
Fast 3D Face Reconstruction from a Single Image Using Different Deep Learning Approaches for Facial Palsy Patients

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Materials
2.2. Method 1: Fitting a 3D Morphable Model
2.2.1. 3D Basel Morphable Model
2.2.2. Model Fitting
Facial Landmark Detection
Pose from Scaled Orthographic Projection
Fitting Correspondences
2.3. Method 2: 3D FLAME (Faces Learned with an Articulated Model and Expressions) Model
2.3.1. The Principle
2.3.2. Model Learning
2.4. Method 3: Deep 3D Face Reconstruction
2.4.1. 3D Morphable Model
2.4.2. Model Learning
2.5. Validation versus Kinect-Driven and MRI-Based Reconstructions
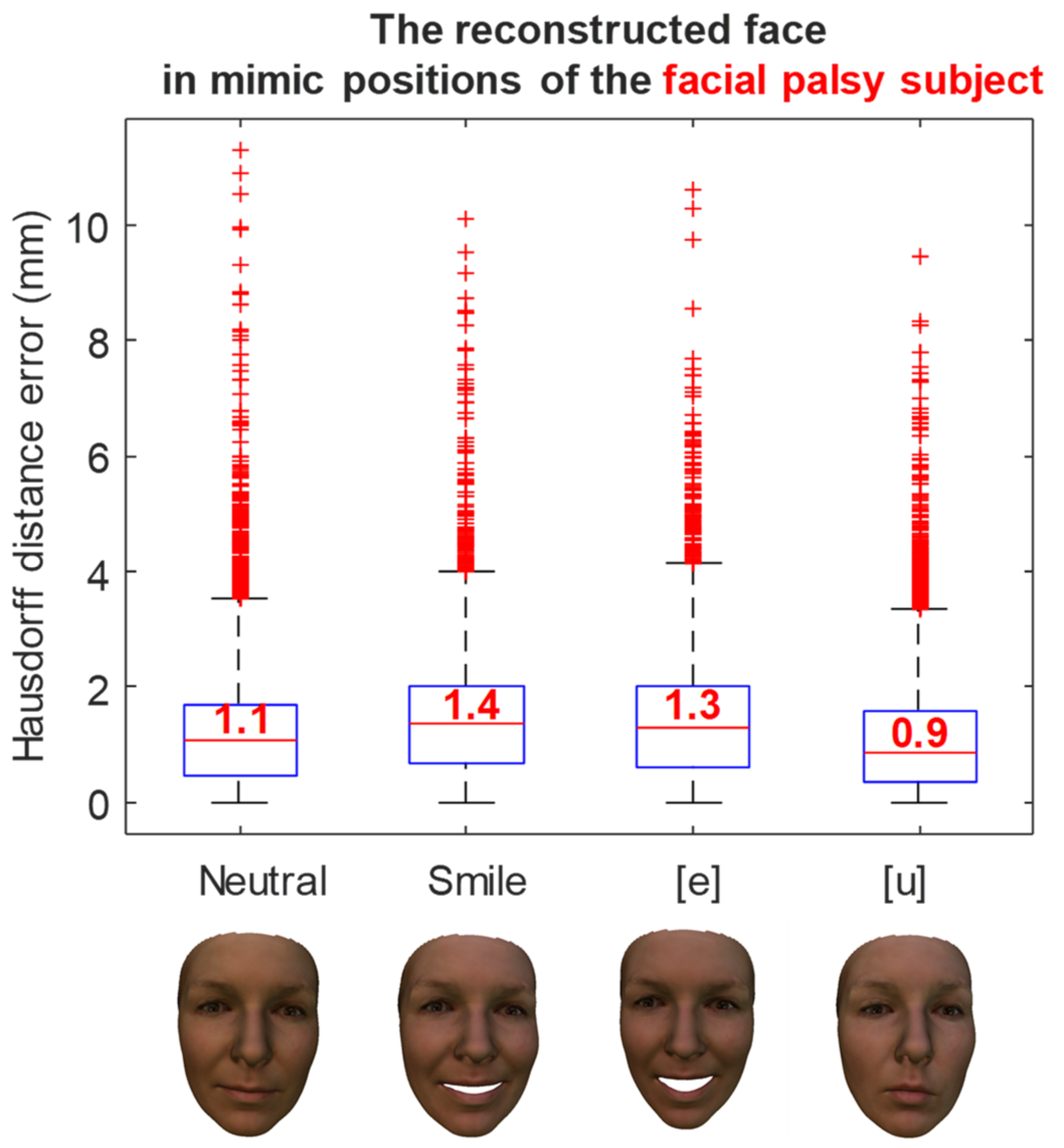
3. Computational Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
List of Abbreviations
| 2D | Two-dimension |
| 3D | Three-dimension |
| 3DMM | 3D morphable model |
| BFM | Basel face model |
| CNNs | Convolutional neural networks |
| DECA | Detailed expression capture and animation |
| DL | Deep learning |
| FLAME | Faces learned with an articulated model and expressions |
| FPS | Frame per second |
| GAN | Generative adversarial network |
| GPU | Graphics processing unit |
| HD | High definition |
| PCA | Principal component analysis |
| ResNet | Residual neural network |
| RGB | Red green blue |
| RGB-D | Red green blue-depth |
| SCAI | Sorbonne center for artificial intelligence |
| SOP | Scaled orthographic projection |
References
- Cawthorne, T.; Haynes, D.R. Facial Palsy. BMJ 1956, 2, 1197–1200. [Google Scholar] [CrossRef] [PubMed]
- Shanmugarajah, K.; Hettiaratchy, S.; Clarke, A.; Butler, P.E.M. Clinical outcomes of facial transplantation: A review. Int. J. Surg. 2011, 9, 600–607. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lorch, M.; Teach, S.J. Facial Nerve Palsy: Etiology and Approach to Diagnosis and Treatment. Pediatr. Emerg. Care 2010, 26, 763–769. [Google Scholar] [CrossRef]
- Hotton, M.; Huggons, E.; Hamlet, C.; Shore, D.; Johnson, D.; Norris, J.H.; Kilcoyne, S.; Dalton, L. The psychosocial impact of facial palsy: A systematic review. Br. J. Health Psychol. 2020, 25, 695–727. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, T.-N.; Dakpe, S.; Ho Ba Tho, M.-C.; Dao, T.-T. Kinect-driven Patient-specific Head, Skull, and Muscle Network Modelling for Facial Palsy Patients. Comput. Methods Programs Biomed. 2021, 200, 105846. [Google Scholar] [CrossRef]
- Nguyen, T.-N.; Tran, V.-D.; Nguyen, H.-Q.; Nguyen, D.-P.; Dao, T.-T. Enhanced head-skull shape learning using statistical modeling and topological features. Med. Biol. Eng. Comput. 2022, 60, 559–581. [Google Scholar] [CrossRef]
