
Semantic Partitioning and Machine Learning in Sentiment Analysis



Abstract
:1. Introduction
- Research question 1: What are the performances of the various machine-learning classifiers of the collected tweets that utilize various extracted features?
- Research question 2: What is the impact of applying semantic partitioning on the collected data prior to invoking machine-learning classifiers?
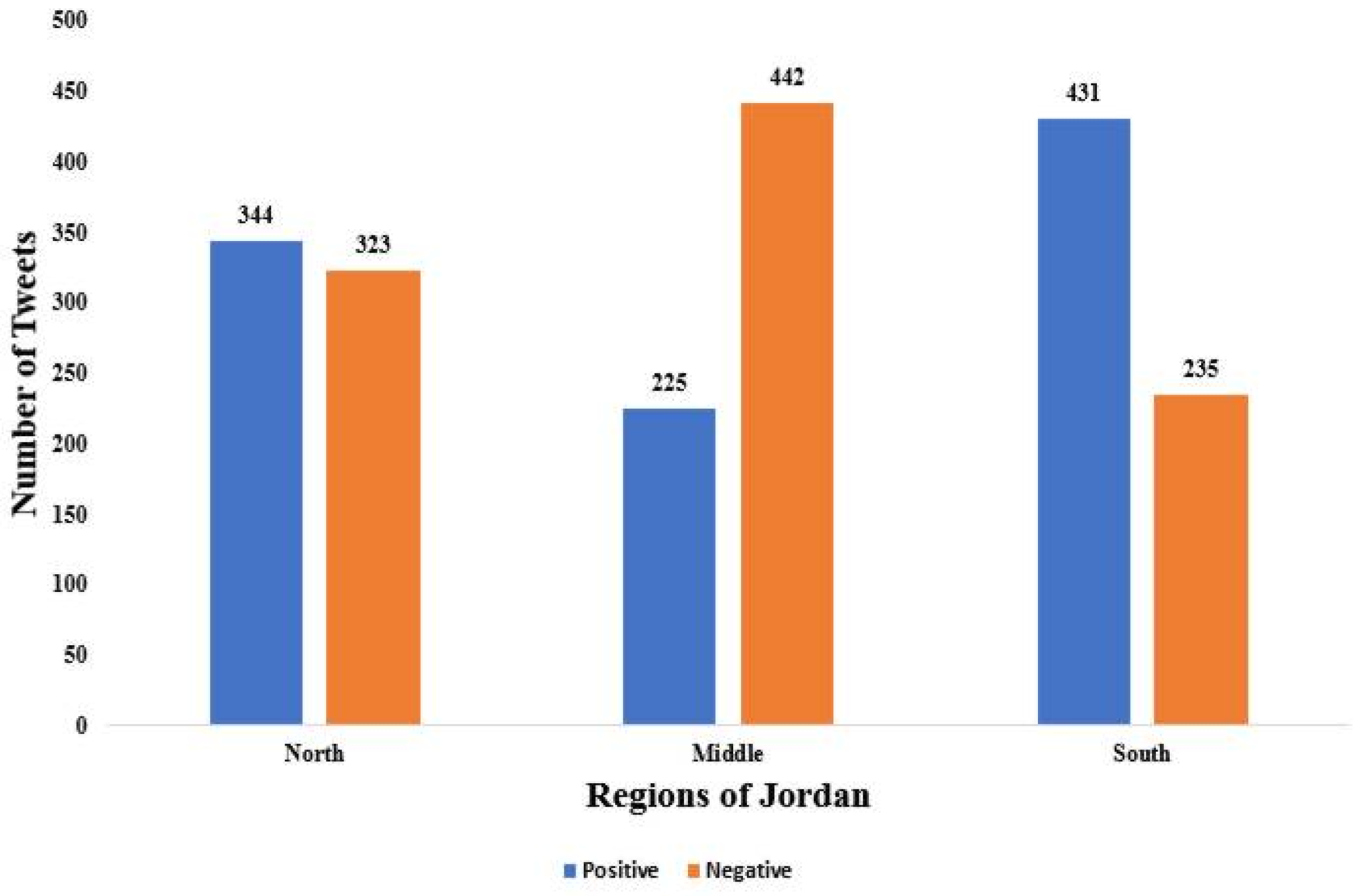
- Research question 3: What are the reactions of Jordanians toward government precautionary measures during the COVID-19 pandemic?
