

Decoding Depression from Different Brain Regions Using Hybrid Machine Learning Methods



Abstract
:1. Introduction
- The direct application of traditional machine learning and deep learning methods, such as traditional classifiers like KNN and SVM, as well as deep learning models like LSTM [12,13,14,15,16]. Although deep learning has demonstrated potential in pattern recognition and feature extraction, it heavily relies on large-scale, high-quality data and is prone to overfitting issues under relatively limited EEG sample conditions.
- Most previous studies have adopted a single-classifier strategy, which makes it difficult to fully leverage the advantages and complementarity of different models in feature recognition.
2. Materials and Methods
2.1. EEG Dataset
2.2. Preprocessing
- (a)
- Channel Preprocessing and Standardization: Using the MNE library, the irrelevant channels (e.g., ‘EEG A2-A1’, ‘EEG 23A-23R’, and ‘EEG 24A-24R’) were removed. The channel names were standardized following the international 10–20 system. The EEG channels were re-referenced using an average reference method to unify the baseline for waveform analysis.
- (b)
- Filtering: EEG signals related to depression typically occur within a 0.5–50 Hz frequency range [18]. An FIR filter was applied to remove low-frequency drift and high-frequency noise, retaining signals within the 0.5–50 Hz range. Additionally, a 50 Hz notch filter was used to suppress power line interference.
- (c)
- Artifact Removal: Independent Component Analysis (ICA) was employed to detect and suppress non-cerebral noise sources, such as electrooculography (EOG), electromyography (EMG), and electrocardiography (ECG). Artifacts, particularly those highly correlated with eye movements detected in the frontal channels, were screened and removed based on a threshold criterion to ensure signal purity.
2.3. Data Segmentation
2.4. Feature Extraction
- (1)
- PSD (Power Spectral Density)PSD is an important characteristic used to describe how a signal is distributed in the frequency domain. It reflects the distribution of signal power across various frequencies.The power spectra for all the EEG frequency bands were computed using the Fast Fourier Transform (FFT) with a sampling frequency of 256 Hz and a default window length equal to twice the lowest frequency of the band. Initially, the Welch method [21] was applied to calculate the PSD for each electrode across the , , , , , and bands. To compute the total power in a specific frequency band, we used Simpson’s rule for numerical integration of the PSD. Relative power can also be calculated by dividing the power of a specific frequency band by the total power across the entire spectrum, thereby accounting for the effect of the bandwidth.The signal was divided into multiple segments, each processed with a window function and subjected to FFT. The PSD estimates from each segment were averaged to yield the final PSD estimate. This approach not only improves the accuracy of PSD estimation but also facilitates a more precise analysis and interpretation of the frequency-domain characteristics of EEG activity. The specific calculation method is as follows:Let the discrete signal x, of length N, be divided into K segments, each containing M data points. The starting points of consecutive segments are spaced R data points apart, meaning that the overlap between consecutive segments is . The m-th segment after windowing is represented as follows:Here, represents the window function, and . The PSD estimate of the m-th segment obtained using the periodogram method, , is given by the following:Finally, the PSD estimate of the signal x, , is obtained by averaging the PSD estimates of all the segments:
- (2)
- Hurst ExponentThe Hurst Exponent (H) is a measure of the long-range dependence and persistence of a time series. It assesses the persistence or anti-persistence of the signal by analyzing its fluctuation behavior.For a given time series , the cumulative deviation sequence is constructed as follows:where is the mean of the time series. For the cumulative deviation sequence , the range and the standard deviation are calculated. The normalized range is given by , and the Hurst Exponent is calculated by fitting the relationship between the normalized range and the time length on a logarithmic scale:
- (3)
- Sample EntropySample entropy is a method for measuring the complexity and uncertainty of a time series. It evaluates the signal’s complexity by calculating the probability of pattern occurrence within the signal. The larger the sample entropy, the more complex the signal, and conversely, the smaller the sample entropy, the simpler the signal.The specific calculation method is as follows: For a given time series , a pattern vector of length m is constructed as . For each pattern vector , the distance to other pattern vectors is calculated (usually the maximum distance), and the number of pattern vectors with a distance less than r is counted. Sample entropy is defined as follows:where A and B are the number of matching pattern vectors, respectively.
