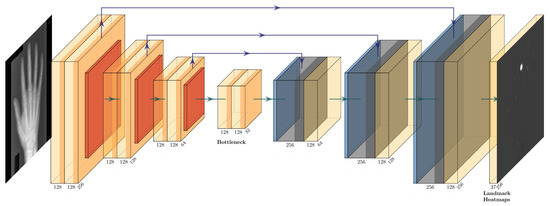
Figure 1.
U-Net architecture used for initial landmark localization, applied to a X-ray image of a hand from our studied dataset. We solely show one output heatmap, but there is a predicted output heatmap for each landmark. While we visualize three levels here, our implementation used four levels. Light yellow blocks indicate convolution layers in the encoder and bottleneck parts of the network, respectively, red blocks indicate average pooling layers, light blue blocks indicate bilinear upsampling, dark blue and dark yellow blocks indicate convolution layers in the decoder part of the U-Net. Purple arrows illustrate skip connections that directly connect encoder and decoder layers.
The network is divided into an encoder part and a decoder part. Each part consists of four levels, and each level consists of two successive convolution layers and an upsampling or downsampling operation. Each convolution layer has 128 input channels, except for the first convolution layer in each decoder level, which expects 256 input filter maps, and the first convolution layer of the network, which processes the input grayscale image. Furthermore, each convolution layer consists of a convolution operation with a kernel size of and stride of 1, followed by batch normalization [35], non-linear activation (LeakyReLU [36] with negative slope of 0.1), and dropout [37] (set to 0.3). Additionally, each encoder level uses average pooling with a kernel size of and a stride of 2 for downsampling. In the decoder part of the network we used fixed bilinear upsampling, as suggested by [15]. Skip connections directly connect encoder and decoder layers, which lets the network effectively combine low and high level features. The final convolution layer of the decoder part outputs 37 heatmap predictions, one heatmap per unique landmark. The main differences to [15] are the batch normalization step after each convolution operation and two consecutive convolution layers in each encoder level instead of three.
2.3. Explicit Landmark Refinement with Markov Random Fields
The investigated explicit landmark refinement methods (GM and our proposed GAFFA) are based on the notion of Markov Random Fields (MRFs) [27,31]. An MRF is an undirected graph, G, with a set of vertices, , connected by edges, . Similar to [10], we let each v correspond to one unique landmark in our dataset and allow each v to have several landmark candidates. The MRF defines a discrete optimization problem, whose solution allows us to rank each landmark candidate of each v according to the agreement between its anatomical feasibility and the initial localization confidence of the U-Net. The definition of landmark candidates depends on the specific method. The Graphical Model has to explicitly extract landmark candidates from the U-Net heatmaps for each v. In contrast, our proposed GAFFA solves the MRF directly in image space and does not require explicit extraction of landmark candidates. For this method, the landmark candidates of a landmark, v, are all pixel locations in input image space. In addition, an MRF requires the definition of its graph topology. Differently to [10], where the topology is learned directly from the data, we manually chose a topology based on the bone connectivity observed in human anatomy, with some additional connections between fingers to further strengthen the spatial constraint, as visualized in Figure 2.
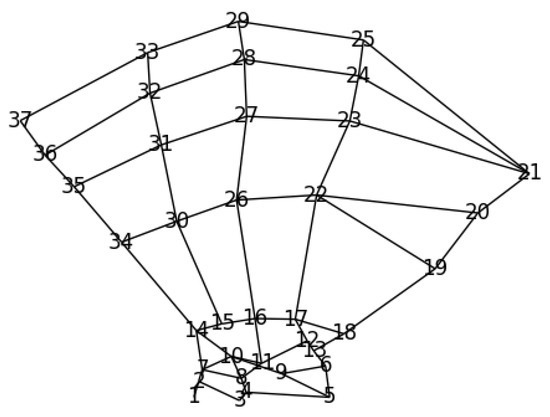
Figure 2.
MRF topology used for this dataset. Each vertex represents one of the 37 unique landmarks in the studied hand dataset. The topology is inspired by the anatomy of the human hand, with additional edge connections between fingers to increase the spatial constraint.
The MRF also requires the definition of unary and binary costs. The unary cost term describes the initial cost of selecting a particular landmark candidate of v as the final landmark location of the unique landmark represented by v. For unary costs, we use the pixel intensities of the respective U-Net heatmaps. The binary cost term defines the cost of choosing two landmark candidates connected by an edge, e, which acts as an anatomical constraint during optimization. For binary costs, both investigated methods rely on first fitting statistical distributions to the measured distances between landmarks that we can observe in the annotated training set. The fitted distributions are then used to estimate how well the observed distances between predicted landmark candidates match our prior anatomical knowledge. Finding the exact solution of the MRF is NP-hard in a cyclic graph [38]. Hence, we approximate the global solution to this optimization problem in both methods with implementations of the sum-product algorithm [39].
2.4. End-to-End Trainable Global Anatomical Feasibility Filter and Analysis
GAFFA is inspired by the works of [25,26]. In their approaches, is defined as the unary marginal distribution representing the probability that landmark is located at the random variable , which represents a 2D image location. For simplicity, denotes , and denotes the approximation of provided by GAFFA. We adopt their definition of the unary marginal probability of computed over all landmarks in its extended neighborhood, , in our defined MRF topology, expressed as
where is the bias describing the probability of a message passing from to , Z is a normalization constant (which is discarded in the implementation of [25,26] as they treat the distributions as energies, focusing only on the maximum value in the final heatmaps), is the conditional probability of given estimated prior to model training, and * denotes the convolution operator. According to [26], this equation represents an iteration of the sum-product algorithm, which we also use to solve the MRF described by the GM.
Following [25], we define as the combination of the local neighborhood of and a fixed set of global landmarks, , that do not need to be directly connected to in the MRF topology. contains only the nearest neighbors, which are all landmarks connected to by an edge, e. For , we manually include and , located on the wrist, as illustrated in Figure 2. This choice is based on the fact that the wrist is the least likely region to be occluded in clinical settings. We also include {}, which mark the metacarpophalangeal joints, and {}, which mark the fingertips, to represent the global structure of a human hand. The inclusion of in is crucial for robustness against occlusion. In extreme cases, where the entire local neighborhood of is occluded, the position can still be roughly estimated using the global landmarks.
2.4.1. Prior Anatomical Knowledge and GAFFA
Unlike the SCN, which only incorporates implicit anatomical constraints into its network architecture, GAFFA uses explicit anatomical priors. We followed a method similar to [25] to estimate each , which serve as anatomical priors that can be further optimized during training as they are used to initialize convolution kernels. However, the training images and their corresponding ground truth coordinates are augmented with the procedures explained in Section 3.2. Therefore, for a more robust estimate of , we already sample each training image three times to account for multiple spatial transformations for each landmark in the prior before starting model training. For each training image, we first translate landmark using the translation vector
which moves landmark to the center of the image. We then use the Gaussian Mixture Model (GMM) framework [28] to estimate each combination. The GMM approach fits a mixture of several Gaussian distributions to the data. Through empirical experimentation with up to 10 different Gaussian distributions, we determined the optimal number by selecting the one with the lowest mean between Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC) values.
Due to the application of , there may be responses outside the initial image boundary set by the input images. Therefore, the resulting heatmaps have twice the resolution of their input images. Consequently, Figure 3 shows a image illustrating the GMM result of , even though the original input images it was trained on had an image resolution of . Also, Figure 3 shows where Landmark 2 should be, given the location of Landmark 6, which was translated to the center of the image.
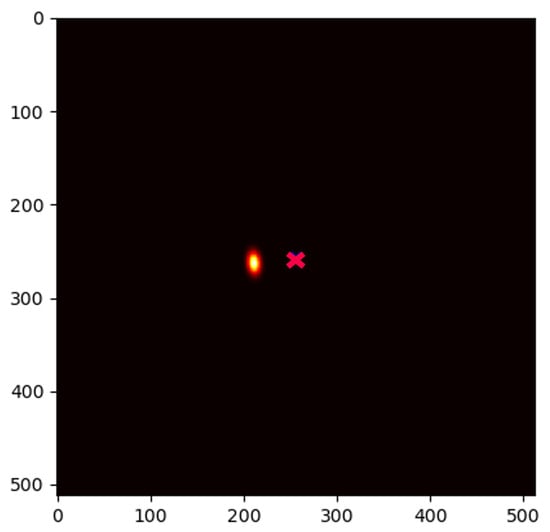
Figure 3.
Conditional distribution heatmap , learned from 597 unique images of the investigated hand dataset, where the red cross marks the center of the frame (representing the location of ) and the heatmap indicates where is likely to be located relatively to .
2.4.2. Numerical Realization
We implement a modified Equation (2) from [25] that no longer quantifies a probability for , but an energy:
where is the predicted energy heatmap of landmark and and with and in all experiments. The product operation in Equation (2) is replaced by a summation of logarithmic terms to improve numerical stability. In addition, the function ensures a positive convolution output, thereby mitigating numerical instability, as noted by [26]. Unlike [25,26], we do not perform a final conversion from logarithmic space, since our focus is on the maximum value, which remains unchanged when not converted from logarithmic space. Additionally, we apply to the bias, similar to [26].
The convolution operation described in Equation (4) is computationally intensive because it requires to be twice the size of and uses as a learnable convolution kernel. To make Equation (4) computationally feasible, we use both the grouped convolution strategy from [25] and the Fourier space convolution method from [26]. Our implementation uses a Fast Fourier Transform (FFT) in PyTorch (https://github.com/fkodom/fft-conv-pytorch last accessed: 7 June 2024), which supports group convolutions. In addition, we heavily downsample , , and to minimize the number of learnable parameters and reduce computational time of the sum in Equation (4). This downsampling is similar to the spatial component reduction in the SCN, but we use bicubic interpolation instead of average pooling to preserve the shape of the original conditional distribution and localization heatmaps. However, the original heatmap resolution is retained for to preserve the initial accuracy of the localization model. Consequently, the final energy sum must be upsampled using bicubic interpolation to match the heatmap resolution of the localization model for the final addition with . Finally, due to the need to manually initialize spatially variant kernel weights, we invert our previously estimated kernels along their spatial dimensions to accommodate PyTorch’s use of cross-correlation rather than convolution (https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html last accessed 7 June 2024), thereby ensuring the correct spatial orientation of the conditional heatmaps.
Overall, we configured GAFFA to regress coordinates following the methodology proposed by [25]. However, the coordinate regression technique is not elaborated in detail by [25]. Consequently, we have chosen the Differentiable Spatial to Numerical Transform (DSNT) approach [30] without regularization. This choice allows us to avoid enforcing a strict target heatmap with a single Gaussian blob for each landmark. The DSNT approach is fully differentiable, ensuring that there is no disconnect between the loss function and the metric of interest. In addition, we use the Mean Squared Error (MSE) loss to compute the discrepancy between predicted and target coordinates, as opposed to the Euclidean distance loss proposed by [30]. This decision is based on the observation that the Euclidean distance loss requires an additional square root computation, while the optimization objective remains essentially the same.
