
KazNewsDataset: Single Country Overall Digital Mass Media Publication Corpus

 , ,
, ,  , ,
, ,  , ,
, ,
Abstract
1. Summary (Required)
2. Data Description (Required)
- (1)
- Weights of correspondence to handpicked topic groups;
- (2)
- Weights of correspondence to 200 topics from BigARTM model;
- (3)
- Type—either news publication or governmental program document.
- HTML and JavaScript code pieces;
- Wrong publication date and time due to format issues;
- Wrong URL;
- In rare cases, a text field can contain text from different publications.
2.1. Form 1 of Corpus Representation
- ID;
- Title;
- Text;
- Source;
- URL;
- Publication date and time;
- Number of views.
2.2. Form 2 of Corpus Representation
- Sixty-seven columns with handpicked and topic groups weights with semantic names (group economy, group politics, etc.). They were normalized to range from 0 to 1;
- Two hundred columns with topic weights were obtained through topic modeling. These columns represent a theta-matrix of the topic model;
- Type—either “news” or “governmental program”.
- Topic-words.json file represents words with weights for the 200 topics obtained through topic-modeling. It is a compressed representation of a phi matrix;
- Topic-expert-labeling-sentiment.json contains expert labeling of topics sentiment. It was used to obtain results described in [31].
3. Methods (Required)
- Publication date and time-.col1.group.smallList li;
- Publication text-.intro, .longText > p;
- Publication title-#bodyContent h1.
4. Limitations of the Study
- The results of model verification are based on datasets, each of which was labeled by a single expert. No thorough validation of expert’s assessments was performed, only visual validation.
- The volume of the labeled subset is small compared to the volume of the corpus.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. LDA and BigARTM Description
References
- Korencÿic, D.; Ristov, S.; Sÿnajder, J. Document-based topic coherence measures for news media text. Expert Syst. Appl. 2018, 114, 357–373. [Google Scholar] [CrossRef]
- Georgiadou, E.; Angelopoulos, S.; Drake, H. Big data analytics and international negotiations: Sentiment analysis of Brexit negotiating outcomes. Int. J. Inf. Manag. 2020, 51, 102048. [Google Scholar] [CrossRef]
- Neuendorf, A. The Content Analysis Guidebook; Sage: Thousand Oaks, CA, USA, 2016. [Google Scholar]
- Flaounas, I.; Ali, O.; Lansdall-Welfare, T.; De Bie, T.; Mosdell, N.; Lewis, J.; Cristianini, N. Research methods in the age of digital journalism: Massive-scale automated analysis of news-content topics, style and gender. Digit. Journal. 2013, 1, 102–116. [Google Scholar] [CrossRef]
- Steinberger, J.; Ebrahim, M.; Ehrmann, M.; Hurriyetoglu, A.; Kabadjov, M.; Lenkova, P.; Steinberger, R.; Tanev, H.; VGЎzquez, S.; Zavarella, V. Creating sentiment dictionaries via triangulation. Decis. Support Syst. 2012, 53, 689–694. [Google Scholar] [CrossRef]
- Vossen, P.; Rigau, G.; Serafini, L.; Stouten, P.; Irving, F.; Van Hage, W.R. NewsReader: Recording history from daily news streams. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC-2014), Reykjavik, Iceland, 26–31 May 2014; pp. 2000–2007. [Google Scholar]
- Li, L.; Zheng, L.; Yang, F.; Li, T. Modeling and broadening temporal user interest in personalized news recommendation. Expert Syst. Appl. 2014, 41, 3168–3177. [Google Scholar] [CrossRef]
- Clerwall, C. Enter the robot journalist: Users’ perceptions of automated content. Journal. Pract. 2014, 8, 519–531. [Google Scholar] [CrossRef]
- Popescu, O.; Strapparava, C. Natural Language Processing meets Journalism. In Proceedings of the 2017 EMNLP Workshop, Copenhagen, Denmark, 7 September 2017; Association for Computational Linguistics: Vancouver, Canada, 2017. [Google Scholar]