- (4)
- Higuchi Fractal DimensionThe Higuchi fractal dimension is a method used to describe the complexity and self-similarity of a time series. It evaluates the complexity of the signal by calculating its dimension at different scales.For a given time series , a new time series is constructed using different scale factors k, where m is the initial point and k is the scale factor. For each new time series , the length is calculated. For a given scale factor k, the average length of all new series is calculated. The fractal dimension is estimated by fitting the relationship between the average length and scale factor on a logarithmic scale, as follows:
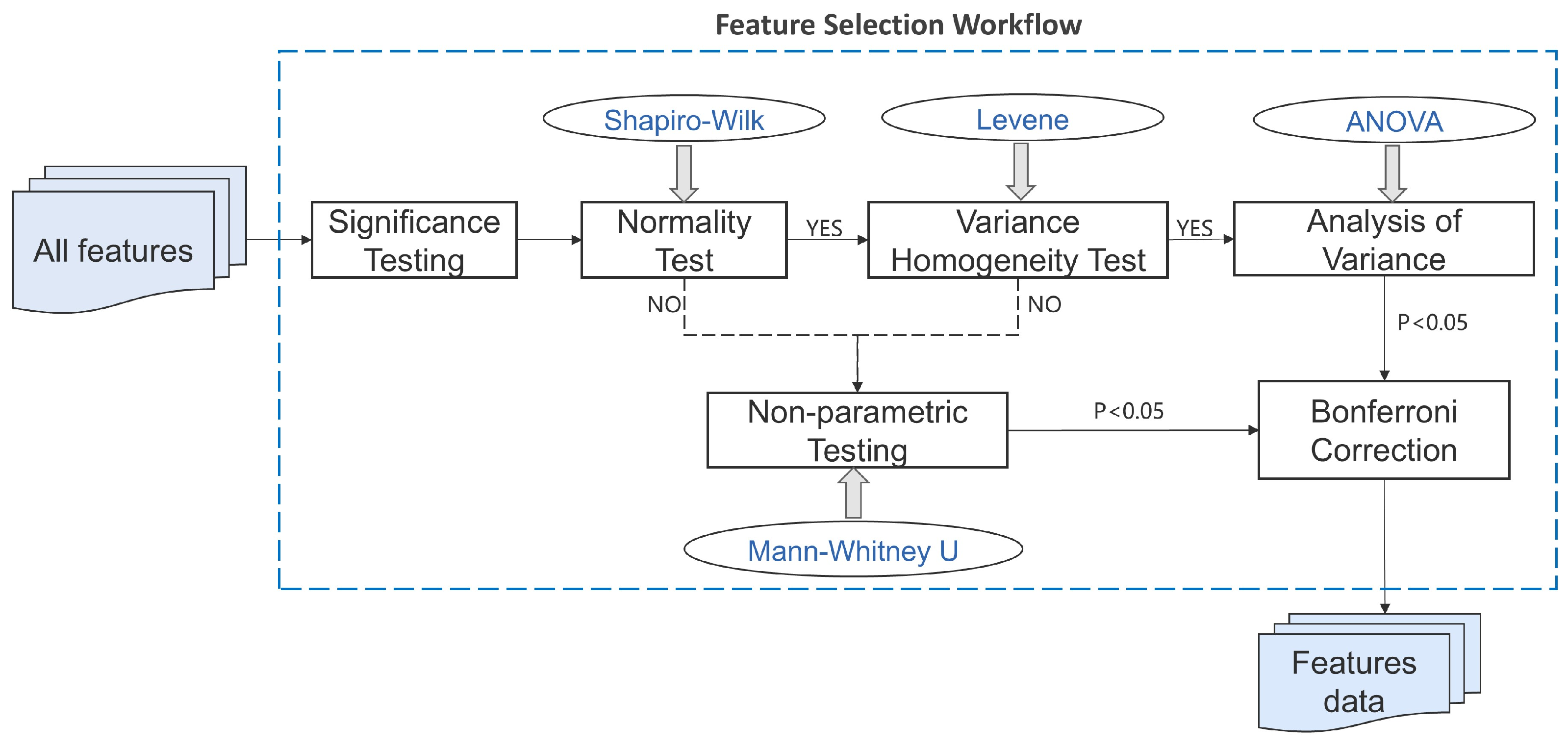
2.5. Feature Selection
2.6. Classifiers
2.7. Evaluation Metrics
- Accuracy
- Recall
- F1 Score
- Area Under the Curve (AUC)The ROC curve is a commonly used tool for evaluating the performance of predictive models, revealing the continuous relationship between sensitivity (recall) and specificity (1–false positive rate). The AUC, the area under the ROC curve, is a key metric for assessing the performance of binary classification models. The AUC measures a model’s ability to rank positive samples ahead of negative samples, with values ranging from 0.5 (no discrimination ability) to 1 (perfect discrimination ability).Definitions:True Positive (TP): The number of MDD samples correctly classified as MDD by the proposed method.False Positive (FP): The number of healthy controls incorrectly classified as MDD by the proposed method.True Negative (TN): The number of healthy controls correctly classified as healthy controls by the proposed method.False Negative (FN): The number of MDD samples incorrectly classified as healthy controls by the proposed method.