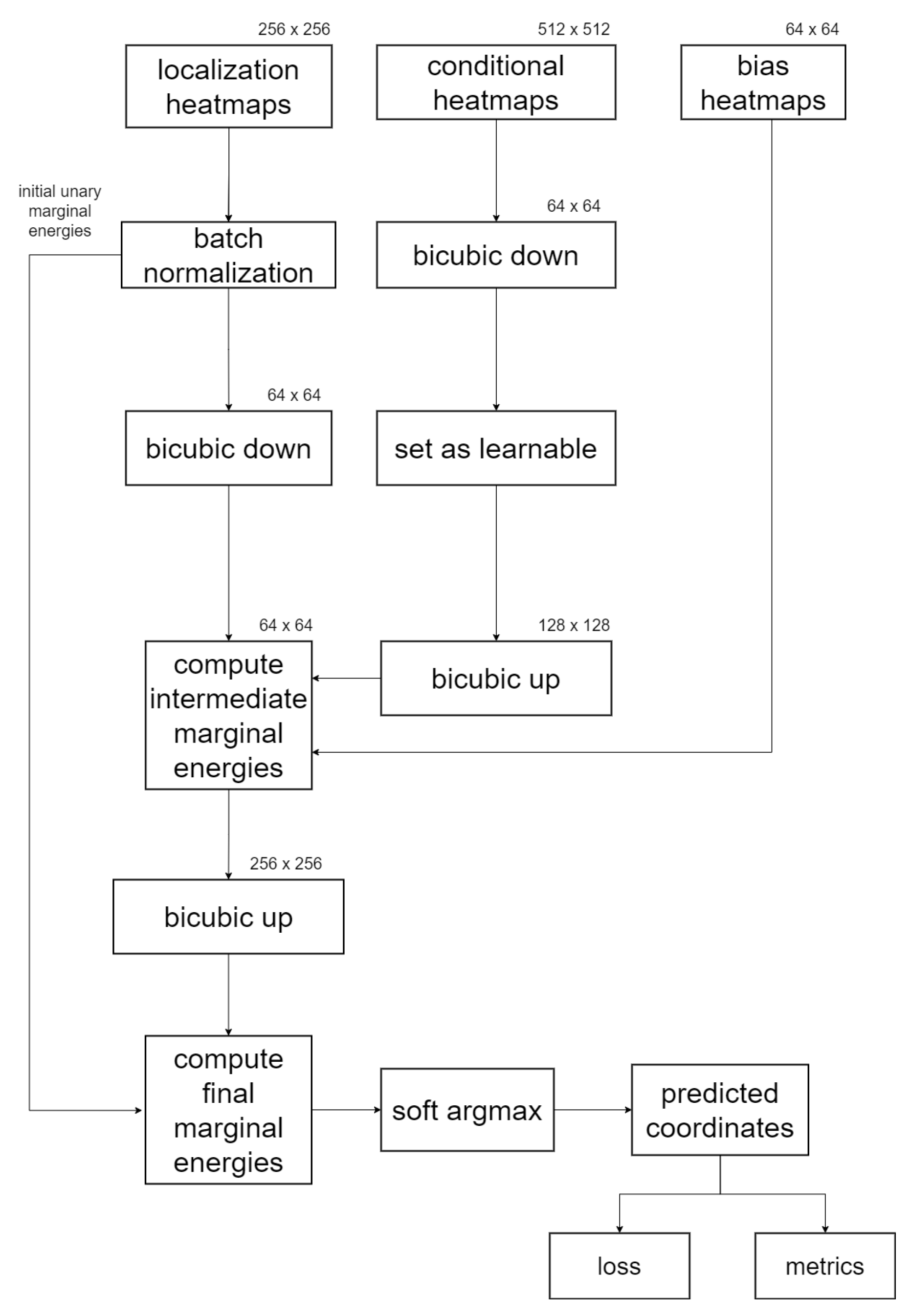
2.4.3. GAFFA Landmark Refinement Flowchart
Figure 4 presents an abstract flowchart illustrating the coordinate regression process of GAFFA, assuming a image resolution for our localization model. Initially, we apply batch normalization to the U-Net localization heatmaps to expedite convergence, as suggested in (https://github.com/max-andr/joint-cnn-mrf last accessed: 7 June 2024), which implements [26]. We then perform bicubic downsampling on the batch-normalized heatmaps and the conditional distribution heatmaps. We keep the conditional heatmaps at a much lower resolution than required for the convolution in Equation (4) to minimize the number of trainable parameters. This requires an upsampling step to restore the conditional heatmaps to twice the resolution of the localization heatmaps. Furthermore, we keep the localization heatmaps at their original resolution in memory for the computation of , as indicated by the line connecting the batch normalization phase to the final computation. The bias terms are interpreted as heatmaps, with each pixel initialized with . After computing the sum in Equation (4), we upsample the intermediate results back to the original resolution before integrating them with , resulting in . Finally, the refined landmark coordinates are extracted from each using the soft argmax function adopted from [30], and these are subsequently used for loss and performance evaluation.
2.4.4. Comparison with SCN and Graphical Model
Our proposed method essentially combines the ideas of the SCN and the GM. It follows the idea of the SCN having subsequent end-to-end trainable components within the network for landmark localization and refinement. However, the landmark refinement component of our method approximately solves an MRF, similar to the GM, which explicitly enforces anatomical constraints. In addition, unlike the GM, the anatomical prior is further refined during training.
External Graphical Model. The Graphical Model (GM) is directly inspired by [10] and requires the explicit extraction of landmark candidates for every v from the U-Net prediction heatmaps. For this, we used a blob extraction method (Laplacian of Gaussian) that returns the location of blob peaks, as we assume Gaussian-distributed blobs near target locations. We rank all found candidates of a heatmap based on their blob peak intensity, (larger is better), which also defines the unary cost of choosing the corresponding landmark candidate. We further process only the top 25 candidates based on this ranking to reduce computation time on the computationally expensive binary cost estimation. Moreover, in all experiments we ignore normalized blob peak values, , below the threshold of 0.015, with defined as
where N is the number of landmark candidates of one landmark.
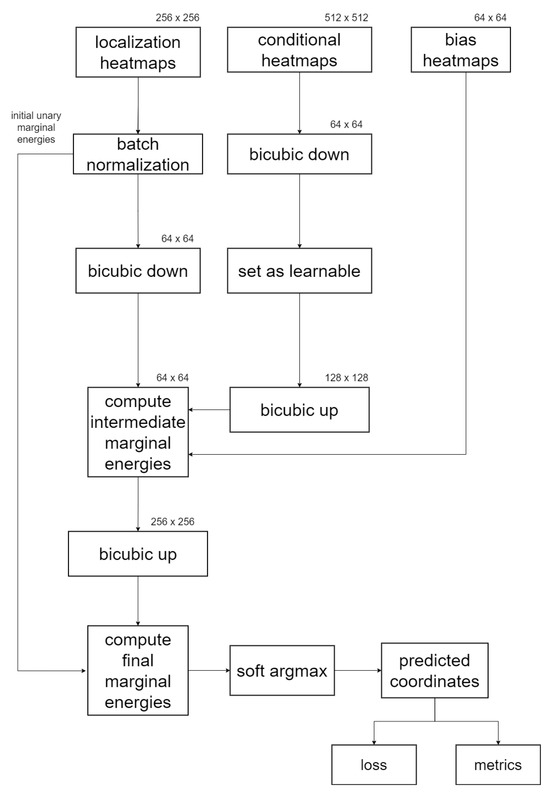
Figure 4.
Flowchart of GAFFA when applied to output heatmaps of the U-Net.
Figure 4.
Flowchart of GAFFA when applied to output heatmaps of the U-Net.
We combine two types of binary cost terms that are weighted to be equally important. For each edge, e, we use ground-truth distances to model a t-distribution of distances between landmarks connected to e. Furthermore, for each e, we perform ratio comparisons between the estimated of the t-distributions and the measured distances between pairs of landmark candidates with landmark pairs of a fixed set of edges that have the three lowest estimated of all t-distributions. The motivation behind these ratio terms is the fact that this dataset has no physical resolution, and ratio estimates are invariant to the required distance normalization, which may be inaccurate in inference since it depends on the accurate localization of two landmarks. After cost estimation, the MRF is approximately solved in a non-differentiable way using Loopy Belief Propagation (LBP) [29], which is a variant of the sum-product algorithm. The solver (https://github.com/mbforbes/py-factorgraph last accessed on 22 July 2024) we use is based on factor graphs [39].
Implicit Landmark Refinement with SCN. The SCN of Payer et al. [15] uses a U-Net model for initial landmark localization, which is expected to produce localization results with high local accuracy but requires global disambiguation after convergence. The spatial configuration component then further processes the heavily downsampled U-Net output with multiple successive convolution layers without further internal downsampling and is expected to converge to a state where it outputs a spatial filter heatmap that can be used for landmark refinement of the initial U-Net outputs.
For comparison, we re-implemented the SCN within our framework. For the localization component, we used the U-Net already described in the previous section. Our spatial configuration component consists of three successive convolution layers with a kernel size of (Payer et al. use kernels, because they train on input images) and 128 feature maps to take advantage of a large receptive field for landmark disambiguation. Compared to the original SCN, we also added a batch normalization layer before each activation function.
2.5. Rich-Representation Learning with Occlusions
Inspired by [3,24], we incorporate occlusion perturbations into our data augmentation process. Figure 5 shows examples of the perturbed images used during training. These images underwent additional augmentation, as described in Section 3.2, before the perturbations were applied. Each batch of images is subjected to identical perturbations, potentially occluding different landmarks depending on the spatial transformation applied prior to perturbation. The occlusion boxes are randomly sized to cover between 1 and 15% of the pixels of each input image in our experiments. In contrast to [24], we focus exclusively on the full occlusion strategy, which involves boxes that completely eliminate local appearance information from parts of the input images before they are processed by the localization model. This approach is clinically relevant to our dataset, as it simulates scenarios such as missing fingers or field-of-view cut-offs. In addition, this method is more general, simulating occlusion in different regions of the hand or wrist.
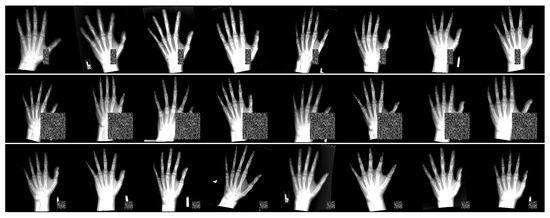
Figure 5.
Examples of perturbed images from 3 batches of 8 input images used in training. Each image in a batch has the same perturbation. Bright regions are regions with intensities above 1.0 (due to data augmentation) and are clamped to 1.0 for visualization purposes (stronger contrast between artificial occlusions and bone tissue).
To prevent the model from overfitting to the centers or intensities of the occlusion boxes, we randomize the pixel intensities and vary the size and placement of the boxes within the scene, potentially avoiding any part of the hand or wrist. Consequently, this perturbation strategy can completely obscure the local information of multiple landmarks in an image, depending on the randomized position of the box. This differs from the protocol in [24], which used uniform black and white boxes with positions randomized close to the ground truth landmark location. Our approach forces the models to rely on global features to make accurate predictions for the occluded landmarks, since the target landmarks used for loss computation remain unchanged. It also improves the overall robustness to noisy structures that are not part of the hand or wrist. Therefore, it applies an implicit anatomical constraint during training.
3. Experimental Setup
Our evaluation procedure consists of two test settings. We adopt the standard test setting that uses three-fold cross validation with the same cross-validation split that can be found in the literature [15,17]. Thus, each fold contains 597 training images and 298 test images, and for all experiments we use the average test performance over all folds, except for the number of outliers, which we sum over all folds. Furthermore, we propose a new occlusion test setting that extends the cross validation of the standard test setting by introducing artificial occlusions to the test images.