2. Proposed Methodology
2.1. Traditional Arabic Language (TAL) Model
| Algorithm 1. Traditional_Arabic_Language ( ) |
| Input: InSet: Set of collected Jordanian Arabic tweets. |
| Output: POutSet: Number of correctly classified positive tweets. |
| NOutSet: Number of correctly classified negative tweets. |
| Accuracy, Precision, Recall, F_Score: Evaluate the performance of the Arabic Language model. |
| Method: |
| 1. InSet=TextProcessing(InSet). |
| 2. InSet=FeatureExtraction(InSet). |
| 3. (TrainingSet, TestingSet)=Validation_Split(InSet). |
| 4. ClassifierModel()=Classifier(ClassifierName,TrainingSet). |
| 5. ConfusionMatrix=CalculateConfusionMatrix(ClassifierModel(TestingSet)). |
| 6. (POutSet,NOutSet,Accuracy,Precision,Recall,F_Score)=CalculateAccuracy(ConfusionMatrix). |
| 7. END Algorithm 1 |
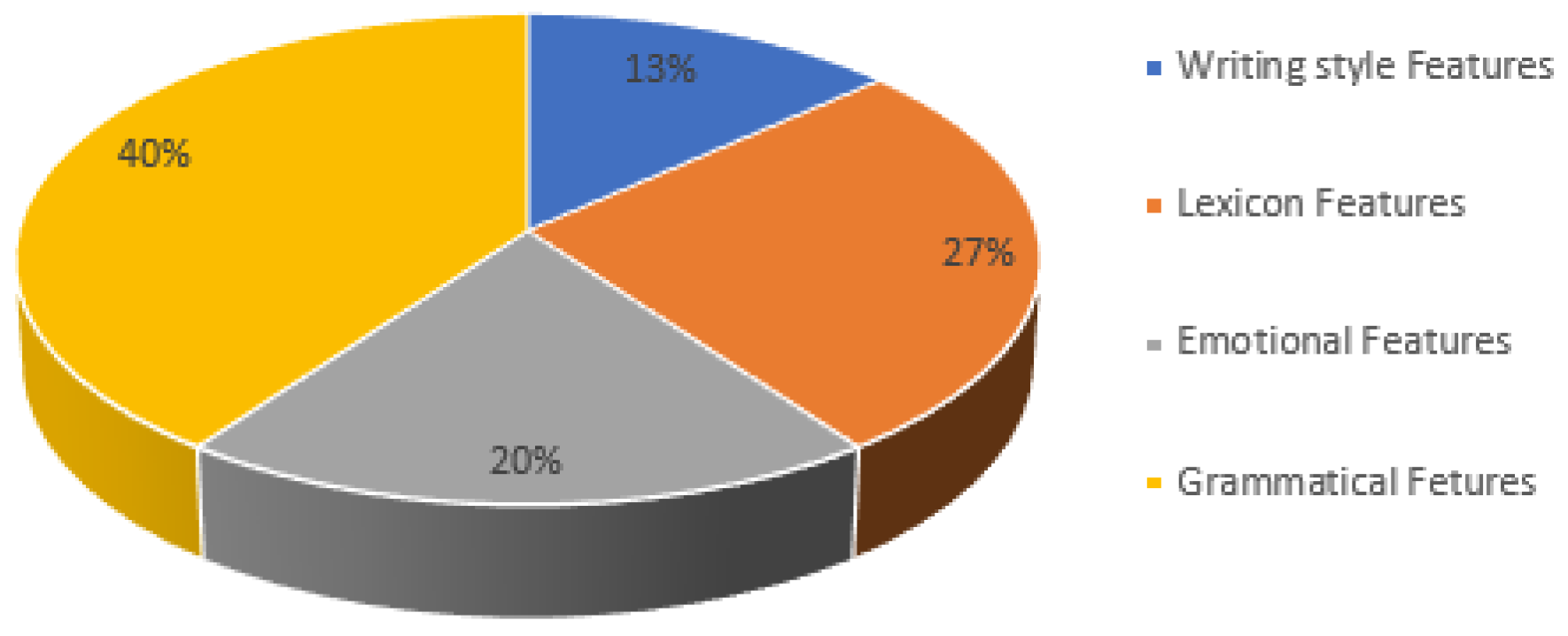
- Lexicon features: it focuses on the word–character structure and emphasizes its effect on the results by computing the number of words and the number of characters per tweet. Moreover, the number of words by length, varying from five characters to ten characters, were counted.
- Writing style features: the writing style is affected by user mood and the user style. Some users used numerical digits when writing certain Arabic letters, while others used special characters and symbols to represent their feelings. Moreover, some users used punctuation, which altered the tweet contents. Therefore, it is paramount to count the number of numerical digits, special characters, symbols, delimiters, and punctuation per tweet [50].
- Grammatical features: many researchers utilized grammatical features to understand the language. In our study, we analyzed 11 grammatical rules exercised in the Arabic tweets: Kan and sisters, Enna and sisters, question tools, exception tools, five verbs, five nouns, plural words, imperative clause, Nidaa clause, Eljar letters, and Eatf letters.
- Emotional features: we focused on SA to mine the emotional statuses of the tweet users. Polarity and emotion were identified in words inside the tweets. They are categorized as positive words, negative words, a combination of positive words, and a combination of negative words, as shown in Table 2.