3. Results
3.1. Classifier Results
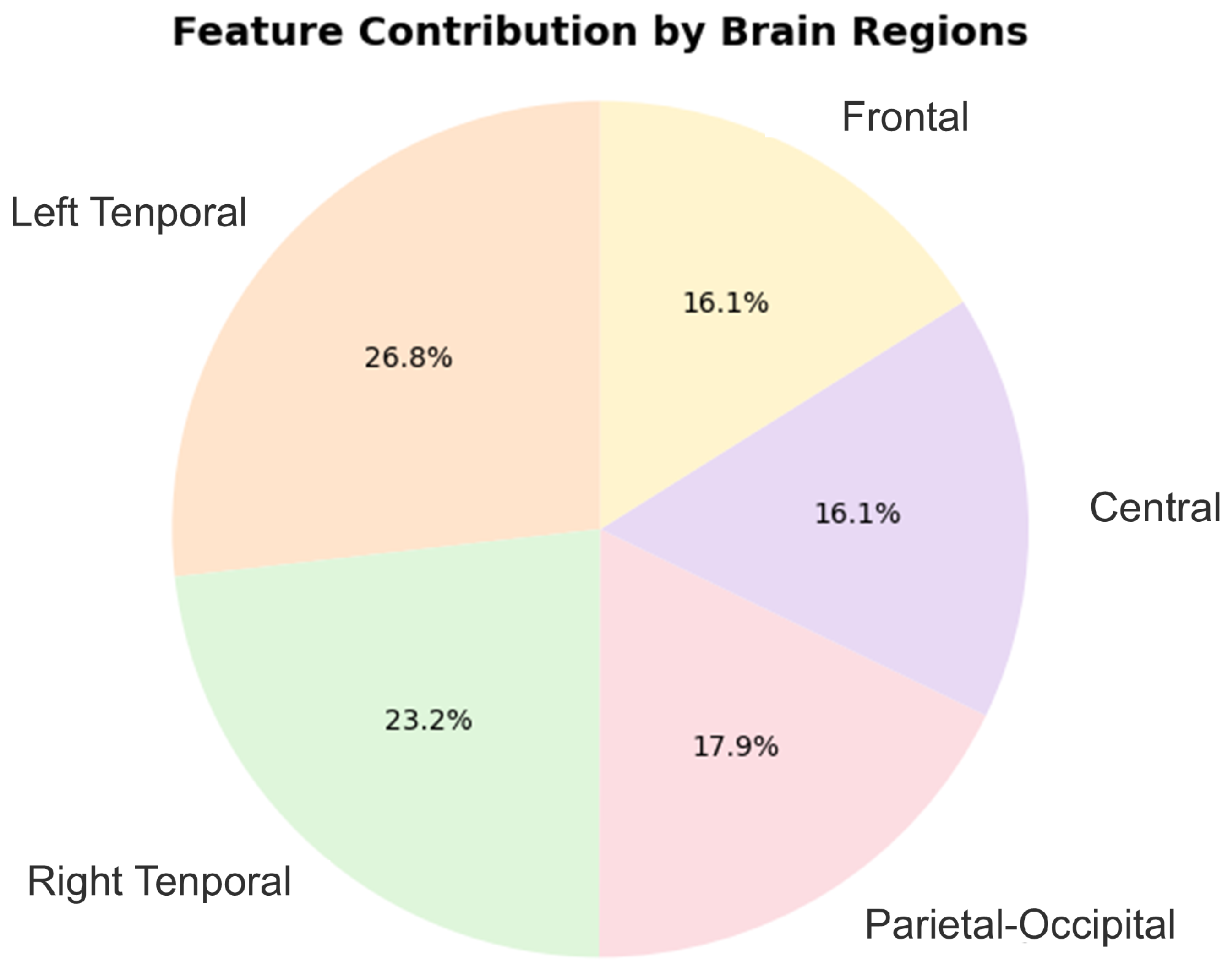
3.2. Brain Region Detection Results with the Proposed Hybrid Model
3.3. Analysis of Frequency Band Features and Brain Region Features
4. Discussion
4.1. Classifier Comparison and Analysis
4.2. Frequency Band Feature Analysis
- (a)
- Delta Waves
- (b)
- Theta Waves
- (c)
- Alpha Waves
- (d)
- Beta1 and Beta2 Waves
- (e)
- Gamma Waves
4.3. Brain Region Feature Analysis
4.4. Comparison with Existing Studies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Marx, W.; Penninx, B.W.; Solmi, M.; Furukawa, T.A.; Firth, J.; Carvalho, A.F.; Berk, M. Major depressive disorder. Nat. Rev. Dis. Prim. 2023, 9, 44. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. Depression. 2023. Available online: https://www.who.int/news-room/fact-sheets/detail/depression (accessed on 18 August 2024).
- Erjavec, G.N.; Sagud, M.; Perkovic, M.N.; Strac, D.S.; Konjevod, M.; Tudor, L.; Uzun, S.; Pivac, N. Depression: Biological markers and treatment. Prog. Neuro-Psychopharmacol. Biol. Psychiatry 2021, 105, 110139. [Google Scholar] [CrossRef] [PubMed]
- de Kwaasteniet, B.; Ruhe, E.; Caan, M.; Rive, M.; Olabarriaga, S.; Groefsema, M.; Heesink, L.; van Wingen, G.; Denys, D. Relation between structural and functional connectivity in major depressive disorder. Biol. Psychiatry 2013, 74, 40–47. [Google Scholar] [CrossRef] [PubMed]
- de Aguiar Neto, F.S.; Garcia Rosa, J.L. Depression biomarkers using non-invasive EEG: A review. Neurosci. Biobehav. Rev. 2019, 105, 83–93. [Google Scholar] [CrossRef]
- Cohen, S.E.; Zantvoord, J.B.; Wezenberg, B.N.; Bockting, C.L.H.; van Wingen, G.A. Magnetic resonance imaging for individual prediction of treatment response in major depressive disorder: A systematic review and meta-analysis. Transl. Psychiatry 2021, 11, 168. [Google Scholar] [CrossRef]
- Crosson, B.; Ford, A.; McGregor, K.M.; Meinzer, M.; Cheshkov, S.; Li, X.; Walker-Batson, D.; Briggs, R.W. Functional imaging and related techniques: An introduction for rehabilitation researchers. J. Rehabil. Res. Dev. 2010, 47, vii. [Google Scholar] [CrossRef]
- Rabcan, J.; Levashenko, V.; Zaitseva, E.; Kvassay, M. Review of methods for EEG signal classification and development of new fuzzy classification-based approach. IEEE Access 2020, 8, 189720–189734. [Google Scholar] [CrossRef]
- Zhu, X.; Wang, X.; Xiao, J.; Liao, J.; Zhong, M.; Wang, W.; Yao, S. Evidence of a dissociation pattern in resting-state default mode network connectivity in first-episode, treatment-naive major depression patients. Biol. Psychiatry 2012, 71, 611–617. [Google Scholar] [CrossRef]
- Röschke, J.; Mann, K.; Fell, J. Nonlinear EEG dynamics during sleep in depression and schizophrenia. Int. J. Neurosci. 1994, 75, 271–284. [Google Scholar] [CrossRef]