- Yin, L.; Wei, X.; Sun, Y.; Wang, J.; Rosato, M.J. A 3D Facial Expression Database For Facial Behavior Research. In Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition (FGR06), Southampton, UK, 10–12 April 2006; pp. 211–216. [Google Scholar] [CrossRef] [Green Version]
- Savran, A.; Alyüz, N.; Dibeklioğlu, H.; Çeliktutan, O.; Gökberk, B.; Sankur, B.; Akarun, L. Bosphorus Database for 3D Face Analysis. In Biometrics and Identity Management; Springer: Berlin/Heidelberg, Germany, 2008; pp. 47–56. [Google Scholar]
- Robinson, M.W.; Baiungo, J. Facial rehabilitation: Evaluation and treatment strategies for the patient with facial palsy. Otolaryngol. Clin. N. Am. 2018, 51, 1151–1167. [Google Scholar] [CrossRef]
- Zhang, L.; Jiang, M.; Farid, D.; Hossain, M.A. Intelligent facial emotion recognition and semantic-based topic detection for a humanoid robot. Expert Syst. Appl. 2013, 40, 5160–5168. [Google Scholar] [CrossRef]
- Dornaika, F.; Raducanu, B. Efficient Facial Expression Recognition for Human Robot Interaction. In Computational and Ambient Intelligence; Sandoval, F., Prieto, A., Cabestany, J., Graña, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4507, pp. 700–708. [Google Scholar] [CrossRef]
- Weise, T.; Bouaziz, S.; Li, H.; Pauly, M. Realtime performance-based facial animation. In Proceedings of theACM SIGGRAPH 2011 Papers on—SIGGRAPH’11, Vancouver, BC, Canada, 7–11 August 2011; p. 1. [Google Scholar] [CrossRef]
- Lee, Y.; Terzopoulos, D.; Walters, K. Realistic modeling for facial animation. In Proceedings of the 22nd Annual Conference on Computer Graphics and Interactive Techniques—SIGGRAPH’95, Los Angeles, CA, USA, 6–11 August 1995; pp. 55–62. [Google Scholar] [CrossRef]
- Weise, T.; Li, H.; van Gool, L.; Pauly, M. Face/Off: Live facial puppetry. In Proceedings of the 2009 ACM SIGGRAPH/Eurographics Symposium on Computer Animation—SCA’09, New Orleans, LA, USA, 1–2 August 2009; p. 7. [Google Scholar] [CrossRef] [Green Version]
- Leo, M.; Carcagnì, P.; Mazzeo, P.L.; Spagnolo, P.; Cazzato, D.; Distante, C. Analysis of Facial Information for Healthcare Applications: A Survey on Computer Vision-Based Approaches. Information 2020, 11, 128. [Google Scholar] [CrossRef] [Green Version]
- Rai, M.C.E.L.; Werghi, N.; al Muhairi, H.; Alsafar, H. Using facial images for the diagnosis of genetic syndromes: A survey. In Proceedings of the 2015 International Conference on Communications, Signal Processing, and their Applications (ICCSPA’15), Sharjah, United Arab Emirates, 16–19 February 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Kermi, A.; Marniche-Kermi, S.; Laskri, M.T. 3D-Computerized facial reconstructions from 3D-MRI of human heads using deformable model approach. In Proceedings of the 2010 International Conference on Machine and Web Intelligence, Algiers, Algeria, 3–5 October 2010; pp. 276–282. [Google Scholar] [CrossRef]