2.2. Semantic Partitioning Arabic Language (SPAL) Model
| Algorithm 2. SemanticPartitioning_ArabicLanguage () |
| Input: InSet: Set of collected Jordanian Arabic tweets. |
| Output: POutSet: Number of correctly classified positive tweets. |
| NOutSet: Number of correctly classified negative tweets. |
| Accuracy, Precision, Recall, F_Score: Evaluate the performance of the Semantic Partitioning Arabic Language model. |
| Method: |
| 1. InSet=TextProcessing(InSet). |
| 2. InSet=FeatureExtraction(InSet). |
| 3. (SubSet1, SubSet2, …, SubSetn)= Semantic_Process(InSet). |
| 4. For each Subset Do |
| 4.1. (TrainingSubSet, TestingSubSet)=Validation_Split(SubSet). |
| 4.2. ClassifierModel()=Classifier(ClassifierName,TrainingSubSet). |
| 4.3. SubSetConfusionMatrix=CalculateConfusionMatrix(ClassifierModel(TestingSubSet)). |
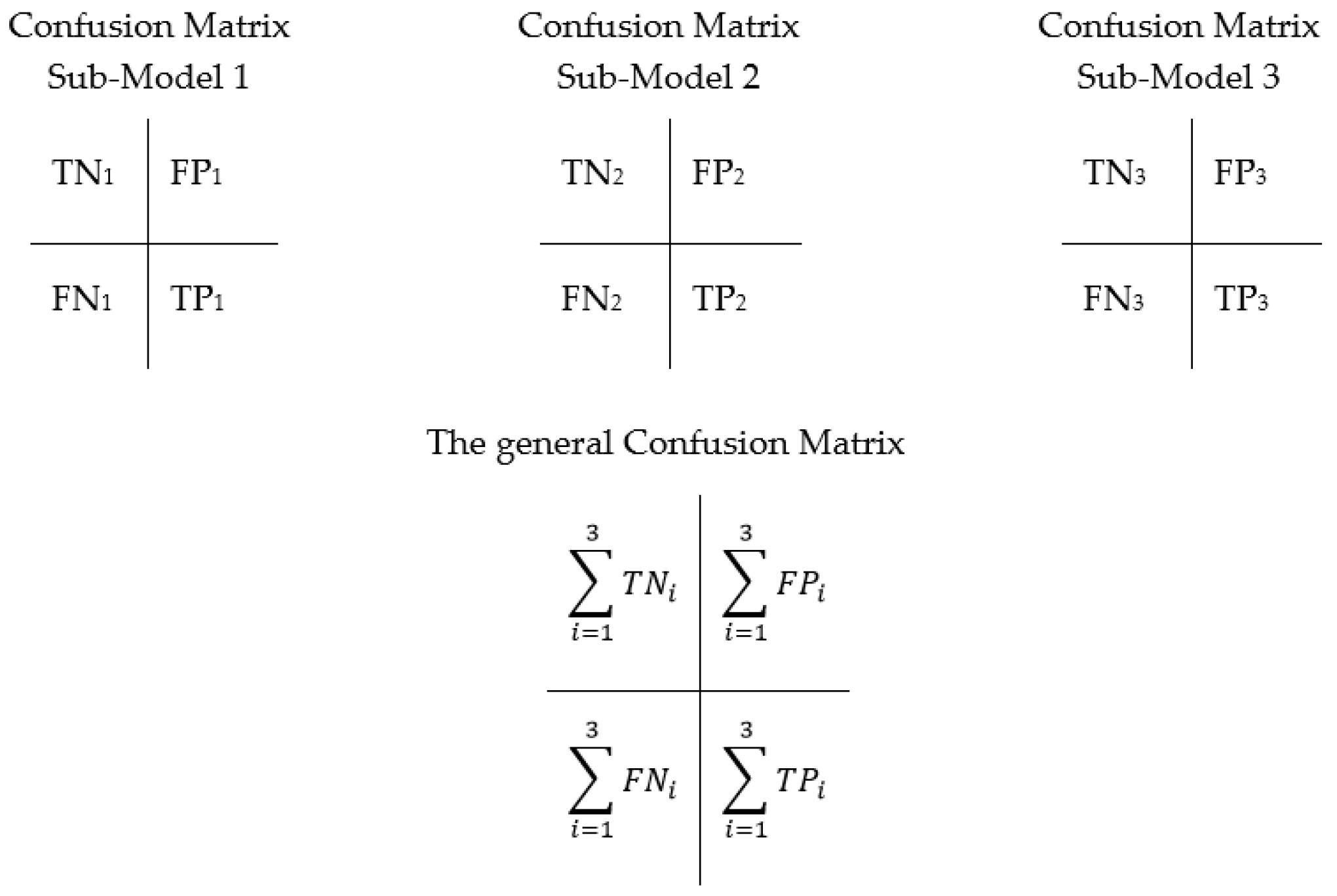
| 5. ConfusionMatrix=MergeConfusionMatrix(SubSetConfusionMatrix1, SubSetConfusionMatrix2,…, SubSetConfusionMatrixn). |
| 6. (POutSubSet,NOutSubSet,Accuracy,Precision,Recall,F_Score)=CalculateAccuracy(ConfusionMatrix). |
| 7. END Algorithm 2 |
- ◦
- TNi: the number of tweets that are negatively classified and their actual polarity is negative for the sub-model i.
- ◦
- TPi: the number of tweets that are positively classified and their actual polarity is positive for the sub-model i.
- ◦
- FNi: the number of tweets that are negatively classified and their actual polarity is positive for the sub-model i.
- ◦
- FPi: the number of tweets that are positively classified and their actual polarity is negative for the sub-model i.
3. Experimental Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Saura, J.R. Using Data Sciences in Digital Marketing: Framework, Methods, and Performance Metrics. J. Innov. Knowl. 2020, 6, 92–102. [Google Scholar] [CrossRef]
- Kastrenakes, J. Twitter’s Final Monthly User Count Shows a Company Still Struggling to Grow. THE VERGE. 23 April 2019. Available online: https://www.theverge.com/2019/4/23/18511383/twitter-q1-2019-earnings-report-mau (accessed on 1 April 2021).