- Jiang, C.; Li, Y.; Tang, Y.; Guan, C. Enhancing EEG-based classification of depression patients using spatial information. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 566–575. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, Z.; Xiong, P.; Liu, X. Depression detection based on analysis of EEG signals in multi brain regions. J. Integr. Neurosci. 2023, 22, 93. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Zhang, Z.; Fu, Z.; Li, B.; Xiong, P.; Liu, X. Cross-subject classification of depression by using multiparadigm EEG feature fusion. Comput. Methods Programs Biomed. 2023, 233, 107360. [Google Scholar] [CrossRef] [PubMed]
- Bashir, N.; Narejo, S.; Naz, B.; Ismail, F.; Anjum, M.R.; Butt, A.; Anwar, S.; Prasad, R. A machine learning framework for Major depressive disorder (MDD) detection using non-invasive EEG signals. Wirel. Pers. Commun. 2023, 140, 39–61. [Google Scholar] [CrossRef]
- Shivcharan, M.; Boby, K.; Sridevi, V. EEG Based Machine Learning Models for Automated Depression Detection. In Proceedings of the 2023 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 14–16 July 2023; IEEE: New York, NY, USA, 2023. [Google Scholar]
- Mahato, S.; Paul, S. Analysis of region of interest (RoI) of brain for detection of depression using EEG signal. Multimed. Tools Appl. 2024, 83, 763–786. [Google Scholar] [CrossRef]
- Mumtaz, W.; Xia, L.; Yasin, M.A.M.; Ali, S.S.A.; Malik, A.S. A wavelet-based technique to predict treatment outcome for major depressive disorder. PLoS ONE 2017, 12, e0171409. [Google Scholar] [CrossRef]
- Li, X.; Hu, B.; Xu, T.; Shen, J.; Ratcliffe, M. A study on EEG-based brain electrical source of mild depressed subjects. Comput. Methods Programs Biomed. 2015, 120, 135–141. [Google Scholar] [CrossRef]
- Meza-Cervera, T.; Kim-Spoon, J.; Bell, M.A. Adolescent depressive symptoms: The role of late childhood frontal EEG asymmetry, executive function, and adolescent cognitive reappraisal. Res. Child Adolesc. Psychopathol. 2023, 51, 193–207. [Google Scholar] [CrossRef]
- Paradiso, S.; Hermann, B.P.; Blumer, D.; Davies, K.; Robinson, R.G. Impact of depressed mood on neuropsychological status in temporal lobe epilepsy. J. Neurol. Neurosurg. Psychiatry 2001, 70, 180–185. [Google Scholar] [CrossRef]
- Zhao, L.; He, Y. Power spectrum estimation of the welch method based on imagery EEG. Appl. Mech. Mater. 2013, 278, 1260–1264. [Google Scholar] [CrossRef]
- Huang, Y.; Yi, Y.; Chen, Q.; Li, H.; Feng, S.; Zhou, S.; Zhang, Z.; Liu, C.; Li, J.; Lu, Q.; et al. Analysis of EEG features and study of automatic classification in first-episode and drug-naïve patients with major depressive disorder. BMC Psychiatry 2023, 23, 832. [Google Scholar] [CrossRef]