- Sreelekha, S.; Bhattacharyya, P.; Shishir, J.; Malathi, D. A Survey report on Evolution of Machine Translation. Int. J. Control Theory Appl. 2016, 9, 233–240. [Google Scholar]
- Höffner, K.; Walter, S.; Marx, E.; Usbeck, R.; Lehmann, J.; Ngomo, A.N. Survey on challenges of Question Answering in the Semantic Web. Semant. Web 2017, 8, 895–920. [Google Scholar] [CrossRef]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing; Pearson: London, UK, 2014; Volume 3. [Google Scholar]
- Deo, A.; Gangrade, J.; Gangrade, S. A survey paper on information retrieval system. Int. J. Adv. Res. Comput. Sci. 2018, 9, 778. [Google Scholar] [CrossRef]
- Shokin, Y.I.; Fedotov, A.M.; Barakhnin, V.B. Problems in Finding Information; Science: Novosibirsk, Russian, 2010; p. 220. [Google Scholar]
- Sun, S.; Luo, C.; Chen, J. A review of natural language processing techniques for opinion mining systems. Inf. Fusion 2017, 36, 10–25. [Google Scholar] [CrossRef]
- Manning, C.; Schutze, H. Foundations of Statistical Natural Language Processing; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Goldberg, Y. A primer on neural network models for natural language processing. J. Artif. Intell. Res. 2016, 57, 345–420. [Google Scholar] [CrossRef]
- Cambria, E. Affective Computing and Sentiment Analysis. In IEEE Intelligent Systems; IEEE: Piscataway, NJ, USA, 2016; Volume 31, pp. 102–107. [Google Scholar] [CrossRef]
- Vilares, D.; Peng, H.; Satapathy, R.; Cambria, E. BabelSenticNet: A Commonsense Reasoning Framework for Multilingual Sentiment Analysis. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 1292–1298. [Google Scholar] [CrossRef]
- Lo, S.L.; Cambria, E.; Chiong, R.; Cornforth, D. Multilingual sentiment analysis: From formal to informal and scarce resource languages. Artif. Intell. Rev. 2017, 48, 499–527. [Google Scholar] [CrossRef]
- Hirschberg, J.; Manning, C.D. Advances in natural language processing. Science 2015, 349, 261–266. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Yang, L.; Chen, Z.; Li, P. A survey on deep learning for big data. Inf. Fusion 2018, 42, 146–157. [Google Scholar] [CrossRef]
- Coronavirus Tweets NLP—Text Classification. Available online: https://www.kaggle.com/datatattle/covid-19-nlp-text-classification (accessed on 12 March 2021).
- Spam Text Message Classification. Available online: https://www.kaggle.com/team-ai/spam-text-message-classification (accessed on 12 March 2021).
- Open Food Facts. Available online: https://www.kaggle.com/openfoodfacts/world-food-facts (accessed on 12 March 2021).
- Getting Real about Fake News. Available online: https://www.kaggle.com/mrisdal/fake-news (accessed on 12 March 2021).
- Credit Card Fraud Detection. Available online: https://www.kaggle.com/konradb/text-recognition-total-text-daset (accessed on 12 March 2021).
- Kazakhstani and Russian News Corpus. 2020. Available online: https://data.mendeley.com/datasets/2vz7vtbhn2/1 (accessed on 12 March 2021).
- Kazakhstani News Corpus for Social Significance Identification with Topic Modelling Results. 2020. Available online: https://data.mendeley.com/datasets/hwj24p9gkh/1 (accessed on 12 March 2021).
- Mukhamediev, R.I.; Yakunin, K.; Mussabayev, R.; Buldybayev, T.; Kuchin, Y.; Murzakhmetov, S.; Yelis, M. Classification of Negative Information on Socially Significant Topics in Mass Media. Symmetry 2020, 12, 1945. [Google Scholar] [CrossRef]
- Barakhnin, V.; Kozhemyakina, O.; Mukhamediev, R.; Borzilova, Y.; Yakunin, K. The design of the structure of the software system for processing text document corpus. Bus. Inform. 2019, 13, 60–62. [Google Scholar] [CrossRef]
- Yakunin, K. Media Monitoring System. Available online: https://github.com/KindYAK/NLPMonitor (accessed on 14 September 2020).