- Boot, A.B.; Sang, E.T.K.; Dijkstra, K.; Zwaan, R.A. How Character Limit Affects Language Usage in Tweets. Palgrave Commun. 2019, 5, 76. [Google Scholar] [CrossRef]
- Boudad, N.; Faizi, R.; Thami, R.O.H.; Chiheb, R. Sentiment Analysis in Arabic: A Review of the Literature. Ain Shams Eng. J. 2018, 9, 2479–2490. [Google Scholar] [CrossRef]
- Liu, B. Sentiment Analysis and Opinion Mining. In Synthesis Lectures on Human Language Technologies; Morgan and Claypool Publishers: San Rafael, CA, USA, 2012; Volume 5, pp. 1–167. [Google Scholar]
- Groh, G.; Hauffa, J. Social relations via NLP-based sentiment analysis. In Proceedings of the 5th International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011. [Google Scholar]
- Gaur, N.; Sharma, N. Sentiment Analysis in Natural Language Processing. Int. J. Eng. Technol. 2017, 3, 144–148. [Google Scholar]
- Al Shamsi, A.A.; Abdallah, S. Text Mining Techniques for sentiment Analysis of Arabic Dialects: Literature Review. Adv. Sci. Technol. Eng. Syst. J. 2021, 6, 1012–1023. [Google Scholar] [CrossRef]
- Tsytsarau, M.; Palpanas, T. Survey on mining subjective data on the web. Data Min. Knowl. Discov. 2012, 24, 478–514. [Google Scholar] [CrossRef]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment Analysis Algorithms and Applications: A Survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef] [Green Version]
- Ghallab, A.; Mohsen, A.; Ali, Y. Arabic Sentiment Analysis: A Systematic Literature Review. Appl. Comput. Intell. Soft Comput. 2020, 2020, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Khan, K.; Baharudin, B.; Khan, A.; Ullah, A. Mining Opinion Components from Unstructured Reviews: A Review. J. King Saud Univ. Comput. Inf. Sci. 2014, 26, 258–275. [Google Scholar] [CrossRef] [Green Version]
- Kumar, M.R.P.; Prabhu, J. Role of sentiment classification in sentiment analysis: A survey. Ann. Libr. Inf. Stud. 2018, 65, 196–209. [Google Scholar]
- Alshamsi, A.; Bayari, R.; Salloum, S. Sentiment Analysis in English Texts. Adv. Sci. Technol. Eng. Syst. J. 2020, 5, 1683–1689. [Google Scholar] [CrossRef]
- Halabi, D.; Awajan, A.; Fayyoumi, E. Syntactic Annotation in the I3rab Dependency Treebank. Int. Arab. J. Inf. Technol. 2021, 18, 1. [Google Scholar]
- UNESCO. History of the Arabic Language at UNESCO. Available online: http://www.unesco.org/new/en/unesco/resources/history-of-the-arabic-language-at-unesco/ (accessed on 1 April 2021).
- Farghaly, A.; Shaalan, K. Arabic natural language processing: Challenges and solutions. ACM Trans. Asian Lang. Inf. Process. 2009, 8, 1–22. [Google Scholar] [CrossRef]
- Rushdi-Saleh, M.; Martin-Valdivia, M.-T.; Ureña-López, L.A.; Perea-Ortega, J.M. OCA: Opinion Corpus for Arabic. J. Am. Soc. Inf. Sci. Technol. 2011, 62, 2045–2054. [Google Scholar] [CrossRef]
- Alotaibi, S.S. Sentiment Analysis in the Arabic Language Using Machine Learning. Ph.D. Thesis, Colorado State University, Fort Collins, CO, USA, 2015. [Google Scholar]
- Defradas, M.; Embarki, M. Typology of Modern Arabic Dialects: Features, Methods and Models of Classification. In Proceedings of the Typology of Modern Arabic Dialects: Features, Methods and Models of Classification, Montpellier, France, 14–15 May 2007. [Google Scholar]
- Thakkar, H.; Patel, D. Approaches for Sentiment Analysis on Twitter: A State-of-Art study. arXiv 2015, arXiv:1512.01043. [Google Scholar]
- Biltawi, M.; Etaiwi, W.; Tedmori, S.; Hudaib, A.; Awajan, A. Sentiment Classification Techniques for Arabic Language: A Survey. In Proceedings of the 7th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 5–7 April 2016; pp. 339–346. [Google Scholar]
- El-Jawad, M.H.A.; Hodhod, R.; Omar, Y.M.K. Sentiment Analysis of Social Media Networks Using Machine Learning. In Proceedings of the 14th International Computer Engineering Conference (ICENCO), Cairo, Egypt, 29–30 December 2018. [Google Scholar]
- Araújo, M.; Diniz, M.L. A comparative study of machine translation for multilingual sentence-level sentiment analysis. Inf. Sci. 2020, 512, 1078–1102. [Google Scholar] [CrossRef] [Green Version]
- Al-Shabi, A.; Adel, A.; Omar, N.; Al-Moslmi, T. Cross-Lingual Sentiment Classification from English to Arabic Using Machine Translation. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 1. [Google Scholar] [CrossRef] [Green Version]
- Barhoumi, A.; Aloulou, C.; Camelin, N.; Estève, Y.; Belguith, L.H. Arabic Sentiment analysis: An empirical study of machine translation’s impact. In Proceedings of the Language Processing and Knowledge Management (LPKM), Sfax, Tunisia, 17–18 October 2018. [Google Scholar]
- Oueslati, O.; Cambria, E.; Ben HajHmida, M.; Ounelli, H. A Review of Sentiment Analysis Research in Arabic Language. Futur. Gener. Comput. Syst. 2020, 112, 408–430. [Google Scholar] [CrossRef]