- Chaudhary, S.; Zhornitsky, S.; Chao, H.H.; van Dyck, C.H.; Li, C.S.R. Emotion processing dysfunction in Alzheimer’s disease: An overview of behavioral findings, systems neural correlates, and underlying neural biology. Am. J. Alzheimer’s Dis. Other Dement. 2022, 37, 15333175221082834. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Ma, J.; Fu, C.-Y.; Yeo, J.; Xiao, S.-S.; Xiao, W.-X.; Li, R.-R.; Zhang, W.; Xie, Z.-M.; Li, Y.-J. Dysfunction of emotion regulation in mild cognitive impairment individuals combined with depressive disorder: A neural mechanism study. Front. Aging Neurosci. 2022, 14, 884741. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Li, J.; Zhao, S.; Zhang, Y.; Li, B.; Liu, X. Fusion of eyes-open and eyes-closed electroencephalography in resting state for classification of major depressive disorder. Biomed. Signal Process. Control 2025, 100, 106964. [Google Scholar] [CrossRef]
- Mahato, S.; Paul, S. Classification of Depression Patients and Normal Subjects Based on Electroencephalogram (EEG) Signal Using Alpha Power and Theta Asymmetry. J. Med. Syst. 2020, 44, 28. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Brain Region | Channels | |
|---|---|---|
| 1 | Frontal | Fp1, Fp2, F3, F4 |
| 2 | Left Temporal | F7, T3, T5 |
| 3 | Parietal–Occipital | P3, P4, O1, O2 |
| 4 | Right Temporal | F8, T4, T6 |
| 5 | Central | C3, C4, Fz, Cz, Pz |
| Feature Category | Feature Name | Feature Description | Feature Count |
|---|---|---|---|
| Spectral Features | Center Freq Relative | Relative center frequency, calculated by Simpson integration of the frequency multiplied by PSD. | 5 regions × 9 features = 45 |
| Center Freq Absolute | Absolute center frequency; the frequency corresponding to the maximum value of PSD. | ||
| Delta Power | Power in the Delta band (1–3 Hz), calculated by Simpson integration of the PSD in this band. | ||
| Theta Power | Power in the Theta band (4–7 Hz). | ||
| Alpha Power | Power in the Alpha band (8–11 Hz). | ||
| Beta1 Power | Power in the Beta1 band (12–20 Hz). | ||
| Beta2 Power | Power in the Beta2 band (21–29 Hz). | ||
| Gamma Power | Power in the Gamma band (30–48 Hz). | ||
| Total Power | Total power, calculated by Simpson integration of the PSD across the entire frequency range. | ||
| Temporal Features | Skewness | Skewness of the signal, reflecting the symmetry of the signal distribution. | 5 regions × 3 features = 15 |
| Kurtosis | Kurtosis of the signal, reflecting the sharpness of the signal distribution. | ||
| Peak Value | Maximum value of the signal. | ||
| Nonlinear Features | Sample Entropy | Sample entropy, reflecting the complexity of the signal. | 5 regions × 5 features = 25 |
| Higuchi FD | Higuchi fractal dimension, reflecting the fractal characteristics of the signal. | ||
| Hurst Exponent | Hurst exponent, reflecting the long-term dependency of the signal. | ||