- Mashechkin, I.V.; Petrovskiy, M.I.; Tsarev, D.V. Methods for calculating the relevance of text fragments based on thematic models in the problem of automatic annotation. Comput. Methods Program. 2013, 14, 91–102. [Google Scholar]
- Vorontsov, K.V.; Potapenko, A.A. Regularization, robustness and sparseness of probabilistic thematic models. Comput. Res. Modeling 2012, 4, 693–706. [Google Scholar] [CrossRef][Green Version]
- Parhomenko, P.A.; Grigorev, A.A.; Astrakhantsev, N.A. A survey and an experimental comparison of methods for text clustering: Application to scientific articles. Proc. Inst. Syst. Program. RAS 2017, 29, 161–200. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Hamed, J.; Yongli, W.; Chi, Y.; Xia, F. Latent Dirichlet Allocation (LDA) and Topic modeling: Models, applications, a survey. Multimed. Tools Appl. 2017, 78, 15169–15211. [Google Scholar]
- Mimno, D.; Wallach, H.; Talley, E.; Leenders, M.; McCallum, A. Optimizing Semantic Coherence in Topic Models. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Scotland, UK, 27–31 July 2011; pp. 262–272. [Google Scholar]
- Vorontsov, K.; Frei, O.; Apishev, M.; Romov, P.; Dudarenko, M. BigARTM: Open Source Library for Regularized Multimodal Topic Modeling of Large Collections. In International Conference on Analysis of Images, Social Networks and Texts; Springer: Cham, Switzerland, 2015; pp. 370–381. [Google Scholar]
- Saaty, T. Group Decision Making and the AHP; Springer: New York, NY, USA, 1989. [Google Scholar]
- Mohammad, A.; Ehsan, A.; Rouzbeh, A.; Vikram, G.; Irene, P. Developing a Novel Risk-based Methodology for Multi-Criteria Decision Making in Marine Renewable Energy Applications. Renew. Energy 2017, 102, 341–348. [Google Scholar] [CrossRef]
- Mukhamediev, R.I.; Mustakayev, R.; Yakunin, K.; Kiseleva, S.; Gopejenko, V. Multi-Criteria Spatial Decision Making Support System for Renewable Energy Development in Kazakhstan. IEEE Access 2019, 7, 122275–122288. [Google Scholar] [CrossRef]
- Yakunin, K.; Ionescu, M.; Murzakhmetov, S.; Mussabayev, R.; Filatova, O.; Mukhamediev, R. Propaganda Identification Using Topic Modelling. Procedia Comput. Sci. 2020, 178, 205–212. [Google Scholar] [CrossRef]