- Duwairi, R.; El-Orfali, M. A Study of the Effects of Preprocessing Strategies on Sentiment Analysis for Arabic Text. J. Inf. Sci. 2014, 40, 501–513. [Google Scholar] [CrossRef] [Green Version]
- Balamurali, A.R.; Khapra, M.; Bhattachary, P. Lost in Translation: Viability of Machine Translation for Cross Language Sentiment Analysis. In Proceedings of the 14th International Conference on Computational Linguistics and Intelligent Text Processing, Samos, Greece, 24–30 March 2013. [Google Scholar]
- Guellil, I.; Saâdane, H.; Azouaou, F.; Gueni, B.; Nouvel, D. Arabic Natural Language Processing: An Overview. J. King Saud Univ. Comput. Inf. Sci. 2021, 33, 497–507. [Google Scholar] [CrossRef]
- Al-Osaimi, S.; Khan, M.B. Sentiment Analysis Challenges of Informal Arabic Language. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 1. [Google Scholar] [CrossRef] [Green Version]
- Al-Ayyoub, M.; Khamaiseh, A.A.; Jararweh, Y.; Al-Kabi, M.N. A Comprehensive Survey of Arabic Sentiment Analysis. Inf. Process. Manag. 2019, 56, 320–342. [Google Scholar] [CrossRef]
- Badaro, G.; Baly, R.; Hajj, H.; El-Hajj, W.; Shaban, K.B.; Habash, N.; Al-Sallab, A.; Hamdi, A. A survey of opinion mining in arabic: A comprehensive system perspective covering challenges and advances in tools, resources, models, applications, and visualizations. ACM Trans. Asian Low Resour. Lang. Inf. Process. 2019, 18, 1–52. [Google Scholar] [CrossRef] [Green Version]
- Abdallah, E.E.; Abo-Suaileek, S.A.-S. Feature-based Sentiment Analysis for Slang Arabic Text. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 298–304. [Google Scholar] [CrossRef]
- Alomari, K.M.; Elsherif, H.M.; Shaalan, K. Arabic Tweets Sentimental Analysis Using Machine Learning. In Proceedings of the International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Arras, France, 27–30 June 2017. [Google Scholar]
- Al-Harbi, O. Classifying Sentiment of Dialectal Arabic Reviews: A Semi-Supervised Approach. Int. Arab. J. Inf. Technol. 2019, 16, 995–1002. [Google Scholar]
- Abdulla, N.A.; Ahmed, N.A.; Shehab, M.A.; Al-Ayyoub, M. Arabic Sentiment Analysis: Lexicon-based and Corpus-based. In Proceedings of the 2013 IEEE Jordan Conference on Applied Electrical Engineering and Computing Technologies (AEECT), Amman, Jordan, 3–5 December 2013. [Google Scholar]
- Abdul-Mageed, M.; Diab, M.; Kübler, S. SAMAR: Subjectivity and Sentiment Analysis for Arabic Social Media. Comput. Speech Lang. 2014, 28, 20–37. [Google Scholar] [CrossRef]
- Alhumoud, S.O.; Al Wazrah, A.A. Arabic Sentiment Analysis Using Recurrent Neural Networks: A Review. Artif. Intell. Rev. 2021, 1–42. [Google Scholar] [CrossRef]
- Hussien, I.O.; Dashtipour, K.; Hussain, A. Comparison of Sentiment Analysis Approaches Using Modern Arabic and Sudanese Dialect. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 10989, pp. 615–624. [Google Scholar]
- Huang, S.; Han, T.; Ansari, N. Big-data-driven network partitioning for ultra-dense radio access networks. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017. [Google Scholar]
- Sawant, M.; Kinage, K.; Pilankar, P.; Chaudhari, N. Database Partitioning: A Review Paper. Int. J. Innov. Technol. Explor. Eng. 2013, 3, 82–85. [Google Scholar]
- Fayyoumi, E.; ALhiniti, O. Recursive Genetic Micro-Aggregation Technique: Information Loss, Disclosure Risk and Scoring Index. Data 2021, 6, 53. [Google Scholar] [CrossRef]
- Hasan, H.; Chuprat, S. Secured data partitioning in multi cloud environment. In Proceedings of the 2014 4th World Congress on Information and Communication Technologies (WICT 2014), Malacca, Malaysia, 8–11 December 2014. [Google Scholar]
- Kaviani, N.; Wohlstadter, E.; Lea, R. Partitioning of Web Applications for Hybrid Cloud Deployment. J. Internet Serv. Appl. 2014, 5, 14. [Google Scholar] [CrossRef] [Green Version]
- Aljameel, S.S.; Alabbad, D.A.; Alzahrani, N.A.; AlQarni, S.M.; AlAmoudi, F.A.; Babili, L.M.; Aljaafary, S.K.; Alshamrani, F.M. A Sentiment Analysis Approach to Predict an Individual’s Awareness of the Precautionary Procedures to Prevent COVID-19 Outbreaks in Saudi Arabia. Int. J. Environ. Res. Public Health 2020, 18, 218. [Google Scholar] [CrossRef]
- Albahli, S.; Algsham, A.; Aeraj, S.; Alsaeed, M.; Alrashed, M.; Rauf, H.T.; Arif, M.; Mohammed, M.A. COVID-19 Public Sentiment Insights: A Text Mining Approach to the Gulf Countries. Comput. Mater. Contin. 2021, 67, 1613–1627. [Google Scholar] [CrossRef]
- Alhumoud, S. Arabic Sentiment Analysis using Deep Learning for COVID-19 Twitter Data. IJCSNS Int. J. Comput. Sci. Netw. Secur. 2020, 20, 132–183. [Google Scholar]
- Al-Tammemi, A.B. The Battle against COVID-19 in Jordan: An Early Overview of the Jordanian Experience. Front. Public Health 2020, 8, 1. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Zhang, X.; Li, K. A Sentiment Classification Model Using Group Characteristics of Writing Style Features. Int. J. Pattern Recognit. Artif. Intell. 2017, 31, 1. [Google Scholar] [CrossRef]