| Shannon Entropy | Shannon entropy, reflecting the entropy value of the signal. | ||
| C0 Complexity | C0 complexity of the signal; the maximum amplitude obtained through FFT. | ||
| Time-Frequency Features | Mean TF Energy | Mean energy calculated across all frequencies and time windows, reflecting the average energy level in the time-frequency domain. | 5 regions × 2 features = 10 |
| Max TF Energy | Maximum energy calculated across all frequencies and time windows, reflecting the peak energy level in the time-frequency domain. | ||
| Total | 95 |
| Classifier Name | Function/Algorithm Principle | Characteristics |
|---|---|---|
| DT | Simulates a decision-making process for classification tasks. | Easy to understand and implement, low computational complexity, robust to missing data and irrelevant features. |
| KNN | Classifies by measuring the similarity between samples in the feature space and making a decision based on the majority vote of the K-nearest neighbors. | Simple and intuitive, no training phase required, suitable for small datasets. |
| RF | Combines multiple decision trees for classification or regression, using a voting mechanism to enhance accuracy. | High accuracy, capable of handling high-dimensional data, resistant to overfitting. |
| SVM | Employs a maximum-margin principle for classification and extends to nonlinear problems using an RBF kernel function. | Well suited for high-dimensional data, performs well on small sample datasets. |
| LGBM | A gradient boosting framework that utilizes single-side sampling and exclusive feature bundling techniques to improve speed and efficiency. | Efficient for large-scale datasets, with high speed and memory efficiency. |
| XGBoost | An optimized gradient boosting algorithm that integrates parallel processing and regularization techniques to control model complexity. | Automatically parallelizes data processing, reduces overfitting, fast training time. |
| GB | Enhances classification and regression performance by iteratively combining multiple weak learners to minimize error. | High predictive accuracy, particularly effective for complex datasets. |
| NN | Mimics the connectivity of neurons in the human brain; well suited for complex pattern recognition tasks. | Capable of processing complex nonlinear data, adaptive learning capabilities, ideal for high-dimensional data such as images and speech. |
| Classification Models | Accuracy | Recall | F1 Score | ROC AUC |
|---|---|---|---|---|
| DT | 91.95% | 92.62% | 91.97% | 91.97% |
| KNN | 96.97% | 95.31% | 96.91% | 99.81% |
| RF | 95.96% | 95.29% | 95.92% | 99.40% |
| SVM | 96.64% | 95.29% | 96.57% | 99.71% |
| LGBM | 94.63% | 94.57% | 94.58% | 98.87% |
| XGBoost | 93.29% | 93.93% | 93.31% | 98.38% |
| GB | 92.28% | 95.33% | 92.52% | 95.73% |