3.1. Evaluation Metrics
We use the evaluation metrics described in [15], which are commonly used in the ALL literature. The Point-to-Point Error (PE) describes the general accuracy measurement of ALL approaches and depends on the previously described normalization constant . Therefore, the PE between a predicted landmark position, , of landmark and the target position, , in image j is defined as
Additionally, we compute the arithmetic mean (), Median (MD), and Standard Deviation (SD) of the for all landmarks in image j. Furthermore, the for all images and landmarks is denoted as . Since robustness against outlier predictions is particularly important for ALL, the literature also suggests evaluating the number of outliers exceeding a certain radius, r, from the target location () and their total percentage (). Specifically, we evaluate outliers that are 2 mm, 4 mm, or 10 mm away from their target location (r > 2 mm, r > 4 mm, r > 10 mm).
3.2. Preprocessing and Data Augmentation
We adopt the preprocessing and data augmentation steps from (https://github.com/christianpayer/MedicalDataAugmentationTool-HeatmapRegression/blob/master/hand_xray/dataset.py last accessed: 25 July 2024), implemented using the SimpleITK library (https://simpleitk.org/ last accessed: 25 July 2024). Our approach uses on-the-fly data augmentation, starting with reducing each image to a resolution of . Spatial transformations are then applied using linear resampling, including translation, rotation, and elastic deformation. For translation, images are randomly shifted by [−10, 10] pixels, and rotations are randomly applied within [−0.2, 0.2] radians, both sampled from a uniform distribution. For elastic deformations, points on a grid are randomly shifted by 20 pixels, followed by a third-order B-spline interpolation.
Following spatial transformations, we perform intensity-based data augmentation. Initially, pixel values are normalized between [−1, 1]. A shift operation is then applied, adding a random value within [−0.15, 0.15] to each pixel. Subsequently, each pixel, p, is updated using a value, v, sampled from the same interval, according to the equation:
where is the new pixel value after scaling and is the original pixel value.
For each image, we generate 37 target heatmaps, each corresponding to a unique landmark. These heatmaps all have pixels set to 0, except pixels near the target location, where a Gaussian-distributed blob with a default of 3 pixels is placed. Additionally, a scaling factor of is applied to each pixel of the target heatmaps to ensure numerical stability, as no significant loss improvement was observed during training without , as noted by [15]. These heatmaps undergo the same spatial transformations (translation, rotation, and elastic deformation) as the input images.
3.3. Model Training
Dataset-specific hyperparameters are directly used from [15], e.g., of 3 pixels for the Gaussian blobs used for generating target heatmaps. We evaluated the performance of each model after training for a fixed number of 800 epochs, using a batch size of 8 for all experiments. During each epoch, the model processes the entire training dataset once. To ensure a fair comparison, we did not use early stopping. Additionally, we exclude the computation of landmark predictions rotated out of the image after data augmentation and preprocessing from the loss. As a result, we observed slower but more stable convergence because not all predicted landmarks contribute to each gradient update, justifying the increased number of epochs, compared to [15], which used only 50 epochs. Moreover, we employed the ADAM optimizer [40] instead of the stochastic gradient descent algorithm used in [15], with an initial learning rate of to facilitate faster convergence and achieve good performance without extensive hyperparameter tuning. To account for the difference in magnitude between the losses of U-Net and GAFFA, we scale them to have the same magnitude in the first batch of the first epoch. Furthermore, we train the U-Net and GAFFA end-to-end in a single training run, differently to [25,26].
3.4. Occlusion Test Setting Details
To the best of our knowledge, existing methods in the literature evaluate the ground truth landmark locations in the test set without introducing artificial complexity. Given that state-of-the-art models [20] nearly achieve the required clinical performance with all detected landmarks within 2 mm of the target [3], we propose a more complex test scenario that incorporates occlusions. The motivation for including artificial occlusions is to better simulate clinical conditions where patients may have missing fingers or tags may occlude parts of the hand. In addition, misaligned fields of view or imaging artifacts may introduce additional occlusions. In such cases, ALL methods should still accurately predict non-occluded landmarks and, if necessary, estimate the likely location of missing or occluded landmarks.
Since we treat all landmark predictions equally in the evaluation, we actually test the model’s understanding of global relationships between image features. When a finger is occluded, a human can still vaguely predict the position of each joint based on the appearance of neighboring fingers. Similarly, models need to understand human anatomy in order to make meaningful predictions. Thus, our proposed occlusion test setting allows us to evaluate the ability of CNN architectures to learn complex global relationships between image features.
The first step in our occlusion testing pipeline is to group all five landmarks belonging to a unique finger, denoted as , where . The exception is the thumb, which is represented by only four landmarks. Thus, we have a total of 24 different landmarks representing all the finger joints that can be occluded in our occlusion test setting. For each image j that we want to test, we first uniformly sample random fingers, where each finger has a chance of being selected for further occlusion testing. Next, we uniformly sample pairs of landmarks ( and ) to determine which should be occluded for each selected finger. We also allow for no landmarks to be occluded in the sampled fingers. Therefore, there is still a small chance that no occlusion will be introduced in a particular test image.
The second step of our test scenario takes the randomly selected landmark pairs and occludes the region between them to simulate a missing part of the finger, potentially removing the local appearance information of several whole fingers. The occlusion of a landmark, , is simulated by drawing multiple circles with a fixed radius, r (set to 10 for images), between the neighboring landmarks and . For this, we compute the vector between the 2D coordinates of and with
where , and , mark the x and y components of the landmarks , , respectively.
In addition, we calculate the number of circles, c, to draw between and with
We also use c and to define vector with
where lies in the span of and can be used to calculate the position of the first circle center when added to the coordinates of . To calculate the remaining circle centers, we scale by scalar k, which is the index of the circle we are interested in, before adding it to the point location of . Finally, we fill all circles that are defined with their center location and radius, r, with the intensity value of zero and apply Gaussian noise ( and ) to make the occlusion intensities vary.
Figure 6 shows example results of our occlusion algorithm. We allow a random mixture of partial and full finger occlusions approximated by circles. Due to the fact that these occlusions are random, there may be sampled occlusion test sets with different levels of difficulty. Therefore, when performing experiments in the occlusion test setting, we average the performance over 30 randomly sampled test runs per cross validation fold to take advantage of the law of large numbers to make the performance evaluation account for the introduced randomness. This also makes it harder for models to overfit on the test setting.
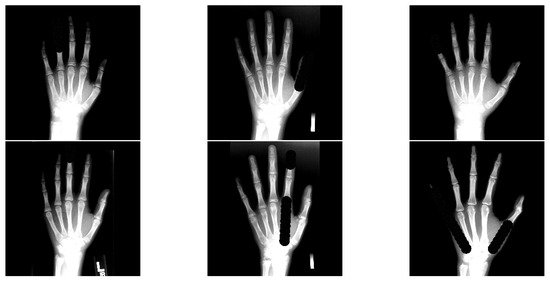
Figure 6.
Six example test images with artificial finger occlusions. Bright regions are regions with intensities above 1.0 (due to data augmentation) and are clamped to 1.0 for visualization purposes (stronger contrast between artificial occlusions and bone tissue).
4. Results
This section reports the experimental results, focusing on the evaluation of landmark refinement methods. First, we primarily evaluated the impact of rich-representation learning with occlusions on the U-Net, as it is the backbone that precedes all landmark refinement methods. Due to the general performance improvement of this perturbation strategy, we kept rich-representation learning enabled for most of the subsequent experiments.
We evaluated the performance of the investigated landmark refinement methods on the discussed standard test setting and occlusion test setting. Furthermore, we compare our best performing GAFFA model with state-of-the-art methods from the literature on the standard test setting. Finally, we show visual results of GAFFA, highlighting its ability to intuitively represent the enforced anatomical constraints as spatial energy heatmaps.
In terms of average inference times, one image took 0.12 s for U-Net, 0.12 s for SCN, 1.81 s for U-Net+GM, and 0.66 s for U-Net+GAFFA. We made these performance measurements on a machine with a GTX 1060 GPU and Intel i5 6600K CPU by averaging over 90 test folds computed in the occlusion test setting.
4.1. Rich-Representation Learning with Occlusions
Exposing the models to occlusions during training largely improved performance across the board, except for the median (MD) metric, as can be seen in Table 1. The initial localization performance of the SCN improved the most when occlusion perturbations were introduced. Inspired by [3], we also investigated the effect of Laplacian blobs, as this distribution gives more importance to the close proximity of the blob peak location. We observed that adding artificial occlusions in training also improves performance in this setup. In addition, we saw slightly better performance when training the U-Net with Laplacian blobs in the standard test setting, even without rich-representation learning. Furthermore, Table 1 also shows that models trained with different blob distributions perform similarly when artificial occlusions are used in training. Except for the reported number of outliers above 4 mm, the U-Net trained with Laplacian blobs has slightly fewer outliers in this scenario. Due to the overall improvement in performance, we continued to use rich-representation learning implemented with artificial occlusions in subsequent experiments.

Table 1.
Comparison of several models that were trained with and without occlusion on the standard test setting. Models were trained with heatmap regression, Mean Squared Error (MSE) loss and target heatmaps that contain Gaussian or Laplacian distributed blobs. Values highlighted in green mark the best result in their respective column. We average the performance over three fixed cross-validation folds per experiment.
4.2. Landmark Refinement Methods and Standard Test Setting
In the standard test setting, the initial localization results of the U-Net trained with rich-representation learning are hard to outperform with our investigated landmark refinement methods, as depicted in Table 2. Post-processing with the Graphical Model severely degrades performance in most metrics, besides a standard deviation of and a number of large outliers (r > 10 mm). The SCN reports a higher amount of small outliers (r > 2 mm) than using the U-Net alone, but improves in filtering larger outliers (r > 4 mm). Training a U-Net with GAFFA, but only evaluating the U-Net component (U-Net+GAFFA), leads to a similar performance as training the U-Net alone. However, the GAFFA model that was trained together with the U-Net from scratch in an end-to-end manner shows higher robustness against large outliers and slightly smaller SD. This result comes at the cost of a slightly increased mean and median of . For completeness, we also trained a U-Net with GAFFA using target heatmaps with Laplacian distributed blobs, which showed similar performance to using Gaussian-distributed blobs in this test setting.
Table 2.
Comparison between different landmark refinement methods on the standard test setting. All models were trained with occlusion perturbation and target heatmaps containing Gaussian-distributed blobs, unless otherwise noted. Models trained with Laplacian blobs are included for completeness, but they are not included in the final comparison. Bold values indicate the best and underlined values indicate the second best performance metric in that column.
4.3. Landmark Refinement Methods and Occlusion Test Setting
The proposed occlusion test setting is much more challenging than the standard test setting used in the literature, as can be seen by comparing the reported performance in Table 2 to Table 3. This test setting further highlights the importance of rich-representation learning in ALL, because models that have been trained Without Artificial Occlusions (WO) perform very poorly in this test setting. This is true for both the U-Net and the SCN models. Surprisingly, the U-Net, with rich-representation learning enabled, largely outperforms the SCN in most metrics in the occlusion test setting. The Graphical Model improves robustness to large outliers and greatly reduces the SD of compared to using the converged U-Net alone, at the cost of larger median and mean , and a larger number of small outliers. In this test setting, we also observed the best overall performance by using the output of GAFFA trained end-to-end with a U-Net from scratch. GAFFA seems to be a good compromise between the high robustness against large outliers of the Graphical Model and the high local accuracy of using the U-Net alone. For completeness, we also trained this model combination with Laplacian blobs, which resulted in even better performance in this test setting. Finally, we can observe in Table 3 that U-Net models evaluated, without their end-to-end trained GAFFA component, show a much lower SD than training and using the U-Net model alone.