- Jakkula, V. Tutorial on Support Vector Machine (SVM); School EECS, Washington State University: Washington, DC, USA, 2011. [Google Scholar]
- Awad, M.; Khanna, R. Support Vector Machines for Classification. In Efficient Learning Machines Theories, Concepts, and Applications for Engineers and System Designers; Apress Open: New York, NY, USA, 2015. [Google Scholar]
- Lowd, D.; Domingos, P. Naive Bayes models for probability estimation. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 529–536. [Google Scholar]
- Nguyen, S.T.; Do, P.M.T. Classification optimization for training a large dataset with Naïve Bayes. J. Comb. Optim. 2020, 40, 141–169. [Google Scholar] [CrossRef]
- Sharma, P. Comparative Analysis of Various Decision Tree Classification Algorithms Using WEKA. Int. J. Recent Innov. Trends Comput. Commun. 2015, 3, 684–690. [Google Scholar] [CrossRef]
- Patel, N.; Upadhyay, S. Study of Various Decision Tree Pruning Methods with Their Empirical Comparison in WEKA. Int. J. Comput. Appl. 2012, 60, 20–25. [Google Scholar] [CrossRef]
- Karabulut, E.M.; Özel, S.A.; Ibrikci, T. A Comparative Study on the Effect of Feature Selection on Classification Accuracy. Procedia Technol. 2012, 1, 323–327. [Google Scholar] [CrossRef] [Green Version]
- Fayyoumi, E.; Idwan, S.; AboShindi, H. Machine Learning and Statistical Modelling for Prediction of Novel COVID-19 Patients Case Study: Jordan. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 122–126. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable, 1st ed.; Lulu: Morrisville, NC, USA, 2019. [Google Scholar]
- Fang, J. Why Logistic Regression Analyses Are More Reliable than Multiple Regression Analyses. J. Bus. Econ. 2013, 4, 620–633. [Google Scholar]
- Dencelin, L.; Ramkumar, T. Analysis of multilayer perceptron machine learning approach in classifying protein secondary structures. Biomed. Res. Comput. Life Sci. Smarter Technol. Adv. 2016, 1, S166–S173. [Google Scholar]
- Han, J.; Kamber, M. Data Mining: Concepts and Techniques; Morgan Kaufmann Publishers: San Francisco, CA, USA, 2001. [Google Scholar]
- Frank, E.; Hall, M.A.; Holmes, G.; Kirkby, R.B.; Pfahringer, B.; Witten, I.H.; Trigg, L. Weka-A Machine Learning Workbench for Data Mining. In Data Mining and Knowledge Discovery Handbook; Springer: Boston, MA, USA, 2009; pp. 1269–1277. [Google Scholar]
- Singh, J.; Singh, G.; Singh, R. Optimization of Sentiment Analysis Using Machine Learning Classifiers. Human Centric Comput. Inf. Sci. 2017, 7, 32. [Google Scholar] [CrossRef]
- Al-Batah, M.S.; Mrayyen, S.; Alzaqebah, M. Arabic Sentiment Classification Using MLP Network Hybrid with Naive Bayes Algorithm. J. Comput. Sci. 2018, 14, 1104–1114. [Google Scholar] [CrossRef] [Green Version]
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. Beyond Accuracy, F-Score and ROC: A Family of Discriminant Measures for Performance Evaluation. In AI 2006: Advances in Artificial Intelligence; Springer: Berlin, Germany, 2006; pp. 1015–1021. [Google Scholar]
- Furini, M.; Montangero, M. TSentiment: On Gamifying Twitter Sentiment Analysis. In Proceedings of the 2016 IEEE Symposium on Computers and Communication (ISCC), Messina, Italy, 27–30 June 2016; pp. 91–96. [Google Scholar]
- Oommen, J.; Fayyoumi, E. A novel method for micro-aggregation in secure statistical databases using association and interaction. In Proceedings of the International Conference on Information and Communications Security, Zhengzhou, China, 12–15 December 2007; pp. 126–140. [Google Scholar]
- Oommen, J.; Fayyoumi, E. On utilizing dependence-based information to enhance micro-aggregation for secure statistical databases. Pattern Anal. Appl. 2013, 16, 99–116. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Polarity | Tweet |
|---|---|
| Positive | (أطباء و ممرضين الاردن هم خط الدفاع الأول في مواجهة مرض كورونا… اللهم أحفظهم جميعا و ردهم الى اهلهم سالمين); (atibaa’ w mumaridin alardin hum khatu aldifae al’awal fi muajahat marad kuruna… allahumm ‘ahfazahum jamieana w radahum alaa ahilahum salimin); (Jordan’s doctors and nurses are the first line of defense in the face of corona disease… May Allah protect them all and return them to their families safely) |
| Positive | (تجنب المصافحة والإتصال المباشر مع الأشخاص وخل السلام نظر); (tajanub almusafahat wal’iitisal almubashir mae al’ashkhas wakhalu alsalam nazar); (Avoid handshakes and direct contact with people and keep the peace of mind) |
| Positive | (مع هذا الوباء تعلمنا من فيروس كورنا إن يومنا العادي ماكان ابداً يوم عادي ، إنما كان نعمة من نعم الله سبحانه وتعالى); (mae hadha alwaba’ tuealamuna min fayrus kurna ‘iina yawmana aleadia makan abdaan yawm eadi, ‘iinama kan niematan min nieam allah subhanah wataealaa); (With this epidemic, we learned from the Corona virus that our normal day was never an ordinary day, but it was a blessing from the blessings of God Almighty) |