- Flynn, C.; Stavness, I.; Lloyd, J.; Fels, S. A finite element model of the face including an orthotropic skin model under in vivo tension. Comput. Methods Biomech. Biomed. Engin. 2015, 18, 571–582. [Google Scholar] [CrossRef]
- Beeler, T.; Bickel, B.; Beardsley, P.; Sumner, B.; Gross, M. High-quality single-shot capture of facial geometry. In Proceedings of the ACM SIGGRAPH 2010 Papers on—SIGGRAPH’10, Los Angeles, CA, USA, 26–30 July 2010; p. 1. [Google Scholar] [CrossRef]
- Chen, C.-H.; Lee, I.-J.; Lin, L.-Y. Augmented reality-based self-facial modeling to promote the emotional expression and social skills of adolescents with autism spectrum disorders. Res. Dev. Disabil. 2015, 36, 396–403. [Google Scholar] [CrossRef]
- Li, C.; Barreto, A.; Chin, C.; Zhai, J. Biometric identification using 3D face scans. Biomed. Sci. Instrum. 2006, 42, 320–325. [Google Scholar]
- Kim, D.; Hernandez, M.; Choi, J.; Medioni, G. Deep 3D Face Identification. arXiv 2017. [Google Scholar] [CrossRef]
- Nguyen, D.-P.; Tho, M.-C.H.B.; Dao, T.-T. Enhanced facial expression recognition using 3D point sets and geometric deep learning. Med. Biol. Eng. Comput. 2021, 59, 1235–1244. [Google Scholar] [CrossRef]
- Morales, A.; Piella, G.; Sukno, F.M. Survey on 3D face reconstruction from uncalibrated images. arXiv 2021. [Google Scholar] [CrossRef]
- Bas, A.; Smith, W.A.P.; Bolkart, T.; Wuhrer, S. Fitting a 3D Morphable Model to Edges: A Comparison Between Hard and Soft Correspondences. In Computer Vision—ACCV 2016 Workshops; Chen, C.-S., Lu, J., Ma, K.-K., Eds.; Springer International Publishing: Cham, Switzerland, 2017; Volume 10117, pp. 377–391. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.; Yan, J.; Yi, D.; Lei, Z.; Li, S.Z. Discriminative 3D morphable model fitting. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Aldrian, O.; Smith, W.A.P. Inverse Rendering of Faces with a 3D Morphable Model. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1080–1093. [Google Scholar] [CrossRef] [Green Version]
- Kemelmacher-Shlizerman, I.; Basri, R. 3D Face Reconstruction from a Single Image Using a Single Reference Face Shape. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 394–405. [Google Scholar] [CrossRef]
- Song, M.; Tao, D.; Huang, X.; Chen, C.; Bu, J. Three-Dimensional Face Reconstruction From a Single Image by a Coupled RBF Network. IEEE Trans. Image Process. 2012, 21, 2887–2897. [Google Scholar] [CrossRef]
- Zhang, G.; Han, H.; Shan, S.; Song, X.; Chen, X. Face Alignment across Large Pose via MT-CNN Based 3D Shape Reconstruction. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 210–217. [Google Scholar] [CrossRef]