Table 3.
Comparison between different landmark refinement methods on the occlusion test setting. All models were trained with occlusion perturbation, except the models marked with WO. One model was trained with Laplacian blobs, but we do not highlight its performance because we want to compare landmark refinement methods as fairly as possible. Bold values indicate the best and underlined values indicate the second best performance metric in that column.
4.4. Comparison to State-of-the-Art
In Table 4, we summarize several reported results using the standard test setting of state-of-the-art methods and compare them to our best model. It is evident that the methods in the literature typically train on higher-resolution images. While higher resolution generally leads to higher accuracy, as indicated by lower mean and median values for models trained on more input pixels, we argue that high robustness to large outliers does not require a high resolution.
Table 4.
Comparison between our best model trained with three-fold cross-validation and state-of-the-art models on the standard test setting. Our model was trained with occlusion perturbations and we averaged the performance over three fixed cross-validation folds, the same as in [15,17]. The method marked with (*) is only mentioned for completeness, as we cannot verify if it used the same testing scenario as [15,17]. Other methods claim to have used three-fold cross-validation. Only a fraction of the methods in the literature report the absolute number of outliers. Therefore, we have estimated these values and marked them in italics. Other unknown values are marked with (?).
Our model outperforms the baseline model from Payer et al. [15] across all metrics, except for the mean and median , despite being trained on only a quarter of the pixels. In addition, we outperform a recent method [17] across all metrics, which also incorporates a strong spatial prior during training. Both methods have public code showing that they use the same cross-validation split.
However, our method is outperformed by the approaches introduced in [20,24], in all metrics except for the number of outliers more than 10 mm from the target. To the best of our knowledge, no other method in the literature matches our robustness to large outliers in this hand dataset, except for the results reported by Viriyasaranon et al. [22]. However, the published code on their linked GitHub repository (https://github.com/seriee/Multiresolution-HTC last accessed 27 July 2024) lacks ALL-related code, and key linked submodules are inaccessible. In addition, they did not specify whether or not they followed the same cross-validation protocol provided by [15], and there is no information on the dataset splits used, which prevents us from reproducing their results. Therefore, we only include their results for completeness. Additionally, we have taken the performance results for [3] from [20], as the original paper does not discuss the performance of their model on the studied hand dataset.
4.5. Qualitative Results of GAFFA and Outlier Analysis
Global Anatomical Feasibility Filter and Analysis (GAFFA) makes it possible to illustrate the learned anatomical constraints in an intuitive way by visualizing the marginal energies of Equation (4) as heatmaps. In the case of the remaining large outlier that we reported in Table 4, we can see that the U-Net and the explicitly enforced anatomical constraint within GAFFA largely agree on the same location, as shown in Figure 7. Hence, we suspect that the outlier prediction is due to an annotation error. In addition, we performed a visual comparison with other input images and their annotations, which also supports this claim, as shown in Figure 8. Therefore, there are strong arguments for considering the position of landmark of image 3836 as an annotation error in this dataset, which, to the best of our knowledge, has not been discussed in the literature.
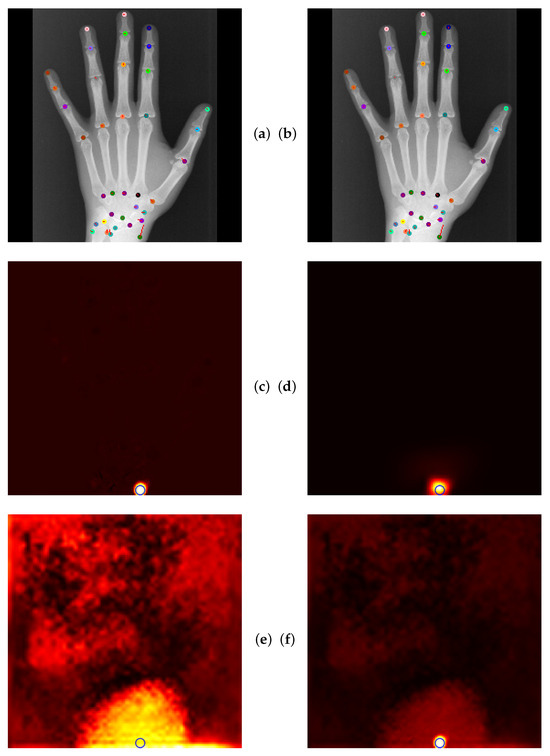
Figure 7.
(a) U-Net localization output with outlier prediction of landmark . (b) GAFFA output, the large outlier remains. (c) Initial marginal energy of shown as heatmap, i.e., brighter pixels have more energy. Blue circle marks the final GAFFA prediction. (d) Marginal energy post sum-product iteration (no bias energy). (e) Bias energy heatmap of . (f) Final marginal energy. GAFFA largely agrees with the initial U-Net prediction. However, the predicted landmark location is more than a centimeter away from its annotation. This strongly suggests that the annotation of is not correctly placed, as it violates the global anatomical feasibility constraint enforced by GAFFA.
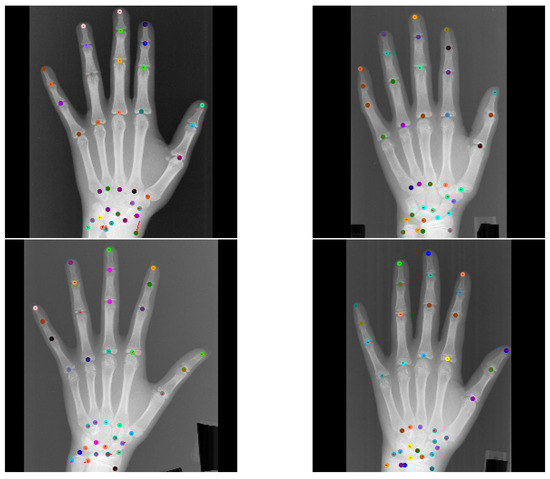
Figure 8.
Top left image shows visual GAFFA output with the only reported large outlier (r > 10 mm) in the standard test setting due to an annotation error. Other images show that similar predictions of the same landmark were accurate. This indicates that the annotation of is not placed correctly in the top left image. Colored circles mark predicted landmark positions and red lines show the distance between predicted location and target location.
We can also see in Figure 9 that the U-Net trained with rich-representation learning still benefits from the introduction of GAFFA. One of the initial U-Net predictions in this example is several centimeters away from the target location, which GAFFA can pull much closer to the annotated target location. Furthermore, this figure shows that the U-Net alone, when trained with artificial occlusions, can understand global relationships between anatomical features and thus accurately localize occluded landmarks where local appearance information is no longer present. However, it cannot be expected that the exact position of landmarks near the fingertips is found based on global information alone, since these landmarks exhibit a high degree of local spatial variety.
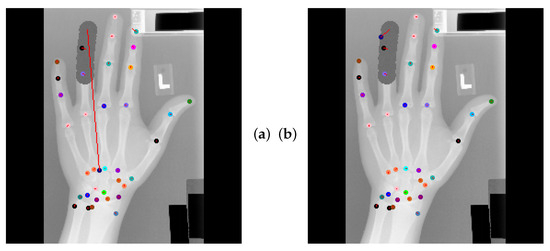

Figure 9.
(a) U-Net localization output with huge outlier prediction (red line) of landmark that is artificially occluded. (b) GAFFA output pulling outlier closer to target. (c) Initial marginal energy of . Green circle marks the U-Net prediction. Blue circle marks the final GAFFA prediction. (d) Marginal energy post sum-product iteration (no bias energy). (e) Bias energy heatmap of . (f) Final marginal energy. This example shows that implicit anatomical constraints can improve overall ALL performance and make models understand the global relationships between anatomical structures. However, the explicit anatomical constraints enforced by GAFFA are needed to further reduce the risk of outlier predictions.
5. Discussion
This section begins with a short discussion of rich-representation learning with occlusions, which improved the performance of our localization model across all metrics. This is followed by a detailed examination of each landmark refinement method.
5.1. Rich-Representation Learning with Occlusions
Our experiments show that incorporating rich-representation learning enables the U-Net to implicitly learn global relations between anatomical structures, consistent with the findings in [3,24]. Our results indicate that the attention mechanism is not required for ALL models to effectively learn global features, contrary to the belief in [1,21]. Consequently, the performance of all our models improved in all scenarios when occlusion perturbations were used during training. This method is essential to achieve occlusion invariance, a highly relevant property in clinical settings, as model performance deteriorates in the occlusion test setting without rich-representation learning. Furthermore, this approach does not introduce additional training parameters or computational complexity.
5.2. Landmark Refinement Methods
We explored explicit anatomical landmark refinement using the Graphical Model (GM), implicit anatomical constraints within the SpatialConfiguration-Net (SCN), and end-to-end trainable explicit anatomical constraints within our proposed Global Anatomical Feasibility Filter and Analysis (GAFFA) method. Furthermore, we utilized rich-representation learning with occlusions in all of these experiments, which represents another form of implicit anatomical constraint applied during training. In this way, we could demonstrate that explicit anatomical constraints are needed to enhance the robustness of ALL methods.
5.2.1. Graphical Model
The GM, solved with Loopy Belief Propagation (LBP), greatly increases the robustness of U-Net predictions in our occlusion test setting by explicitly leveraging prior anatomical information. However, it also heavily increases the reported mean and median , especially in the standard test setting, where this landmark refinement method generally degrades initial localization performance for most metrics. We argue that this performance degradation can be partially attributed to the need for a blob peak extraction method to define landmark candidates, which introduces errors by assuming perfectly Gaussian blobs within a certain width range controlled by the parameter. Furthermore, this method is limited to selecting landmark candidates extracted from the corresponding prediction heatmap of a unique landmark and cannot introduce new candidates. Finally, the GM is a separate, non-differentiable component that cannot be integrated into end-to-end training.
Although graphical models have been effectively used for landmark refinement in previous studies [10,11], we argue that their performance largely depends on the uncertainty of shallow prediction methods, such as Regression Forests [10,41], which generate many landmark candidates for each unique landmark. In the context of deep-learning models trained on large datasets, which are confident in their predictions after convergence, our results show that the GM is severely outperformed by both the SCN and GAFFA across all metrics, except for Standard Deviation (SD) and large outliers, where it performs similarly to GAFFA. However, we argue that the use of the GM is justified in scenarios where models are uncertain (e.g., very small datasets) and provide sufficient landmark candidates such that there are anatomically feasible candidates to choose from for each unique landmark.
5.2.2. SpatialConfiguration-Net
The SCN, in contrast to the Graphical Model, supports end-to-end training and relies on a weaker implicit anatomical constraint through its spatial configuration component. This component allows the overall model to partition the ALL task into localization and refinement during training. However, there is no guarantee that the model converges to this state, as the loss only evaluates the final heatmap computed with the Hadamard product between the localization prediction and the output of the spatial configuration component. Our experimental results deviate from those reported in Payer et al. [15], who showed that the SCN outperforms the U-Net. It can be argued that differences in our setup (e.g., use of the Adam optimizer, lower resolution, batch normalization in the spatial configuration component, and a batch size larger than one) could explain the different performance measurements compared to [15]. However, according to [15], the performance improvement of the SCN is mainly due to the addition of the spatial configuration component, which acts as a spatial filter and constrains the output to anatomical feasibility after convergence. After training the SCN in our framework, our localization component indeed converged to accurately report locally similar structures, and the spatial configuration component acted as a spatial filter, as illustrated in Figure 10.