- Mukhamediev, R.; Musabayev, R.; Buldybaev, Т.; Kuchin, Y.; Symagulov, A.; Ospanova; Yakunin, K.; Murzakhmetov, S.; Sagyndyk, B. Media assessment experiments based on a thematic corpus model. Cloud Sci. 2020, 7, 87–104. [Google Scholar]
- Yakunin, K.; Mukhamediev, R.; Kuchin, Y.; Musabayev, R.; Buldybayev, T.; Murzakhmetov, S. Classification of negative publication in mass media using topic modeling. J. Phys. Conf. Ser 2020. in print. [Google Scholar]
- Yakunin, K.; Musabaev, R.; Yelis, M.; Mukhamediev, R. The topic of energy in news publications. In Proceedings of the All-Russian Scientific Conference and the xiii Youth School with International Participation, Moscow, Russian, 24–25 November 2020; pp. 451–456. [Google Scholar]
- Musabaev, R.; Muhamedyev, R.; Kuchin, Y.; Symagulov, A.; Yakunin, K. On a method of multimodal media ranking using corpus based topic modelling. Inf. Technol. Manag. Soc. 2019, 4, 5. [Google Scholar]
- Yakunin, K.; Mukhamediev, R.; Mussabayev, R.; Buldybayev, T.; Kuchin, Y.; Murzakhmetov, S.; Rassul, Y.; Ospanova, U. Mass Media Evaluation Using Topic Modelling. In International Conference on Digital Transformation and Global Society; Springer: Cham, Switzerland, 2020; pp. 130–135. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
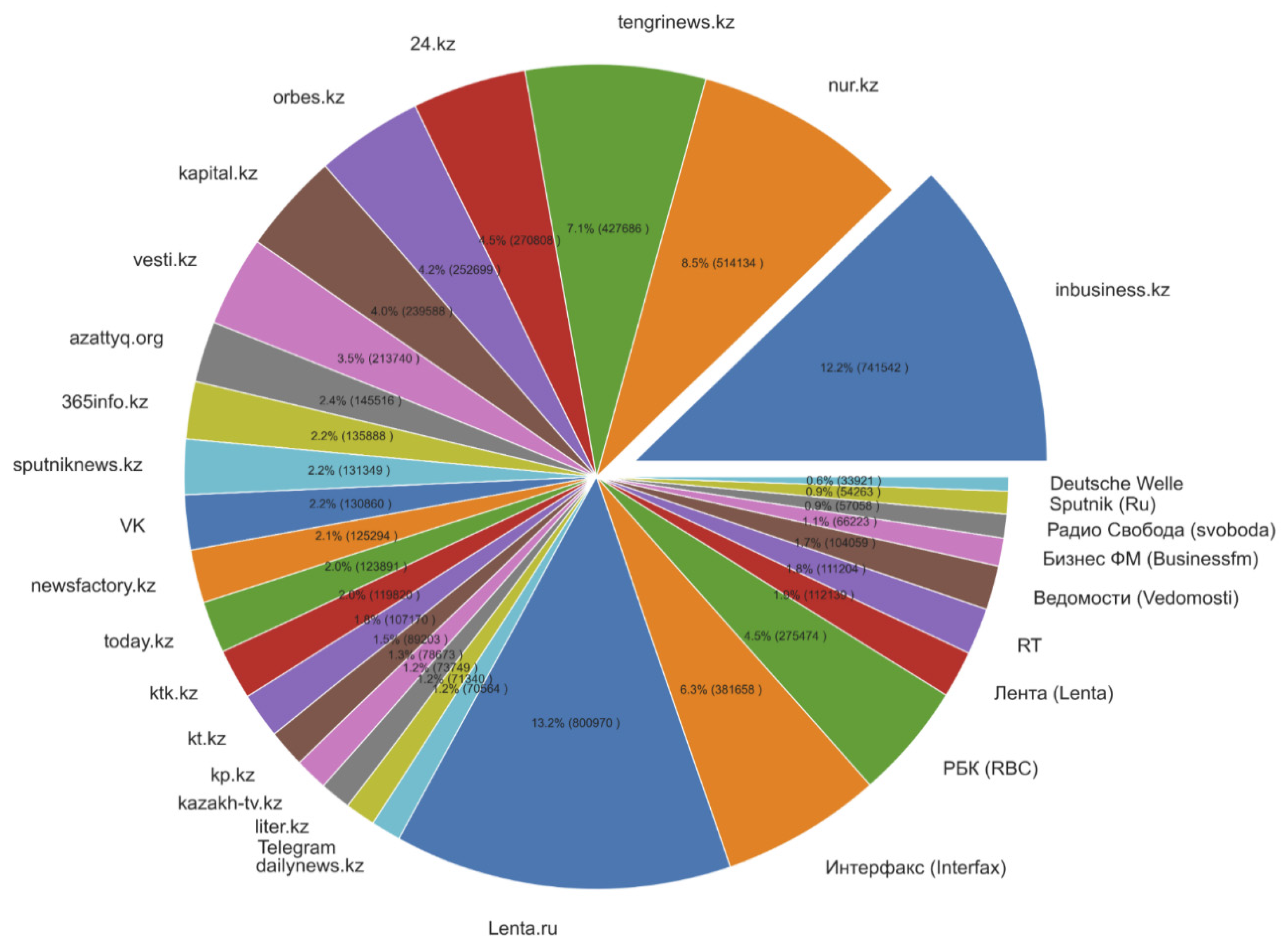
| Source | Number of Documents |
|---|---|
| https://inbusiness.kz/ru, accessed on 14 March 2021 | 741,542 |
| https://www.nur.kz/, accessed on 14 March 2021 | 514,134 |
| https://tengrinews.kz/, accessed on 14 March 2021 | 427,687 |
| https://24.kz/ru/, accessed on 14 March 2021 | 270,809 |
| https://forbes.kz/, accessed on 14 March 2021 | 252,699 |
| https://kapital.kz/, accessed on 14 March 2021 | 239,588 |
| http://vesti.kz/, accessed on 14 March 2021 | 213,740 |
| https://rus.azattyq.org/, accessed on 14 March 2021 | 145,517 |
| https://365info.kz/, accessed on 14 March 2021 | 135,889 |
| https://sputniknews.kz/, accessed on 14 March 2021 | 131,350 |
| VK | 130,860 |
| http://www.newsfactory.kz/, accessed on 14 March 2021 | 125,294 |