| NN | 96.64% | 95.95% | 96.61% | 99.20% |
| Ours | 98.07% | 97.27% | 98.16% | 98.06% |
| Classification Models | Best Parameters |
|---|---|
| DT | ‘max_depth’: 20, ‘min_samples_split’: 10 |
| KNN | ‘n_neighbors’: 5, ‘weights’: ’distance’ |
| RF | ‘max_depth’: 10, ‘n_estimators’: 200 |
| SVM | ‘C’: 1, ’gamma’: ‘auto’, ’kernel’: ’rbf’ |
| LGBM | ‘learning_rate’: 0.1, ‘n_estimators’: 500 |
| XGBoost | ‘learning_rate’: 0.05, ‘n_estimators’: 1000 |
| GB | ‘learning_rate’: 0.1, ‘n_estimators’: 200 |
| NN | ‘hidden_layer_sizes’: (50, 50), ‘max_iter’: 1000, ‘solver’: ‘adam’ |
| Ours | ‘dt_max_depth’: 5, ‘knn_n_neighbors’: 5, ‘xgb_learning_rate’: 0.01, ‘xgb_max_depth’: 3, ‘xgb_n_estimators’: 100 |
| Brain Region | Accuracy | Recall | F1 Score | ROC AUC |
|---|---|---|---|---|
| Frontal | 87.61% | 84.57% | 87.38% | 88.73% |
| Left Temporal | 91.92% | 90.62% | 91.77% | 93.24% |
| Right Temporal | 85.28% | 86.67% | 85.51% | 89.90% |
| Parietal–Occipital | 87.94% | 87.98% | 87.93% | 89.83% |
| Central | 89.64% | 88.57% | 89.56% | 91.20% |
| Study | Method | Classification Method | Best Accuracy |
|---|---|---|---|
| Yang, Jianli, et al. (2023) [12] | PSD + LZC + brain region combination (frontal, temporal, central) | SVM | 92.4% (SVM) |
| Yang, Jianli, et al. (2025) [25] | Fusion of LZC, SE, and KC features in the EO state and the PSD and SE features in the EC state | SVM | 94.58% (SVM) |
| Mahato et al. (2020) [26] | Band power features (Delta, Theta, Alpha, Beta, Alpha1, Alpha2) and Theta asymmetry (average and paired) | SVM, Logistic Regression (LR), Naïve-Bayesian (NB), DT | 88.33% (SVM) |
| Mahato et al. (2024) [16] | Nonlinear features (SampEn, DFA) along with EEG band power features | Linear Discriminant Analysis (LDA), NB, LR, DT, SVM, Bagging | 95.23% (SVM) |
| OURS | Brain region segmentation into left and right temporal lobes, linear and nonlinear features | Stacking (KNN, DT, XGBoost) | 98.07% (Stacking) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sang, Q.; Chen, C.; Shao, Z. Decoding Depression from Different Brain Regions Using Hybrid Machine Learning Methods. Bioengineering 2025, 12, 449. https://doi.org/10.3390/bioengineering12050449
Sang Q, Chen C, Shao Z. Decoding Depression from Different Brain Regions Using Hybrid Machine Learning Methods. Bioengineering. 2025; 12(5):449. https://doi.org/10.3390/bioengineering12050449
Chicago/Turabian StyleSang, Qi, Chen Chen, and Zeguo Shao. 2025. "Decoding Depression from Different Brain Regions Using Hybrid Machine Learning Methods" Bioengineering 12, no. 5: 449. https://doi.org/10.3390/bioengineering12050449
APA StyleSang, Q., Chen, C., & Shao, Z. (2025). Decoding Depression from Different Brain Regions Using Hybrid Machine Learning Methods. Bioengineering, 12(5), 449. https://doi.org/10.3390/bioengineering12050449