Figure 10.
(a) Localization (U-Net) output. Locally accurate, but globally ambiguous landmark predictions. (b) Spatial configuration output. Spatial filter for landmark disambiguation. (c) Final SCN output. (d) Target heatmap. The gray areas in the top images are due to the fact that these images have a very different intensity distribution than the bottom images. Therefore, they are shown with different contrast settings to visually depict the intensity range within each image more clearly.
Our results indicate that the anatomical constraint modeled within the SCN architecture is too weak for reliable outlier filtering. Additionally, the implicit partitioning of the ALL task into localization and spatial constraint in the SCN does not adapt to occlusion perturbations during training as effectively as using the U-Net alone. We hypothesize that this behavior is due to the constrained receptive field of the spatial configuration component, which is limited by its kernel size and cannot fully exploit information from neighboring landmark predictions that are not occluded when specific landmarks are blocked. Although the spatial configuration component uses very large kernels (resulting in a large number of learnable parameters) and operates in a highly downsampled image space, it does not undergo further downsampling during each convolution. Our results show that the U-Net can internally handle landmark disambiguation just as well without additional parameters. Similarly, GAFFA also has large kernels and operates in the same image space, but it includes a fixed internal mathematical model that ensures that occluded landmarks can be estimated by other landmark predictions with intact local appearance, while using prior anatomical information for kernel initialization.
5.2.3. Global Anatomical Feasibility Filter and Analysis
GAFFA outperforms other landmark refinement methods in our framework across all experiments and test settings. This is achieved despite having a similar number of learnable parameters, operating in the same image space, using the same localization model training setup with occlusion perturbations, and the same training duration. In the occlusion test setting, GAFFA reduced the standard deviation to almost half the value compared to using the U-Net alone, while maintaining low mean and median compared to the GM. Even using only the U-Net component trained with GAFFA showed more robustness to large outliers and lower SD in the occlusion test setting than the U-Net model trained alone. This demonstrates that GAFFA is a valuable component for end-to-end training with a U-Net, improving robustness to outliers after convergence, which is critical for ALL performance in clinical scenarios.
Our visualization results of GAFFA further confirm that this methodology is the most promising landmark refinement approach in our framework. The state of converged deep-learning models is often difficult to interpret, with no guarantee of robust handling of out-of-distribution inputs. GAFFA provides a fixed, differentiable mathematical constraint within a CNN that improves the robustness of landmark predictions by approximately solving a Markov Random Field (MRF) with a single iteration of the sum-product algorithm. This imposes a strong anatomical constraint on the predictions of the localization model by using pre-computed conditional distribution heatmaps that encode prior anatomical knowledge. In addition, this approach allows us to intuitively visualize the anatomical certainty of our approximated MRF solution by staying in image space. Staying in image space is a big advantage over the GM because it does not require inaccurate blob detection methods for landmark candidate extraction. Therefore, we found only a small increase in the mean and median point-to-point error compared to using the U-Net alone. Furthermore, GAFFA uses information from all prediction heatmaps to filter each unique landmark, where all pixels in our localization heatmap space are potential landmark candidates, which is another advantage over the Graphical Model.
Despite using grouped convolutions in Fourier space with FFT, a drawback of GAFFA is its inference time, which is almost six times longer than using the U-Net alone (GTX 1060 GPU and Intel i5 6600K CPU). This is due to the computationally expensive large convolution kernels used repeatedly in Equation (4). In addition, the definition of a dataset-specific graph topology, as shown in Figure 2, is necessary to handle occlusions without increasing the computational overhead, as each added global landmark is convolved with every other landmark in GAFFA.
Regarding related work, GAFFA could not outperform the reported performance of state-of-the-art approaches trained on much higher resolution inputs. However, it is unclear whether or not they used the same test setup with cross-validation as Payer et al. [15], as their test schemes are not described in detail. Only two of the papers [20,24] that outperform our model on the standard test setting mention three-fold cross-validation, but do not specify if they used the same splitting as [15]. Since they have not published their code, we cannot verify the correct splitting. For this reason, we have included a performance measurement of [3] for the studied hand dataset, which was taken from a results table in [20], as the original paper of [3] does not discuss experiments with this dataset.
However, we were able to outperform the SCN model of [15] on all metrics except mean and median , which are not as important as robustness to outliers in clinical practice, especially when localization serves as an initial step for more detailed segmentation or classification/regression tasks [33,34]. Furthermore, we outperformed a very recent state-of-the-art approach [17] on all metrics in the standard test setting, which also uses prior anatomical information during training and employs the coordinate regression scheme of DSNT. Importantly, the authors of [17] used the same test setup with the same cross-validation split as [15], and their code is publicly available. Finally, we argue that the reported performance of [22] is difficult to reproduce because they have not published any information about their test and training splits or their general testing scheme. They claim to have no outlier prediction more than 10 mm from the ground truth location. However, we argue that the found annotation error of the hand dataset makes it very difficult for converged models to report no outliers beyond 10 mm (our best model reports one 10 mm outlier). We further argue that models that agree with this annotation error are unlikely to understand the anatomical relationships as well as GAFFA and may have overfitted on the dataset. In addition, the explicit anatomical constraints within GAFFA are enforced during training and inference, which is not guaranteed by other methods in the literature that only use implicit anatomical constraints.
In cases of large outliers in the occlusion test setting, where strong occlusions can cause entire fingers to be missing, it becomes increasingly difficult to accurately predict the landmark location the closer the landmark is to the fingertips. In these cases, as shown in Figure 9, we cannot expect our model to be very accurate locally due to insufficient information; however, we are still able to provide a good estimate due to our incorporated explicit anatomical constraint.
Overall, these observations strongly suggest that, to the best of our knowledge, our approach is the most robust to large outliers in the literature at the time of writing, while still maintaining comparable performance on other metrics to other state-of-the-art methods.
6. Conclusions
Current ALL literature mainly focuses on implicit anatomical constraints to make ALL methods more robust against outlier predictions, which are detrimental for subsequent medical applications. This work investigates how well explicit anatomical constraints can improve the landmark refinement performance of ALL methods. We propose the end-to-end trainable Global Anatomical Feasibility Filter and Analysis (GAFFA) method that explicitly enforces anatomical constraints based on prior anatomical knowledge learned from the data. We compared the proposed method with two other landmark refinement techniques, the SpatialConfiguration-Net (SCN) and the Graphical Model (GM). SCN has an implicit anatomical constraint within the network, as it expects its two components to converge to a state where one acts as a locally accurate localizer, while the other is expected to act as a spatial filter. However, there is no guarantee that the model will converge to this state. The GM uses an explicit anatomical constraint by defining the landmark refinement task as a discrete optimization problem that is approximated in an external post-processing step. However, it cannot be closely integrated into an end-to-end trained model.
We tested all methods on the standard test setting, which we adopted directly from the literature, and the occlusion test setting, which brings the test setting closer to clinical practice, where occlusions may occur. The occlusion test setting demonstrated that the U-Net can capture the global relationship between anatomical structures without using attention, which is often thought to be necessary for CNNs to effectively learn global features [1,21]. By exposing it to artificial occlusions during training, the U-Net alone was able to accurately localize landmarks, even in the absence of local appearance information. However, despite using implicit anatomical constraints during training, it still requires the use of GAFFA to increase robustness against anatomically infeasible predictions.
We could demonstrate that GAFFA outperforms the other implemented landmark refinement paradigms GM and SCN in both test settings. Compared to the state-of-the-art methods, GAFFA shows a high level of robustness against large outliers while still performing well on other metrics. There are other methods [22] that claim to have zero outliers that are 10 mm away from the target position (we report one). However, we were able to show that there is an annotation error in the dataset, which prevents our model from reporting zero large outliers. This was possible due to visual inspection and the fact that we can visually analyze the learned anatomical constraint within GAFFA. Therefore, we argue that models that agree with this annotation error overfit on the dataset and cannot understand anatomy as well as GAFFA.
Future Work
GAFFA may have shown high outlier robustness on this 2D dataset. However, we argue that current ALL methods are performance saturated on the studied, still widely used, hand dataset. Therefore, future work should focus on applying our proposed method to other datasets, e.g., [42], which are more complex and better represent occlusions that may occur in clinical practice. Furthermore, since GAFFA introduces computational overhead, it has to be investigated how to best extend our proposed method to 3D data. Moreover, we believe that there is potential for further automating the process of finding annotation errors with GAFFA that should be explored in future work. In addition, data efficiency is a very important property for models working on medical imaging tasks due to the sparsity of annotated data. Although we could not fully explore this aspect for our investigated models, preliminary experiments with only 50 training samples per fold indicated that GAFFA is more sensitive to weight initialization compared to other methods. Therefore, this aspect should also be further investigated in future experiments. Finally, to use GAFFA in a clinical setting, future work has to explore how to introduce a flag indicating whether a landmark is present (not occluded) in an image or not. This would allow physicians or subsequent medical applications to exclude the marked landmarks from further analysis.
Author Contributions
S.J.J., conceptualization, methodology, software, visualization, writing—original draft; A.H., methodology, investigation, writing—review and editing; M.U., conceptualization, methodology, funding acquisition, supervision, writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded in whole or in part by the Austrian Science Fund (FWF) 10.55776/PAT1748423.
Data Availability Statement
The data presented in this study are available publicly. Upon acceptance, we will provide data and code for our test scenarios and models via a publicly available repository.