- Zhou, Y.; Deng, J.; Kotsia, I.; Zafeiriou, S. Dense 3D Face Decoding over 2500FPS: Joint Texture & Shape Convolutional Mesh Decoders. arXiv 2019. [Google Scholar] [CrossRef]
- Blanz, V.; Vetter, T. A morphable model for the synthesis of 3D faces. In Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques—SIGGRAPH’99, Los Angeles, CA, USA, 8–13 August 1999; pp. 187–194. [Google Scholar] [CrossRef]
- Paysan, P.; Knothe, R.; Amberg, B.; Romdhani, S.; Vetter, T. A 3D Face Model for Pose and Illumination Invariant Face Recognition. In Proceedings of the 2009 Sixth IEEE International Conference on Advanced Video and Signal Based Surveillance, Genova, Italy, 2–4 September 2009; pp. 296–301. [Google Scholar] [CrossRef]
- Cao, C.; Weng, Y.; Zhou, S.; Tong, Y.; Zhou, K. FaceWarehouse: A 3D Facial Expression Database for Visual Computing. IEEE Trans. Vis. Comput. Graph. 2014, 20, 413–425. [Google Scholar] [CrossRef] [Green Version]
- Suwajanakorn, S.; Kemelmacher-Shlizerman, I.; Seitz, S.M. Total Moving Face Reconstruction. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; Volume 8692, pp. 796–812. [Google Scholar] [CrossRef]
- Snape, P.; Panagakis, Y.; Zafeiriou, S. Automatic construction Of robust spherical harmonic subspaces. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 91–100. [Google Scholar] [CrossRef] [Green Version]
- Wood, E.; Baltrusaitis, T.; Hewitt, C.; Johnson, M.; Shen, J.; Milosavljevic, N.; Wilde, D.; Garbin, S.; Raman, C.; Shotton, J.; et al. 3D face reconstruction with dense landmarks. arXiv 2022. [Google Scholar] [CrossRef]
- Cao, X.; Chen, Z.; Chen, A.; Chen, X.; Li, S.; Yu, J. Sparse Photometric 3D Face Reconstruction Guided by Morphable Models. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4635–4644. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.; Zollhöfer, M.; Tewari, A.; Thies, J.; Richardt, C.; Theobalt, C. InverseFaceNet: Deep Monocular Inverse Face Rendering. arXiv 2018. [Google Scholar] [CrossRef]
- Li, X.; Weng, Z.; Liang, J.; Cei, L.; Xiang, Y.; Fu, Y. A Novel Two-Pathway Encoder-Decoder Network for 3D Face Reconstruction. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3682–3686. [Google Scholar] [CrossRef]
- Pan, X.; Tewari, A.; Liu, L.; Theobalt, C. GAN2X: Non-Lambertian Inverse Rendering of Image GANs. arXiv 2022. [Google Scholar] [CrossRef]
- Nguyen, D.-P.; Ho Ba Tho, M.-C.; Dao, T.-T. Reinforcement learning coupled with finite element modeling for facial motion learning. Comput. Methods Programs Biomed. 2022, 221, 106904. [Google Scholar] [CrossRef] [PubMed]
- Rosenberg, J.D. Facial Nerve Paralysis Photo Gallery. Available online: https://www.drjoshuarosenberg.com/facial-nerve-paralysis-photo-gallery/ (accessed on 5 February 2022).