| Positive | (تحية فخر واعتزاز بوزير صحتنا الانسان الباشا سعد جابر وبكل طبيب وممرض وصيدلاني وفني وكافة الكوادر في القطاع الصحي الذين يسهروا على سلامتنا رغم تعريض انفسهم للعدوى); (tahiat fakhr waietizaz biwazir sihatina alainsan albasha saed jabir wabikuli tabib wamumarid wasaydilaniun wafaniyun wakafat alkawadir fi alqitae alsihiyi aladhin yasharuu ealaa salamatina raghm taerid ainfsihim lileadwaa); (Greetings of pride and pride to our Minister of Health, the human being, Pasha Saad Jaber, and to all the doctors, nurses, pharmacists, technicians and all cadres in the health sector who ensure our safety despite exposing themselves to infection) |
| Negative | (ليس من باب التشاؤم، لكن إنخفاض الاصابات ليس مؤشر ايجابي او سلبي، المهم هو الجدول الزمني كامل لخطة احتواء المرض); (lays min bab altashawumu, lakina ‘iinkhifad alasabat lays muashir ayjaby aw salbi, almuhimu hu aljadwal alzamaniu kamil likhutat ahtiwa’ almarad); (Not out of pessimism, but the decrease in infections is not a positive or negative indicator, the important thing is the complete schedule of the disease containment plan) |
| Negative | (يا ريت الحكومة تصير تعطينا رقم الفحوصات اللي قاعدة تعملها يومياً للتوضيح، لأنه للأمانة كيرف الأردن (وكثير دول عربية) رياضياً مش منطقي…); (ya ryt alhukumat tasir tuetina raqm alfuhusat allly qaeidatan taemaluha ywmyaan liltawdihi, li’anah lil’amanat kirf al’urdun (wkathir dual earabiatun) ryadyaan mish mantiqi…); (I wish the government would give us the number of tests that it does daily for clarification, because to be honest, Jordan (and many Arab countries) is mathematically not logical…) |
| Negative | (عيب وعار عليكم …يعني للاسف عندي معلومات عن ناس حضروا حفلة العرس لكنهم مختبئين مع كل اسف…); (eayb waear ealaykum …yaeni lilasif eindi maelumat ean nas hadaruu haflat aleurs lakinahum mukhtabiiyn mae kuli asf…); (Shame on you… I mean, unfortunately, I have information about people who attended the wedding party, but they are hiding, with all the regret…) |
| Negative | (سيبونا من أعراض #كورونا مين بلشت تظهر عنده أعراض الإفلاس); ( sibuna min ‘aerad #kuruna min balisht tazhar eindah ‘aerad al’iiflas); (Sibona is one of the symptoms of #Corona, who started showing symptoms of bankruptcy) |
| Negative | (ناس يا عالم يا هووووو…. انا قبل أربع سنوات إنتخبت مجلس نواب #وينهم ؟؟؟؟) (ya nas ya ealam ya huwuwu…. ana qabl ‘arbae sanawat ‘iintakhabat majlis nuaab #wianhim ????); (Hey people, world, hoooooooo….Four years ago, I elected parliament #Where are they????) |
| Emotional Features | Example |
|---|---|
| Positive word feature | الحمد الله; alhamd allah; Praise be to God تفاؤل; tafawulu; optimism تعاون; taeawuni; cooperation يعافينا; yaeafina; recovery يشفي; yashfi; healing أفضل; ‘afdal; better سعيد; saeid; happy فرج; faraj; relief |
| Negative word feature | خوف; khufa; Fear هلع; halaea; panic موت; mut; death وفيات; wafiat; deaths فساد; fasad; corruption حرامية; haramiat; thieves مش; mash; not ملعون; maleun; cursed مغصوص; maghsus; crippled |
| Combination of positive words | لعنة الله عليك; laenat allah ealayk; God damn you ارتفاع الأسعار; airtifae al’asear; Rising prices ما بنعرف وين; ma binaerif win; We don’t know where سيب الموضوع; sib almawdue; Leave the topic |
| Combination of negative words | معك حق; maeak haqun; You are right الأمل بالله; al’amal biallah; Hope in God فسحة أمل; fushat ‘amal; a space of hope بيعين الله; bieayn allah; God bless |
| Polarity | Tweet |
|---|---|
| Negative | (ليس من باب التشاؤم، لكن إنخفاض الاصابات ليس مؤشر ايجابي او سلبي، المهم هو الجدول الزمني كامل لخطة احتواء المرض); (lays min bab altashawumu, lakina ‘iinkhifad alasabat lays muashir ayjaby aw salbi, almuhimu hu aljadwal alzamaniu kamil likhutat ahtiwa’ almarad); (Not out of pessimism, but the decrease in infections is not a positive or negative indicator, the important thing is the complete schedule of the disease containment plan) كامل لخطة احتواء المرض |
| Positive | (تجنب المصافحة والإتصال المباشر مع الأشخاص وخل السلام نظر); (tajanub almusafahat wal’iitisal almubashir mae al’ashkhas wakhalu alsalam nazar); (Avoid handshakes and direct contact with people and keep the peace of mind) |
| Positive | (أطباء و ممرضين الاردن هم خط الدفاع الأول في مواجهة مرض كورونا… اللهم أحفظهم جميعا و ردهم الى اهلهم سالمين); (atibaa’ w mumaridin alardin hum khatu aldifae al’awal fi muajahat marad kuruna… allahumm ‘ahfazahum jamieana w radahum alaa ahilahum salimin); (Jordan’s doctors and nurses are the first line of defense in the face of corona disease… May Allah protect them all and return them to their families safely) |
| Polarity | Tweet |
|---|---|
| Negative | (عيب وعار عليكم …يعني للاسف عندي معلومات عن ناس حضروا حفلة العرس لكنهم مختبئين مع كل اسف…); ( eayb waear ealaykum …yaeni lilasif eindi maelumat ean nas hadaruu haflat aleurs lakinahum mukhtabiiyn mae kuli asf…); (Shame on you… I mean, unfortunately, I have information about people who attended the wedding party, but they are hiding, with all the regret…) |