Acknowledgments
We thank Franz Thaler for fruitful discussions during the course of this project.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ALL | Anatomical Landmark Localization |
| CPU | Central Processing Unit |
| GPU | Graphics Processing Unit |
| CNN | Convolutional Neural Network |
| SCN | SpatialConfiguration-Net |
| GM | Graphical Model |
| GAFFA | Global Anatomical Feasibility Filter and Analysis |
| MRF | Markov Random Field |
| GMM | Gaussian Mixture Model |
| LBP | Loopy Belief Propagation |
| FFT | Fast Fourier Transform |
| MSE | Mean Squared Error |
| DSNT | Differentiable Spatial to Numerical Transform |
| MD | Median |
| SD | Standard Deviation |
| WO | Without Artificial Occlusions |
References
- Lu, G.; Shu, H.; Bao, H.; Kong, Y.; Zhang, C.; Yan, B.; Zhang, Y.; Coatrieux, J. CMF-Net: Craniomaxillofacial Landmark Localization on CBCT Images using Geometric Constraint and Transformer. Phys. Med. Biol. 2023, 68, 095020. [Google Scholar] [CrossRef]
- Wang, C.W.; Huang, C.T.; Lee, J.H.; Li, C.H.; Chang, S.W.; Siao, M.J.; Lai, T.M.; Ibragimov, B.; Vrtovec, T.; Ronneberger, O.; et al. A benchmark for comparison of dental radiography analysis algorithms. Med. Image Anal. 2016, 31, 63–76. [Google Scholar] [CrossRef] [PubMed]
- Oh, K.; Oh, I.; Le, V.N.T.; Lee, D. Deep Anatomical Context Feature Learning for Cephalometric Landmark Detection. IEEE J. Biomed. Health Inform. 2020, 25, 806–817. [Google Scholar] [CrossRef]
- Rakosi, T. An Atlas and Manual of Cephalometric Radiography; Lea & Febiger: Philadelphia, PA, USA, 1982. [Google Scholar]
- Oktay, O.; Bai, W.; Guerrero, R.; Rajchl, M.; de Marvao, A.; O’Regan, D.P.; Cook, S.A.; Heinrich, M.P.; Glocker, B.; Rueckert, D. Stratified Decision Forests for Accurate Anatomical Landmark Localization in Cardiac Images. IEEE Trans. Med. Imaging 2017, 36, 332–342. [Google Scholar] [CrossRef]
- Urschler, M.; Zach, C.; Ditt, H.; Bischof, H. Automatic Point Landmark Matching for Regularizing Nonlinear Intensity Registration: Application to Thoracic CT Images. In Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), Copenhagen, Denmark, 1–6 October 2006; Volume 9, pp. 710–717. [Google Scholar] [CrossRef]
- Tiulpin, A.; Melekhov, I.; Saarakkala, S. KNEEL: Knee Anatomical Landmark Localization using Hourglass Networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef]
- Zhao, Q.; Zhu, J.; Zhu, J.; Zhou, A.; Shao, H. Bone Anatomical Landmark Localization with Cascaded Spatial Configuration Network. Meas. Sci. Technol. 2022, 33, 065401. [Google Scholar] [CrossRef]
- Glocker, B.; Feulner, J.; Criminisi, A.; Haynor, D.R.; Konukoglu, E. Automatic localization and identification of vertebrae in arbitrary field-of-view CT scans. In Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), Nice, France, 1–5 October 2012; pp. 590–598. [Google Scholar] [CrossRef]
- Donner, R.; Menze, B.H.; Bischof, H.; Langs, G. Global Localization of 3D Anatomical Structures by pre-filtered Hough Forests and Discrete Optimization. Med. Image Anal. 2013, 17, 1304–1314. [Google Scholar] [CrossRef]
