




Data 2025, 10(11), 170; https://doi.org/10.3390/data10110170 (registering DOI) - 26 Oct 2025
Abstract
Continuous monitoring of electrical parameters is essential for understanding energy consumption, assessing power quality, and analyzing load behavior. This paper presents a dataset comprising measurements of three-phase voltages and currents, active and reactive power (per phase and total), power factor, and system frequency.
[...] Read more.
Continuous monitoring of electrical parameters is essential for understanding energy consumption, assessing power quality, and analyzing load behavior. This paper presents a dataset comprising measurements of three-phase voltages and currents, active and reactive power (per phase and total), power factor, and system frequency. The data was collected between April and December 2024 in the low-voltage system of a university laboratory, using high-accuracy power analyzers installed at the point of common coupling. Measurements were recorded every 10 min, generating 79 files with 432 records each, for a total of approximately 34,128 entries. To ensure data quality, the values were validated, erroneous entries removed, and consistency verified using power triangle relationships. The curated dataset is provided in tabular (CSV) format, with each record including a timestamp, three-phase voltages, three-phase currents, active and reactive power (per phase and total), power factor (per phase and global), and system frequency. This dataset offers a comprehensive characterization of electrical behavior in a university laboratory over a nine-month period. It is openly available for reuse and can support research in power system analysis, renewable energy integration, demand forecasting, energy efficiency, and the development of machine learning models for smart energy applications.
Full article
(This article belongs to the Topic Smart Energy Systems, 2nd Edition)
►
Show Figures
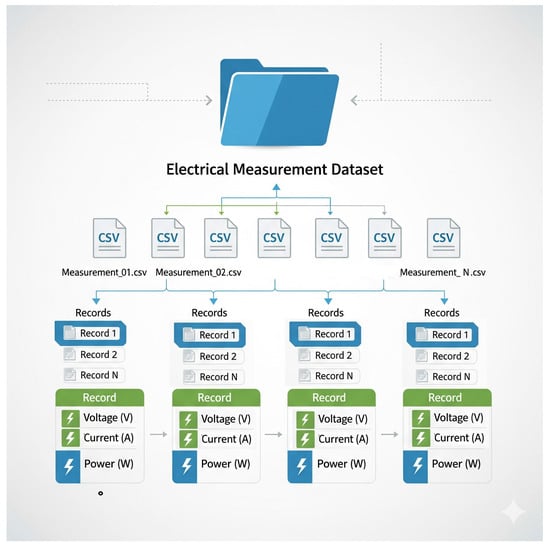
Figure 1























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}