| http://today.kz, accessed on 14 March 2021 | 123,892 |
| https://www.ktk.kz/, accessed on 14 March 2021 | 119,820 |
| https://www.kt.kz/, accessed on 14 March 2021 | 107,171 |
| http://www.kp.kz/, accessed on 14 March 2021 | 89,203 |
| https://kazakh-tv.kz/ru, accessed on 14 March 2021 | 78,674 |
| https://liter.kz/, accessed on 14 March 2021 | 73,749 |
| Telegram | 71,340 |
| http://www.dailynews.kz/, accessed on 14 March 2021 | 70,564 |
| Source | Number of Documents |
|---|---|
| Lenta.ru | 800,970 |
| Интepφaкc (Interfax) | 381,659 |
| PБK (RBC) | 275,474 |
| Лeнтa (Lenta) | 112,139 |
| RT | 111,204 |
| Beдoмocти (Vedomosti) | 104,059 |
| Бизнec ΦM (Businessfm) | 66,224 |
| Paдиo Cвoбoдa (svoboda) | 57,059 |
| Sputnik (Ru) | 54,264 |
| Deutsche Welle | 33,922 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yakunin, K.; Kalimoldayev, M.; Mukhamediev, R.I.; Mussabayev, R.; Barakhnin, V.; Kuchin, Y.; Murzakhmetov, S.; Buldybayev, T.; Ospanova, U.; Yelis, M.; et al. KazNewsDataset: Single Country Overall Digital Mass Media Publication Corpus. Data 2021, 6, 31. https://doi.org/10.3390/data6030031
Yakunin K, Kalimoldayev M, Mukhamediev RI, Mussabayev R, Barakhnin V, Kuchin Y, Murzakhmetov S, Buldybayev T, Ospanova U, Yelis M, et al. KazNewsDataset: Single Country Overall Digital Mass Media Publication Corpus. Data. 2021; 6(3):31. https://doi.org/10.3390/data6030031
Chicago/Turabian StyleYakunin, Kirill, Maksat Kalimoldayev, Ravil I. Mukhamediev, Rustam Mussabayev, Vladimir Barakhnin, Yan Kuchin, Sanzhar Murzakhmetov, Timur Buldybayev, Ulzhan Ospanova, Marina Yelis, and et al. 2021. "KazNewsDataset: Single Country Overall Digital Mass Media Publication Corpus" Data 6, no. 3: 31. https://doi.org/10.3390/data6030031
APA StyleYakunin, K., Kalimoldayev, M., Mukhamediev, R. I., Mussabayev, R., Barakhnin, V., Kuchin, Y., Murzakhmetov, S., Buldybayev, T., Ospanova, U., Yelis, M., Zhumabayev, A., Gopejenko, V., Meirambekkyzy, Z., & Abdurazakov, A. (2021). KazNewsDataset: Single Country Overall Digital Mass Media Publication Corpus. Data, 6(3), 31. https://doi.org/10.3390/data6030031