- Potesil, V.; Kadir, T.; Platsch, G.; Brady, M. Personalized graphical models for anatomical landmark localization in whole-body medical images. Int. J. Comput. Vis. 2015, 111, 29–49. [Google Scholar] [CrossRef]
- Urschler, M.; Ebner, T.; Štern, D. Integrating Geometric Configuration and Appearance Information into a Unified Framework for Anatomical Landmark Localization. Med. Image Anal. 2018, 43, 23–36. [Google Scholar] [CrossRef]
- Ghesu, F.C.; Georgescu, B.; Zheng, Y.; Grbic, S.; Maier, A.; Hornegger, J.; Comaniciu, D. Multi-scale deep reinforcement learning for real-time 3D-landmark detection in CT scans. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 176–189. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Payer, C.; Štern, D.; Bischof, H.; Urschler, M. Integrating Spatial Configuration into Heatmap Regression based CNNs for Landmark Localization. Med. Image Anal. 2019, 54, 207–219. [Google Scholar] [CrossRef] [PubMed]
- Ao, Y.; Wu, H. Feature Aggregation and Refinement Network for 2D Anatomical Landmark Detection. J. Digit. Imaging 2023, 36, 547–561. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Zhao, R.; Leung, F.H.F.; Banerjee, S.; Lam, K.; Zheng, Y.; Ling, S.H. Landmark Localization from Medical Images with Generative Distribution Prior. IEEE Trans. Med. Imaging 2024, 43, 2679–2692. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Weng, C.; Huang, Y.; Fu, C.; Yeh, Y.; Yeh, C.; Tsai, T. Automatic Recognition of Whole-Spine Sagittal Alignment and Curvature Analysis through a Deep Learning Technique. Eur. Spine J. 2022, 31, 2092–2103. [Google Scholar] [CrossRef] [PubMed]
- Ham, G.; Oh, K. Learning Spatial Configuration Feature for Landmark Localization in Hand X-rays. Electronics 2023, 12, 4038. [Google Scholar] [CrossRef]
- Zhu, H.; Yao, Q.; Zhou, S.K. DATR: Domain-Adaptive Transformer for Multi-Domain Landmark Detection. arXiv 2022, arXiv:2203.06433. [Google Scholar] [CrossRef]
- Viriyasaranon, T.; Ma, S.; Choi, J. Anatomical Landmark Detection Using a Multiresolution Learning Approach with a Hybrid Transformer-CNN Model. In Proceedings of the Medical Image Computing and Computer Assisted Intervention (MICCAI), Vancouver, BC, Canada, 8–12 October 2023; pp. 433–443. [Google Scholar] [CrossRef]
- Guo, M.; Xu, T.; Liu, J.; Liu, Z.; Jiang, P.; Mu, T.; Zhang, S.; Martin, R.R.; Cheng, M.; Hu, S. Attention Mechanisms in Computer Vision: A Survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Kang, J.; Oh, K.; Oh, I. Accurate Landmark Localization for Medical Images using Perturbations. Appl. Sci. 2021, 11, 10277. [Google Scholar] [CrossRef]
- Gdoura, A.; Degünther, M.; Lorenz, B.; Effland, A. Combining CNNs and Markov-like Models for Facial Landmark Detection with Spatial Consistency Estimates. J. Imaging 2023, 9, 104. [Google Scholar] [CrossRef]
- Tompson, J.; Jain, A.; LeCun, Y.; Bregler, C. Joint Training of a Convolutional Network and a Graphical Model for Human Pose Estimation. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Kindermann, R.; Snall, J.L. Markov Random Fields and Their Applications; American Mathematical Society: Providence, RI, USA, 1980. [Google Scholar]