- Sagonas, C.; Antonakos, E.; Tzimiropoulos, G.; Zafeiriou, S.; Pantic, M. 300 Faces In-The-Wild Challenge: Database and results. Image Vis. Comput. 2016, 47, 3–18. [Google Scholar] [CrossRef] [Green Version]
- Belhumeur, P.N.; Jacobs, D.W.; Kriegman, D.J.; Kumar, N. Localizing Parts of Faces Using a Consensus of Exemplars. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2930–2940. [Google Scholar] [CrossRef]
- Matthews, I.; Baker, S. Active Appearance Models Revisited. Int. J. Comput. Vis. 2004, 60, 135–164. [Google Scholar] [CrossRef] [Green Version]
- Dementhon, D.F.; Davis, L.S. Model-based object pose in 25 lines of code. Int. J. Comput. Vis. 1995, 15, 123–141. [Google Scholar] [CrossRef]
- Feng, Y.; Feng, H.; Black, M.J.; Bolkart, T. Learning an Animatable Detailed 3D Face Model from In-The-Wild Images. arXiv 2021. [Google Scholar] [CrossRef]
- Li, T.; Bolkart, T.; Black, M.J.; Li, H.; Romero, J. Learning a model of facial shape and expression from 4D scans. ACM Trans. Graph. 2017, 36, 1–17. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015. [Google Scholar] [CrossRef]
- Ramamoorthi, R.; Hanrahan, P. An efficient representation for irradiance environment maps. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques—SIGGRAPH’01, Los Angeles, CA, USA, 12–17 August 2001; pp. 497–500. [Google Scholar] [CrossRef]
- Wang, Y.; Tao, X.; Qi, X.; Shen, X.; Jia, J. Image Inpainting via Generative Multi-column Convolutional Neural Networks. arXiv 2018. [Google Scholar] [CrossRef]
- Deng, Y.; Yang, J.; Xu, S.; Chen, D.; Jia, Y.; Tong, X. Accurate 3D Face Reconstruction with Weakly-Supervised Learning: From Single Image to Image Set. arXiv 2020. [Google Scholar] [CrossRef]
- Bulat, A.; Tzimiropoulos, G. How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks). In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1021–1030. [Google Scholar] [CrossRef] [Green Version]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision Pattern Recognit, CVPR, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, T.-N.; Dakpé, S.; Ho Ba Tho, M.-C.; Dao, T.-T. Real-time computer vision system for tracking simultaneously subject-specific rigid head and non-rigid facial mimic movements using a contactless sensor and system of systems approach. Comput. Methods Programs Biomed. 2020, 191, 105410. [Google Scholar] [CrossRef]
- Aspert, N.; Santa-Cruz, D.; Ebrahimi, T. MESH: Measuring errors between surfaces using the Hausdorff distance. In Proceedings of the IEEE International Conference on Multimedia and Expo, Lausanne, Switzerland, 29 August 2002; pp. 705–708. [Google Scholar] [CrossRef]
- Karp, E.; Waselchuk, E.; Landis, C.; Fahnhorst, J.; Lindgren, B.; Lyford-Pike, S. Facial Rehabilitation as Noninvasive Treatment for Chronic Facial Nerve Paralysis. Otol. Neurotol. 2019, 40, 241–245. [Google Scholar] [CrossRef]