| Negative | (سيبونا من أعراض #كورونا مين بلشت تظهر عنده أعراض الإفلاس); ( sibuna min ‘aerad #kuruna min balisht tazhar eindah ‘aerad al’iiflas); (Sibona is one of the symptoms of #Corona, who started showing symptoms of bankruptcy) |
| Positive | (مع هذا الوباء تعلمنا من فيروس كورنا إن يومنا العادي ماكان ابداً يوم عادي ، إنما كان نعمة من نعم الله سبحانه وتعالى); (mae hadha alwaba’ tuealamuna min fayrus kurna ‘iina yawmana aleadia makan abdaan yawm eadi, ‘iinama kan niematan min nieam allah subhanah wataealaa); (With this epidemic, we learned from the Corona virus that our normal day was never an ordinary day, but it was a blessing from the blessings of God Almighty) |
| Polarity | Tweet |
|---|---|
| Negative | (يا ريت الحكومة تصير تعطينا رقم الفحوصات اللي قاعدة تعملها يومياً للتوضيح، لأنه للأمانة كيرف الأردن (وكثير دول عربية) رياضياً مش منطقي…); (ya ryt alhukumat tasir tuetina raqm alfuhusat allly qaeidatan taemaluha ywmyaan liltawdihi, li’anah lil’amanat kirf al’urdun (wkathir dual earabiatun) ryadyaan mish mantiqi…); (I wish the government would give us the number of tests that it does daily for clarification, because to be honest, Jordan (and many Arab countries) is mathematically not logical…) |
| Positive | (تحية فخر واعتزاز بوزير صحتنا الانسان الباشا سعد جابر وبكل طبيب وممرض وصيدلاني وفني وكافة الكوادر في القطاع الصحي الذين يسهروا على سلامتنا رغم تعريض انفسهم للعدوى); (tahiat fakhr waietizaz biwazir sihatina alainsan albasha saed jabir wabikuli tabib wamumarid wasaydilaniun wafaniyun wakafat alkawadir fi alqitae alsihiyi aladhin yasharuu ealaa salamatina raghm taerid ainfsihim lileadwaa); (Greetings of pride and pride to our Minister of Health, the human being, Pasha Saad Jaber, and to all the doctors, nurses, pharmacists, technicians and all cadres in the health sector who ensure our safety despite exposing themselves to infection) |
| Negative | (ناس يا عالم يا هووووو…. انا قبل أربع سنوات إنتخبت مجلس نواب #وينهم ؟؟؟؟) (ya nas ya ealam ya huwuwu…. ana qabl ‘arbae sanawat ‘iintakhabat majlis nuaab #wianhim ????); (Hey people, world, hoooooooo….Four years ago, I elected parliament #Where are they????) |
| Classified Method | Analysis Model | Accuracy (%) | Correctly Classified | Misclassified |
|---|---|---|---|---|
| SVM | TAL | 66.67 | 400 | 200 |
| SPAL | 69.33 | 416 | 184 | |
| NB | TAL | 58.33 | 350 | 250 |
| SPAL | 59.18 | 355 | 245 | |
| J48 | TAL | 70.83 | 425 | 175 |
| SPAL | 71.73 | 430 | 170 | |
| MLP | TAL | 67.00 | 402 | 198 |
| SPAL | 69.83 | 419 | 181 | |
| LR | TAL | 62.83 | 377 | 223 |
| SPAL | 63.50 | 381 | 219 |
| Classified Method | Analysis Model | Polarity | Precision | Recall | F-Score |
|---|---|---|---|---|---|
| SVM | TAL | Positive | 0.711 | 0.844 | 0.771 |
| Negative | 0.500 | 0.313 | 0.385 | ||
| Weighted Average | 0.640 | 0.667 | 0.642 | ||
| SPAL | Positive | 0.462 | 0.429 | 0.444 | |
| Negative | 0.778 | 0.800 | 0.789 | ||
| Weighted Average | 0.687 | 0.694 | 0.690 | ||
| NB | TAL | Positive | 0.667 | 0.750 | 0.706 |
| Negative | 0.333 | 0.250 | 0.286 | ||
| Weighted Average | 0.556 | 0.583 | 0.566 | ||
| SPAL | Positive | 0.286 | 0.286 | 0.286 | |
| Negative | 0.714 | 0.714 | 0.714 | ||
| Weighted Average | 0.592 | 0.592 | 0.592 | ||
| J48 | TAL | Positive | 0.705 | 0.969 | 0.816 |
| Negative | 0.750 | 0.188 | 0.300 | ||
| Weighted Average | 0.720 | 0.708 | 0.644 | ||
| SPAL | Positive | 0.600 | 0.400 | 0.480 | |
| Negative | 0.750 | 0.871 | 0.806 | ||
| Weighted Average | 0.701 | 0.717 | 0.700 | ||
| MLP | TAL | Positive | 0.742 | 0.869 | 0.795 |
| Negative | 0.528 | 0.354 | 0.374 | ||
| Weighted Average | 0.652 | 0.673 | 0.658 | ||
| SPAL | Positive | 0.442 | 0.471 | 0.468 | |
| Negative | 0.795 | 0.797 | 0.792 | ||
| Weighted Average | 0.696 | 0.712 | 0.693 | ||
| LR | TAL | Positive | 0.896 | 0.670 | 0.604 |
| Negative | 0.253 | 0.365 | 0.374 | ||
| Weighted Average | 0.623 | 0.572 | 0.598 | ||
| SPAL | Positive | 0.500 | 0.071 | 0.625 | |
| Negative | 0.723 | 0.971 | 0.829 | ||
| Weighted Average | 0.660 | 0.714 | 0.628 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fayyoumi, E.; Idwan, S. Semantic Partitioning and Machine Learning in Sentiment Analysis. Data 2021, 6, 67. https://doi.org/10.3390/data6060067
Fayyoumi E, Idwan S. Semantic Partitioning and Machine Learning in Sentiment Analysis. Data. 2021; 6(6):67. https://doi.org/10.3390/data6060067
Chicago/Turabian StyleFayyoumi, Ebaa, and Sahar Idwan. 2021. "Semantic Partitioning and Machine Learning in Sentiment Analysis" Data 6, no. 6: 67. https://doi.org/10.3390/data6060067
APA StyleFayyoumi, E., & Idwan, S. (2021). Semantic Partitioning and Machine Learning in Sentiment Analysis. Data, 6(6), 67. https://doi.org/10.3390/data6060067