- McLachlan, G.J.; Rathnayake, S. On the Number of Components in a Gaussian Mixture Model. In Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery; Wiley: Hoboken, NJ, USA, 2014; Volume 4, pp. 341–355. [Google Scholar] [CrossRef]
- Wainwright, M.J.; Jordan, M.I. Graphical Models, Exponential Families, and Variational Inference. Found. Trends Mach. Learn. 2008, 1, 1–305. [Google Scholar] [CrossRef]
- Nibali, A.; He, Z.; Morgan, S.; Prendergast, L. Numerical Coordinate Regression with Convolutional Neural Networks. arXiv 2018, arXiv:1801.07372. [Google Scholar] [CrossRef]
- Szeliski, R.; Zabih, R.; Scharstein, D.; Veksler, O.; Kolmogorov, V.; Agarwala, A.; Tappen, M.; Rother, C. A Comparative Study of Energy Minimization Methods for Markov Random Fields with Smoothness-Based Priors. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1068–1080. [Google Scholar] [CrossRef] [PubMed]
- Ebner, T.; Štern, D.; Donner, R.; Bischof, H.; Urschler, M. Towards Automatic Bone Age Estimation from MRI: Localization of 3D Anatomical Landmarks. In Proceedings of the Medical Image Computing and Computer Assisted Intervention (MICCAI), Boston, MA, USA, 14–18 September 2014; pp. 421–428. [Google Scholar] [CrossRef]
- Štern, D.; Payer, C.; Urschler, M. Automated Age Estimation from MRI Volumes of the Hand. Med. Image Anal. 2019, 58, 101538. [Google Scholar] [CrossRef] [PubMed]
- Štern, D.; Payer, C.; Giuliani, N.; Urschler, M. Automatic Age Estimation and Majority Age Classification From Multi-Factorial MRI Data. IEEE J. Biomed. Health Inform. 2019, 23, 1392–1403. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6 July–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier Nonlinearities Improve Neural Network Acoustic Models. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 17–19 June 2013; Volume 30, p. 3. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Kolmogorov, V. Convergent Tree-Reweighted Message Passing for Energy Minimization. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1568–1583. [Google Scholar] [CrossRef]
- Kschischang, F.; Frey, B.; Loeliger, H.A. Factor Graphs and the Sum-Product Algorithm. IEEE Trans. Inf. Theory 2001, 47, 498–519. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Criminisi, A.; Shotton, J. Decision Forests for Computer Vision and Medical Image Analysis; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Hadzic, A.; Urschler, M.; Press, J.A.; Riedl, R.; Rugani, P.; Štern, D.; Kirnbauer, B. Evaluating a Periapical Lesion Detection CNN on a Clinically Representative CBCT Dataset-A Validation Study. J. Clin. Med. 2023, 13, 197. [Google Scholar] [CrossRef]
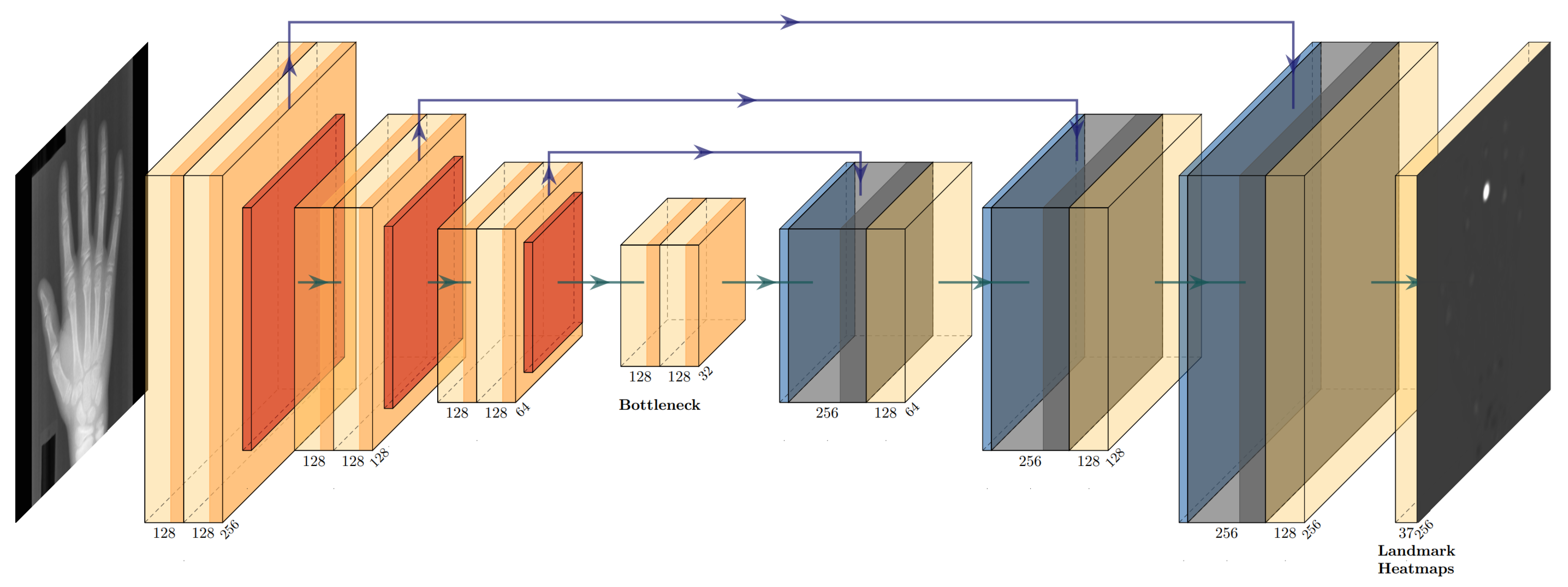
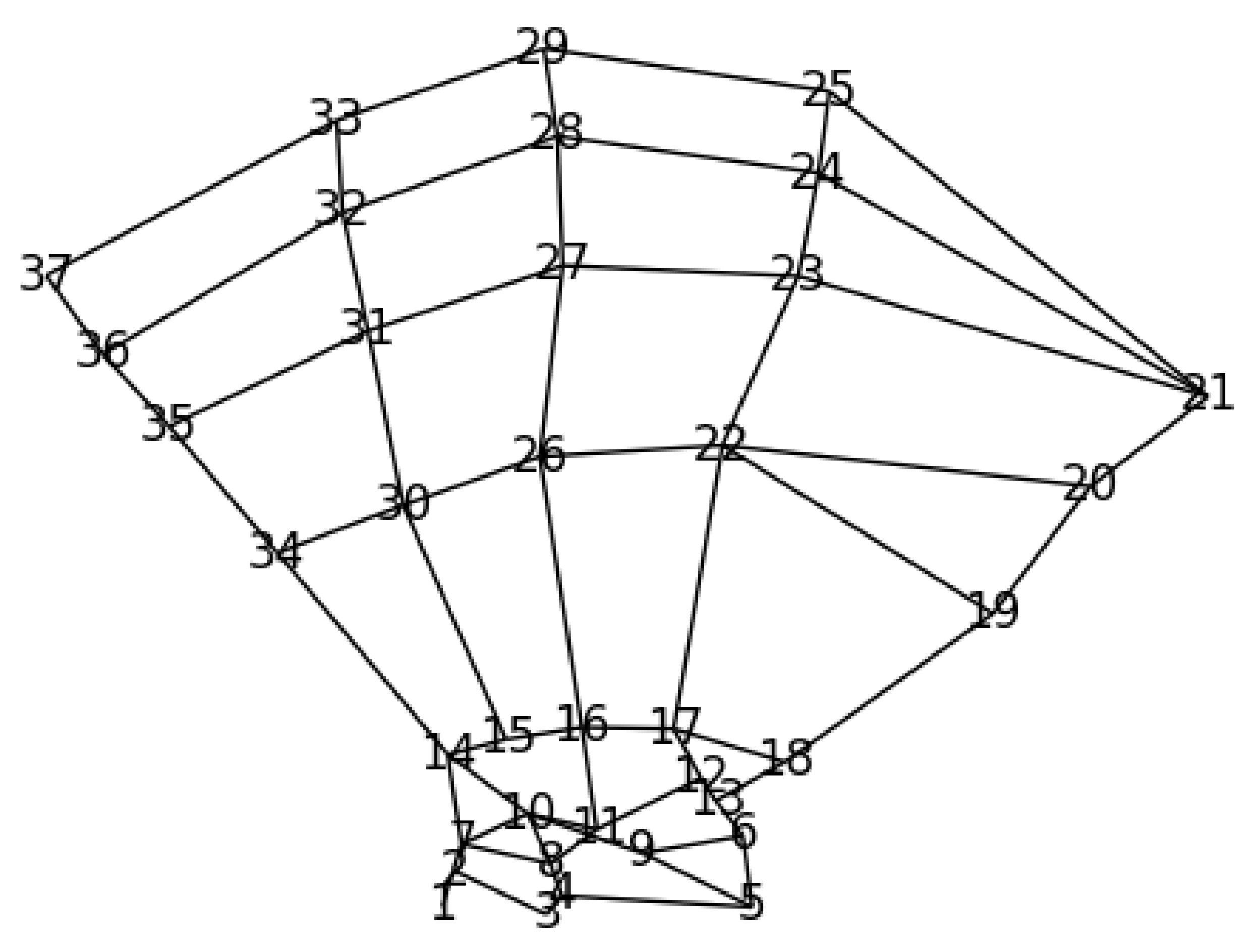
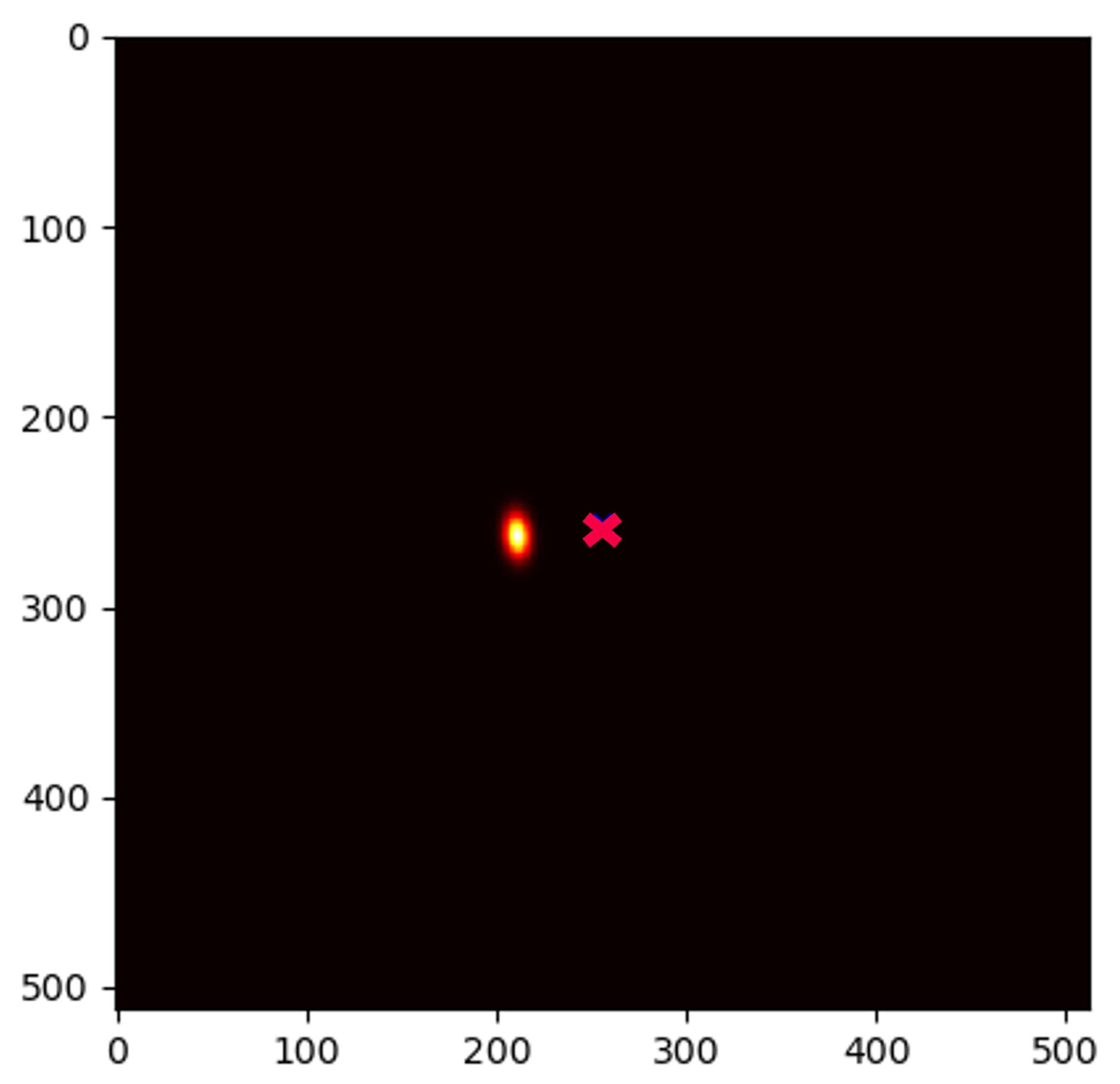
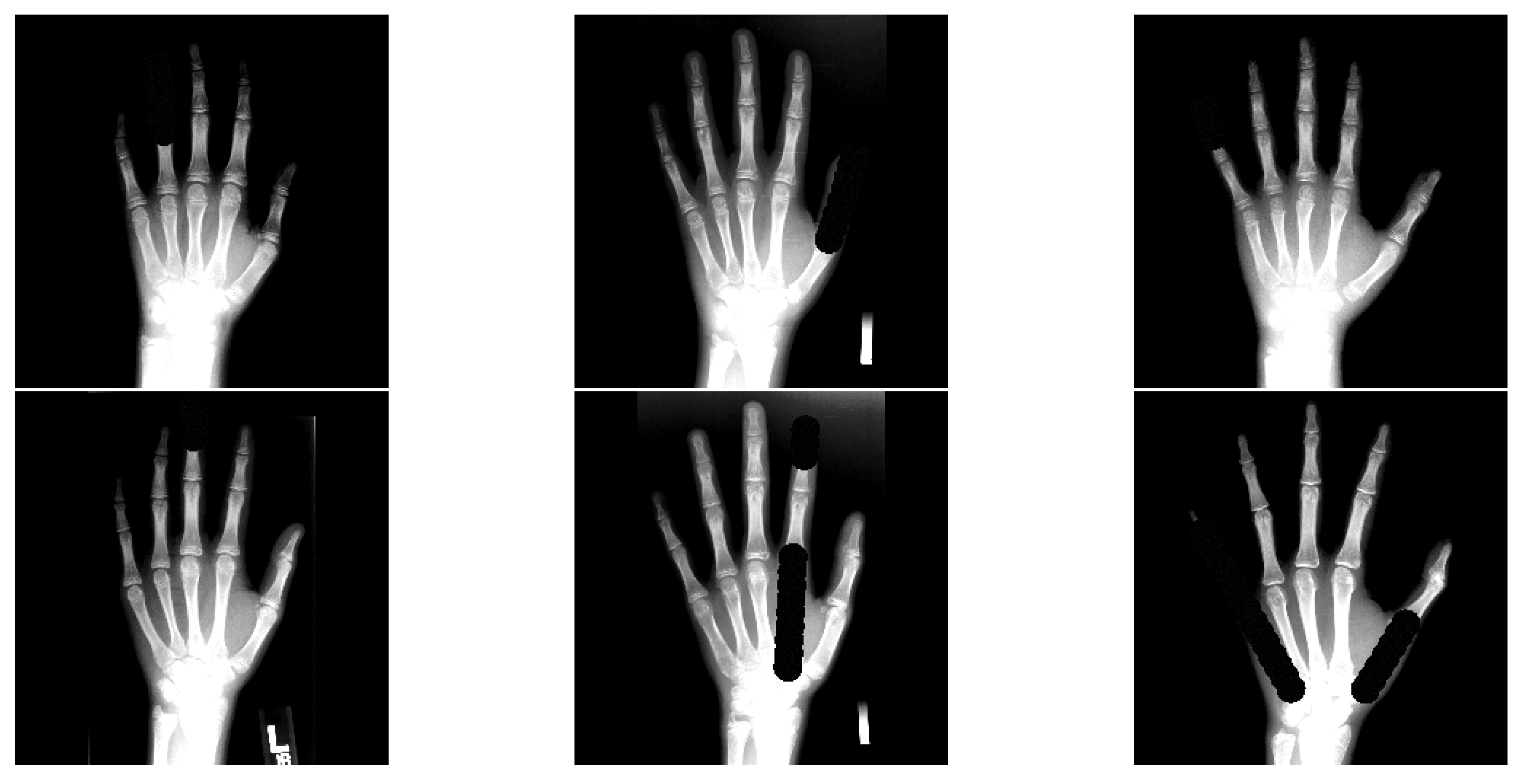
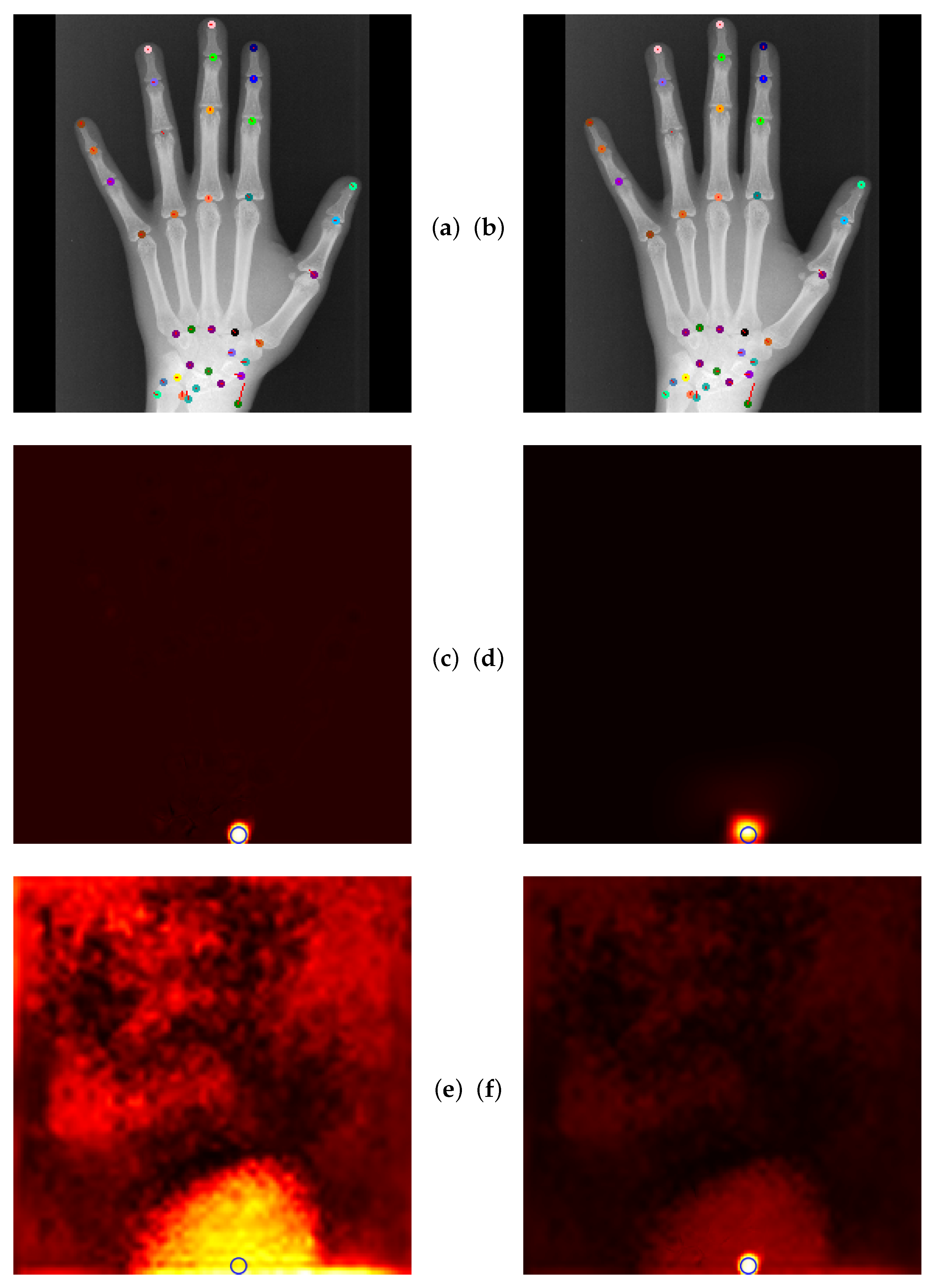
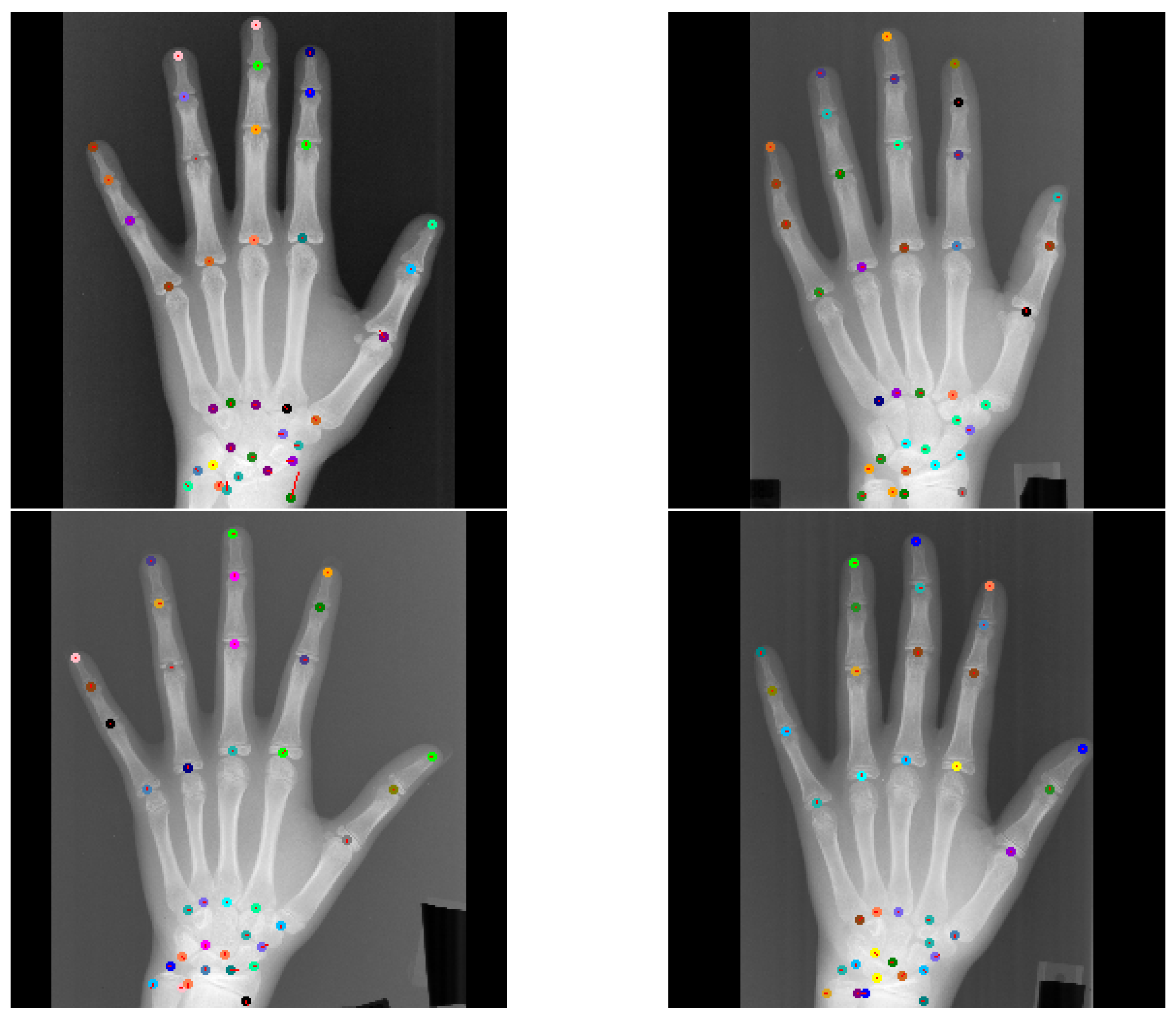
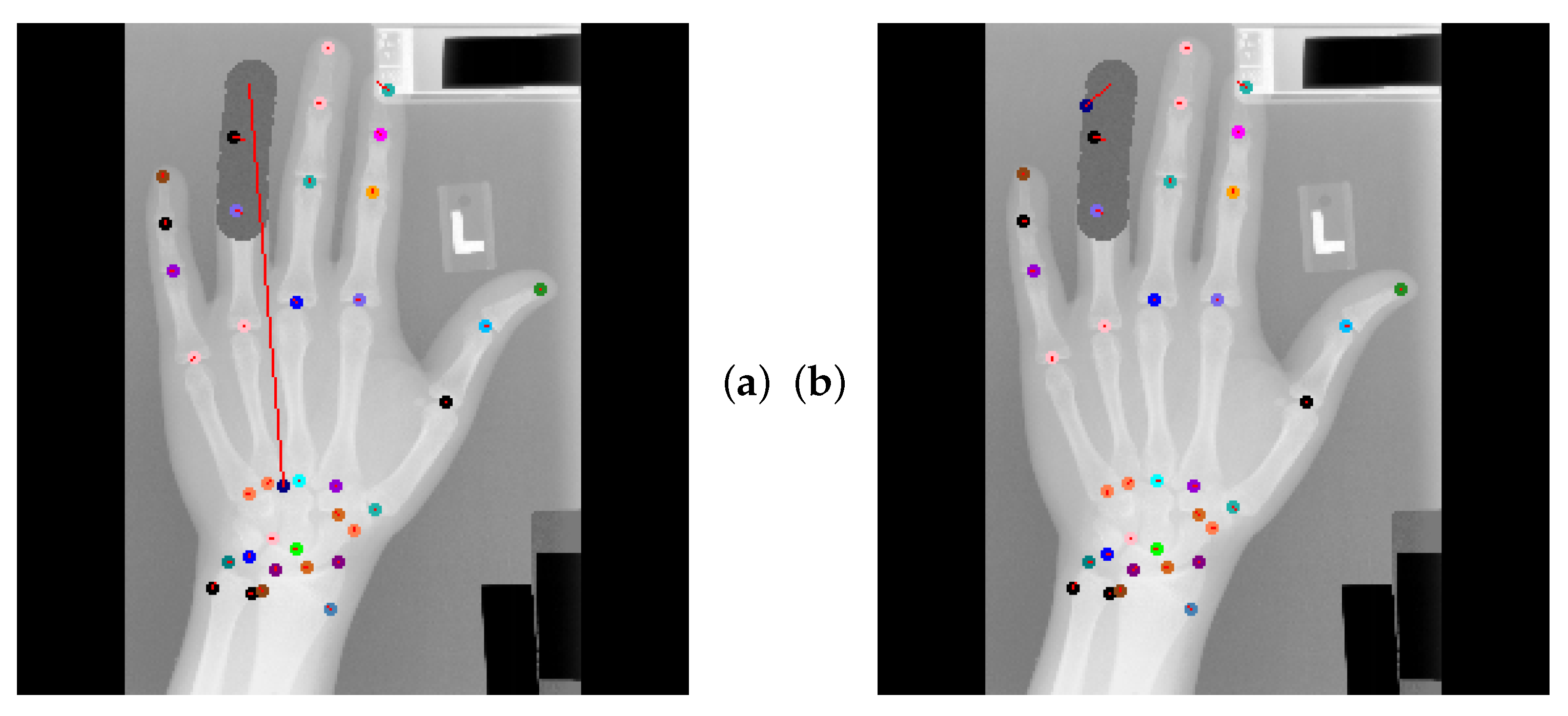


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).