- Hamm, J.; Kohler, C.G.; Gur, R.C.; Verma, R. Automated Facial Action Coding System for dynamic analysis of facial expressions in neuropsychiatric disorders. J. Neurosci. Methods 2011, 200, 237–256. [Google Scholar] [CrossRef] [Green Version]
- Pan, Z.; Shen, Z.; Zhu, H.; Bao, Y.; Liang, S.; Wang, S.; Li, X.; Niu, L.; Dong, X.; Shang, X.; et al. Clinical application of an automatic facial recognition system based on deep learning for diagnosis of Turner syndrome. Endocrine 2021, 72, 865–873. [Google Scholar] [CrossRef]
- Wu, D.; Chen, S.; Zhang, Y.; Zhang, H.; Wang, Q.; Li, J.; Fu, Y.; Wang, S.; Yang, H.; Du, H.; et al. Facial Recognition Intensity in Disease Diagnosis Using Automatic Facial Recognition. J. Pers. Med. 2021, 11, 1172. [Google Scholar] [CrossRef]
- Urbanová, P.; Ferková, Z.; Jandová, M.; Jurda, M.; Černý, D.; Sochor, J. Introducing the FIDENTIS 3D Face Database. Anthropol. Rev. 2018, 81, 202–223. [Google Scholar] [CrossRef] [Green Version]
- Ranjan, A.; Bolkart, T.; Sanyal, S.; Black, M.J. Generating 3D faces using Convolutional Mesh Autoencoders. arXiv 2018. [Google Scholar] [CrossRef]
- Jiang, Z.-H.; Wu, Q.; Chen, K.; Zhang, J. Disentangled Representation Learning for 3D Face Shape. arXiv 2019. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Subject | Error (mm) | Method | Subject | Error (mm) |
|---|---|---|---|---|---|
| Fitting—Kinect comparison | 1 | Fitting—MRI comparison | 1 | ||
| 2 | 2 | ||||
| 3 | 3 | ||||
| Mean | Mean | ||||
| Deca—Kinect comparison | 1 | Deca—MRI comparison | 1 | ||
| 2 | 2 | ||||
| 3 | 3 | ||||
| 4 | 4 | ||||
| Mean | Mean | ||||
| Deep3Dface—Kinect comparison | 1 | Deep3Dface—MRI comparison | 1 | ||
| 2 | 2 | ||||
| 3 | 3 | ||||
| 4 | 4 | ||||
| Mean | Mean |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, D.-P.; Nguyen, T.-N.; Dakpé, S.; Ho Ba Tho, M.-C.; Dao, T.-T. Fast 3D Face Reconstruction from a Single Image Using Different Deep Learning Approaches for Facial Palsy Patients. Bioengineering 2022, 9, 619. https://doi.org/10.3390/bioengineering9110619
Nguyen D-P, Nguyen T-N, Dakpé S, Ho Ba Tho M-C, Dao T-T. Fast 3D Face Reconstruction from a Single Image Using Different Deep Learning Approaches for Facial Palsy Patients. Bioengineering. 2022; 9(11):619. https://doi.org/10.3390/bioengineering9110619
Chicago/Turabian StyleNguyen, Duc-Phong, Tan-Nhu Nguyen, Stéphanie Dakpé, Marie-Christine Ho Ba Tho, and Tien-Tuan Dao. 2022. "Fast 3D Face Reconstruction from a Single Image Using Different Deep Learning Approaches for Facial Palsy Patients" Bioengineering 9, no. 11: 619. https://doi.org/10.3390/bioengineering9110619
APA StyleNguyen, D.-P., Nguyen, T.-N., Dakpé, S., Ho Ba Tho, M.-C., & Dao, T.-T. (2022). Fast 3D Face Reconstruction from a Single Image Using Different Deep Learning Approaches for Facial Palsy Patients. Bioengineering, 9(11), 619. https://doi.org/10.3390/bioengineering9110619